1.@Component注解与其衍生注解
(1) 在Spring中,@Component注解用于说明某个类是一个bean,之后Spring在类路径扫描过程中会将该bean添加至容器中;@Component注解还有很多衍生注解,如@Repository, @Service和@Controller,它们分别用于三层架构中的持久层,业务层和控制层,因此,对于一个业务层的普通Service类,一般情况下用@Component或@Service都是可行的,但更推荐用@Service注解,因为该注解不仅能清晰的指明被标注的类是一个业务类,此外,这些注解还是Spring AOP的理想切入目标,能方便的对某一层进行切入(例如:切入控制层,进行权限校验)
(2) Spring提供的许多注解都可以用作元注解,如Spring的@RestController注解,它就是将@Controller和@ResponseBody注解组合出来的一个新注解,使用该注解,在我们期望类中所有方法都返回json格式数据时,就不用在每一个方法上都标注@ResponseBody注解了,因此,Spring推荐我们根据业务需要,结合元注解来实现自定义注解
2.自动扫描并注册bean
(1) 上文我们提到了@Component注解等,那么,Spring该如何扫描到这些注解并将它们注入进容器中呢? 这就需要类路径扫描注解@ComponentScan了,我们需要把它添加到有@Configuration注解标注的配置类上,在容器启动后,Spring就会扫描指定包下的bean并将其注入进容器中,如下所示
//声明3个类,这三个类均位于cn.example.spring.boke同一个包下,其中ExampleA和ExampleB被注解标注,表明它们是bean,需要被注入进容器中,ExampleC是一个普通的类
@Service
public class ExampleA { }
@Component
public class ExampleB { }
public class ExampleC { }
//使用@Configuration注解定义一个配置类,在该配置类上,使用@ComponentScan注解指定包扫描路径为cn.example.spring.boke,这时,Spring就会扫描该包以及该包的子包下所有符合条件的bean,并将它们注入容器中,该注解等同于在之前提到过的<context:component-scan base-package="..."/>标签
@Configuration
@ComponentScan("cn.example.spring.boke")
public class Config { }
//启动容器,注意这里使用的是AnnotationConfigApplicationContext容器,而非之前的ClassPathXmlApplicationContext容器,而我们也不再需要xml配置文件,实现了完全的基于注解的配置
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(Config.class);
Arrays.stream(ctx.getBeanDefinitionNames()).forEach(System.out::println);
//打印结果如下,可以看到,容器扫描到了exampleA和exampleB以及我们的配置类config,而忽略了exampleC(其他的bean是Spring隐式自动添加的)
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.annotation.internalCommonAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
config
exampleA
exampleB
3.使用过滤器来自定义组件扫描规则
(1) 默认情况下,Spring仅检测被@Component、@Repository、@Service、@Controller、@Configuration和以@Component等作为元注解的自定义注解(如:@RestController)标注的类,不过,我们可以通过自定义@ComponentScan注解中的过滤器属性includeFilters和excludeFilters来修改这一默认行为,如下
//只修改上面例子中的配置类,此处假设我们只扫描被@Service注解标注的类,其自定义过滤规则如下
//includeFilters:要被注入的 excludeFilters:不要被注入的 @ComponentScan.Filter:指定过滤类型
@Configuration
@ComponentScan(basePackages = "cn.example.spring.boke",
includeFilters = @ComponentScan.Filter(Component.class),
excludeFilters = @ComponentScan.Filter(Service.class))
public class Config {
}
//输出结果如下,可见我们的exampleA已被排除在外
org.springframework.context.annotation.internalConfigurationAnnotationProcessor
org.springframework.context.annotation.internalAutowiredAnnotationProcessor
org.springframework.context.annotation.internalCommonAnnotationProcessor
org.springframework.context.event.internalEventListenerProcessor
org.springframework.context.event.internalEventListenerFactory
config
exampleB
exampleC
过滤类型:
| 过滤类型 | 说明 |
|---|---|
| annotation(默认,按照注解过滤) | 如上面例子中的属性excludeFilters = @ComponentScan.Filter(Service.class),就是排除掉所有被@Service注解标注的类 |
| assignable( 按照类型过滤) | 例如:excludeFilters = @ComponentScan.Filter(type = FilterType.ASSIGNABLE_TYPE, value = ExampleA.class),就是排除掉ExampleA这个类型的bean |
| aspectj(按照切面表达式过滤) | 例如:cn.example..*Service+,这是一个切入点表达式,会对所有符合这个切入点表达式的bean进行过滤 |
| regex(按照正则表达式过滤) | 同上,只不过满足的是正则表达式 |
| custom(自定义过滤器) | 实现org.springframework.core.type.TypeFilter接口来自定义过滤器,实现自定义过滤规则 |
(2) 设置@ComponentScan注解中的useDefaultFilters属性值为false,来禁用默认过滤器,即关闭Spring对于那些默认注解(如@Component等)的自动扫描检测
4.在组件中定义bean的元数据
(1) 除了上面使用注解的方式外,我们还可以通过@Bean注解,在Spring的某个组件(即bean)中定义其他bean的元数据,并将这个bean提供给Spring,如下
//配置类
@Configuration
@ComponentScan(basePackages = "cn.example.spring.boke")
public class Config { }
//一个普通的类
public class ExampleA {}
//在FactoryMethodComponent这个组件中定义bean exampleA的配置元数据,并将其提供给Spring容器
//除了如下所示使用@Component注解外,还可以使用@Configuration注解
@Component
public class FactoryMethodComponent {
//使用@Bean注解,表明该方法是一个工厂方法,它返回的结果需要向Spring中注入
//还可以根据需要,使用其他的注解如@Scope,@Lazy来修饰这个被返回的bean
@Bean
@Qualifier("exampleA")
public ExampleA exampleAInstance() {
return new ExampleA();
}
}
//启动容器,打印其中的bean,可以发现bean exampleA已被注入进容器中
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(Config.class);
Arrays.stream(ctx.getBeanDefinitionNames()).forEach(System.out::println);
(2) 在使用@Bean注解向容器中注入bean过程中,我们还可以使用InjectionPoint来查看这个返回的bean最后会作为容器中的哪个bean的属性从而被实例化的,一般用于确定原型bean或懒加载bean的创建时机,例子如下
public class ExampleA { }
//懒加载的bean:exampleB和exampleC,它们都依赖ExampleA
@Component
@Lazy
public class ExampleB {
@Autowired
private ExampleA exampleA;
}
@Component
@Lazy
public class ExampleC {
@Autowired
private ExampleA exampleA;
}
//用于注入bean exampleA
@Component
public class FactoryMethodComponent {
//使用InjectionPoint,查看究竟是因为ExampleB依赖了ExampleA,从而导致ExampleA被创建,还是因为ExampleC依赖了ExampleA,从而导致ExampleA被创建
//同样也定义ExampleA为懒加载,避免容器提前就创建好了这些bean
@Bean
@Lazy
public ExampleA exampleAInstance(InjectionPoint injectionPoint) {
System.out.println("exampleA is created for " + injectionPoint.getMember().getDeclaringClass().getName());
return new ExampleA();
}
}
//配置类
@Configuration
@ComponentScan(basePackages = "cn.example.spring.boke")
public class Config {}
//启动容器,查看打印结果
AnnotationConfigApplicationContext ctx = new AnnotationConfigApplicationContext(Config.class);
ctx.getBean(ExampleB.class);
//打印结果如下,可以看到,是因为上面需要获取到ExampleB,而ExampleB又依赖了ExampleA,从而导致Spring创建了ExampleA,可见导致ExampleA被创建的源头在于ExampleB,因此,InjectionPoint就是用来指明被注入的bean是作为哪个bean的依赖项而被实例化的,这就是InjectionPoint的语义
exampleA is created for cn.example.spring.boke.ExampleB
//如果我们将上面的获取ExampleB改为获取ExampleC,输出的结果就会指明ExampleA是因为ExampleC的缘故而被创建
ctx.getBean(ExampleC.class);
(3) 上面提到了,@Bean注解既可以放在由@Component注解标注的类中,又可以放在由@Configuration注解标注的类中,它们之间的区别是@Component类没有被CGLIB增强,不会拦截其中的方法或字段的调用
5.命名组件
(1) Spring在组件扫描过程中,所扫描到的组件的名称是由BeanNameGenerator策略生成的,在一般情况下,组件的名称就是类名首字母小写,如下
//默认情况下,类名首字母小写,因此下面这个bean的名称为exampleA
@Component
public class ExampleA { }
//当然,我们也可以自定义bean的名称,如下面这个bean的名称不再是exampleB,而是我们提供的bbb
@Component("bbb")
public class ExampleB { }
(2) 如果我们不想是用Spring提供的这个默认的bean的命名策略,我们可以实现BeanNameGenerator接口(需确保提供一个无参构造函数),来自定义bean的命名策略,然后将它作为@ComponentScan注解的属性nameGenerator的值即可,如下所示
@Configuration
@ComponentScan(basePackages = "cn.example.spring.boke", nameGenerator = MyNameGenerator.class)
public class Config {
// ...
}
(3) 在某些情况下,会出现不同包中出现相同类名的类的情况,如下t1包下存在类A,t2包下也存在类A,此时,如果这两个类都要作为Spring的bean,按照默认的命名规则,在容器启动时,便会抛出bean命名冲突的异常,此时,我们就可以使用Spring所提供的,以类的全路径作为bean名称的BeanNameGenerator:FullyQualifiedAnnotationBeanNameGenerator,来解决这一冲突
6.为检测到组件声明作用域
(1) 默认情况下,Spring自动扫描所添加的组件的作用域为singleton,我们可以用@Scope注解来指明其他的作用域,如下
//默认情况下,下面这个bean,它的作用域为singleton
@Component
public class ExampleA { }
//使用@Scope注解来改变它的作用域,注意该注解只有标注在和@Component及其衍生注解或@Bean注解一同使用时才有效
@Component
@Scope("prototype")
public class ExampleA { }
(2) 如果我们想要自定义Scope的解析规则,可以实现ScopeMetadataResolver接口(记得要在其中提供一个无参构造函数),然后将其注册为@ComponentScan注解的scopeResolver属性即可
(3) 在之前,我们讨论过了,一个singleton依赖了另一个非singleton的bean的情况,在这种情况下,我们就需要使用代理,来避免singleton bean始终依赖的是同一个非singleton bean,而@ComponentScan注解上的scopedProxy属性就可用来为非singleton bean配置代理模式,它有4个取值,分别为:DEFAULT - 不使用代理, NO - 按情况选择,如果类实现了接口就使用JDK代理,如果没有实现接口就使用CGLib代理, INTERFACES - 使用JDK代理, TARGET_CLASS - 使用CGLib代理,如下所示
//一个prototype类型的bean exampleA
@Component
@Scope("prototype")
public class ExampleA { }
//配置scopedProxy属性,使非singleton bean使用CGLib代理
@Configuration
@ComponentScan(basePackages = "cn.example.spring.boke", scopedProxy = ScopedProxyMode.TARGET_CLASS)
public class Config { }
//启动,打印,可以看到如下两个exampleA,其中一个是Spring生成的代理对象
scopedTarget.exampleA
exampleA
7.为候选组件生成索引
(1) 尽管类路径扫描的很快,但Spring还提供了一个创建候选bean列表功能,来提升大型应用程序的启动性能,它本质上就是先把所有的bean都列出来存到一个文件中,启动时直接加载这个文件读取就行,不需要再全部遍历扫描一遍了,为了实现这一功能,首先我们得加一个Spring提供的索引依赖如下
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-indexer</artifactId>
<version>5.2.22.RELEASE</version>
<optional>true</optional>
</dependency>
</dependencies>
然后,执行maven的clean和package命令,查看新打出来的jar包,在META-INF目录下,就可以查看到Spring为我们生成的候选bean列表文件spring.components
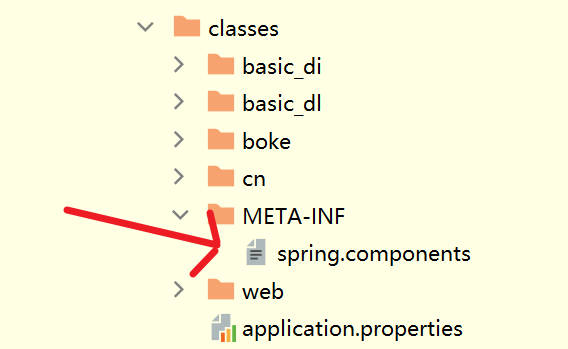
其内容如下所示,都是我们应用程序中自定义的bean
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我安装了ruby版本管理器,并将RVM安装的ruby实现设置为默认值,这样'哪个ruby'显示'~/.rvm/ruby-1.8.6-p383/bin/ruby'但是当我在emacs中打开inf-ruby缓冲区时,它使用安装在/usr/bin中的ruby。有没有办法让emacs像shell一样尊重ruby的路径?谢谢! 最佳答案 我创建了一个emacs扩展来将rvm集成到emacs中。如果您有兴趣,可以在这里获取:http://github.com/senny/rvm.el
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
如何使此根路径转到:“/dashboard”而不仅仅是http://example.com?root:to=>'dashboard#index',:constraints=>lambda{|req|!req.session[:user_id].blank?} 最佳答案 您可以通过以下方式实现:root:to=>redirect('/dashboard')match'/dashboard',:to=>"dashboard#index",:constraints=>lambda{|req|!req.session[:user_id].b
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我需要根据字符串路径的长度将字符串路径数组转换为符号、哈希和数组的数组给定以下数组:array=["info","services","about/company","about/history/part1","about/history/part2"]我想生成以下输出,对不同级别进行分组,根据级别的结构混合使用符号和对象。产生以下输出:[:info,:services,about:[:company,history:[:part1,:part2]]]#altsyntax[:info,:services,{:about=>[:company,{:history=>[:part1,:pa
我想用这两种语言中的任何一种(最好是ruby)制作一个窗口管理器。老实说,除了我需要加载某种X模块外,我不知道从哪里开始。因此,如果有人有线索,如果您能指出正确的方向,那就太好了。谢谢 最佳答案 XCB,X的下一代API使用XML格式定义X协议(protocol),并使用脚本生成特定语言绑定(bind)。它在概念上与SWIG类似,只是它描述的不是CAPI,而是X协议(protocol)。目前,C和Python存在绑定(bind)。理论上,Ruby端口只是编写一个从XML协议(protocol)定义语言到Ruby的翻译器的问题。生