
🌇个人主页:_麦麦_
📚今日名言:生活不可能像你想象的那么好,也不会像你想象的那么糟。——莫泊桑《羊脂球》

目录
好久不见,今天为小伙伴们带来C语言中有关结构体的详细知识,干货满满,图文并茂一定要看到底哦!
结构是一些值的集合,这些值称为成员变量,结构的每个成员可以是不同类型的变量
struct tag
{
member—list;
} ;
注:分号不能丢
//结构的声明演示:描述一个学生
struct Stu
{
char name[20]; //名字
char sex[5]; //性别
int age; //年龄
char id[20]; //学号
};在声明结构的时候,可以不完全声明【匿名结构体类型】,由于匿名,所以声明后就得在后面直接创建变量。
//匿名结构体类型
struct
{
int a;
char b;
float c;
}x; //创建变量x注:哪怕两个匿名结构体中的内容完全一样也会被编译器当成两个完全不同的类型
//匿名结构体类型1
struct
{
int a;
char b;
float c;
}x;
//匿名结构体类型2
struct
{
int a;
char b;
float c;
}*p;
//非法操作
p = &x;结构体变量的定义共分为三类:
①全局变量定义
②局部变量定义
③在结构的声明的同时定义变量
//结构体变量的三种定义方法
struct Stu
{
char name[20]; //名字
char sex[5]; //性别
int age; //年龄
char id[20]; //学号
}Stu1; //声明结构的同时定义变量
struct Stu Stu2; //全局变量定义
int main()
{
struct Stu Stu3; //局部变量定义
return 0;
}结构体变量的初始化即定义变量的同时赋初值。不过结构体的初始化也分为正常的初始化和嵌套初始化。
//结构体变量的初始化
struct Peo
{
char name[20]; //名字
char sex[5]; //性别
int age; //年龄
};
struct Peo Peo1 = { "陈书婷","女",35}; //结构体正常初始化
struct Node
{
char movie[20];
struct Peo p;
}Peo2 = { "狂飙",{"高志强","男",40 }}; //结构体嵌套初始化
struct Node Peo3 = { "狂飙",{"高启盛","男","28"}}; //结构体嵌套初始化
注:结构体的初始化其实可以更加灵活——乱序,按照自己想法来初始化。
struct Peo
{
char name[20]; //名字
char sex[5]; //性别
int age; //年龄
};
struct Peo Peo4 = { .sex = "男",.name = "安欣",.age = 30 };采取指针的形式
在结构中包含一个类型为该结构本身的成员
//自引用1(错误示范)
struct Node
{
int date;
struct Node next;
};
//自引用2(正确示范)
struct Node
{
int date;
struct Node* next;
};在小伙伴们掌握了结构体的基本使用之后,接下来让我们深入讨论一个问题:如何计算结构体的大小?为了解决这个问题,我们就必须掌握结构体的对齐规则。
● 第一个成员在与结构体变量偏移量为0的地址处
●其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数=编译器默认的一个对齐数与该成员大小的较小值
★VS中默认的值为8
●结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍
●如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍
#include<stdio.h>
//结构体内存对齐代码1
struct s1
{
double d; //对齐数8
char c; //对齐数1
int i; //对齐数4
};
//结构体内存对齐代码2
struct s2
{
char c1; //对齐数1
struct s1 s1; //对齐数8
double d; //对齐数8
};
int main()
{
printf("%d", sizeof(struct s1)); //16
printf("%d", sizeof(struct s2)); //32
return 0;
}
结构体内存对齐代码1:首先我们将"d"成员放入内存中,由于它是第一个成员,且对齐数为8,所以从偏移量为0的地址一直放到偏移量为7的地址。其次是"c"成员,它的对齐数为1,因此可以放在偏移量为8的地址处,最后是"i"成员,它的对齐数是4,但是偏移量为9的地址并不是对齐数4的倍数,所以我们只好跳到偏移量为12的地址处,直至偏移量为15的地址处才放下"i"成员。在将所有的成员放入后,就是计算结构体s1的大小,由于15并不是最大对齐数8的倍数,所以结构体s1的大小为16个字节。
结构体内存对齐代码2:首先我们将"c1"成员放入内存中,由于它是第一个成员,且对齐数为1,所以放入偏移量为0的地址处。其次是"s1"成员,该嵌套结构体内的最大对齐数为8,因此跳到偏移量为8的地址处开始存放double类型成员,直至偏移量为15的地址处才存放完毕。接着是char类型成员,对齐数为1,存放在偏移量为16的地址处。继而是整型成员,对齐数为4,从偏移量为20的地址存放,直至偏移量为23的地址处存放完毕。最后是"d"成员,对齐数为8,从偏移量为24的地址存放,直至偏移量为31的地址处存放结束。在将所有的成员放入后,就是计算结构体s2的大小,由于31并不是最大对齐数8的倍数,所以结构体s2的大小为32个字节
最后总结一下计算结构体大小的步骤:
①计算出所有成员的对齐数并得出结构体的最大对齐数
②根据每个成员的对齐数依次存放每个成员
③所有成员存放完毕后,依据结构体的最大对齐数得出结构体大小
那么如何证明我们对结构体成员的偏移量计算是否正确呢?C语言中提供了一个宏来计算结构体成员的偏移量?(无需掌握,只是证明我们上述计算的思路无误)
#include<stddef.h>
int main()
{
printf("%d\n", offsetof(struct s1,d));
printf("%d\n", offsetof(struct s1,c));
printf("%d\n", offsetof(struct s1,i));
printf("%d\n", offsetof(struct s2, c1));
printf("%d\n", offsetof(struct s2, s1.d));
printf("%d\n", offsetof(struct s2, s1.c));
printf("%d\n", offsetof(struct s2, s1.i));
printf("%d\n", offsetof(struct s2, d));
return 0;
}
在了解完结构体的内存,可能有的小伙伴会发出如下的疑问:为什么会存在内存对齐呢,这到底有什么用呢?
大部分的参考资料都是如是说的:
1.平台原因(移植原因):
不是所有的硬件平台都能任意访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些 特定类型的数据,否则就会抛出硬件异常
2.性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界对齐。
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
总的来说:结构体的内存对齐是拿空间来换取时间的做法
那么在设计结构体的时候,我们既要满足对齐,又要节省空间,该如何做呢?
让占用空间小的成员尽量集中在一起
那么默认对齐数可以修改吗?答案是肯定的。在C语言中存在#pragma这个预处理指令,通过这个我们就可以改变默认对齐数了。
//修改默认对齐数
#include <stdio.h>
#pragma pack(2)
struct s1
{
char c1;
int i;
char c2;
};

注:如果将默认对齐数设置为1,则不存在对齐效果。在平常的使用中,小伙伴们一定要根据实际需求修改默认对齐数
在之前的指针学习中我们了解到了"传值调用"和"传址调用"这两个概念,那么在结构体传参时依旧存在以上两种方式,那么那种方式是最优选择呢?
//结构体传参
#include <stdio.h>
struct s
{
int date[1000];
int num;
};
struct s s1 = { {1,2,3,4},666 };
void print1(struct s s1)
{
printf("%d",s1.num);
}
void print2(struct s* s1)
{
printf("%d", s1->num);
}
int main()
{
print1(s1); //传结构体
print2(&s1); //传地址
}其实,在结构体传参这一步中传结构体的地址是一个更好的选择。因为函数传参的时候,参数是需要压栈的,会有时间和空间上的系统开销。如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,所以会导致性能的下降。
在结构体讲完之后就要向小伙伴们介绍结构体实现位段的能力
位段的声明和结构是类似的,却能更加的节省空间,但是有两个地方存在差异:
①位段的成员必须是int、unsigned int 或 signed int
②位段的成员名后边有一个冒号和数字【表示占几个二进制位】
#include <stdio.h>
struct A
{
int _a : 2; //a只占2个二进制位
int _b : 5; //b只占5个二进制位
int _c : 10; //c只占10个二进制位
int _d : 30; //d只占30个进制位
};
int main()
{
printf("%d\n", sizeof(struct A)); //打印为8个字节,是不是更节省空间了呢
return 0;
}1.位段的成员可以是int 、unsigned int、signed int、或者是char(属于整形家族)类型
2.位段的空间上是按照需要以4个字节(int)或者1个字节(char)的方式来开辟的
3.位段设计很多不确定因素,位段是不跨平台的,注意可移植的程序应该避免位段
4.位段是不存在内存对齐的
注:在不同的编译器中,同一位段的大小也是不确定的,接下来我们以VS2019的环境下解释上述位段的大小为何为8个字节。

在理解完位段在VS下的内存开辟,那么内存是如何使用的呢?在VS的环境下,内存开辟后是从右向左使用的且为小端存储,依旧以上面的代码为例:

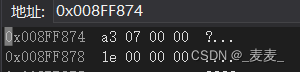
①int位段被当成有符号数还是无符号数是不确定的
②位段中最大位的数目不能确定(16位机器最大16,32位机器最大32,写成27,在16位机器会出现问题)
③位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义
④当一个结构包含两个位段,第二个位段成员比较大,无法容纳与第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的
总结:跟结构相比,位段可以达到同样的效果,但是可以很好地节省空间,但是有跨平台的问题存在
大家都知道彼此之间相互的交流看似简单,其实文字交流的背后是大量的网络数据,而位段的使用恰好可以对数据进行压缩,减少网络的压力和负担。形象的来说,我们可以把网络想象成高速公路,如果上面全是未经压缩的数据,也就都是大卡车的话,就会十分拥挤。而如果采取位段的方式,对没有必要使用的空间进行压缩,就可以将大卡车变成小轿车,从而缓解交通压力。
关于结构体的讲解就已经全部结束了,下期我们会继续分享自定义类型的其他成员!
关注我 _麦麦_分享更多干货:_麦麦_的博客_CSDN博客-领域博主
大家的「关注❤️ + 点赞👍 + 收藏⭐」就是我创作的最大动力!谢谢大家的支持,我们下期见!
我正在尝试设置一个puppet节点,但rubygems似乎不正常。如果我通过它自己的二进制文件(/usr/lib/ruby/gems/1.8/gems/facter-1.5.8/bin/facter)在cli上运行facter,它工作正常,但如果我通过由rubygems(/usr/bin/facter)安装的二进制文件,它抛出:/usr/lib/ruby/1.8/facter/uptime.rb:11:undefinedmethod`get_uptime'forFacter::Util::Uptime:Module(NoMethodError)from/usr/lib/ruby
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
我有一些代码在几个不同的位置之一运行:作为具有调试输出的命令行工具,作为不接受任何输出的更大程序的一部分,以及在Rails环境中。有时我需要根据代码的位置对代码进行细微的更改,我意识到以下样式似乎可行:print"Testingnestedfunctionsdefined\n"CLI=trueifCLIdeftest_printprint"CommandLineVersion\n"endelsedeftest_printprint"ReleaseVersion\n"endendtest_print()这导致:TestingnestedfunctionsdefinedCommandLin
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano

