最近因为要搭Hadoop集群,确实花了好大的心血在里面,因为我的Linux也是前两天速成的,好多东西都还是边查资料边搭。但我最终确实成功了,留了一点点小问题在里面。(当Hadoop集群start-all之后resourcemanager无论我怎么按照网上的方法调试都不出现)
现在就来回顾一下我的第一次Hadoop集群之旅。
参考:
如何构建虚拟机Hadoop集群,搭建3台ubuntu虚拟机集群_北冥有渔的博客-CSDN博客如何构建虚拟机Hadoop集群,搭建3台ubuntu虚拟机集群克隆集群机器通过虚拟机搭建Hadoop集群,发现使用的VMware workstation 15 player版本没有克隆功能,于是找到了手动克隆方法:参考:https://blog.csdn.net/weixin_44763047/article/details/111772941搭建集群一台Ubuntu主机系统作Master(yjh-ubuntu),一台Ubuntu主机系统命名为slave01,一台Ubuntu主机系统命名为slahttps://blog.csdn.net/weixin_44763047/article/details/115222913我跟着上面这个步骤一步一步做,但是出现了很多问题,自己一步一步去解决,我把会发生的情况和会有的坑都放在我的文章里了,以及我还有的疑问。
首先你要创建三台一模一样的Ubuntu虚拟机
网络类型最好先选用NAT模式,等ssh调通了再进行其他操作,静态ip之类。
当然先创建一台,再利用克隆的功能克隆出另外两台是更明智的选择,但是VMware workstation
15.x版本及以上已经没有克隆功能了,以下是手动克隆的传送门:
现在有三台虚拟机,改hostname:将其中一台改作Master,一台改作slave1,一台改作slave2。让其三者处于同一局域网中。
vim /etc/hostname记得修改完按esc,然后冒号+wq(保存),冒号+q(不保存)
由Master节点举例
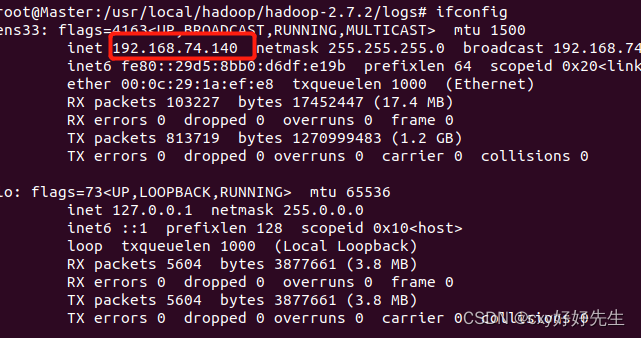
输入 ipconfig(以下是下载ipconfig的方法)
最终可以得到
Master 192.168.74.140
slave1 192.168.74.133
slave2 192.168.74.139
接下来修改节点IP映射
sudo vim /etc/hosts 还是以Master节点为例(三台都要改)
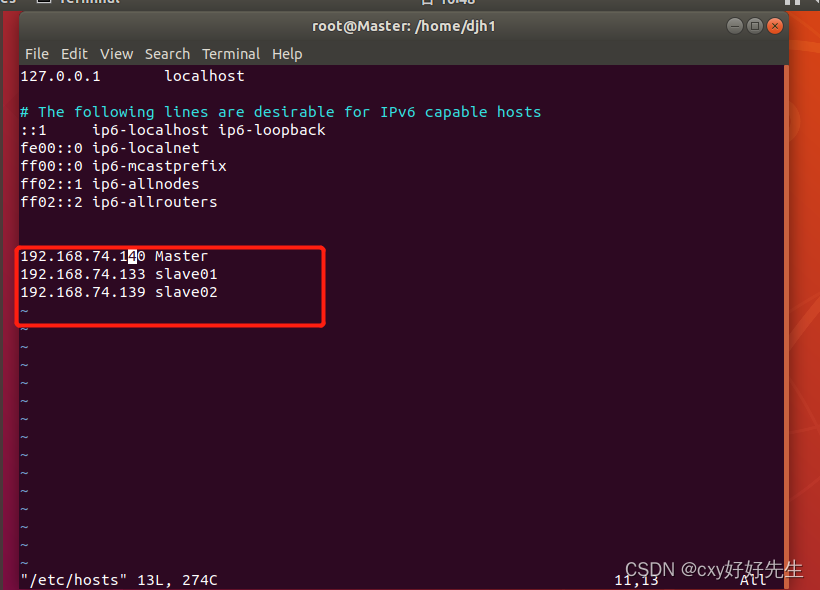
:wq保存
三台虚拟机全部重启后生效
利用刚刚记录下来的ip地址,三台虚拟机互相ping通。
ping IP地址能够ping通的结果是如图:
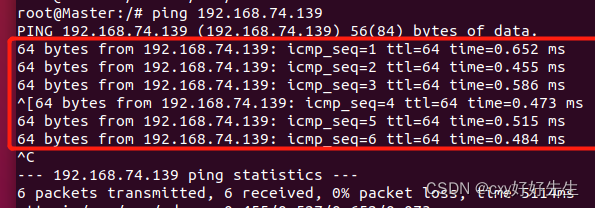
当三台都互相ping通就成功。
这一步给你们一个传送门把
因为Ubuntu这个系统他并没有自带ssh服务,需要自己安装。(三台都要)
sudo apt-get install openssh-server #安装服务,一路回车
sudo /etc/init.d/ssh restart #启动服务
sudo ufw disable #关闭防火墙
有时候用apt 或者apt-get 时会碰上以下情况(没碰到可以不看加红部分)

参考文章:
ps -e | grep ssh只要出现了两个进程说明你成功了。

已经全部搭建完毕,但是还是先发出来,没啥时间写博客,还得先继续学习,明天有空补上
接下来:在master节点生成SSH公钥,公钥储存在 /home/hadoop/.ssh 中
cd ~/.ssh # 如果没有该目录,先执行一次ssh localhost
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以
让master 节点可以无密码 SSH 本机,在 master 节点上执行
cat ./id_rsa.pub >> ./authorized_keys完成后可执行 ssh master验证一下(需要输入 yes,成功后执行 exit 返回原来的终端)
ssh djh1
接着在 master 节点将上公匙传输到 slave01节点,过程中需要输入 slave01 节点的密码,传输100%以后就是传过去了:
scp ~/.ssh/id_rsa.pub djh2@slave01:/home/djh2
接着在 slave01节点上,把公钥加入授权
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
rm ~/id_rsa.pub # 用完就可以删掉了
slave02 也重复上面的步骤
你就可以免密码ssh两个节点了
需要修改 /usr/local/hadoop/hadoop-2.10.1/etc/hadoop 中的5个配置文件。
slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml
slaves

core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directions.</description>
</property>
</configuration>
hdfs-site.xml
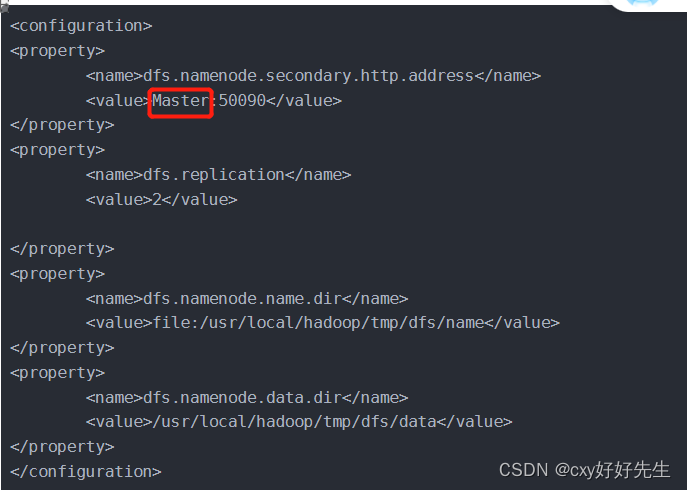
mapred-site.xml
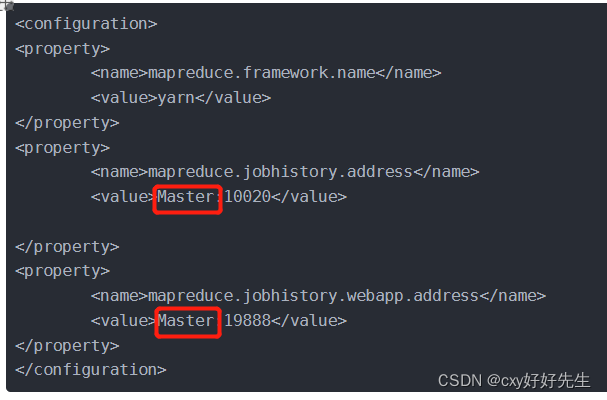
yarn-site.xml
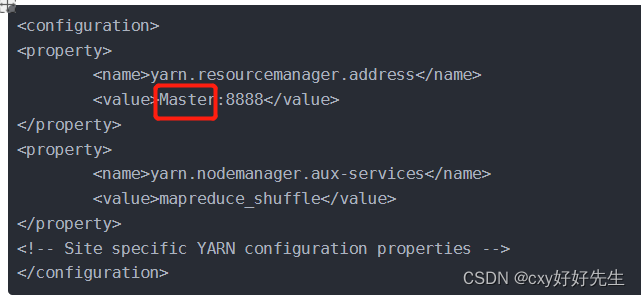
配置好以后,将master 节点上的 /usr/local/hadoop/hadoop-2.10.1/etc/hadoop 文件夹复制到剩余节点上。
在 master 节点执行:
cd /usr/local #去到/usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
cd hadoop/hadoop-2.7.2
sudo rm -r ./logs # 删除日志文件
sudo tar -zcf ~/hadoop.Master.tar.gz ./hadoop # 先压缩再复制
cd ~ #跳转到有压缩包的路径下
scp ./hadoop..Master.tar.gz slave01:/home/djh2/hadoop
#发送到slave01节点,其他salve节点也要执行
在剩余 salve 节点上执行(以slave01为例):
首次启动 Hadoop 需要将 master 节点格式化:
在hdfs namenode -format # 首次运行需要执行初始化,之后不需要
start-all.sh
mr-jobhistory-daemon.sh start historyserver 通过命令 jps 可以查看各个节点的启动进程
jps
master 有 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServe
以上进程缺少任意一个都表示有错。(我就是在这一步出现了错误,ResourceManager进程缺少)不知如何解决。
希望大家发现错误能给我纠正,共同学习共同进步,谁会ResourceManager进程的开启的话可以在评论区告诉我,或者私信我,实在是搞不出来。
再次说明参考:
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
-if!request.path_info.include?'A'%{:id=>'A'}"Text"-else"Text"“文本”写了两次。我怎样才能只写一次并同时检查path_info是否包含“A”? 最佳答案 有两种方法可以做到这一点。使用部分,或使用content_forblock:如果“文本”较长,或者是一个重要的子树,您可以将其提取到一个部分。这会使您的代码变干一点。在给出的示例中,这似乎有点矫枉过正。在这种情况下更好的方法是使用content_forblock,如下所示:-if!request.path_info.inc
我的Rails应用程序中安装了carrierwave。但是,当用户上传多页pdf时,我只希望应用程序获取文档中的第一页并将其转换为jpeg。这可能吗?用什么命令?这是我的uploader。#encoding:utf-8classImageUploader[200,300]##defscale(width,height)##dosomething#end#Createdifferentversionsofyouruploadedfiles:version:thumbdoprocess:resize_to_fill=>[150,210]process:convert=>:jpgdefful