阅读本章节前你需要先阅读了 Django 模型 进行基础配置及了解常见问题的解决方案。
接下来我们重新创建一个项目 app01(如果之前已创建过,忽略以下操作):
django-admin.py startproject app01
接下来在 settings.py 中找到 INSTALLED_APPS 这一项,如下:
INSTALLED_APPS = (
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'app01', # 添加此项
)
接下来,告诉 Django 使用 pymysql 模块连接 mysql 数据库:
在项目中的 models.py 中添加以下类:
然后在命令行执行以下命令:
$ python3 manage.py migrate # 创建表结构 $ python3 manage.py makemigrations app01 # 让 Django 知道我们在我们的模型有一些变更 $ python3 manage.py migrate app01 # 创建表结构
如果执行以上命令时会出现如下报错信息:

原因是 MySQLclient 目前只支持到 Python3.4,因此如果使用的更高版本的 python,需要修改如下:
通过报错信息的文件路径找到 ...site-packages\Django-2.0-py3.6.egg\django\db\backends\mysql 这个路径里的 base.py 文件,把这两行代码注释掉(代码在文件开头部分):
if version < (1, 3, 13):
raise ImproperlyConfigured('mysqlclient 1.3.13 or newer is required; you have %s.' % Database.__version__)

一般点报错的代码文件路径信息,会自动跳转到报错文件中行数,此时我们在报错的代码行数注释掉。
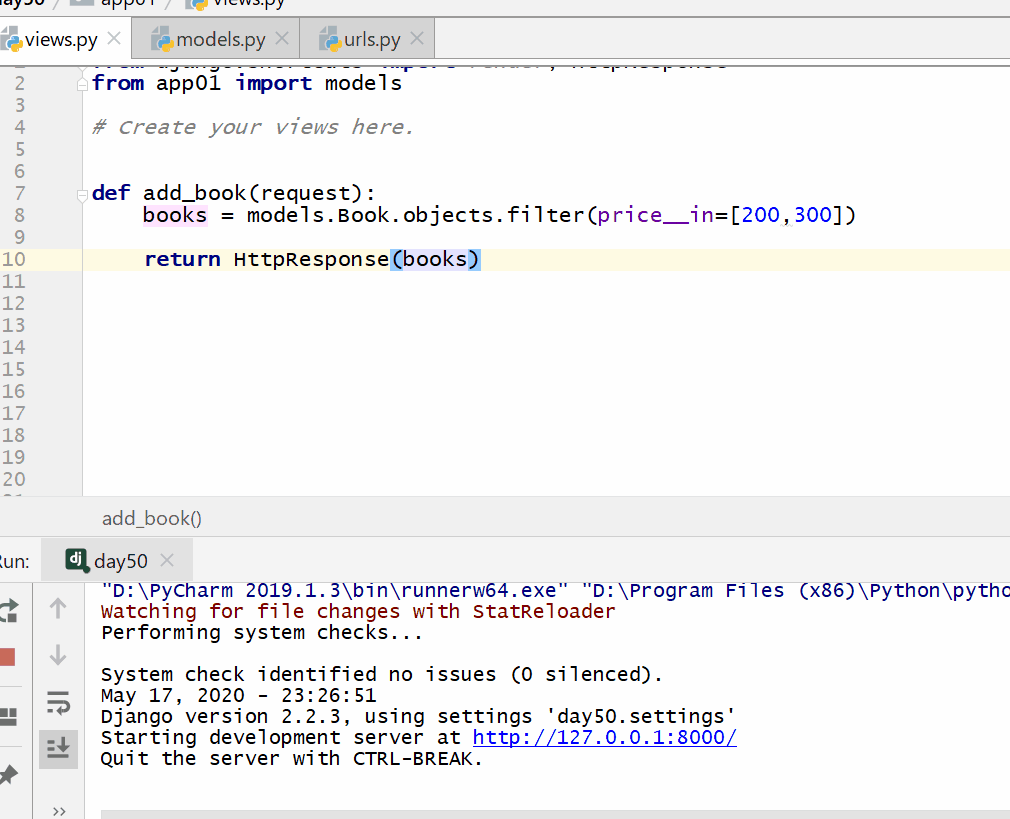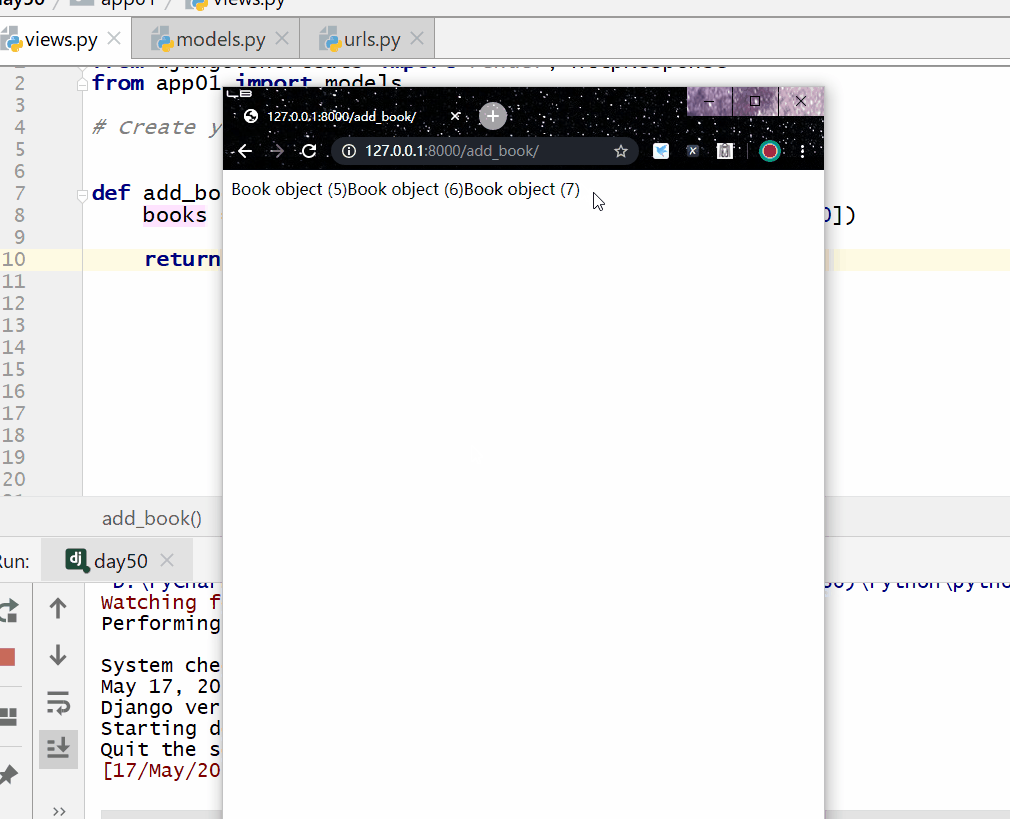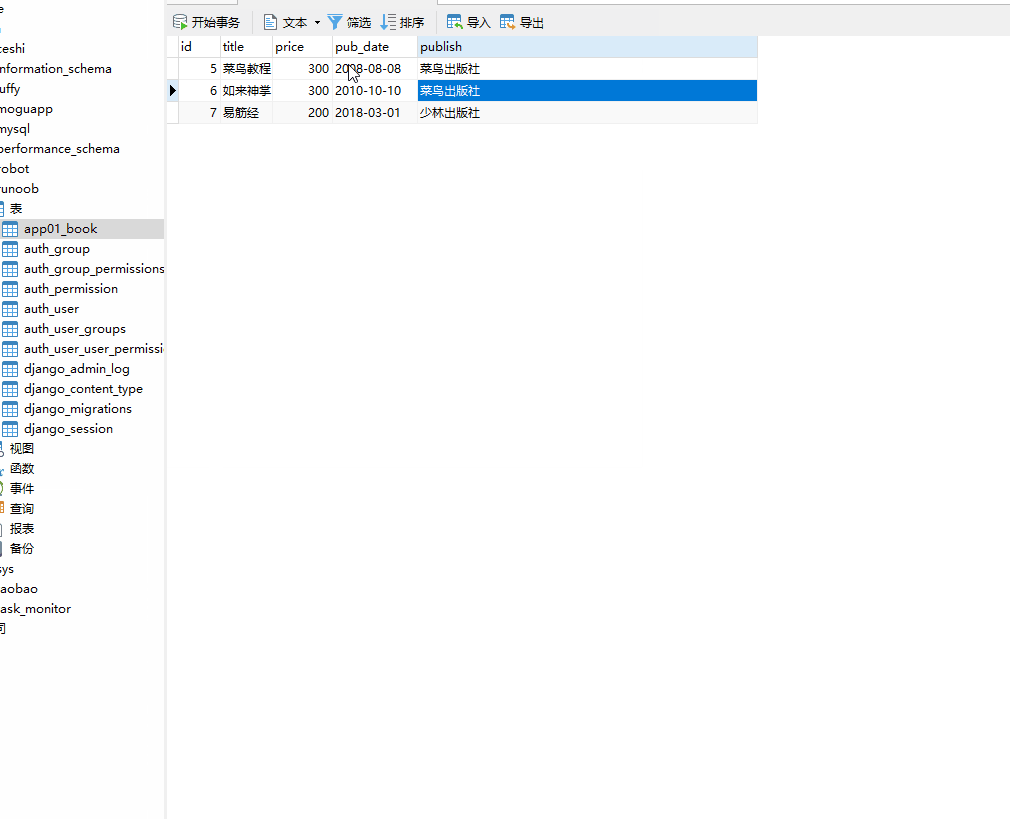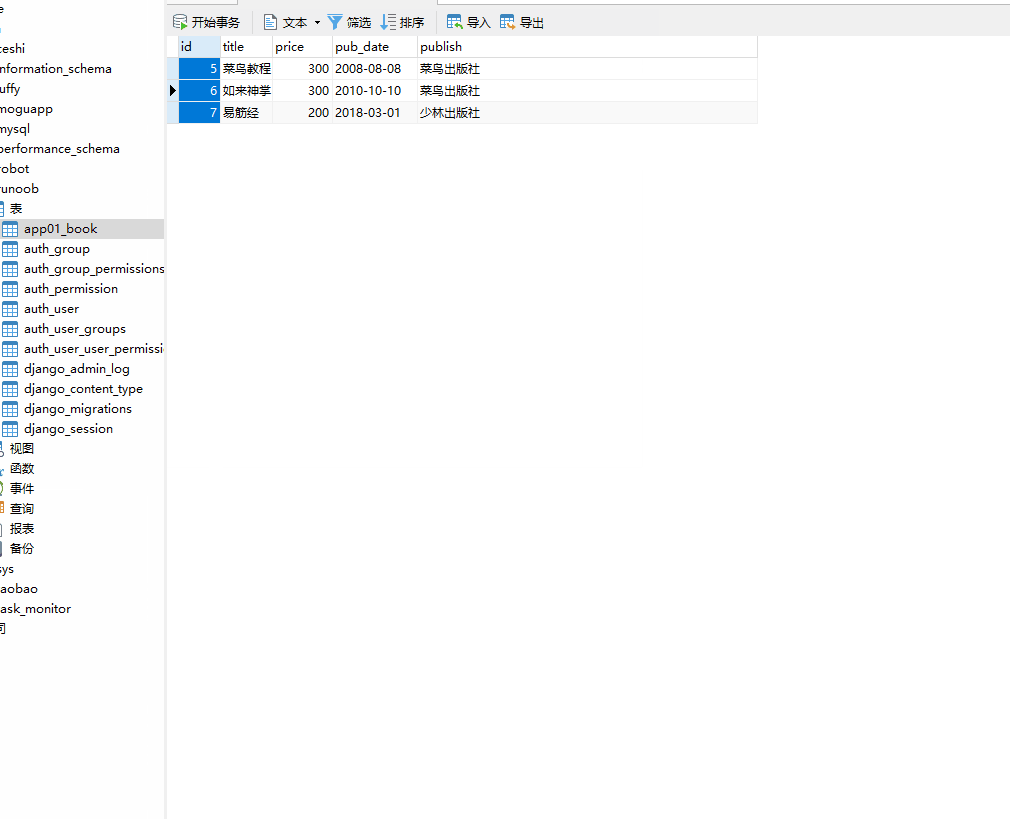
这时数据库 runoob 就会创建一个 app01_book 的表。
接下来我们在app01 项目里添加 views.py 和 models.py 文件,app01 项目目录结构:
app01 |-- app01 | |-- __init__.py | |-- __pycache__ | |-- asgi.py | |-- migrations | |-- models.py | |-- settings.py | |-- urls.py | |-- views.py | `-- wsgi.py
规则配置:
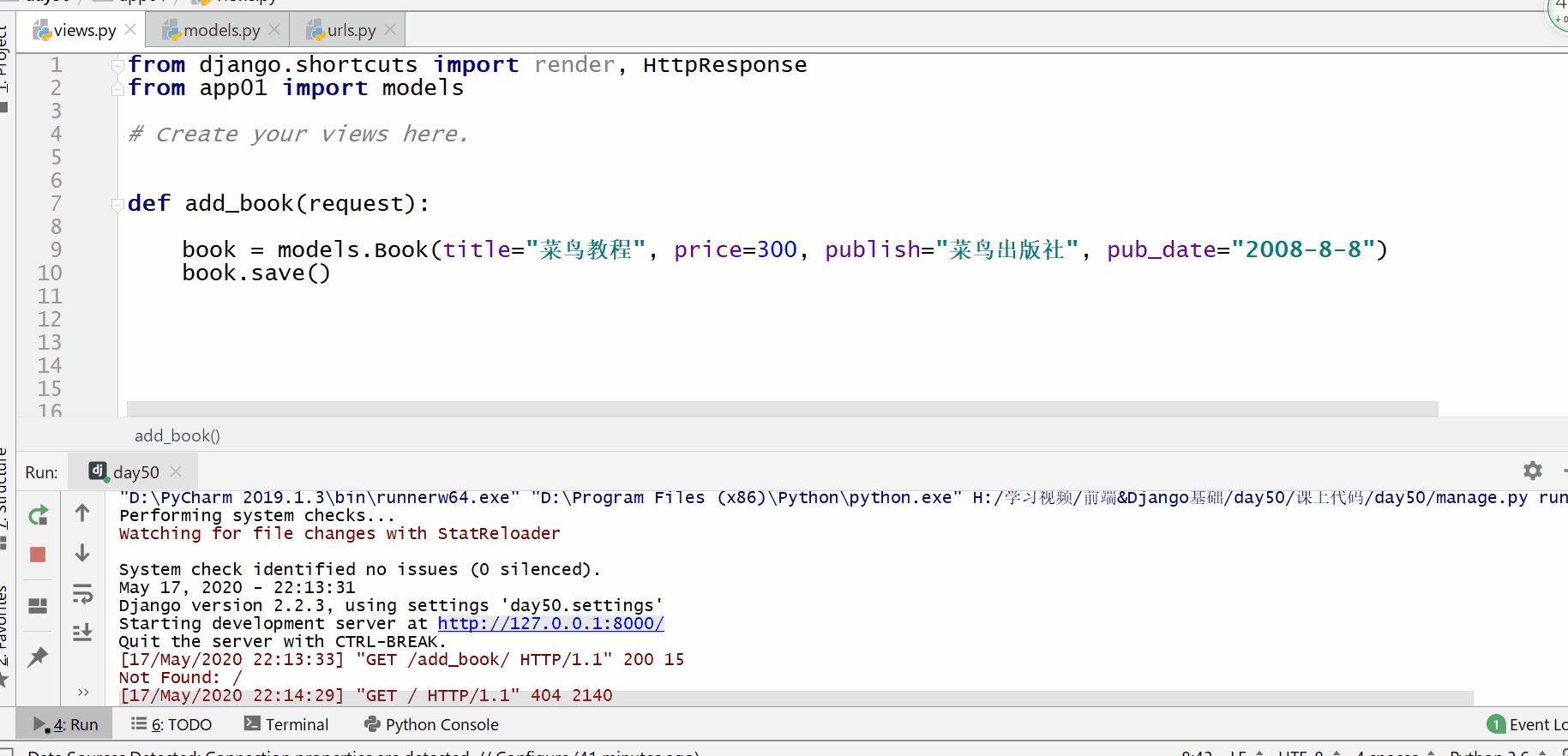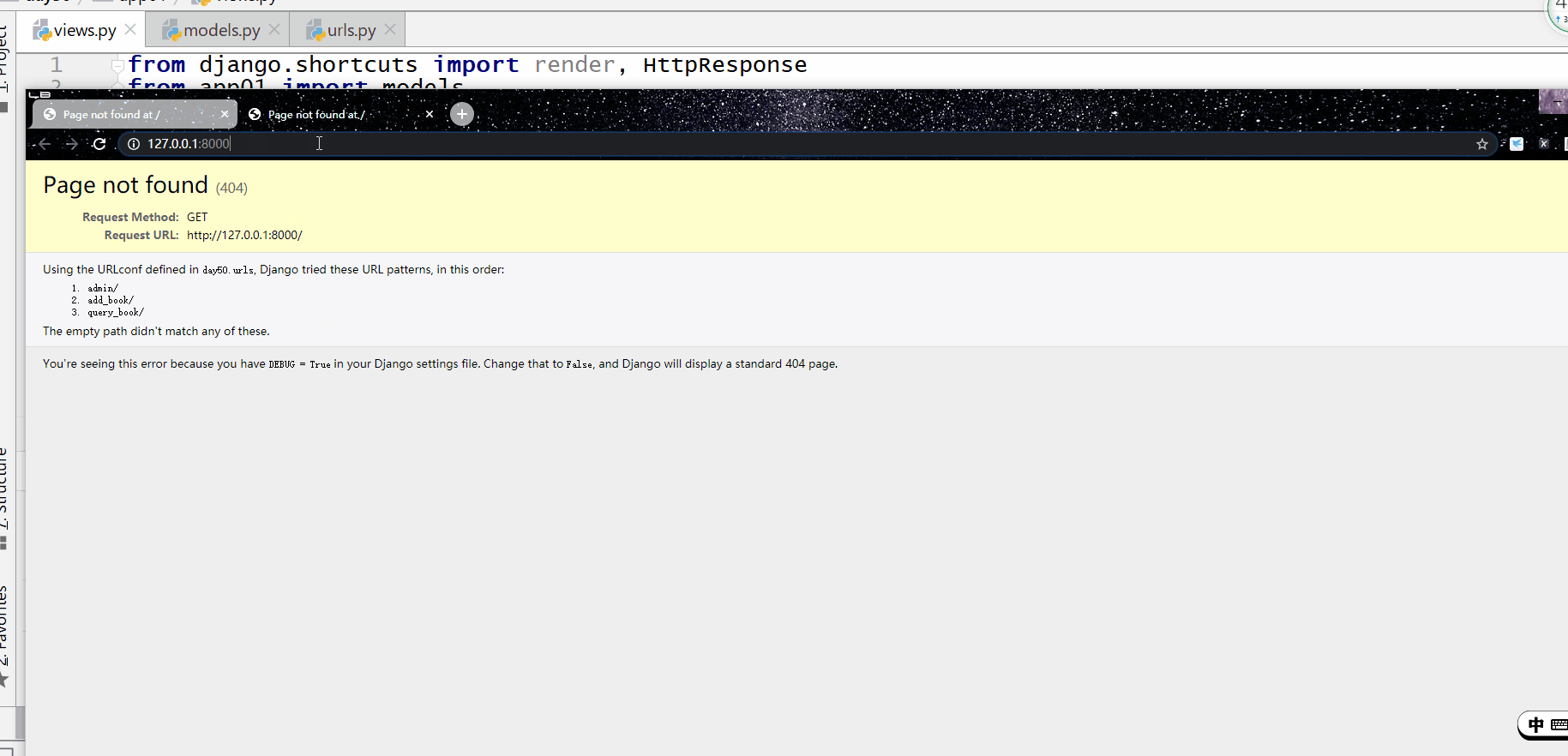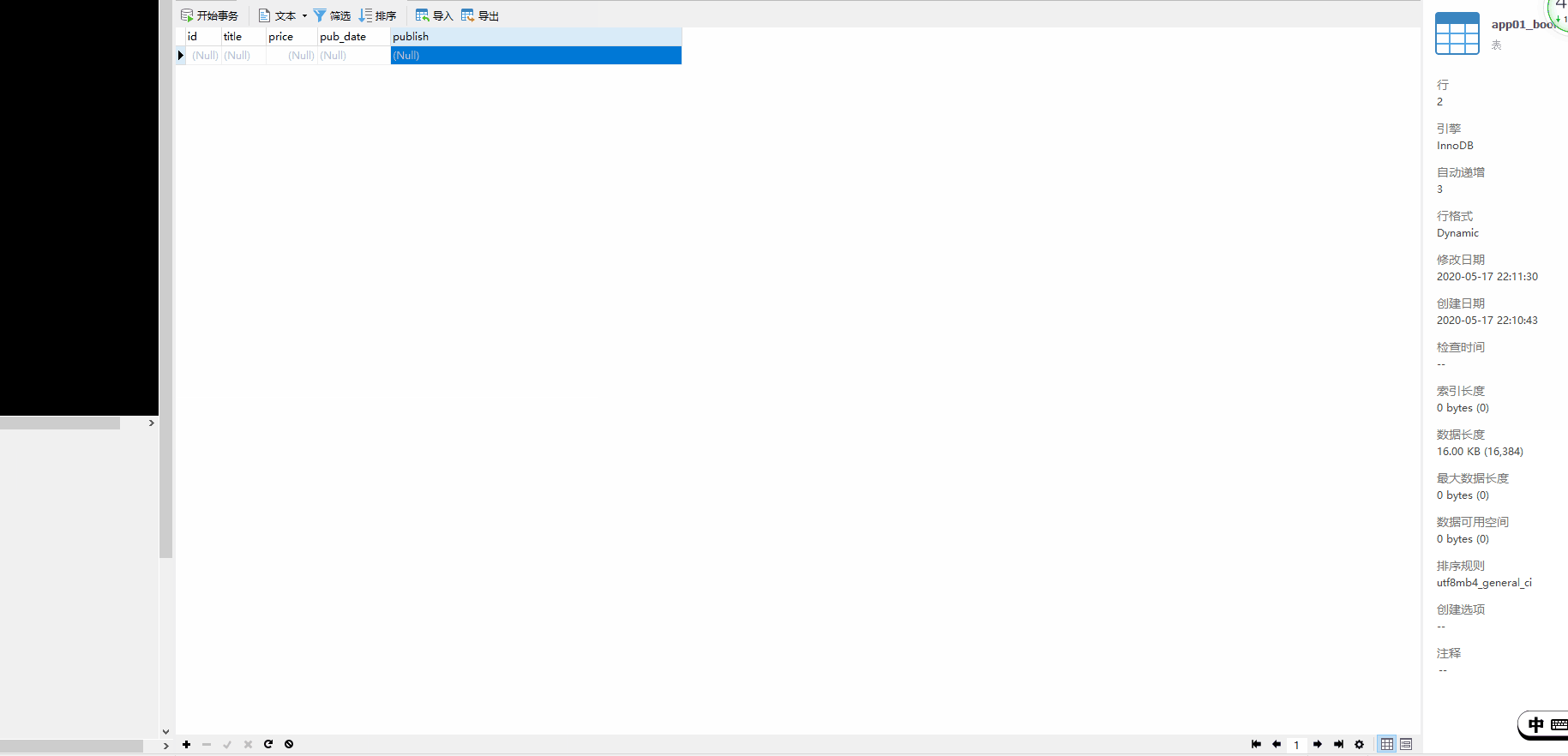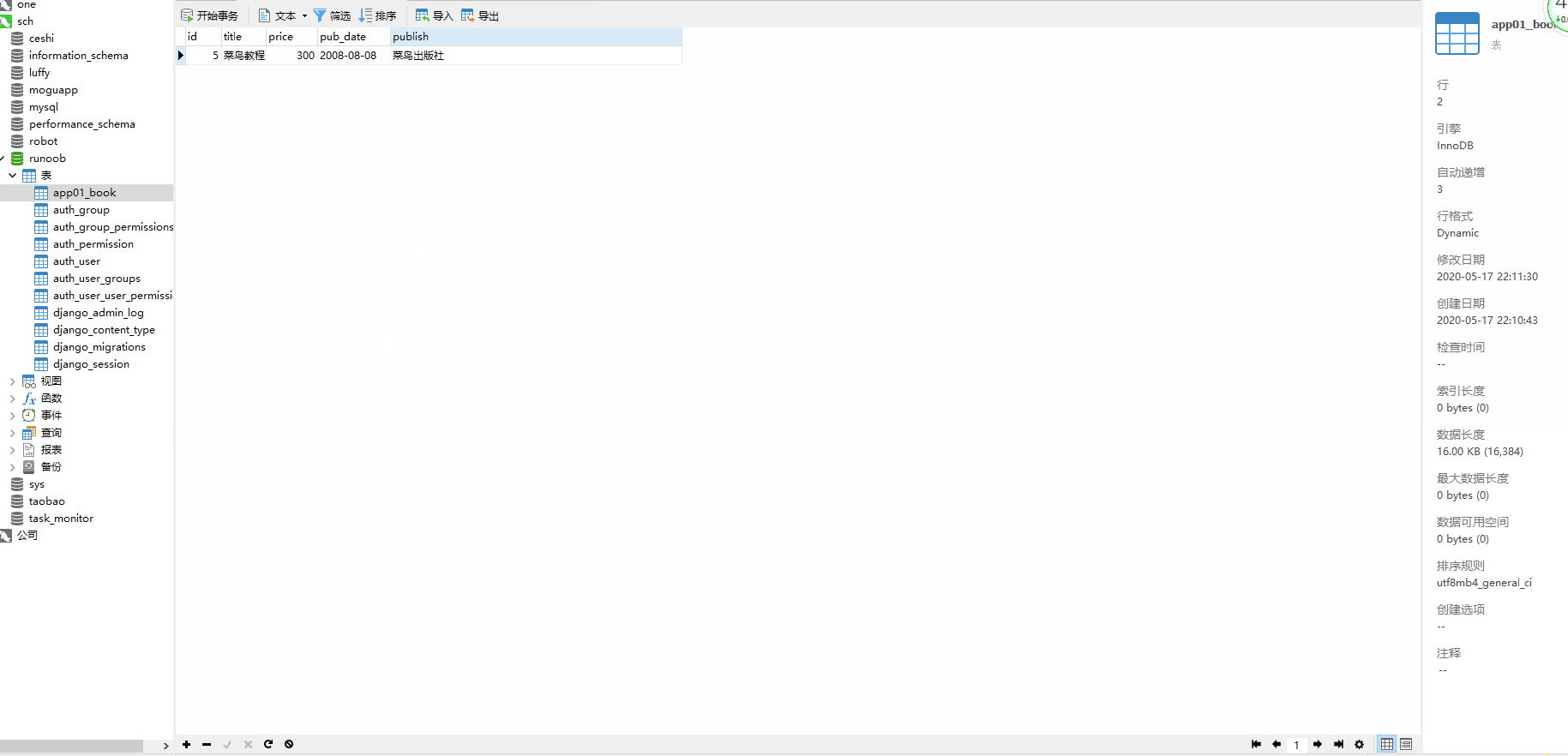
方式一:模型类实例化对象
需从 app 目录引入 models.py 文件:
from app 目录 import models
并且实例化对象后要执行 对象.save() 才能在数据库中新增成功。
方式二:通过 ORM 提供的 objects 提供的方法 create 来实现(推荐)
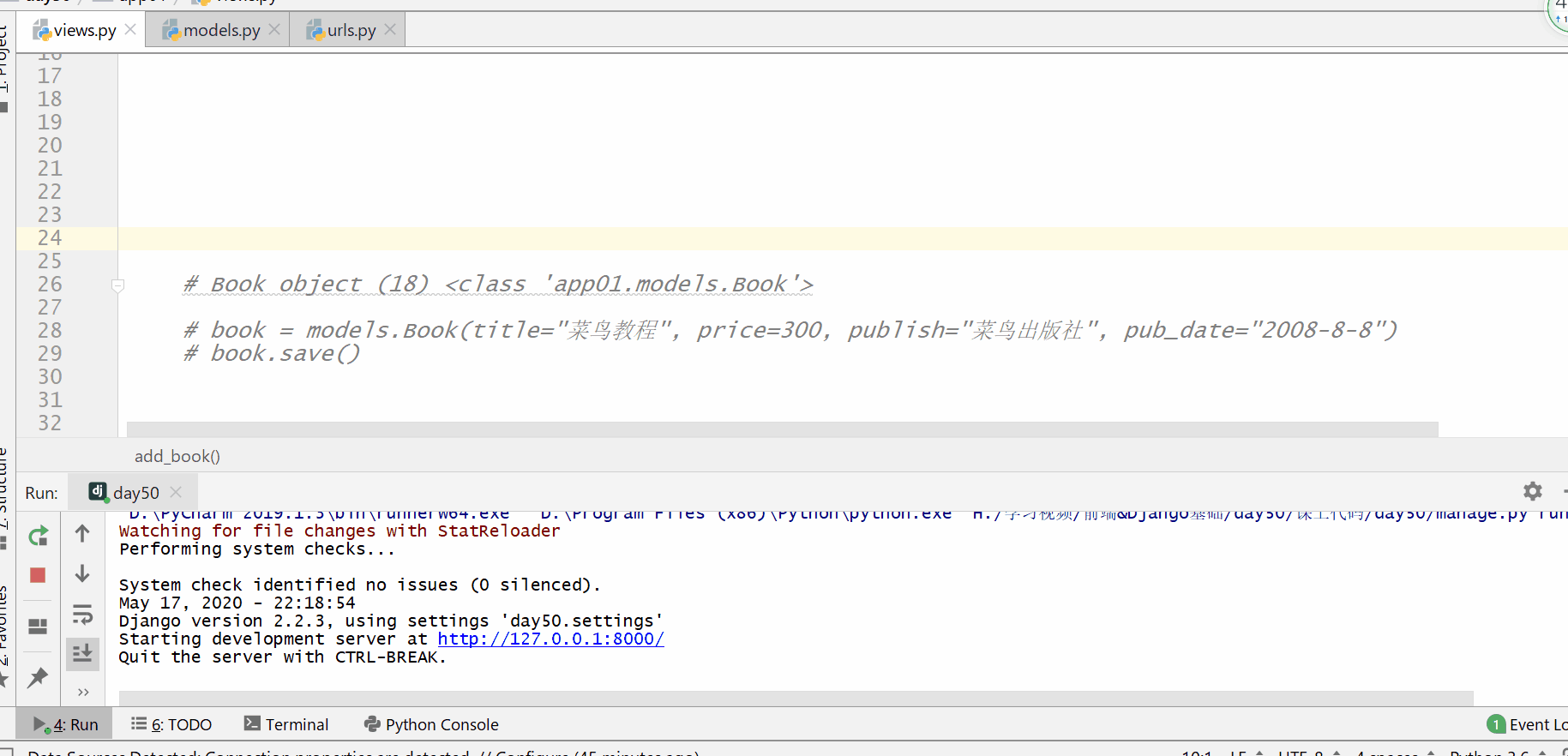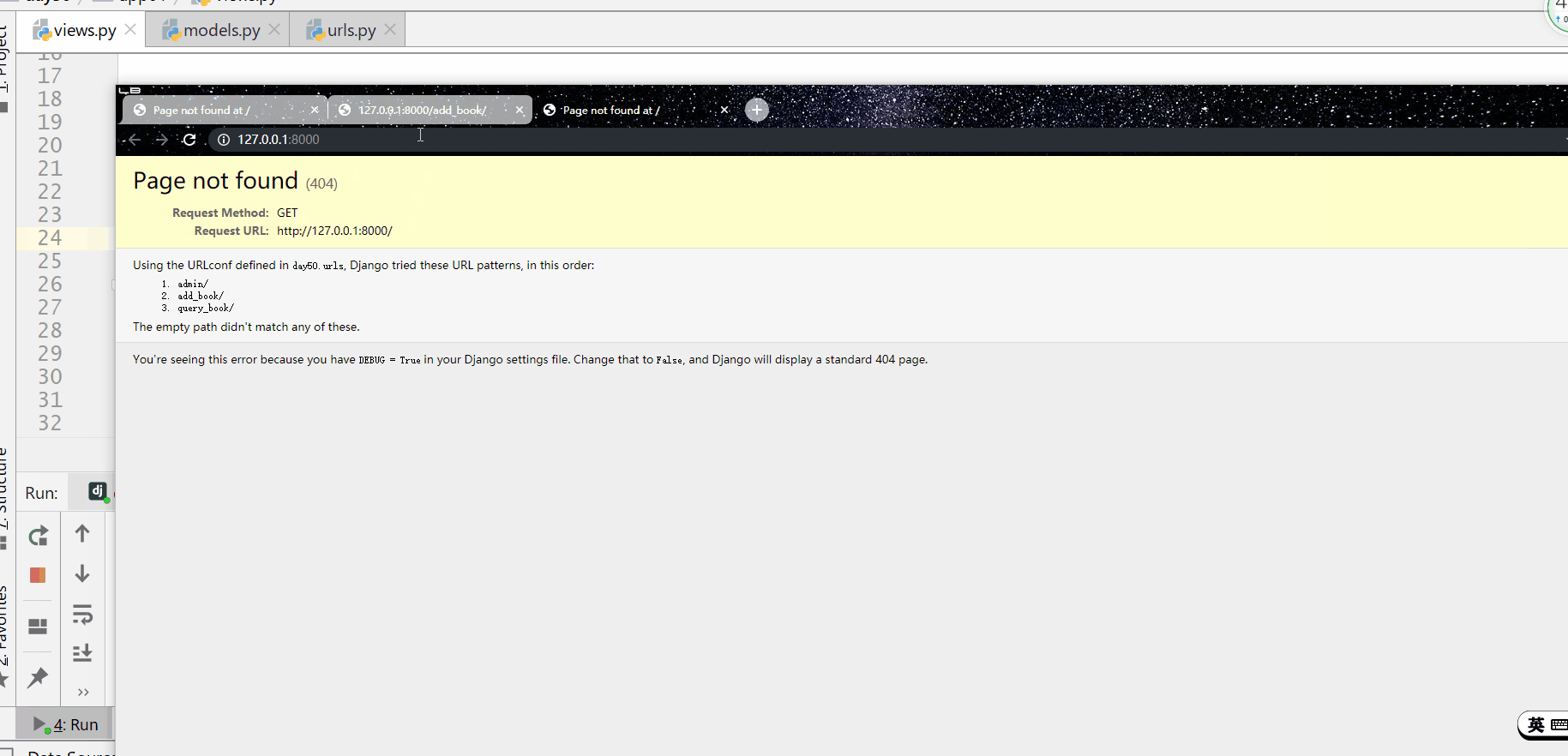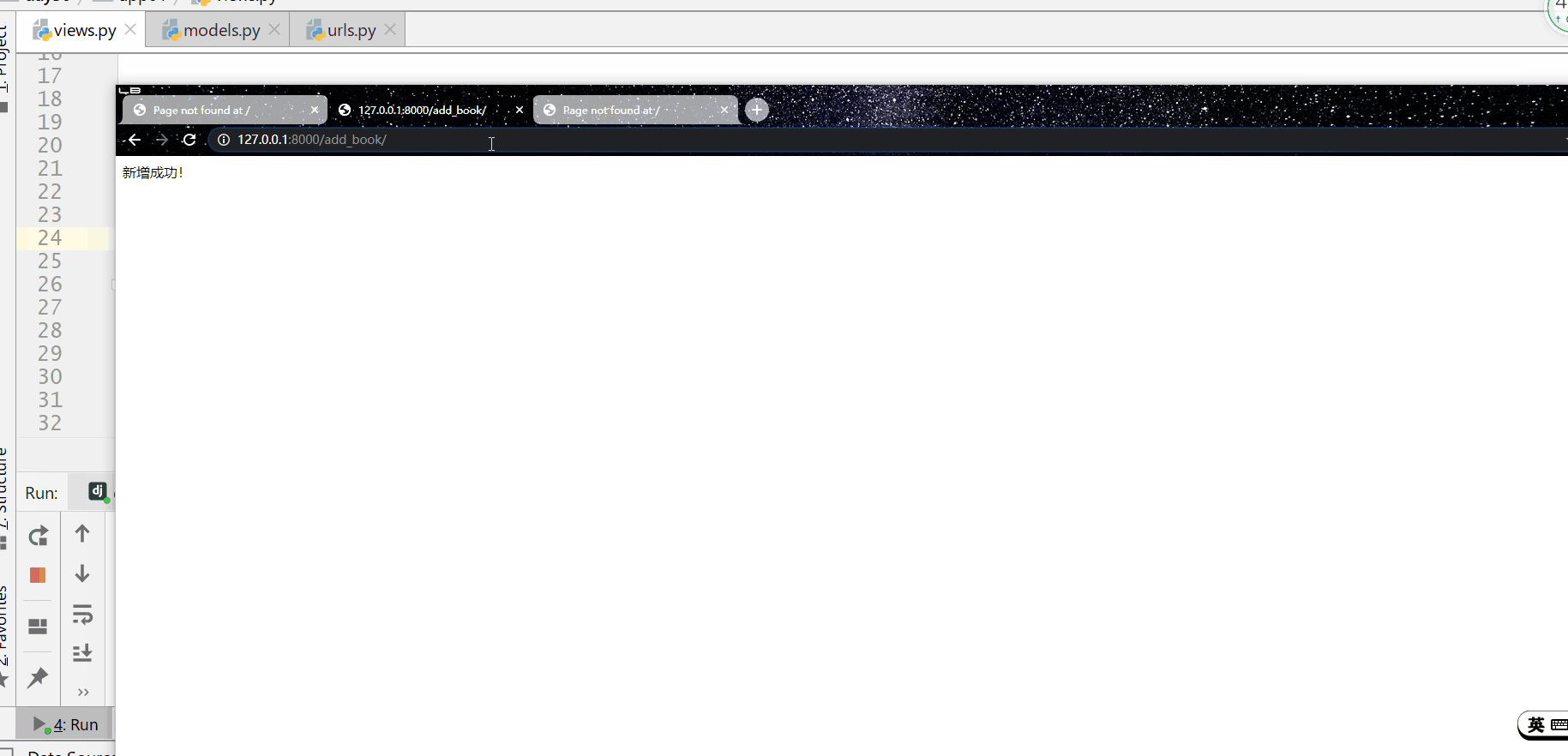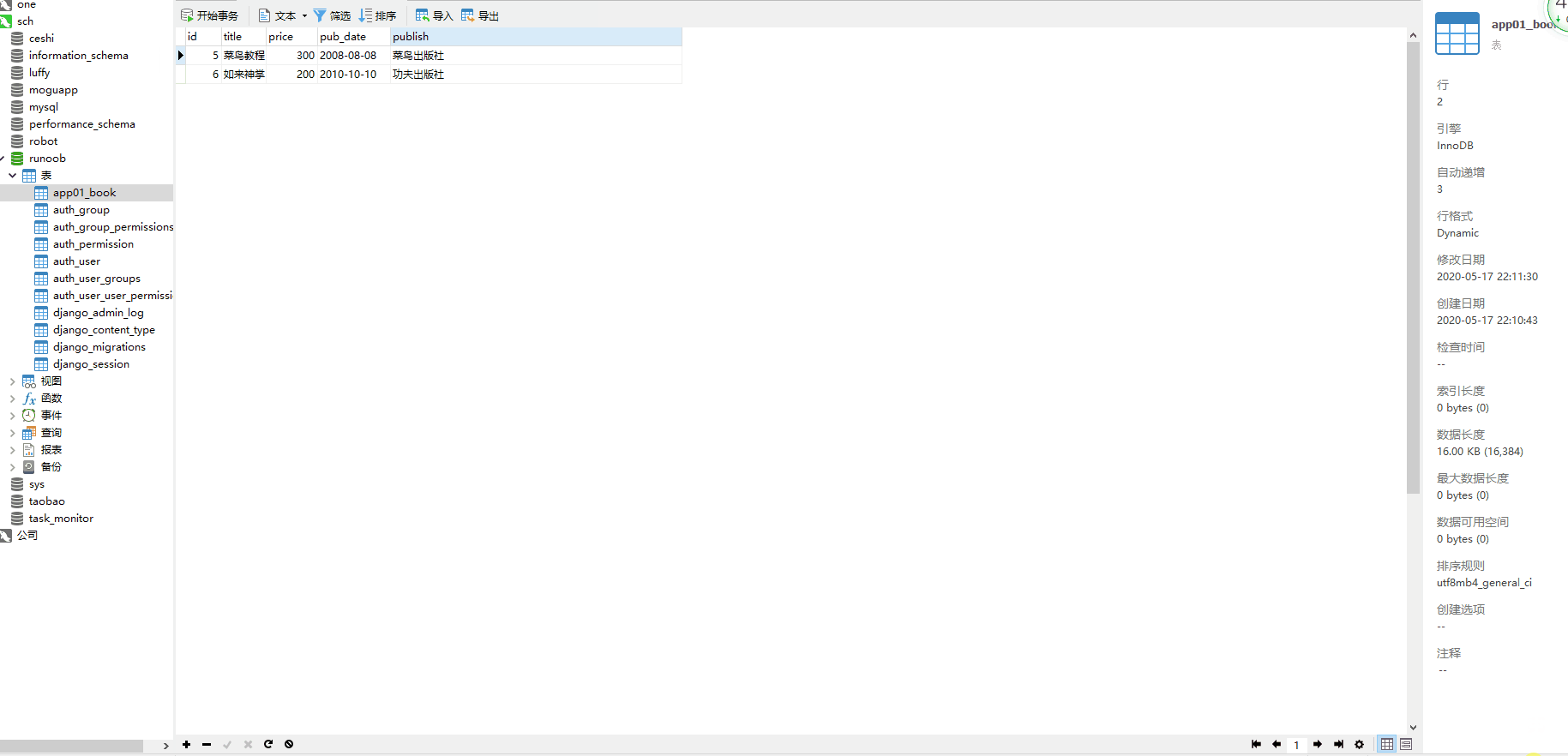
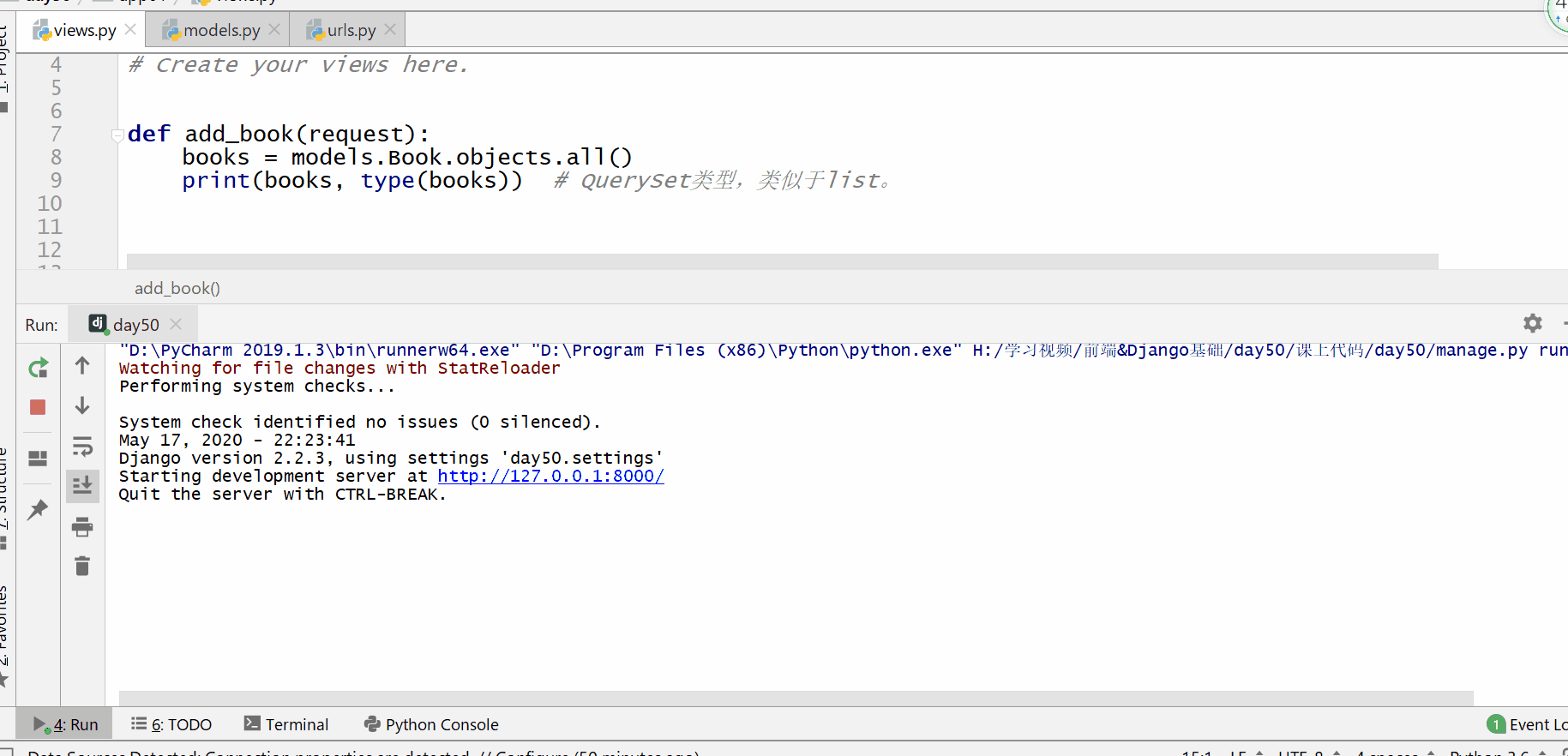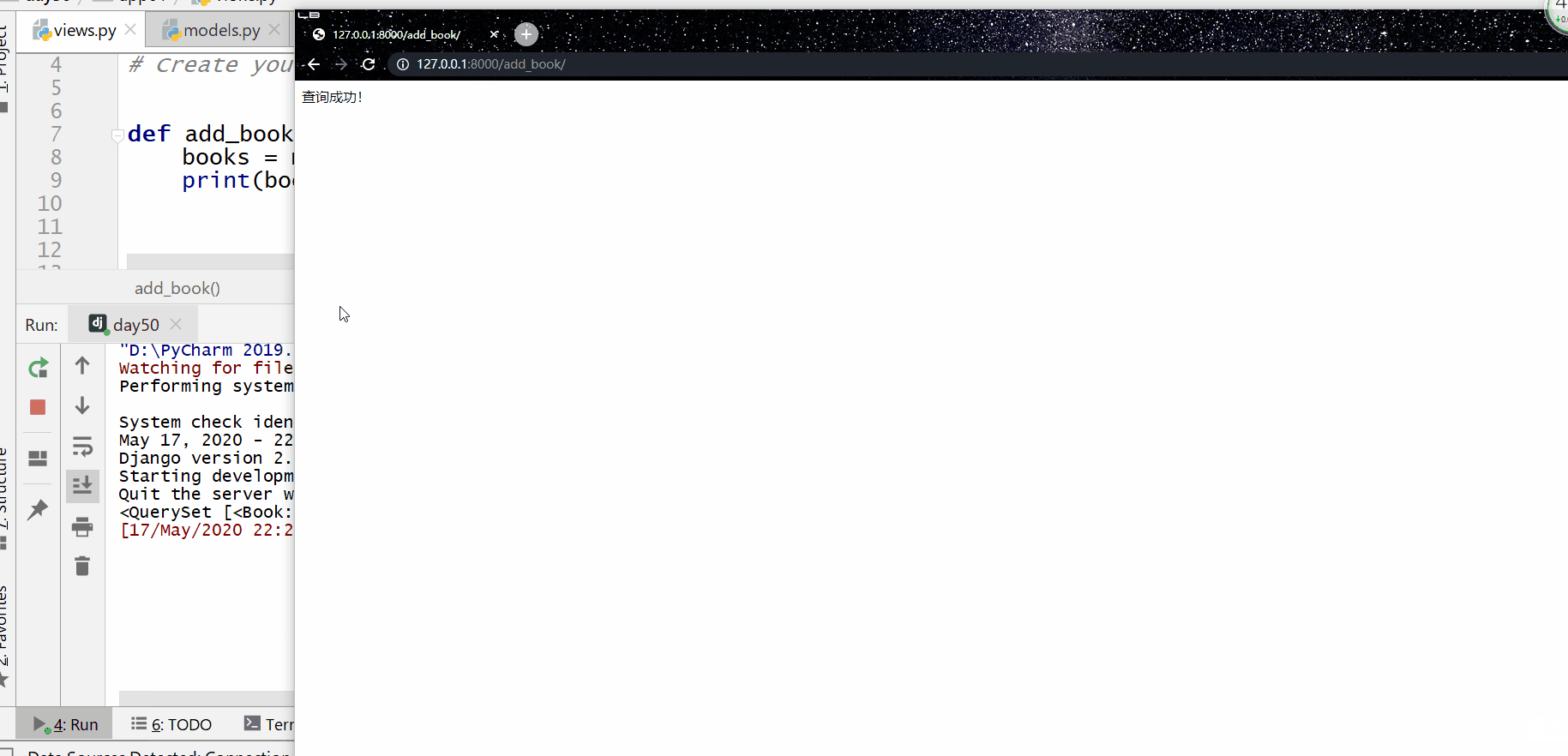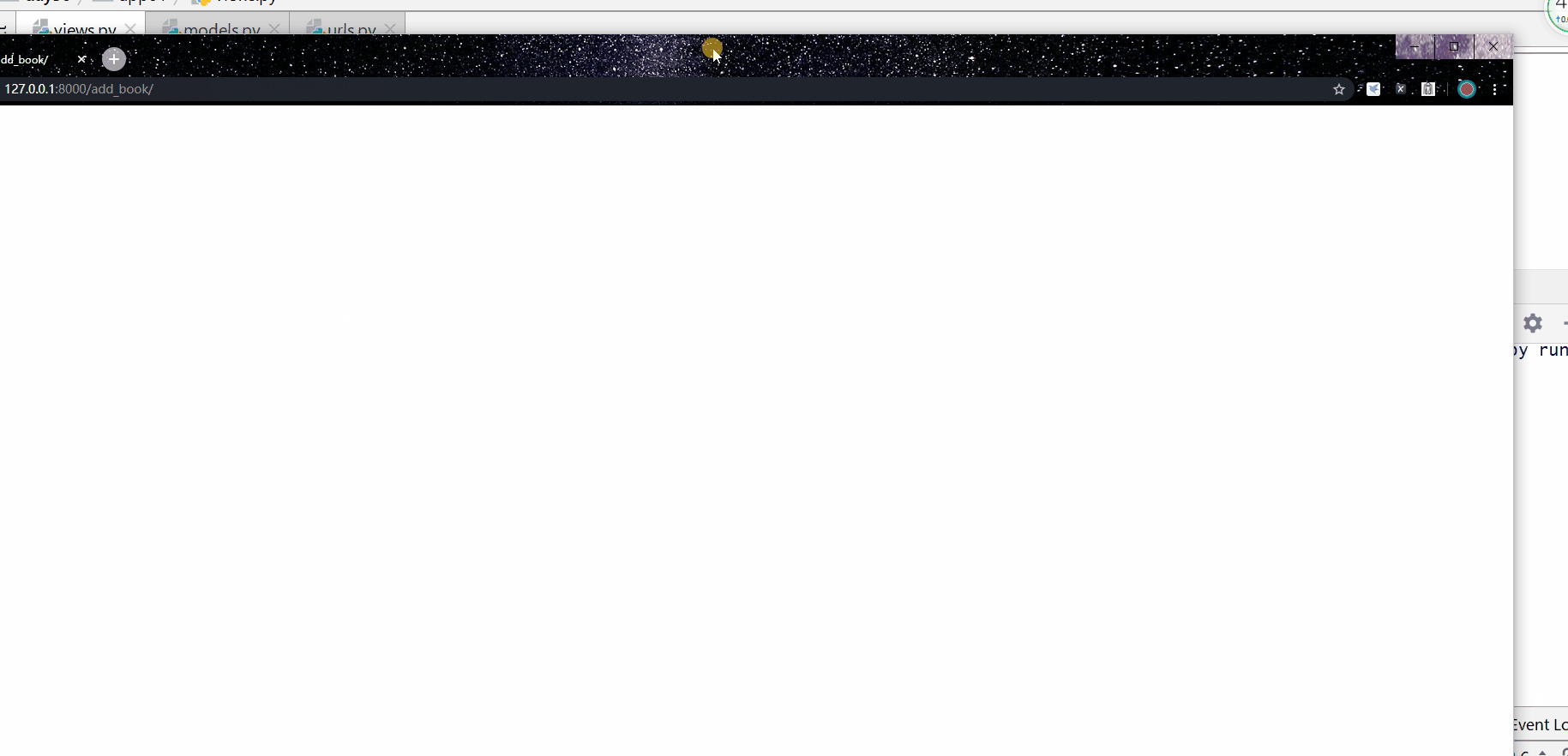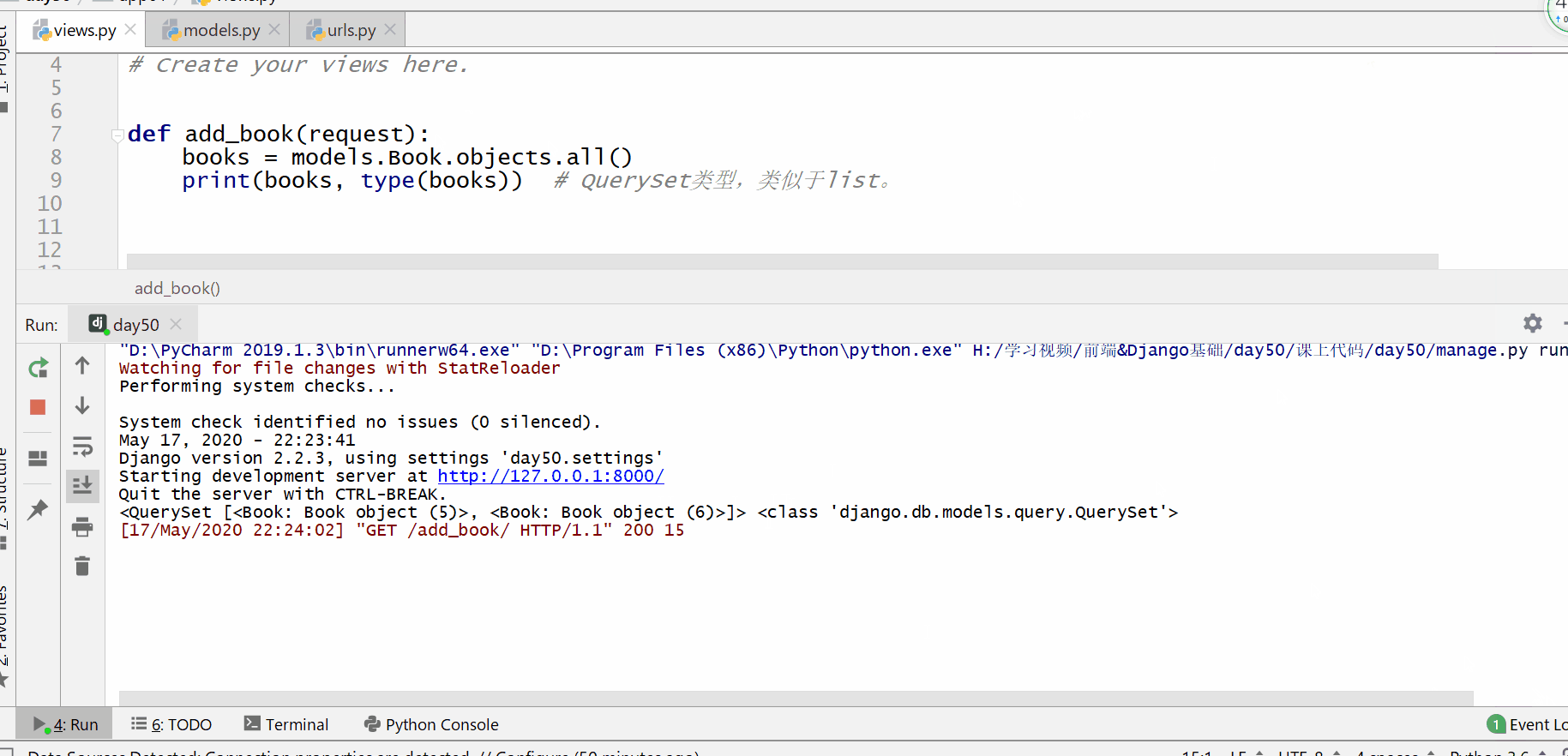
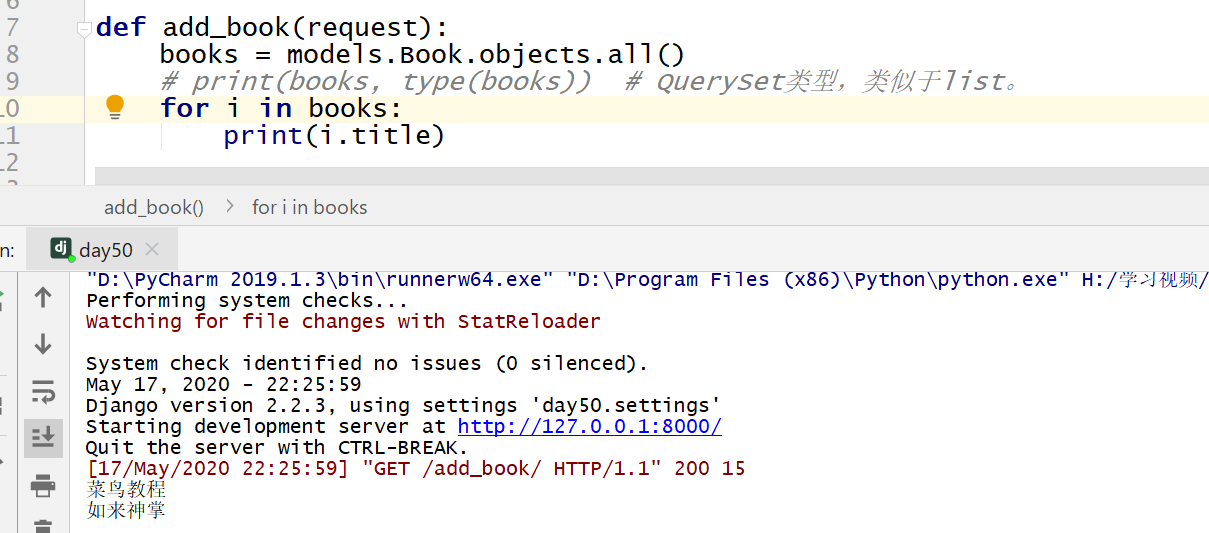
使用 all() 方法来查询所有内容。
返回的是 QuerySet 类型数据,类似于 list,里面放的是一个个模型类的对象,可用索引下标取出模型类的对象。
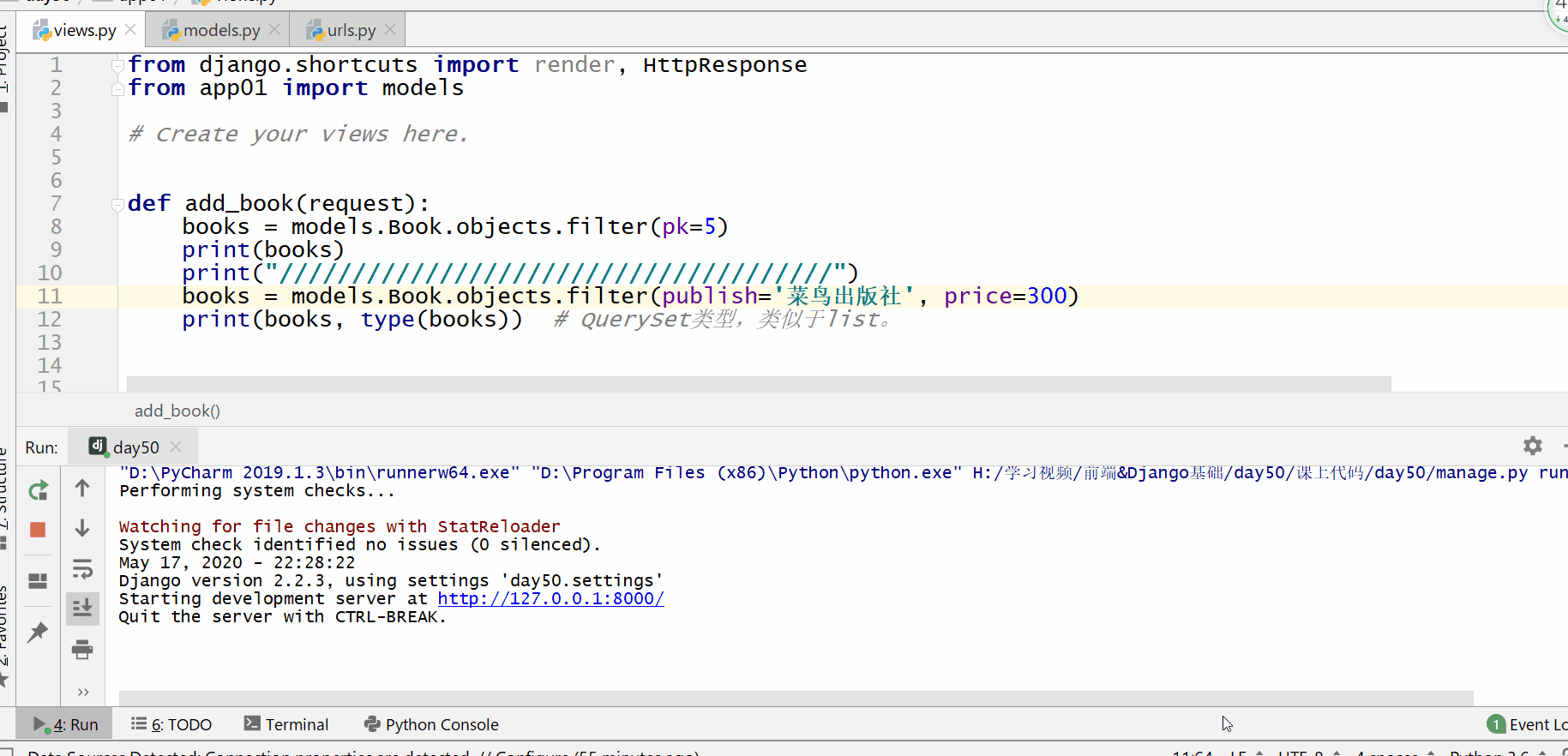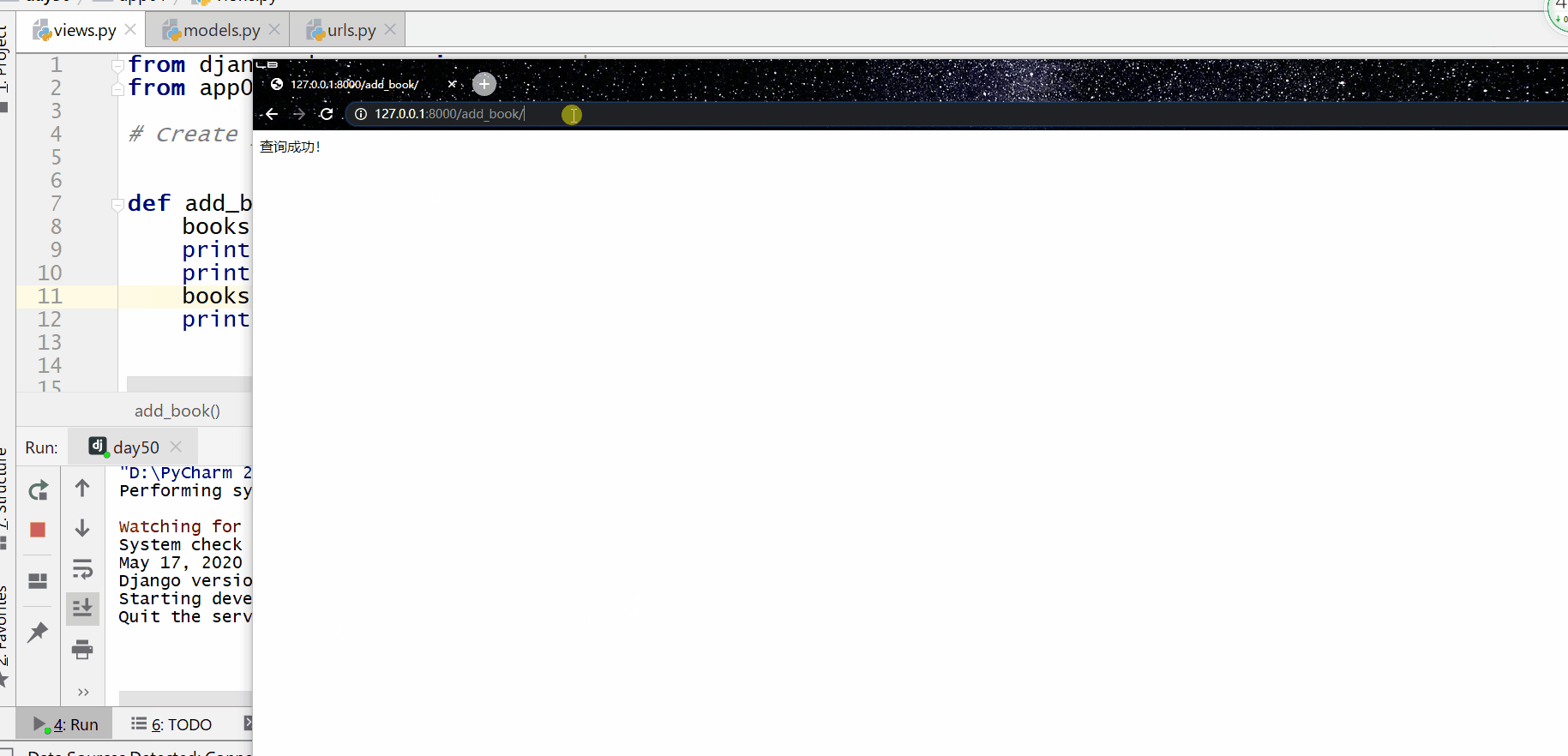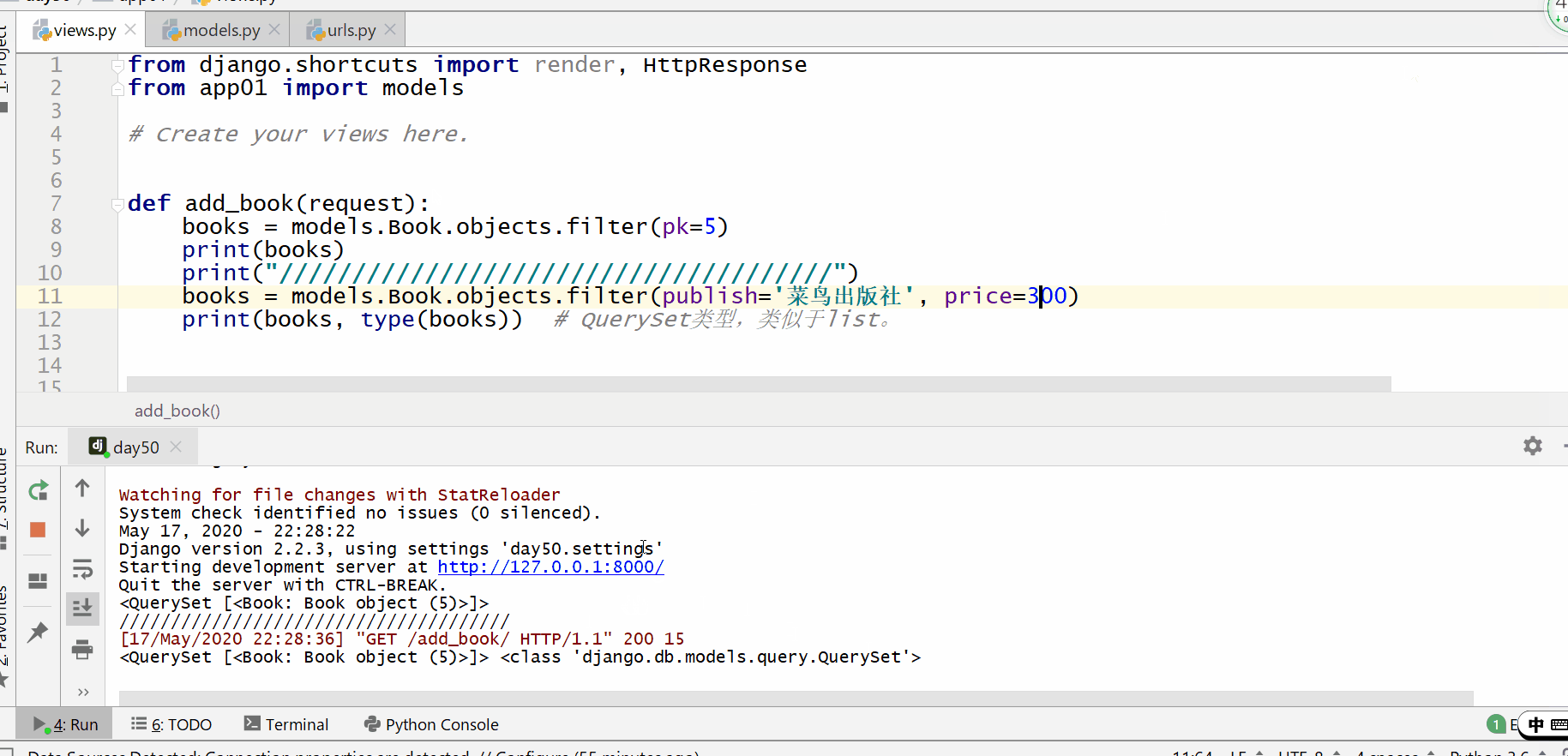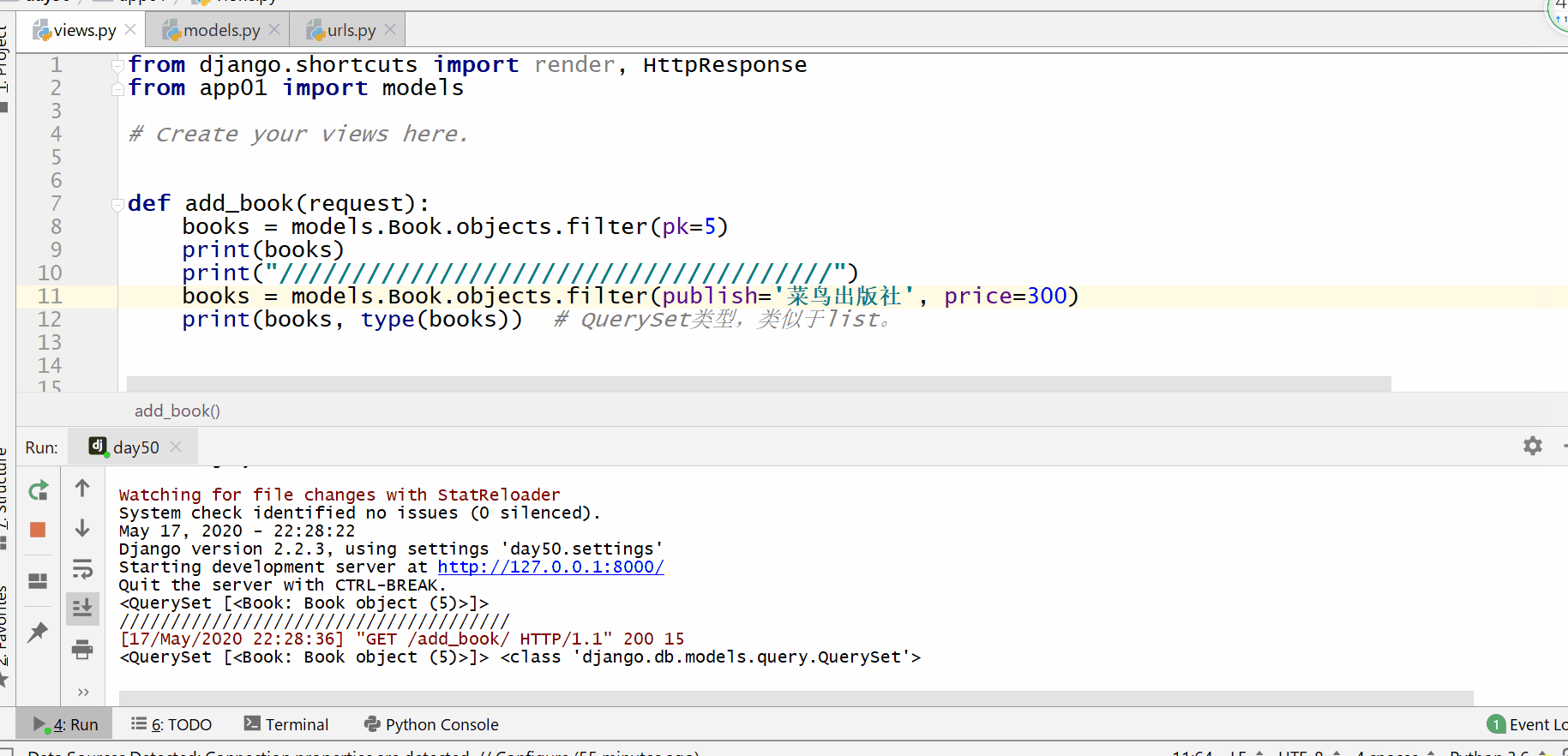
filter() 方法用于查询符合条件的数据。
返回的是 QuerySet 类型数据,类似于 list,里面放的是满足条件的模型类的对象,可用索引下标取出模型类的对象。
pk=3 的意思是主键 primary key=3,相当于 id=3。
因为 id 在 pycharm 里有特殊含义,是看内存地址的内置函数 id(),因此用 pk。
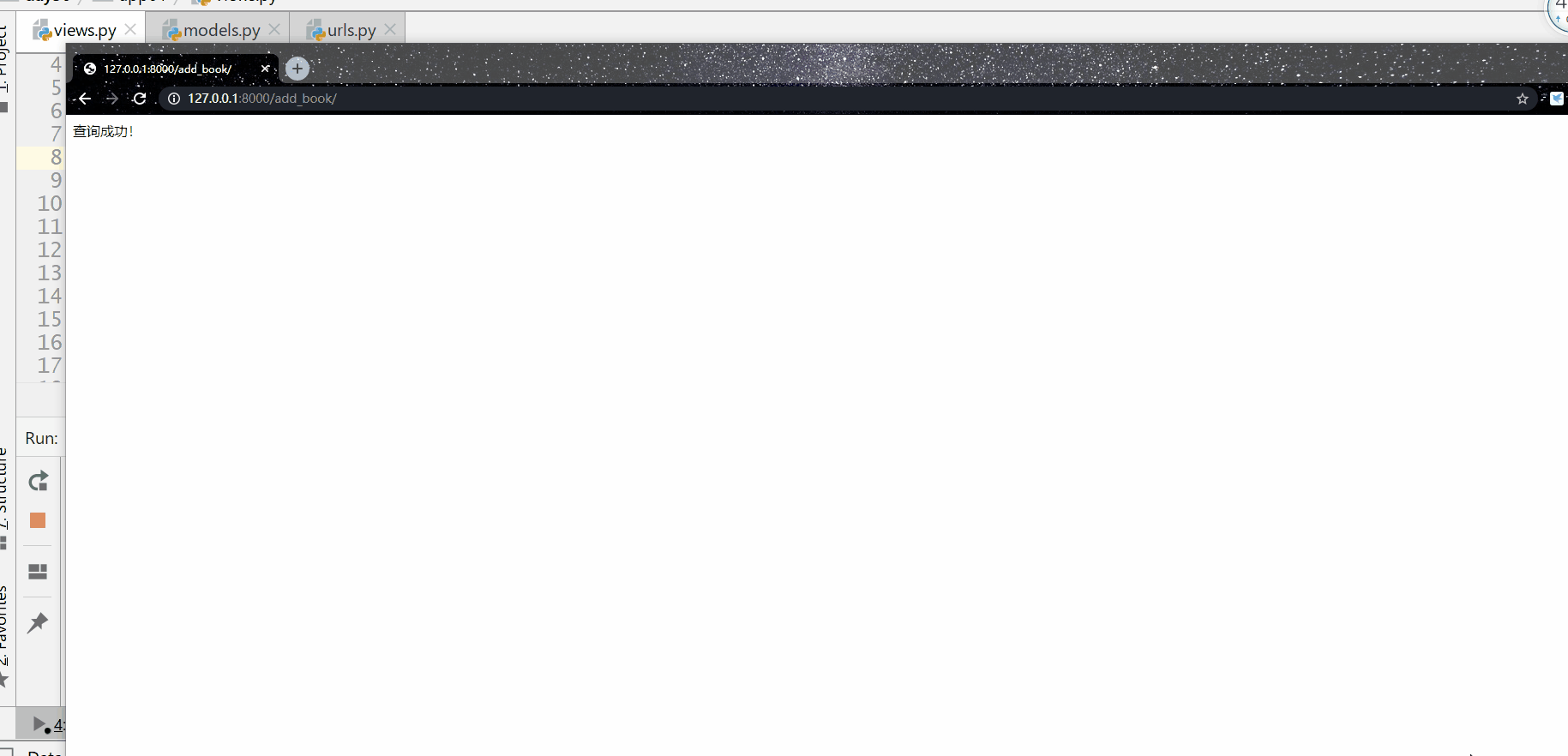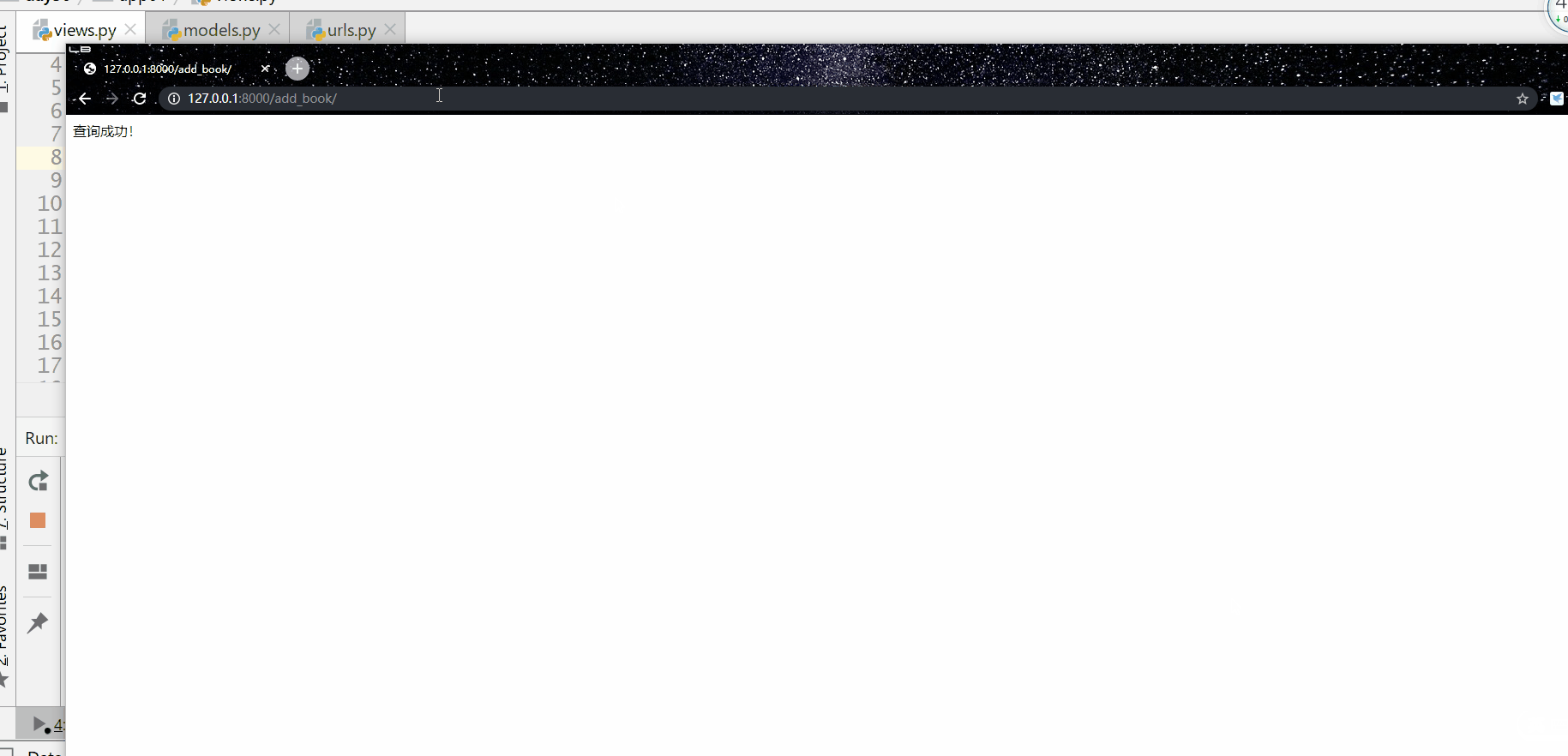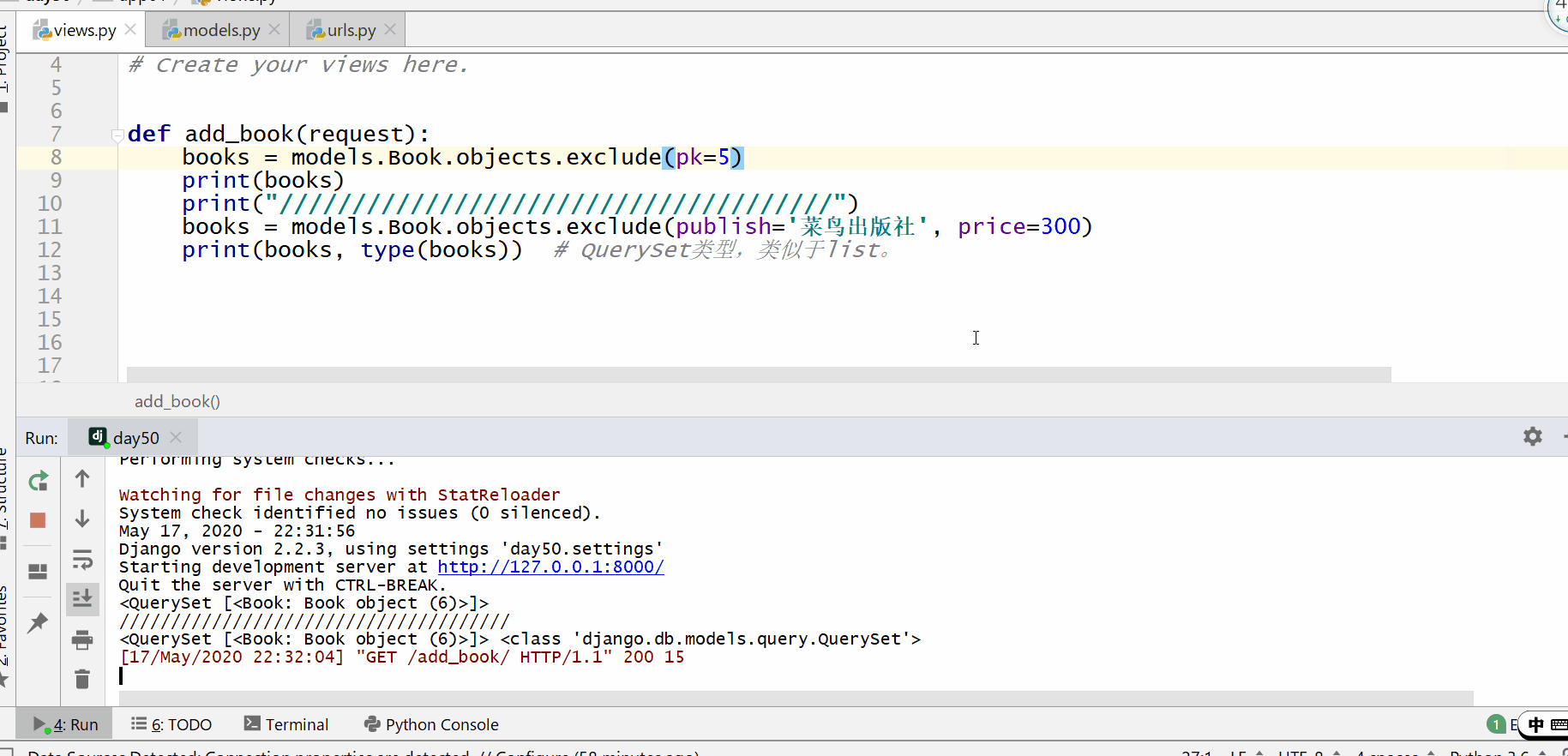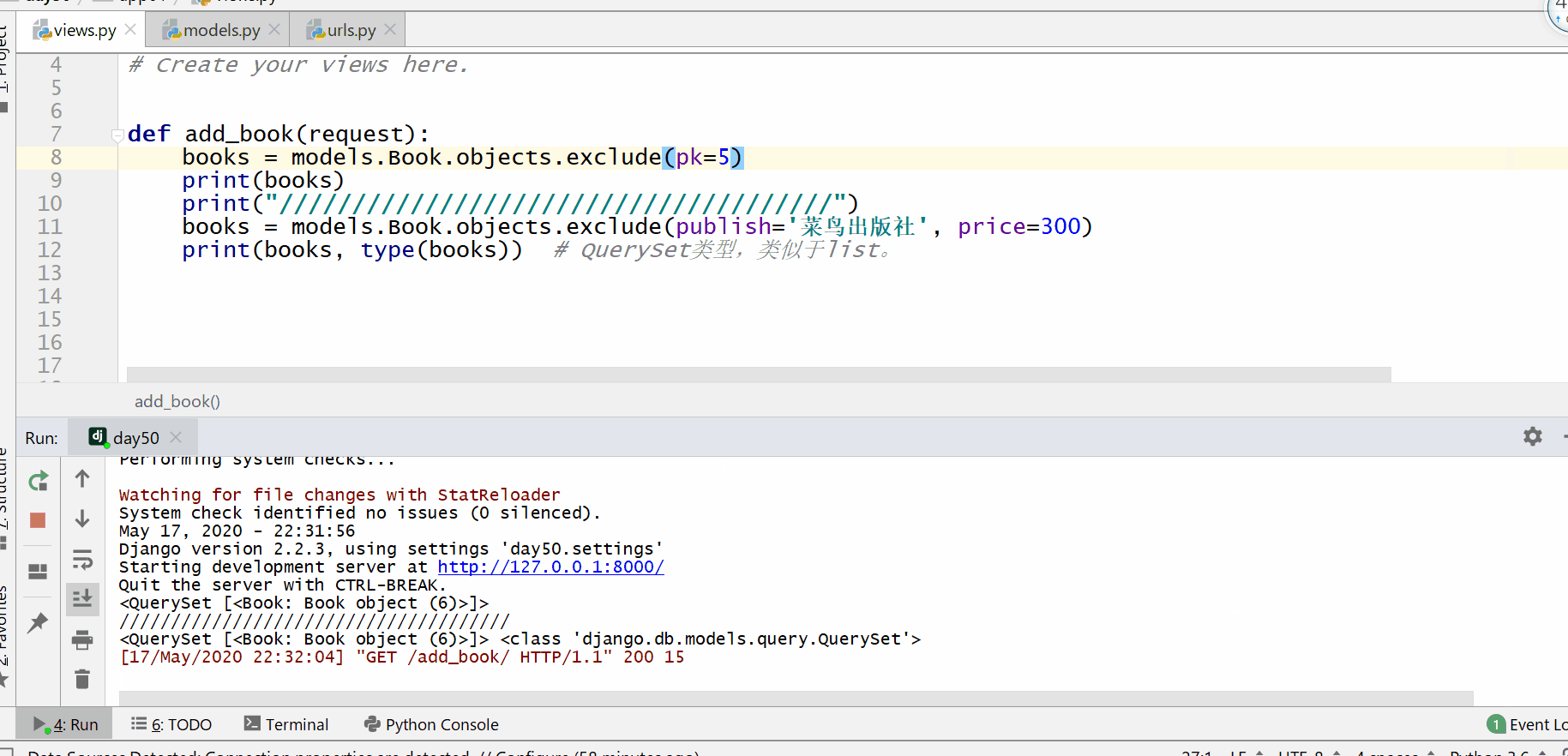
exclude() 方法用于查询不符合条件的数据。
返回的是 QuerySet 类型数据,类似于 list,里面放的是不满足条件的模型类的对象,可用索引下标取出模型类的对象。
get() 方法用于查询符合条件的返回模型类的对象符合条件的对象只能为一个,如果符合筛选条件的对象超过了一个或者没有一个都会抛出错误。
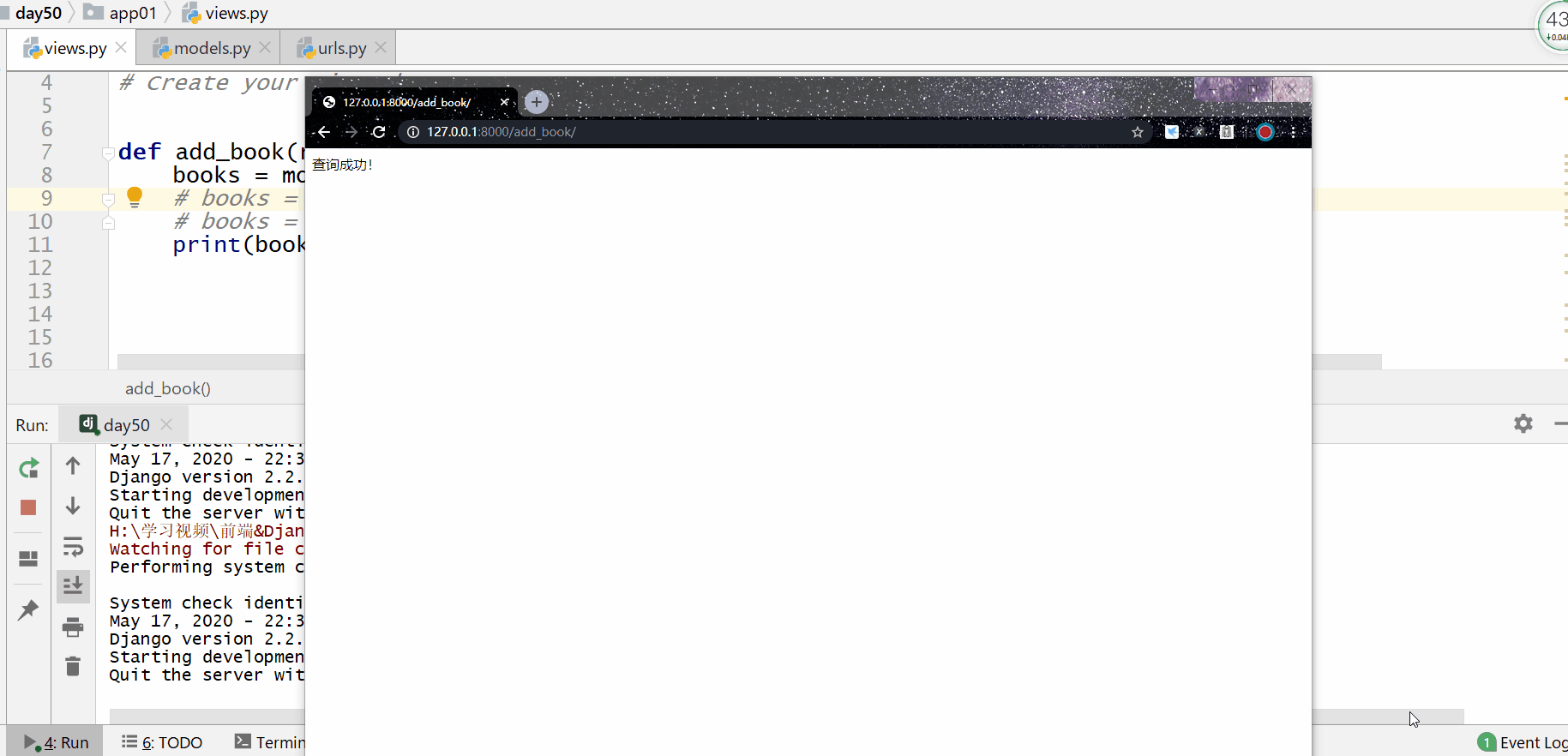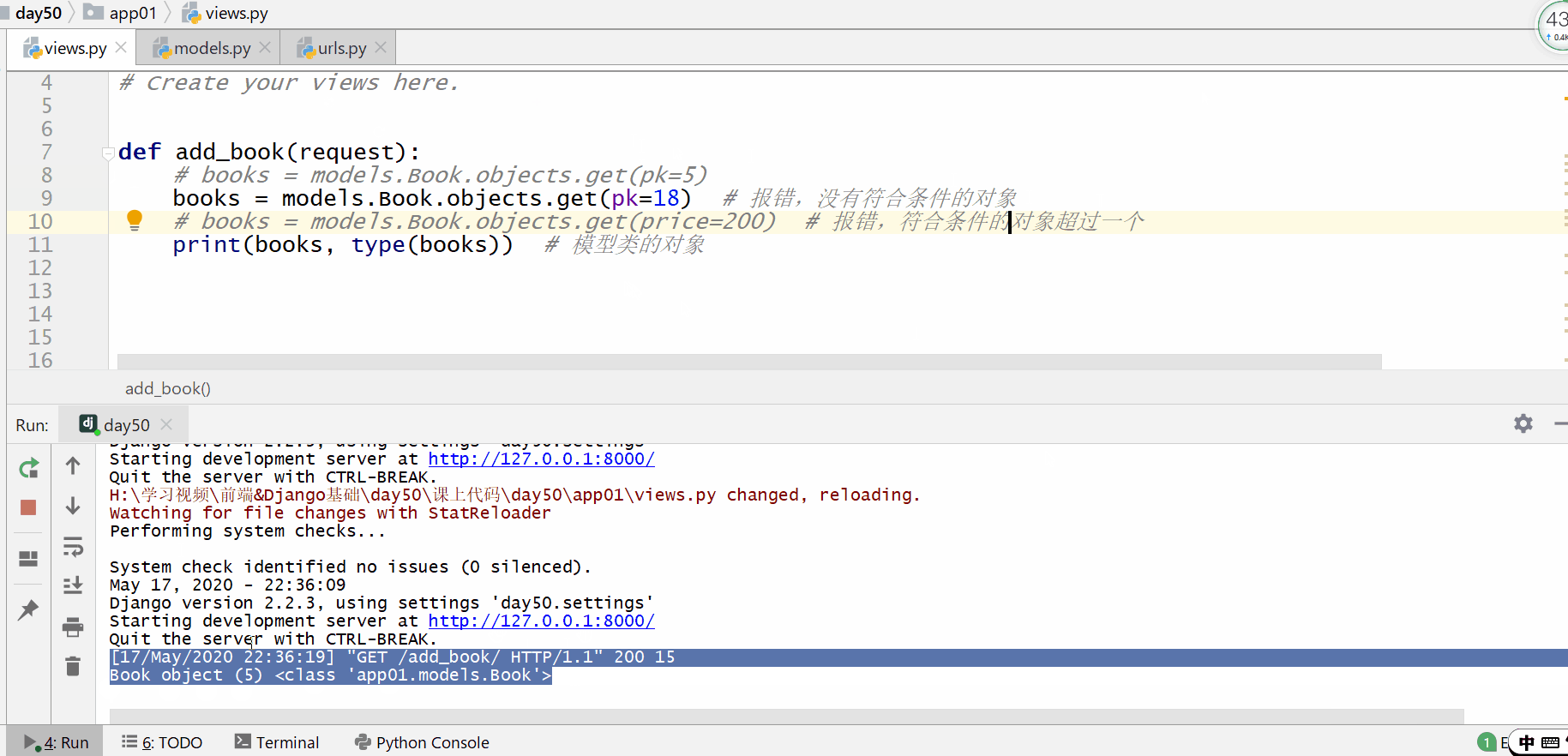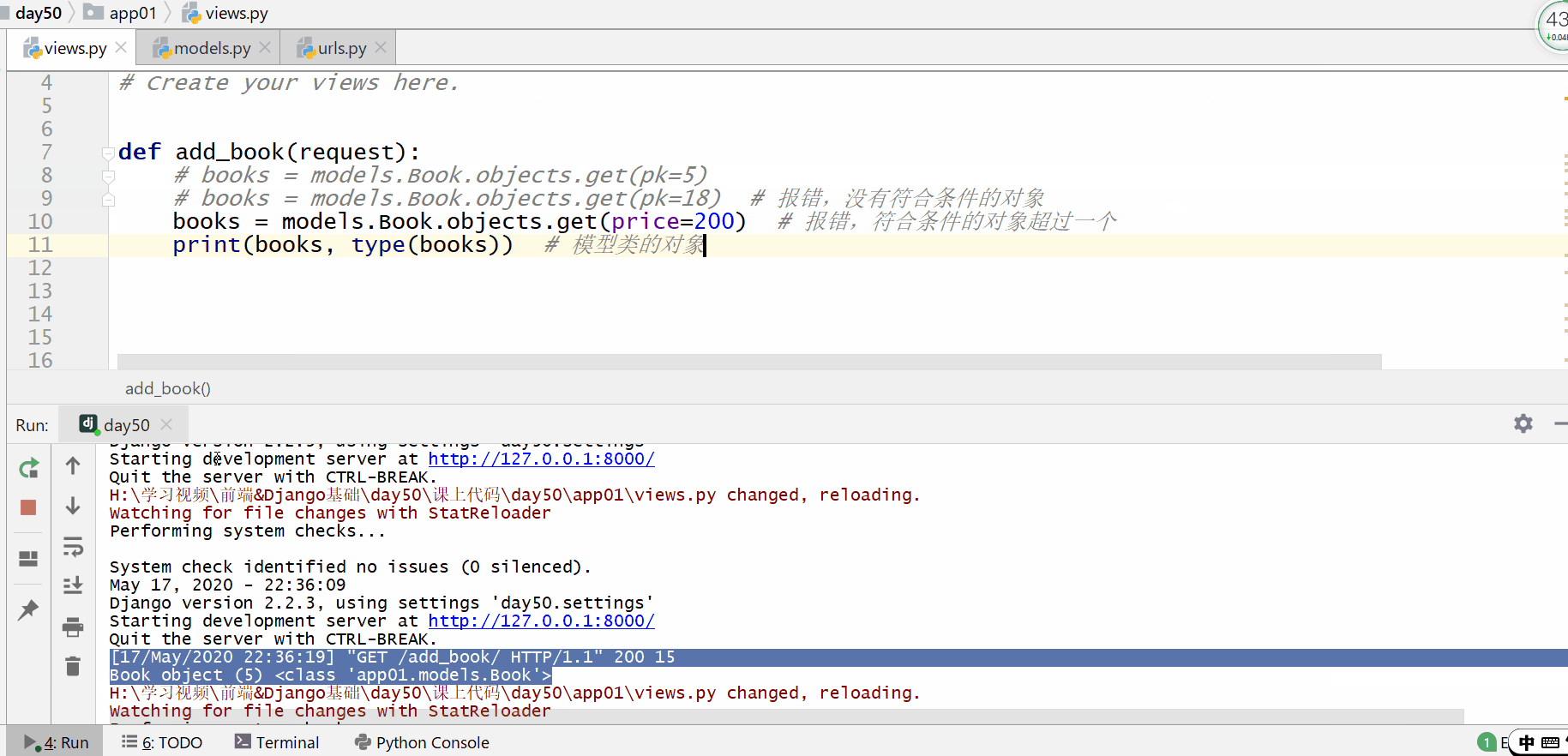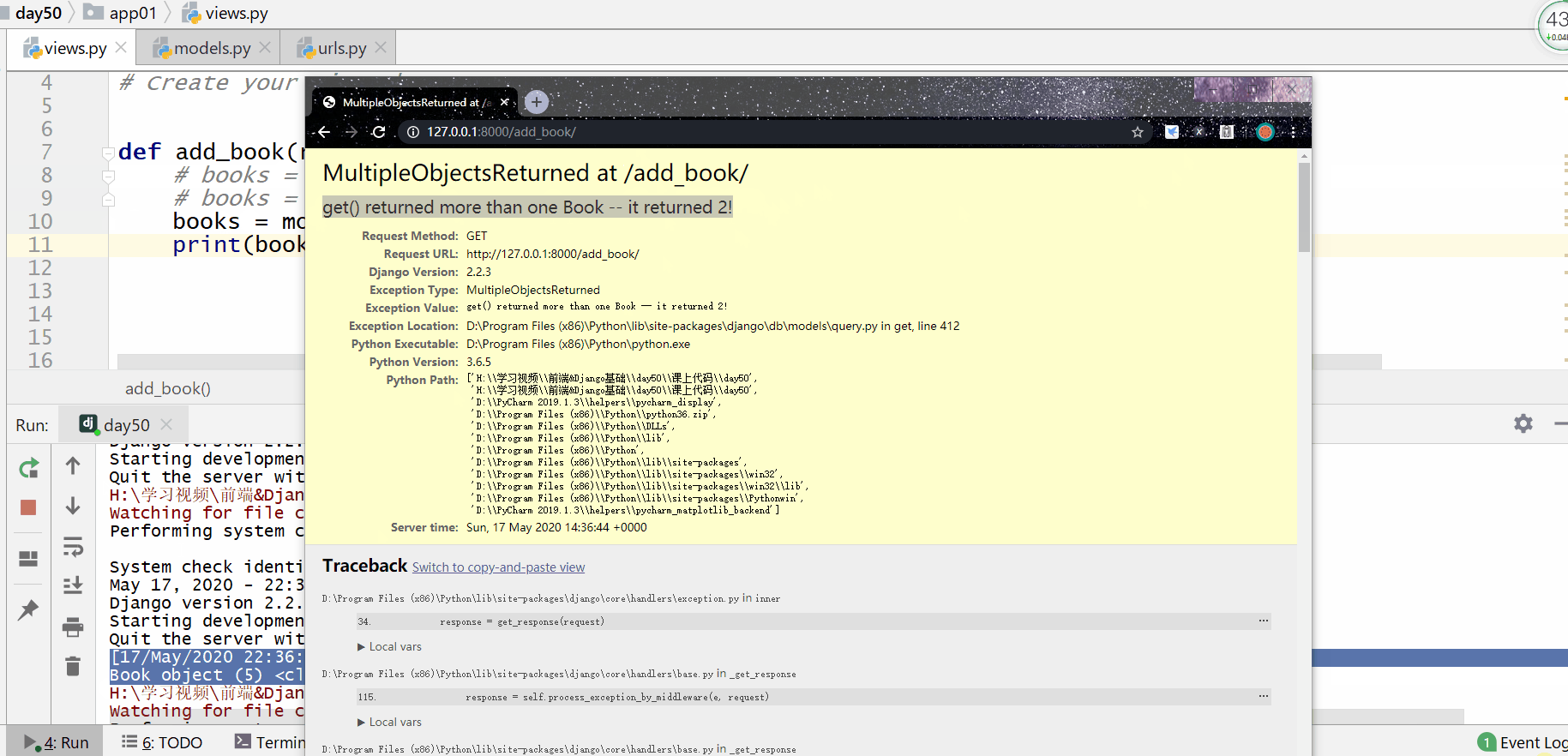
order_by() 方法用于对查询结果进行排序。
返回的是 QuerySet类型数据,类似于list,里面放的是排序后的模型类的对象,可用索引下标取出模型类的对象。
注意:
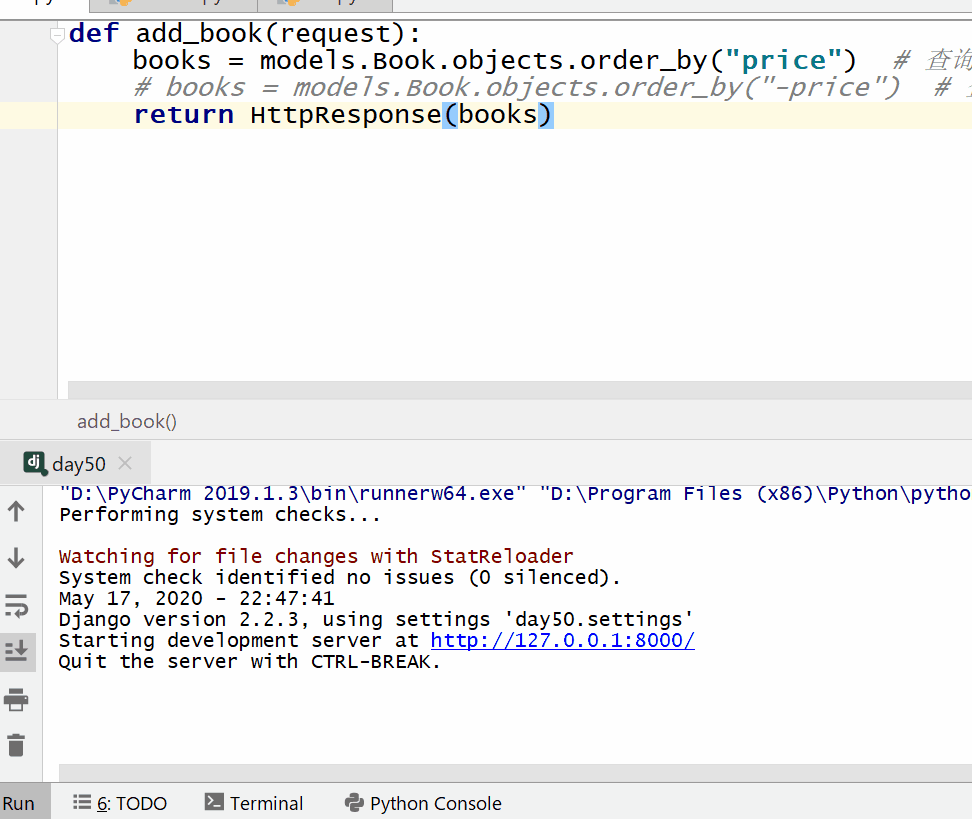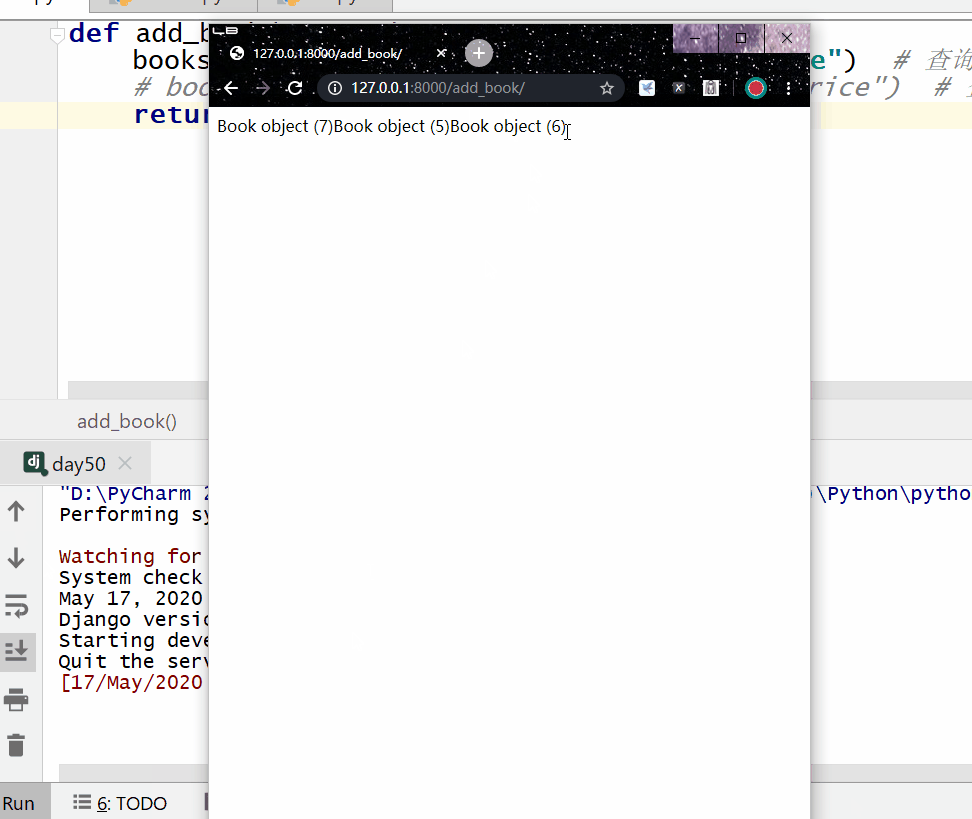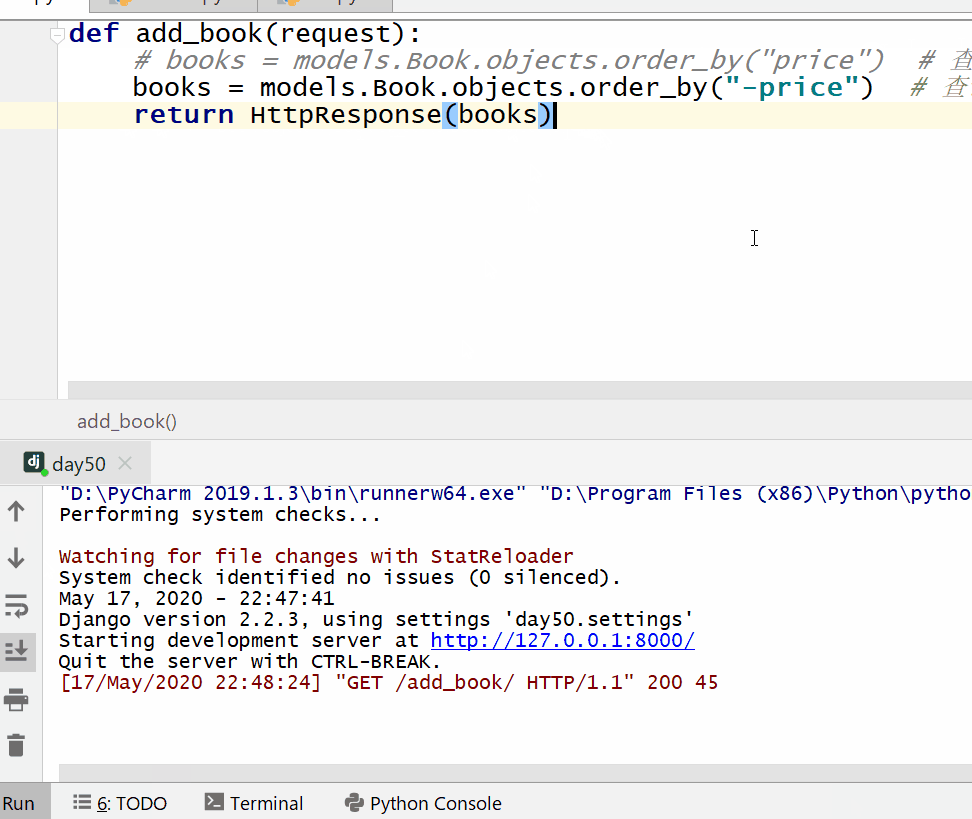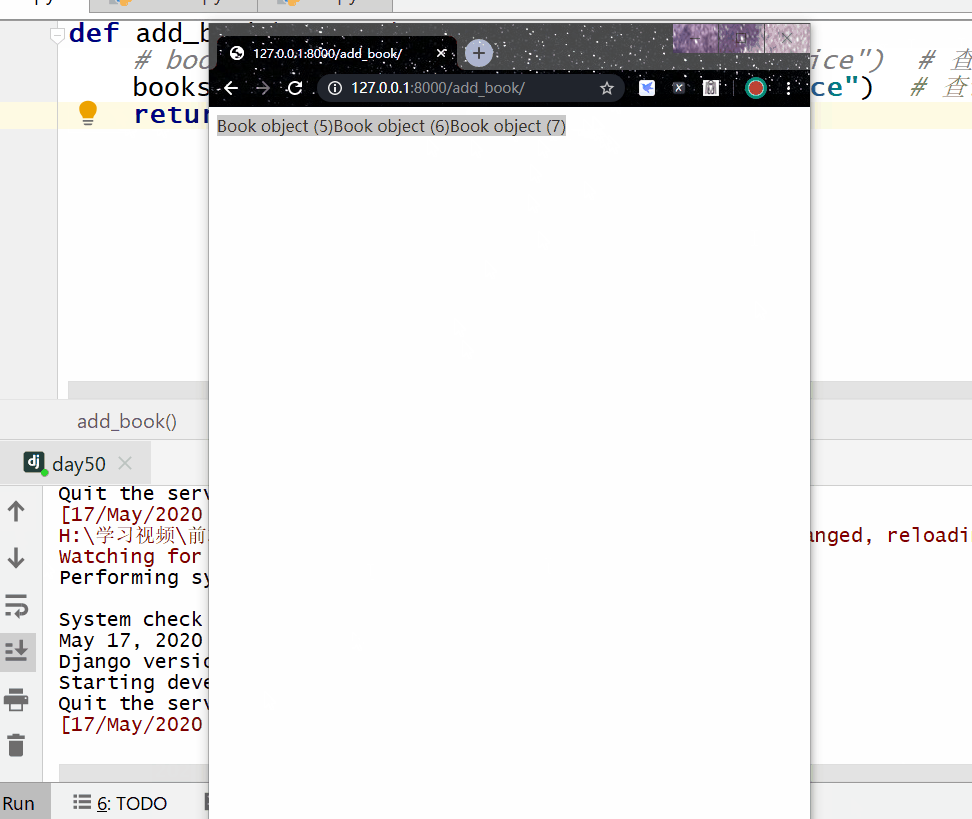
reverse() 方法用于对查询结果进行反转。
返回的是 QuerySe t类型数据,类似于 list,里面放的是反转后的模型类的对象,可用索引下标取出模型类的对象。
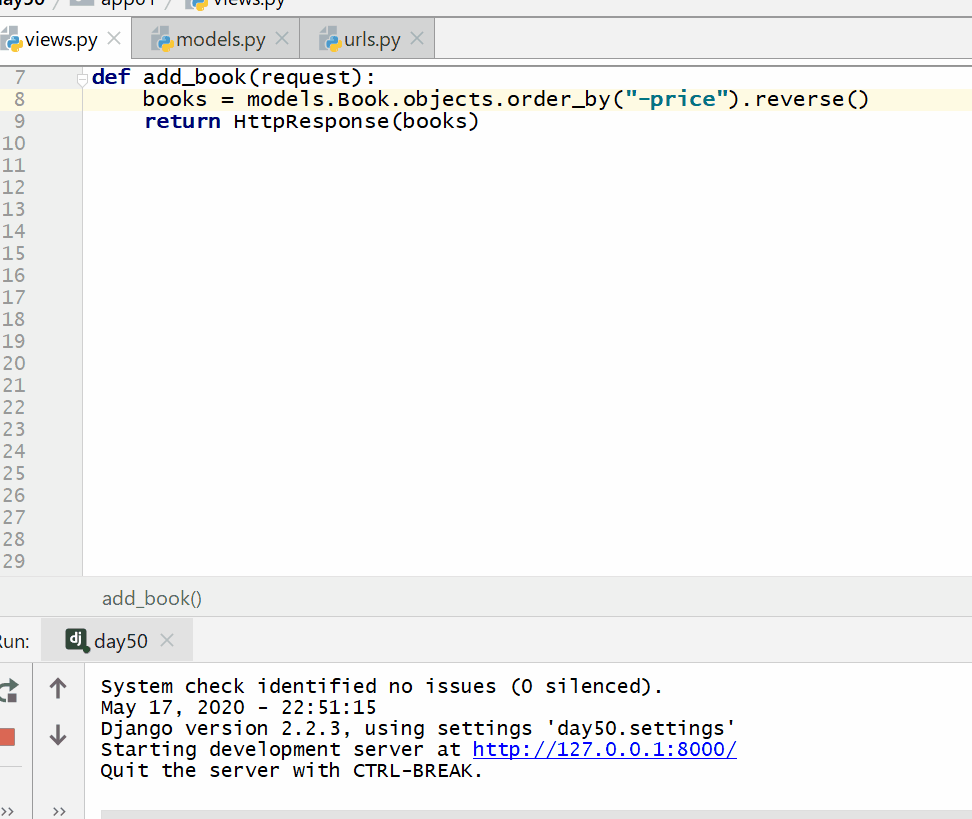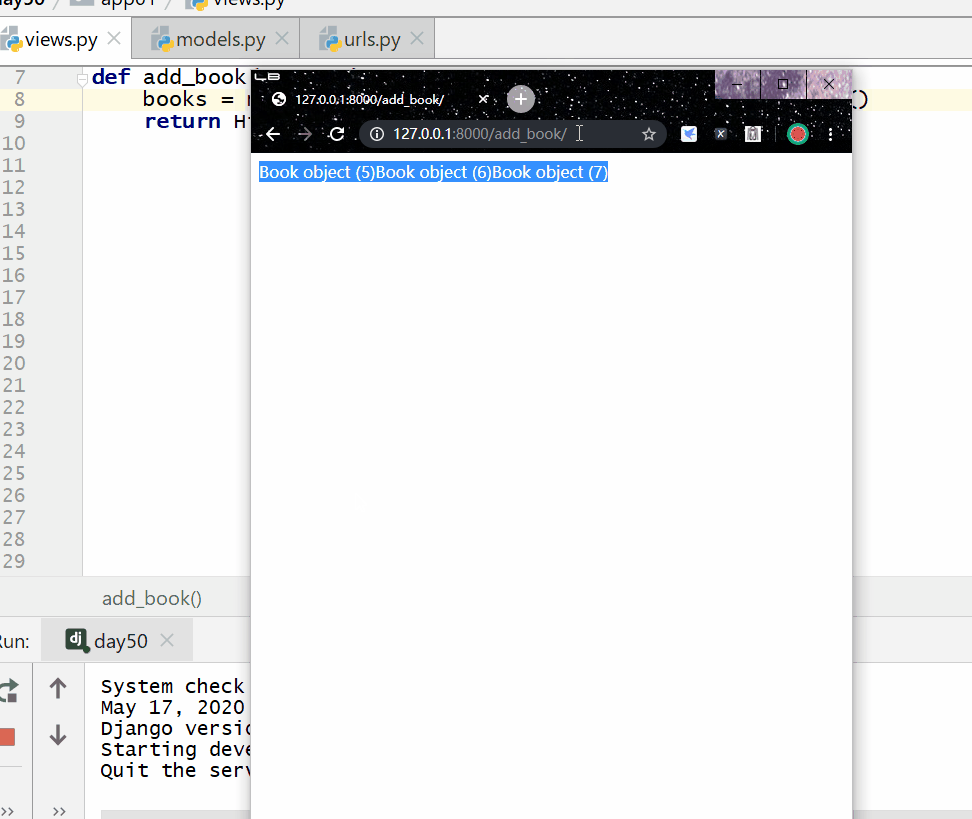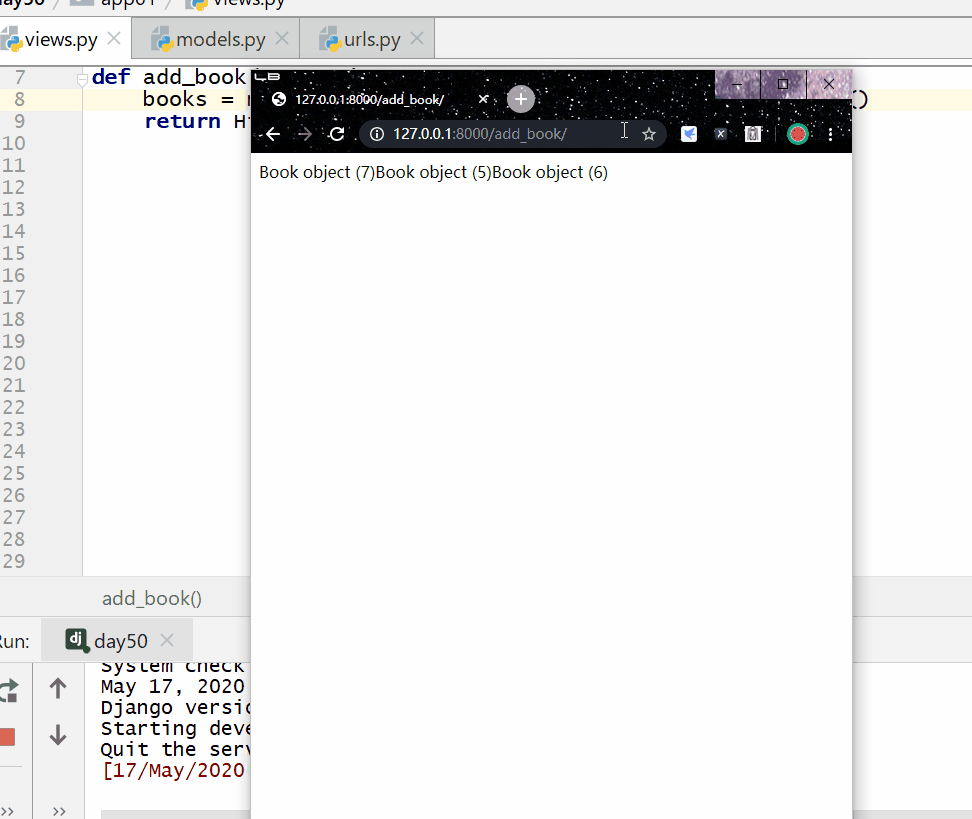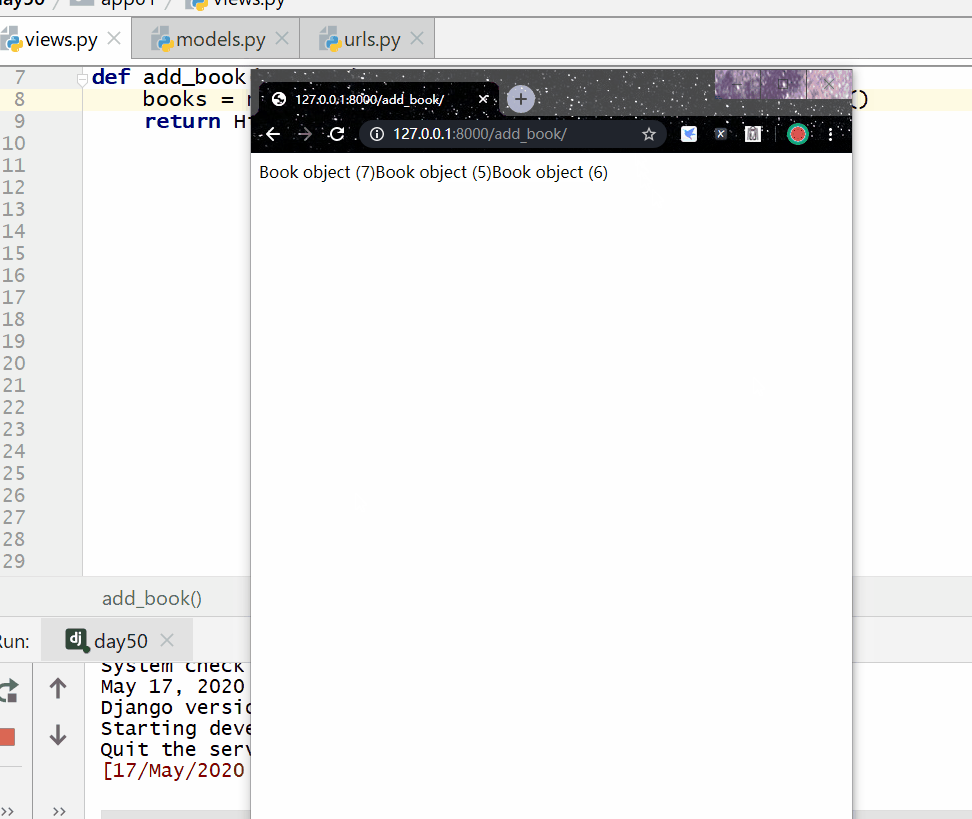
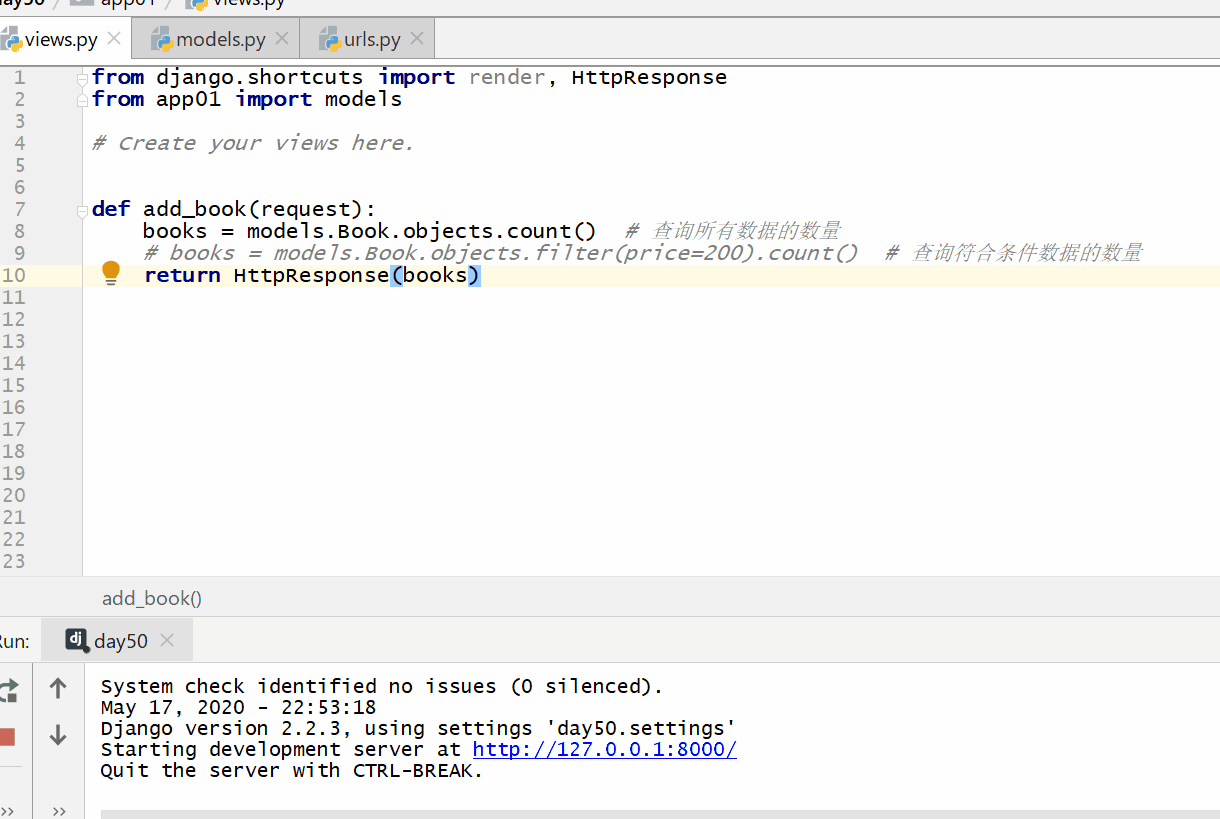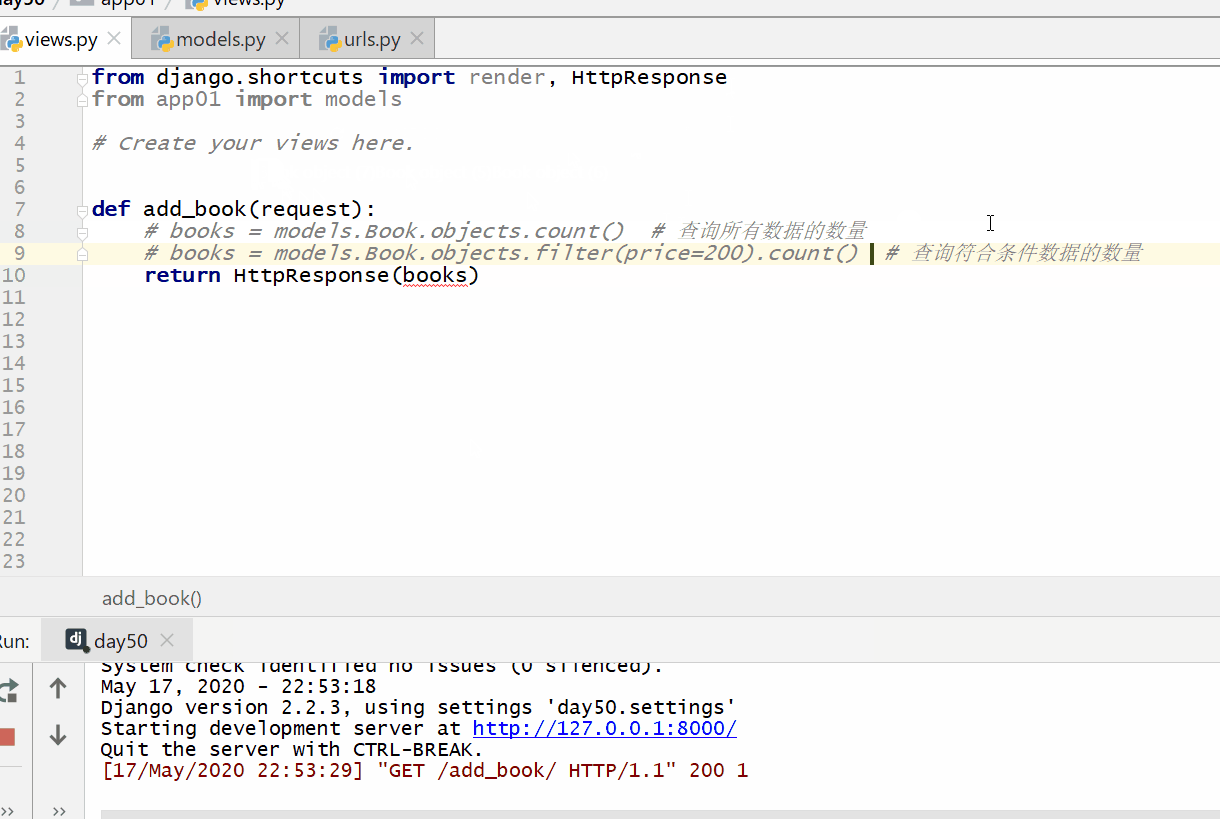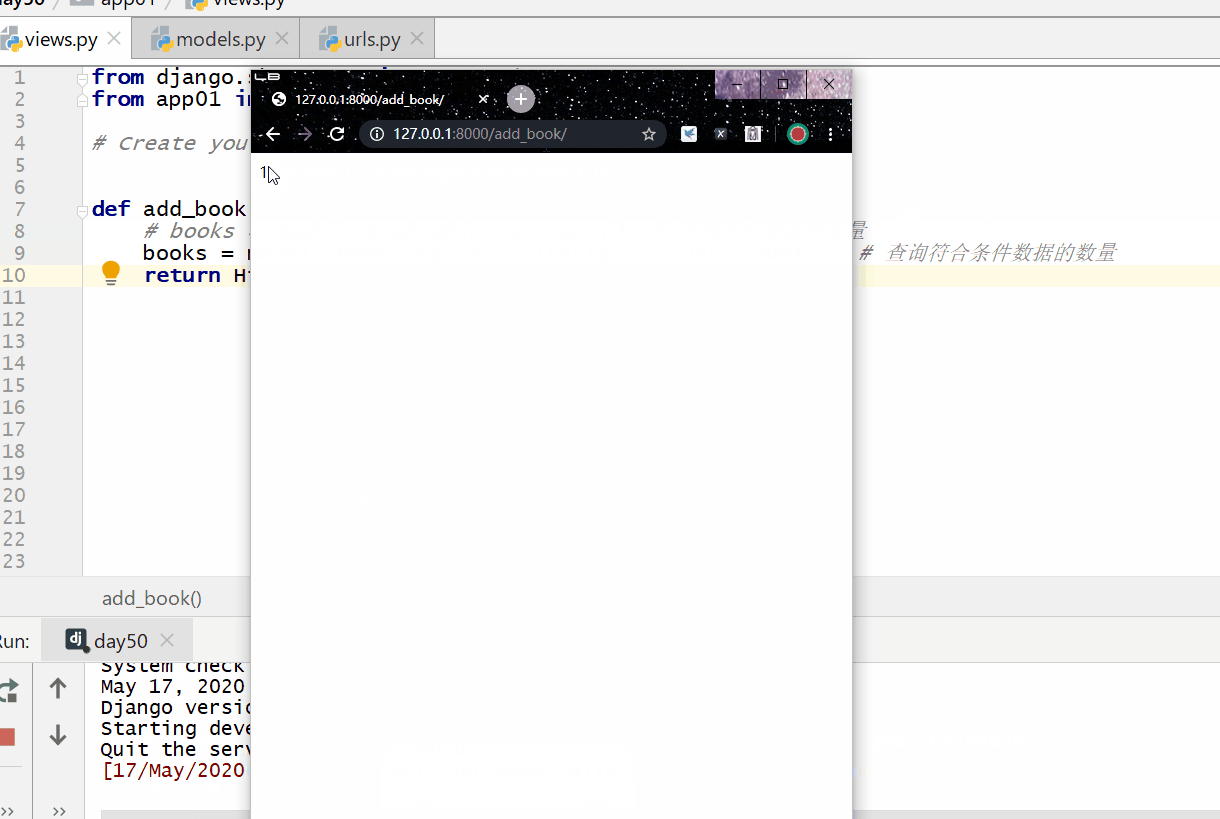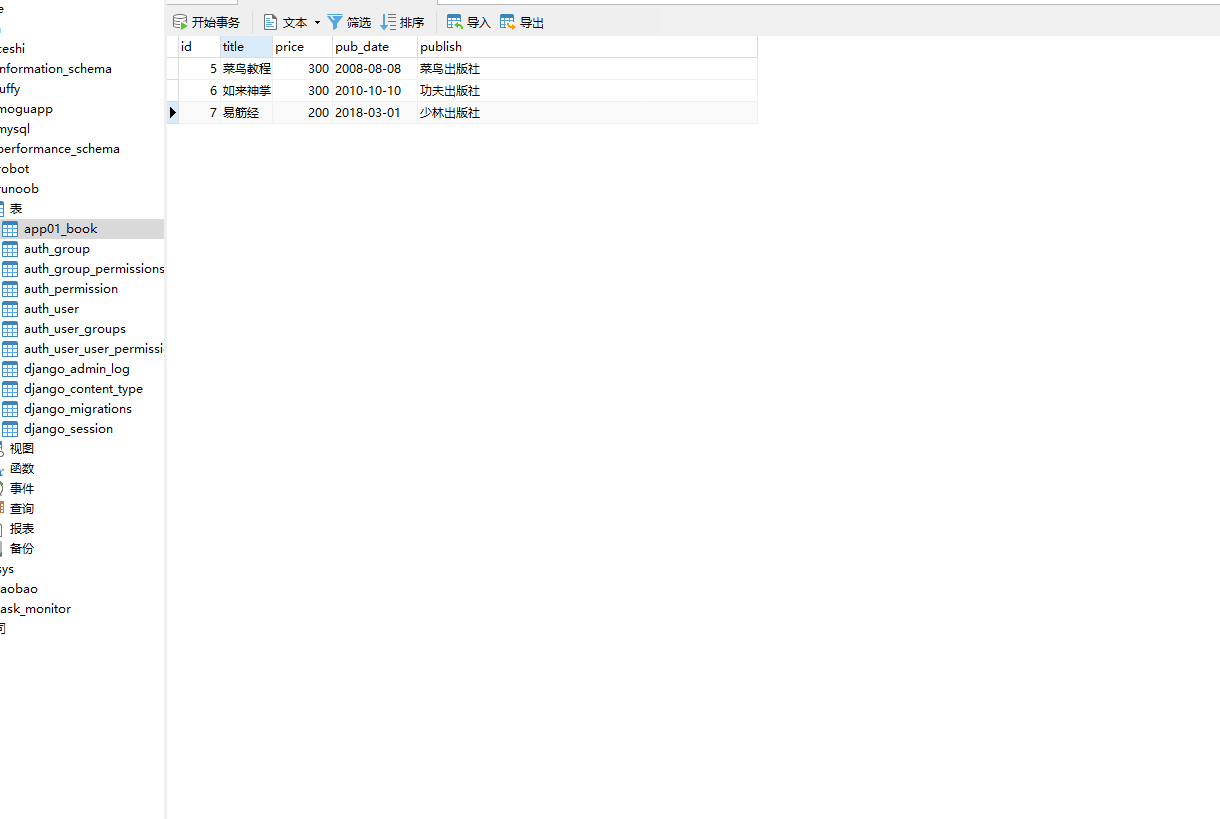
count() 方法用于查询数据的数量返回的数据是整数。
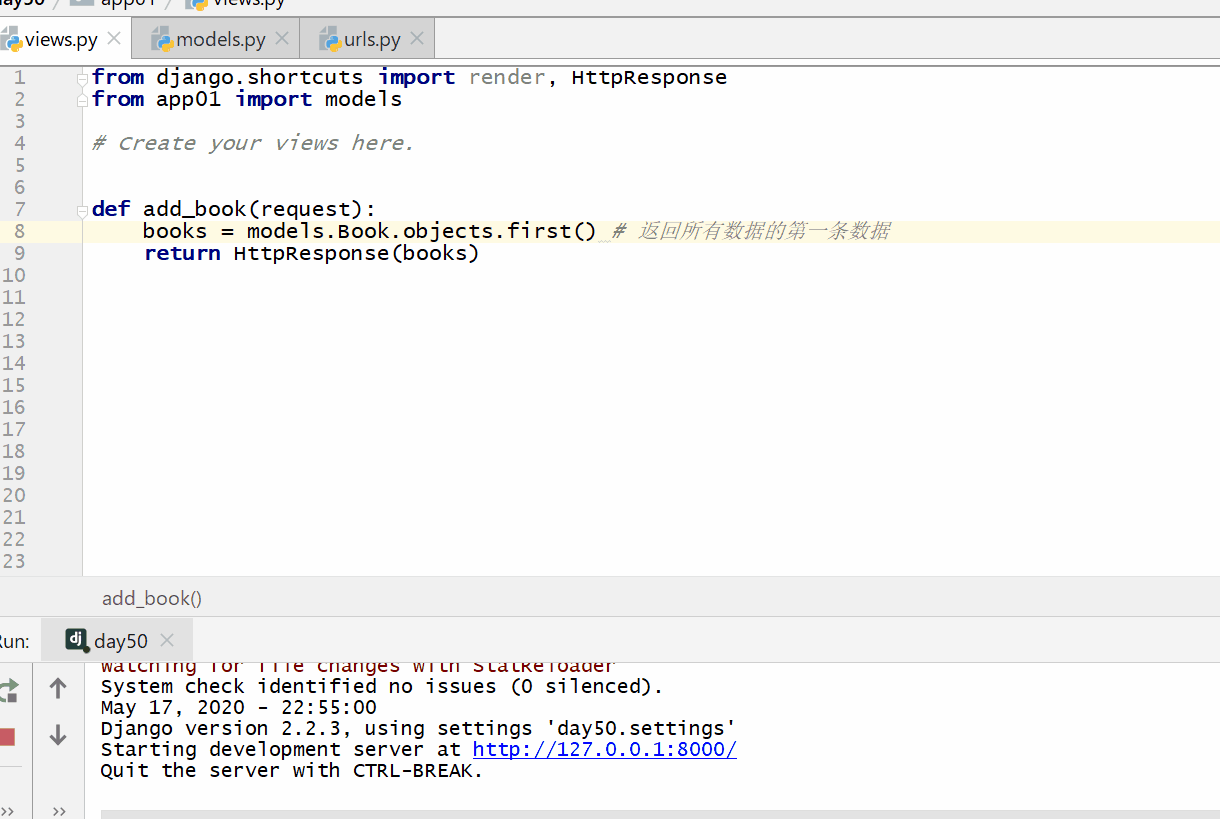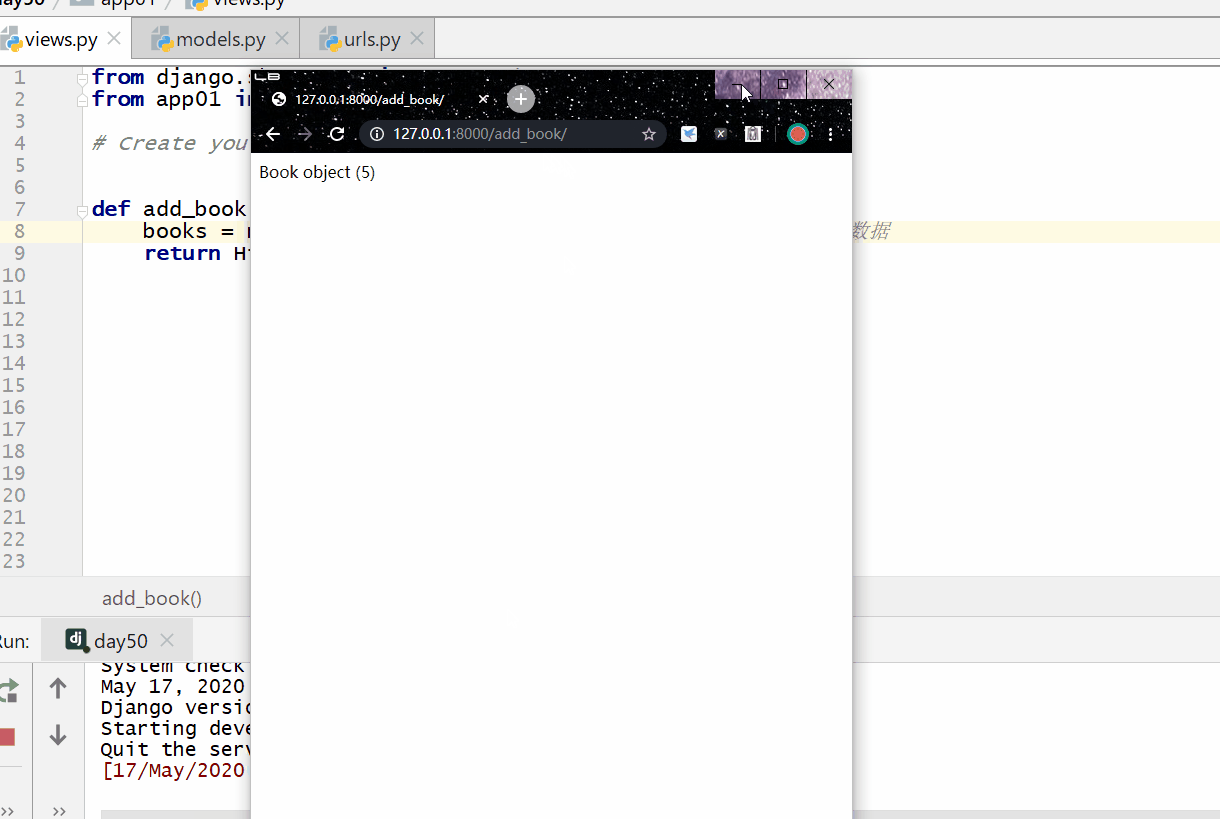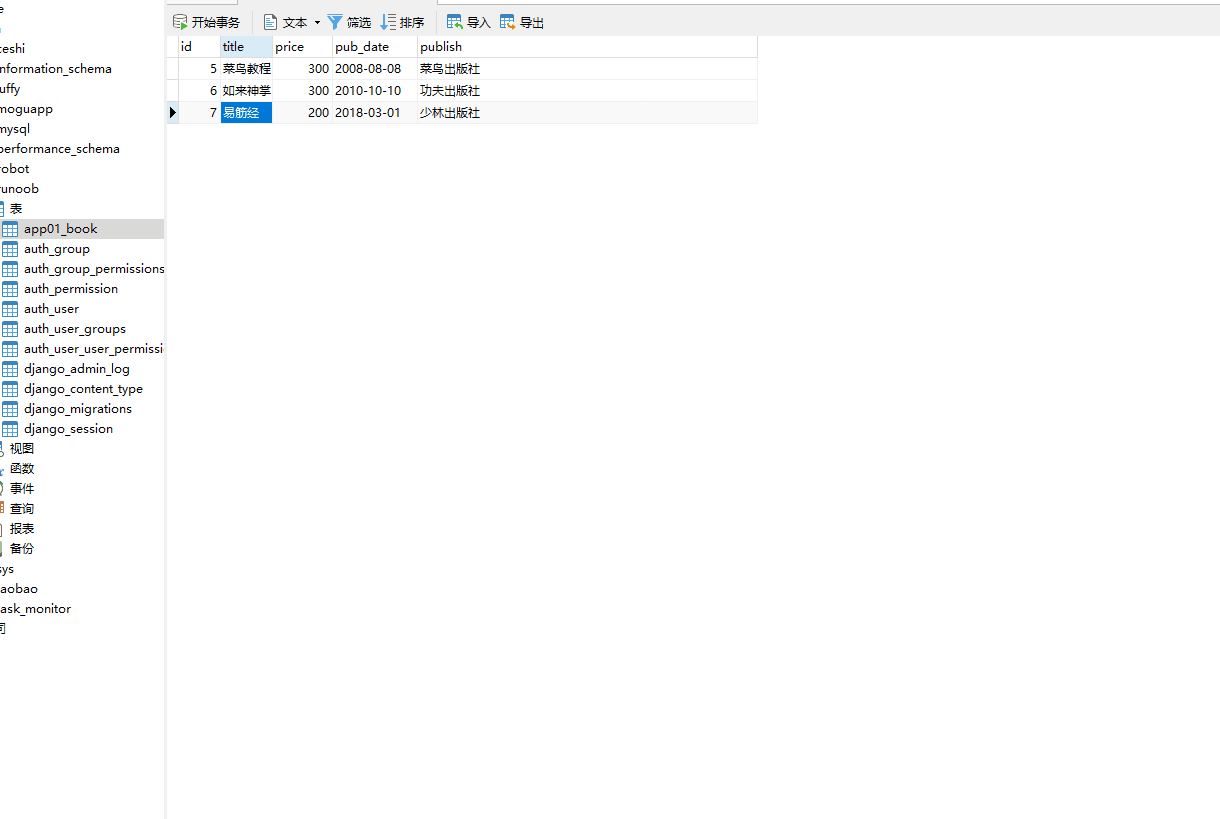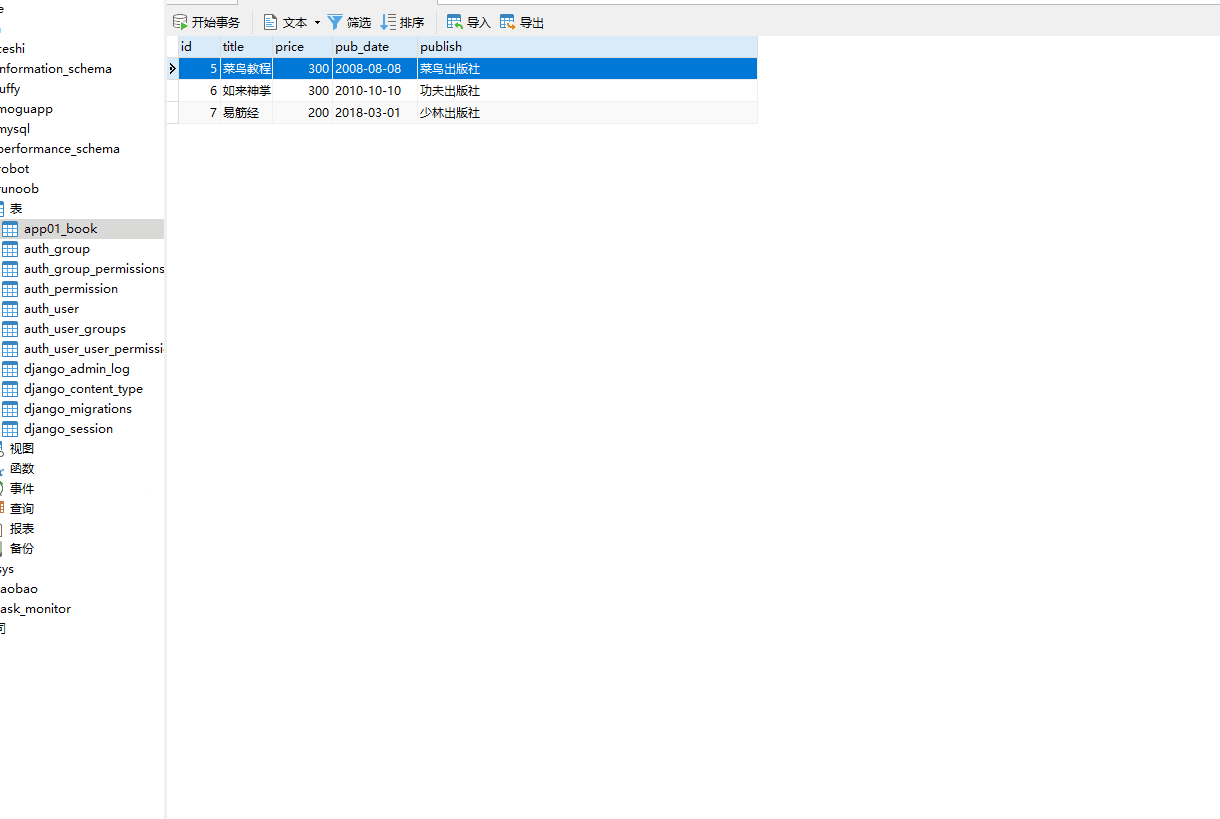
first() 方法返回第一条数据返回的数据是模型类的对象也可以用索引下标 [0]。
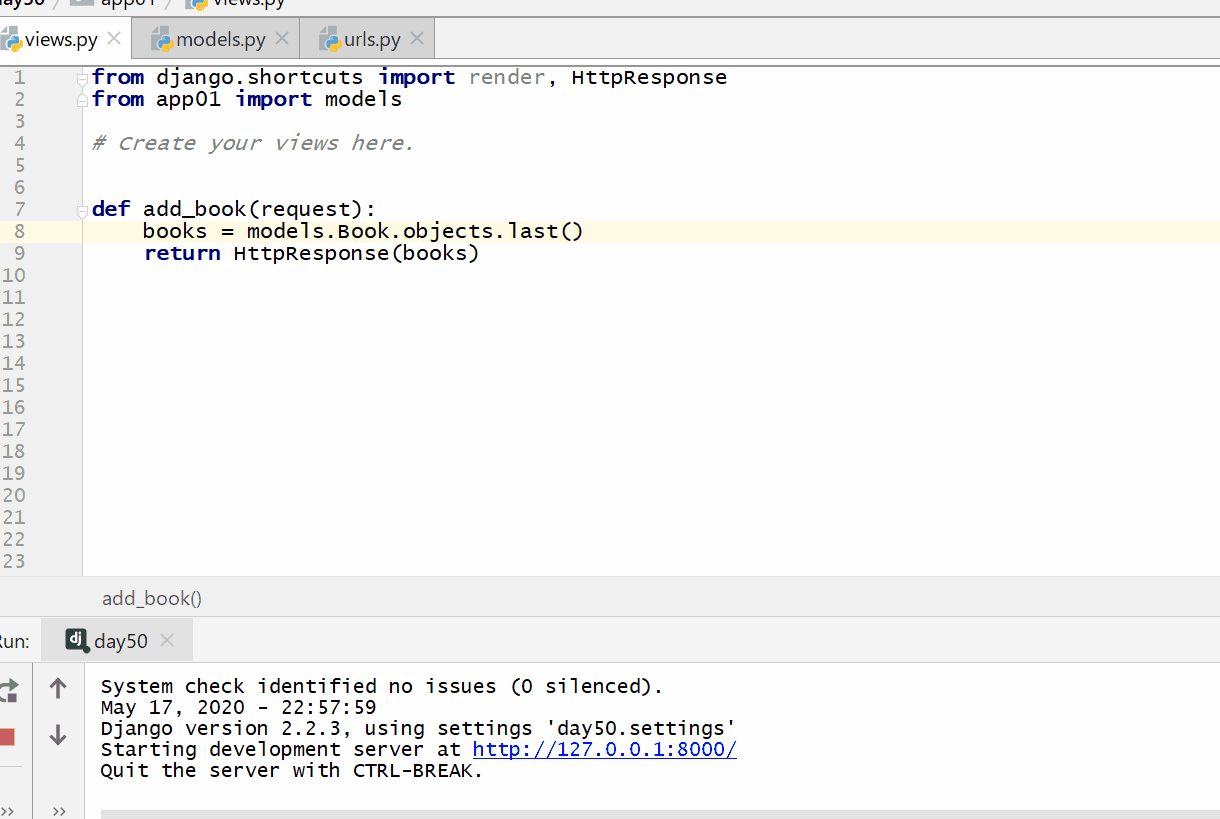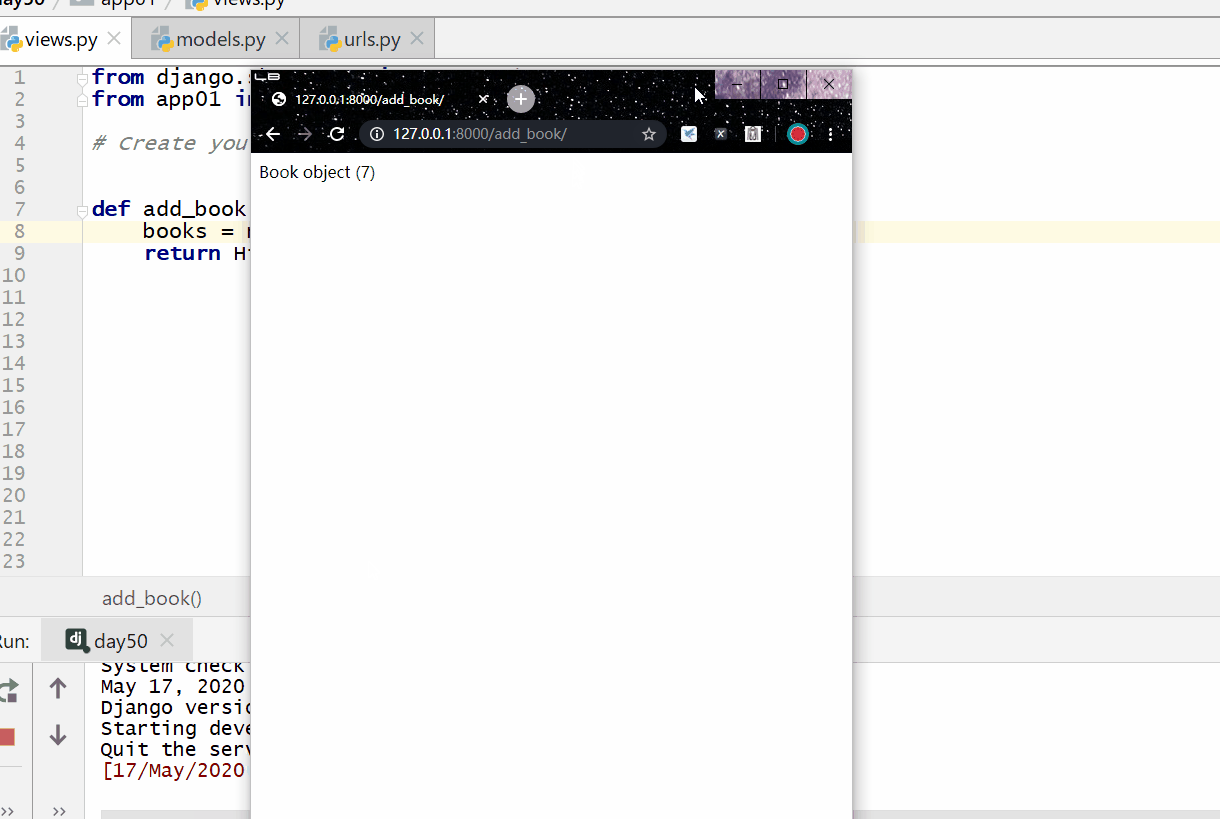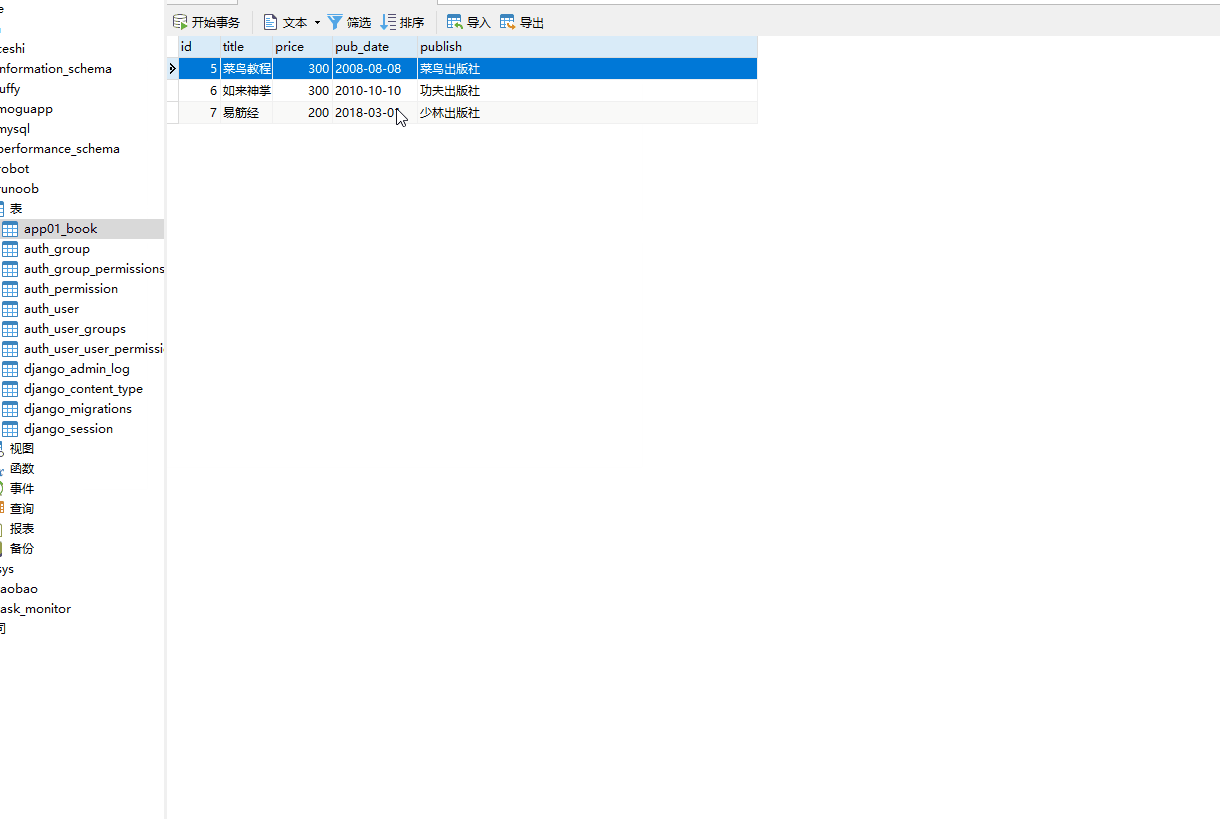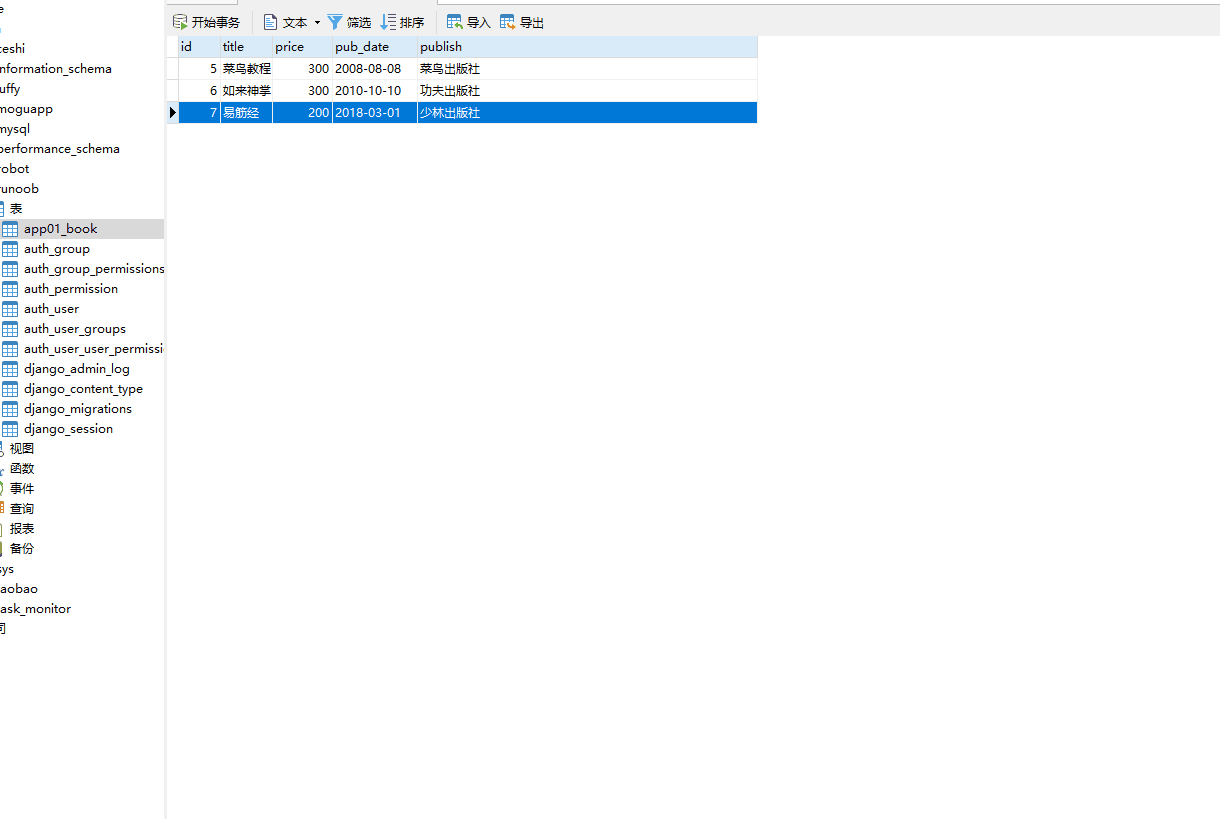
last() 方法返回最后一条数据返回的数据是模型类的对象不能用索引下标 [-1],ORM 没有逆序索引。
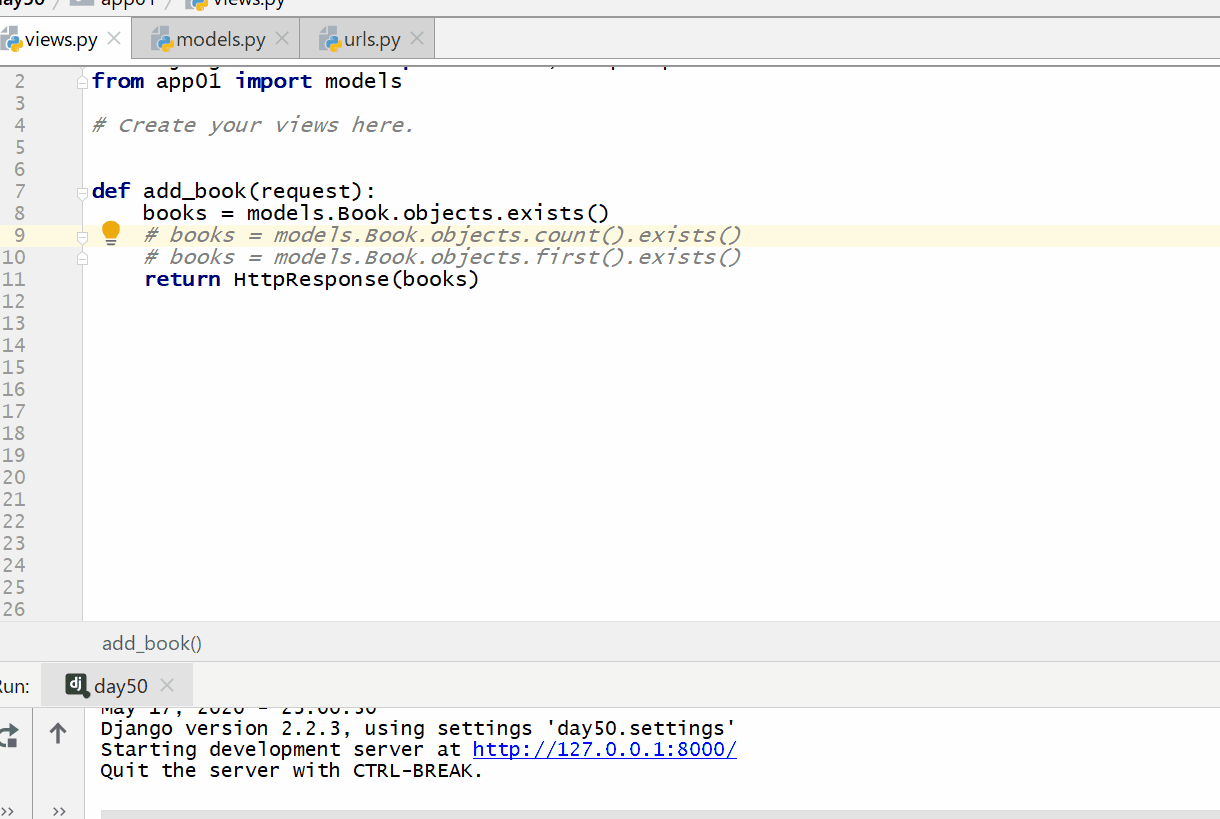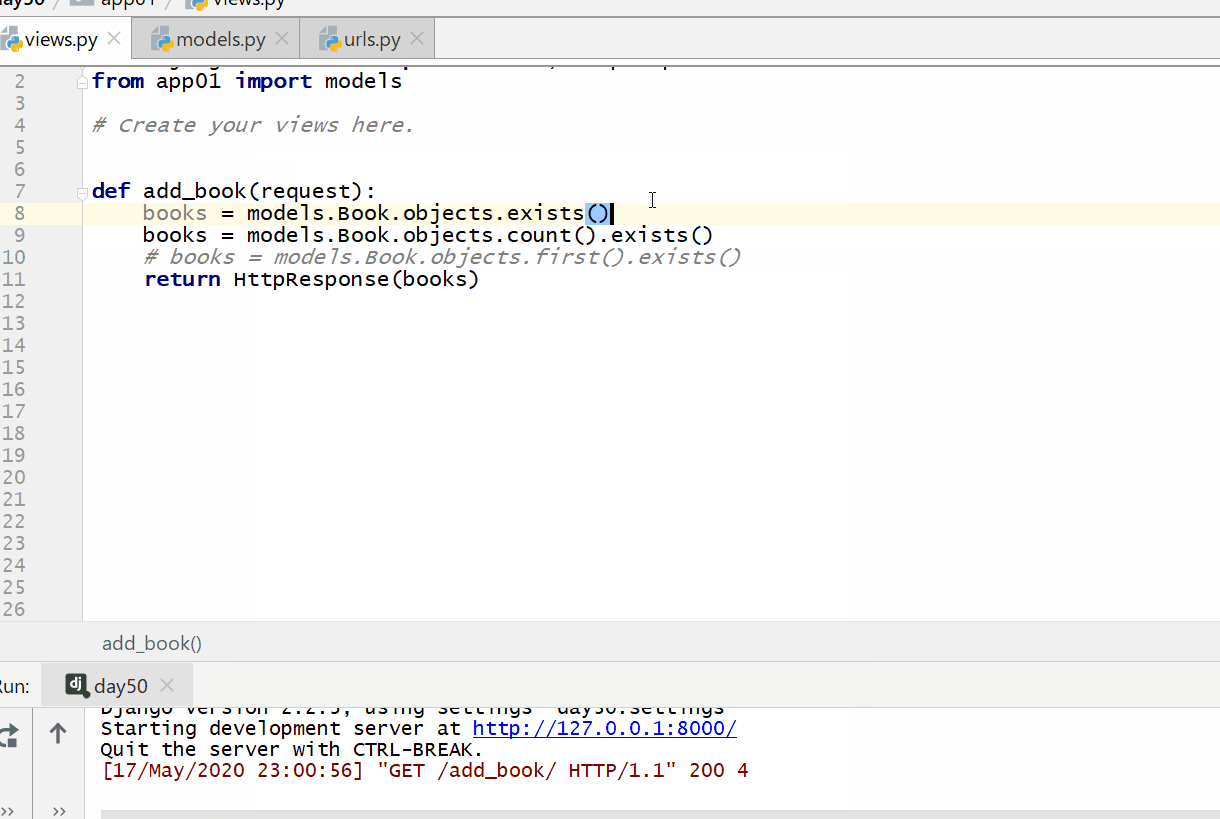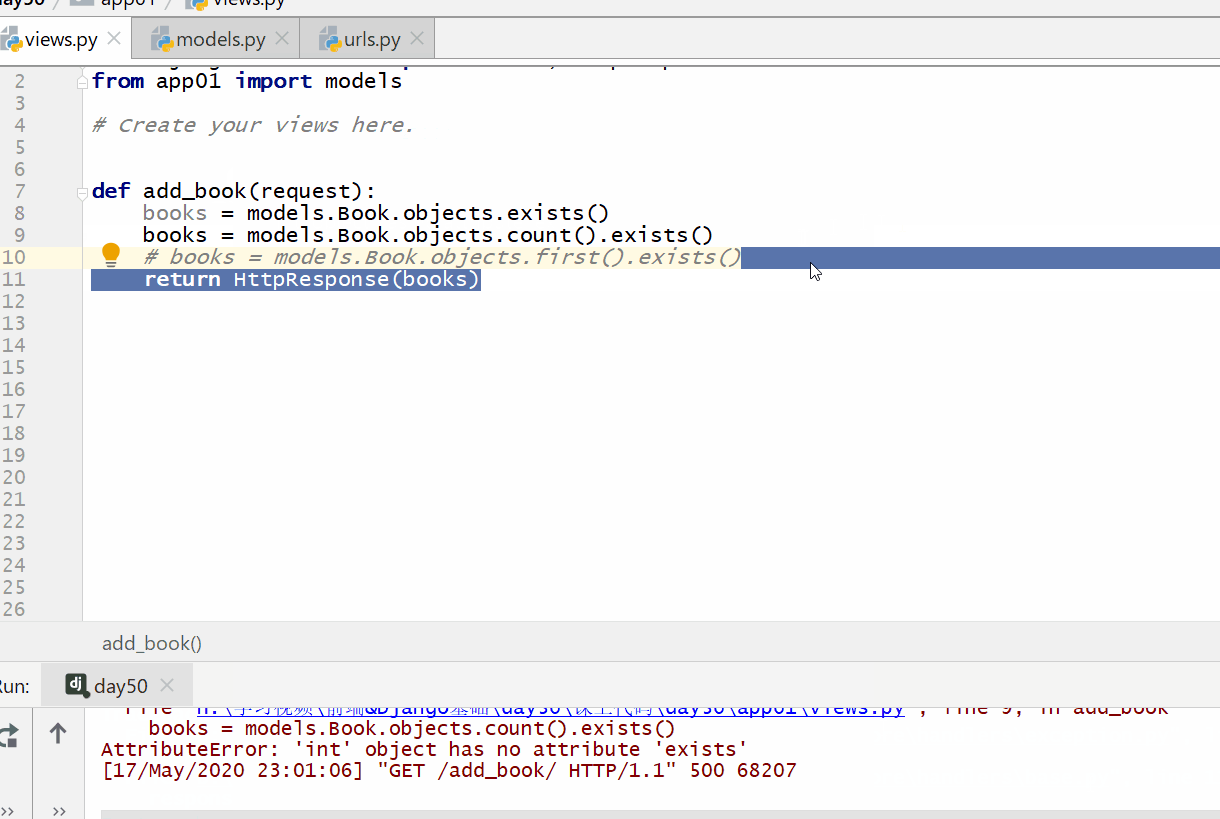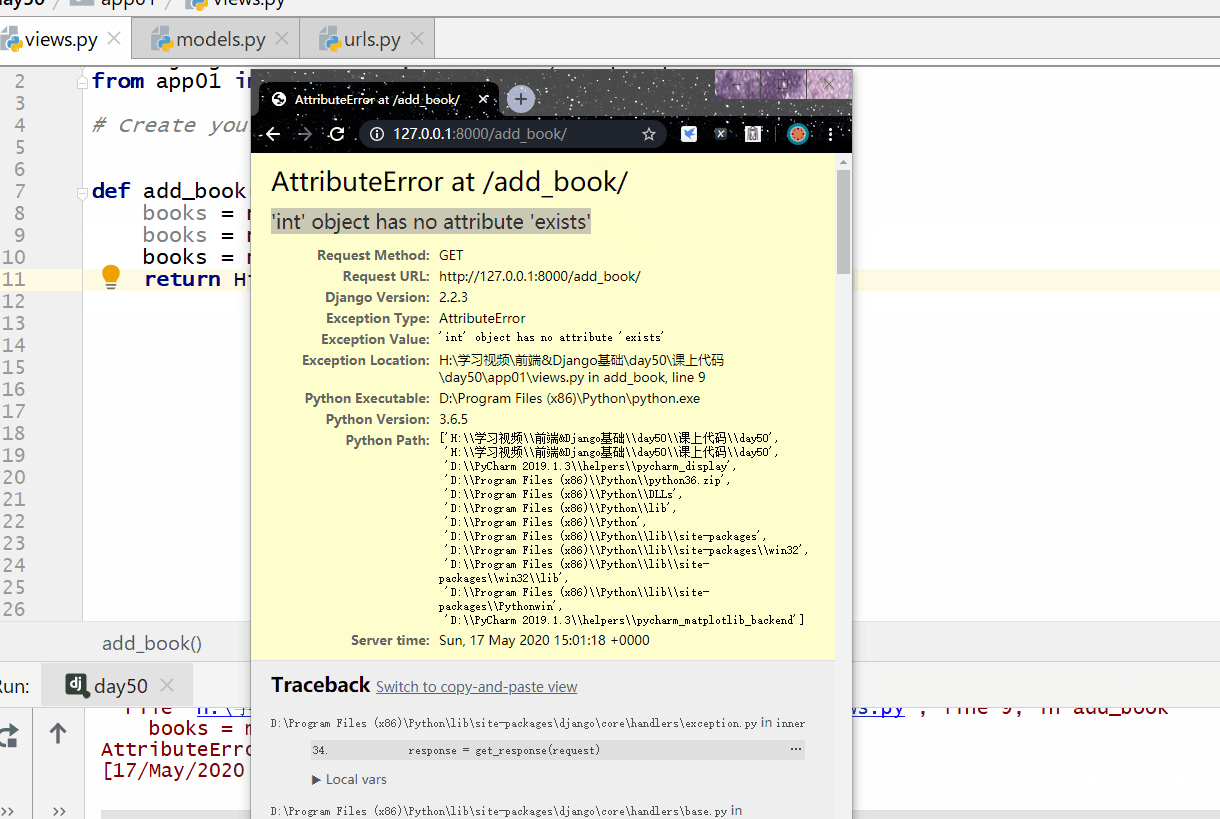
exists() 方法用于判断查询的结果 QuerySet 列表里是否有数据。
返回的数据类型是布尔,有为 true,没有为 false。
注意:判断的数据类型只能为 QuerySet 类型数据,不能为整型和模型类的对象。
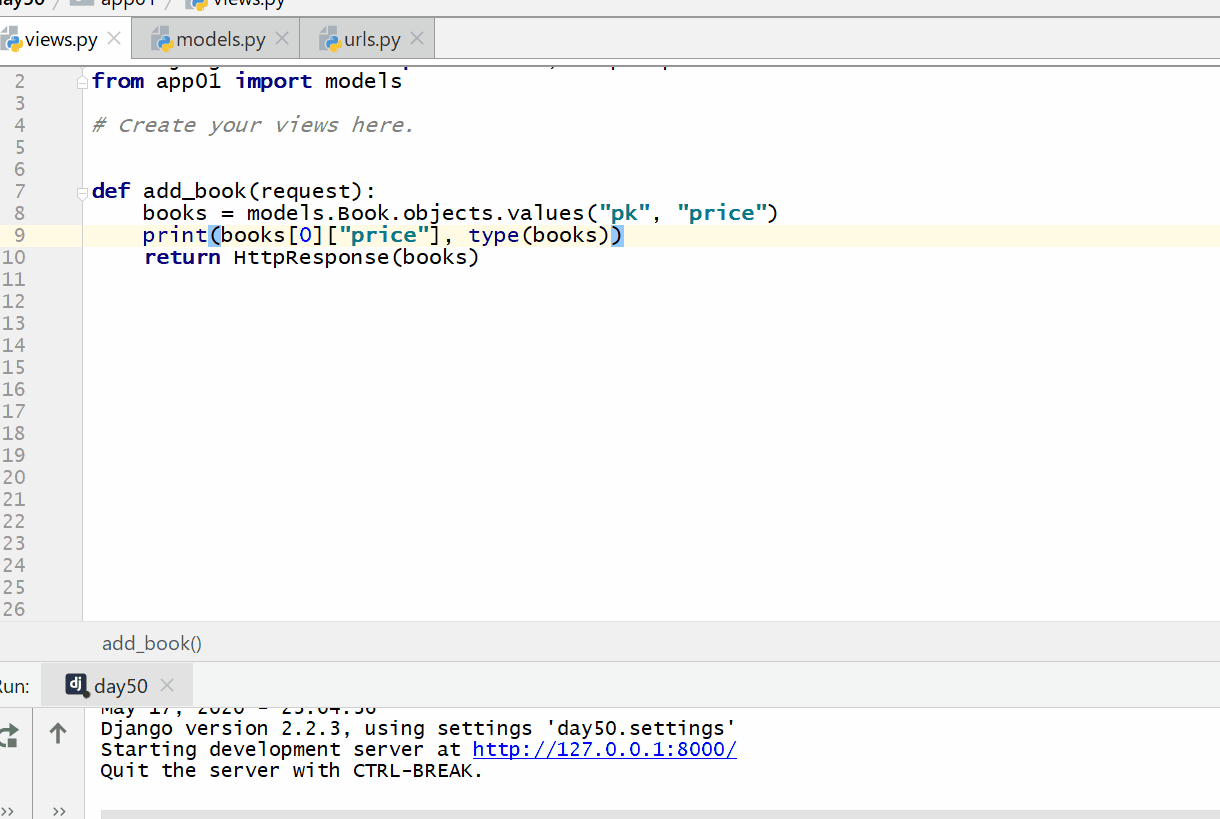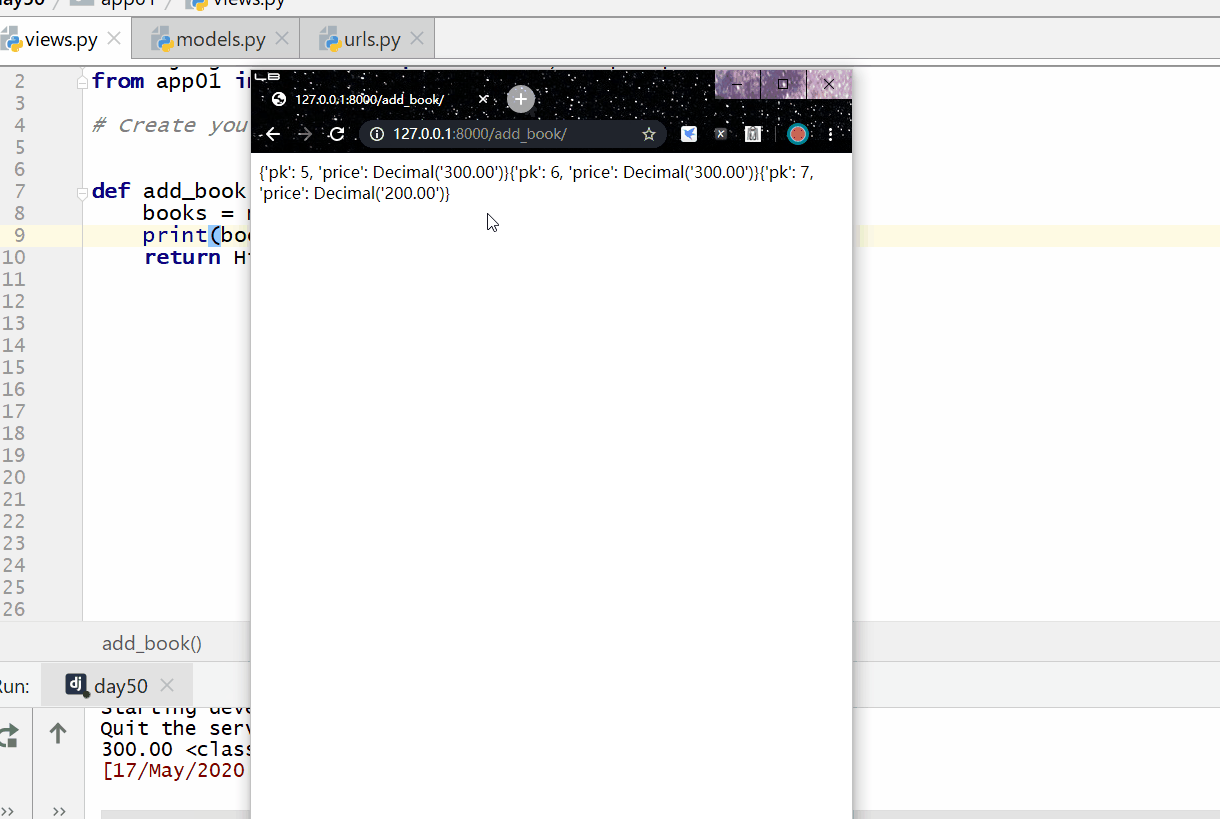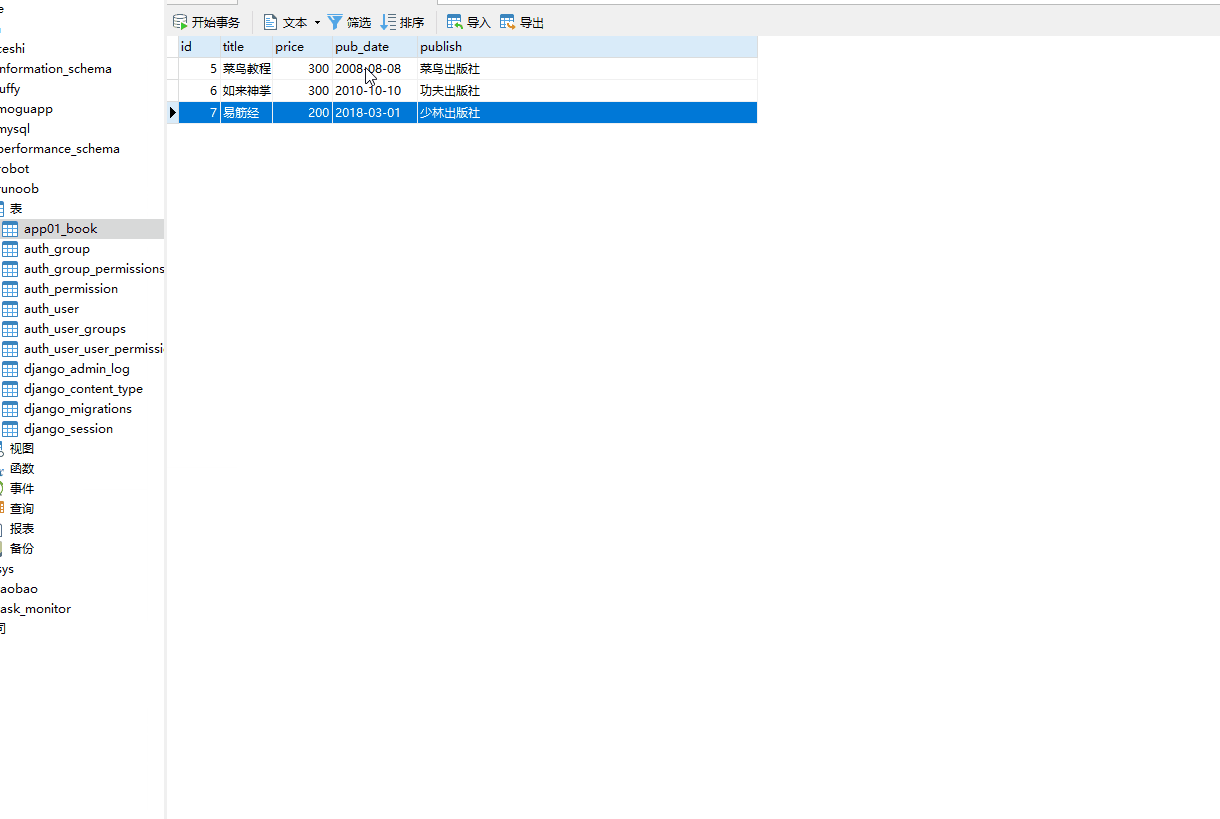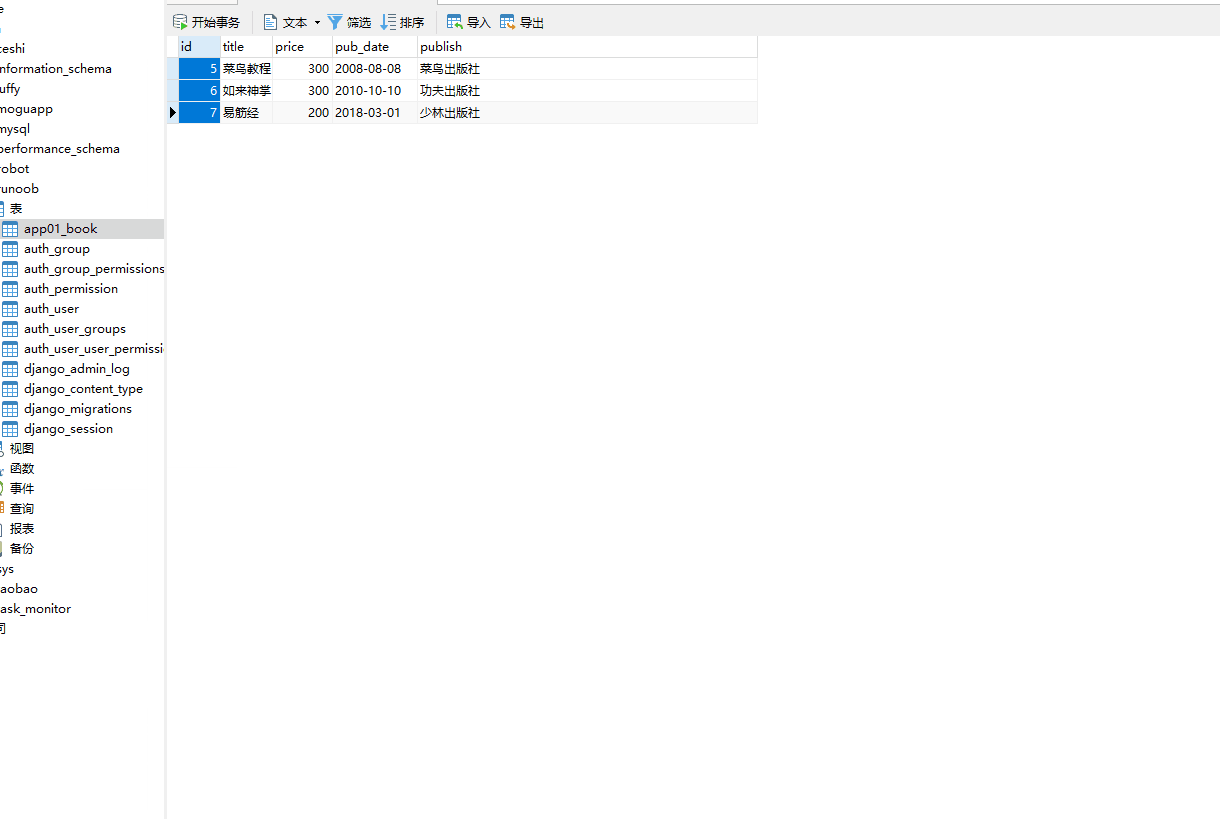
values() 方法用于查询部分字段的数据。
返回的是 QuerySet 类型数据,类似于 list,里面不是模型类的对象,而是一个可迭代的字典序列,字典里的键是字段,值是数据。
注意:
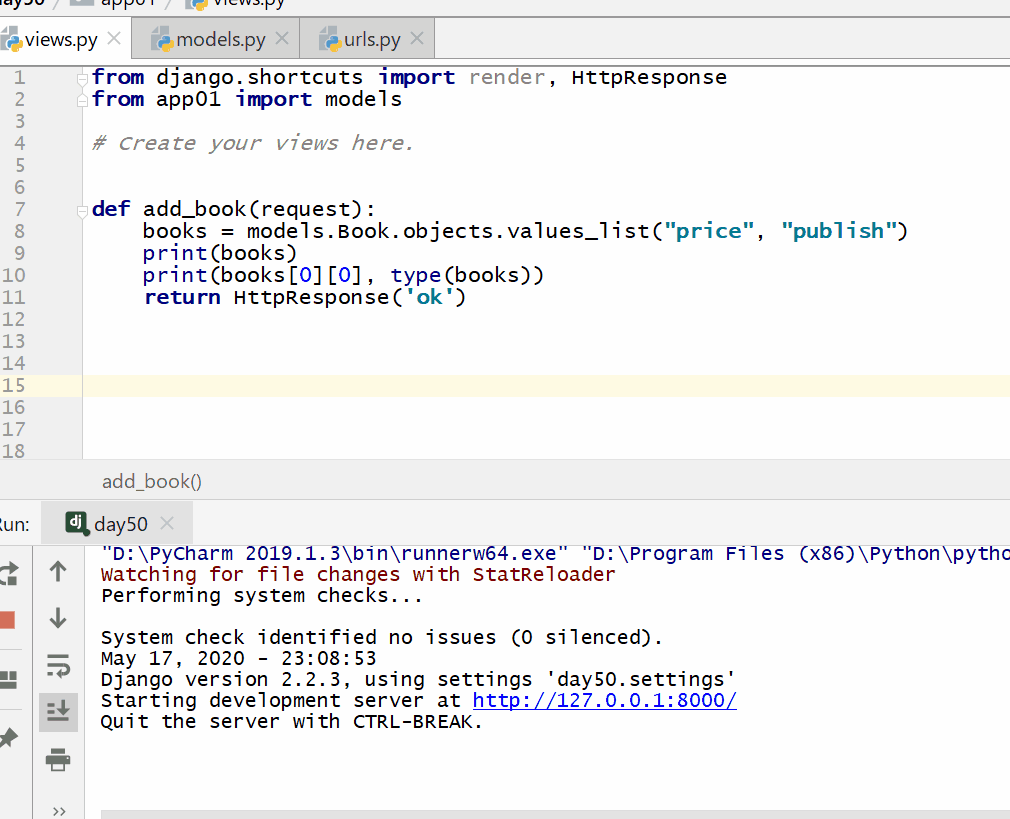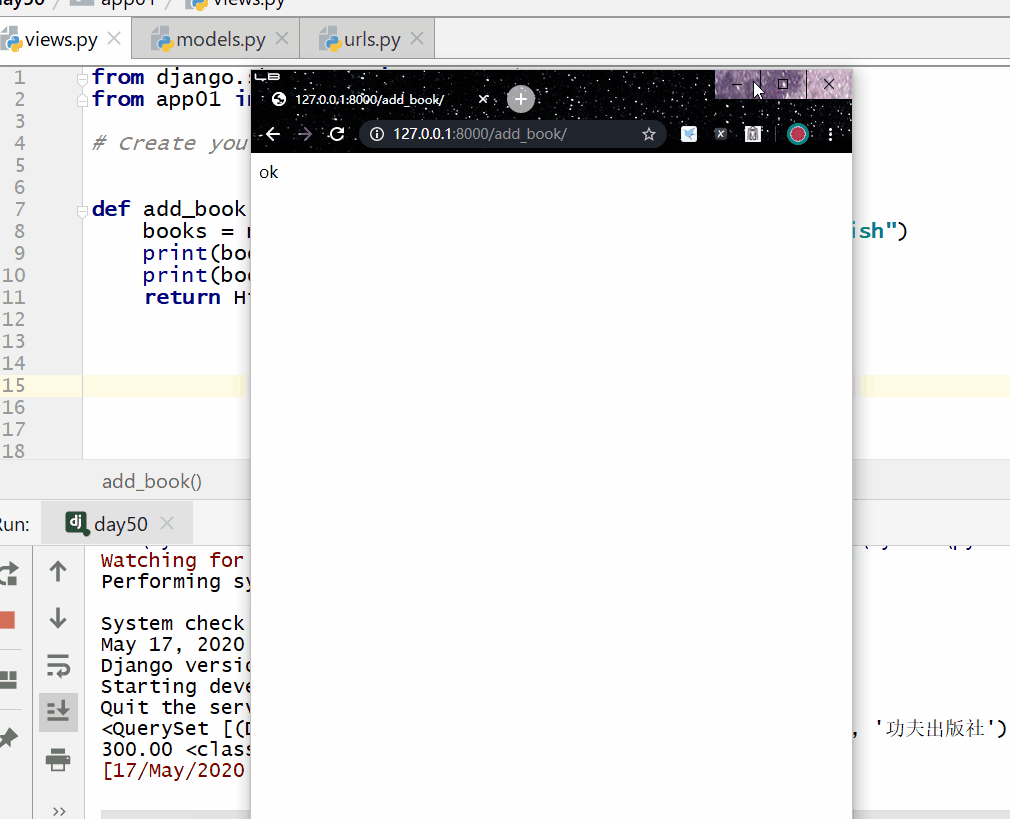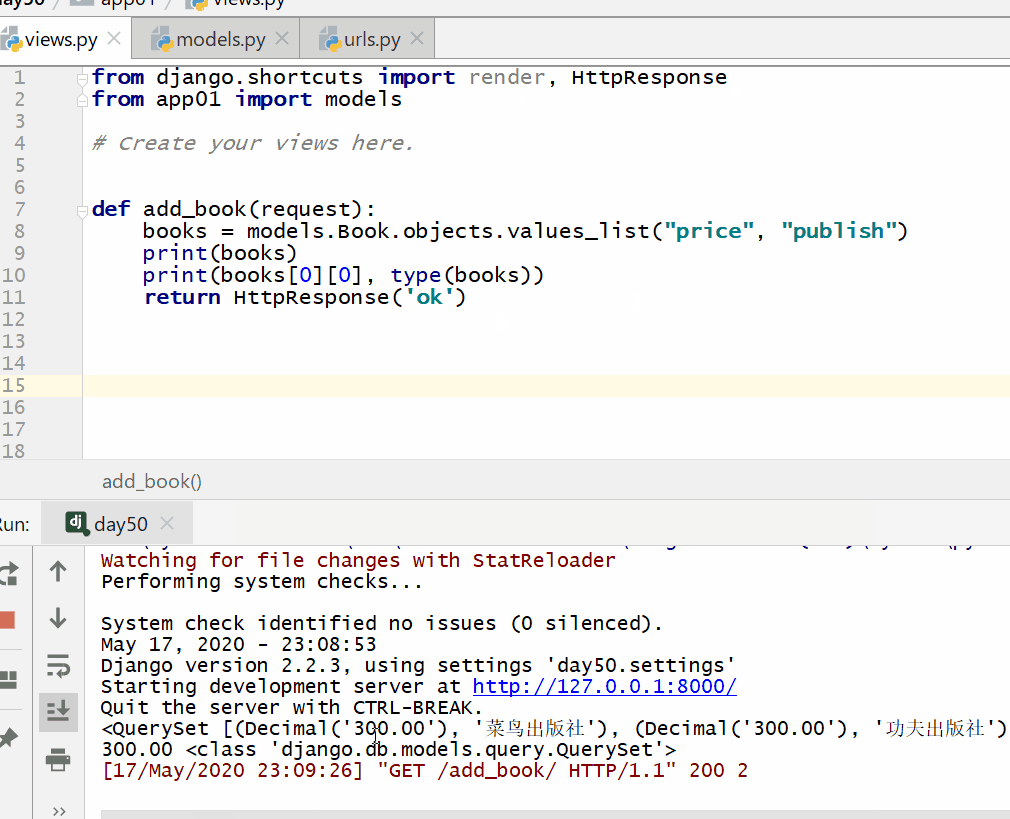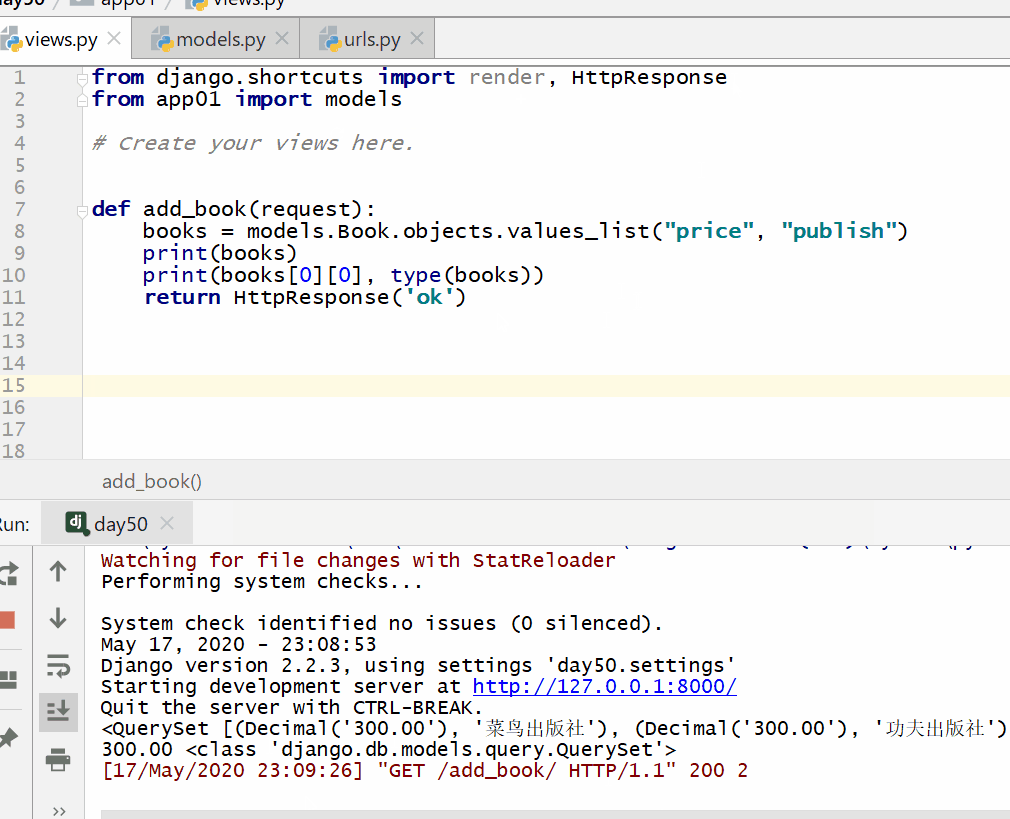
values_list() 方法用于查询部分字段的数据。
返回的是 QuerySet 类型数据,类似于 list,里面不是模型类的对象,而是一个个元组,元组里放的是查询字段对应的数据。
注意:
distinct() 方法用于对数据进行去重。
返回的是 QuerySet 类型数据。
注意:
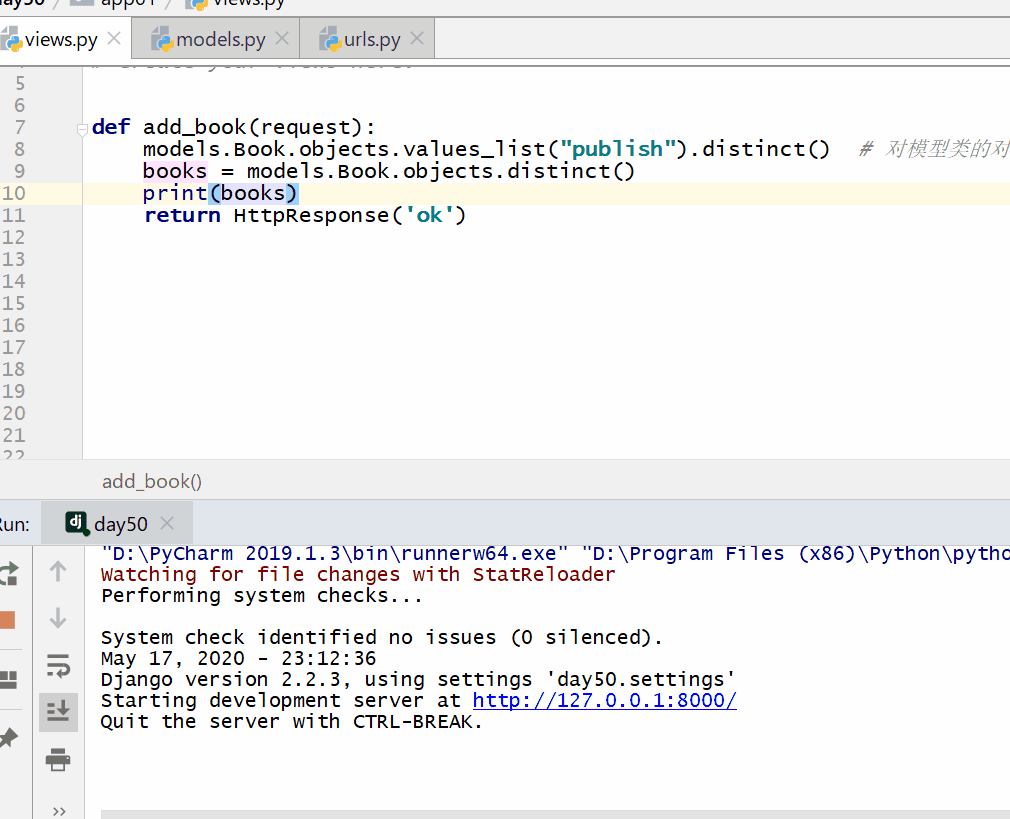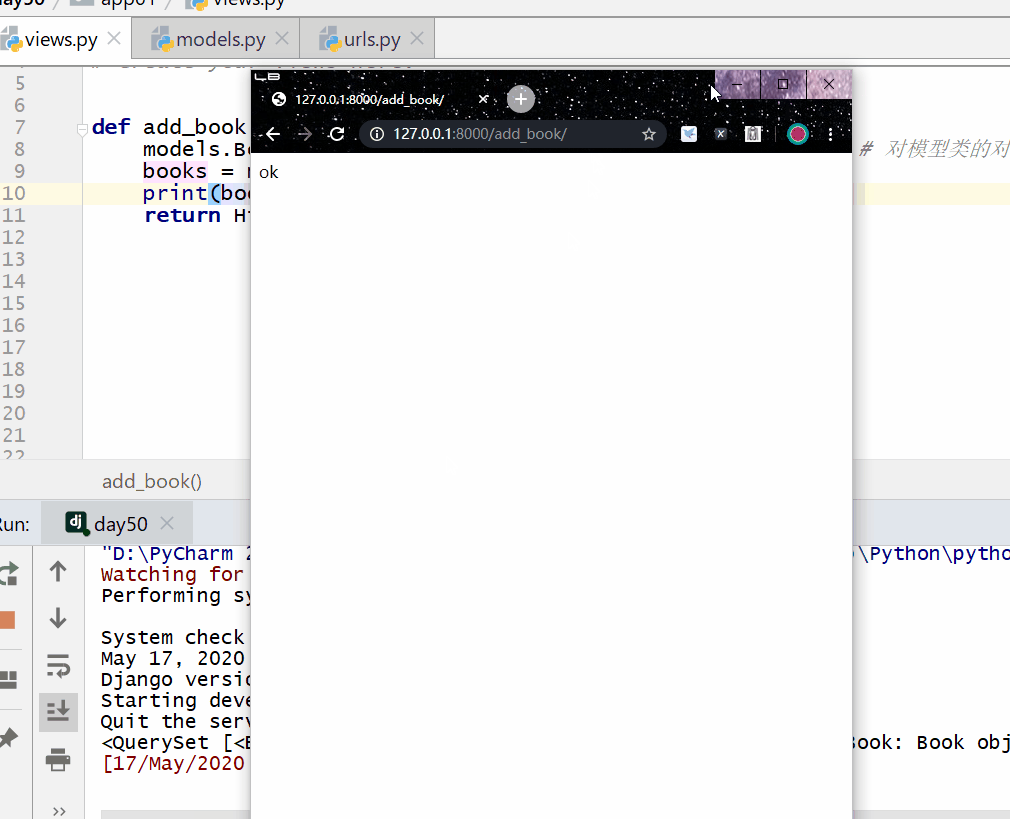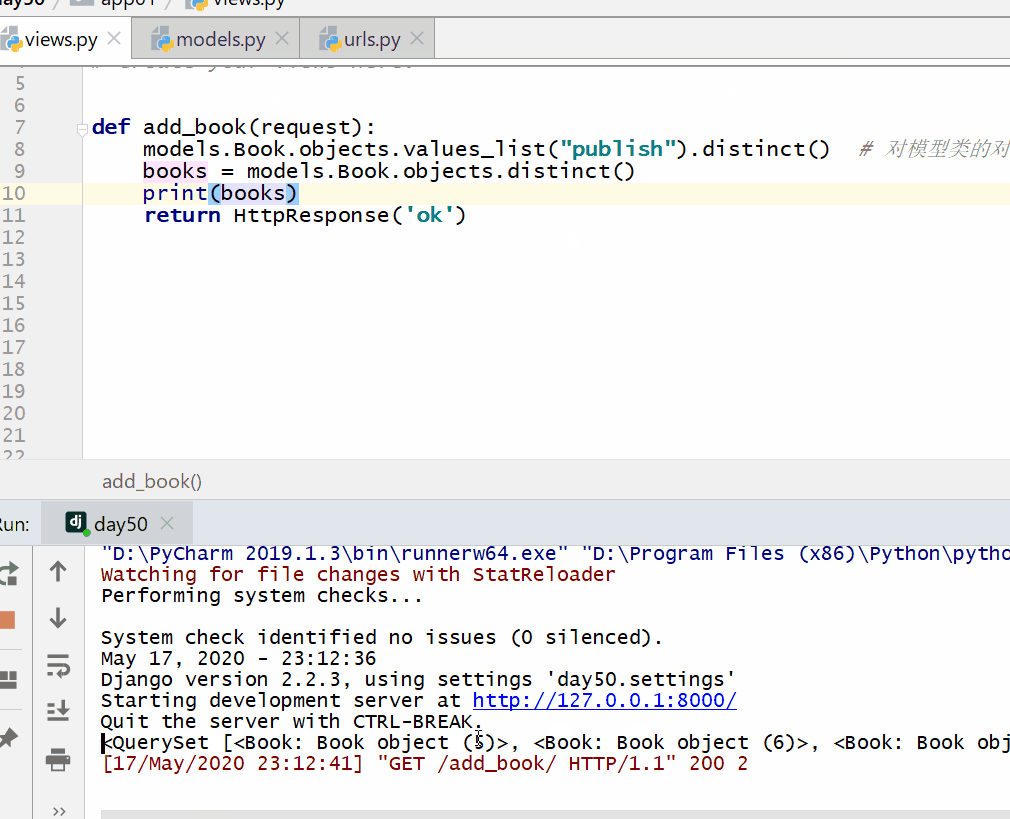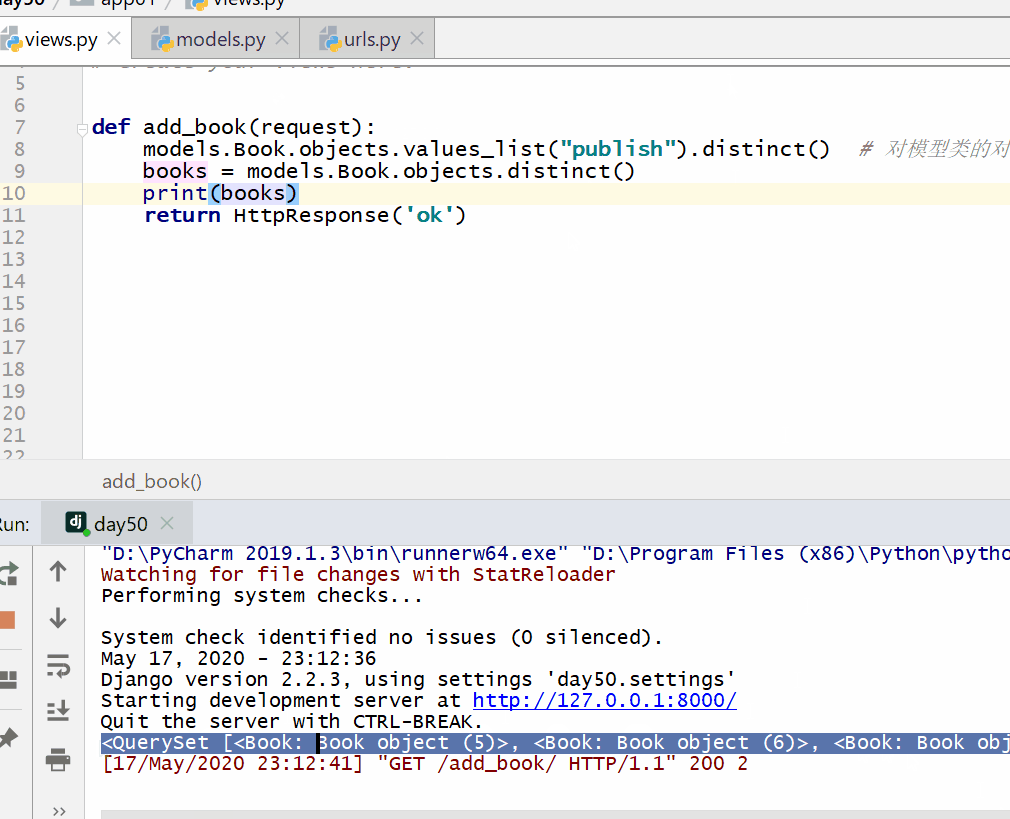
filter() 方法基于双下划线的模糊查询(exclude 同理)。
注意:filter 中运算符号只能使用等于号 = ,不能使用大于号 > ,小于号 <>
__in 用于读取区间,= 号后面为列表 。
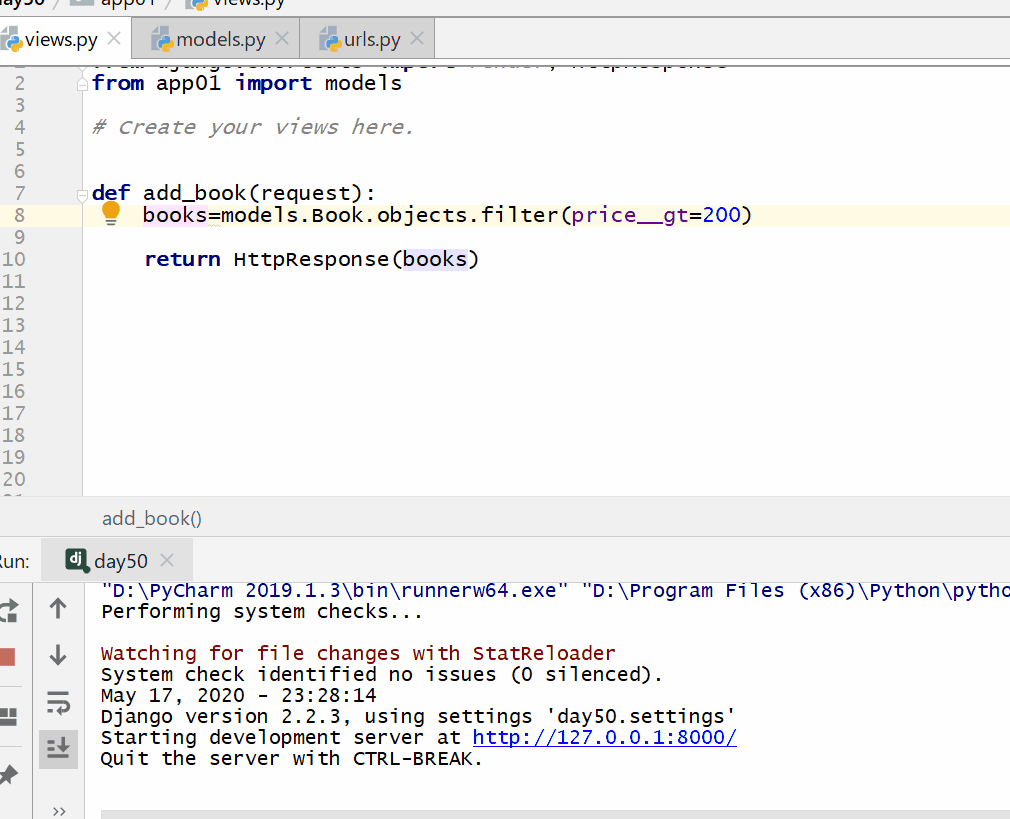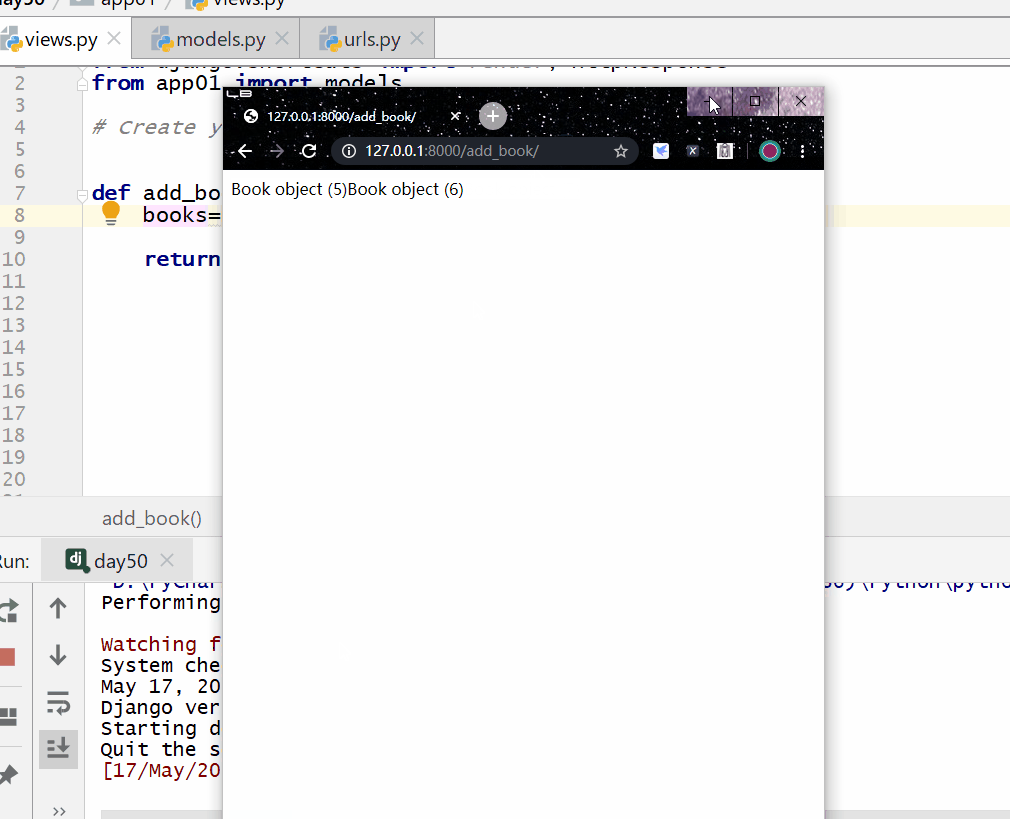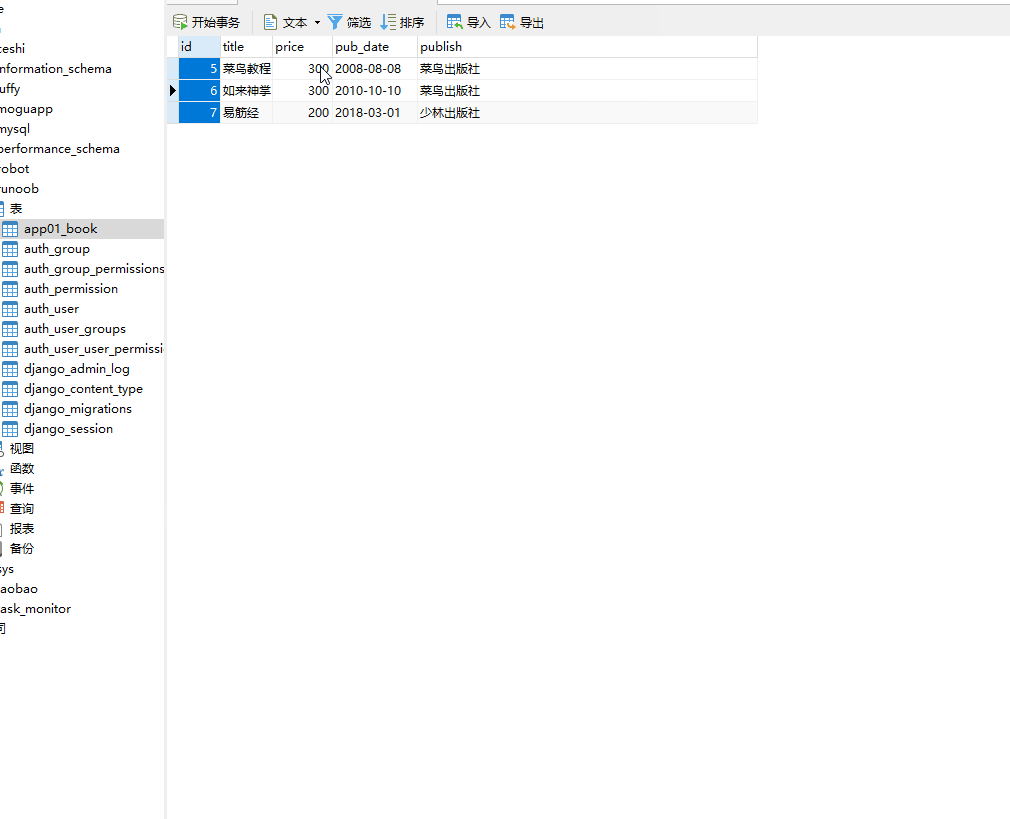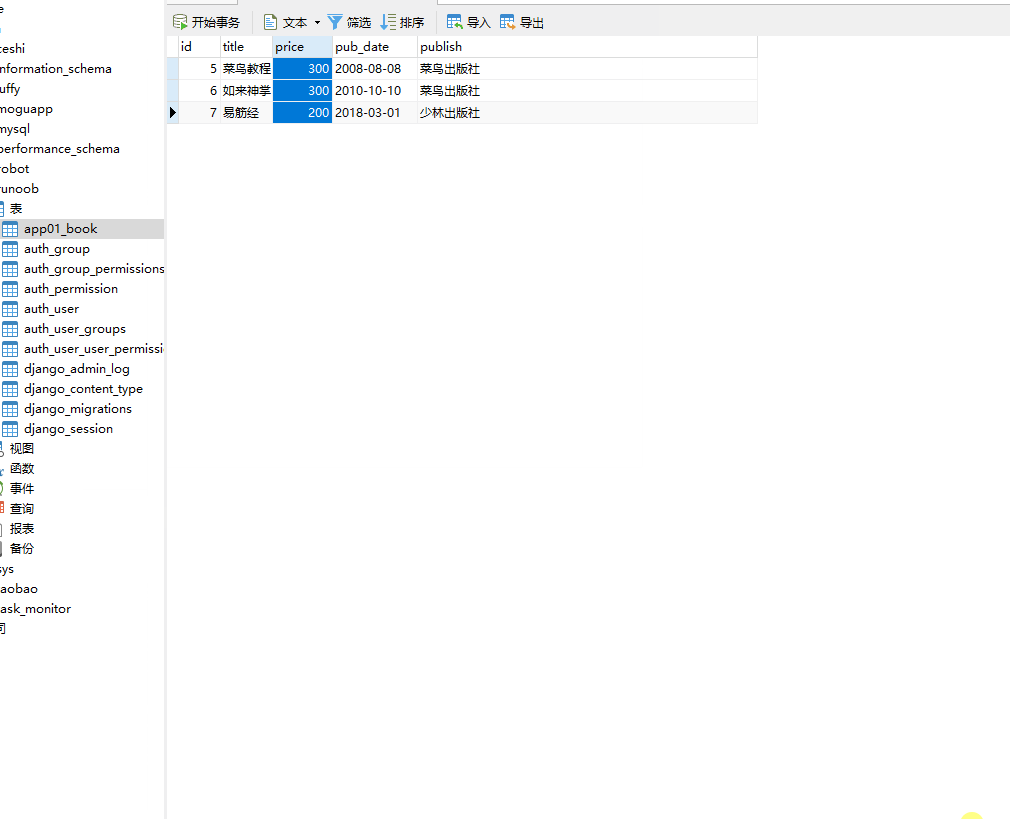
__gt 大于号 ,= 号后面为数字。
# 查询价格大于200的数据 books = models.Book.objects.filter(price__gt=200)
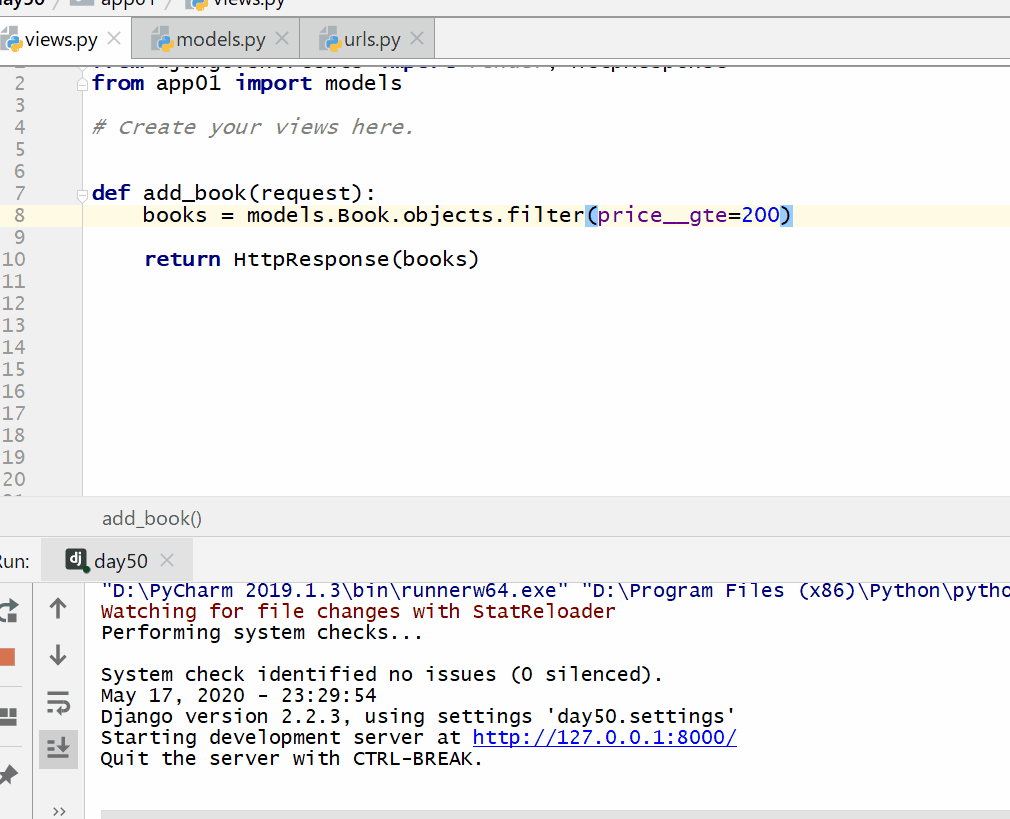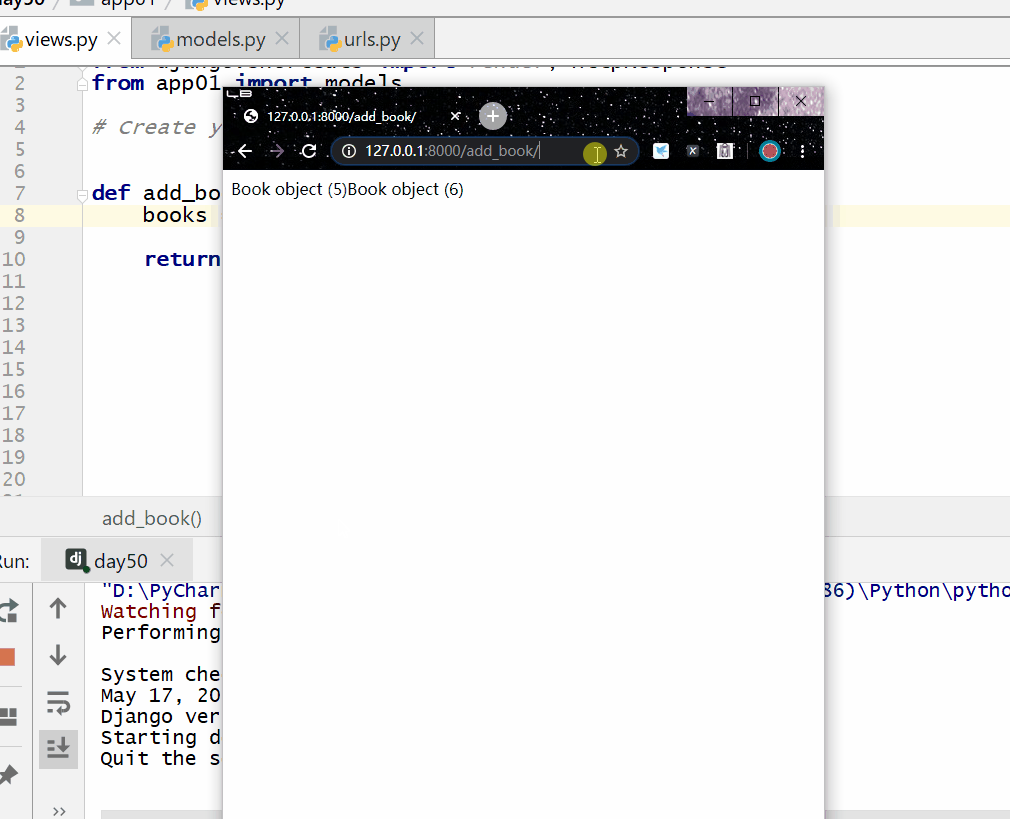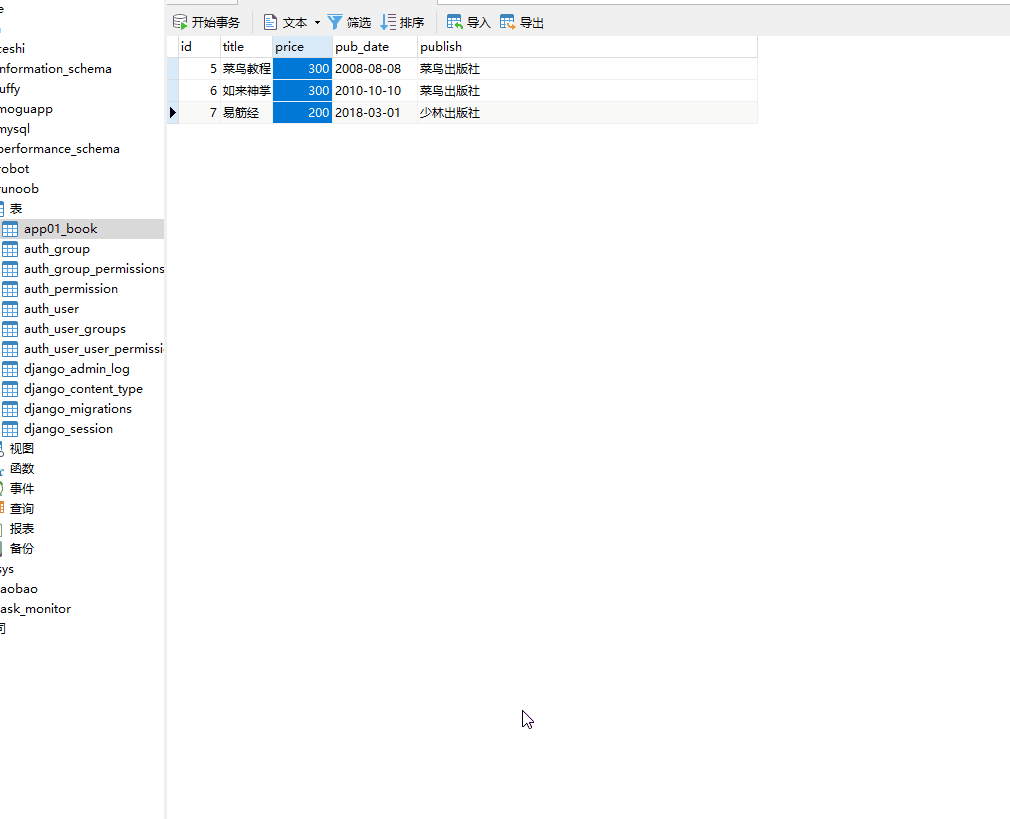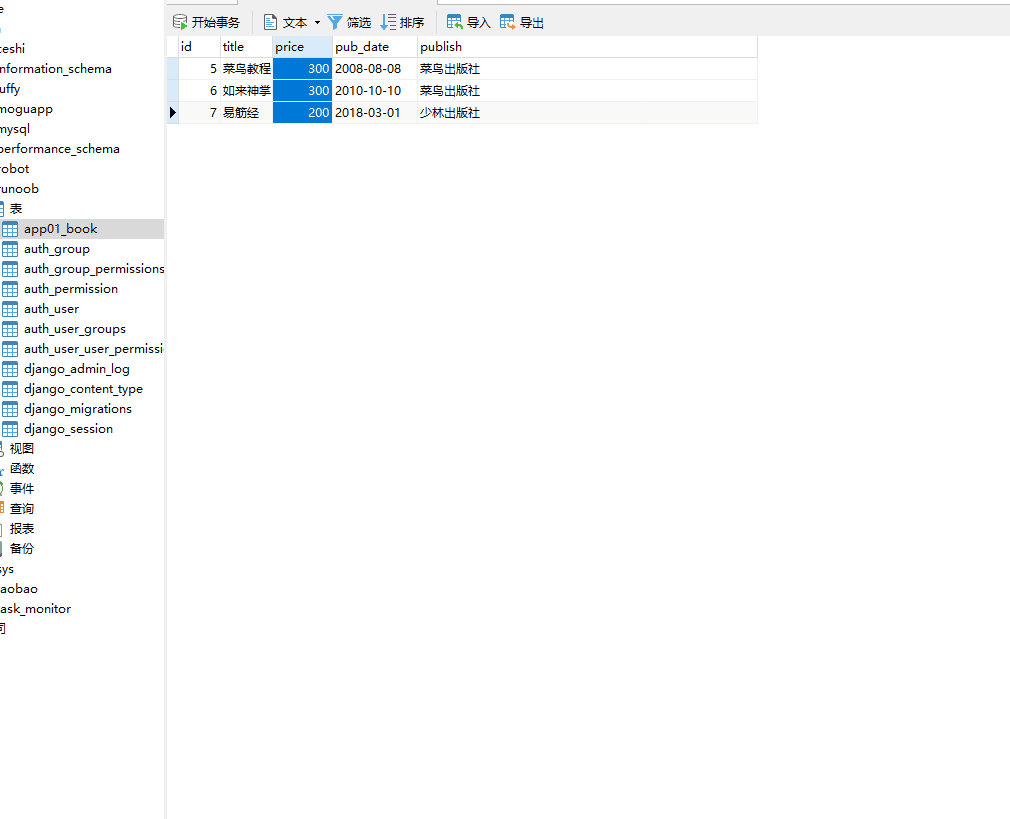
# 查询价格大于等于200的数据 books = models.Book.objects.filter(price__gte=200)
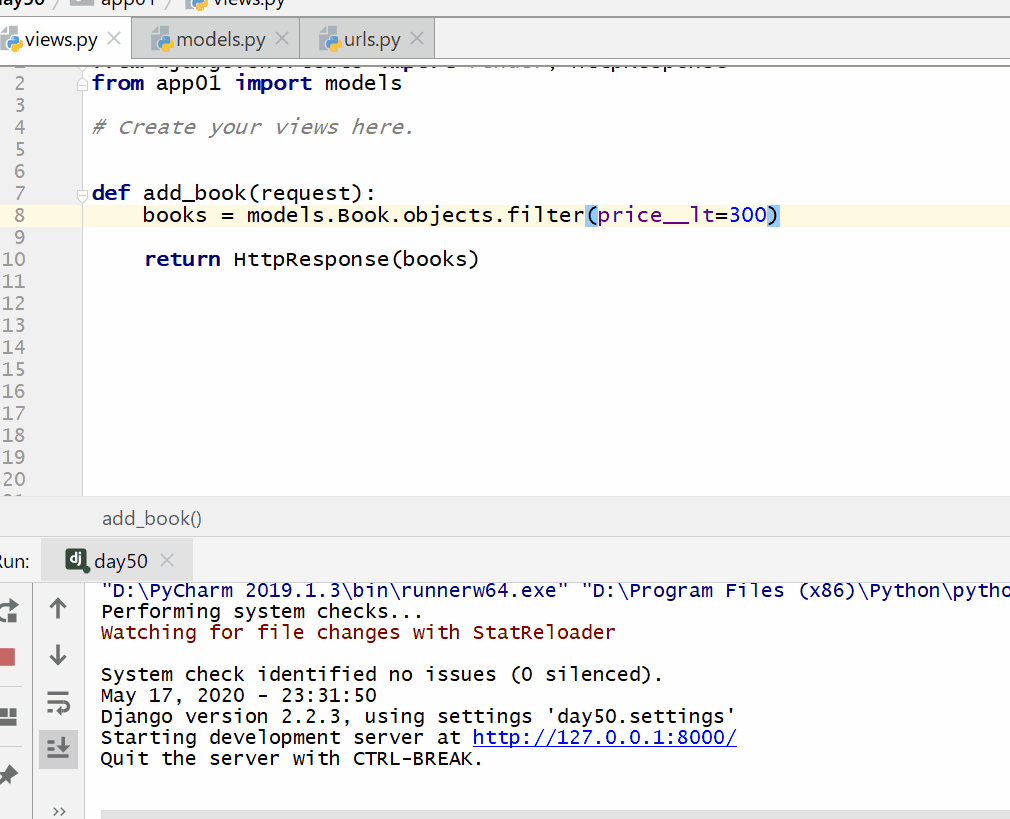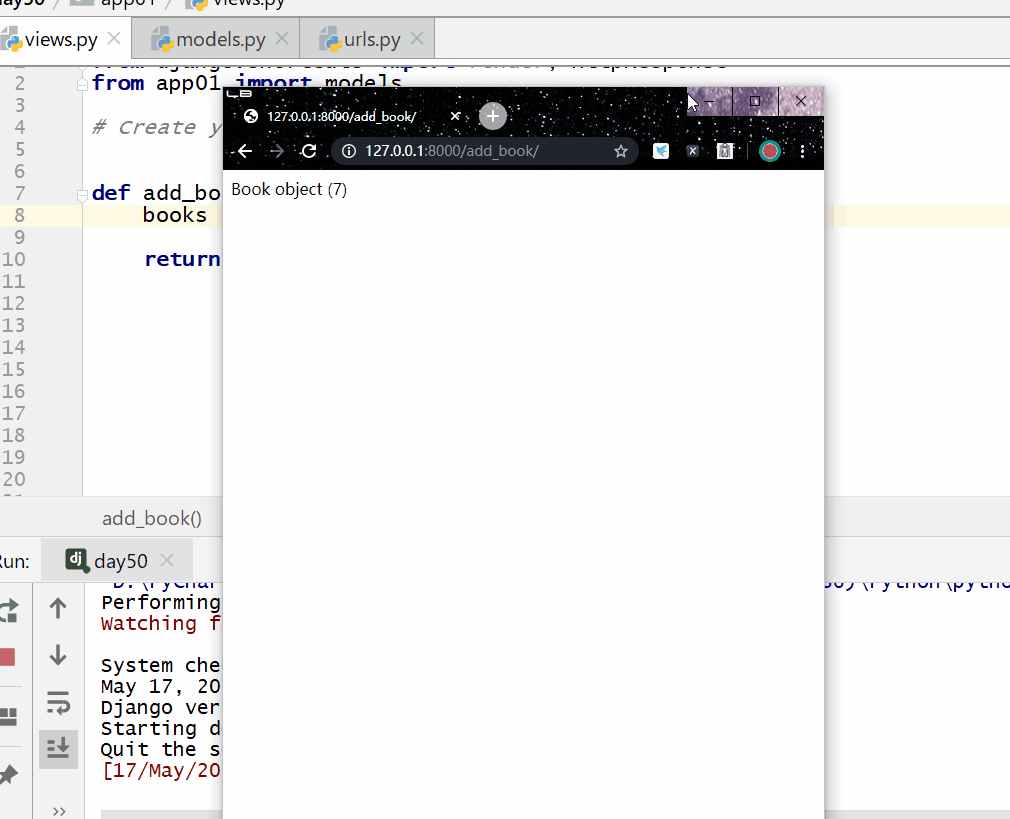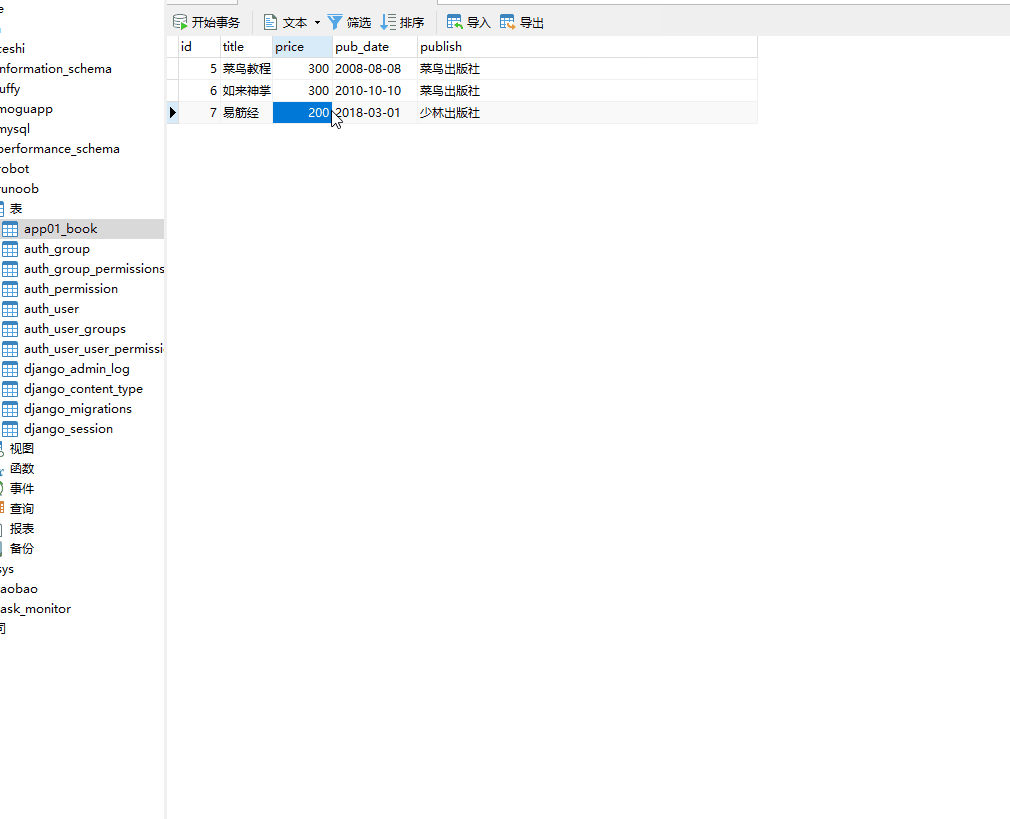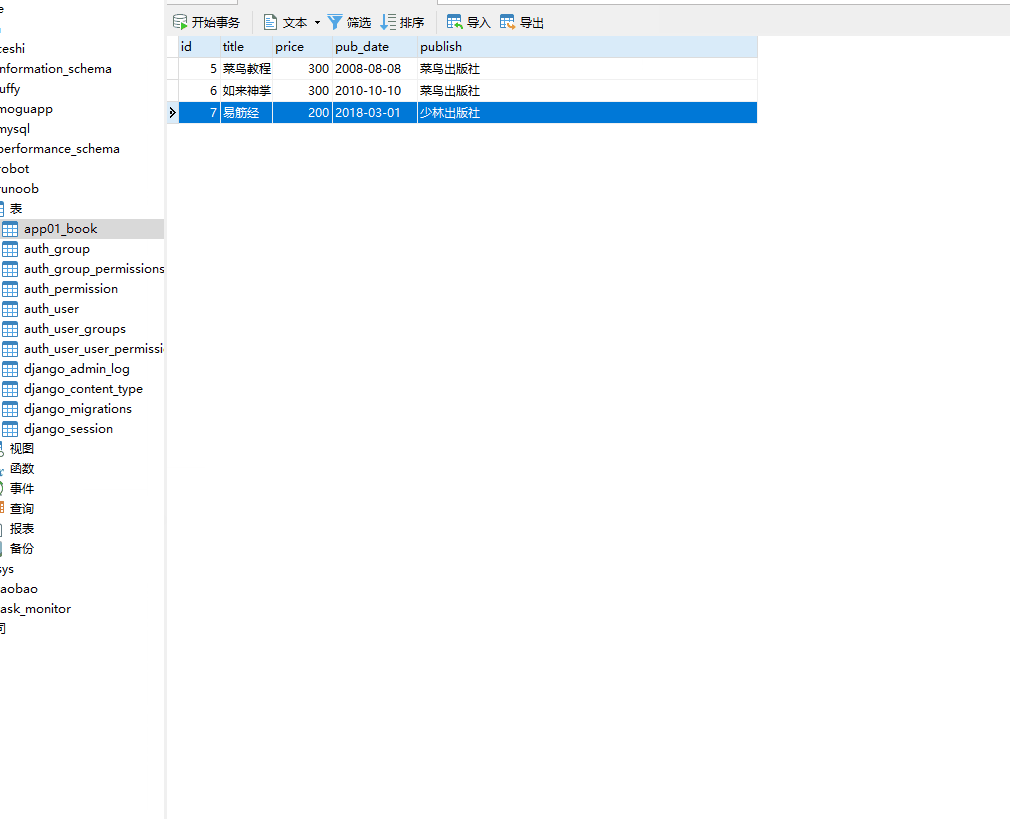
__lt 小于,=号后面为数字。
# 查询价格小于300的数据 books=models.Book.objects.filter(price__lt=300)
__lte 小于等于,= 号后面为数字。
# 查询价格小于等于300的数据 books=models.Book.objects.filter(price__lte=300)
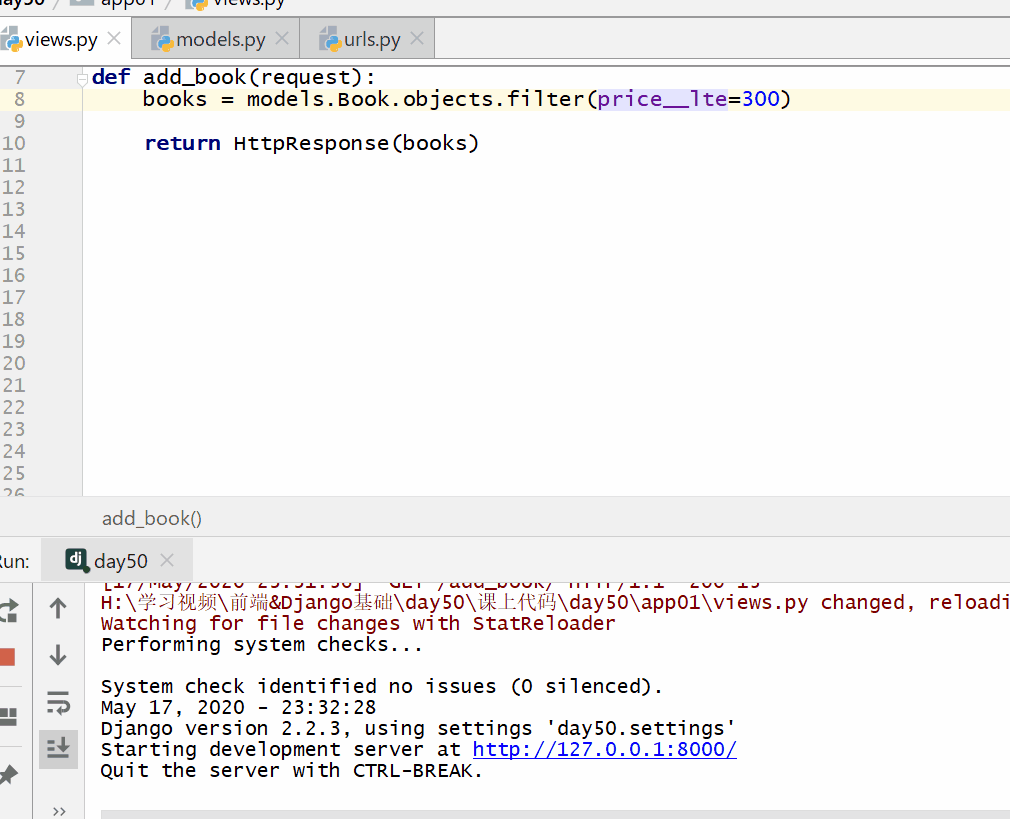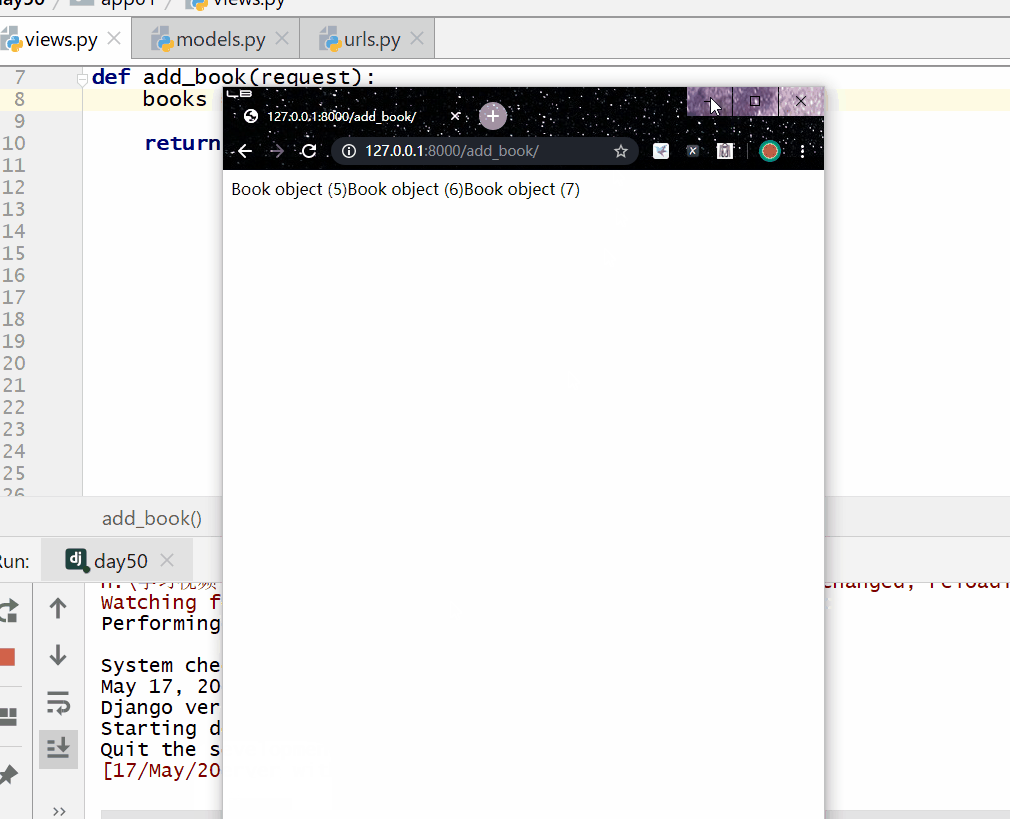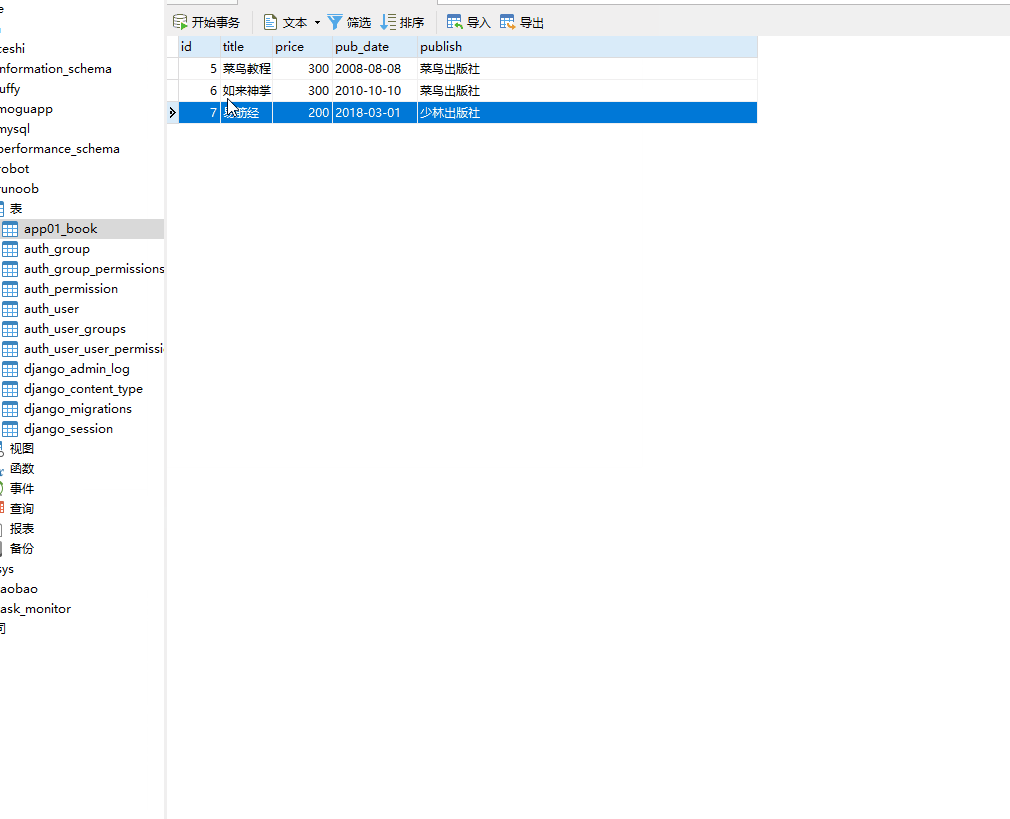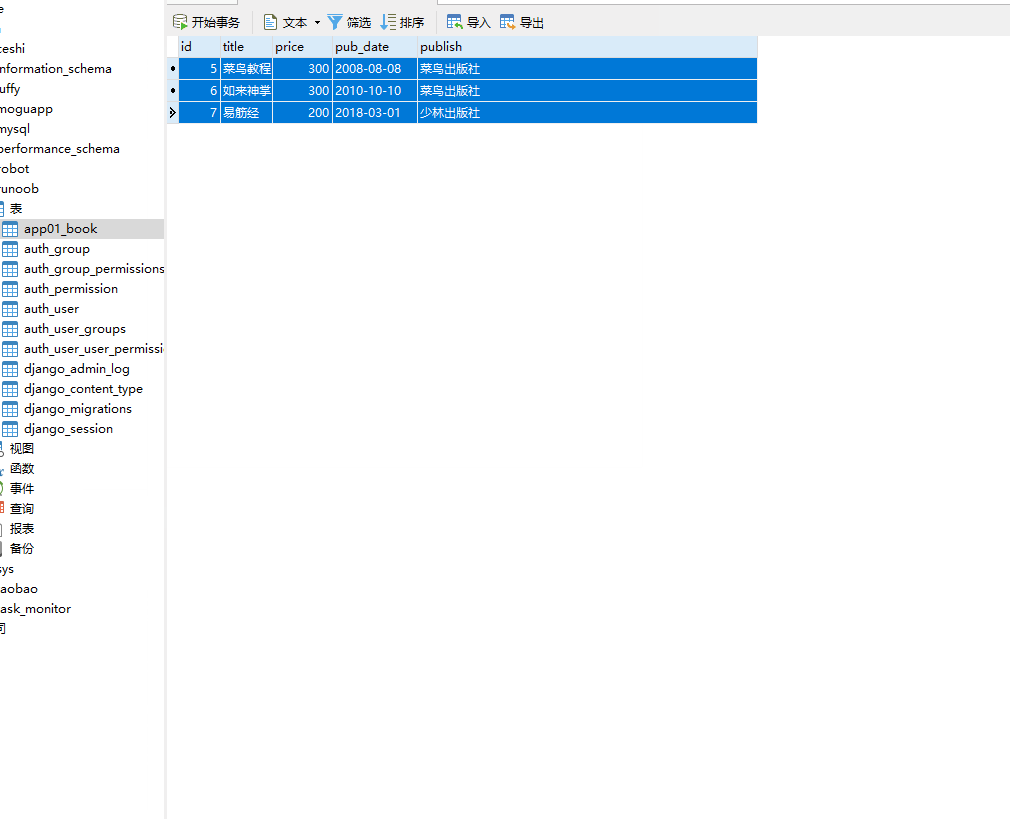
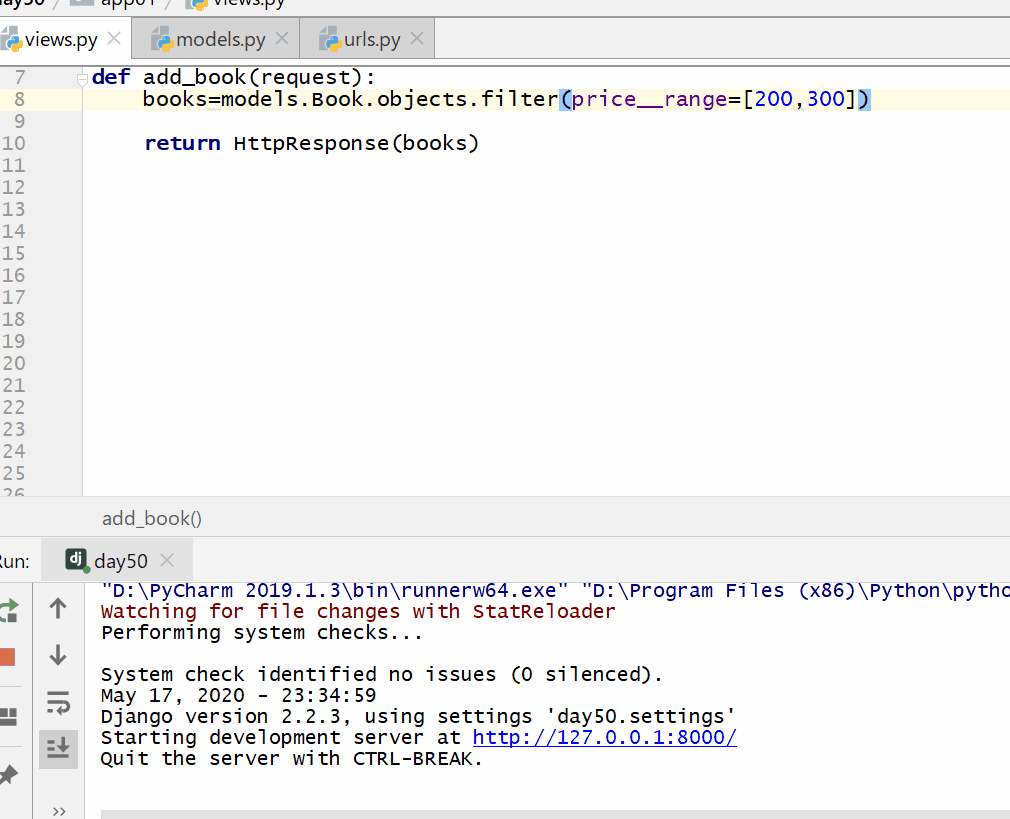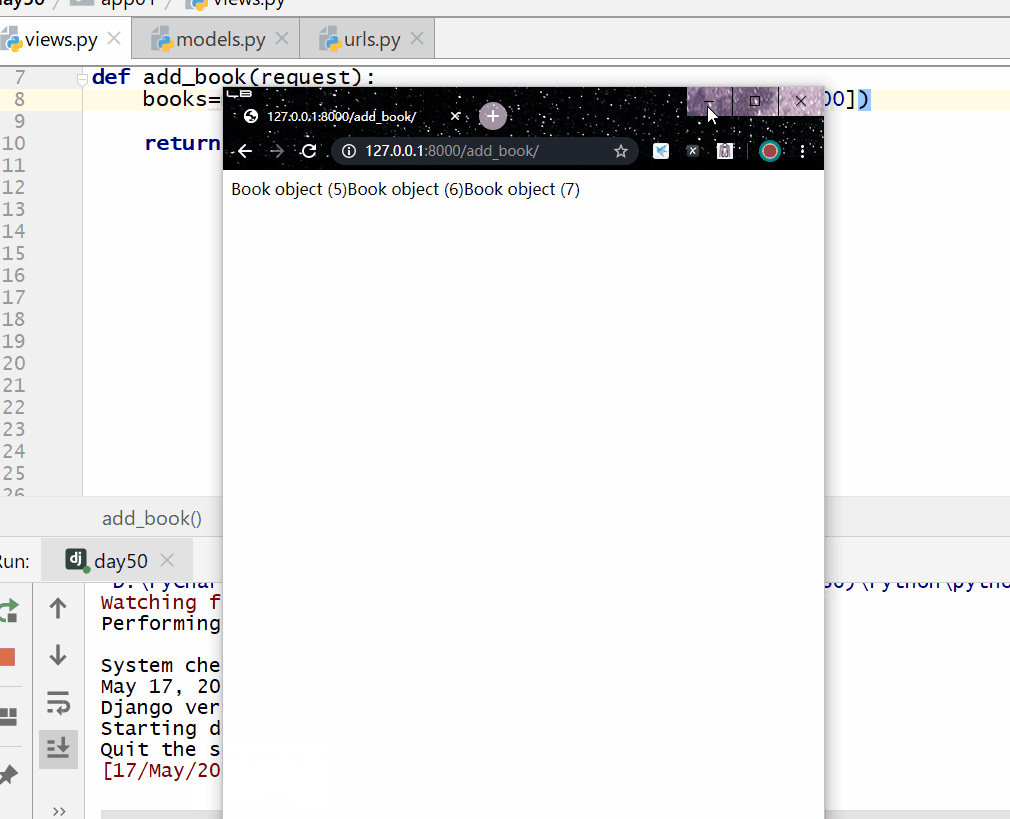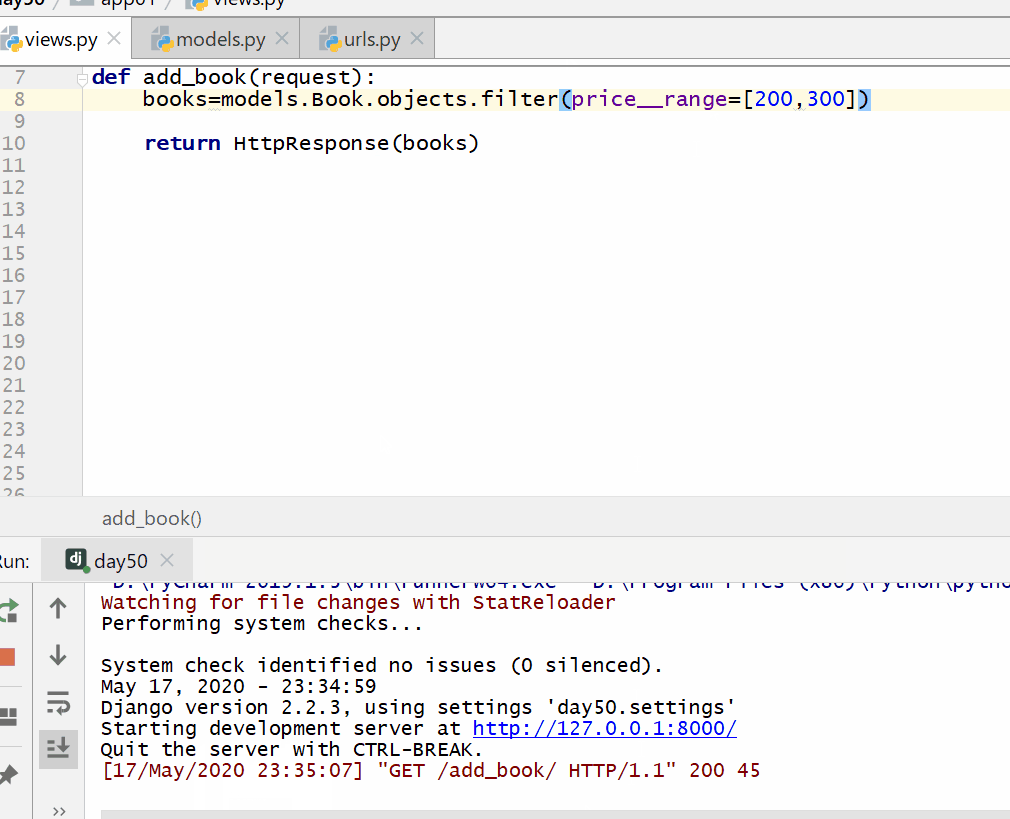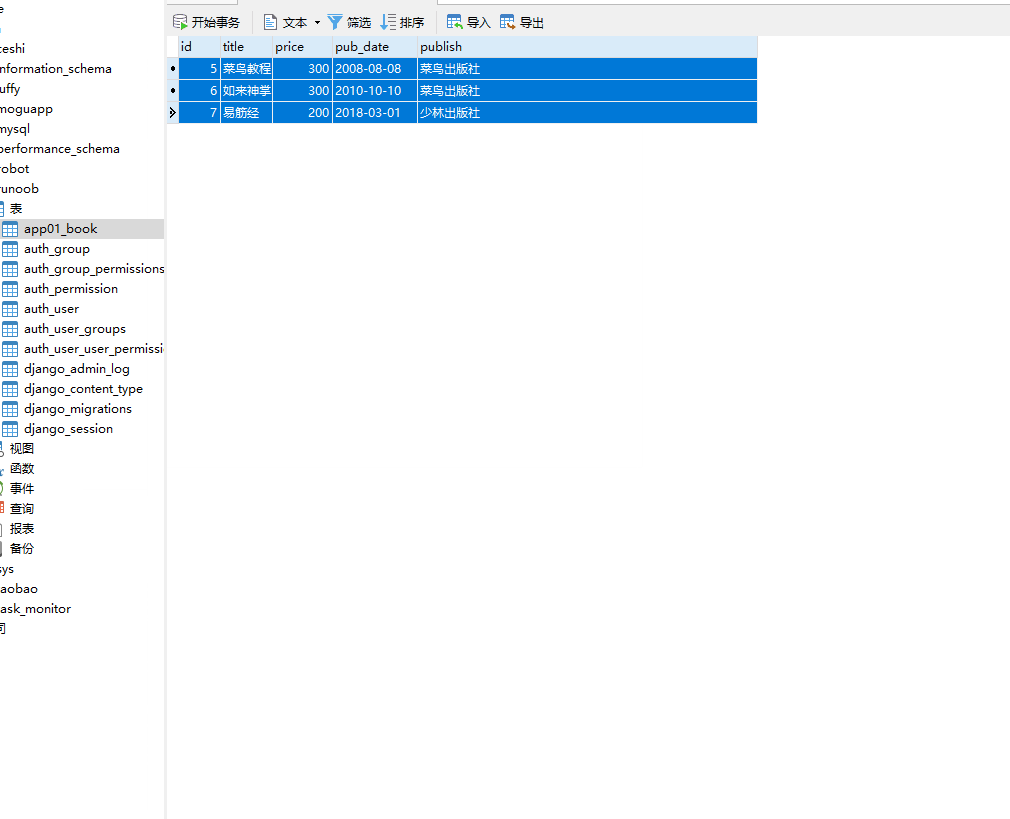
__range 在 ... 之间,左闭右闭区间,= 号后面为两个元素的列表。
books=models.Book.objects.filter(price__range=[200,300])
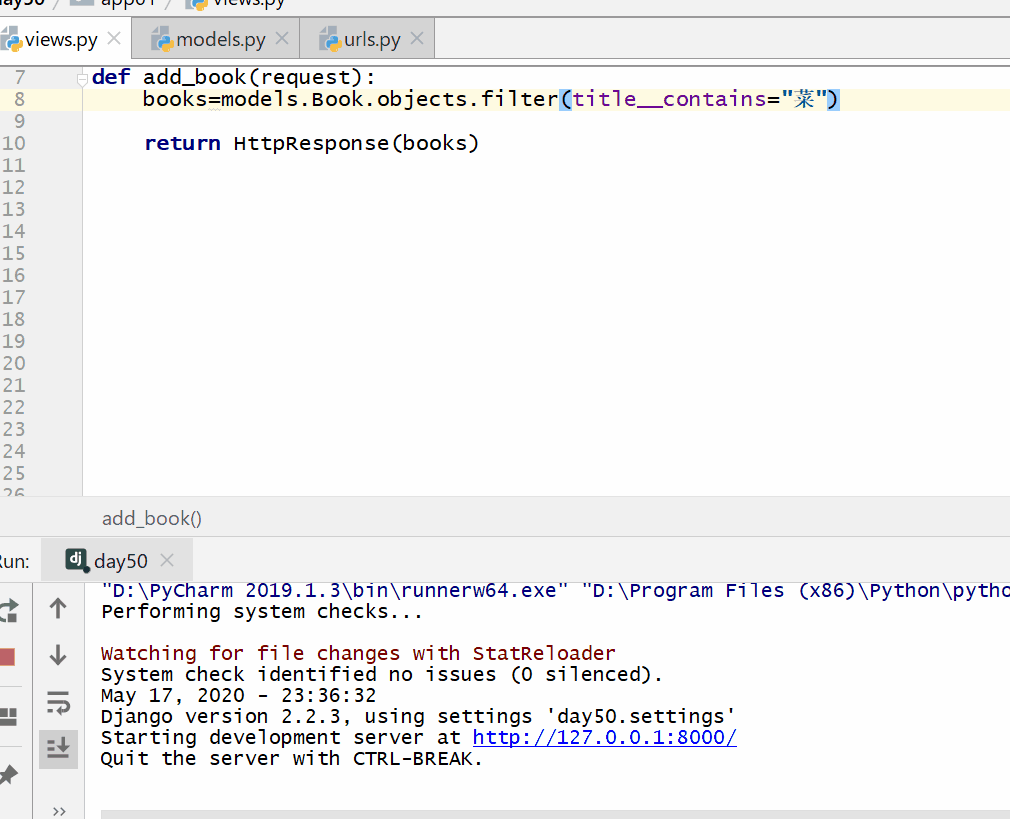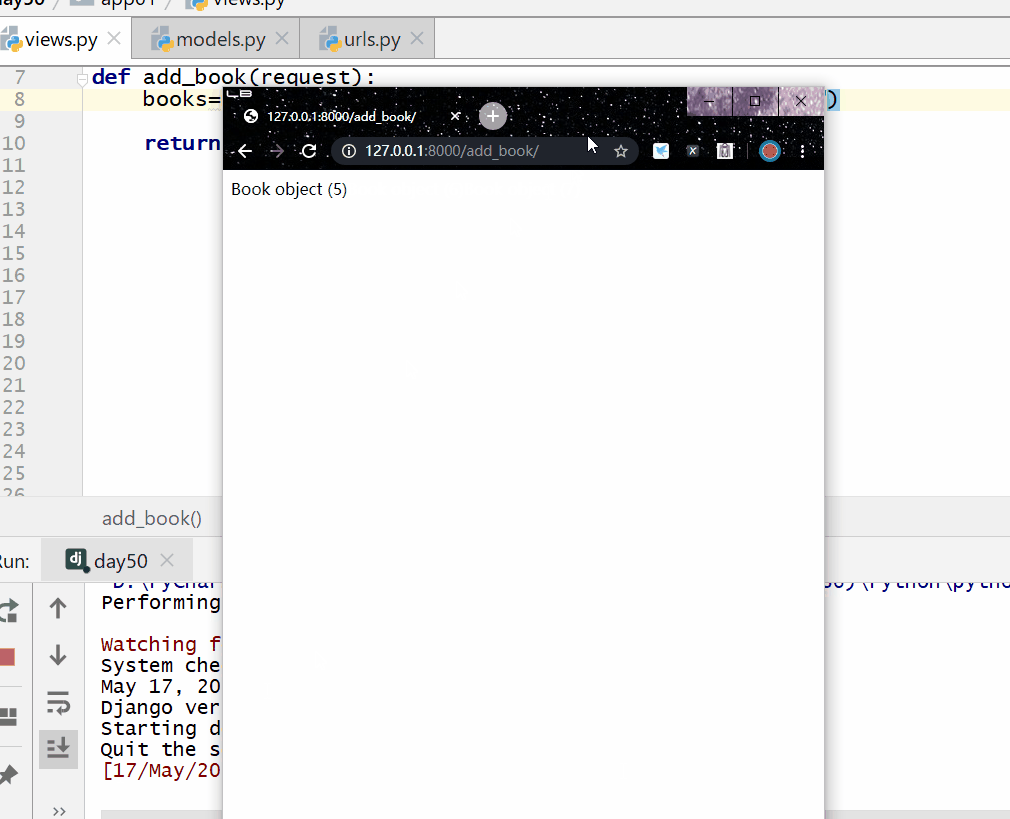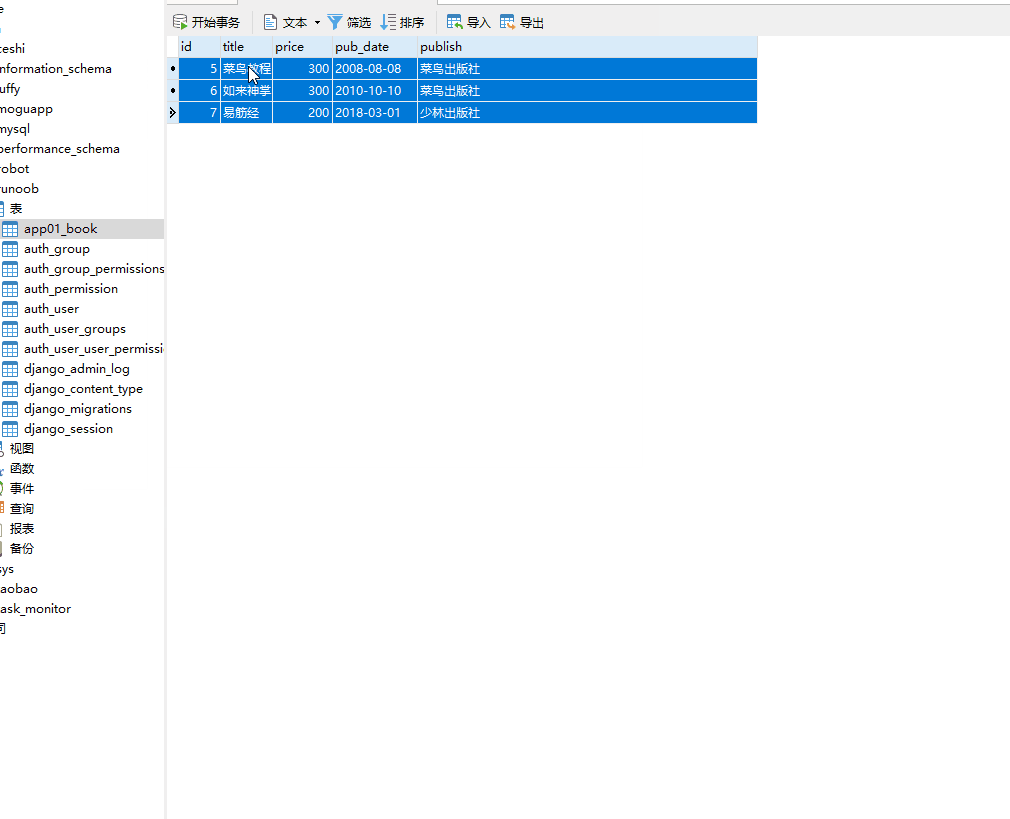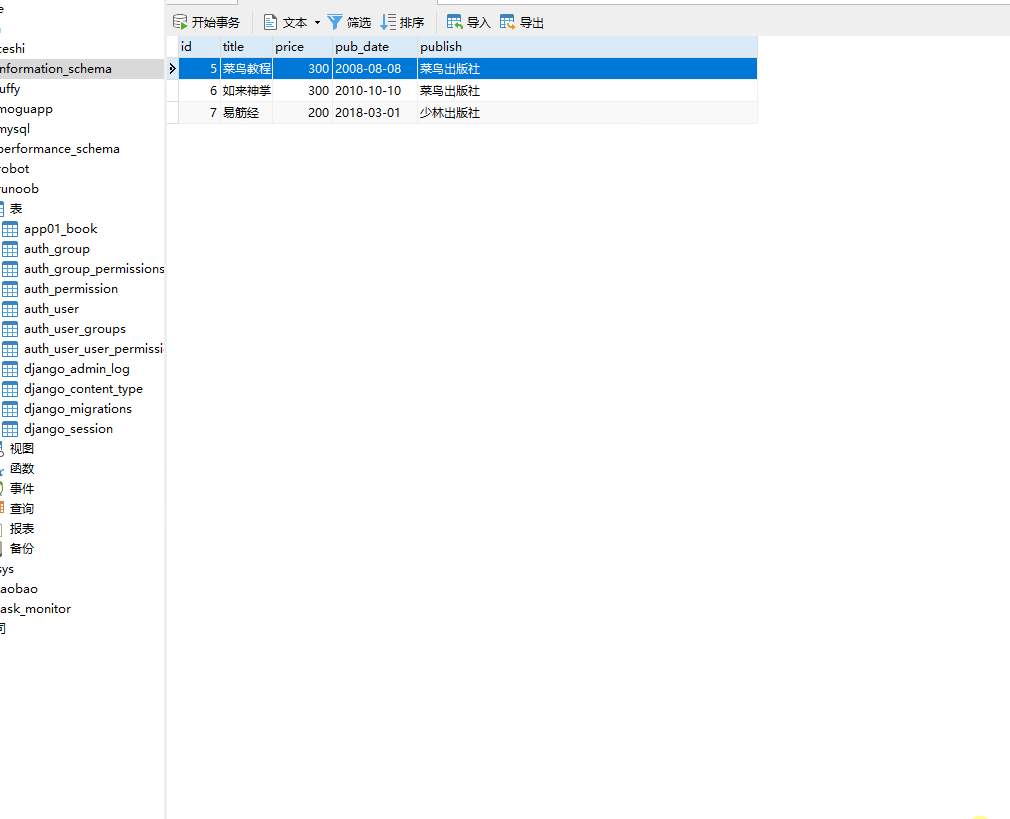
__contains 包含,= 号后面为字符串。
books=models.Book.objects.filter(title__contains="菜")
__icontains 不区分大小写的包含,= 号后面为字符串。
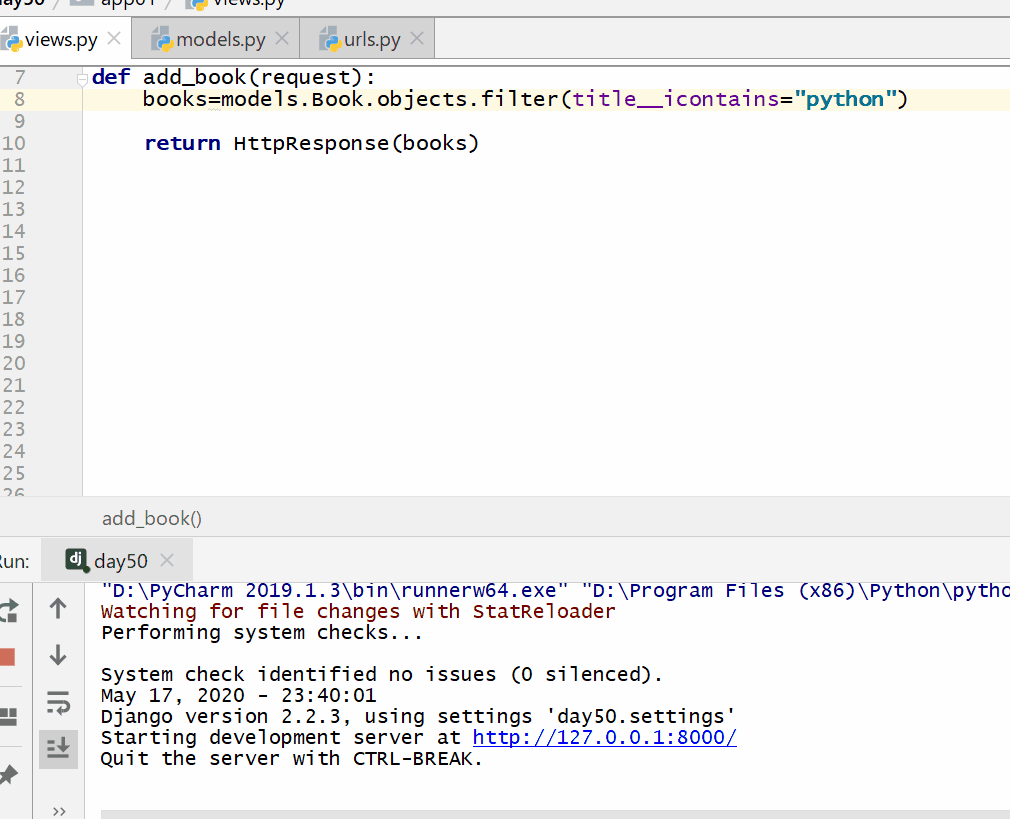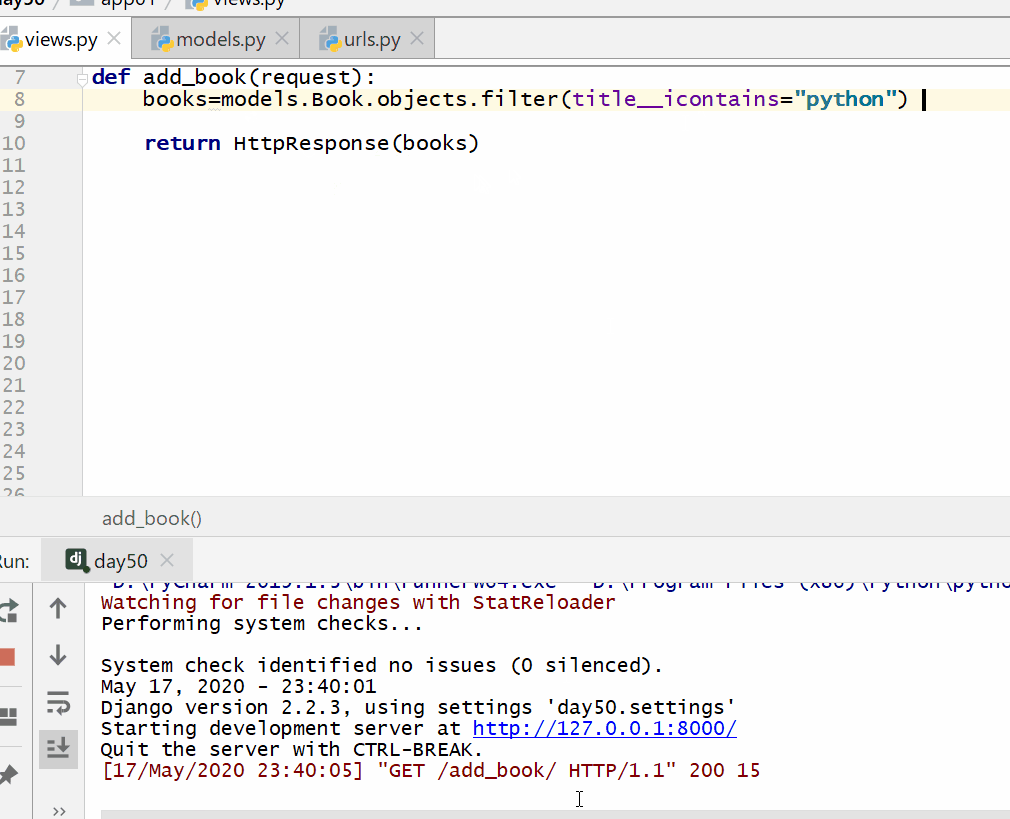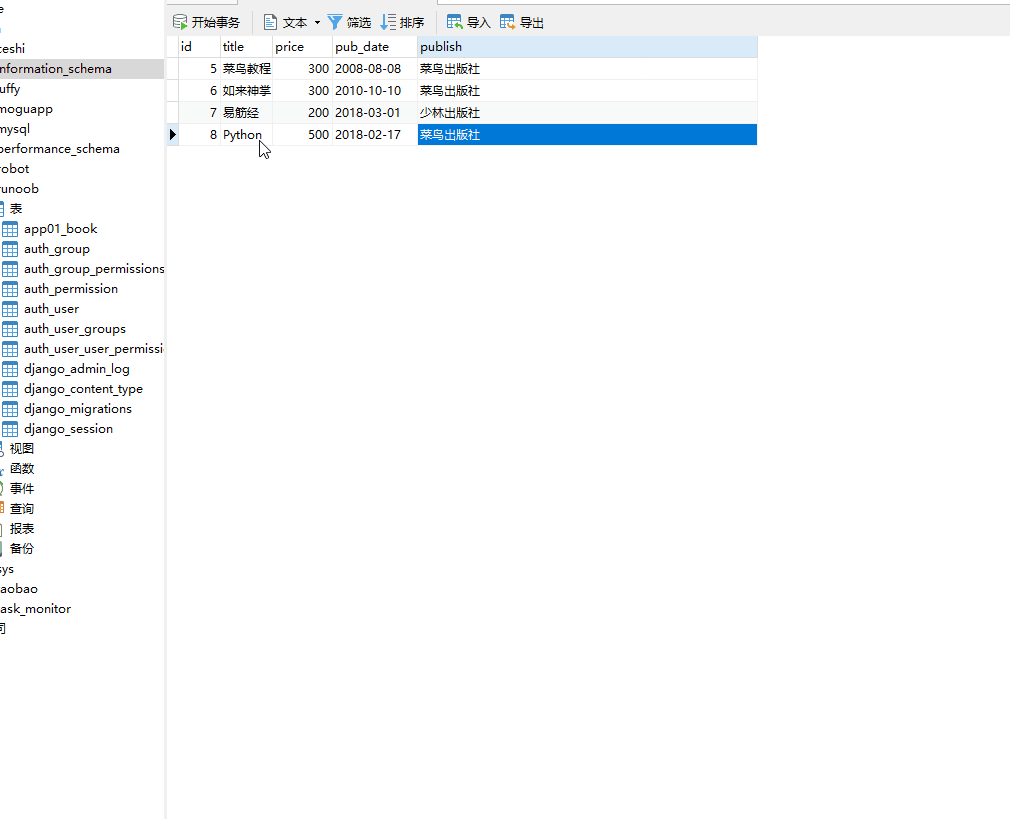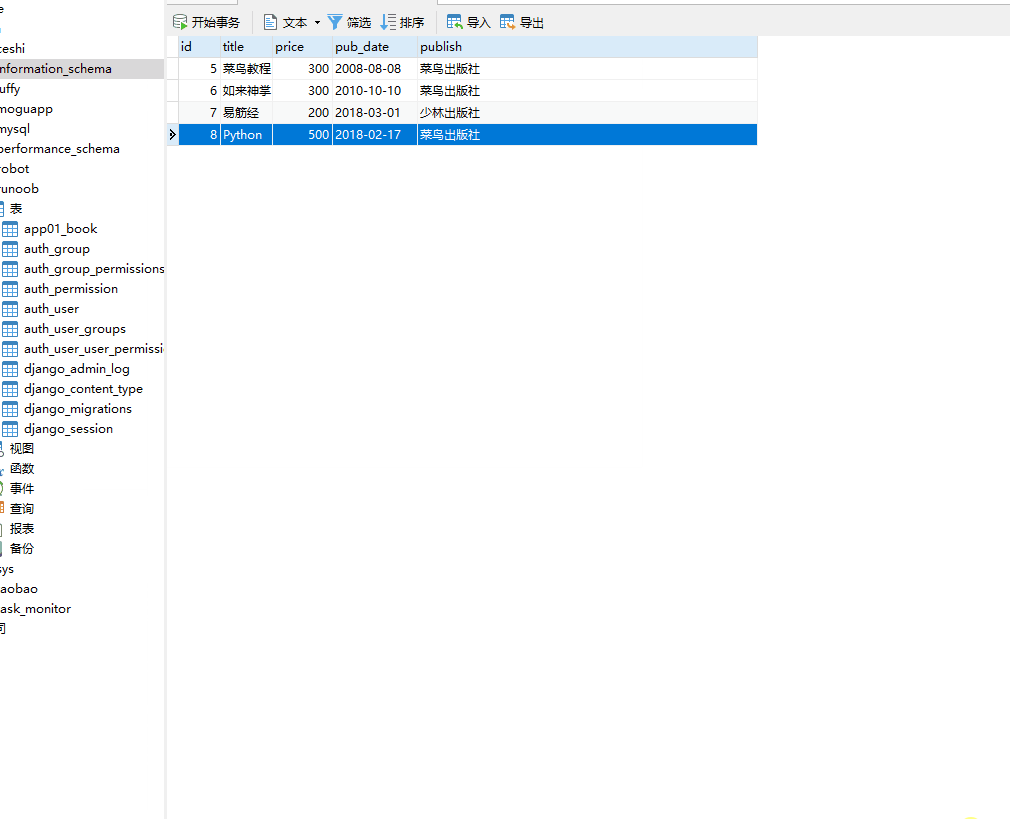
books=models.Book.objects.filter(title__icontains="python") # 不区分大小写
__startswith 以指定字符开头,= 号后面为字符串。
books=models.Book.objects.filter(title__startswith="菜")
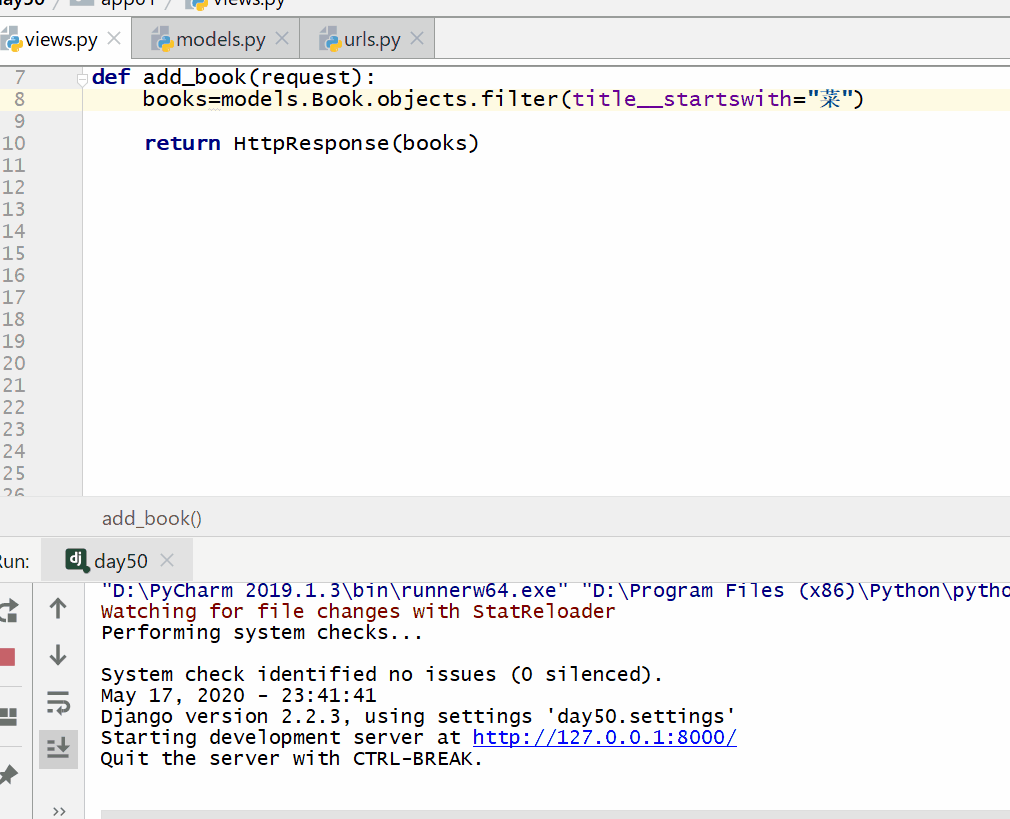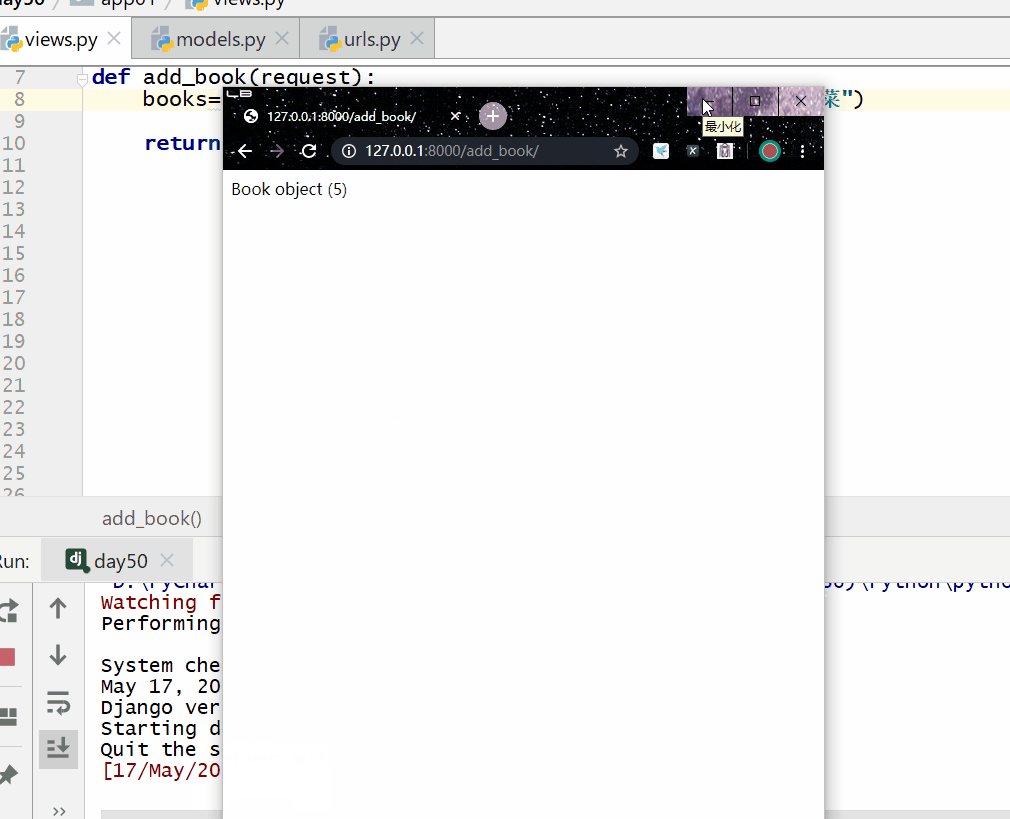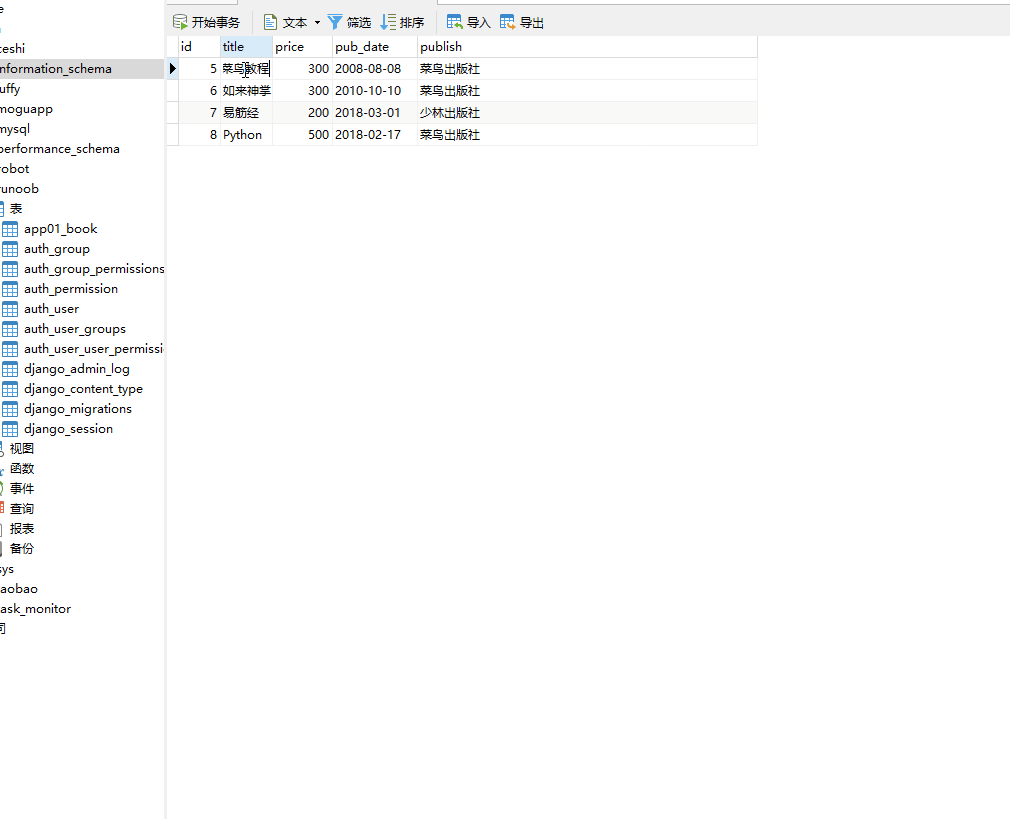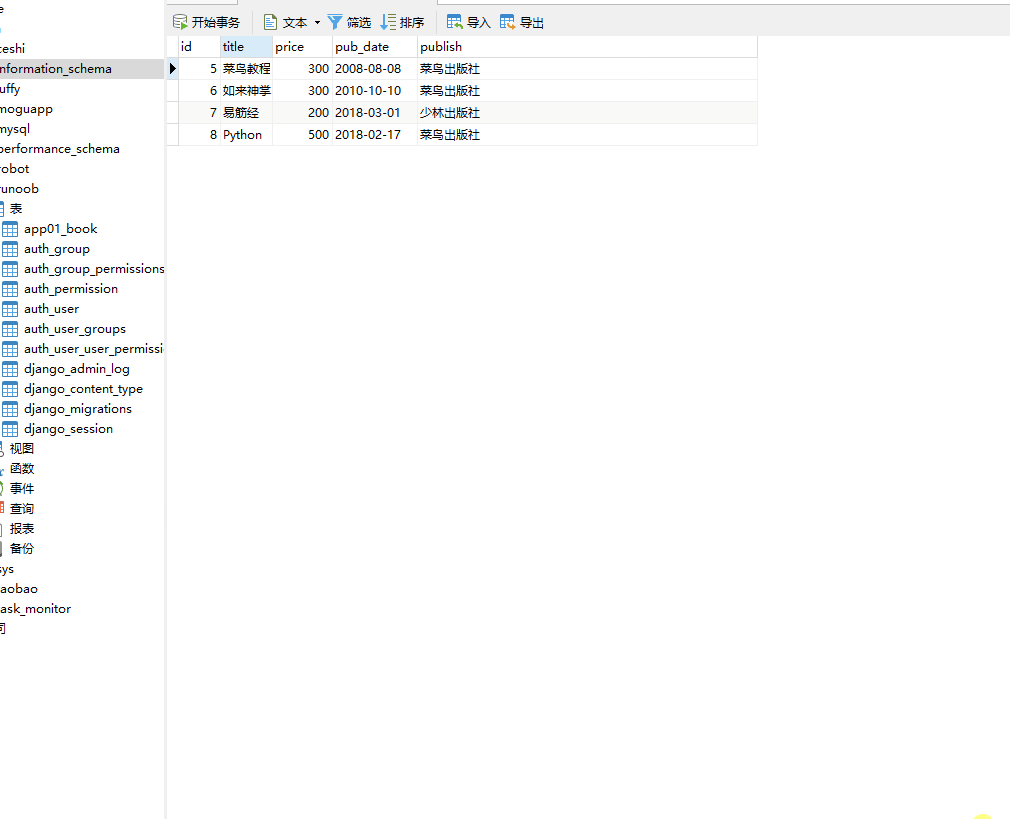
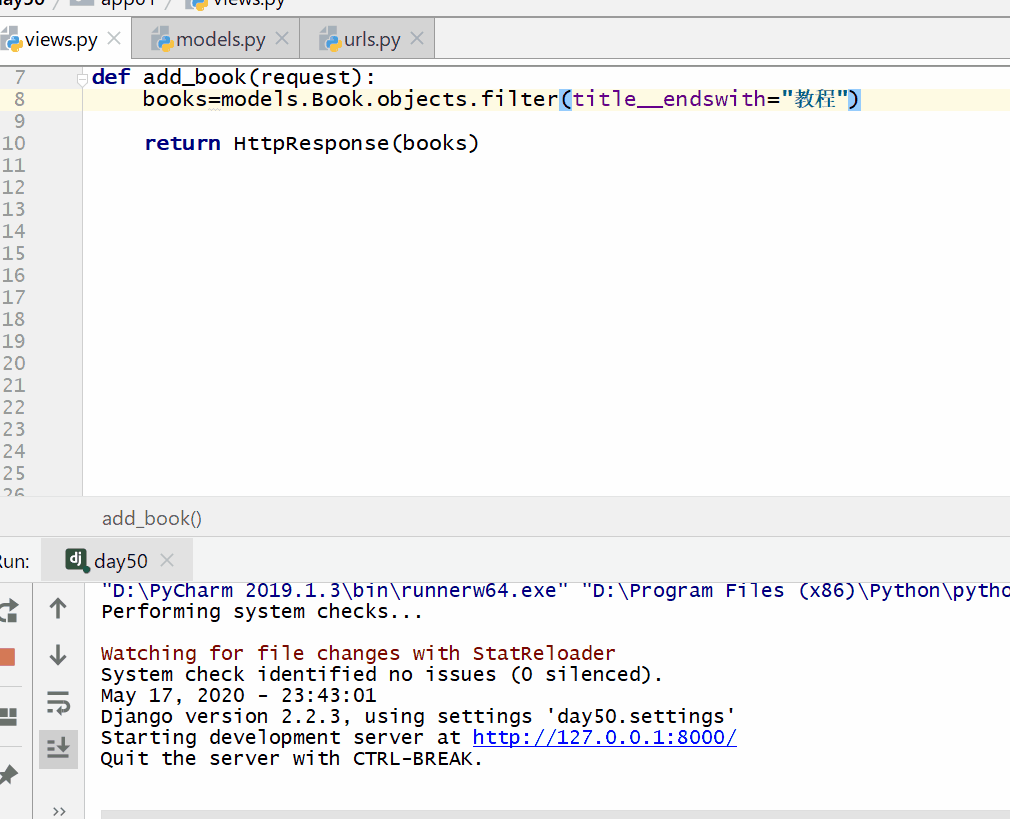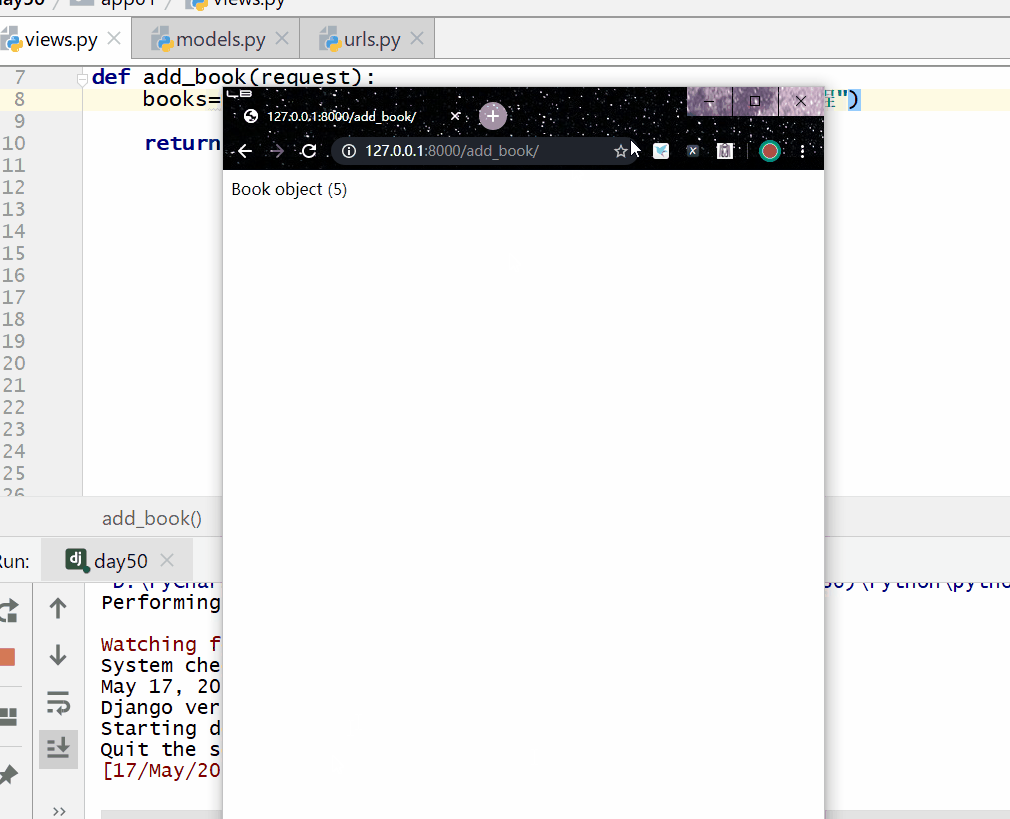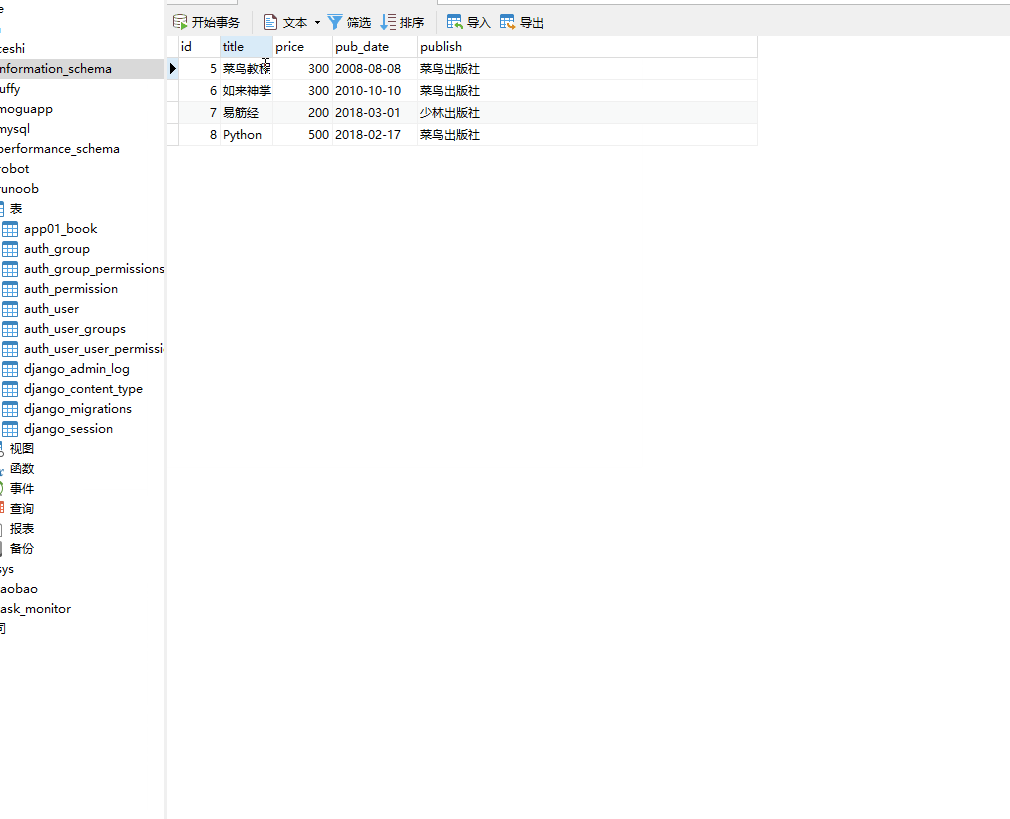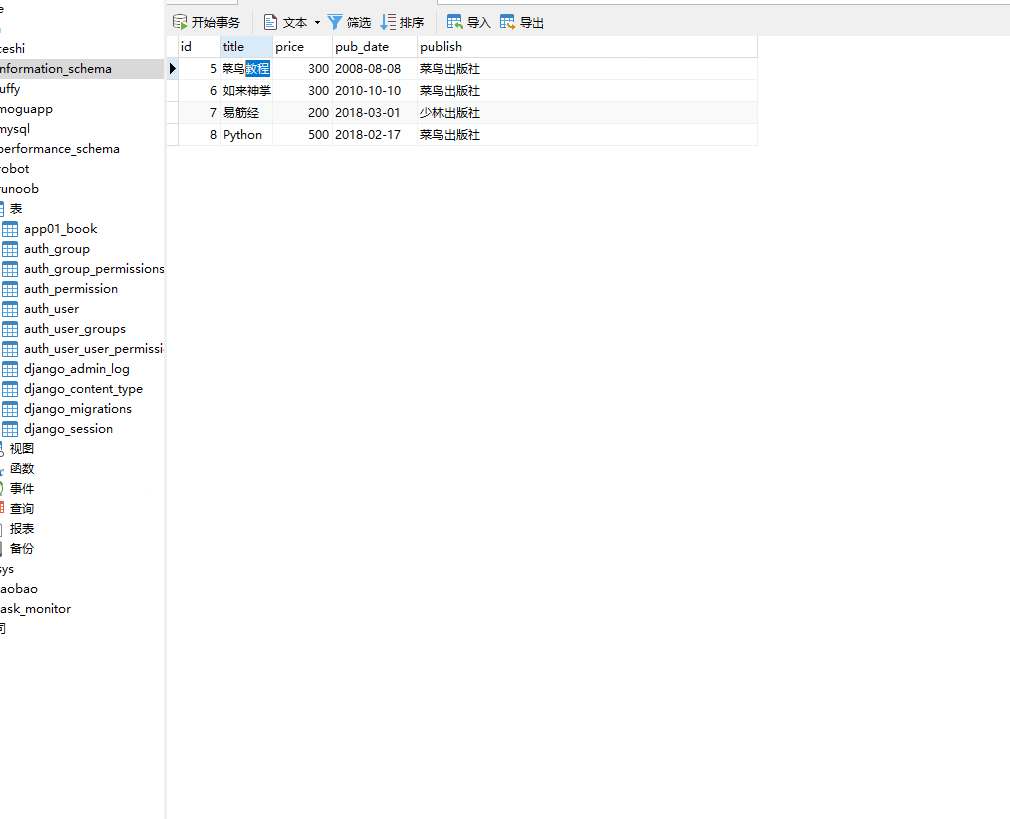
__endswith 以指定字符结尾,= 号后面为字符串。
books=models.Book.objects.filter(title__endswith="教程")
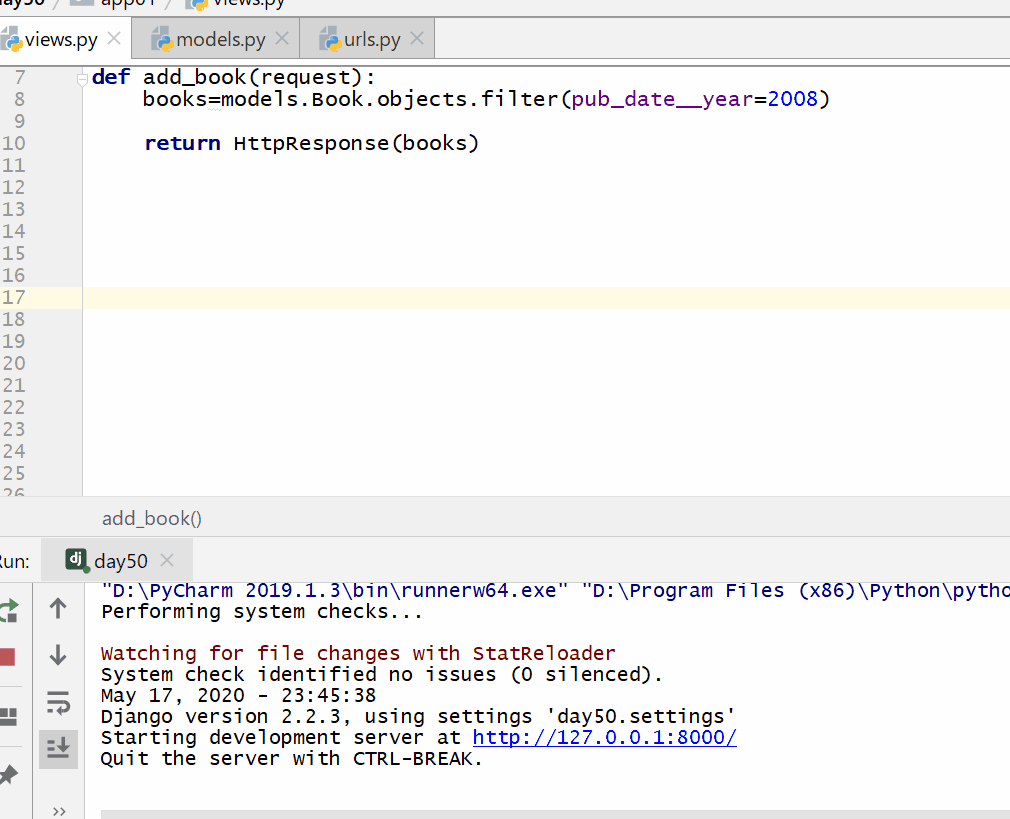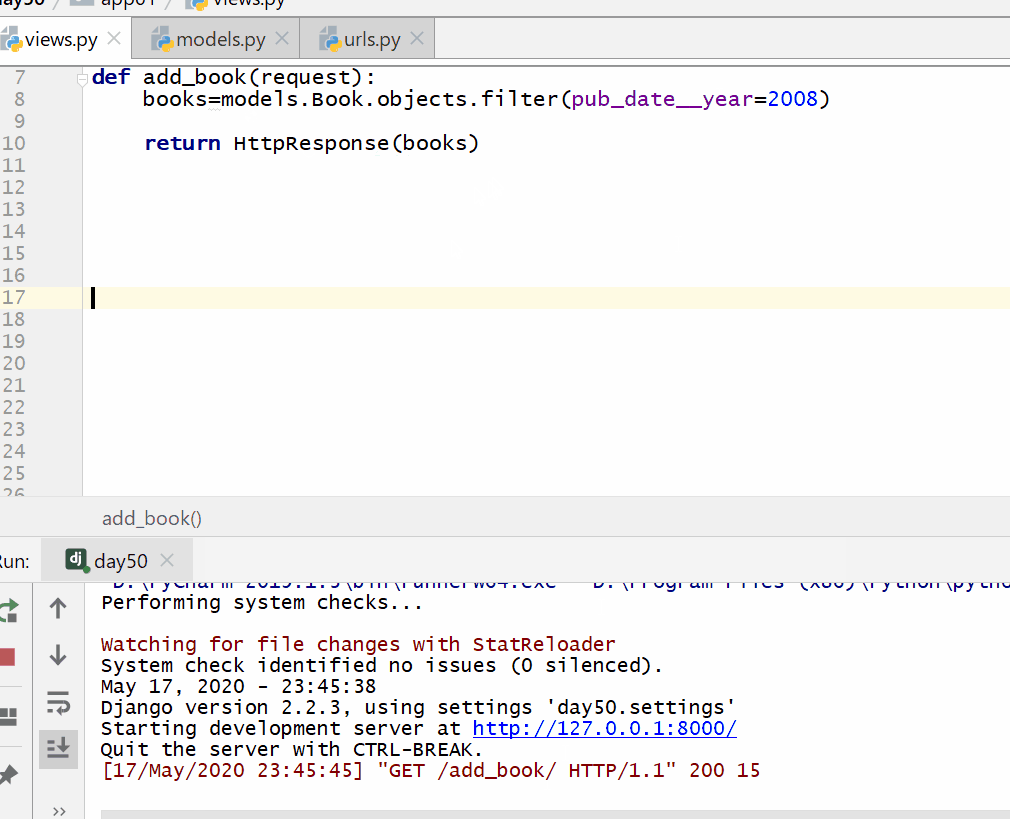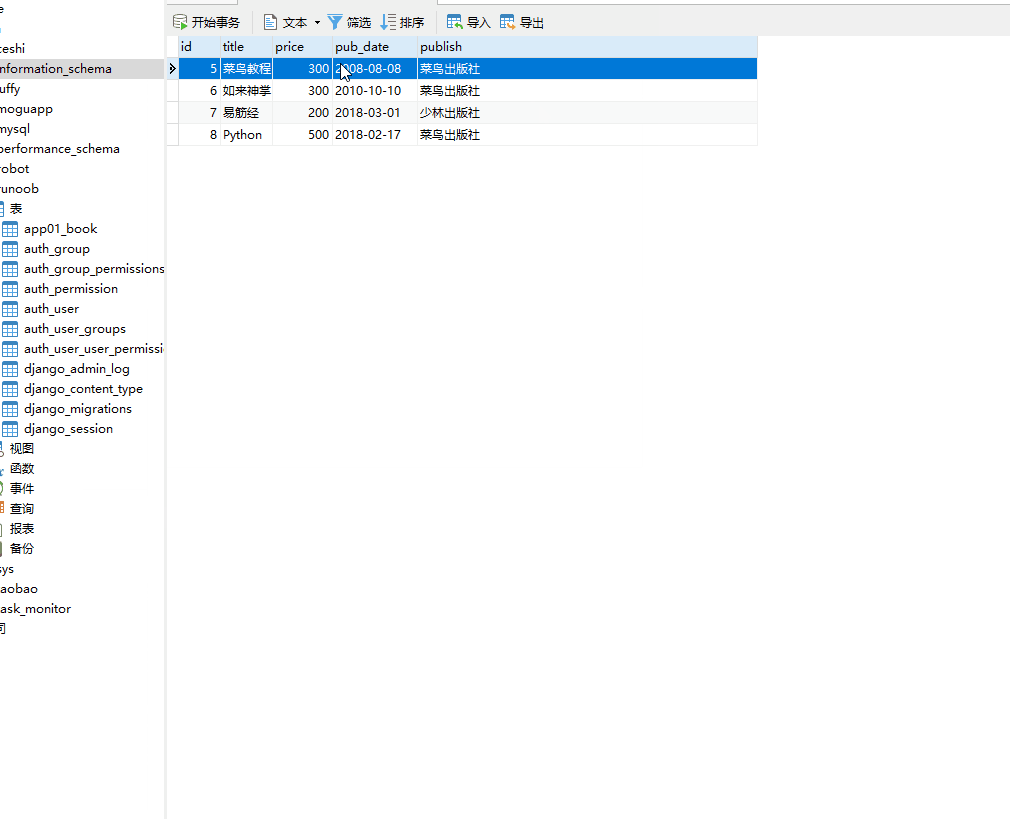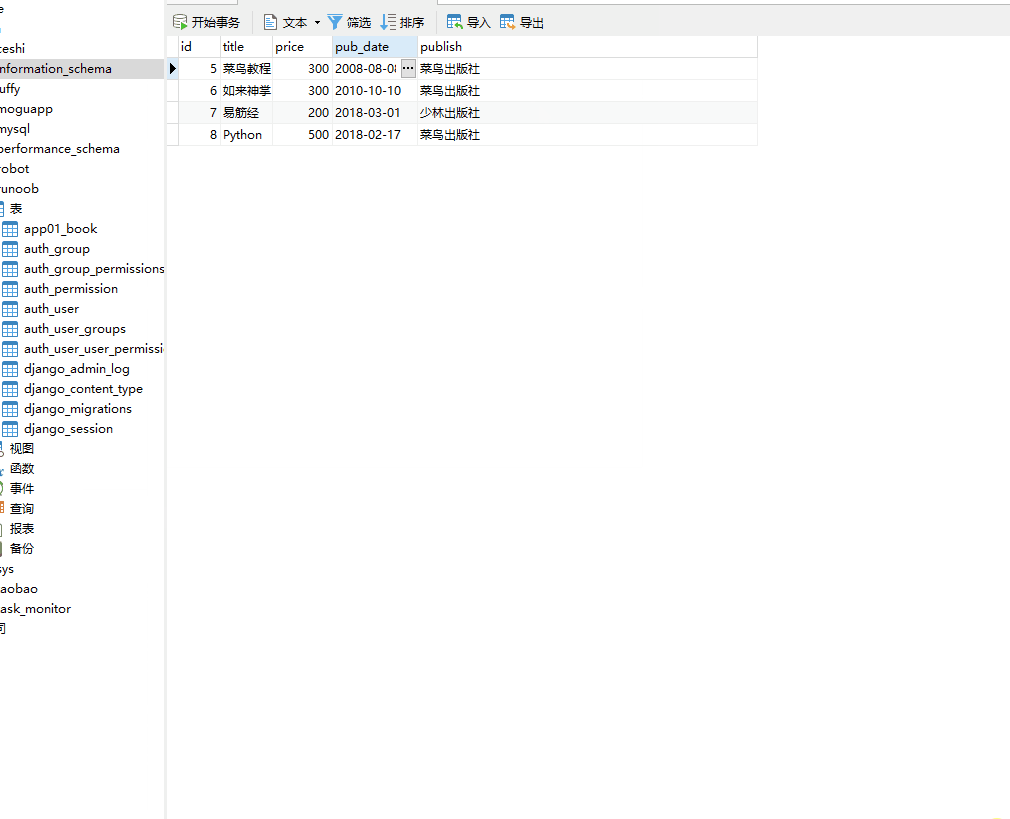
__year 是 DateField 数据类型的年份,= 号后面为数字。
books=models.Book.objects.filter(pub_date__year=2008)
__month 是DateField 数据类型的月份,= 号后面为数字。
books=models.Book.objects.filter(pub_date__month=10)
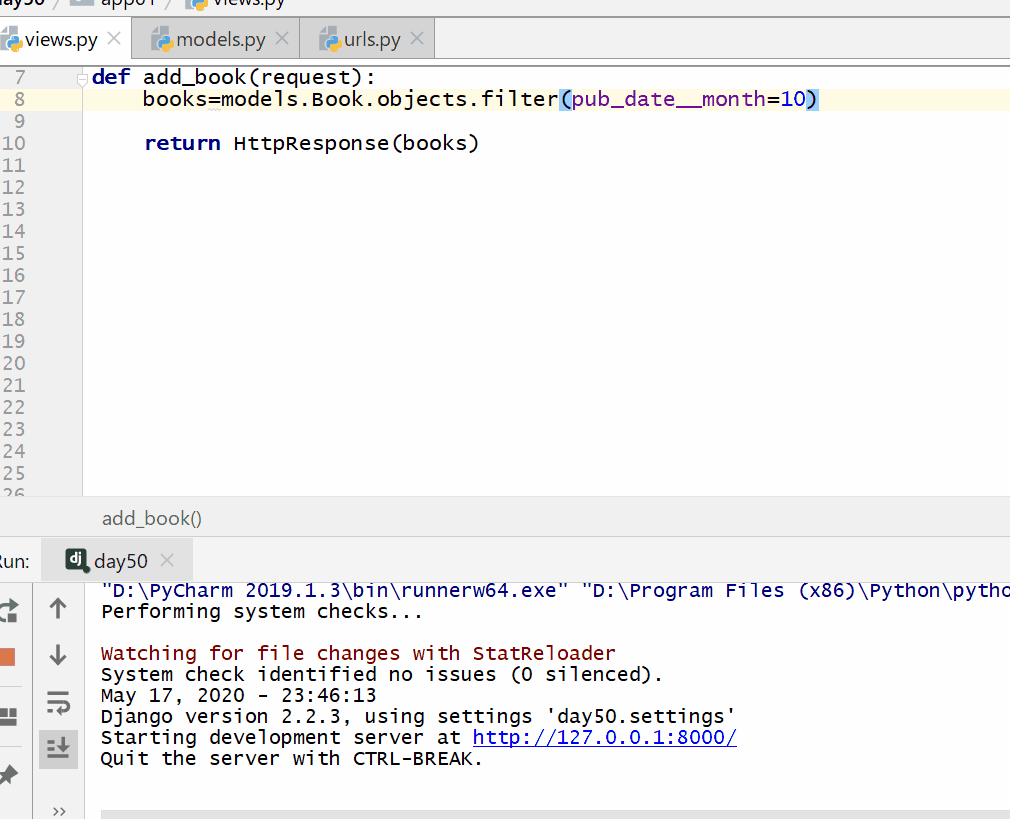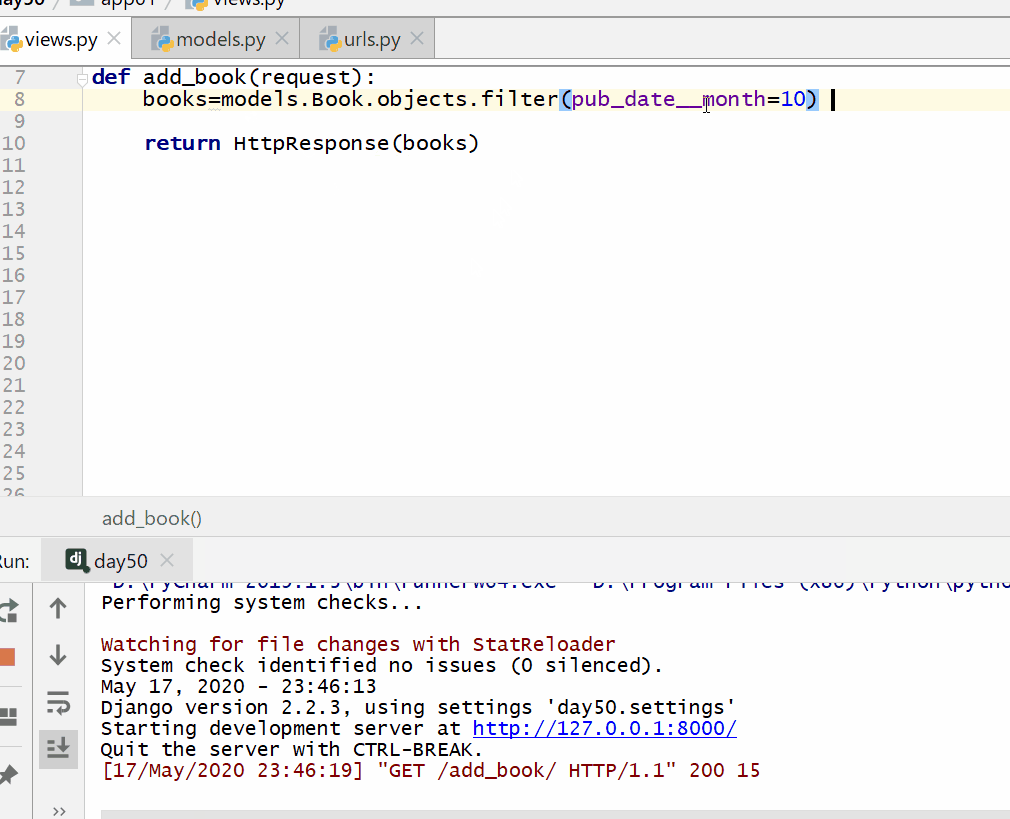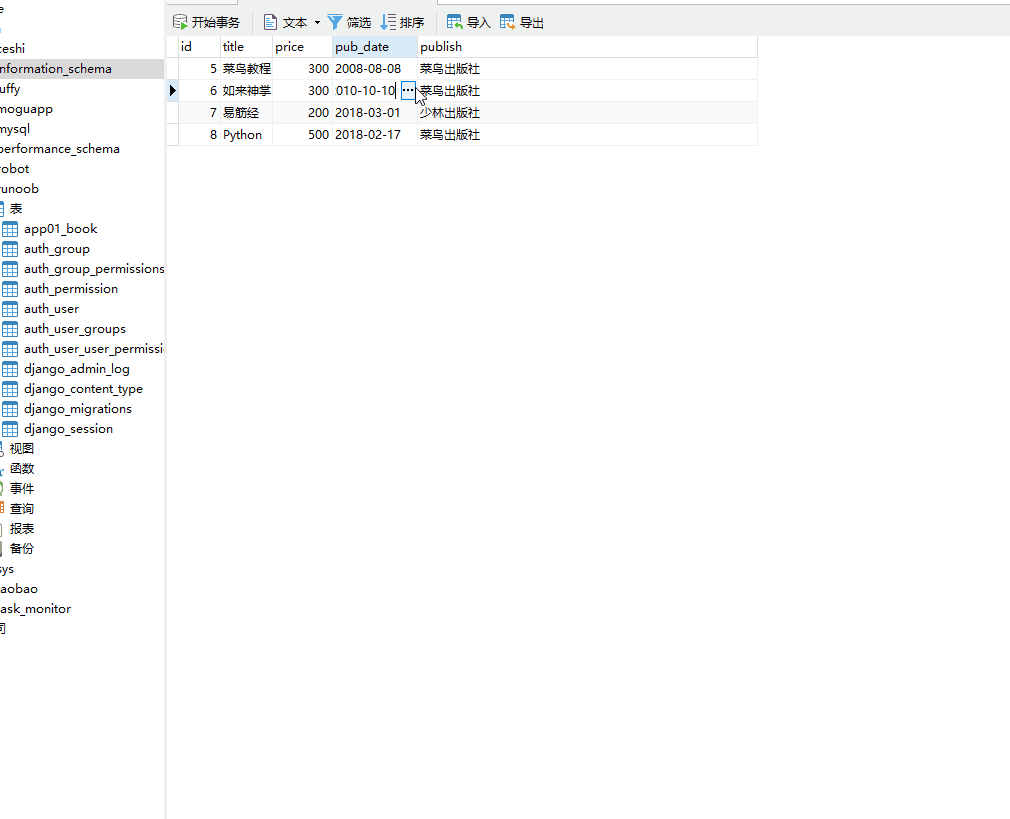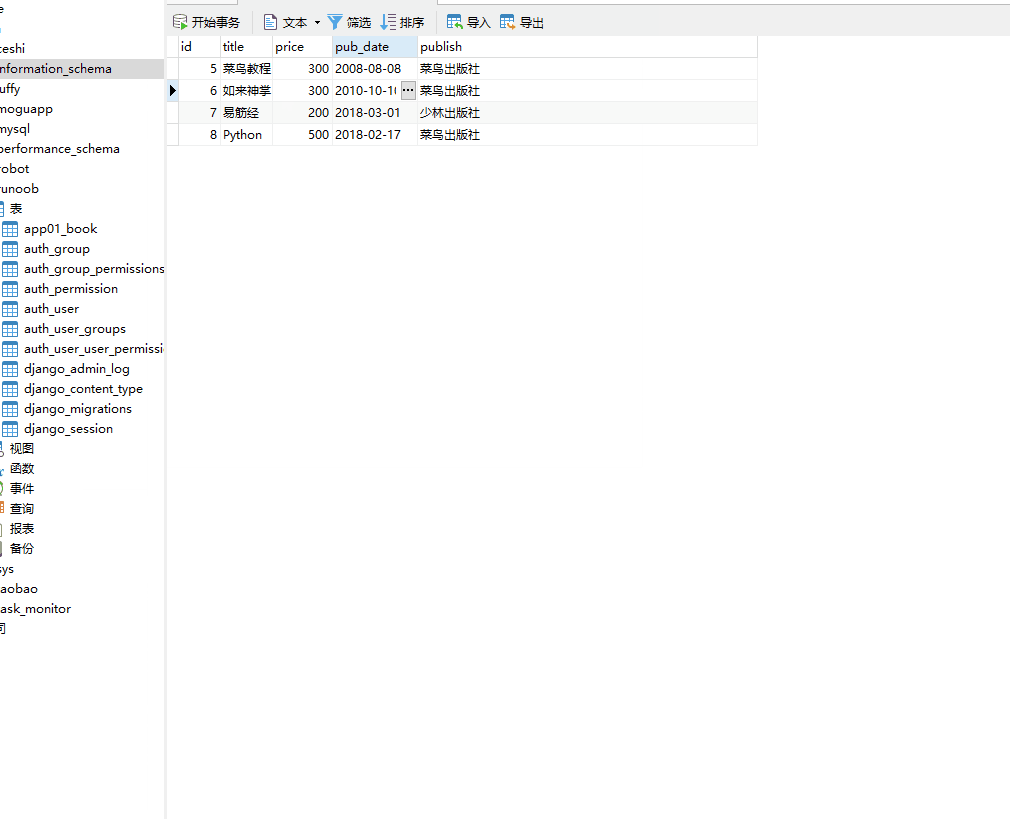
__day 是DateField 数据类型的天数,= 号后面为数字。
books=models.Book.objects.filter(pub_date__day=01)
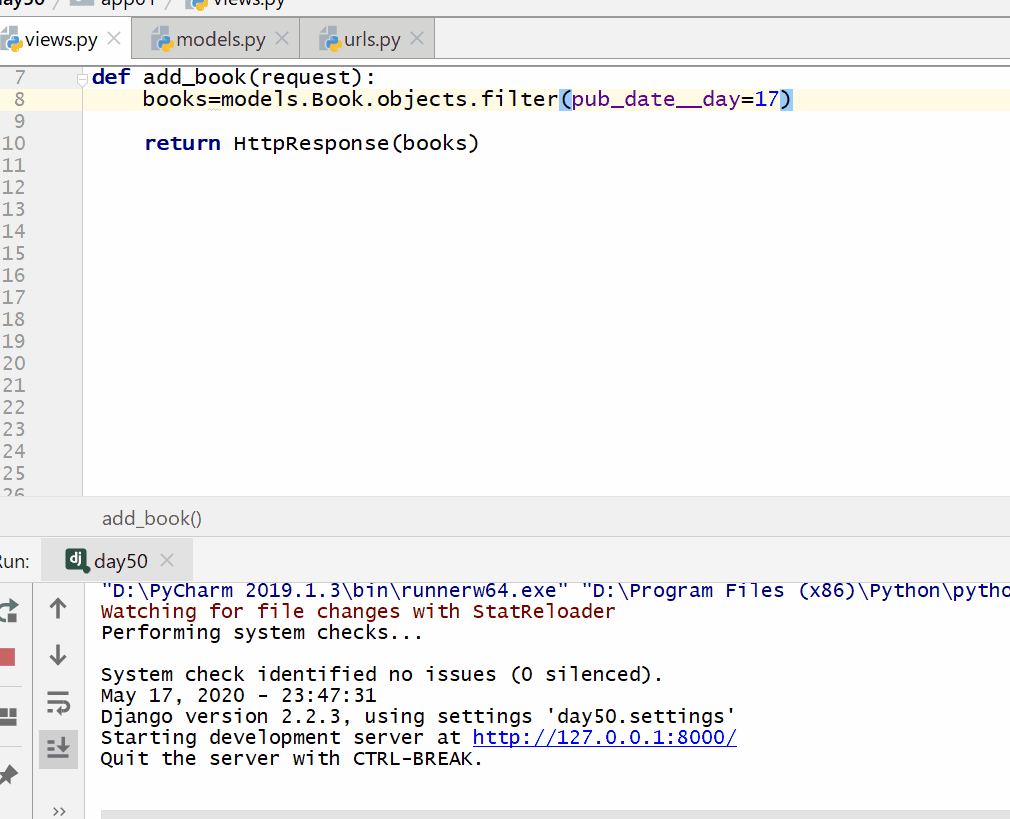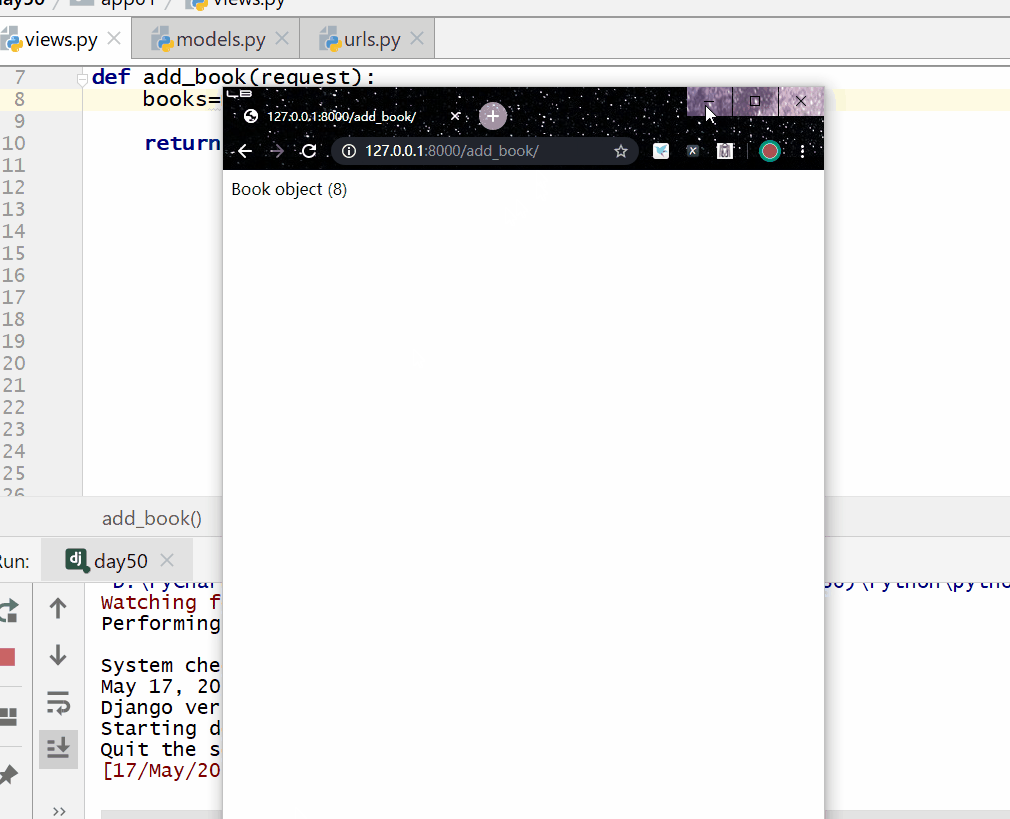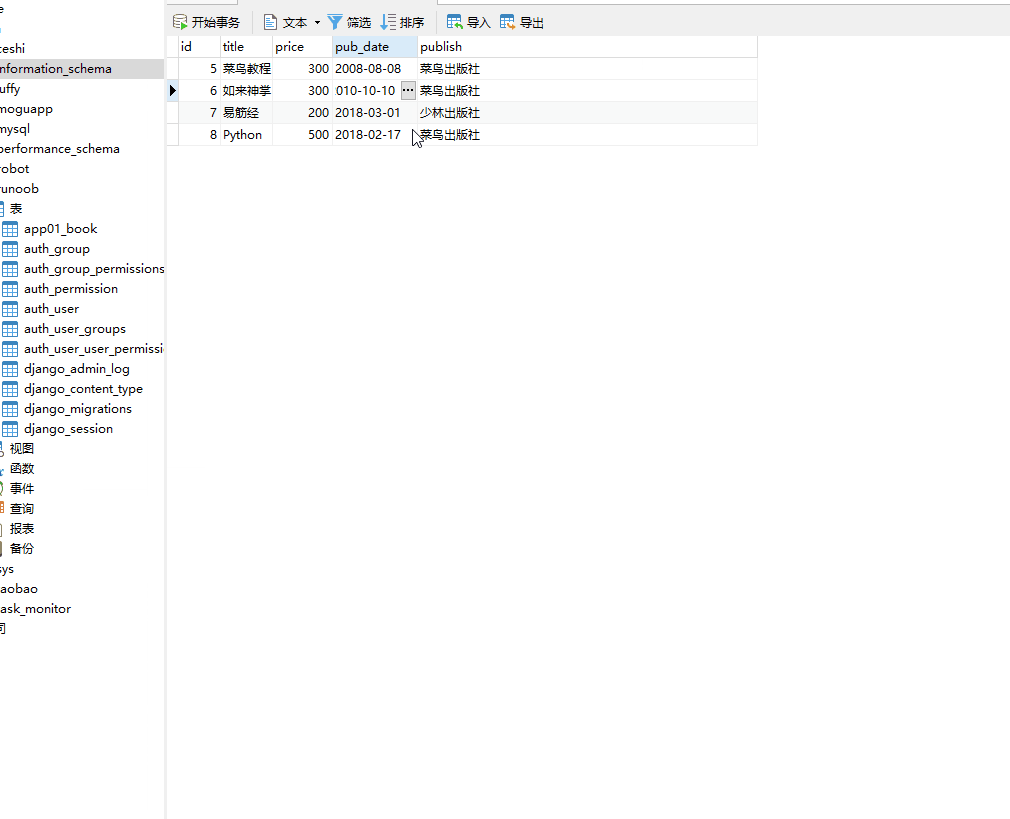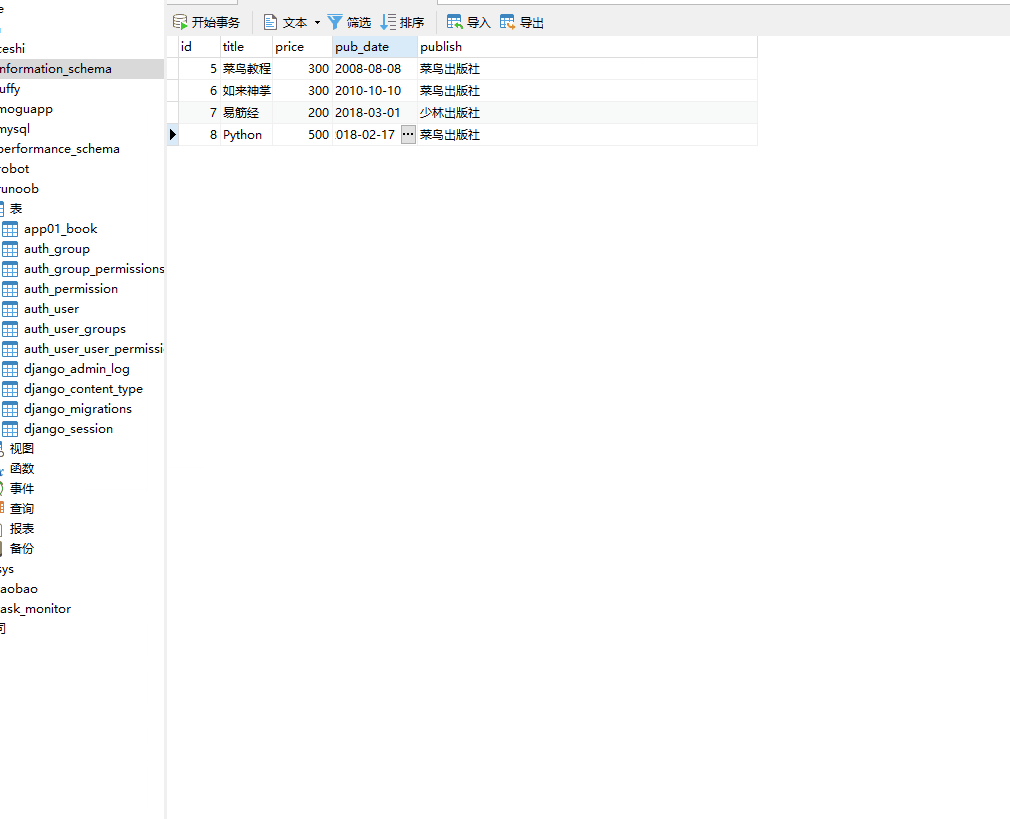
方式一:使用模型类的 对象.delete()。
返回值:元组,第一个元素为受影响的行数。
books=models.Book.objects.filter(pk=8).first().delete()
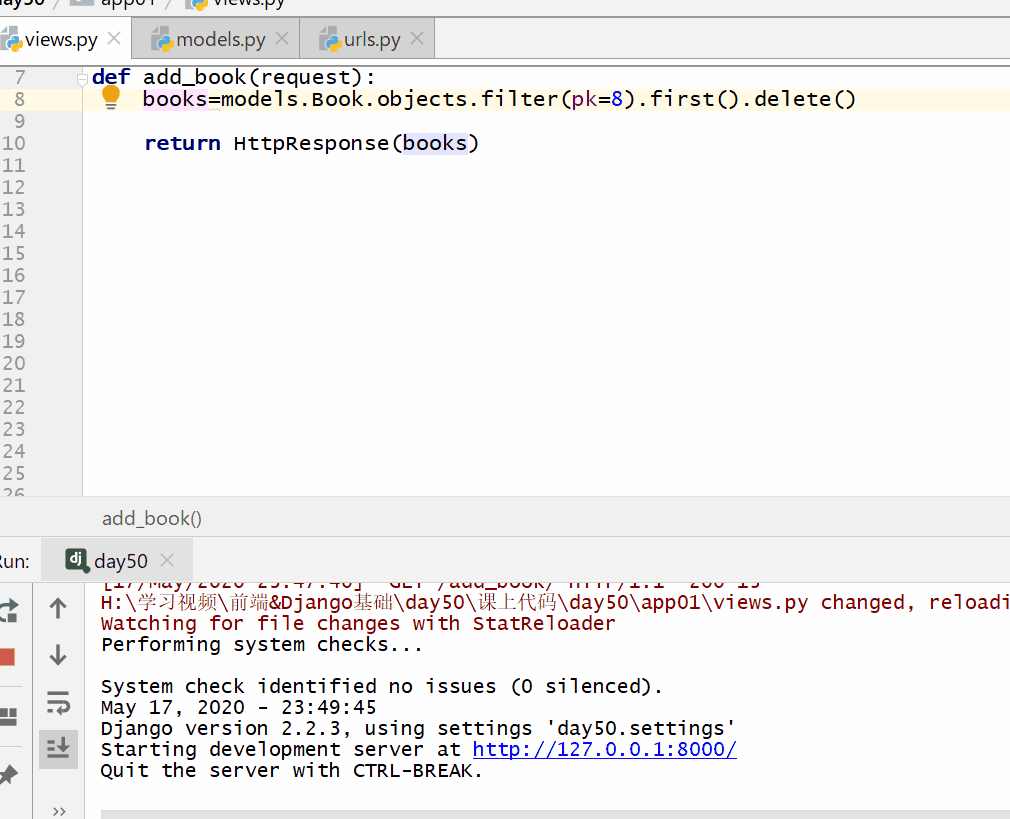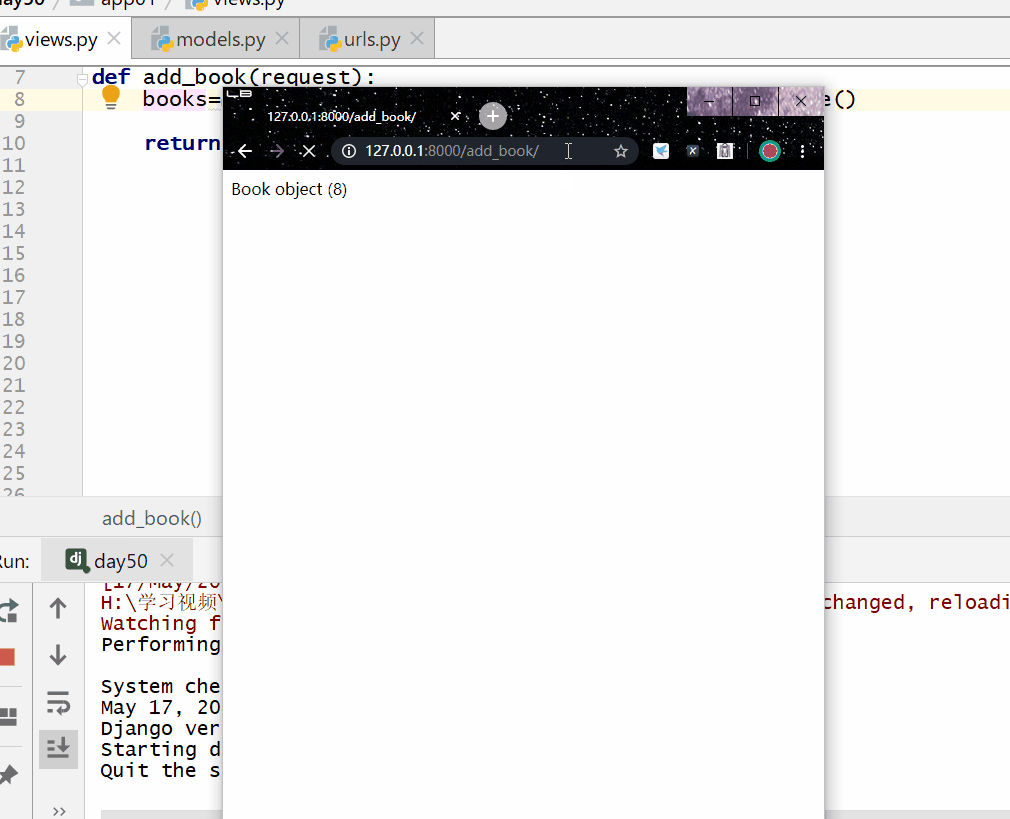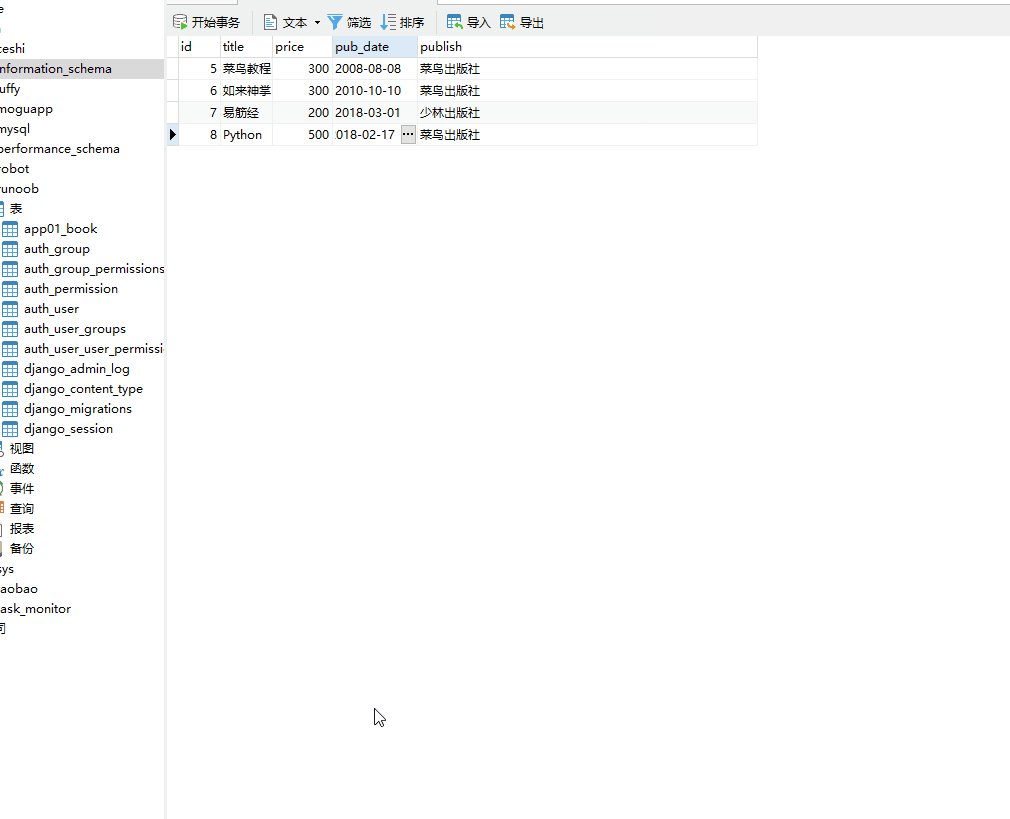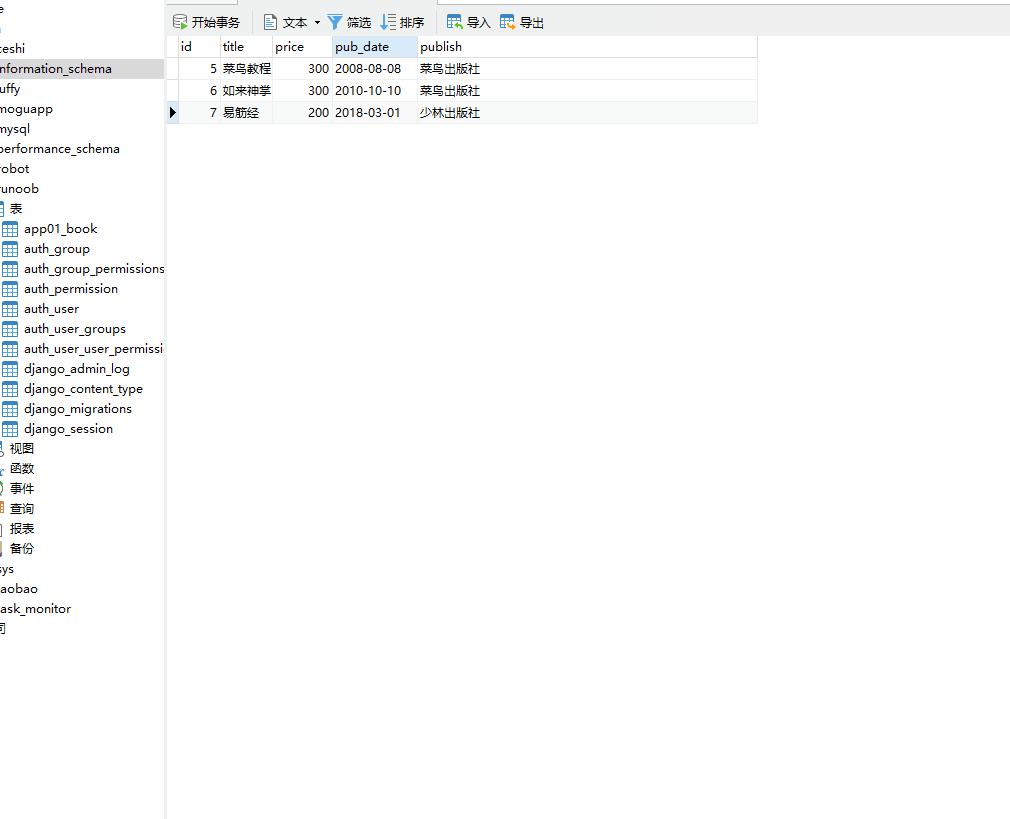
方式二:使用 QuerySet 类型数据.delete()(推荐)
返回值:元组,第一个元素为受影响的行数。
books=models.Book.objects.filter(pk__in=[1,2]).delete()
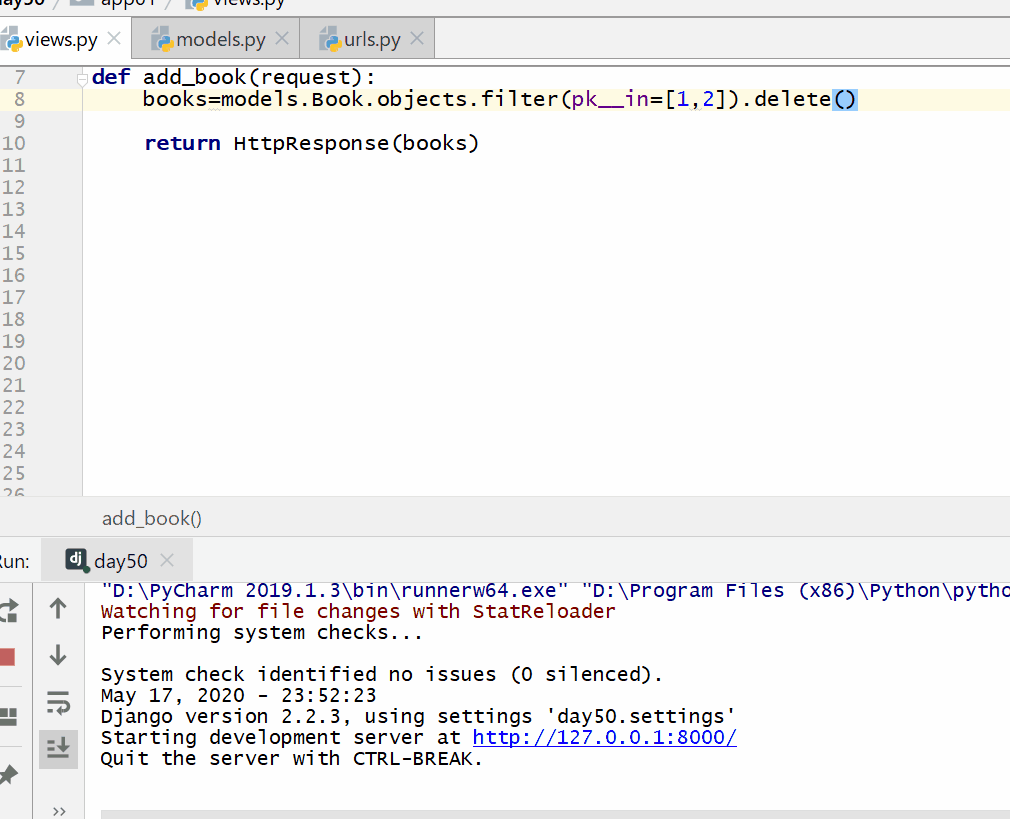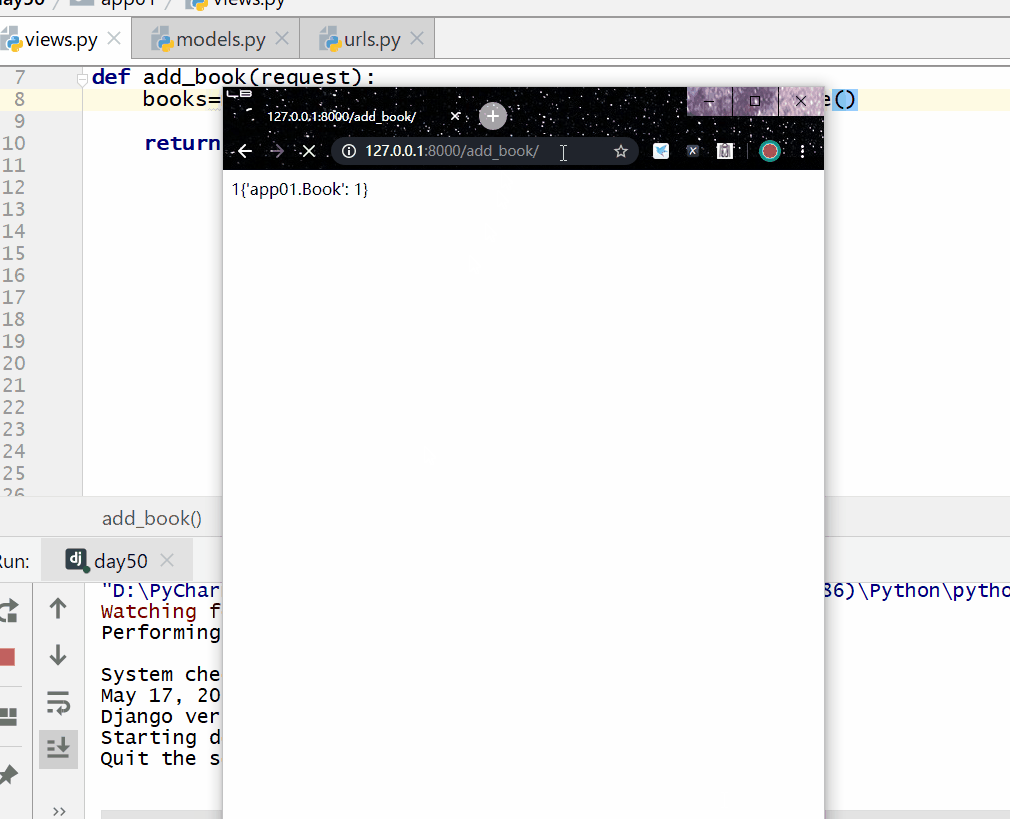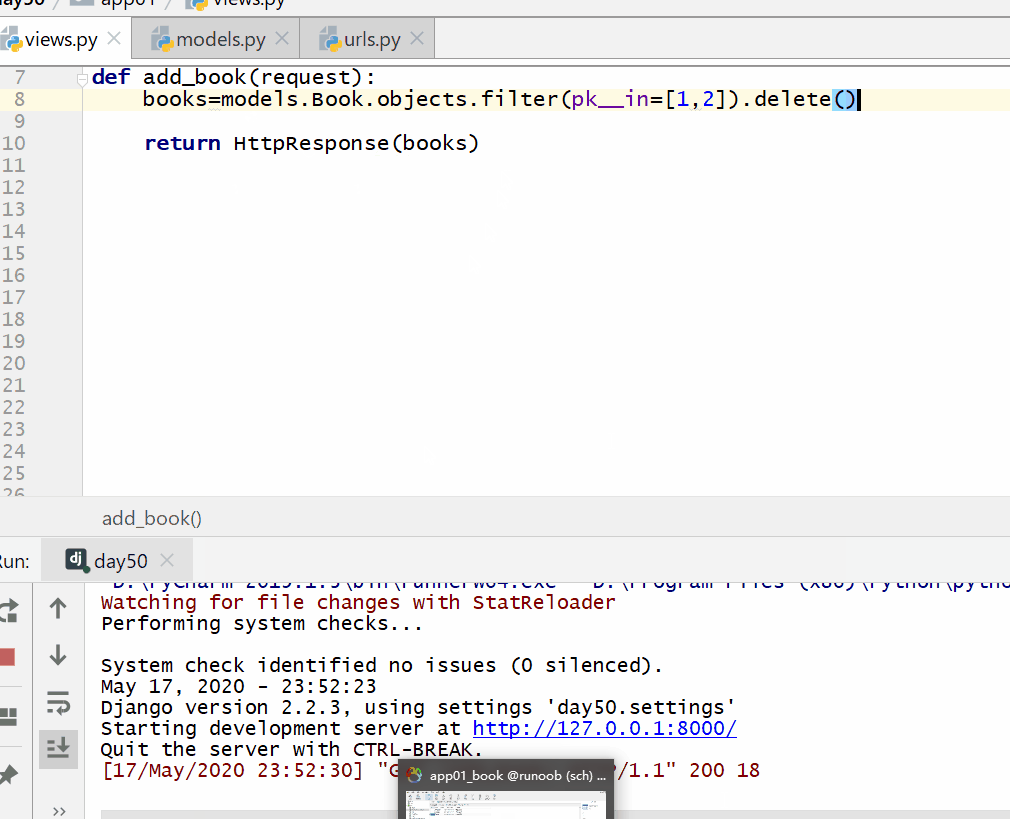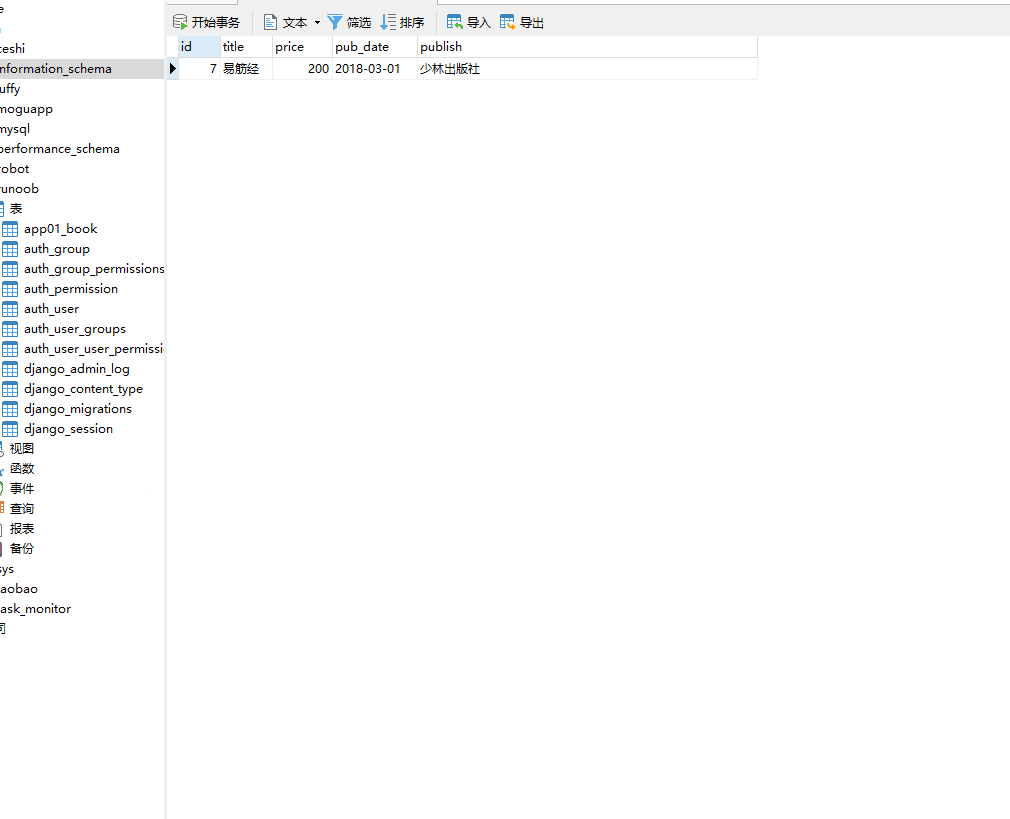
注意:
books=models.Book.objects.delete() # 报错 books=models.Book.objects.all().delete() # 删除成功
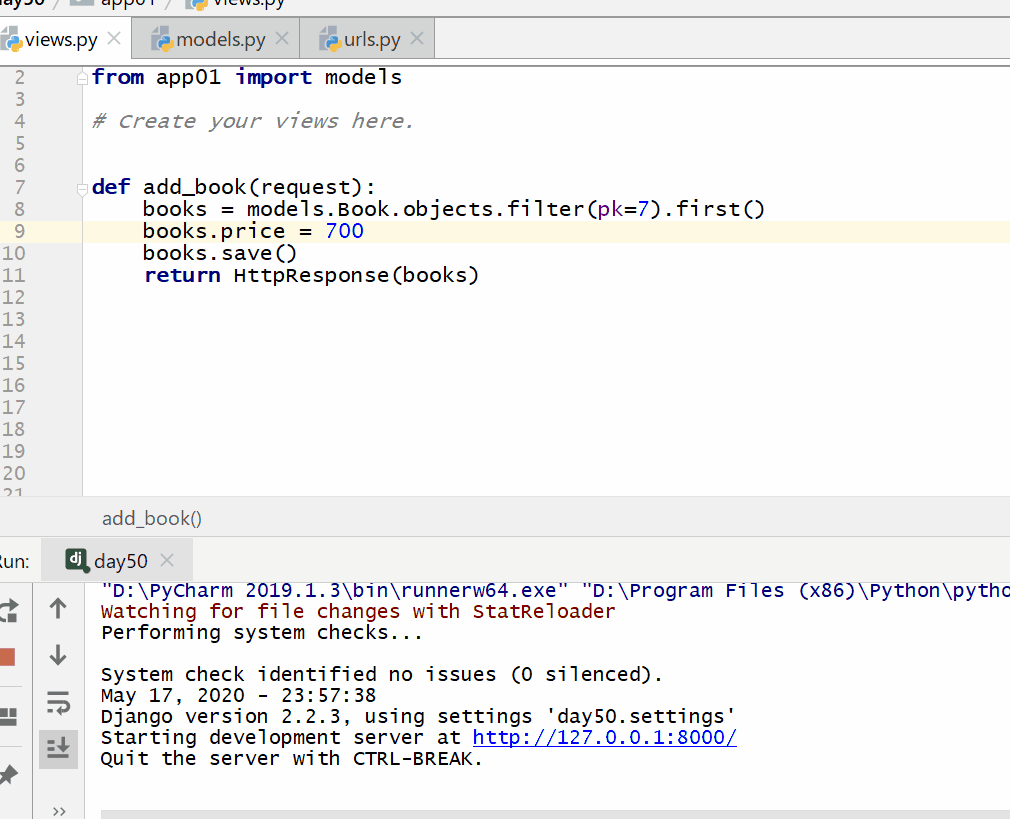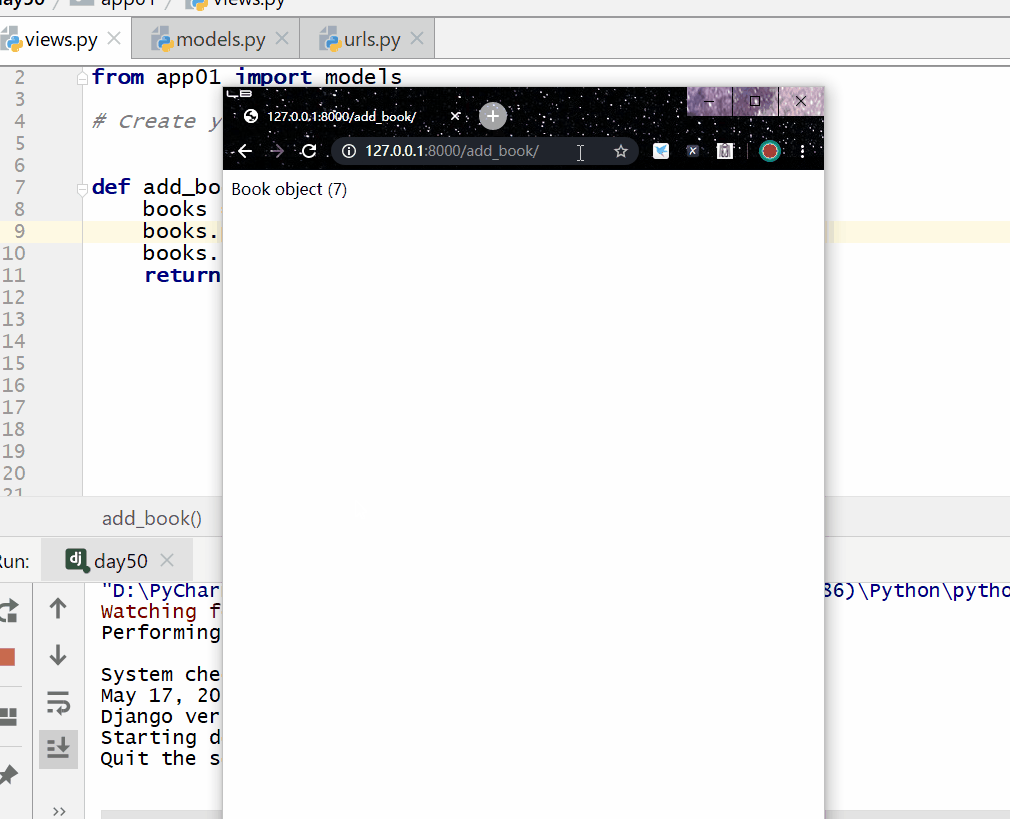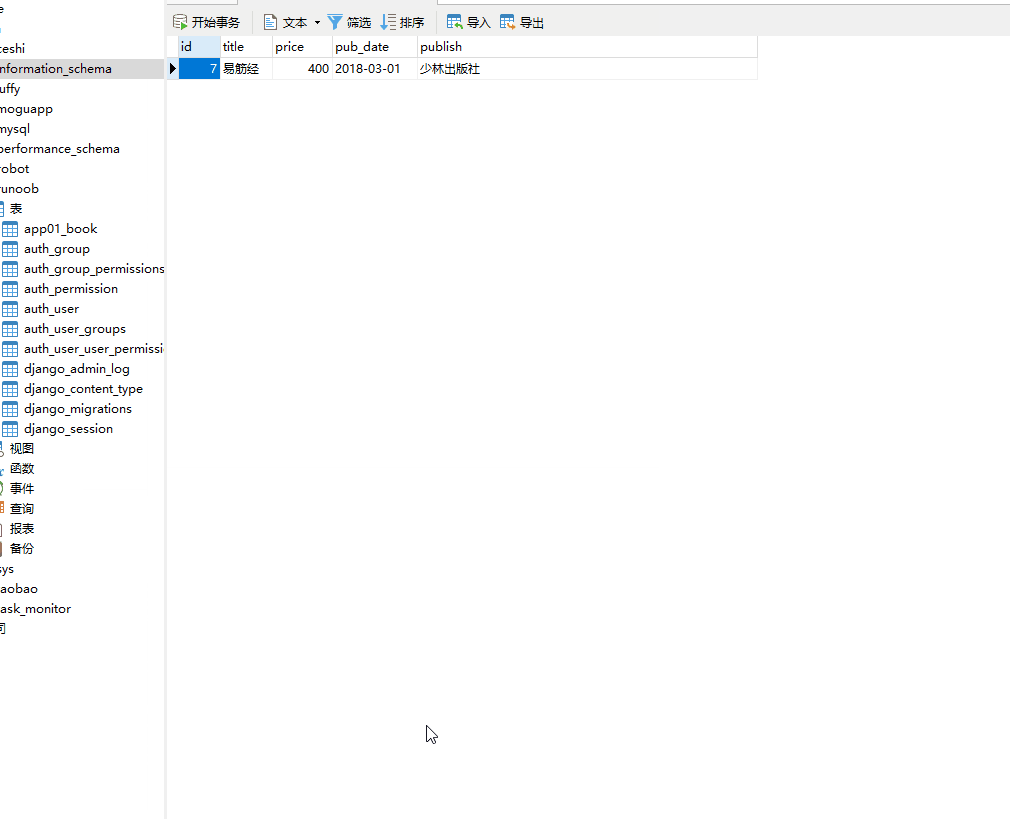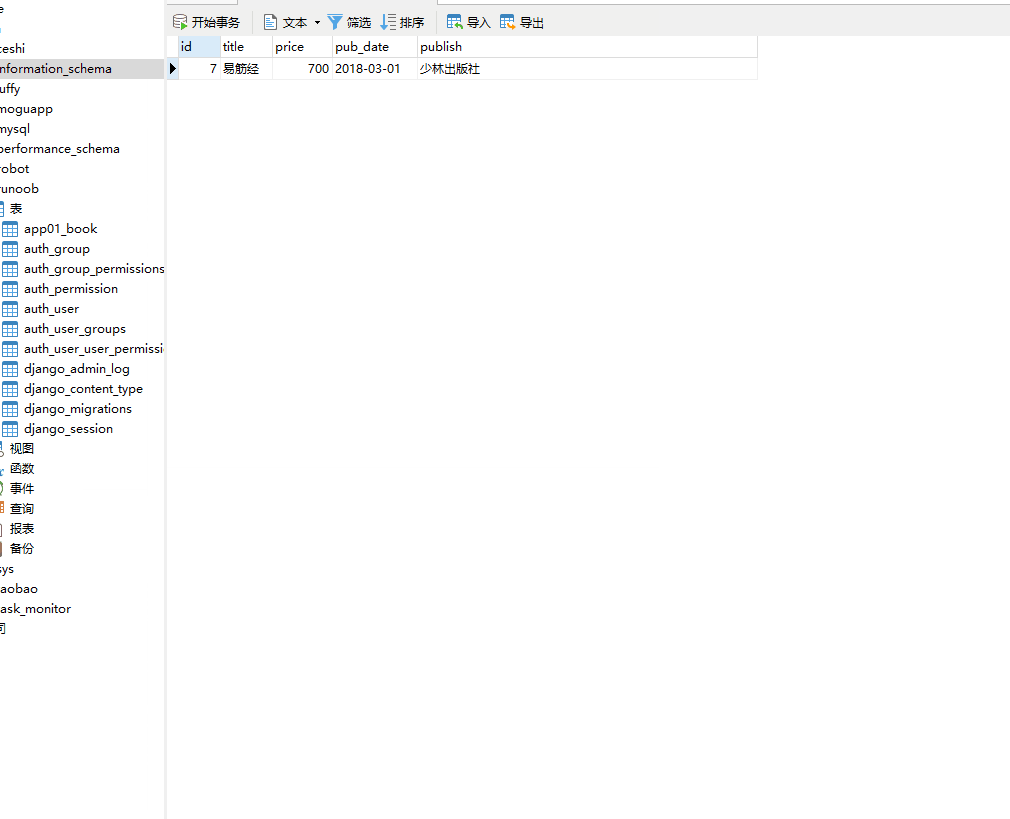
方式一:
模型类的对象.属性 = 更改的属性值 模型类的对象.save()
返回值:编辑的模型类的对象。
books = models.Book.objects.filter(pk=7).first() books.price = 400 books.save()
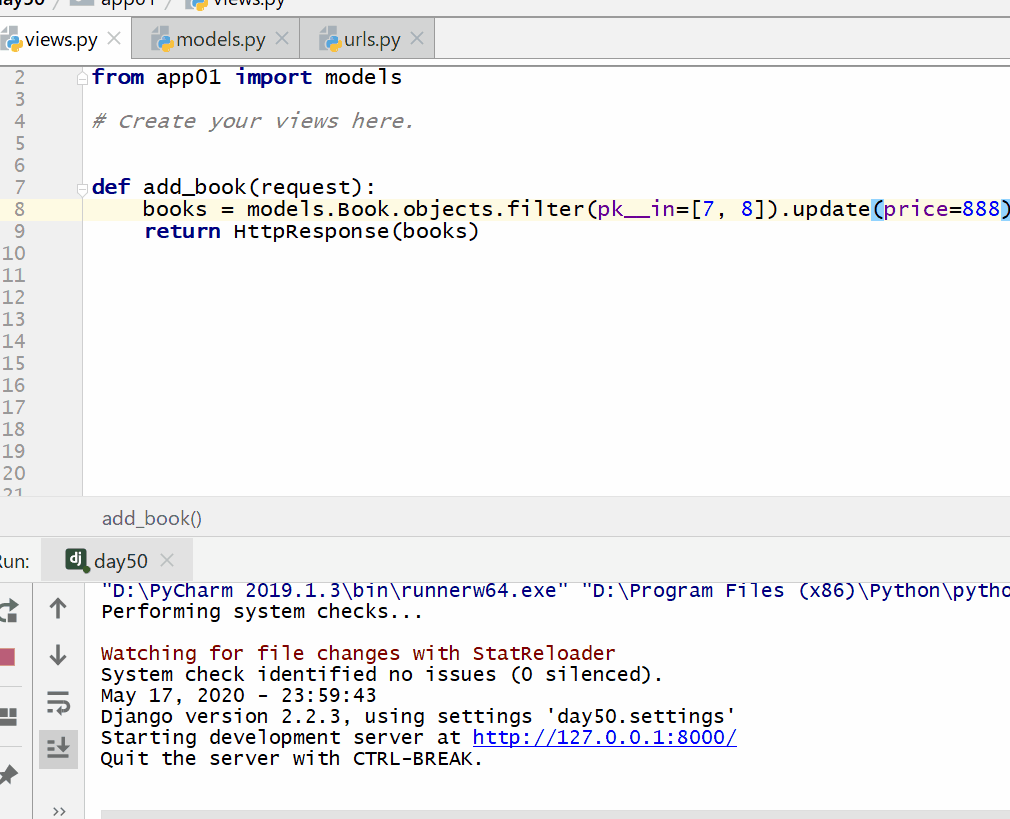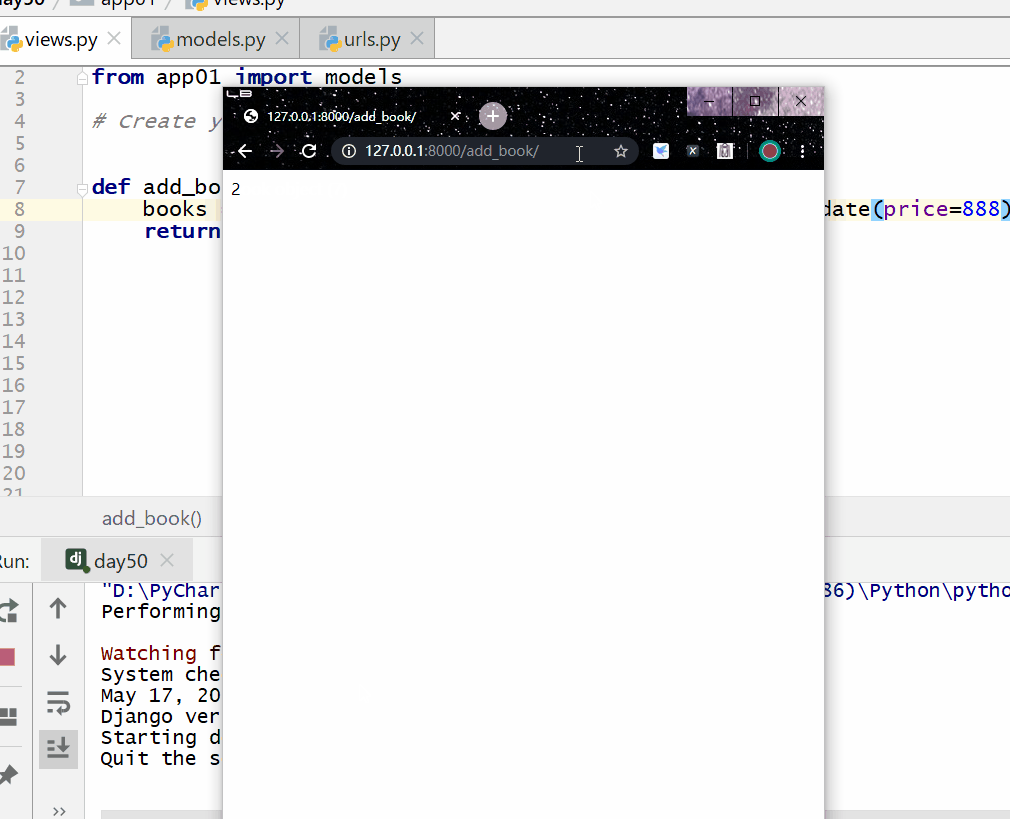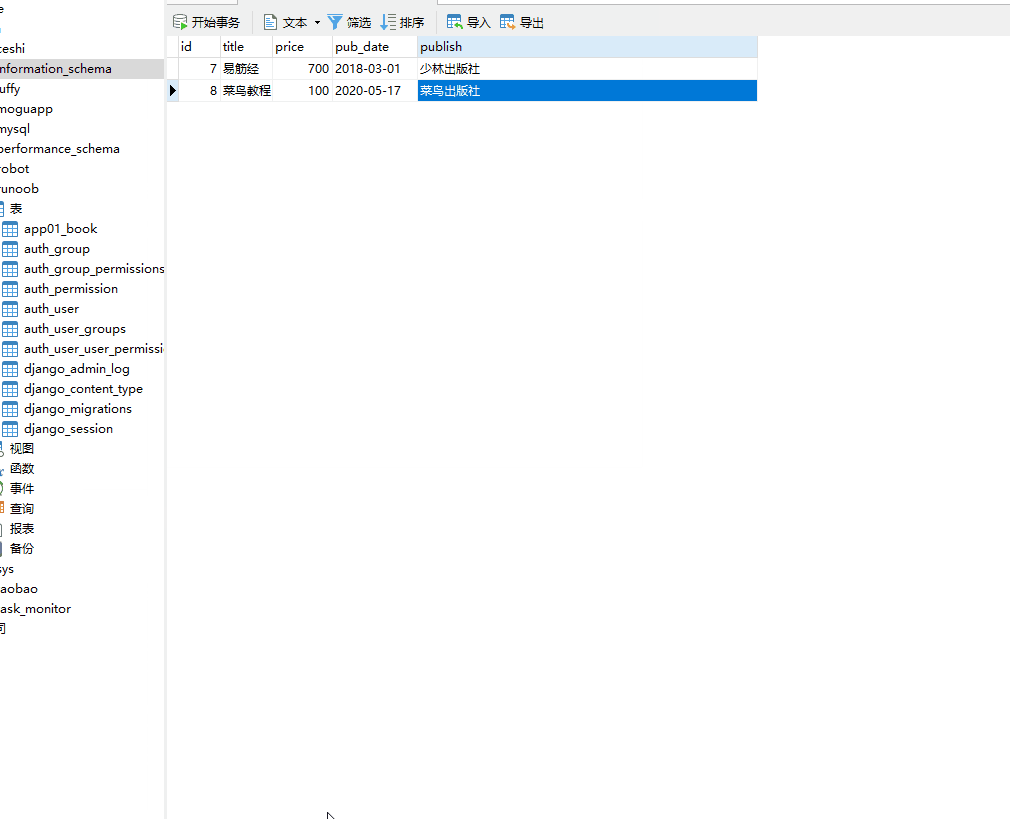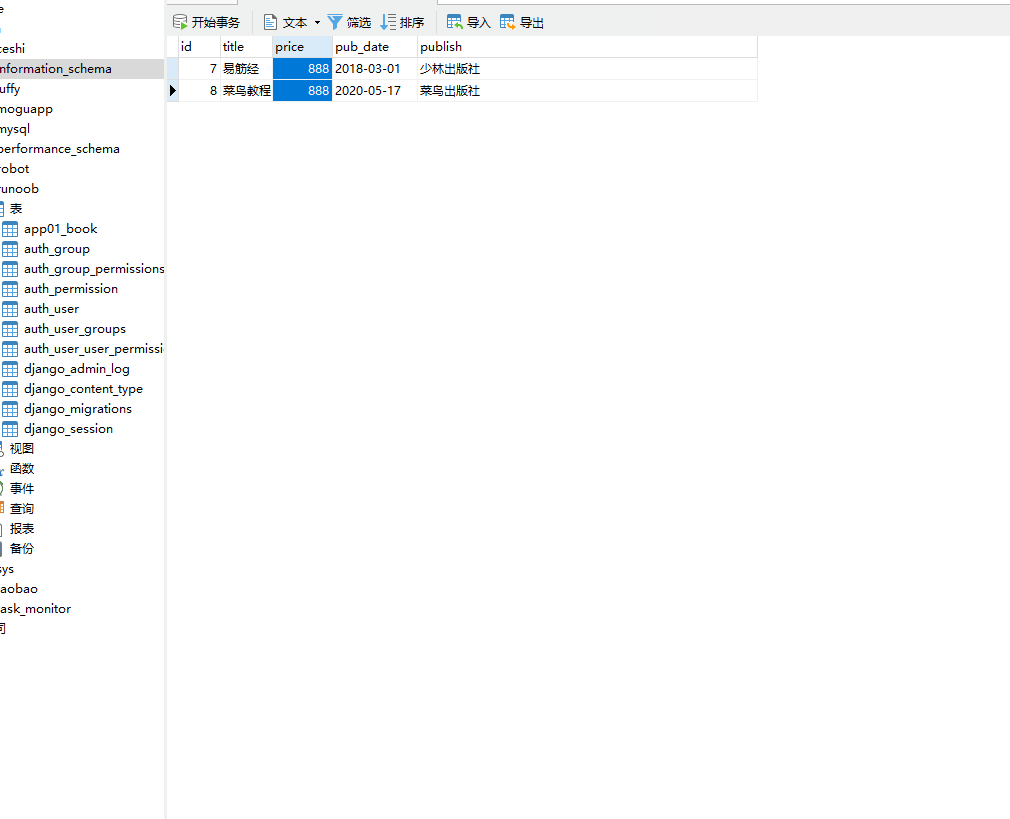
方式二:QuerySet 类型数据.update(字段名=更改的数据)(推荐)
返回值:整数,受影响的行数
这是我的实体:publicclassAccountextendsAbstractEntity{@Id@SequenceGenerator(name="accountSequence",sequenceName="SQ_ACCOUNTS",allocationSize=1)@GeneratedValue(strategy=GenerationType.SEQUENCE,generator="accountSequence")@Column(name="ACC_ID",nullable=false)privateLongid;...}publicclassIntegrationextend
类似这个问题PivotTableinc#,我正在寻找c++中数据透视表的实现。由于项目要求速度相当关键,并且性能关键部分项目的其余部分是用c++编写的,因此非常需要用c++实现或从c++调用。有谁知道类似于Excel或OpenOffice中的数据透视表的实现?我宁愿不必从头开始编写这样的代码,但如果我要这样做,我应该怎么做呢?应该了解哪些算法和数据结构?任何指向算法的链接都将不胜感激。 最佳答案 我确定您不是在询问Excel中数据透视表的全部功能。我认为您需要基于离散解释变量和给定统计数据的简单统计表。如果你这样做,我认为从头开始编
点开视频后,再点视频下方《展开全文》直接看国奖文字等超全资料截图哦。(小白必看)大创(国创)国家级最新模板资料分享大学生创新创业训练项目怎么准备模板参考学习立项结题报告中期检查报告申报书的创新点和项目特色流程表结项任务书阶段性报告验收表实施心得成果怎么写,保研额外加分必备,大学期间,大创一定要去做一做,含金量很高。一个项目立项后,需要持续一年的时间才能结题,在这一年里,我们可以学习到很多东西,我讲讲我们从立项到结题的大概过程。我们队员搭配是:交通运输工程,汽车服务工程,地理信息科学,交通工程。在大二下学期4月立项省部级,项目叫基于5G技术的VR-定制旅游-沉浸式服务新型平台设计。立项的时候需要
HUDI表相关概念表类型cowmor分区表/不分区表用户可以在SparkSQL中创建分区表和非分区表。要创建分区表,需要使用partitionedby语句指定分区列来创建分区表。当没有使用createtable命令进行分区的by语句时,table被认为是一个未分区的表。内部表和外部表一般情况下,SparkSQL支持两种表,即内部表和外部表。如果使用location语句指定一个位置,或者使用createexternaltable显式地创建表,那么它就是一个外部表,否则它被认为是一个内部表。特别注意:从hudi0.10.0开始,在创建hudi表时必须指定primaryKey用于表示主键字段。假如你
HUDI表相关概念表类型cowmor分区表/不分区表用户可以在SparkSQL中创建分区表和非分区表。要创建分区表,需要使用partitionedby语句指定分区列来创建分区表。当没有使用createtable命令进行分区的by语句时,table被认为是一个未分区的表。内部表和外部表一般情况下,SparkSQL支持两种表,即内部表和外部表。如果使用location语句指定一个位置,或者使用createexternaltable显式地创建表,那么它就是一个外部表,否则它被认为是一个内部表。特别注意:从hudi0.10.0开始,在创建hudi表时必须指定primaryKey用于表示主键字段。假如你
这是我的存储过程CreatePROCEDURE[dbo].getUserAndEnumASBEGINselect*fromuser_masterwhereid=1select*fromenum_masterwhereid=1End我用hibernate写的Sessionsession=HibernateFactory.getSessionFactory().openSession();Transactiontr=session.beginTransaction();SQLQueryqr=session.createSQLQuery("getUserAndEnum");Listlist=
这是我的存储过程CreatePROCEDURE[dbo].getUserAndEnumASBEGINselect*fromuser_masterwhereid=1select*fromenum_masterwhereid=1End我用hibernate写的Sessionsession=HibernateFactory.getSessionFactory().openSession();Transactiontr=session.beginTransaction();SQLQueryqr=session.createSQLQuery("getUserAndEnum");Listlist=
我想写一个查询,如SELECT*FROMRelease_date_typeaLEFTJOINcache_mediabona.id=b.id。我是SpringDataJPA的新手。我不知道如何为Join查询编写实体。这是一个尝试:@Entity@Table(name="Release_date_type")publicclassReleaseDateType{@Id@GeneratedValue(strategy=GenerationType.TABLE)privateIntegerrelease_date_type_id;//...@Column(nullable=true)priva
我想写一个查询,如SELECT*FROMRelease_date_typeaLEFTJOINcache_mediabona.id=b.id。我是SpringDataJPA的新手。我不知道如何为Join查询编写实体。这是一个尝试:@Entity@Table(name="Release_date_type")publicclassReleaseDateType{@Id@GeneratedValue(strategy=GenerationType.TABLE)privateIntegerrelease_date_type_id;//...@Column(nullable=true)priva
文章目录前言一、实现效果二、QSS简介及用法1.什么是QSS?2.怎么使用QSS?三、QSS用法一:单个控件调用setStyleSheet函数四、QSS用法二:编写单个界面.qss文件的并读取1.创建qss文件2.qss文件语法格式3.读取qss文件4.界面换肤五、完整源码1.main.cpp文件2.startwin.h文件3.startwin.cpp文件4.setwin.h文件5.setwin.cpp文件6.图片素材及qss文件附:QSS样式表属性及含义总结前言 本篇,我们将对QSS样式表进行简单介绍,并且使用QSS样式表实现界面换肤功能。一、实现效果通过点击主界面的设置按钮,进入皮肤设