注意力机制是自深度学习快速发展后广泛应用于自然语言处理、统计学习、图像检测、语音识别等领域的核心技术,例如将注意力机制与RNN结合进行图像分类,将注意力机制运用在自然语言处理中提高翻译精度,注意力机制本质上说就是实现信息处理资源的高效分配,例如先关注场景中的一些重点,剩下的不重要的场景可能会被暂时性地忽略,注意力机制能够以高权重去聚焦重要信息,以低权重去忽略不相关的信息,并且还可以不断调整权重,使得在不同的情况下也可以选取重要的信息。其基本网络框架如图所示。
注意力机制自提出后,影响了基于深度学习算法的许多人工智能领域的发展。而当前注意力机制已成功地应用于图像处理、自然语言处理和数据预测等方面,其中包括注意力机制与传统算法循环神经网络(Recurrent Neural Network,RNN) 、 编 − 解 码 器 (encoder- decoder)、长短期记忆(Long Short-Term Memory,LSTM)人工神经网络等的结合,并应用于图像处理、自然语言处理和数据预测等领域;以及以自注意力(self-attention)为基本结构单元的transformer、reformer 和Hopfield 等算法。
注意力机制的第一次提出是在视觉图像领域中,指出注意力的作用就是将之前传统的视觉搜索方法进行优化, 可选择地调整视觉对网络的处理,减少了需要处理的样本数据并且增加了样本间的特征匹配。但是因为结构的简单,无法检测到特征间的相关性,并且没有任何循环机制,所以在整个视觉识别过 程中,无法重现图像轮廓,因此人们就想到了将注意力机制与具有循环机制的循环神经网络(RNN)结合,RNN 结构和展开图:
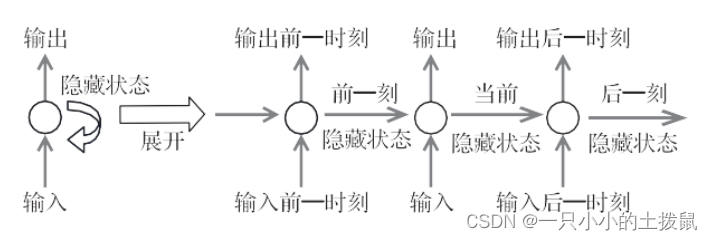
RNN下一时刻的输出与前面多个时刻的输入和自己当前状态有关,因此能够保留特征间的相关性,但是由于每一步状态的记录也会导致误差累积,从而有可能造成梯度爆炸;并且如果输入过多的序列信息,梯度的传递性不是很高,也会出现梯度消失的现象,而循环神经网络(RNN)模型与 attention 机制结合,利用注意力机制对特定的区域进行高分辨率处理。将注意力集中在图片中特定的部分,不是处理全部图像,而是有针对性地选择相应位置处理,提取图像中的关键信息同时忽略无关信息,网络层数也不会过深,梯度爆炸的问题也得到了解决。使整个模型的性能提高。
利用神经网络实现机器翻译属于encoder-decoder 机制,但是encoder-decoder 方法有个明显缺陷就是,它的编码解码都是对应定长的句子,所以当输入不同长度的句子时,这个方法的性能往往会降低很多;此外针对不同语言需要选择不同的编解码器,所以不具有普遍适用性。而基于注意力机制的对齐和翻译联合学习的方法是将输入都转换为向量,然后在解码过程中根据注意力机制自适应地选择向量的子集,避免了将输入句子压缩,保留完整句子信息。基本模型如下所示:
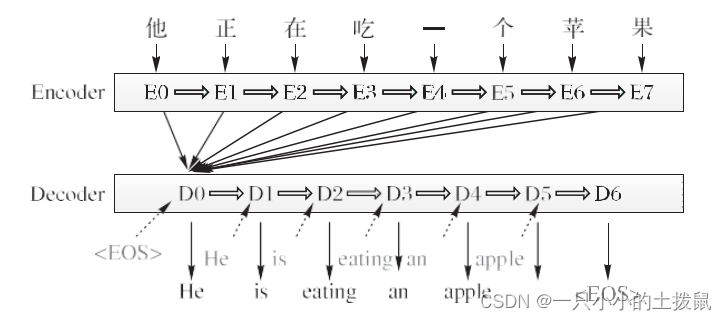
当输入长度不同的句子时,编码只需把所有输入转换为向量,而解码则自适应地选择向量长度,所 以可以让模型更好地处理不同长度的句子。
传统神经网络预测数据常使用RNN 进行预测, 但是这种方法同样因为训练层数多和长距离的序列时常存在梯度爆炸和梯度消失等问题,因此一种结合了注意力机制想法的 RNN 变体出现 —— 长短期记忆人工神经网络(LSTM)。LSTM 本质上仍然是一种RNN 的递归神经网络结构[35], 但它能够解决RNN 中存在的梯度消失问题,是因为它有着独特设计的“门”结构(输入门、遗忘门和输出门),其结构单元如图所示。
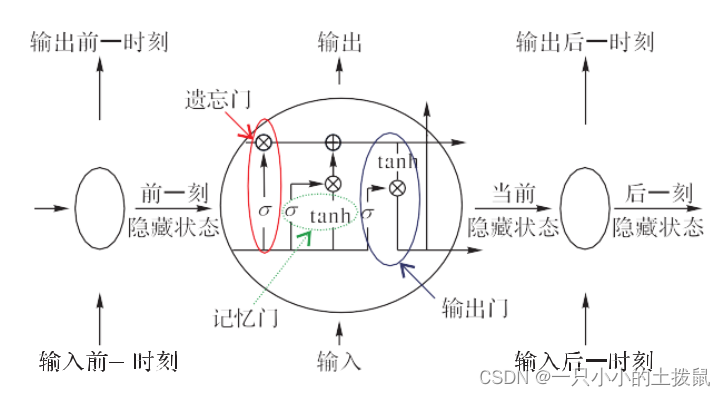
LSTM 模型结构将细胞单元进行了扩充,其中遗忘门就是决定“忘记”哪些无用的信息;而记忆门则是决定保留哪些重要信息,从而进行传递;输出门则是将遗忘门和记忆门的细胞状态进行整合,然后输出至下一个细胞单元。它将细胞单元进行更改,新增“遗忘门”“记忆门”和“输出门”就是为了对长序列进行挑选,然后将较长的序列转化为包含有重要信息的短序列,将数据进行传递,有效解决了传统算法预测数据时的问题。
Vaswani 等在2017 年发表的“Attention is all you need”介绍了以self-attention为基本单元的Transformer 模型,使得注意力机制得到真正的成功运用。transformer 是由左边的编码器和右边的解码器组成。编码器负责把输入序列进行位置编码后映射为隐藏层,然后解码器再把隐藏层映射为输出序列。编码器包含 4 个部分:
编码器的第一个位置是将输入的数据转换为向量,通过位置编码后,将其输入到多头注意力。这里的位置编码就是记录序列数据之间顺序的相关性,相比较之前的RNN 顺序输入,transformer 方法不需要将数据一一输入,可以直接并行输入,并存储好数据之间的位置关系,大大提高了计算速度,减少了存储空间。
第二部分的多头注意力是为了获取数据内部之间的相关性,弥补了CNN 方法中数据缺少关联性的缺点。
第三部分是残差连接和标准化,在映射关系转换过程中,往往会存在计算产生的残差,而残差的存在会因为网络层数的增加,模型学习的映射关系越来越不精确,因此要通过残差连接和层标准化,有效提高模型的学习能力,并使数据更加标准,加快收敛,是一种优化技巧。
最后再通过由两个全连接层组成的前向反馈层,将学习得到的数据进行非线性映射,即加大强的部分,减小弱的部分,最后再标准化,这样通过编码器得到的学习结果更加精准和具有代表性。
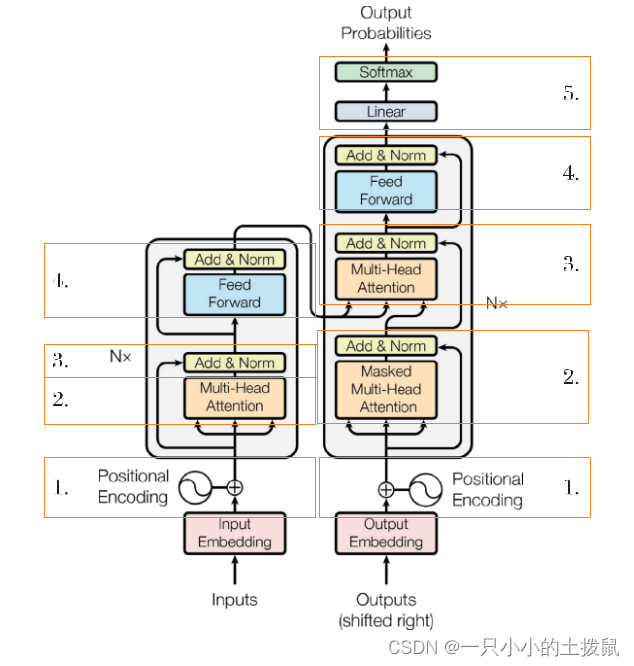
根据transformer 结构可知,解码器相对比编码器是在第二部分多了一个掩码多头注意力。这个的目的是因为前面编码器训练时数据的长度是不一样的,而这里的解码器将这些数据中最大的长度作为计算单元进行训练,并且只需要之前数据对当前的影响,而不需要未来数据对它的影响,因此将后面未来预测的数据利用函数掩码掉,从而不参与训练。之后的两项与解码器中相同,最后再通过一次线性化和softmax 层完成输出,这里的线性化和softmax 层是将向量转换为输出所要求的类型,如机器翻译中,就会将向量根据概率大小选出合适的词语,从而完成翻译。
transformer 通过注意力机制、编码解码、残差前馈网络和线性化等解决了许多问题。如解决了传统神经网络算法训练 慢的缺陷,是因为它根据 CNN 中的卷积思想,结合了多头注意力,实现并行计算,大大加快了计算速度,并在多项语言翻译任务中取得较好的结果;而位置编码又使得 transformer 具备了CNN 欠缺而RNN 擅长的能力,将序列数据间的关系可以存储下来,在自然语言处理的上下文语义等应用方面得到了 广泛的应用。但是同时 transformer 也有其他缺陷,如只能让长序列得到高效处理,短序列的效率并没有得到提高;针对长序列。训练这些模型的成本就会很高。
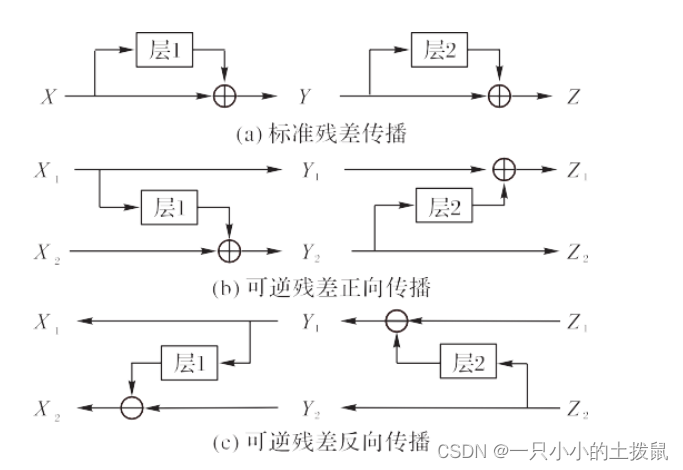
针对transformer 中一些缺陷,reformer 对其进行了改进。首先是将transformer 中的点积注意力替换为局部位置敏感哈希注意力。transformer 中的多头注意力是并行计算并叠加, 它计算两个数据点之间的attention score 需要将多个自注意力连起来因此导致计算量很大,所占内存较多。而reformer 选了用局部敏感哈希注意力,代替多头注意力。此外,在训练网络时为了反向传播计算,往往每一层的激活值都要被记录下来,所以层数越多,所占内存也越多。因此reformer 便提出了用可逆残差取代标准残差层。在反向传播时按需计算每个层的激活值,而不需要把它们都存在内存中,在网络中的最后一 层激活值可以恢复中间任何一层的激活值。可逆残差层如图所示。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput