
目录
在你想要放弃的时候,想想是什么让你当初坚持走到了这里。
Kubernetes (k8s) 是一个容器编排平台,允许在容器中运行应用程序和服务。今天学习一下k8s 控制器。
文章标记颜色说明:
- 黄色:重要标题
- 红色:用来标记结论
- 绿色:用来标记一级论点
- 蓝色:用来标记二级论点
回忆一下,我和你详细介绍了 Pod 的用法,讲解了 Pod 这个 API 对象的各个字段。而接下来,我们就一起来看看“编排”这个 Kubernetes 项目最核心的功能吧。
实际上,你可能已经有所感悟:Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。
说得更形象些,“容器”镜像虽然好用,但是容器这样一个“沙盒”的概念,对于描述应用来说,还是太过简单了。
这就好比,集装箱固然好用,但是如果它四面都光秃秃的,吊车还怎么把这个集装箱吊起来并摆放好呢?
所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架“吊车”,可以更轻松地操作它。
Kubernetes 操作这些“集装箱”的逻辑,都由控制器(Controller)完成
Kube-controller-manager是Kubernetes中的一个控制器,是Kubernetes系统中的一个组件,负责运行一些后台控制循环(controller loop),并监视系统中的各个资源的状态。
kube-controller-manager通常运行在Master节点上。kube-controller-manager包含了多个控制器,每个控制器都负责处理不同的资源。
以下是kube-controller-manager中的一些重要控制器:
Deployment控制器:用于确保Deployment对象所管理的Pod副本数量符合预期,并且进行滚动更新(Rolling Update)。
ReplicaSet控制器:用于确保ReplicaSet对象所管理的Pod副本数量符合预期。
DaemonSet 控制器:DaemonSet 控制器用于在集群中的每个节点上启动一个 Pod 副本,以便运行一些系统级别的守护进程,如日志收集器和监控代理。如果有新的节点加入集群,DaemonSet 控制器会自动在新节点上启动相应的 Pod 副本。
StatefulSet控制器:用于确保StatefulSet对象所管理的有状态应用程序的副本数量符合预期。
Node控制器:用于确保所有Node对象的状态都是最新的,并管理Node的状态。
Service控制器:用于确保Service对象的状态符合预期,并处理Service的创建、更新和删除等操作。
Namespace控制器:用于确保Namespace对象的状态符合预期,并处理Namespace的创建、更新和删除等操作。
Endpoint控制器:用于确保Endpoint对象的状态符合预期,并处理Endpoint的创建、更新和删除等操作。
Job控制器:用于确保Job对象所管理的任务成功完成,并对失败的任务进行重试。
CronJob控制器:用于确保CronJob对象所管理的定时任务按照预期执行。
在kube-controller-manager中,每个控制器都是一个独立的进程,它们之间相互独立,互不影响。同时,kube-controller-manager会自动监视资源对象的状态变化,并触发相应的控制器处理,以确保系统状态的一致性和稳定性。
了解具体的使用之前,需要先看下“循环控制”这个概念
在 Kubernetes 中,控制循环(control loop)是一种通用的编排模式,用于监控和控制集群中的资源。
控制循环通过对比当前状态和期望状态之间的差异来确保集群的期望状态得以实现。
具体而言,控制循环包括以下几个步骤:
监控资源状态:控制循环会定期检查集群中的资源状态,例如 Pod、Service、Deployment 等。
计算期望状态:根据 Kubernetes 集群的配置文件和用户提交的操作,控制循环会计算出资源的期望状态。例如,用户可能会提交一个 Deployment 的 YAML 文件,其中指定了需要部署的 Pod 数量和镜像版本等信息,控制循环就会根据这些信息计算出 Deployment 的期望状态。
对比当前状态和期望状态:控制循环会将当前状态和期望状态进行对比,找出二者之间的差异。例如,如果一个 Deployment 的期望 Pod 数量为 3,但是当前只有 2 个 Pod 在运行,那么控制循环就会发现这个差异。
执行调整操作:控制循环会根据差异来执行调整操作,使得当前状态逐渐接近期望状态。例如,控制循环会自动创建新的 Pod,以便使得 Deployment 中的 Pod 数量达到期望值。
重复执行:控制循环会一直重复上述步骤,直到当前状态和期望状态完全一致。
注意,控制循环并不是一个线性的过程,而是由多个控制器(Controller)组成的复杂系统。每个控制器都会负责监控和管理一个或多个资源,例如 Deployment、StatefulSet、DaemonSet 等。不同的控制器之间还可以相互协作,以实现更复杂的功能。
我们曾经使用过 Deployment 这个最基本的控制器对象。现在,我们一起来回顾一下这个名叫 nginx-deployment 的例子:
apiVersion: apps/v1
kind: Deployment #资源类型
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
这个 Deployment 定义的编排动作非常简单,即:确保携带了 app=nginx 标签的 Pod 的个数,永远等于 spec.replicas 指定的个数,即 2 个。
这就意味着,如果在这个集群中,携带 app=nginx 标签的 Pod 的个数大于 2 的时候,就会有旧的 Pod 被删除;反之,就会有新的 Pod 被创建。
这时,你也许就会好奇:究竟是 Kubernetes 项目中的哪个组件,在执行这些操作呢?
没错,就是今天介绍 kube-controller-manager 的组件。
那他具体怎么控制的呢?我们以这个 Deployment 为例,分析一下:
实际上,这个组件,是一系列控制器的集合。可以查看一下 Kubernetes 项目pkg/controller 目录:
$ cd kubernetes/pkg/controller/
$ ls -d */
deployment/ job/ podautoscaler/
cloud/ disruption/ namespace/
replicaset/ serviceaccount/ volume/
cronjob/ garbagecollector/ nodelifecycle/ replication/ statefulset/ daemon/
...这个目录下面的每一个控制器,都以独有的方式负责某种编排功能。而我们的 Deployment,正是这些控制器中的一种。
实际上,这些控制器之所以被统一放在 pkg/controller 目录下,就是因为它们都遵循 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。就是上面说的那个控制循环
比如,现在有一种待编排的对象 X,它有一个对应的控制器。那么,用一段 Go 语言风格的伪代码,描述这个控制循环:
for {
实际状态 := 获取集群中对象 X 的实际状态(Actual State)
期望状态 := 获取集群中对象 X 的期望状态(Desired State)
if 实际状态 == 期望状态{
什么都不做
} else {
执行编排动作,将实际状态调整为期望状态
}
}在具体实现中,实际状态往往来自于 Kubernetes 集群本身。
比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
而期望状态,一般来自于用户提交的 YAML 文件。
比如,Deployment 对象中 Replicas 字段的值。
很明显,这些信息往往都保存在 Etcd 中。接下来,以 Deployment 为例,简单描述一下它对控制器模型的实现:
Deployment 控制器从 Etcd 中获取到所有携带了“app: nginx”标签的 Pod,然后统计它们的数量,这就是实际状态;
Deployment 对象的 Replicas 字段的值就是期望状态;
Deployment 控制器将两个状态做比较,然后根据比较结果,确定是创建 Pod,还是删除已有的 Pod
其实,像 Deployment 这种控制器的设计原理,就是“用一种对象管理另一种对象”的“艺术”。
其中,这个控制器对象本身,负责定义被管理对象的期望状态。比如,Deployment 里的 replicas=2 这个字段。
而被控制对象的定义,则来自于一个“模板”。比如,Deployment 里的 template 字段。
可以看到,Deployment 这个 template 字段里的内容,跟一个标准的 Pod 对象的 API 定义,丝毫不差。而所有被这个 Deployment 管理的 Pod 实例,其实都是根据这个 template 字段的内容创建出来的。
像 Deployment 定义的 template 字段,在 Kubernetes 项目中有一个专有的名字,叫作 PodTemplate(Pod 模板)。
这个概念非常重要,因为后面讲解到的大多数控制器,都会使用 PodTemplate 来统一定义它所要管理的 Pod。更有意思的是,我们还会看到其他类型的对象模板,比如 Volume 的模板。
至此,对 Deployment 以及其他类似的控制器,做一个简单总结了:
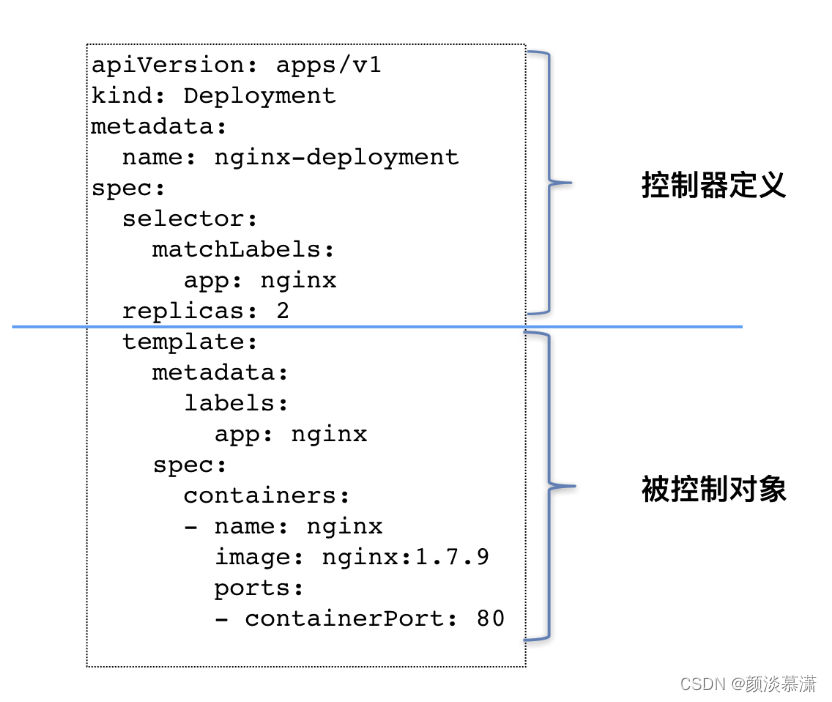
如上图所示,类似 Deployment 这样的一个控制器,实际上都是由
- 上半部分的控制器定义(包括期望状态)
- 下半部分的被控制对象的模板组成的
在这篇文章中,以 Deployment 为例,详细分享了 Kubernetes 项目如何通过一个称作“控制器模式”(controller pattern)的设计方法,来统一地实现对各种不同的对象或者资源进行的编排操作。
这个实现思路,正是 Kubernetes 项目进行容器编排的核心原理。
在此后讲解 Kubernetes 编排功能的文章中,我都会遵循这个逻辑展开,并且带你逐步领悟控制器模式在不同的容器化作业中的实现方式。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
当我在Rails控制台中按向上或向左箭头时,出现此错误:irb(main):001:0>/Users/me/.rvm/gems/ruby-2.0.0-p247/gems/rb-readline-0.4.2/lib/rbreadline.rb:4269:in`blockin_rl_dispatch_subseq':invalidbytesequenceinUTF-8(ArgumentError)我使用rvm来管理我的ruby安装。我正在使用=>ruby-2.0.0-p247[x86_64]我使用bundle来管理我的gem,并且我有rb-readline(0.4.2)(人们推荐的最少
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我将我的Rails应用程序部署到OpenShift,它运行良好,但我无法在生产服务器上运行“Rails控制台”。它给了我这个错误。我该如何解决这个问题?我尝试更新rubygems,但它也给出了权限被拒绝的错误,我也无法做到。railsc错误:Warning:You'reusingRubygems1.8.24withSpring.UpgradetoatleastRubygems2.1.0andrun`gempristine--all`forbetterstartupperformance./opt/rh/ruby193/root/usr/share/rubygems/rubygems
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt