//头一回用新版编辑器,找不到目录按钮在哪儿了😂,大家可以看侧边栏将就一下。
本篇博文将给大家逐步拆分,细致地讲解一下在使用继承关系时,内存中究竟发生了什么。如果对jvm内存毫无了解或了解不多,大家可以先去看一下up之前写过的java创建对象的内存图解,有一定基础的读者就可以直接开始了。🆗,废话少说,Let's go!
我们以Parent类为父类(采用标准JavaBean格式敲),采取多层继承的方式(便于大家加深理解)——首先定义Child类并让Child类去继承Parent类;然后再定义Hua类并让Hua类去继承Child类。最后以Test类为测试类。继承关系图如下:

Parent类代码如下 :
package knowledge.succeed.essence;
/**
* 父类:Parent类(JavaBean标准)
* */
public class Parent {
//成员变量
private String name;
private int age;
//无参构造
public Parent() {
}
//有参构造
public Parent(String name, int age) {
this.name = name;
this.age = age;
}
//getter,setter方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
Child类代码如下 :
package knowledge.succeed.essence;
/**
* Child:子类(派生类)
*/
public class Child extends Parent {
//Child类构造器
public Child () {
}
public Child (String name, int age) {
super(name, age);
}
//Child类成员方法
public void ears() {
System.out.println("动耳神功!");
}
}
Hua类代码如下 :
package knowledge.succeed.essence;
/** 子类的子类 : Hua类 */
public class Hua extends Child{
//Hua类的构造
public Hua() {
}
public Hua(String name, int age) {
super(name, age);
}
//Hua类特有成员方法
public void skill() {
System.out.println("五行相生,分石化玉。");
}
}
Test类代码如下 :
package knowledge.succeed.essence;
//测试类
public class Test {
public static void main(String[] args) {
Hua fuHua = new Hua(); //从这行代码开始执行。
//利用setter,getter方法来修改和获取fuHua对象的属性
// (本质上修改的就是Parent父类的成员变量)
fuHua.setName("云墨丹心");
fuHua.setAge(5000);
System.out.println("fuHua's name = " + fuHua.getName());
System.out.println("fuHua's age = " + fuHua.getAge());
System.out.println("----------------------------------");
//调用Child类的成员方法
fuHua.ears();
//调用Hua类特有的成员方法
fuHua.skill();
}
}
运行结果 :

(u‿ฺu)好滴,我们就以上面的代码为栗,给大家分析一下,在使用继承的整个过程中,内存中究竟发生了神马:
因为main() 函数是程序的唯一入口,因此,包含main函数的Test类的字节码文件会优先加载到方法区。如下图所示 :

main方法加载进栈 ,如下图所示 :

从main方法第一行开始执行代码。第一条语句是创建Hua类对象,从右向左执行。遇到了new关键字,new的是Hua类对象。
因为Hua类的字节码文件此时还没有加载到方法区,jvm无法识别Hua,因此下一步需要将Hua类的字节码文件加载到方法区(假设Hua类成员方法在方法区中的地址值为0x0088)。但是,加载前jvm发现:Hua类继承了Child类,而Child类又继承了Parent类,因此类的字节码文件的加载顺序为 :先加载Parent类,再加载Child类,最后加载Hua类。(假设Child类成员方法在方法区中的地址值为0x0077,Parent类成员方法在方法区中的地址值为0x0066)。如下图所示 :

Hua类的字节码文件加载到方法区之后,new关键字会在堆内存开辟空间给新的Hua类对象,假设Hua类对象在堆内存中的地址值为0x0011。如下图所示 :

根据继承中对象的初始化顺序 : 先初始化父类内容,再初始化子类内容。fuHua对象属于Hua类,而Hua类继承了Child了,Child类又继承了Parent类。这里再强调一点,尽管Parent类中的属性为本类私有,但是Parent类提供的公开的setter和getter方法使得我们可以间接访问Parent类的属性。并且,不管是实例化Child类还是Hua类,最终使用的属性——本质上都是Parent类中的属性。
因此,首先我们要将fuHua对象的堆空间划分出一块来,用于存放Parent类的内容,并根据Parent类的字节码文件,将划分出的空间在分成三部分。当然,其中的成员方法部分,实际保存的是成员方法在方法区中的地址值,将来如果通过对象调用成员方法,可以通过这个保存的地址值进一步找到方法区中的成员方法。如下图所示 :
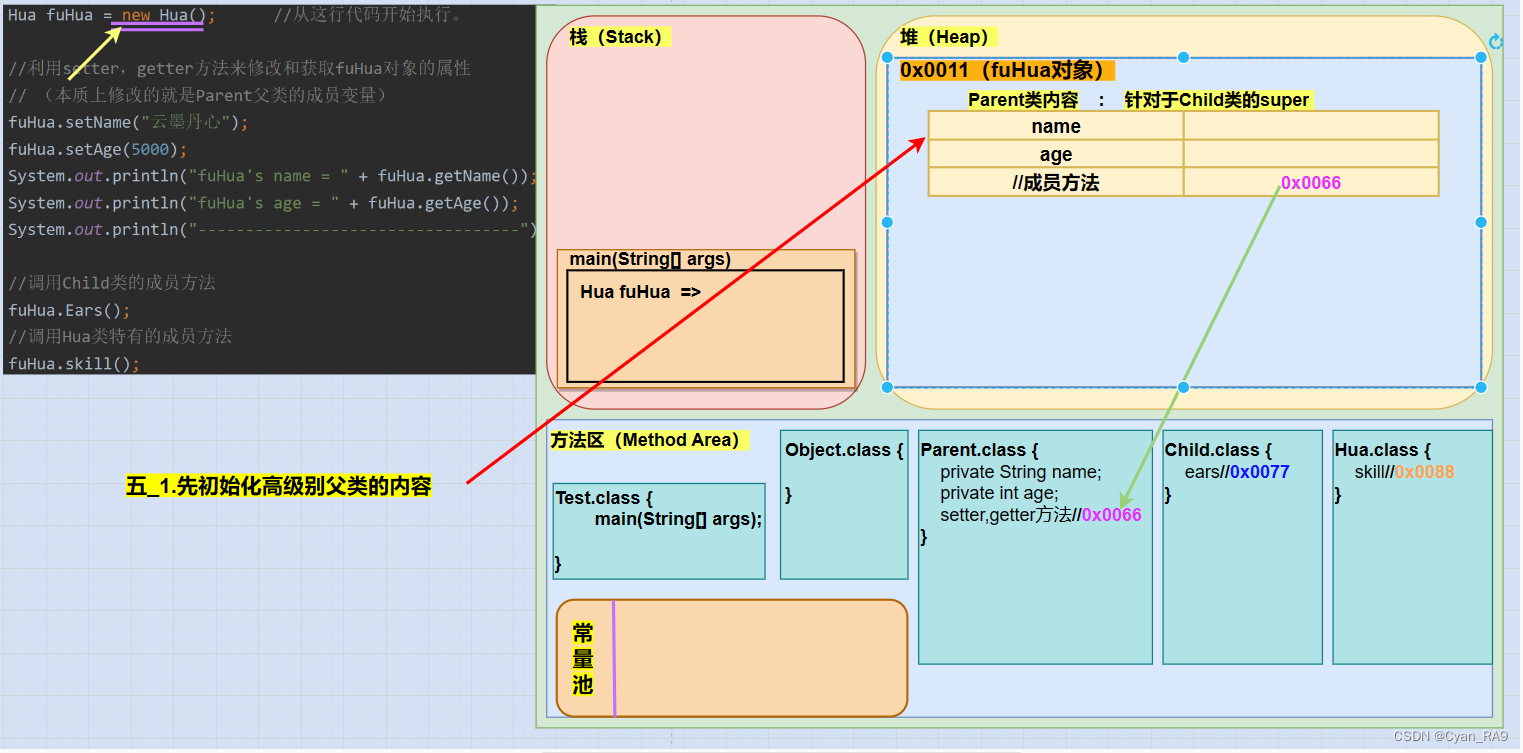
继而,要对Parent类的属性进行初始化,在创建对象的内存图解一文中我们已讲过,对属性的初始化共分为三个步骤 : ①默认初始化,②显式初始化,③构造器初始化。
注意 : name和age属性分别是String类型和int类型,因此默认初始化后的值分别为null和0。而在Parent类中,我们也没有对name和age进行人为的赋值,因此显式初始化步骤省去。又因为我们创建fuHua这一对象时,调用的是Hua类的无参构造,而Hua类的无参构造默认隐含的super语句会调用Child类的无参构造,Child类的无参构造默认隐含的super语句会调用Parent类的无参构造,所以最终会使用Parent类的无参构造来进行构造器初始化,因此构造器初始化后,name和age属性的值仍然为默认值。如下图所示 :

🆗,Parent类内容初始化完成。下一步,要在fuHua对象的堆空间内再划分出一片区域来,去存放Child类的内容。如下图所示 :

Hua类的父类的父类和Hua类的父类都已经初始化完成,下一步就是初始化子类——Hua类的内容了。如下图所示 :

创建的子类对象已初始化完成,最后,把对象的地址值返回给fuHua引用就可以了,如下图所示 :
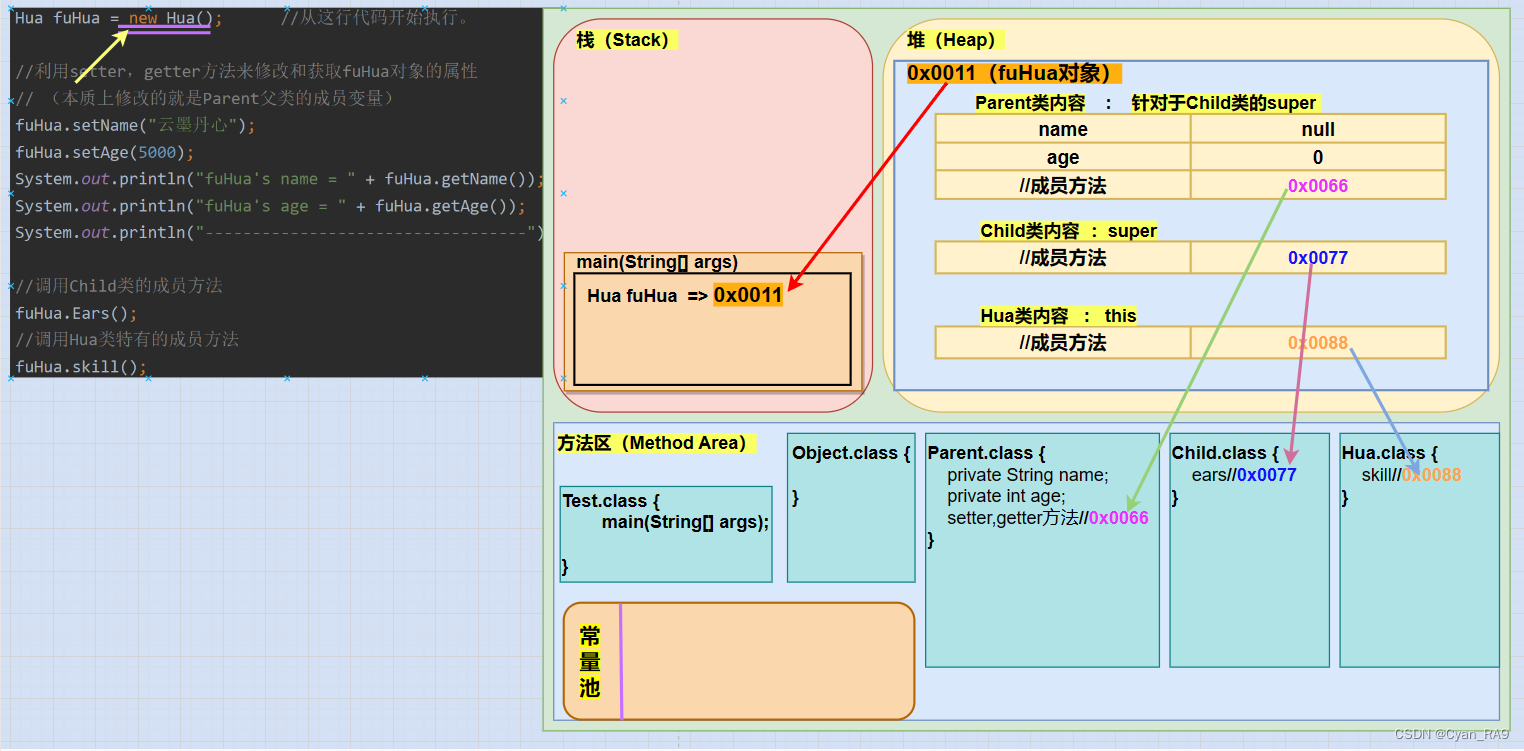
至此,new关键字的操作完成。当我们通过"对象." 的形式来调用时,实质就是通过引用fuHua指向的堆内存中对象的地址,进一步找到对象的成员变量或者成员方法。
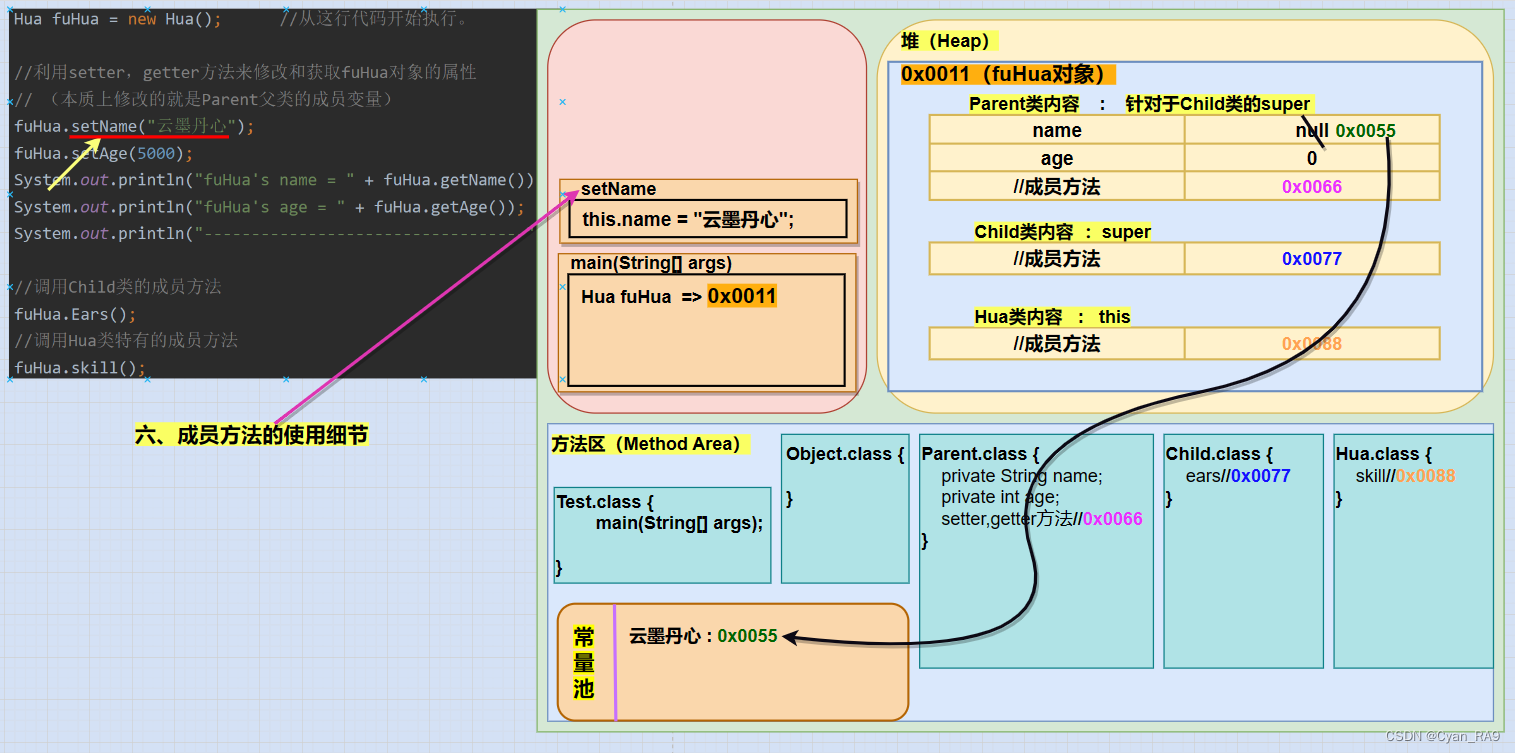
继续执行main中的代码,下一步调用了setName方法,JVM会先通过fuHua这个引用找到堆内存中的对象,然后,再通过对象中Parent类内容的成员方法的地址,进而找到方法区中的成员方法,进行调用。调用setName方法时,setName方法要进栈,如下图所示 :

调用setName方法,方法体中this.name = name;会将传入的形参赋值给Parent类的name成员变量,此处为"云墨丹心"。注意,赋值后,在堆内存中的name属性,实质保存的是"云墨丹心"在常量池中的地址值,真正的"云墨丹心"在常量池内并且有自己的地址值。如下图所示 :
继续向下执行代码,setAge方法的调用与setName原理相同。只不过age属性的值会在堆内存中直接变化。如下图所示 :

继续向下执行代码,两条输出语句中分别调用了getName方法和getAge方法,调用原理仍然不变,同样,这两个方法也要依次进栈。调用getter方法,返回方法对应的属性,因为内存图实在放不下了,所以我这里就简单写了😂。如下图所示 :

接下来有调用Child类的特有方法ears(),以及Hua类的特有方法skill()。其实还是一个套路,先通过对象中保存的成员方法的地址值,找到方法区中对应的成员方法,继而成员方法进栈,实现调用。如下图所示 : (其中,黑色箭头代表Child类的ears方法,蓝色箭头代表Hua类的skill方法)

🆗,到这里main函数中的代码执行完毕。大家一定要记住,创建的fuHua对象,本质上是对分配的堆空间的引用(即指向这里的指针)。真正的对象就是堆空间中分配的这块内容。并且,在继承关系中,不管是本类内容,还是父类内容,都在堆空间的本类对象中。 但平时工作学习中,我们将堆空间的引用简称为了什么什么对象,但它的本质一定要清楚。
以上就是Java中使用继承关系的内存图解,应该是够详细了,至少图文并茂(bushi),如果发现有问题,欢迎指正,大家一起交流。感谢阅读!。
System.out.println("END---------------------------------------------------------------------------");
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我的问题的一个例子是体育游戏。一场体育比赛有两支球队,一支主队和一支客队。我的事件记录模型如下:classTeam"Team"has_one:away_team,:class_name=>"Team"end我希望能够通过游戏访问一个团队,例如:Game.find(1).home_team但我收到一个单元化常量错误:Game::team。谁能告诉我我做错了什么?谢谢, 最佳答案 如果Gamehas_one:team那么Rails假设您的teams表有一个game_id列。不过,您想要的是games表有一个team_id列,在这种情况下
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
在我的系统中,我已经定义了STI。Dog继承自Animal,在animals表中有一个type列,其值为"Dog"。现在我想让SpecialDog继承自dog,只是为了在某些特殊情况下稍微修改一下行为。数据还是一样。我需要通过SpecialDog运行的所有查询,以返回数据库中类型为Dog的值。我的问题是因为我有一个type列,rails将WHERE"animals"."type"IN('SpecialDog')附加到我的查询中,所以我不能获取原始的Dog条目。所以我想要的是以某种方式覆盖rails在通过SpecialDog访问数据库时使用的值,使其表现得像Dog。有没有办法覆盖用于类型