String类中的重点
由于String的不可更改特性,在我们想要改变字符串的时候,都是在new的对象上进行改变,并没有改变字符串本身,为了能在字符串本身上进行的修改,不用创建大量临时对象,Java中提供StringBuilder和StringBuffer类
先来看看Stringbuffer的源码实现,以及栈和堆的内存分配:
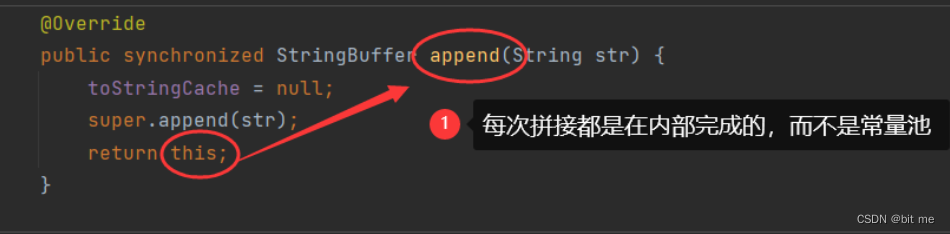
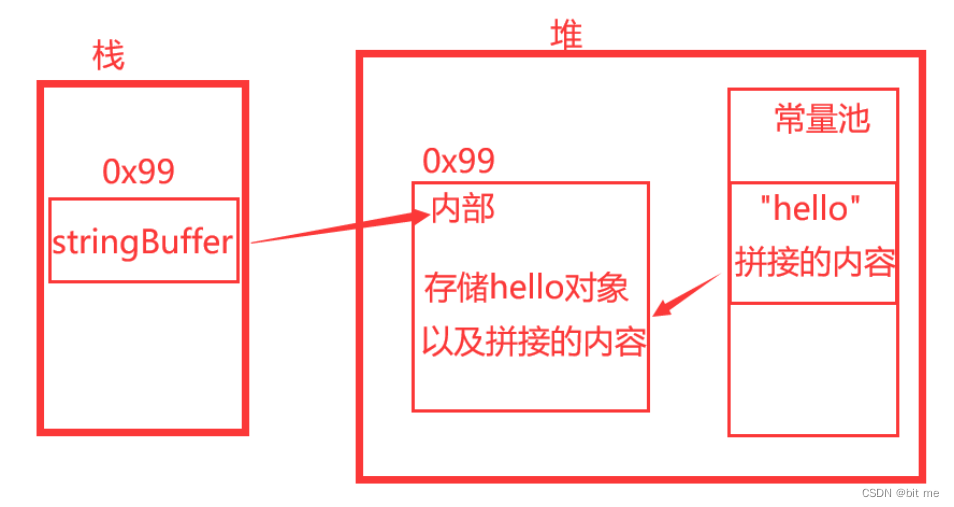
可以看到stringBuffer一直都在内部进行操作,而不是在常量池里面,所以只会返回内部的内容,新加入的内容都会进入内部和常量池中,从而不需要创建大量临时对象来接收新的内容
我们再看一看Stringbuilder的源码实现,它的栈和堆的内存分配和Stringbuffer是一样的
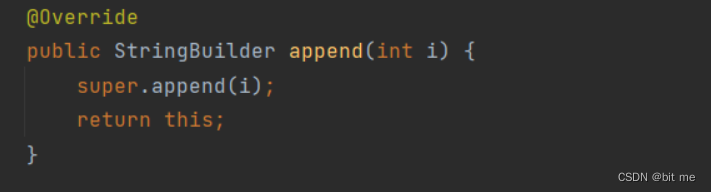
我们可以发现在StringBuffer的源码实现比StringBuilder实现里面多了synchronized,synchronized代表线程安全,StringBuffer是线程安全的,StringBuilder不是线程安全的
线程安全是啥呢,线程安全指的是内存的安全,在每个进程的内存空间中都会有一块特殊的公共区域,通常称为堆(内存)。进程内的所有线程都可以访问到该区域,这就是造成问题的潜在原因。
所以线程安全指的是,在堆内存中的数据由于可以被任何线程访问到,在没有限制的情况下存在被意外修改的风险。即堆内存空间在没有保护机制的情况下,对多线程来说是不安全的地方,因为你放进去的数据,可能被别的线程“破坏”。
在一段函数执行的过程中,具有线程安全的代码不会被外界所影响,相当于把这段函数锁在一个空间里,当函数执行完毕之后,锁就开了

例如人们上厕所,当第一个人进去上厕所之后,后面的人排队上厕所,当你不锁门的情况下,后面的人就可能会进来,干扰到你,但是当你反锁了门锁之后,后面的人就不能随意进出了,就对你不会有影响,所以在这里的门锁就和我们的线程安全类似,当你具备线程安全后就不用担心被别的线程所干扰了
但是我们这里就会产生一个疑问了,既然StringBuffer比StringBuilder安全,那为什么还需要StringBuilder呢?
线程安全会频繁的加锁和释放锁会消耗系统的资源,而在有些情况下,是不需要线程安全的,所以这时候就用StringBuilder更好,总之得看情况而定
举例我们字符串的拼接
String str = "abc";
str = str + "123";
System.out.println(str);

在字节码文件里我们可以看到new了一个StringBuilder对象,字符串的拼接也用append的方法来写的,并且调用优化了toString方法
相同情况下,多次拼接就会多次new StringBuilder对象,使得内部执行异常繁琐,多个对象是的程序运行不能最大化执行代码,我们就必须要使用StringBuilder来优化了
String str = "abc";
for (int i = 0; i < 10; i++) {
str = str +i;
}
System.out.println(str);
优化后的代码
String str = "abc";
StringBuilder sb = new StringBuilder(str);
for (int i = 0; i < 10; i++) {
sb.append(i);
}
System.out.println(sb.toString());
优化后的代码就只有一个StringBuilder对象,极大的提升了代码的性能,有人会说为什么不用Stringbuffer,在这里没有涉及到线程,用了会浪费资源,所以这两种方法各有优势,使用得看情况而论
String、StringBuffer、StringBuilder的区别
①String的内容不可修改,StringBuffer与StringBuilder的内容可以修改
②StringBuffer与StringBuilder大部分功能是相似的
③StringBuffer采用同步处理,属于线程安全操作;而StringBuilder未采用同步处理,属于线程不安全操作
以下总共创建了多少个String对象【前提不考虑常量池之前是否存在】
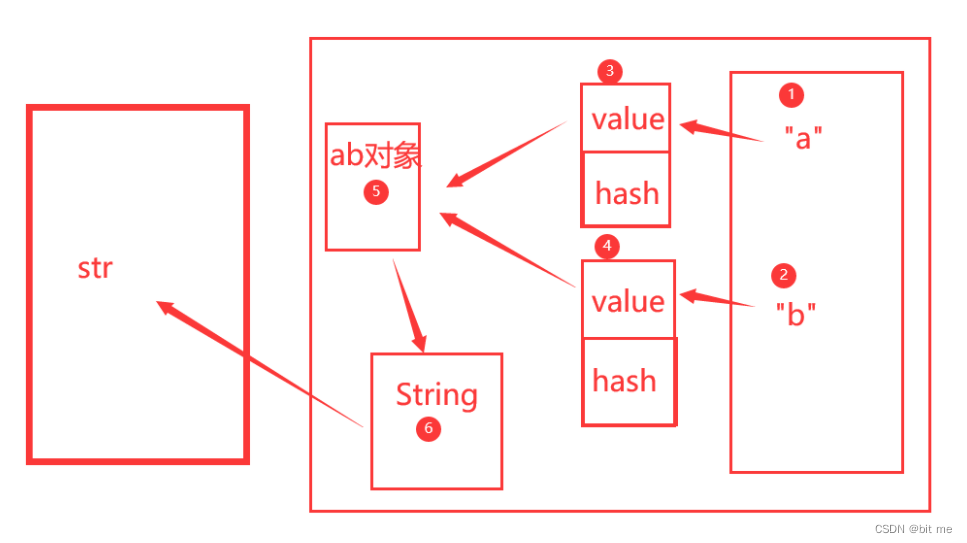
String str = new String("ab");
String str1 = new String("a") + new String("b");
第一个str创建了两个对象,第一个对象是字符串"ab",属于常量池里面的,第二个对象是new了一个对象,里面有value和hash
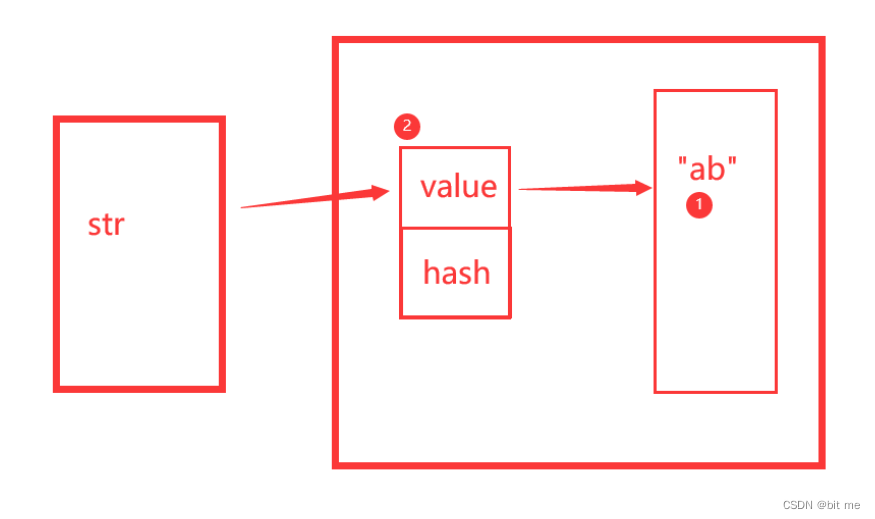
第二个str创建了六个对象,第一个对象是字符串"a",第二个对象是字符串"b",第三个对象是a new的一个对象,里面有value和hash,第四个对象是b new的一个对象,里面有value和hash,第五个对象是第三第四个对象合起来创建的一个Stringbuilder对象,第六个对象就是Stringbuilder的toString方法生成的一个String对象
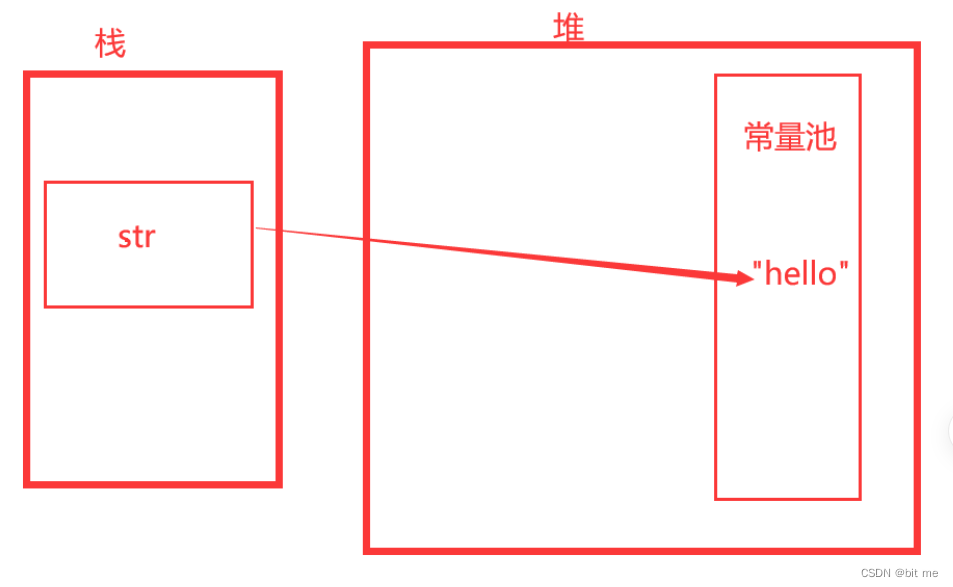
JDK1.8中
只会开辟一块堆内存空间,保存在字符串常量池中,然后str共享常量池中的String对象
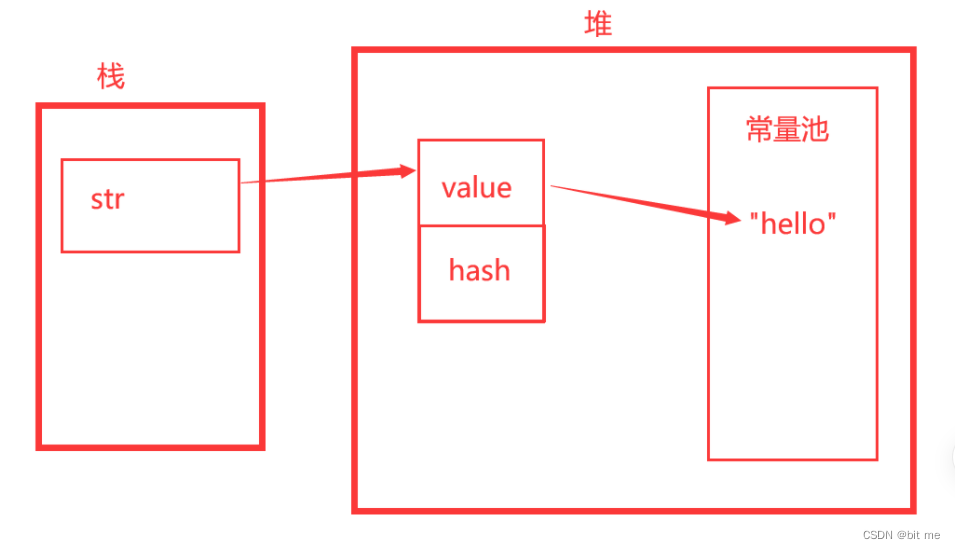
会开辟两块堆内存空间,字符串"hello"保存在字符串常量池中,然后用常量池中的String对象给新开辟的String对象赋值。
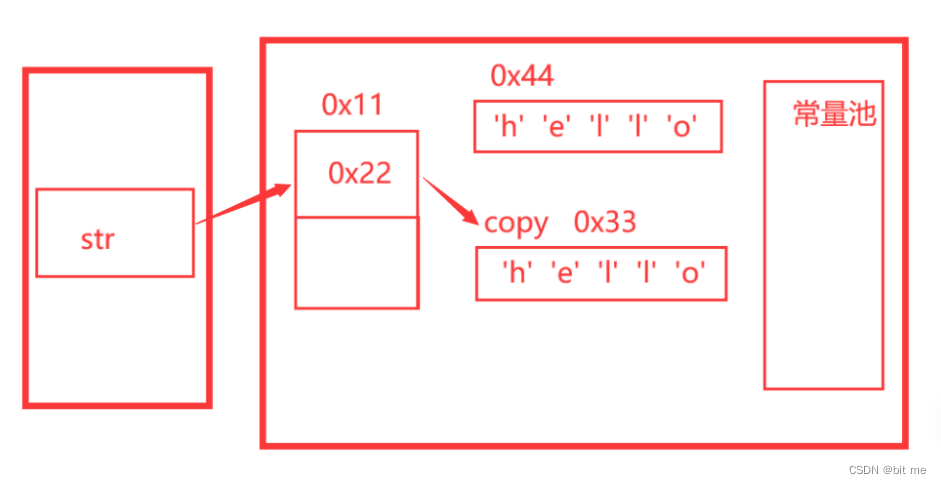
现在在堆上创建一个String对象,然后利用copyof将重新开辟数组空间,将参数字符串数组中内容拷贝到String对象中(常量池没有东西,只有双引号的内容才会在常量池里面)
给定一个字符串s ,找到它的第一个不重复的字符,并返回它的索引 。如果不存在,则返回-1 。
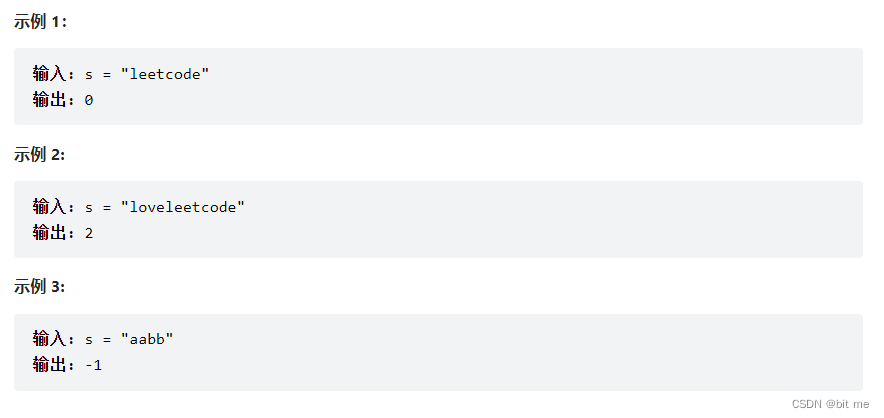
思路:
public int firstUniqChar(String s) {
//对参数进行判断
if(s == null || s.length() == 0){
return -1;
}
int[] array = new int[26];//0
for(int i = 0;i < s.length();i++){//先遍历一次数组,把每个元素出现的次数都记录下来
char ch = s.charAt(i);
array[ch-'a']++;
}
for(int i = 0;i < s.length();i++){//再次遍历数组,从左往右,输出记录后第一个只出现了一次的字符
char ch = s.charAt(i);
if(array[ch-'a'] == 1){
return i;
}
}
return -1;
}
计算字符串最后一个单词的长度,单词以空格隔开,字符串长度小于5000。(注:字符串末尾不以空格为结尾)

思路:
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
while(scan.hasNextLine()){
String str = scan.nextLine();
int index = str.lastIndexOf(" ");
String ret = str.substring(index+1);
System.out.println(ret.length());
}
}
如果在将所有大写字符转换为小写字符、并移除所有非字母数字字符之后,短语正着读和反着读都一样。则可以认为该短语是一个 回文串 。
字母和数字都属于字母数字字符。
给你一个字符串 s,如果它是回文串 ,返回 true ;否则,返回 false 。

思路:
private boolean isCharacter(char ch){
if (ch >= 'a' && ch <= 'z' || ch >= '0' && ch <= '9'){//判断字符合理性
return true;
}
return false;
}
public boolean isPalindrome(String s){
//1.把所有的字符变成小写的
s = s.toLowerCase();
int i = 0;
int j = s.length()-1;
while(i < j){//i和j的下标要合法
while(i < j && !isCharacter(s.charAt(i))){//此处不用if是因为在第一个字母或数字之前可能会有空格
i++;//i下标就是一个合法的数字字符或字母
}
while(i < j && !isCharacter(s.charAt(j))){//判断j是不是合法的数字字符或字母
j--;//j下标就是一个合法的数字字符或字母
}
if(s.charAt(i) != s.charAt(j)){//当两边字母或数字不一样的时候,返回false
return false;
}else {
i++;
j--;
}
}
return true;
}
我正在尝试从Postgresql表(table1)中获取数据,该表由另一个相关表(property)的字段(table2)过滤。在纯SQL中,我会这样编写查询:SELECT*FROMtable1JOINtable2USING(table2_id)WHEREtable2.propertyLIKE'query%'这工作正常:scope:my_scope,->(query){includes(:table2).where("table2.property":query)}但我真正需要的是使用LIKE运算符进行过滤,而不是严格相等。然而,这是行不通的:scope:my_scope,->(que
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
在Ruby1.9.3(可能还有更早的版本,不确定)中,我试图弄清楚为什么Ruby的String#split方法会给我某些结果。我得到的结果似乎与我的预期相反。这是一个例子:"abcabc".split("b")#=>["a","ca","c"]"abcabc".split("a")#=>["","bc","bc"]"abcabc".split("c")#=>["ab","ab"]在这里,第一个示例返回的正是我所期望的。但在第二个示例中,我很困惑为什么#split返回零长度字符串作为返回数组的第一个值。这是什么原因呢?这是我所期望的:"abcabc".split("a")#=>["bc"
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
我正在尝试按Rails相关模型中的字段进行排序。我研究的所有解决方案都没有解决如果相关模型被另一个参数过滤?元素模型classItem相关模型:classPriority我正在使用where子句检索项目:@items=Item.where('company_id=?andapproved=?',@company.id,true).all我需要按相关表格中的“位置”列进行排序。问题在于,在优先级模型中,一个项目可能会被多家公司列出。因此,这些职位取决于他们拥有的company_id。当我显示项目时,它是针对一个公司的,按公司内的职位排序。完成此任务的正确方法是什么?感谢您的帮助。PS-我
假设您有一个可执行文件foo.rb,其库bar.rb的布局如下:/bin/foo.rb/lib/bar.rb在foo.rb的header中放置以下要求以在bar.rb中引入功能:requireFile.dirname(__FILE__)+"../lib/bar.rb"只要对foo.rb的所有调用都是直接的,这就可以正常工作。如果你把$HOME/project和符号链接(symboliclink)foo.rb放入$HOME/usr/bin,然后__FILE__解析为$HOME/usr/bin/foo.rb,因此无法找到bar.rb关于foo.rb的目录名.我意识到像rubygems这
玩转ruby,我已经:#!/usr/bin/ruby-w#WorldweatheronlineAPIurlformat:http://api.worldweatheronline.com/free/v1/weather.ashx?q={location}&format=json&num_of_days=1&date=today&key={api_key}require'net/http'require'json'@api_key='xxx'@location='city'@url="http://api.worldweatheronline.com/free/v1/weather.
我有代码:classScenedefinitialize(number)@number=numberendattr_reader:numberendscenes=[Scene.new("one"),Scene.new("one"),Scene.new("two"),Scene.new("one")]groups=scenes.inject({})do|new_hash,scene|new_hash[scene.number]=[]ifnew_hash[scene.number].nil?new_hash[scene.number]当我启动它时出现错误:freq.rb:11:in`[]'
我的Ruby代码中有一个看起来有点像这样的结构Parameter=Struct.new(:name,:id,:default_value,:minimum,:maximum)稍后,我使用创建了这个结构的一个实例freq=Parameter.new('frequency',15,1000.0,20.0,20000.0)在某些时候,我需要这个结构的精确副本,所以我调用newFreq=freq.clone然后,我更改newFreq的名称newFreq.name.sub!('f','newF')奇迹般地,它也改变了freq.name!像newFreq.name='newFrequency'这样
术语中文解释Ability原子化服务帮助用户完成任务的原子化服务,和用户的意图进行关联。Fulfillment服务履行通过图标,卡片,语音等形式呈现用户意图。开发者通过接口的方式,处理用户意图,返回内容。Intent意图用于表达用户想要达成的目标或完成的任务。HUAWEIAssistant智能助手“无微不智”的个人助手,通过不断的学习用户的使用习惯,不断的为用户提供贴心的精准的便捷的个性化服务。AISearch全局搜索用户可快速搜索关键词,与之匹配的原子化服务则会出现在搜索结果中。SmartService智慧服务用户订阅原子化服务,在到达特定触发条件(时间、地点、事件)后,卡片推送至用户智能助