本期给大家带来的是是《LeetCode 热题 HOT 100》第四题——寻找两个正序数组的中位数的题目讲解!!!()
本文目录
题目如下 :👇
给定两个大小分别为 m 和 n 的正序(从小到大)数组 nums1 和 nums2。请你找出并返回这两个正序数组的 中位数 。
算法的时间复杂度应该为 O(log (m+n))
示例 1:
输入:nums1 = [1,3], nums2 = [2]
输出:2.00000
解释:合并数组 = [1,2,3] ,中位数 2示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:2.50000
解释:合并数组 = [1,2,3,4] ,中位数 (2 + 3) / 2 = 2.5
首先,我们需要注意的一点就是关于本题时间复杂度的要求,本题要求的时间复杂度为 O(log (m+n)) ,这里一定要特别注意!!
其次,我们来对给出的示例给出解释说明,分析题意:
首先,大家拿道题,第一种想到的可能就是直接对这两个数组进行合并在进行排序处理,排完序之后紧接着根据数据长度的奇偶性,我们来判断中位数的到底是n/2还是n/2+1:
代码如下:
class Solution {
public:
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
vector<int>arr;
for(auto& e :nums1) {arr.push_back(e);}
for(auto& e :nums2) {arr.push_back(e);}
sort(arr.begin(),arr.end());
int m=arr.size();
if( m % 2 == 0){
return (double)(arr[m/2]+arr[m/2-1]) /2.0;
} else{
return arr[m/2];
}
}
};
💨 这种做法可以通过但是却不符合提本题的要求,因为它的时间复杂度就为了 O((m+n)log (m+n)),这样做时间复杂度就取决于排序的代价。因此,这种方法我就此忽略。
其实我们在稍加思考,就可以想到一种优化方法。
💨 我们可以联想到归并排序,这个我想大概应该都学过的。我们不用在进行先合并在sorted,我们可以直接把这两个归并为一个已经排序好的数组。此时这就是双指针的算法,时间复杂度此时为O(m+n)。
这个还可以进行优化,我们不需要对全部进行归并操作,因为我们只关心中位数,因此我们可以计算中位数的下标,假设此时中位数的下表为 k,时间复杂度就为O(k),k的取值取决于数组的长度还是,介于(m+n)/2和 (m+n)/2+1。但是此时依然也不能满足我们题意的 log 级别的时间复杂度的要求.
注意:
题目如下:
给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。
请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。
注意:
示例 1:
输入:nums1 = [1,2,3,0,0,0], m = 3, nums2 = [2,5,6], n = 3
输出:[1,2,2,3,5,6]
解释:需要合并 [1,2,3] 和 [2,5,6] 。
合并结果是 [1,2,2,3,5,6] ,其中斜体加粗标注的为 nums1 中的元素。
示例 2:
输入:nums1 = [1], m = 1, nums2 = [], n = 0
输出:[1]
解释:需要合并 [1] 和 [] 。
合并结果是 [1] 。示例 3:
输入:nums1 = [0], m = 0, nums2 = [1], n = 1
输出:[1]
解释:需要合并的数组是 [] 和 [1] 。
合并结果是 [1] 。
注意,因为 m = 0 ,所以 nums1 中没有元素。nums1 中仅存的 0 仅仅是为了确保合并结果可以顺利存放到 nums1 中。
💥题意分析:
💥解题思路:
1、直接法
代码如下:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
//此时我们选nums1作为 填充数组,把nums2中元素全部插入到nums1中
for(int i=0; i<n; ++i)
{
nums1[m+i]=nums2[i];
}
//此时,全部的元素都在nums1数组中了,最后排序输出即可
sort(nums1.begin(),nums1.end());
}
};性能分析:
2、归并排序思想
图解:
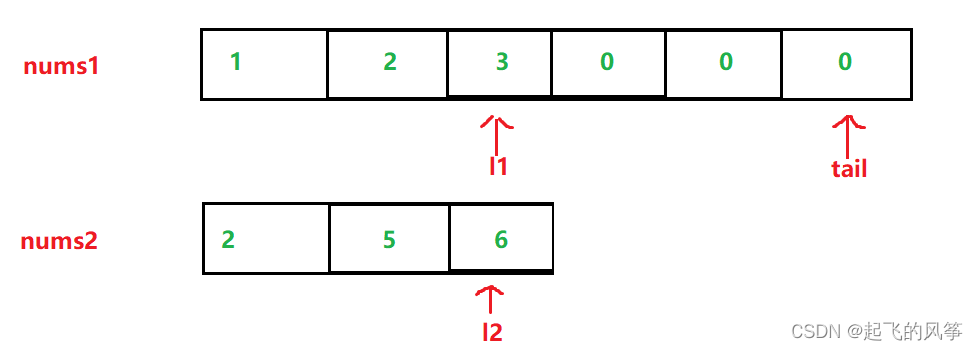
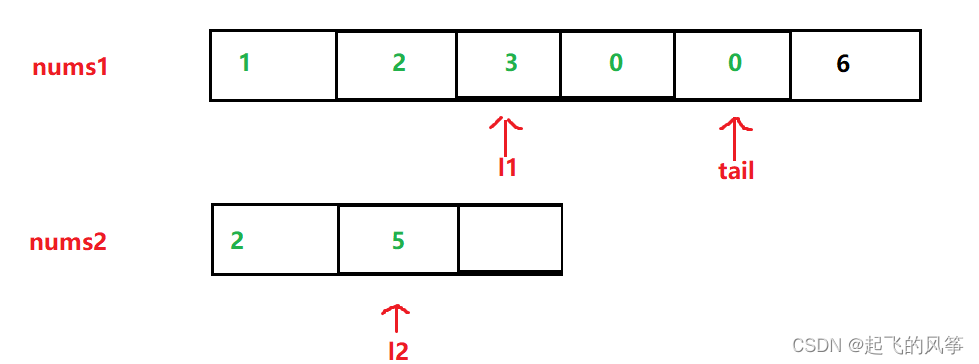
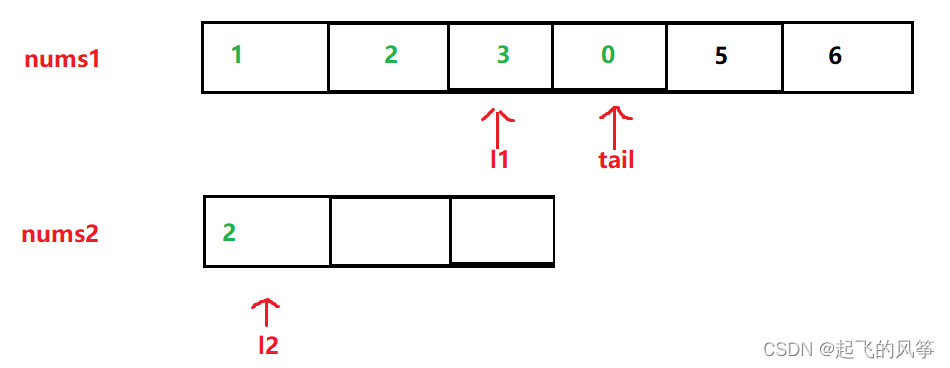
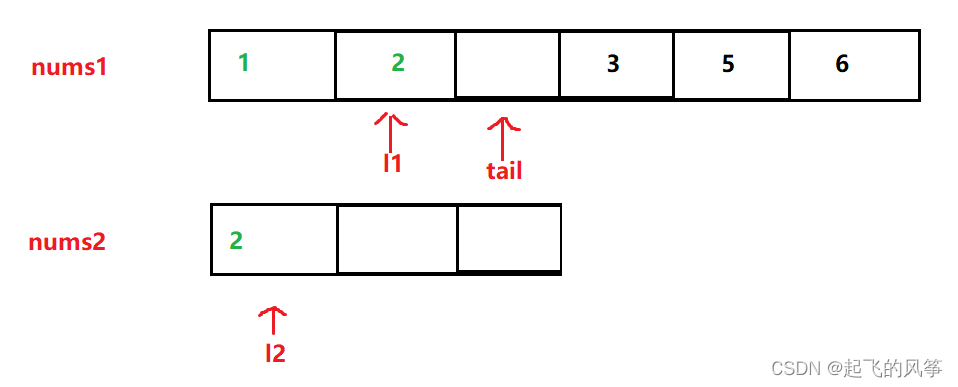
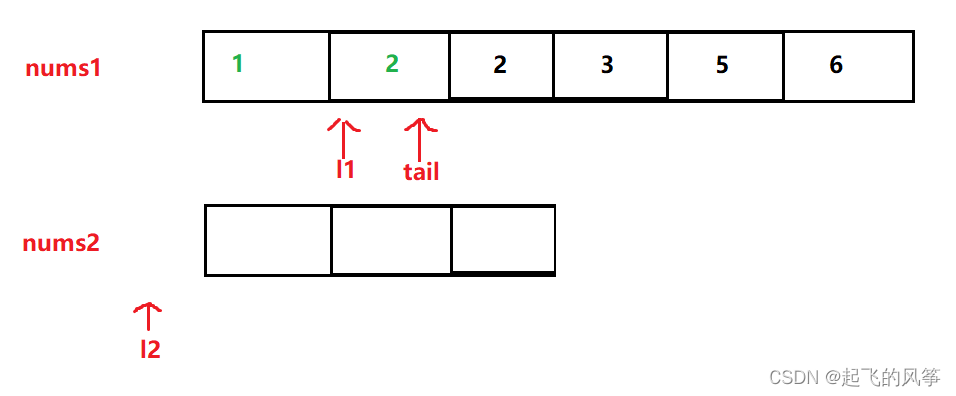
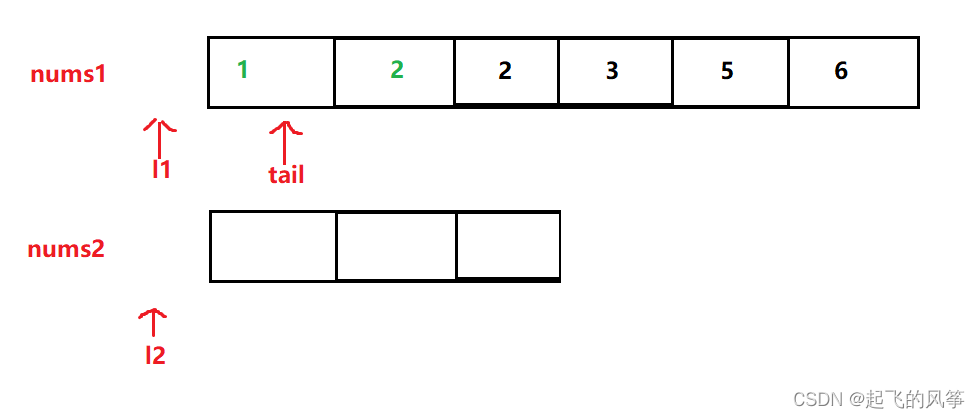
代码如下:
class Solution {
public:
void merge(vector<int>& nums1, int m, vector<int>& nums2, int n) {
int l1 = m - 1;
int l2 = n - 1;
int tail = m + n - 1;
while (l1 >= 0 && l2 >= 0)
{
if (nums1[l1] > nums2[l2])
{
nums1[tail--] = nums1[l1--];
}
else
{
nums1[tail--] = nums2[l2--];
}
}
while (l1 >= 0)
{
nums1[tail--] = nums1[l1--];
}
while (l2 >= 0)
{
nums1[tail--] = nums2[l2--];
}
}
};
性能分析:
温馨小提示:
我们除了从后往前操作之外,还有从前往后操作。这个任务就交给大家了,原理跟上面讲到的一样的!!!
最后,其实我们可以想到,要想实现 log 级别的时间复杂度,最容易想到的就是采用二分查找的思想。
但是二分查找,我们之前学过的都是对一个数组进行二分查找,本题我们这里有两个数组,因此此题的难度我们可以看到标的是 困难。但是也不要害怕,接下来我带大家分析一波
图解:
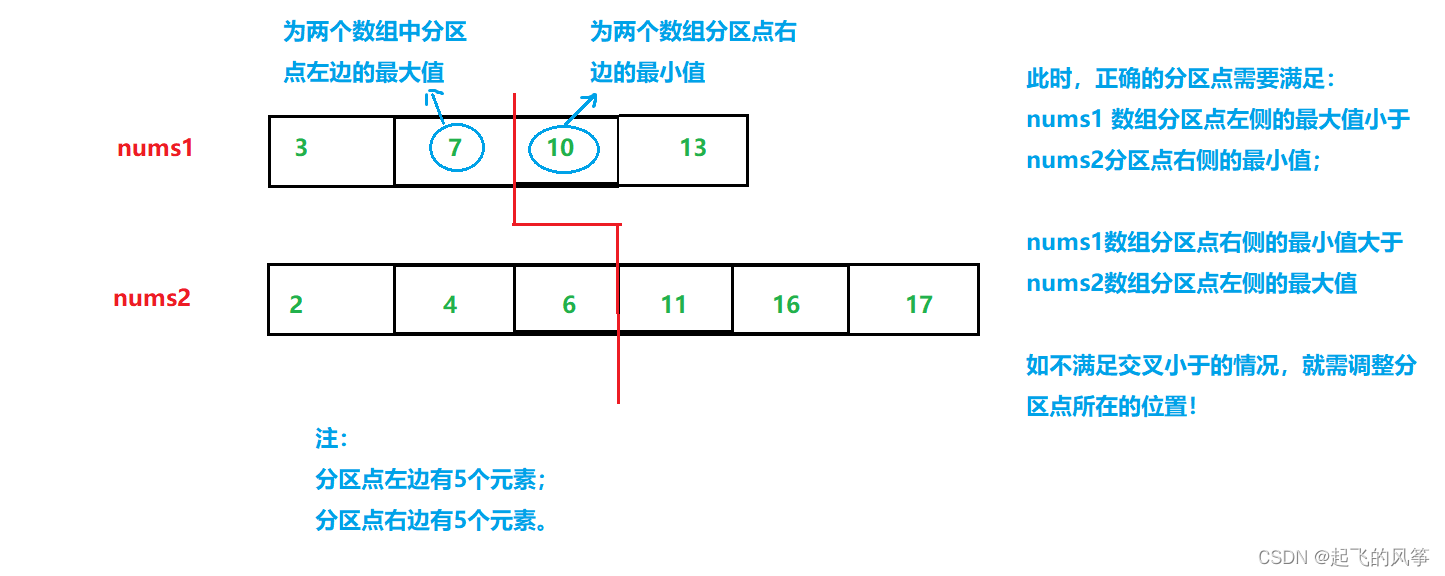
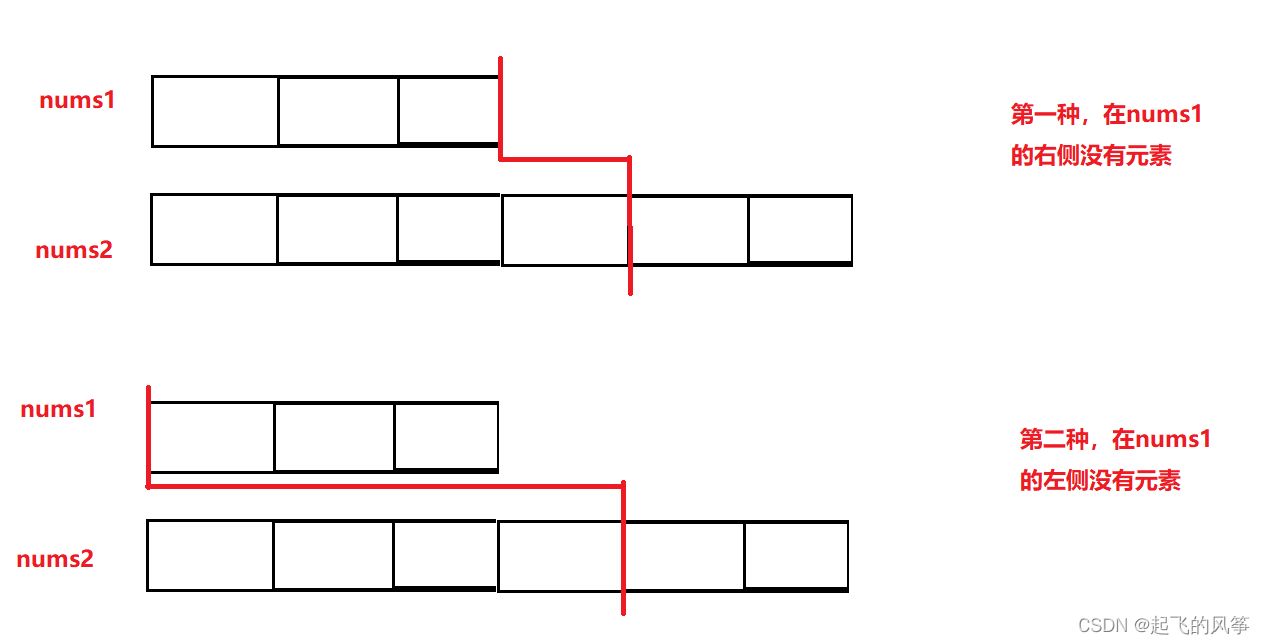
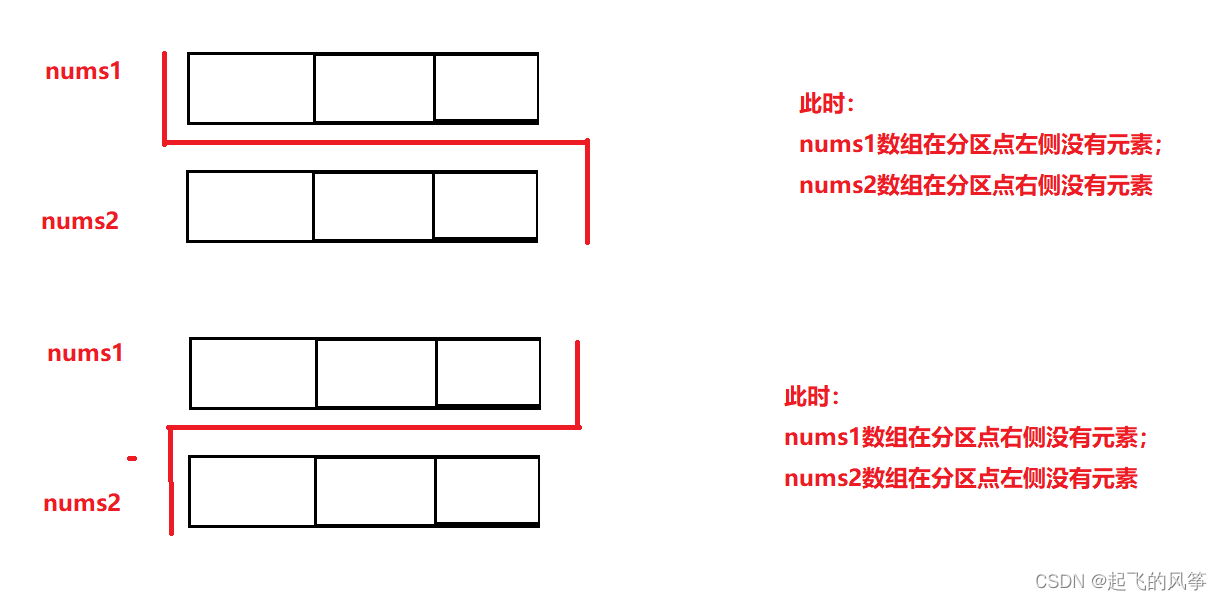
具体步骤:
代码如下:
class Solution {
public:
double findMedianSortedArrays(vector<int>& nums1, vector<int>& nums2) {
//记录两个数组的长度大小
int m = nums1.size();
int n = nums2.size();
//确保第一个数组始终是较短数组
if (m > n)
{
return findMedianSortedArrays(nums2, nums1);
}
//在较短数组的区间 【0,m】之间里查找出合适的分区点
//使得较短数组满足我们需要的条件
int left = 0;
int right = m;
while (left <= right) {
//找到较短数组的分区点partition1
int partition1 = (left + right) / 2;
//利用公式找到较长数组的分区点partition2
int partition2 = (m + n + 1) / 2 - partition1;
//然后我们检查分区点是否在数组的边界,如果没有,我们检查分区点处元素是否形成有效的中位数
//如果没有,我们可以相应的调整分区点
//较短数组找到分区点后,因为数组是已经排好序的
//当 partition1=0 时,说明较小数组分割线左边没有值,为了不影响
//nums1[partition1] <= nums2[partition2]和 Math.max(maxLeft1, maxLeft2)的判断
//所以将它设置为int的最小值,即INT_MIN
int maxLeft1 = (partition1 == 0) ? INT_MIN : nums1[partition1 - 1];
//较短数组找到分区点后,因为数组是已经排好序的
//partition1 等于较小数组的长度时,说明较小数组分割线右边没有值,为了不影响
// nums2[partition2] <= nums1[partition1] 和 Math.min(minRight1, minRight2)的判断,
//所以将它设置为int的最大值,即INT_MAX
int minRight1 = (partition1 == m) ? INT_MAX : nums1[partition1];
//较长数组找到分区点后,因为数组是已经排好序的
//当partition2等于0时,说明较长数组分割线左边没有值,为了不影响
// nums2[partition2] <= nums1[partition1] 和 Math.max(maxLeft1, maxLeft2)的判断,
//所以将它设置为int的最小值,即INT_MIN
int maxLeft2 = (partition2 == 0) ? INT_MIN : nums2[partition2 - 1];
//较长数组找到分区点后,因为数组是已经排好序的
//当partition2 == n,说明较长数组分割线右边没有值,为了不影响
//nums1[partition1] <= nums2[partition2] 和 Math.min(minRight1, minRight2)的判断,
//所以将它设置为int的最大值,即INT_MAX
int minRight2 = (partition2 == n) ? INT_MAX : nums2[partition2];
//然后,我们计算两个数组中分区左侧的最大元素和两个数组中分区右侧的最小元素
//如果较短数组中分区左侧的最大元素小于或等于较长数组中分区右侧的最小元素 并且
//较短数组中分区右侧的最小元素大于等于较长数组中分区左侧的最大元素 ,然后表明我们找到了中位数
if (maxLeft1 <= minRight2 && maxLeft2 <= minRight1) {
//如果合并后数组的长度是偶数,我们取分区左侧最大元素和分区右侧最小元素的平均值
if ((m + n) % 2 == 0)
{
return (max(maxLeft1, maxLeft2) + min(minRight1, minRight2)) / 2.0;
}
//如果合并后数组的长度是奇数,我们取分区左侧最大元素作为作为中位数
else
{
return max(maxLeft1, maxLeft2);
}
}
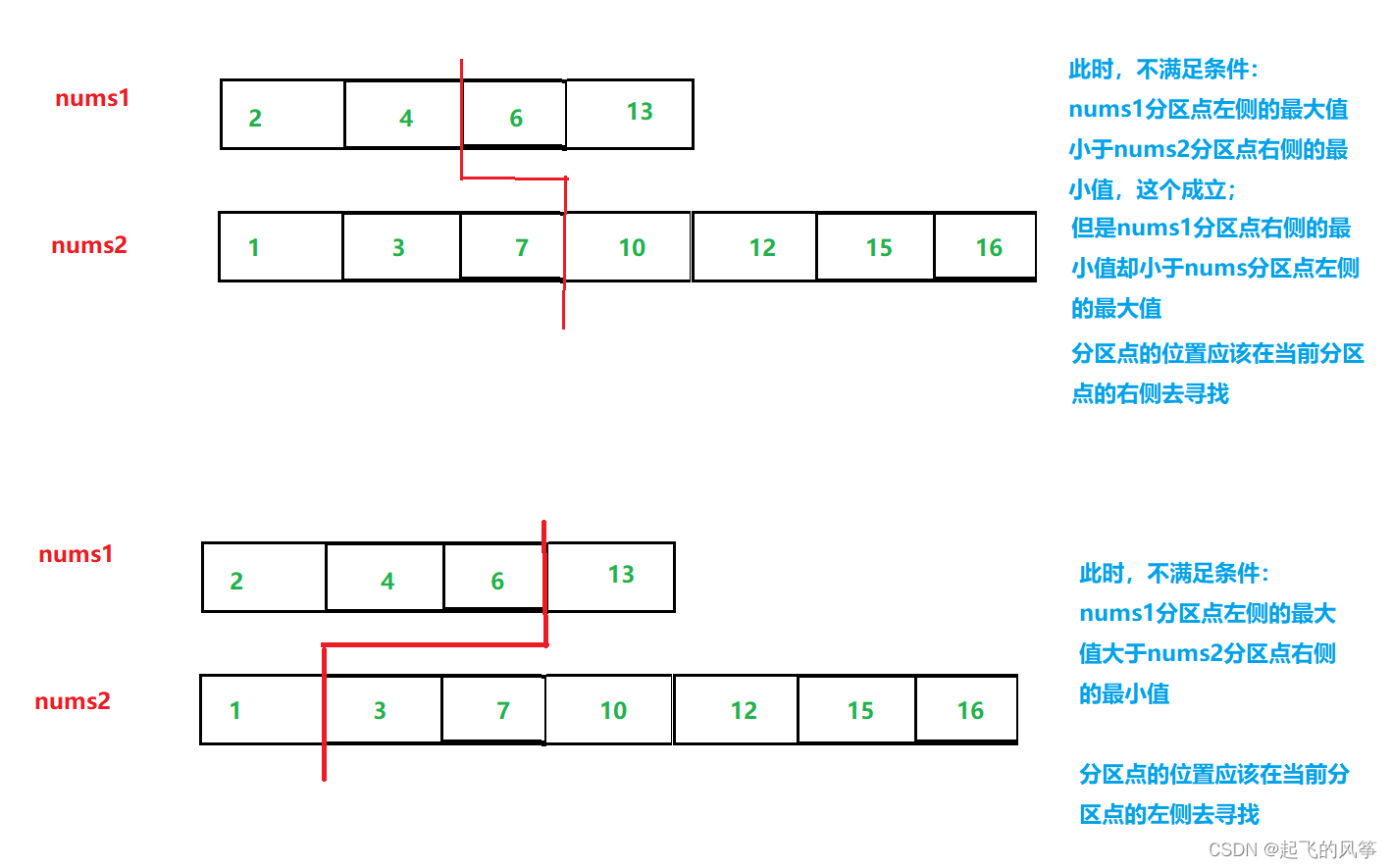
//此处用了maxleft1 < minRight2的取反,当较小数组中分区点的左边的值大于较长数组中分区点的右边的值
//表面右指针应该左移
else if (maxLeft1 > minRight2)
{
right = partition1 - 1;
}
//满足条件,左指针继续右移到 partition1 + 1位置处
else
{
left = partition1 + 1;
}
}
return 0.0;
}
};性能分析:
到此,本题便讲解结束了!!
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
我从用户Hirolau那里找到了这段代码:defsum_to_n?(a,n)a.combination(2).find{|x,y|x+y==n}enda=[1,2,3,4,5]sum_to_n?(a,9)#=>[4,5]sum_to_n?(a,11)#=>nil我如何知道何时可以将两个参数发送到预定义方法(如find)?我不清楚,因为有时它不起作用。这是重新定义的东西吗? 最佳答案 如果您查看Enumerable#find的文档,您会发现它只接受一个block参数。您可以将它发送两次的原因是因为Ruby可以方便地让您根据它的“并行赋
我已经有很多两个值数组,例如下面的例子ary=[[1,2],[2,3],[1,3],[4,5],[5,6],[4,7],[7,8],[4,8]]我想把它们分组到[1,2,3],[4,5],[5,6],[4,7,8]因为意思是1和2有关系,2和3有关系,1和3有关系,所以1,2,3都有关系我如何通过ruby库或任何算法来做到这一点? 最佳答案 这是基本Bron–Kerboschalgorithm的Ruby实现:classGraphdefinitialize(edges)@edges=edgesenddeffind_maximum_
我有两个文本文件,master.txt和926.txt。如果926.txt中有一行不在master.txt中,我想写入一个新文件notinbook.txt。我写了我能想到的最好的东西,但考虑到我是一个糟糕的/新手程序员,它失败了。这是我的东西g=File.new("notinbook.txt","w")File.open("926.txt","r")do|f|while(line=f.gets)x=line.chompifFile.open("master.txt","w")do|h|endwhile(line=h.gets)ifline.chomp!=xputslineendende
之前有人问过这个问题,我发现了以下clip关于如何一次设置一个类对象的所有属性,但由于批量分配保护,这在Rails中是不可能的。(例如,您不能Object.attributes={})有没有一种很好的方法可以将一个类的属性合并到另一个类中?object1.attributes=object2.attributes.inject({}){|h,(k,v)|h[k]=vifObjectModel.column_names.include?(k);h}谢谢。 最佳答案 利用assign_attributes使用:without_prote
我有两个具有以下格式的哈希mydetails[x['Id']]=x['Amount']这将包含如下数据hash1={"A"=>"0","B"=>"1","C"=>"0","F"=>"1"}hash2={"A"=>"0","B"=>"3","C"=>"0","E"=>"1"}我期待这样的输出:Differencesinhash:"B,F,E"非常感谢任何帮助。 最佳答案 这个解决方案可能更容易理解:(hash1.keys|hash2.keys).select{|key|hash1[key]!=hash2[key]}Array#|返回2
我正在为我的用户实现一些rubyonrails代码推特内容。我正在创建正确的oauth链接...类似http://twitter.com/oauth/authorize?oauth_token=y2RkuftYAEkbEuIF7zKMuzWN30O2XxM8U9j0egtzKv但在我的测试帐户授予对twitter的访问权限后,它会弹出一个页面,上面写着“您已成功授予对.我不知道用户应该在哪里输入此PIN以及他们为什么必须这样做。我认为这不是必要的步骤。Twitter应该将用户重定向到我在应用程序设置中提供的回调URL。有谁知道为什么会这样?更新我找到了thisarticle声明我需