高可用(high availability,HA)指的是若当前工作中的机器宕机了,系统会自动处理异常,并将工作无缝地转移到其他备用机器上,以保证服务的高可靠性与可用性。
而Zookeeper是一个分布式协调服务,Zookeeper即可用来保证Hadoop集群的高可用性。通过zookeeper集群与Hadoop2.X中的两个NameNode节点之间的通信,保证集群中总有一个可用的NameNode(即active NameNode),从而实现双NameNode节点构成的NameNode HA,达到HDFS高可用性。同Zookeeper也可用来保证ResourceManager HA,即实现YARN高可用性。
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode放在同一台机器上。
这里装了四台机器,ant151,ant152,ant153,ant154。这里的四台机器均已经安装了zookeeper。
zookeeper安装步骤见→zookeeper集群搭建
ant151 | ant152 | ant153 | ant154 |
NameNode | NameNode | ||
DataNode | DataNode | DataNode | DataNode |
NodeManager | NodeManager | NodeManager | NodeManager |
ResourceManager | ResourceManager | ||
JournalNode | JournalNode | JournalNode | |
DFSZKFController | DFSZKFController | ||
zk0 | zk1 | zk2 |
Hadoop配置文件分为默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件。
core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml四个配置文件放在$HADOOP_HOME/etc/hadoop路径下。
<property>
<name>fs.defaultFS</name>
<value>hdfs://gky</value>
<description>逻辑名称,必须与hdfs-site.xml中的dfs.nameservices值保持一致</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/soft/hadoop313/tmpdata</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
<description>默认用户</description>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
<description></description>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
<description></description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>读写文件的buffer大小为:128K</description>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>ant151:2181,ant152:2181,ant153:2181</value>
<description></description>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>10000</value>
<description>hadoop链接zookeeper的超时时长设置为10s</description>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>Hadoop中每一个block的备份数</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/soft/hadoop313/data/dfs/name</value>
<description>namenode上存储hdfs名字空间元数据目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/soft/hadoop313/data/dfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ant151:9869</value>
<description></description>
</property>
<property>
<name>dfs.nameservices</name>
<value>gky</value>
<description>指定hdfs的nameservice,需要和core-site.xml中保持一致</description>
</property>
<property>
<name>dfs.ha.namenodes.gky</name>
<value>nn1,nn2</value>
<description>gky为集群的逻辑名称,映射两个namenode逻辑名</description>
</property>
<property>
<name>dfs.namenode.rpc-address.gky.nn1</name>
<value>ant151:9000</value>
<description>namenode1的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.gky.nn1</name>
<value>ant151:9870</value>
<description>namenode1的http通信地址</description>
</property>
<property>
<name>dfs.namenode.rpc-address.gky.nn2</name>
<value>ant152:9000</value>
<description>namenode2的RPC通信地址</description>
</property>
<property>
<name>dfs.namenode.http-address.gky.nn2</name>
<value>ant152:9870</value>
<description>namenode2的http通信地址</description>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ant151:8485;ant152:8485;ant153:8485/gky</value>
<description>指定NameNode的edits元数据的共享存储位置(JournalNode列表)</description>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/soft/hadoop313/data/journaldata</value>
<description>指定JournalNode在本地磁盘存放数据的位置</description>
</property>
<!-- 容错 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<description>开启NameNode故障自动切换</description>
</property>
<property>
<name>dfs.client.failover.proxy.provider.gky</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<description>失败后自动切换的实现方式</description>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<description>防止脑裂的处理</description>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<description>使用sshfence隔离机制时,需要ssh免密登陆</description>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<description>关闭HDFS操作权限验证</description>
</property>
<property>
<name>dfs.image.transfer.bandwidthPerSec</name>
<value>1048576</value>
<description></description>
</property>
<property>
<name>dfs.block.scanner.volume.bytes.per.second</name>
<value>1048576</value>
<description></description>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>job执行框架: local, classic or yarn</description>
<final>true</final>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>ant151:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>ant151:19888</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>map阶段的task工作内存</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>2048</value>
<description>reduce阶段的task工作内存</description>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>开启resourcemanager高可用</description>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrcabc</value>
<description>指定yarn集群中的id</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>指定resourcemanager的名字</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>ant153</value>
<description>设置rm1的名字</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>ant154</value>
<description>设置rm2的名字</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>ant153:8088</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>ant154:8088</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>ant151:2181,ant152:2181,ant153:2181</value>
<description>指定zk集群地址</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>运行mapreduce程序必须配置的附属服务</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/soft/hadoop313/tmpdata/yarn/local</value>
<description>nodemanager本地存储目录</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/soft/hadoop313/tmpdata/yarn/log</value>
<description>nodemanager本地日志目录</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
<description>resource进程的工作内存</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
<description>resource工作中所能使用机器的内核数</description>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>256</value>
<description></description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>开启日志聚集功能</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
<description>日志保留多少秒</description>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description></description>
</property>
<property>
<name>yarn.application.classpath</name>
<value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
<description></description>
</property>
export JAVA_HOME=/opt/soft/jdk180
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
ant151
ant152
ant153
ant154
vim /etc/profile
启动hadoop集群,需要有java环境,这里的JAVA_HOME同样也要配置
# HADOOP_HOME
export HADOOP_HOME=/opt/soft/hadoop313
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/lib
# JAVA_HOME
export JAVA_HOME=/opt/soft/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
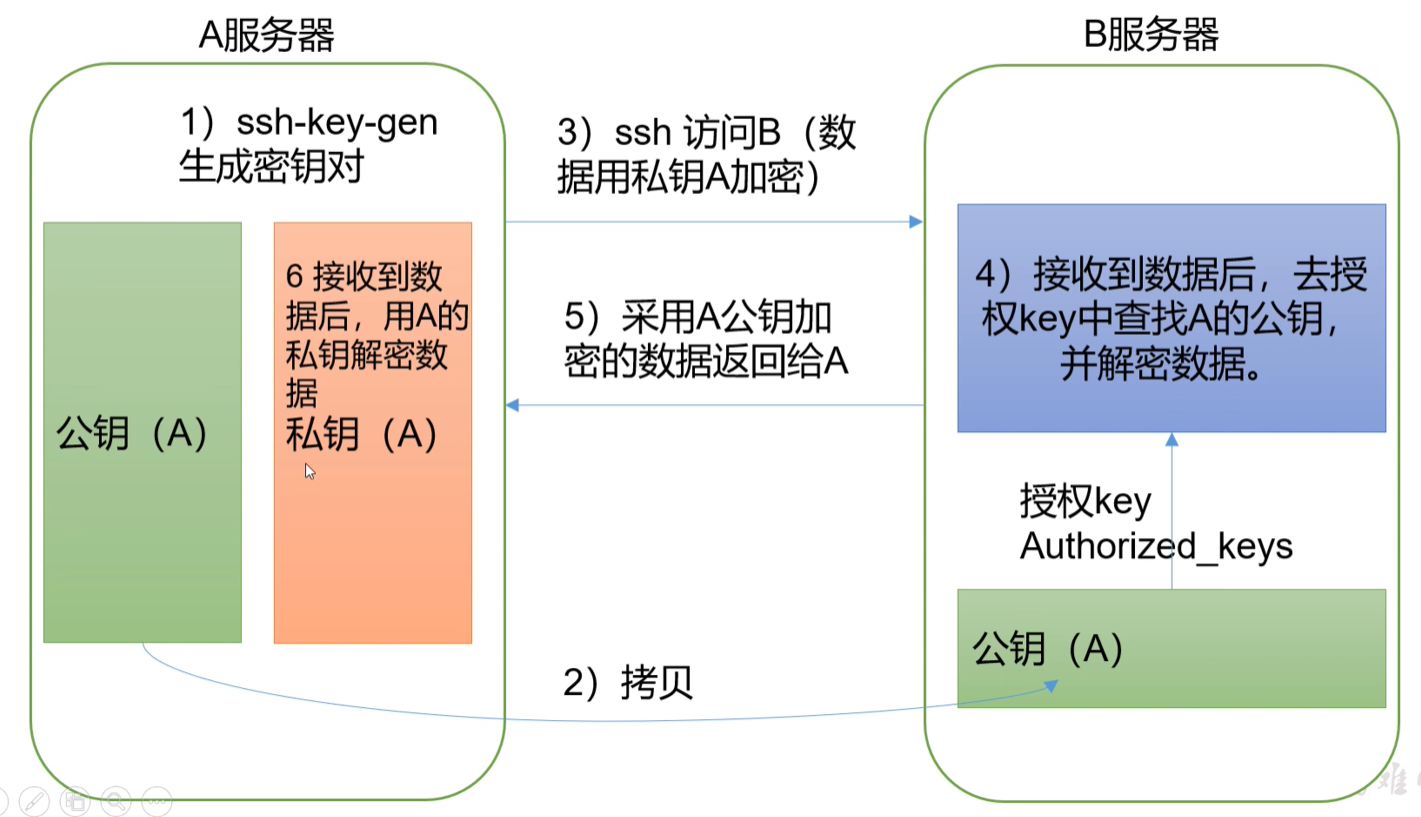
所有提示均按回车默认
[root@hadoop02 .ssh]# ssh-keygen -t rsa -P ''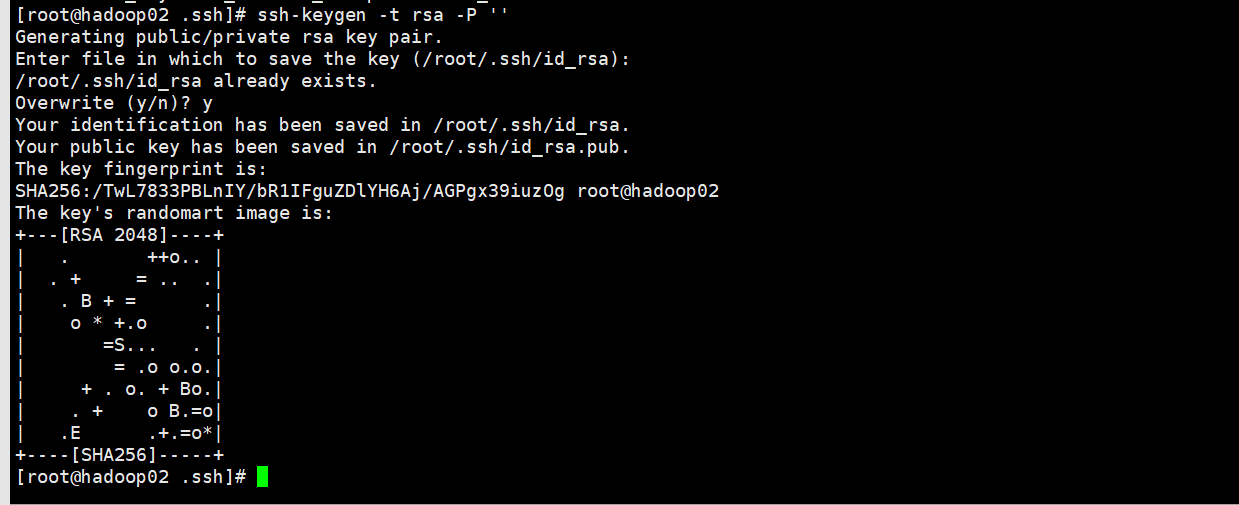
在用户的家目录下回自动生成一个隐藏的文件夹“.ssh”,里面会有两个文件,分别是id_rsa和id_rsa.pub
id_rsa是本机的私钥,在使用ssh协议向其它主机传输数据前,主机会使用该私钥对数据进行加密;
id_rsa.pub是本机的公钥,因为ssh协议采用非对称加密法(公钥可以用来解密使用私钥进行加密的数据,同样,私钥也可以用来解密公钥进行加密的数据),所以主机一般将该公钥放到其它需要远程登录到的主机的ssh服务器中

# 将公钥追加到authorized_keys文件中(免密登录自己)
[root@hadoop02 .ssh]# cat /root/.ssh/id_rsa.pub >> ./authorized_keys
# 上传公钥到ant152、ant153中
[root@hadoop02 .ssh]# ssh-copy-id -i ./id_rsa.pub -p22 root@ant152
[root@hadoop02 .ssh]# ssh-copy-id -i ./id_rsa.pub -p22 root@ant153
[root@hadoop02 .ssh]# systemctl restart sshd
# 免密登录
[root@hadoop02 .ssh]# ssh ant153
可以直接运行脚本文件
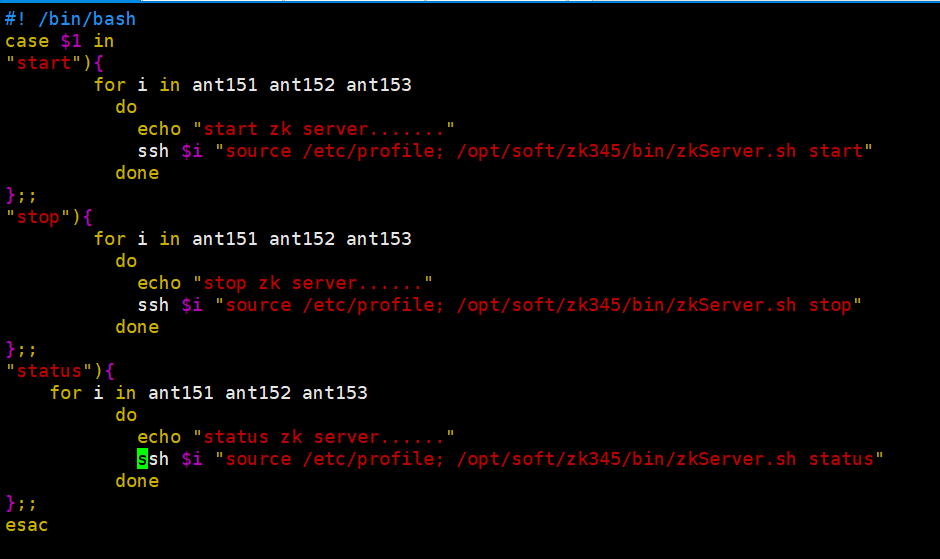
代码:
[root@ant151 shell]# ./zkop.sh start 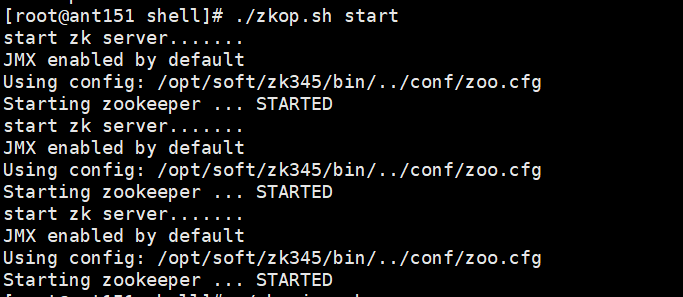
[root@ant151 shell]# hdfs --daemon start journalnode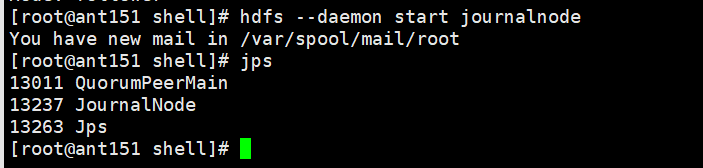
[root@ant151 shell]# hdfs namenode -format
[root@ant151 shell]# hdfs --daemon start namenode
[root@ant151 shell]# hdfs namenode -bootstrapStandby
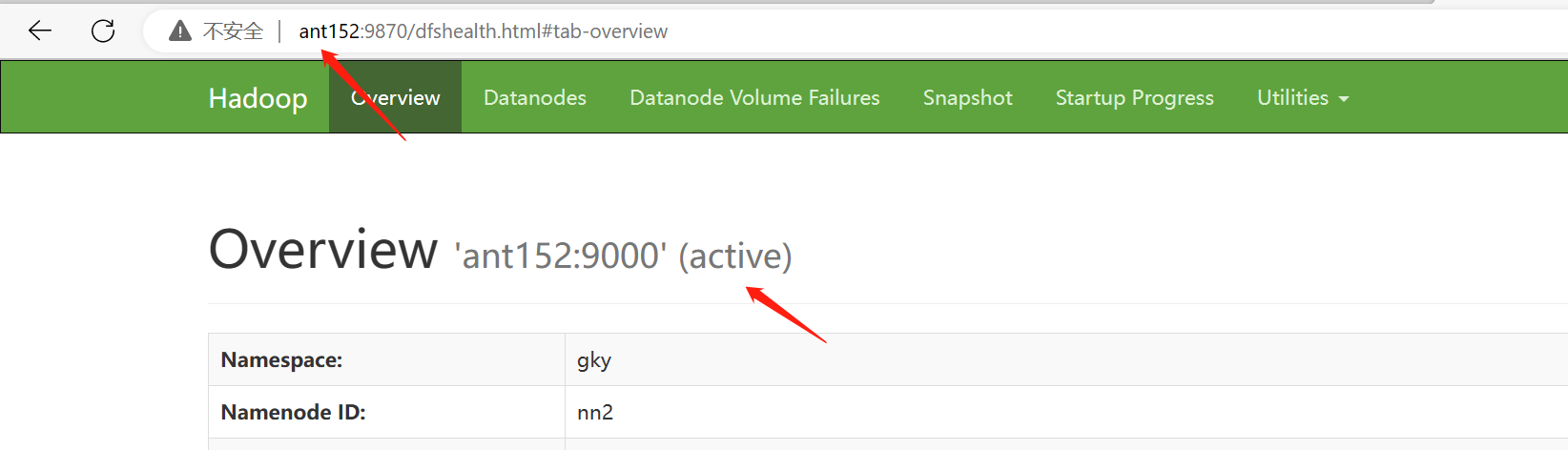
[root@ant152 soft]# hdfs --daemon start namenode查看namenode节点状态:hdfs haadmin -getServiceState nn1|nn2
[root@ant152 soft]# hdfs haadmin -getServiceState nn1
[root@ant151 soft]# stop-dfs.sh
[root@ant151 soft]# hdfs zkfc -formatZK
[root@ant151 soft]# start-dfs.sh
[root@ant151 soft]# start-yarn.sh
[root@ant151 soft]# yarn rmadmin -getServiceState rm1
rm1状态:standby

rm2状态:active
当前进程状态:
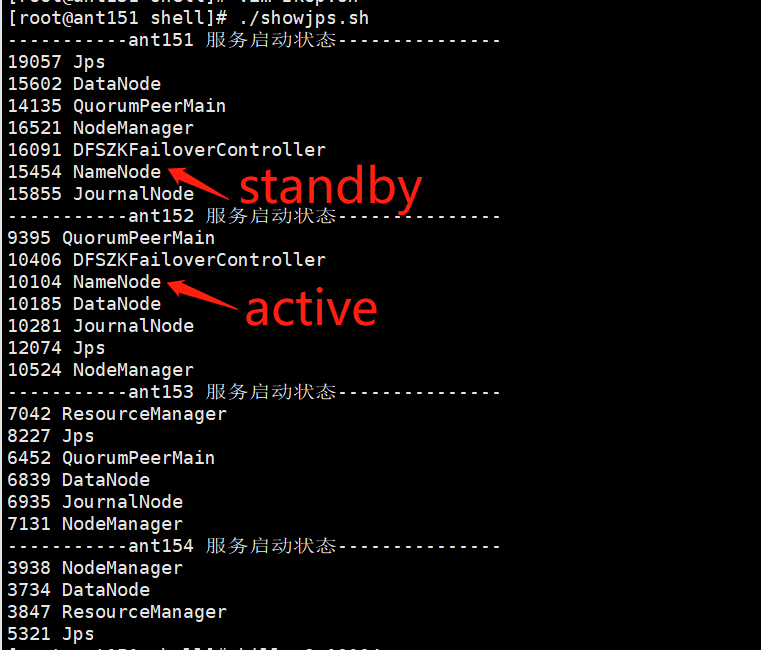
kill掉active进程

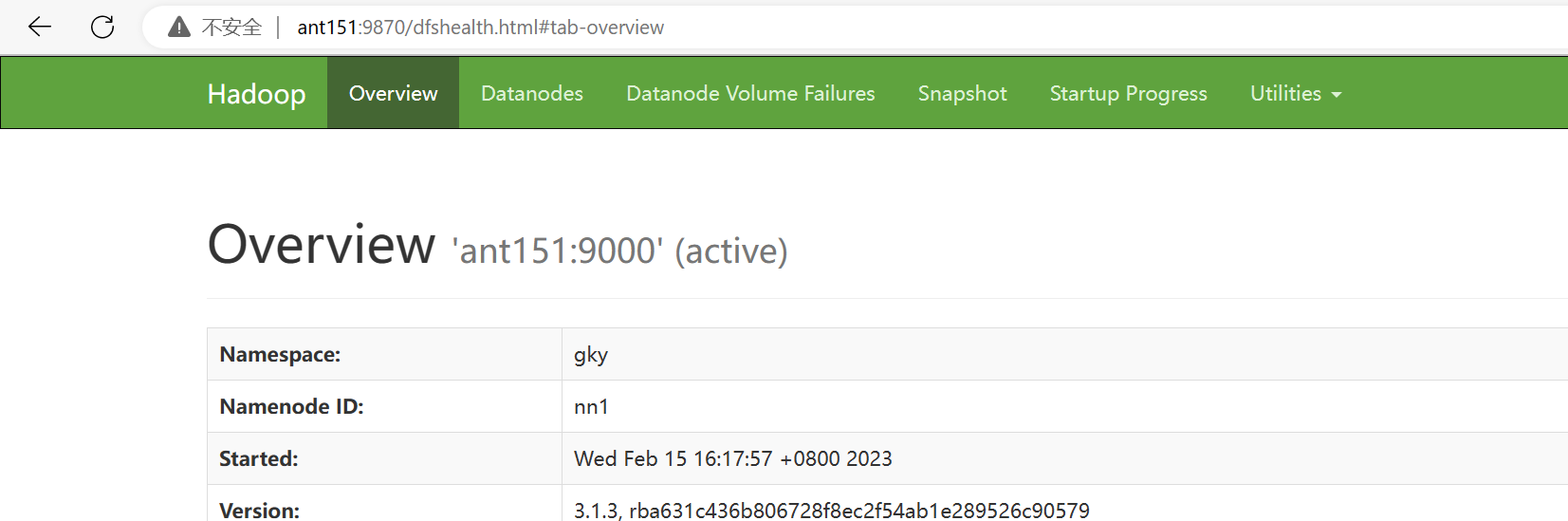
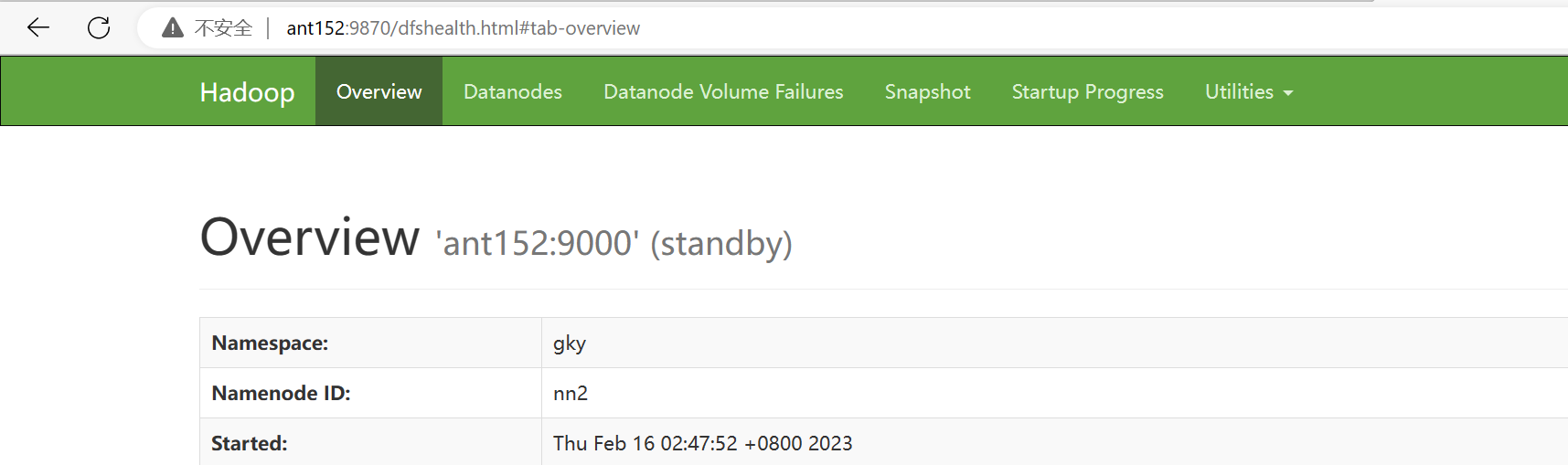
尝试访问,无法链接

恢复ant152的namenode进程

整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh整体启动/停止YARN
start-yarn.sh/stop-yarn.sh分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager进入~/bin目录创建脚本:
vim hadoopstart.sh
#!/bin/bash
# 判断参数个数
if [ $# -lt 1 ]
then
echo "Not Enough Arguement!"
exit;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.4/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.4/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.4/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.4/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.4/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.4/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac进入~/bin目录下创建脚本:
vim jpsall.sh
#! /bin/bash
for host in hadoop102 hadoop103 hadoop104 hadoop100
do
echo --------- $host ----------
ssh $host jps
done
HDFS NameNode 内部通常端口:8020/9000/9820
HDFS NameNode 用户查询端口:9870
Yarn查看任务运行情况:8088
历史服务器:19888
HDFS NameNode 内部通常端口:8020/9000
HDFS NameNode 用户查询端口:50070
Yarn查看任务运行情况:8088
历史服务器:19888
3.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml workers
2.x core-site.xml hdfs-site.xml yarn-site.xml mapred-site.xml slaves
同步时间的下面操作三台机都需要
[root@ant151 soft]# yum install -y ntpdate[root@ant151 soft]# crontab -e
每五分钟更新一次时间ant151设置时间同步

其他两台节点与ant151同步更新时间

[root@ant151 soft]# service crond start我在app/helpers/sessions_helper.rb中有一个帮助程序文件,其中包含一个方法my_preference,它返回当前登录用户的首选项。我想在集成测试中访问该方法。例如,这样我就可以在测试中使用getuser_path(my_preference)。在其他帖子中,我读到这可以通过在测试文件中包含requiresessions_helper来实现,但我仍然收到错误NameError:undefinedlocalvariableormethod'my_preference'.我做错了什么?require'test_helper'require'sessions_hel
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我的rails3.1.6应用程序中有一个自定义访问器方法,它为一个属性分配一个值,即使该值不存在。my_attr属性是一个序列化的哈希,除非为空白,否则应与给定值合并指定了值,在这种情况下,它将当前值设置为空值。(添加了检查以确保值是它们应该的值,但为简洁起见被删除,因为它们不是我的问题的一部分。)我的setter定义为:defmy_attr=(new_val)cur_val=read_attribute(:my_attr)#storecurrentvalue#makesureweareworkingwithahash,andresetvalueifablankvalueisgiven
有没有办法在liquidtemplate中输出(用于调试/信息目的)可用对象和对象属性??也就是说,假设我正在使用jekyll站点生成工具,并且我在我的index.html模板中(据我所知,这是一个液体模板)。它可能看起来像这样{%forpostinsite.posts%}{{post.date|date_to_string}}»{{post.title}}{%endfor%}是否有任何我可以使用的模板标签会告诉我/输出名为post的变量在此模板(以及其他模板)中可用。此外,是否有任何模板标签可以告诉我post对象具有键date、title、url、摘录、永久链接等
我尝试在我的应用中只使用:symbols作为关键词。我尝试在:symbol=>logic或string=>UI/languagespecific之间做出严格的决定但我也得到了每个JSON的一些“值”(即选项等),因为JSON中没有:symbols,所以我调用的所有哈希都具有“with_indifferent_access”属性。但是:数组是否有相同的东西?像那样a=['std','elliptic',:cubic].with_indifferent_accessa.include?:std=>true?编辑:将rails添加到标签 最佳答案
我进行了一些谷歌搜索,似乎缺少用于jRuby的IDE。我读过TextMate和Sublime,但它们不提供调试或代码完成功能。有人可以提出建议吗(或者这项技术还处于起步阶段)? 最佳答案 有几个选项;我更喜欢JetBrains'IntelliJ(RubyMine).AptanahasanEclipseplugin.NetBeansusedtohaveofficialsupport,不确定currentstate是什么是。 关于ruby-哪些IDE可用于jRuby?,我们在StackOve
我将guard与rspec和cucumber一起使用。要连续运行选定的规范,我只需使用focus标记来确定我要处理的内容。但问题是,如果没有带有该标签的规范,我想运行所有规范。我该怎么做?注意::我知道所有RSpec选项。因此,请仅在阅读问题后回复。 最佳答案 我通过以下配置实现了您描述的行为:#torunonlyspecificspecs,add:focustothespec#describe"foo",:focusdo#OR#it"shouldfoo",:focusdoconfig.treat_symbols_as_metada
我从事Rails已有一段时间,并且刚刚开始深入研究Ruby元编程,Rails从中获得了强大的力量。我真的想不通这个,这让我发疯。Controller中的实例变量如何提供给Rails中的View(与View共享)?我知道它背后有一些元编程魔法,但我无法弄明白。在此先感谢您的所有帮助。 最佳答案 更新:原来接受的答案是错误的我现在将它留在下面以证明我错了。在获得足够多的反对票后,我决定研究这实际上是如何工作的。我最初的回答是在我对Rails还很陌生之后写的,并且是基于我使用过的其他MVC库(特别是:CodeIgniter)的工作方式的假
对于最近的一个项目,我有几个View是这样的代码:这在开发模式下工作得很好......我将它推出到生产模式并且它爆炸了,说count不是Array的有效方法。我将每个实例都改为使用Array#length,它似乎可以正常工作。1)这种行为差异的原因是什么?2)我应该注意开发模式和生产模式之间的任何其他令人兴奋的差异吗?道德:确保您的生产托管环境使用与本地开发环境相同的Ruby版本。:)谢谢汤姆 最佳答案 count方法仅在Ruby1.9及更高版本中可用。我建议您使用与服务器相同版本的Ruby以避免此类问题-1.9中发生了很多变化
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建