获得maven仓库:
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.9</version>
</dependency>
使用navicat创建一个数据库
新建项目
导入依赖
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.9</version>
</dependency>
编写mybatis的核心配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis?&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai"/>
<property name="username" value="root"/>
<property name="password" value="18227022334a"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="Mapper/UserMapper.xml"/>
</mappers>
</configuration>
<!--注:xml文件中使用&符号需要改成使用 & 代替-->
编写mybatis工具类(封装):
public class MybatisUtils {
private static SqlSessionFactory sqlSessionFactory;
//第一步:获取SqlSessionFactory对象
static {
try {
String resource = "mybatis-config.xml";//路径写对
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
} catch (IOException e) {
e.printStackTrace();
}
}
//通过SqlSessionFactory对象获取SqlSession对象
//SqlSession:SqlSession 提供了在数据库执行 SQL 命令所需的所有方法。你可以通过 SqlSession 实例来直接执行已映射的 SQL 语句。
public static SqlSession getSqlSession(){return sqlSessionFactory.openSession();}//当传递一个true参数时表示自动提交事务
}
编写
编写实体类
//注;实体类的属性名必须与数据库的列名一致,否则无法进行匹配从而出现数据为空的现象,当然也可以在Mapper.xml配置中通过编写一个resultMap来进行映射,此时名字可以不相同
public class User {
private int id;
private String username;
private String password;
public User() {
}
public User(int id, String username, String password) {
this.id = id;
this.username = username;
this.password = password;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
}
编写Mapper接口(Dao)
public interface UserMapper {
public List<User> getUser();
}
编写Mapper配置文件
//注:每个Mapper文件都需要在mybatis-config.xml文件中去注册
//<mapper resource="Mapper/UserMapper.xml"/>
//相当于Mapper的接口实现类
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
//namespace:命名空间,指定要实现的Mapper接口,路径映射
<mapper namespace="com.study.dao.UserMapper">
//id:唯一匹配于Mapper接口的方法名
//resultType:返回类型,必须写全限定名称
<select id="getUser" resultType="com.study.pojo.User">
select * from user;
</select>
</mapper>
测试
public class UserMapperTest {
@Test
public void test(){
//获得sqlSession对象
SqlSession sqlSession = MybatisUtils.getSqlSession();
//获取UserMapper的对象以调用接口内的方法
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
//调用方法
List<User> users = userMapper.getUser();
//遍历结果集
for (User user : users) {
System.out.println(user.getId() + " " + user.getUsername() + " " + user.getPassword());
}
//关闭sqlSessoin
sqlSession.close();
}
}
SqlSessionFactoryBuilder:
可以重用 SqlSessionFactoryBuilder 来创建多个 SqlSessionFactory 实例,但最好还是不要一直保留着它,以保证所有的 XML 解析资源可以被释放给更重要的事情
SqlSessionFactory:
SqlSessionFactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由丢弃它或重新创建另一个实例,最简单的就是使用单例模式或者静态单例模式
SqlSession:
SqlSession 的实例不是线程安全的,因此是不能被共享的,每次打开一个 SqlSession,记得关闭它, 这个关闭操作很重要
接口:
public User getUserById(int id);
Mapper配置文件
<select id="getUserById" resultType="com.study.pojo.User">
select * from user where id=#{id};
</select>
测试
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
User user = userMapper.getUserById(1);
sqlSession.close();
接口:
public void insertUser(User user);
Mapper配置文件
<insert id="insertUser">
insert into user values (#{id},#{username},#{password});
</insert>
测试
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
userMapper.insertUser(new User(5,"老六","1234"));
sqlSession.commit();
sqlSession.close();
//注:在Mybatis中增删改查找都需要使用事务,必须手动提交事务如果没有配置自动管理事务的情况下
接口:
public void insertUser(User user);
Mapper配置文件
<insert id="insertUser">
insert into user values (#{id},#{username},#{password});
</insert>
测试
//当有多个参数的时候,可以使用@Param()注解指定名字
//public void updateName(@Param("id") int id,@Param("username") String username);
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
userMapper.updateName(3,"王五");
sqlSession.commit();
sqlSession.close();
接口:
public void insertUser(User user);
Mapper配置文件
<insert id="insertUser">
insert into user values (#{id},#{username},#{password});
</insert>
测试
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
userMapper.deleteUserById(5);
sqlSession.commit();
sqlSession.close();
当接口中传递的对象有多个的时候,除了可以使用·@Param()注解之外,我们常常使用一个不算规范但是特别好用的方式,那就是传递Map
接口:
public void updateNameById(Map<String,Object> map);
mapper配置文件:
<update id="updateNameById" >
update user set username=#{username} where id=#{id};
</update>
调用:
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
Map<String,Object> map=new HashMap();
map.put("username","战三");
map.put("id",2);
userMapper.updateNameById(map);
sqlSession.commit();
sqlSession.close();
总结:
方式一:在java代码在传递“%”
userMapper.getUserLike("%张%");
方式二:在mapper文件的sql语句中实现
<select id="getUserLike" resultType="com.study.pojo.User">
select * from user where username like "%"#{name}"%" ;
</select>
MyBatis 的配置文件包含了会深深影响 MyBatis 行为的设置和属性信息。 配置文档的顶层结构如下:
MyBatis 可以配置成适应多种环境,不过要记住:尽管可以配置多个环境,但每个 SqlSessionFactory 实例只能选择一种环境。
environments 元素定义了如何配置环境。
<environments default="development">
<environment id="development">
<transactionManager type="JDBC">
<property name="..." value="..."/>
</transactionManager>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
<!--如果要切换环境只需要更改环境default,改成需要使用的环境的id-->
<environment id="test">
</environment>
</environments>
注意点:
可以从外部的资源环境读取,也可以在内部定义,可以动态的替换环境中的配置信息
外部资源文件引入:
db.properties
driver=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai
username=root
password=11111111
引入:
<properties resource="db.properties"> </properties>
内部使用property定义:
<properties resource="org/mybatis/example/config.properties">
<property name="username" value="dev_user"/>
<property name="password" value="F2Fa3!33TYyg"/>
</properties>
设置好的属性可以动态替换:
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
注:如果同时使用了外部资源文件和内部定义的方式那么会使用外部资源文件。
类型别名可为 Java 类型设置一个缩写名字,降低冗余的全限定类名书写
方式一:使用具体的全限定类名
<typeAliases>
<typeAlias alias="Author" type="domain.blog.Author"/>
<typeAlias alias="Blog" type="domain.blog.Blog"/>
</typeAliases>
注:设定之后在其他使用domain.blog.Author的地方就可以使用Author代替
方式二:使用实体类包名
<typeAliases>
<package name="domain.blog"/>
</typeAliases>
注:通过这种方式设定之后,在该包下所有的实体类的全限定类名可以使用该类名的首字母小写来代替,比如User使用user代替
总结:两种方式各有优劣,当类比较少的时候可以使用第一种方式,当类比较多的时候可以使用第二种方式,如果想在使用第二种方式的同时给特点的类设定指定名字,可以使用注解的方式,且如果同时使用了第一种方式和第二种方式那么使用两个别名都正确。
@Alias("author")
public class Author {}
1.常用的一些设置:
| 设置名 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。 | true | false | true |
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 |
true | false | false |
| useGeneratedKeys | 允许 JDBC 支持自动生成主键,需要数据库驱动支持。如果设置为 true,将强制使用自动生成主键。尽管一些数据库驱动不支持此特性,但仍可正常工作(如 Derby)。 | true | false | False |
| mapUnderscoreToCamelCase | 是否开启驼峰命名自动映射,即从经典数据库列名 A_COLUMN 映射到经典 Java 属性名 aColumn。 | true | false | False |
| logImpl | 指定 MyBatis 所用日志的具体实现,未指定时将自动查找。 | SLF4J | LOG4J | LOG4J2 | JDK_LOGGING | COMMONS_LOGGING | STDOUT_LOGGING | NO_LOGGING | 未设置 |
日志:
作用:告诉 MyBatis 到哪里去找映射文件
实现方式:
方式一:resource(推荐)
<!-- 使用相对于类路径的资源引用 -->
<mappers>
<mapper resource="org/mybatis/builder/AuthorMapper.xml"/>
<mapper resource="org/mybatis/builder/BlogMapper.xml"/>
<mapper resource="org/mybatis/builder/PostMapper.xml"/>
</mappers>
方式二:url(极不推荐)
<!-- 使用完全限定资源定位符(URL) -->
<mappers>
<mapper url="file:///var/mappers/AuthorMapper.xml"/>
<mapper url="file:///var/mappers/BlogMapper.xml"/>
<mapper url="file:///var/mappers/PostMapper.xml"/>
</mappers>
方式三:class
<!-- 使用映射器接口实现类的完全限定类名 -->
<mappers>
<mapper class="org.mybatis.builder.AuthorMapper"/>
<mapper class="org.mybatis.builder.BlogMapper"/>
<mapper class="org.mybatis.builder.PostMapper"/>
</mappers>
注:
方式四:name
<!-- 将包内的映射器接口实现全部注册为映射器 -->
<mappers>
<package name="org.mybatis.builder"/>
</mappers>
注:
假设存在一个数据库user表,字段如下:
一个User实体类如下:
public class User {
private int id;
private String username;
private String password;
}
那么当查询结果集为User类型的时候,会出现姓名为空的问题。
解决方式:
方式一:在sql语句中使用别名
select id ,name as usernaem,password from user;
方式二:resultMap结果映射
<resultMap id="userMap" type="user">
<id property="id" column="id"/>
<result property="username" column="name"></result>
<result property="password" column="password"></result>
</resultMap>
<select id="getUserAll" resultMap="userMap">
select * from user ;
</select>
resultMap 元素是 MyBatis 中最重要最强大的元素。
ResultMap 的设计思想是,对简单的语句做到零配置,对于复杂一点的语句,只需要描述语句之间的关系就行了。
ResultMap 的优秀之处——你完全可以不用显式地配置它们,如上面的resultMap可以改为
<resultMap id="userMap" type="user">
<result property="username" column="name"></result>
</resultMap>
即只需要显示的配置不匹配的情况即可。
注:其实第一种方法使用别名的本质上还是使用了resultMap的映射,因为在这些情况下,MyBatis 会在幕后自动创建一个 ResultMap,再根据属性名来映射列到 JavaBean 的属性上。
当我们操作数据库出现错误时,需要借助一些手段进行排错
日志类别:
配置日志:
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
使用了日志之后,我们就可以查看到非常多的信息
介绍:
log4j:
导入log4j依赖
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
log4j.properties
#将等级为debug的日志信息输出到console和file,其中console为控制台,名字可以自己定义,file相同
log4j.rootLogger=DEBUG,console,file
#控制台输出的相关设置
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%p:%c%n%m%l%n%m
#文件输出的相关设置
log4j.appender.file=org.apache.log4j.FileAppender
log4j.appender.file.File=d:/log4jFile/mybatis.log
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %F %p %m%n
log4j.appender.file.MaxFileSize=10mb
#控制日志的输出鉴别
log4j.logger.org.mybatis=DEBUG
log4j.logger.java.sql.ResultSet=DEBUG
log4j.logger.java.sql=DEBUG
log4j.logger.java.sql.Statement=DEBUG
log4j.logger.java.sql.PreparedStatement=DEBUG
在mybatis-config中配置log4j的使用
<settings>
<setting name="logImpl" value="LOG4J"/>
</settings>
思考:为什么要分页
select * from user limit startIndex,pagesize;
select *from user limit pagesize; -- 当只有一个参数的时候,从第一个数据开始
接口:
public List<User> getUser();
mapper.xml:
<select id="getUser" resultType="com.study.pojo.User">
select * from user ;
</select>
实现:
SqlSession sqlSession = MybatisUtils.getSqlSession();
RowBounds rowBounds=new RowBounds(1,2);
List<User> list = sqlSession.selectList("com.study.dao.UserMapper.getUser", null, rowBounds);
for (Object user : list) {
System.out.println(user.toString());
}
使用PageHelper分页插件,https://pagehelper.github.io/,了解一下即可,如有需要再看使用文档。
使用建议:除非是很简单的操作,否则尽量建议使用xml方式完成,一般而言我们都会使用xml。
@Insert:
插入记录的时候麻烦的一点是主键如何生成,对此基本上有三种方案,分别是手动指定(应用层)、自增主键(数据层单表)、选择主键(数据层多表)。(如想了解可以查)
@Insert("insert into user values (#{id},#{username},null)")
@Delete:
@Delete("delete from user where id=#{id};")
@Updata:
@Update(" update user set username=#{username} where id=#{id};")
@select:
@Select("select * from user")
@Param:
在接口中传递多个参数的时候可以指定
public void updateName(@Param("id") int id,@Param("username") String username);
注:
@Results, @Result:
当使用select标签时,如果查询的字段与当前实体类不能进行很好的匹配那么需要我们进行一个映射
@Results(id = "userMap", value = {
@Result(id=true, column = "id", property = "id"),
@Result(column = "username", property = "username"),
@Result(column = "passwd", property = "passwd"),
})
@Select("SELECT * FROM t_user WHERE id=#{id}")
User loadByIdResultMap(Long id);
@ResultMap:
如果以及存在一个@Results,那么可以通过@ResultMap指定id名字去引用它
@ResultMap("userMap")
@Select("SELECT * FROM t_user WHERE id=#{id}")
User loadByIdResultMapReference(Long id);
接口:
public interface UserMapper {
@Select("select * from user")
public List<User> getUser();
@Update(" update user set username=#{username} where id=#{id};")
public void updateName(@Param("id") int id,@Param("username") String username);
@Insert("insert into user values (#{id},#{username},null)")
public void insertUser(User user);
@Delete("delete from user where id=#{id};")
public void deleteUserById(int id);
}
mybatis-config.xml注册接口:
<mappers>
<mapper class="com.study.dao.UserMapper"/>
</mappers>
测试:
SqlSession sqlSession = MybatisUtils.getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
List<User> user = userMapper.getUser();
//userMapper.insertUser(new User(6,"随便","123123"));
//userMapper.updateName(2,"还行");
//userMapper.deleteUserById(1);
for (User user1 : user) {
System.out.println(user1);
}
sqlSession.commit();
sqlSession.close();
本质:反射机制实现
底层:动态代理
注:虽然注解和xml配置文件可以同时使用,但是如果在接口中的同一个方法上既使用了注解,有在xml文件中进行了配置,也就是对同一个方法同时使用了注解配置文件两种方式,那么程序会报错。
Lombok项目是一个java库,它可以自动插入到编辑器和构建工具中,增强java的性能。不需要再写getter、setter或equals方法,只要有一个注解,你的类就有一个功能齐全的构建器、自动记录变量等等.
常用注解:
Lombok的使用:
在IDEA中安装Lombok插件
在项目中导入lombok的jar包
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
使用:
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Persosn {
private String name;
private int age;
}
注:由于使用@Data只含有无参构造函数,使用要结合@AllArgsConstructor使用,但是使用了@AllArgsConstructor之后@Data的无参构造函数就会消失,使用需要再搭配@NoArgsConstructor使用。
注:缺点:无法承载有各种参数的构造函数,但是我们可以手动的去添加。
比如多个学生对应一个老师,就是多对一
实体类如下:
@Data
public class Student {
private int id;
private String name;
private Teacher teacher;//多个学生一个老师
}
@Data
public class Teacher {
private int id;
private String name;
}
实现关键:association
<resultMap id="Student_t" type="student">
<result property="id" column="id"/>
<result property="name" column="name"/>
<association property="teacher" column="tid" javaType="teacher" select="getTeacher"/>
</resultMap>
<select id="getStudent" resultMap="Student_t">
select * from student ;
</select>
<select id="getTeacher" resultType="teacher">
select * from teacher where id=#{id}
</select
通过嵌套一个子查询的方式,通过学生的tid去找到对应的老师
<resultMap id="Student_t2" type="student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<association property="teacher" javaType="teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
</association>
</resultMap>
<select id="getStudent2" resultMap="Student_t2">
select s.id sid,s.name sname,t.id tid ,t.name tname from student s,teacher t where s.tid=t.id;
</select>
通过对结果集直接进行映射
比如一个老师有多个学生,对于老师而言就是一对多
实体类如下:
@Data
public class Student {
private int id;
private String name;
private int tid;
}
@Data
public class Teacher {
private int id;
private String name;
private List<Student> students;
}
实现关键:collection
<resultMap id="teacher_s1" type="teacher">
<result property="id" column="id"/>
<result property="name" column="name"/>
<collection property="students" ofType="student" column="id" select="getStudent" javaType="ArrayList"/>
</resultMap>
<select id="getTeacher" resultMap="teacher_s1">
select * from teacher t;
</select>
<select id="getStudent" resultType="student">
select * from student where tid=#{id};
</select>
<resultMap id="teacher_s2" type="teacher">
<result property="id" column="tid"/>
<result property="name" column="tname"/>
<collection property="students" ofType="student">
<result property="id" column="sid"/>
<result property="name" column="sname"/>
<result column="tid" property="tid"/>
</collection>
</resultMap>
<select id="getTeacher1" resultMap="teacher_s2">
select s.id sid,s.name sname,t.id tid ,t.name tname from student s,teacher t where s.tid=t.id;
</select>
附:面试高频问题;
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
种类:
在数据库中根据以下实体类创建blog表
@Data
public class Blog {
private String id;
private String title;
private String author;
private Date createTime;
private int views;
}
拓展:实体类中的id类型是String,在具体的一个项目中其实我们可以使用UUID这个类来随机生成一个唯一的ID,工具类简单封装如下:
public class IDUtils {
public static String getId(){
return UUID.randomUUID().toString().replace("-","");
}
}
新建项目,导入相关依赖
配置文件的编写
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
注:开启这个设置可以自动将数据库的下划线映射到实体类的驼峰命名属性
新建实体类Blog
建立对应的Mapper接口
建立对应的Mapper配置文件
注册配置文件
测试环境搭建是否成功
<select id="queryBlog" resultType="blog">
select * from blog where 1=1
<if test="id != null">
and id=#{id}
</if>
<if test="title != null">
and title =#{title}
</if>
<if test="author!='李四'">
and author =#{author}
</if>
<if test="views > 800 ">
and views>#{views}
</if>
</select>
注:第一个where条件后面加一个1=1是为了方便后面的每一个判断条件追加sql的第一个能写and
<select id="queryBlog" resultType="blog">
select * from blog
<where>
<choose>
<when test="id != null">
id=#{id}
</when>
<when test="title != null">
and title =#{title}
</when>
<when test="author!='李四'">
and author =#{author}
</when>
<otherwise>
and views>#{views}
</otherwise>
</choose>
</where>
</select>
where:where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
set:set 元素可以用于动态包含需要更新的列,忽略其它不更新的列
<update id="updateAuthorIfNecessary">
update Author
<set>
<if test="author != null">author=#{author},</if>
<if test="title != null">title=#{title},</if>
<if test="views >= 0">views=#{views}</if>
</set>
</update>
trim:
trim包含的属性;
可以自定义标签的替换方式,比如与where等同效果的格式如下:
<trim prefix="WHERE" prefixOverrides="AND |OR ">
...
</trim>
prefixOverrides 属性会忽略通过管道符分隔的文本序列(注意此例中的空格是必要的)。上述例子会移除所有 prefixOverrides 属性中指定的内容,并且插入 prefix 属性中指定的内容。
与set等同效果的格式如下:
<trim prefix="SET" suffixOverrides=",">
...
</trim>
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。
可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。
<select id="queryBlog" resultType="blog">
select * from blog
<where>
<foreach collection="names" item="name" open="author in (" close=")" separator=",">
#{name}
</foreach>
</where>
</select>
测试:
@Test
public void test() {
SqlSession sqlSession = MybatisUtils.getSqlSession();
BlogMapper blogMapper = sqlSession.getMapper(BlogMapper.class);
ArrayList<String> names = new ArrayList<>();
names.add("张三");
names.add("李四");
Map<String,List> map=new HashMap<>();
map.put("names",names);
List<Blog> blogs = blogMapper.queryBlog(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
sql片段的作用就是可以将一部分sql代码抽取出来,然后可以对他进行一个复用。
<select id="queryBlog" resultType="blog">
select * from blog
<where>
<include refid="choose"></include>
</where>
</select>
<sql id="choose">
<choose>
<when test="id != null">
id=#{id}
</when>
<when test="title != null">
and title =#{title}
</when>
<when test="author!='李四'">
and author =#{author}
</when>
</choose>
</sql>
注意事项:
动态sql本质上就是拼接sql语句
建议:
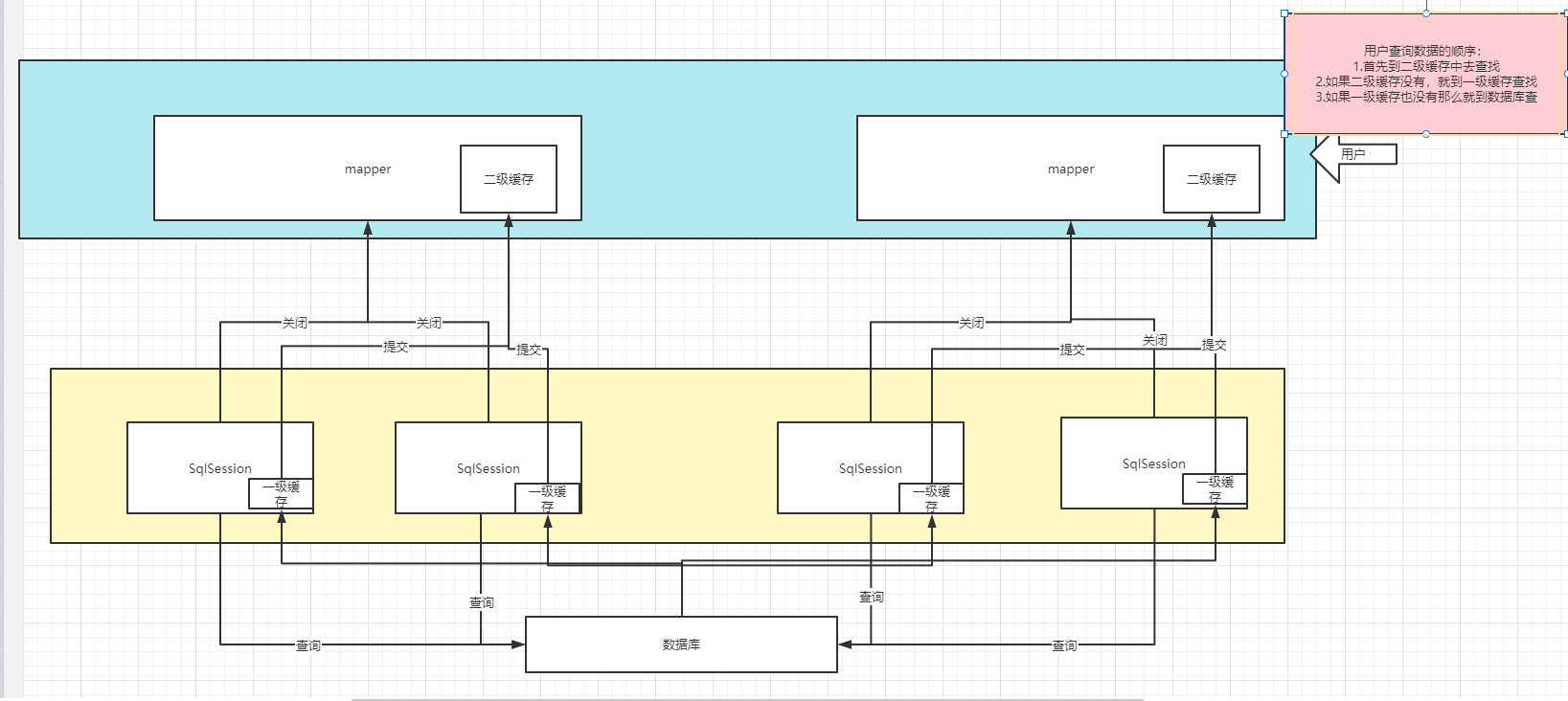
mybatis本身有两种缓存,分别为一级缓存和二级缓存
一级缓存:
二级缓存:
测试步骤:
开启日志
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
</settings>
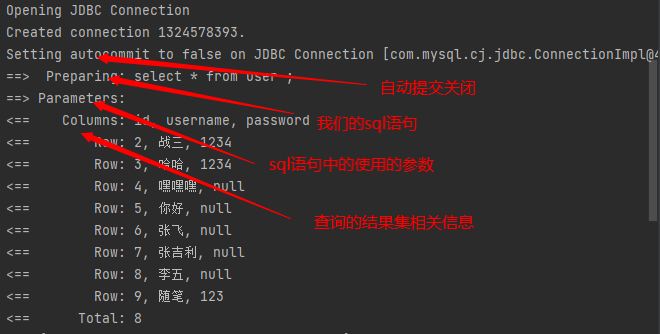
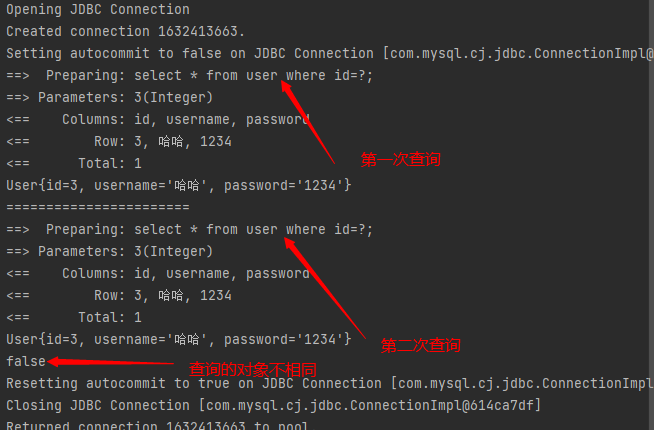
测试在同一个SqlSession期间查询相同的数据
查看日志输出
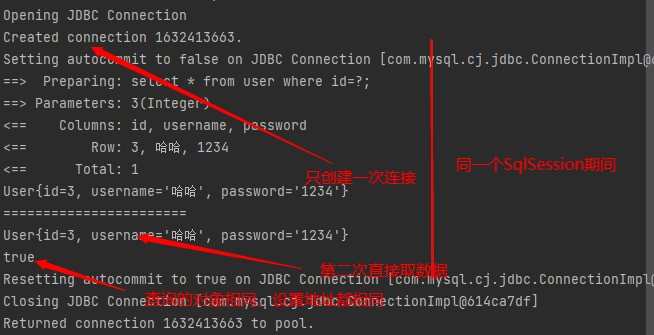
缓存失效的情况:
查询不一样的数据
增删改操作,由于可能会改变原来的数据,所有缓存也会失效
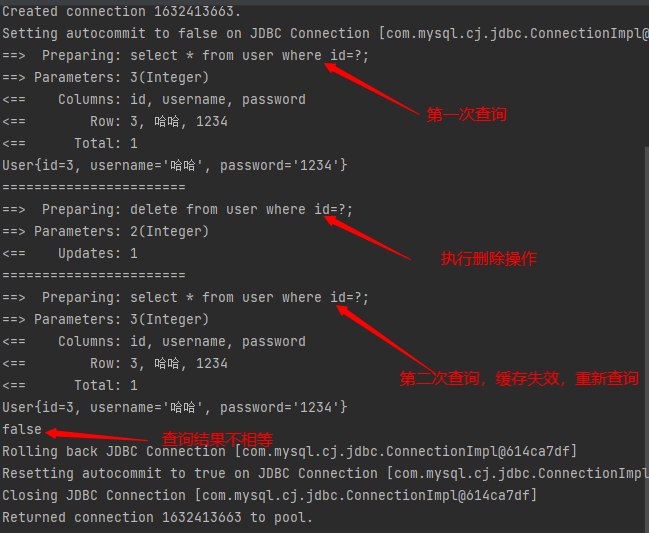
查询不同的Mapper.xml
手动清除缓存
sqlSession.clearCache();
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
缓存不会定时进行刷新(也就是说,没有刷新间隔)
小结:一级缓存是默认开启的,也关闭不掉,只能手动清理或者设置,一级缓存其实就相当于一个Map
测试步骤:
开启二级缓存设置;
<setting name="cacheEnabled" value="true"/>
<!--注:二级缓存是默认开启的,但是我们一般会显示的写出来-->
在要使用二级缓存的mapper.xml配置文件中开启缓存:
<!--直接开启-->
<cache/>
<!--当然还可以给缓存设置一些属性-->
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
<!--该缓存的
清除缓存策略:FIFO(最近最少使用)
刷新间隔:60s
最多存储:结果对象或列表的 512 个引用
返回的对象被认为是只读的
-->
测试
小结:
在使用二级缓存的时候可能会报错:
Error serializing object. Cause: java.io.NotSerializableException
解决:原因是没有将实体类序列化,所以直接将类序列化即可
在mapper.xml文件中,对于查找标签都可以手动设置是否开启缓存
useCache="true"
缓存清除的策略:
LRU – 最近最少使用:移除最长时间不被使用的对象。FIFO – 先进先出:按对象进入缓存的顺序来移除它们。SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。所有的数据都会先存到一级缓存,只有当会话提交或者关闭才会提交到二级缓存
注:一般可以采用redis来做缓存!!
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
(本文是网络的宏观的概念铺垫)目录计算机网络背景网络发展认识"协议"网络协议初识协议分层OSI七层模型TCP/IP五层(或四层)模型报头以太网碰撞路由器IP地址和MAC地址IP地址与MAC地址总结IP地址MAC地址计算机网络背景网络发展 是最开始先有的计算机,计算机后来因为多项技术的水平升高,逐渐的计算机变的小型化、高效化。后来因为计算机其本身的计算能力比较的快速:独立模式:计算机之间相互独立。 如:有三个人,每个人做的不同的事物,但是是需要协作的完成。 而这三个人所做的事是需要进行协作的,然而刚开始因为每一台计算机之间都是互相独立的。所以前面的人处理完了就需要将数据
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
目录1关系运算符2运算符优先级3关系表达式的书写代码实例:下面是面试中可能遇到的问题:1关系运算符C++中有6个关系运算符,用于比较两个值的大小关系,它们分别是:运算符描述==等于!=不等于小于>大于小于等于>=大于等于这些运算符返回一个布尔值,即true或false。例如,当x等于y时,x==y的结果为true,否则结果为false。2运算符优先级在C++中,关系运算符的优先级高于赋值运算符,但低于算术运算符。以下是关系运算符的优先级,从高到低排列:运算符描述>,,>=,关系运算符==,!=相等性运算符&&逻辑与`如果在表达式中有多个运算符,则按照优先级顺序依次进行运算。3关系表达式的书写在
一.计算机组成原理 这本书利用组合逻辑、同步时序逻辑电路设计的相关知识,从逻辑门开始逐步构建运算器、存储器、数据通路和控制器,最终集成为完整的CU原型系统,使读者从设计者的角度理解计算机部件构成及运行的基本原理,掌握软硬件协同的概念。 全书共9章,主要内容包括计算机系统概述、数据信息的表示、运算方法与运算器、存储系统、指令系统、中央处理器、指令流水线、总线系统、输入输出系统。1.计算机系统概述1.1计算机发展历程 计算机是一种能够按照事先存储的程序,自动、高速、准确地对相关信息进行处理的电子设备。1946年2月,世界上第一台电子数字计算机ENIAC(ElectronicNum
其实现在基础的资料和视频到处都是,就是看你有没有认真的去找学习资源了,去哪里学习都是要看你个人靠谱不靠谱,再好的教程和老师,你自己学习不进去也是白搭在正式选择之前,大可以在各种学习网站里面找找学习资源先自己学习一下为什么选择学软件测试?同学们理由众多!大概分这几类:①不受开发语言、行业产品变化限制;②入门更简单,对零基础、女生都友好;③软件项目都需要测试人员,职业生涯稳;④学习周期短,但薪资并不低。要想“肩扛”一条线?需掌握三大技能:技能1:掌握测试流程,熟悉系统框架能提前与开发人员一起制定测试计划,通过测试左移,推动代码评审,代码审计,单元测试,自动化冒烟测试,来保证研发阶段的质量。技能2: