在自然语言处理中,通常用于分类任务,例如语言模型、情感分类等。NLL损失全称为Negative Log-Likelihood Loss,其含义是负对数似然损失。
在NLP任务中,我们通常将文本数据表示为一个序列,例如单词序列或字符序列(一句话就是一个序列【sequence】)。对于分类任务,我们需要将每个序列映射到一个类别标签。因此,我们需要一个模型,能够将输入序列映射到输出标签。
在模型训练期间,我们需要最小化模型预测结果和真实标签之间的差异,以使模型的预测结果更加接近真实结果,使用NLL损失可以帮助我们实现这一点。
具体来说,对于一个输入序列 x 和真实标签 y,我们可以使用模型预测的标签分布 和真实标签 y 的对数概率来计算NLL损失,计算公式就是右半部分:

NLL损失的含义是:如果我们的模型的预测结果 越接近真实标签 y ,那么
的值就越小。
在模型训练期间,我们使用NLL损失来计算每个样本的损失值,并通过反向传播算法更新模型参数以最小化总体NLL损失。这样可以帮助我们训练出更好的模型,使其在测试数据上的表现更好。
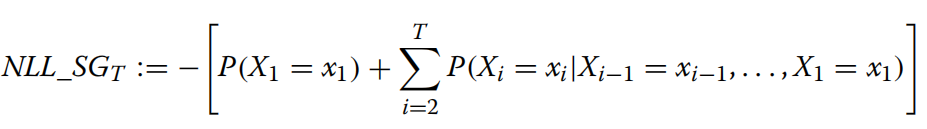
总之,这个损失函数的目的是通过最小化模型的预测值与真实token序列之间的差异来训练语言模型。在训练过程中,通过“Teacher’s forcing”方法,模型可以更好地学习语法和语义规则,提高模型在生成下一个token时的准确性和流畅性。
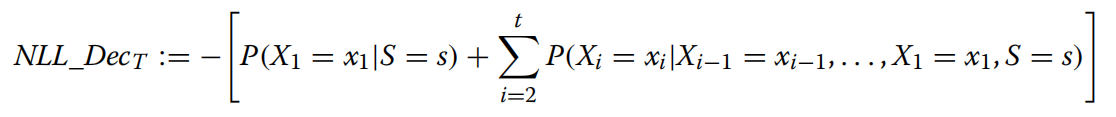
具体来说,该损失函数的第一项是第一个时间步的损失,表示在给定输入序列 s 的情况下,模型生成第一个标记 的概率与真实标记的概率之间的差异。第二项是从第二个时间步开始的损失项,表示在给定输入序列和前面的标记的情况下,模型生成第 i 个标记
的概率与真实标记的概率之间的差异。
总之,该损失函数的目的是通过最小化模型预测的标记序列与真实标记序列之间的差异来训练生成模型,使其在给定输入序列的情况下能够生成符合语言规则和语义的标记序列。通过优化该损失函数,可以提高生成模型的生成准确性和流畅性。
将上面的损失函数写成NLL损失的样式:
假设 是给定的序列,S 是上下文,
是可能的值,
是给定先前历史和上下文 S=s 条件下,预测
为
的概率。
则 可以表示为:
其中第一项是条件概率 的负对数,第二项是从第二个时刻开始的条件概率
的负对数之和。
有人可以告诉我如何根据自定义字符串对嵌套数组进行排序吗?比如有没有办法排序:[['Red','Blue'],['Green','Orange'],['Purple','Yellow']]“橙色”、“黄色”,然后是“蓝色”?最终结果如下所示:[['Green','Orange'],['Purple','Yellow'],['Red','Blue']]它不是按字母顺序排序的。我很想知道我是否可以定义要排序的值以实现上述目标。 最佳答案 sort_by对于这种排序总是非常方便:a=[['Red','Blue'],['Green','Ora
我有两个数组。第一个数组包含排序顺序。第二个数组包含任意数量的元素。我的属性是保证第二个数组中的所有元素(按值)都在第一个数组中,而且我只处理数字。A=[1,3,4,4,4,5,2,1,1,1,3,3]Order=[3,1,2,4,5]当我对A进行排序时,我希望元素按照Order指定的顺序出现:[3,3,3,1,1,1,1,2,4,4,4,5]请注意,重复是公平的游戏。A中的元素不应更改,只能重新排序。我该怎么做? 最佳答案 >>source=[1,3,4,4,4,5,2,1,1,1,3,3]=>[1,3,4,4,4,5,2,1,1
我认为这很容易,并且已经很努力地搜索过,但似乎无法让它工作。我有以下哈希:@friends=[{"name"=>"JohnSmith","id"=>"12345"},{"name"=>"JaneDoe","id"=>"23456"},{"name"=>"SamuelJackson","id"=>"34567"},{"name"=>"KateUpton","id"=>"45678"}]我正在尝试按名称的字母顺序对其进行排序。现在我正在这样做:@friends.sort{|a,b|a[0]b[0]}但是,它只是以非字母顺序输出完整结果。 最佳答案
我有一个嵌套的数字数组,排列如下:ids=[[5,8,10],[8,7,25],[15,30,32],[10,8,7]]我只需要一个包含所有键的数组,无需重复,所以我使用了这个:ids=ids.flatten.uniq产生这个:ids=[5,8,10,7,25,15,30,32]由于我使用了.uniq,它消除了重复值。但是,我想根据它们在子数组中出现的频率来对值进行排序,而不是它们碰巧处于的顺序——所以像这样:ids=[8,10,7,5,25,15,30,32] 最佳答案 应该这样做:ids.flatten.group_by{|i|
抱歉,如果之前有人问过这个问题,我什至不确定如何搜索它,而且我搜索的内容没有产生任何有用的答案。这是我的问题,我有一个框架,基本上管理将提交给PBS集群的作业,每个作业都需要从输入文件中读取。我们的情况是,我们有超过5k个作业需要运行,并且有批处理,比方说,大约30个从不同的文件读取,但其余的从另一个作业正在读取的文件中读取。这可以很容易地处理(虽然不是最好的解决方案购买可能是我们拥有的时间范围内最快的解决方案)通过能够按ID对作业列表进行排序,这基本上意味着它将从哪个文件读取,即我想像这样对数组进行排序a=[1,1,1,2,2,2,3,3,3,4,4,4]进入a=[1,2,3,4,1
我有一个看起来像这样的ruby数组:my_array=['mushroom','beef','fish','chicken','tofu','lamb']我想对数组进行排序,使“鸡肉”和“牛肉”成为前两项,然后其余项按字母顺序排序。我该怎么做呢? 最佳答案 irb>my_array.sort_by{|e|[e=='chicken'?0:e=='beef'?1:2,e]}#=>["chicken","beef","fish","lamb","mushroom","tofu"]这将为数组的每个元素创建一个排序键,然后根据排序键对数组
我有一个Array的Array,我想按最长到最短的长度排序。我使用sort_by轻松实现了这一点>a=[[1,2,9],[4,5,6,7],[1,2,3]]>a.sort_by(&:length).reverse#ora.sort_by{|e|e.length}.reverse=>[[4,5,6,7],[1,2,3],[1,2,9]]然而,我想要的是为等长列表设置一种决胜局。如果两个列表的长度相等,则最后一个条目较大的列表应该排在第一位。所以上面的[1,2,9]和[1,2,3]应该调换一下。我不关心两个列表的长度和最后一个元素都相等的情况,如果发生这种情况,它们可以按任何顺序排列。我不
我想AND或OR数组中的所有元素,但要有一些控制,如散列元素选择所示。这是我希望实现的行为:a=[{:a=>true},{:a=>false}]a.and_map{|hash_element|hash_element[:a]}#=>falsea.or_map{|hash_element|hash_element[:a]}#=>true在Ruby中是否有一种巧妙、干净的方法来做到这一点? 最佳答案 您可以为此使用all?和any?:a=[{:a=>true},{:a=>false}]a.any?{|hash_element|has
我通常会做类似的事情array.sort{|a,b|a.somethingb.something}我应该如何干燥它? 最佳答案 使用排序方式array.sort_by{|e|e.something或sort_lambda=lambda{|e|e.something}array.sort_by(&sort_lambda)使用后者,您可以在其他sort_by语句中重用sort_lambda 关于ruby-在ruby中对数组进行排序的最简单代码?,我们在StackOverflow上找到一个
假设我有an_array=[[2,3],[1,4],[1,3],[2,1],[1,2]]我想按每个内部数组的第一个值对这个数组进行排序,然后按第二个值排序(因此排序后的数组应如下所示:[[1,2],[1,3],[1,4],[2,1],[2,3]])执行此操作最易读的方法是什么? 最佳答案 这是排序数组的默认行为(参见Array#方法定义以获取证明)。你应该能够做到:an_array.sort 关于ruby-按两个值对数组进行排序,我们在StackOverflow上找到一个类似的问题: