操作符和表达式
分类:
+ - * / %
算术操作符的使用:
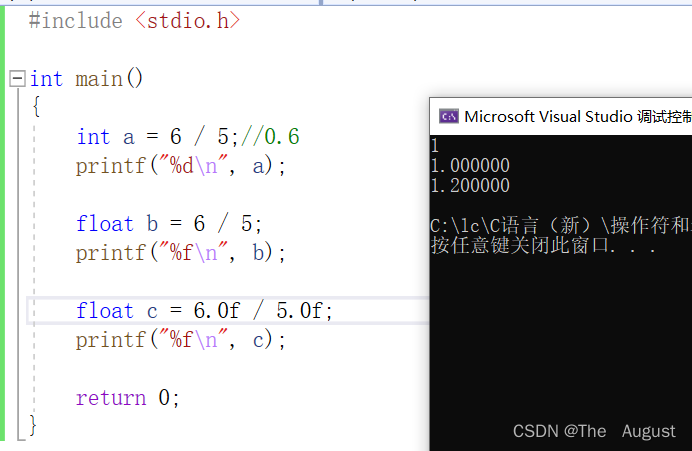
注:直接写出的小数,编译器会默认认为是double类型的数
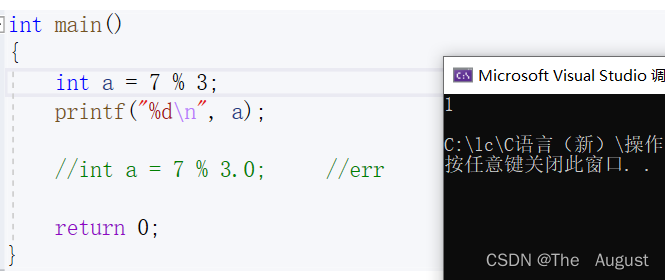
注:%和/是不支持被零除或被零求模的
总结:
<< 左移操作符
>> 右移操作符
左移操作符 移位规则:左边抛弃、右边补0

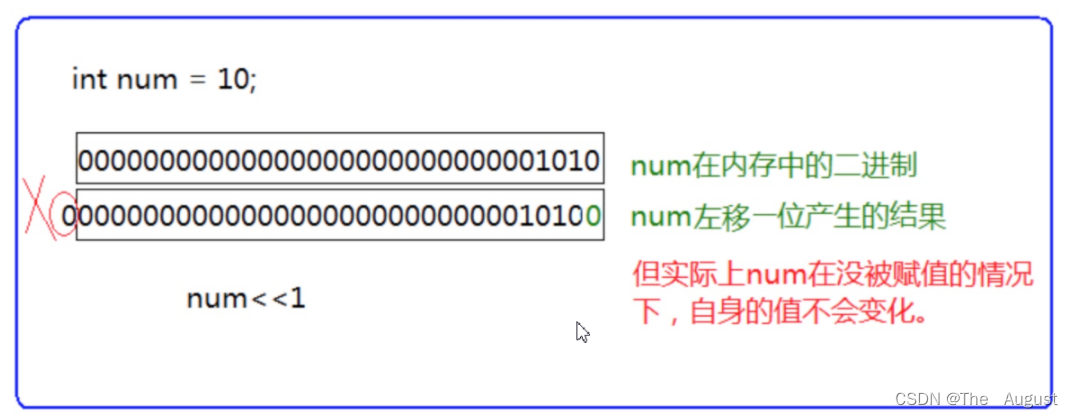
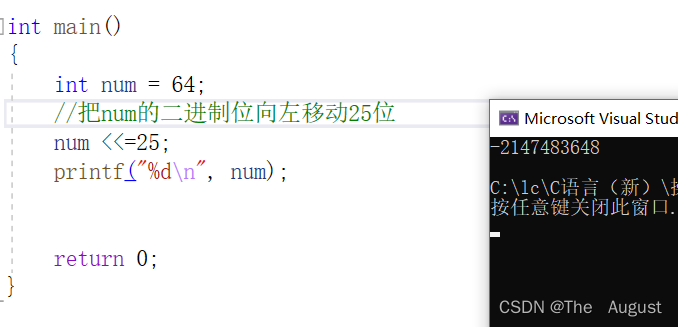
注:左移操作符左边抛弃、右边补0(包括符号位,移动到符号位是什么就是什么)
右移操作符 移位规则:
首先右移运算分两种:


可以看出在VS编译器下采用的是算术右移
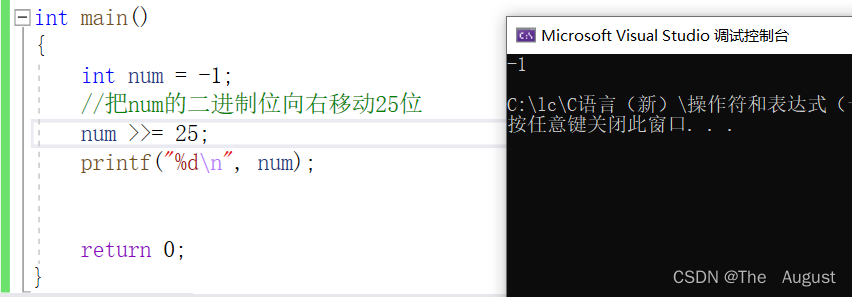
注意:
例如:
int num = 10;
num>>-1;//error
补充:
& //按位与
| //按位或
^ //按位异或
按位与操作符的使用:
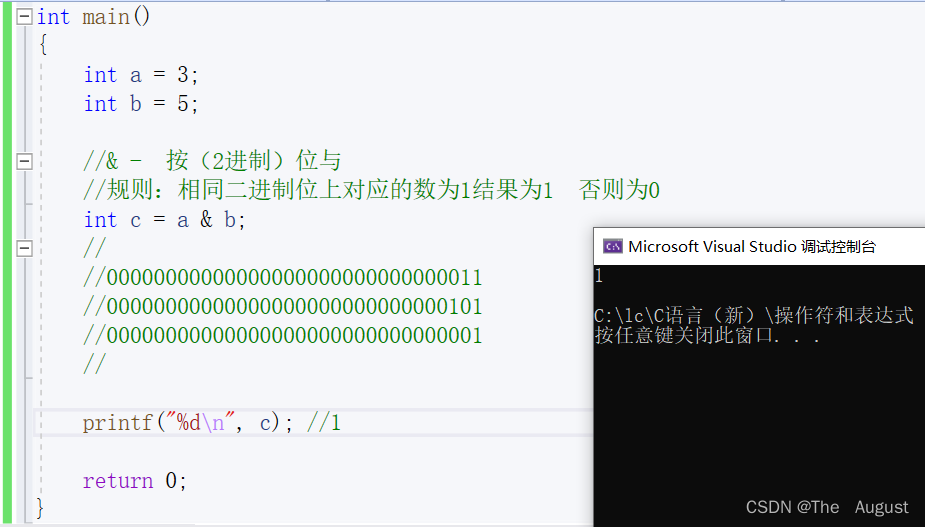
按位或操作符的使用:
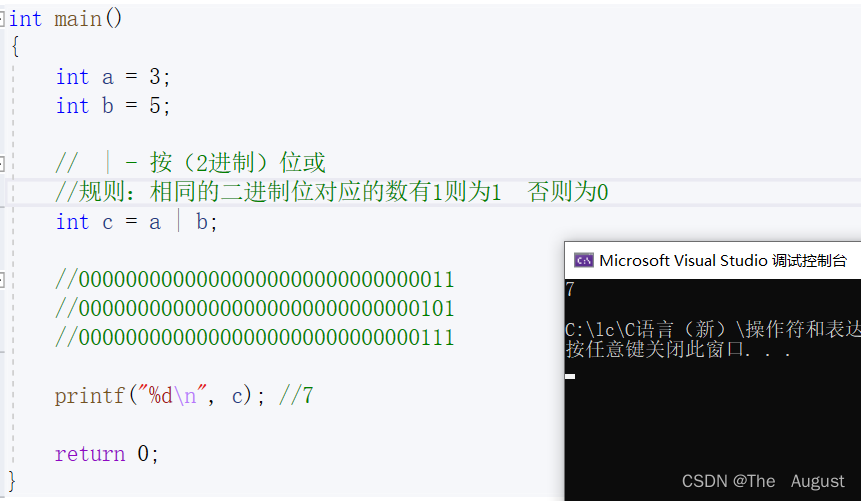
按位异或操作符的使用:
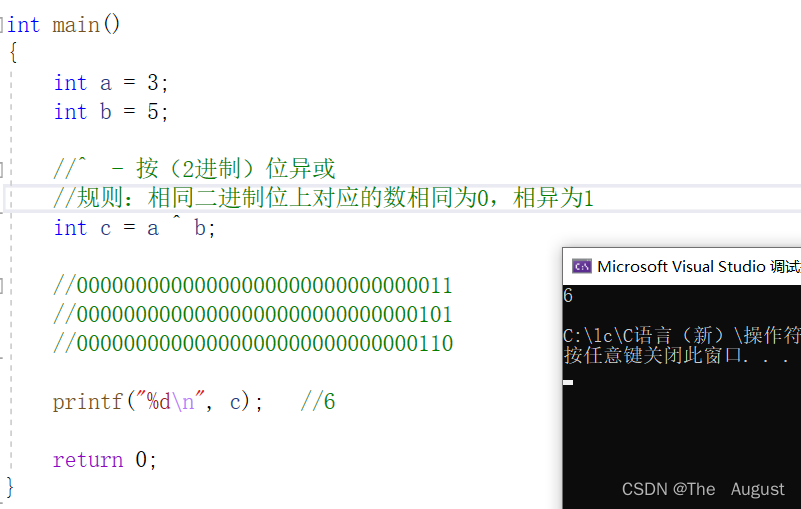
注:
不能创建临时变量(第三个变量),实现两个数的交换。
//版本一:
int main()
{
int a = 3;
int b = 5;
printf("a = %d b = %d\n", a, b);
//数值太大会溢出
a = a + b;
b = a - b;
a = a - b;
printf("a = %d b = %d\n", a, b);
return 0;
}
//版本二:
int main()
{
int a = 3;
int b = 5;
//交换
printf("a=%d b=%d\n", a, b);
a = a ^ b;
b = a ^ b;
a = a ^ b;
printf("a=%d b=%d\n", a, b);
return 0;
}
版本一是有缺陷的,当两个数值过大时两数相加会发生溢出现象(因为int存储是存在范围的,如果过大会发生溢出)。但是版本二就不存在这种现象,因为没有进位就不存在溢出。
编写代码实现:求一个整数存储在内存中的二进制中1的个数。
#include <stdio.h>
int main()
{
int num = -1;
int i = 0;
int count = 0;//计数
while(num)
{
count++;
num = num&(num-1);
}
printf("二进制中1的个数 = %d\n",count);
return 0;
}
赋值操作符的使用:
double salary = 10000.0;
salary = 20000.0;//使用赋值操作符赋值。
//赋值操作符可以连续使用
int a = 10;
int x = 0;
int y = 20;
a = x = y+1;//连续赋值
//与上面的代码含义相同
x = y+1;
a = x;
//这样的写法更加清晰爽朗而且易于调试。
复合赋值符
+=
-=
*=
/=
%=
>>=
<<=
&=
|=
^=
这些运算符都可以写成复合的效果
复合赋值符的使用:
int x = 10;
x = x+10;
x += 10;//复合赋值
//上面两行代码是等价的
//其他运算符一样的道理。这样写更加简洁。
注意:在C语言中=赋值;==判断是否相等
单目操作符是只有一个操作数的操作符
! 逻辑反操作
- 负值
+ 正值
& 取地址
sizeof 操作数的类型长度(以字节为单位)
~ 对一个数的二进制按位取反
-- 前置、后置--
++ 前置、后置++
* 间接访问操作符(解引用操作符)
(类型) 强制类型转换
逻辑反操作符的使用:
int main()
{
int flag = 5;
printf("%d\n", !flag);//0
int u = 0;
printf("%d\n", !u); //1
//flag为真,打印hehe
if (flag)
{
printf("hehe\n");
}
//flag为假,打印haha
if (!flag)
{
printf("haha\n");
}
return 0;
}
注:如果非0的值运用逻辑反操作符得到的是0;如果0值运用逻辑反操作符得到的是1
正值负值操作符的使用:
int a=10;
a=-a;
a=+a; //一般+是省略的
sizeof运算符的使用:

注:sizeof既可以通过变量名计算大小也可以通过类型计算大小
sizeof和数组
#include <stdio.h>
void test1(int arr[])
{
printf("%d\n", sizeof(arr));//4/8
}
void test2(char ch[])
{
printf("%d\n", sizeof(ch));//4/8
}
int main()
{
int arr[10] = {0};
char ch[10] = {0};
printf("%d\n", sizeof(arr));//40
printf("%d\n", sizeof(ch));//10
test1(arr);
test2(ch);
return 0;
}
练习:
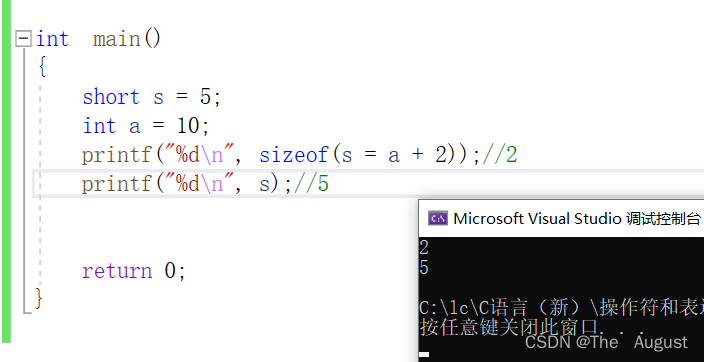
源文件变成可执行程序需要经过编译、链接、运行。s=a+2这样的表达式运行是在运行期间运行的,但是sizeof计算s的大小时sizeof(s=a+2)的时候是在编译期间计算的。sizeof计算s=a+2这个表达式时就已经知道判断的结果s说了算,所以sizeof就把这个计算s所占空间大小的2已经计算好了。计算好之后这个表达式就已经处理完了,所以当真正最终跑到运行期间的时候这个地方s=a+2这个代码就没有了,这个地方相当于就是个2了,打印2是运行期间要做的事情。但是注意s=a+2这个表达式已经在编译期间处理过了所以运行期间s=a+2根本没有计算,因此s的值没有发生过任何改变。
注:sizeof括号中的表达式是不参与运算的
按位取反操作符的使用
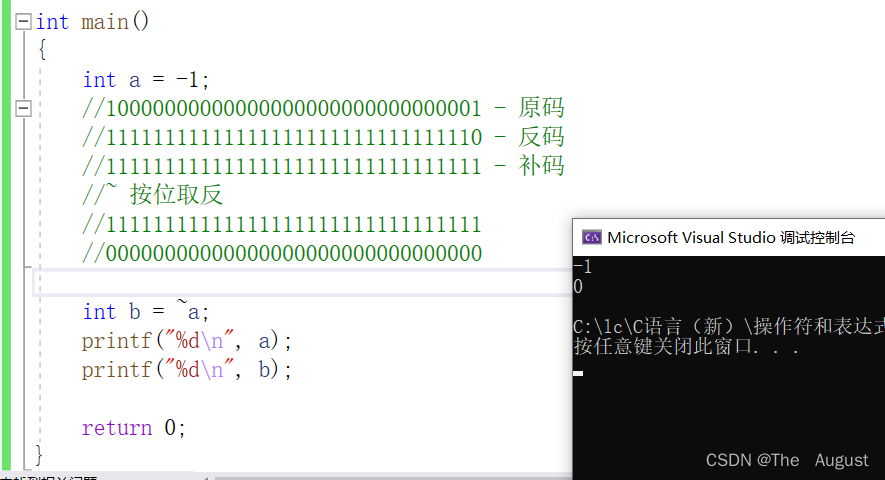
练习:
将特定二进制位上的数置为0或者1
int main()
{
int a = 13;
//把a的二进制中的第5位置成1
a = a | (1 << 4);
//00000000000000000000000000001101
//00000000000000000000000000010000
//00000000000000000000000000011101
printf("a = %d\n", a);//29
//把a的二进制中的第5位置成0
a = a & ~(1 << 4);
//00000000000000000000000000011101
//11111111111111111111111111101111 //00000000000000000000000000010000
//00000000000000000000000000001101
printf("a = %d\n", a);//13
return 0;
}
前置、后置++、–操作符的使用:
int main()
{
int a = 10;
printf("%d\n", a--);//10
printf("%d\n", a);//9
//后置++,先使用,再++
int b = a++; //9
//前置++, 先++,后使用
int c = ++a; //11
//后置--,先使用,后--
int d = a--; //11
//前置--,先--,后使用
int e = --a; //9
return 0;
}
补充:
#include <stdio.h>
int main()
{
int a = 1;
int b = (++a) + (++a) + (++a);
printf("%d\n", b);
return 0;
}
这段代码的运行结果在Linux平台下的gcc编译器中的结果是10;在Windows平台下的VS2019编译器中的结果是12。
取地址、解引用操作符的使用
int main()
{
int a = 10;
printf("%p\n", &a);//& - 取地址操作符
int * pa = &a;//pa是用来存放地址的 - pa就是一个指针变量
*pa = 20;//* - 解引用操作符 - 间接访问操作符
printf("%d\n", a);//20
return 0;
}
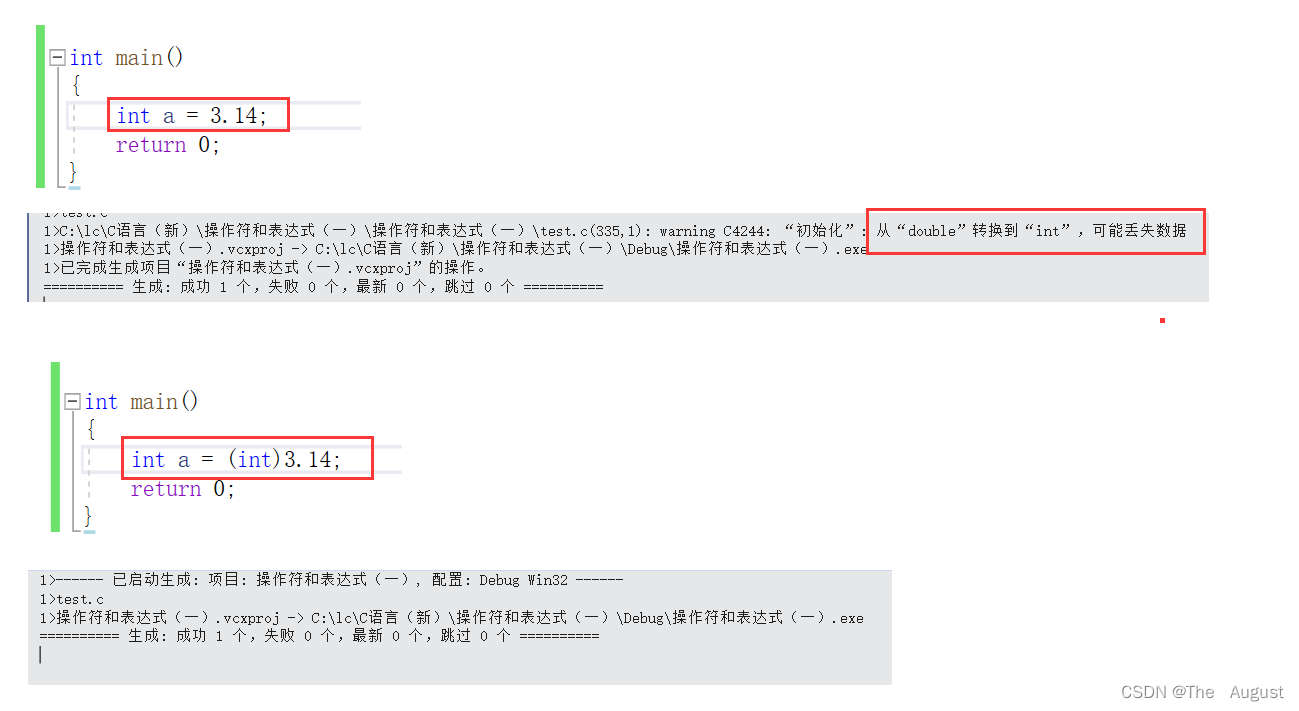
强制类型转换的使用:
> 大于
>= 大于等于
< 小于
<= 小于等于
!= 不相等
== 相等
注:
&& 逻辑与
|| 逻辑或
逻辑与:两者之中只要有一个为假则为假,两者同时为真则为真
逻辑或:两者之中只要有一个为真则为真,两者同时为假则为假
区分逻辑与和按位与 区分逻辑或和按位或
1&2----->0
1&&2---->1
1|2----->3
1||2---->1
经典笔试题:
#include <stdio.h>
int main()
{
int i = 0,a=0,b=2,c =3,d=4;
i = a++ && ++b && d++; //1 2 3 4
//int i = 0,a=1,b=2,c =3,d=4;
//i = a++ && ++b && d++; //2 3 3 5
//i = a++||++b||d++; //1 3 3 4
printf("a = %d\n b = %d\n c = %d\nd = %d\n", a, b, c, d);
return 0;
}
注:逻辑与操作符的特点是只要当前条件为假时,后面的条件不进行判断,整个结果为假;逻辑或操作符的特点是只要当前条件为真时,后面的条件不进行判断,整个结果为真
三目操作符:有三个操作数的操作符
exp1 ? exp2 : exp3
表达式一的结果如果为真整个表达式的结果是表达式二的运行结果;如果为假整个表达式的结果是表达式三的运行结果
如果表达式一结果为真表达式二计算表达式三不计算(表达式二的结果是整个表达式的结果);如果表达式一的结果为假表达式二不计算表达式三计算(表达式三的结果是整个表达式的结果)
条件操作符的使用:
int main()
{
int a = 3;
int b = 0;
int m = 0;
//版本一
if (a > b)
m = a;
else
m = b;
//版本二
//三目操作符
m = (a > b ? a : b);
//这两段代码表示的含义一样
return 0;
}
exp1, exp2, exp3, …expN
逗号表达式,就是用逗号隔开的多个表达式。 逗号表达式中的逗号称为逗号操作符
逗号表达式的使用:
//代码1
int a = 1;
int b = 2;
//逗号表达式
int c = (a>b, a=b+10, a, b=a+1); //a=12 b=13 c=13
//代码2
if (a =b + 1, c=a / 2, d > 0)
//代码3
a = get_val();
count_val(a);
while (a > 0)
{
//业务处理
a = get_val();
count_val(a);
}
//使用逗号表达式改写:
while (a = get_val(), count_val(a), a>0)
{
//业务处理
}
//这两段代码含义相同,只是第一段代码比较冗余
注:逗号表达式,从左向右依次执行。整个表达式的结果是最后一个表达式的结果。
[ ] 下标引用操作符
操作数:一个数组名 + 一个索引值
下标引用操作符的使用:
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 }; //[]定义数组时指定数组大小的一种语法格式
// 0 1 2 3 4
printf("%d\n", arr[4]);//[] - 就是下标引用操作符
//[] 访问数组具体的某一个元素
//[] 的操作数是2个:arr , 4
return 0;
}
( ) 函数调用操作符
函数调用操作符的使用:
//函数的定义
int Add(int x, int y)
{
return x + y;
}
void test()
{}
int main()
{
int a = 10;
int b = 20;
//函数调用
int ret = Add(a, b);//() - 函数调用操作符
//()操作符的操作数有三个:Add、a、b
test();//() - 函数调用操作符
//()操作符的操作数有一个:test
return 0;
}
注:( ) 函数调用操作符接受一个或者多个操作数:第一个操作数是函数名,剩余的操作数就是传递给函数的参数。
访问一个结构的成员
. 结构体.成员名
-> 结构体指针->成员名
结构体成员访问操作符的使用:
//结构成员访问操作符
//.
//->
//创建了一个自定义的类型
struct Book
{
//结构体的成员(变量)
char name[20];
char id[20];
int price;
};
int main()
{
struct Book b = {"C语言", "C20210509", 55};
struct Book * pb = &b;
//结构体指针->成员名
printf("书名:%s\n", pb->name);
printf("书号:%s\n", pb->id);
printf("定价:%d\n", pb->price);
printf("书名:%s\n", (*pb).name);
printf("书号:%s\n", (*pb).id);
printf("定价:%d\n", (*pb).price);
//结构体变量名.成员名
printf("书名:%s\n", b.name);
printf("书号:%s\n", b.id);
printf("定价:%d\n", b.price);
return 0;
}
表达式求值的顺序一部分是由操作符的优先级和结合性决定。同样,有些表达式的操作数在求值的过程中可能需要转换为其他类型。
C的整型算术运算总是至少以缺省整型类型的精度来进行的。为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
整型提升的实例:
//实例1
char a,b,c;
a = b + c;
b和c的值被提升为普通整型,然后再执行加法运算。加法运算完成之后,结果将被截断,然后再存储于a中
如何进行整体提升呢?
整形提升是按照变量的数据类型的符号位来提升的
//负数的整形提升
char c1 = -1;
变量c1的二进制位(补码)中只有8个比特位:
1111111
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为1
提升之后的结果是:
11111111111111111111111111111111
//正数的整形提升
char c2 = 1;
变量c2的二进制位(补码)中只有8个比特位:
00000001
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为0
提升之后的结果是:
00000000000000000000000000000001
//无符号整形提升,高位补0
详解:
int main()
{
char a = 3;
//00000000000000000000000000000011
//00000011 - a
char b = 127;
//00000000000000000000000001111111
//01111111 - b
//这里进行整形算术运算时a和b都是char类型的,都没有达到一个int的大小,这里就需要发生整形提升
char c = a + b;
//00000000000000000000000000000011
//00000000000000000000000001111111
//00000000000000000000000010000010
//发生截断,因为char只能存储1个字节(8比特位),只能放低8比特位
//10000010 - c
//内存中存储的是补码,内存中计算是以补码的形式计算的。%d打印是以原码的形式进行打印的
//11111111111111111111111110000010 - 补码
//11111111111111111111111110000001 - 反码
//10000000000000000000000001111110 - 原码
//-126
//%d有符号的整形打印,这里需要进行整型提升
printf("%d\n", c);//打印出来肉眼可见的是原码
//-126
return 0;
}
总结:表达式中的字符和短整型操作数在进行计算时,会进行整型提升。这是因为在运算时不管是字符和短整型都没有达到整形的大小,但是CPU计算的时候又是用整形的方式计算的,这个时候把字符和短整型提升成整形,那计算的精度也会变高。
注:非整型类型只要参与运算就会整型提升这句话是错的。float不需要整型提升的,自身的大小达不到整形大小才会进行整型提升的
整形提升的例子:
实例一:
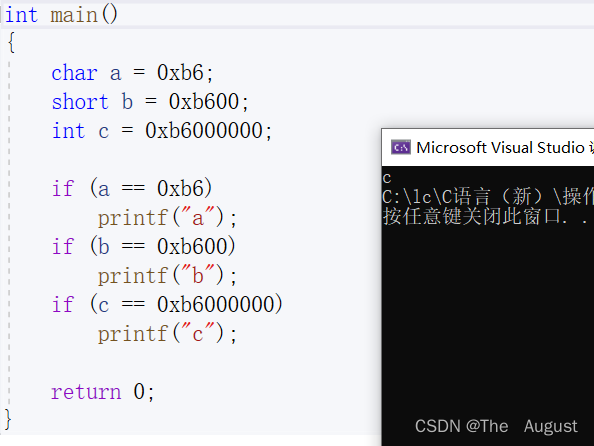
实例一中的a,b要进行整形提升(因为要进行比较),但是c不需要整形提升(因为c是整型) a,b整形提升之后,变成了负数,所以表达式a == 0xb6,b == 0xb600 的结果是假,但是c不发生整形提升,则表达式 c==0xb6000000 的结果是真
实例二:
int main()
{
char c = 1;
printf("%u\n", sizeof(c));//1
printf("%u\n", sizeof(+c));//4
printf("%u\n", sizeof(-c));//4
printf("%u\n", sizeof(!c));//4 这里以gcc编译器为准 gcc - 4(在vs中运行结果是1)
return 0;
}
实例二中的c只要参与表达式运算就会发生整形提升,表达式 +c会发生提升,所以sizeof(+c) 是4个字节。表达式 -c 也会发生整形提升,所以 sizeof(-c) 是4个字节。表达式 !c 也会发生整形提升,所以 sizeof(!c) 是4个字节(这里以gcc为准,因为gcc编译器设计时更接近C语言标准)。但是sizeof( c ) ,就是1个字节。
注:
补充:sizeof函数返回的类型是无符号整数
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数的转换为另一个操作数的类型,否则操作就无法进行。下面的层次体系称为寻常算术转换
long double
double
float
unsigned long int
long int
unsigned int
int
如果某个操作数的类型在上面这个列表中排名较低,那么首先要转换为另外一个操作数的类型后执行运算。
注:
float f = 3.14;
int num = f;//隐式转换,会有精度丢失
复杂表达式的求值有三个影响的因素:
两个相邻的操作符先执行哪个?取决于他们的优先级。如果两者的优先级相同,取决于他们的结合性。
int main()
{
int a = 4;
int b = 5;
//int c = a + b * 7;//优先级决定了计算顺序
int c = a + b + 7;//优先级不起作用,结合性决定了顺序
return 0;
}
操作符优先级
| 操作符 | 描述 | 用法示例 | 结果类型 | 结合性 | 是否控制求值顺序 |
|---|---|---|---|---|---|
| () | 聚组 | (表达式) | 与表达式同 | N/A | 否 |
| () | 函数调用 | rexp(rexp,…,rexp) | rexp | L-R | 否 |
| [ ] | 下标引用 | rexp[rexp] | lexp | L-R | 否 |
| . | 访问结构成员 | lexp.member_name | lexp | L-R | 否 |
| -> | 访问结构指针成员 | rexp->member_name | lexp | L-R | 否 |
| ++ | 后缀自增 | lexp ++ | rexp | L-R | 否 |
| – | 后缀自减 | lexp – | rexp | L-R | 否 |
| ! | 逻辑反 | ! rexp | rexp | R-L | 否 |
| ~ | 按位取反 | ~ rexp | rexp | R-L | 否 |
| + | 单目,表示正值 | + rexp | rexp | R-L | 否 |
| - | 单目,表示负值 | - rexp | rexp | R-L | 否 |
| ++ | 前缀自增 | ++ lexp | rexp | R-L | 否 |
| – | 前缀自减 | – lexp | rexp | R-L | 否 |
| * | 间接访问 | * rexp | lexp | R-L | 否 |
| & | 取地址 | & lexp | rexp | R-L | 否 |
| sizeof | 取其长度,以字节表示 | sizeof rexp sizeof(类型) | rexp | R-L | 否 |
| (类型) | 类型转换 | (类型) rexp | rexp | R-L | 否 |
| * | 乘法 | rexp * rexp | rexp | L-R | 否 |
| / | 除法 | rexp / rexp | rexp | L-R | 否 |
| % | 整数取余 | rexp % rexp | rexp | L-R | 否 |
| + | 加法 | rexp + rexp | rexp | L-R | 否 |
| - | 减法 | rexp - rexp | rexp | L-R | 否 |
| << | 左移位 | rexp << rexp | rexp | L-R | 否 |
| >> | 右移位 | rexp >> rexp | rexp | L-R | 否 |
| > | 大于 | rexp > rexp | rexp | L-R | 否 |
| >= | 大于等于 | rexp >= rexp | rexp | L-R | 否 |
| < | 小于 | rexp < rexp | rexp | L-R | 否 |
| <= | 小于等于 | rexp <= rexp | rexp | L-R | 否 |
| == | 等于 | rexp == rexp | rexp | L-R | 否 |
| != | 不等于 | rexp != rexp | rexp | L-R | 否 |
| & | 位与 | rexp & rexp | rexp | L-R | 否 |
| ^ | 位异或 | rexp ^ rexp | rexp | L-R | 否 |
| | | 位或 | rexp | rexp | rexp | L-R | 否 |
| && | 逻辑与 | rexp && rexp | rexp | L-R | 是 |
| || | 逻辑或 | rexp || rexp | rexp | L-R | 是 |
| ? : | 条件操作符 | rexp ? rexp : rexp | rexp | N/A | 是 |
| = | 赋值 | lexp = rexp | rexp | R-L | 否 |
| += | 以…加 | lexp += rexp | rexp | R-L | 否 |
| -= | 以…减 | lexp -= rexp | rexp | R-L | 否 |
| *= | 以…乘 | lexp *= rexp | rexp | R-L | 否 |
| /= | 以…除 | lexp /= rexp | rexp | R-L | 否 |
| %= | 以…取模 | lexp %= rexp | rexp | R-L | 否 |
| <<= | 以…左移 | lexp <<= rexp | rexp | R-L | 否 |
| >>= | 以…右移 | lexp >>= rexp | rexp | R-L | 否 |
| &= | 以…与 | lexp &= rexp | rexp | R-L | 否 |
| ^= | 以…异或 | lexp ^= rexp | rexp | R-L | 否 |
| |= | 以…或 | lexp |= rexp | rexp | R-L | 否 |
| , | 逗号 | rexp,rexp | rexp | L-R | 是 |
有一些表达式是没有办法确定唯一的计算路径的——问题表达式
一些问题表达式:
实例一:
//表达式的求值部分由操作符的优先级决定。
a*b + c*d + e*f
注释:实例一在计算的时候,由于比+的优先级高,只能保证* 的计算是比+早,但是优先级并不能决定第三个* 比第一个+早执行。
所以表达式的计算顺序就可能是:
a*b
c*d
a*b + c*d
e*f
a*b + c*d + e*f
或者:
a*b
c*d
e*f
a*b + c*d
a*b + c*d + e*f
实例二:
c + --c;
注释:同上,操作符的优先级只能决定自减–的运算在+的运算的前面,但是并没有办法得知,+操作符的左操作数的获取在右操作数之前还是之后求值,所以结果是不可预测的,是有歧义的。
实例三:
//非法表达式
int main()
{
int i = 10;
i = i-- - --i * ( i = -3 ) * i++ + ++i;
printf("i = %d\n", i);
return 0;
}
实例三在不同编译器中测试结果:非法表达式程序的结果
| 值 | 编译器 |
|---|---|
| -128 | Tandy 6000 Xenix 3.2 |
| -95 | Think C 5.02(Macintosh) |
| -86 | IBM PowerPC AIX 3.2.5 |
| -85 | Sun Sparc cc(K&C编译器) |
| -63 | gcc,HP_UX 9.0,Power C 2.0.0 |
| 4 | Sun Sparc acc(K&C编译器) |
| 21 | Turbo C/C++ 4.5 |
| 22 | FreeBSD 2.1 R |
| 30 | Dec Alpha OSF1 2.0 |
| 36 | Dec VAX/VMS |
| 42 | Microsoft C 5.1 |
实例四:
int fun()
{
static int count = 1;
return ++count;
}
int main()
{
int answer;
answer = fun() - fun() * fun();
printf( "%d\n", answer);
return 0;
}
这个代码是有实际的问题。虽然在大多数的编译器上求得结果都是相同的。但是上述代码 answer = fun() - fun() * fun(); 中只能通过操作符的优先级得知:先算乘法,再算减法。但函数的调用先后顺序无法通过操作符的优先级确定。
实例五:
#include <stdio.h>
int main()
{
int i = 1;
int ret = (++i) + (++i) + (++i);
printf("%d\n", ret);
printf("%d\n", i);
return 0;
}
这个代码是有问题的。在Linux平台下gcc编译器中的结果是10(3+3+4);而在Windows平台下VS编译器中的结果是12(4+4+4)。看看同样的代码产生了不同的结果,因为这段代码中的第一个 + 在执行的时候,第三个++是否执行,这个是不确定的。因为依靠操作符的优先级和结合性是无法决定第一个 + 和第三个前置 ++ 的先后顺序。
总结:程序员写出的表达式如果不能通过操作符的属性确定唯一的计算路径,那这个表达式就是存在问题的。
补充:
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://
我需要一个非常简单的字符串验证器来显示第一个符号与所需格式不对应的位置。我想使用正则表达式,但在这种情况下,我必须找到与表达式相对应的字符串停止的位置,但我找不到可以做到这一点的方法。(这一定是一种相当简单的方法……也许没有?)例如,如果我有正则表达式:/^Q+E+R+$/带字符串:"QQQQEEE2ER"期望的结果应该是7 最佳答案 一个想法:你可以做的是标记你的模式并用可选的嵌套捕获组编写它:^(Q+(E+(R+($)?)?)?)?然后你只需要计算你获得的捕获组的数量就可以知道正则表达式引擎在模式中停止的位置,你可以确定匹配结束
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.