1. Git 对象
Git 的核心部分是一个简单的键值对数据库。可以向 Git 仓库中插入任意类型的内容,它会返回一个唯一的键,通过该键可以在任意时刻再次取回该内容。
所有内容均以树对象和数据对象的形式存储,其中树对象对应了 UNIX 中的目录项,数据对象则大致上对应了 inodes 或文件内容。一个树对象包含了一条或多条树对象记录(tree entry),每条记录含有一个指向数据对象或者子树对象的 SHA-1 指针,以及相应的模式、类型、文件名信息。
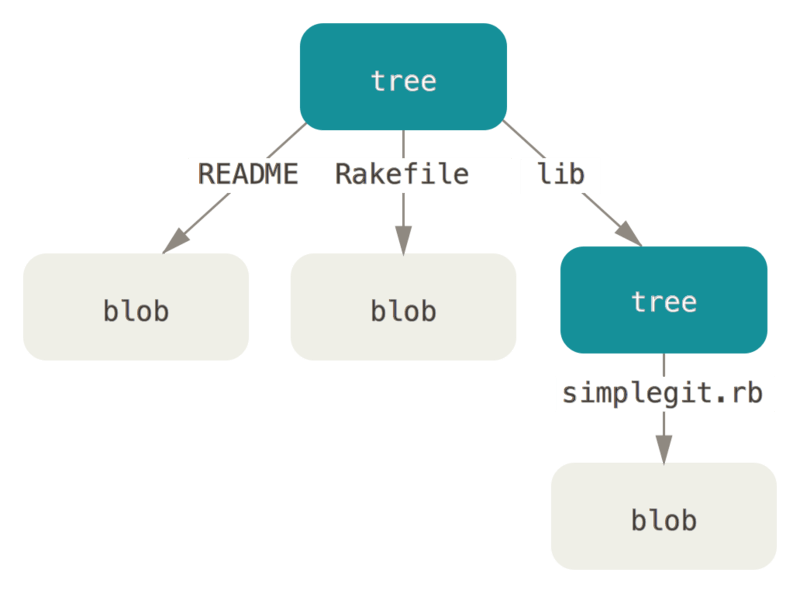
Git 保存的不是文件的变化或者差异,而是一系列不同时刻的快照 。
在进行提交操作时,Git 会保存一个提交对象(commit object),它包含指向树对象的指针。
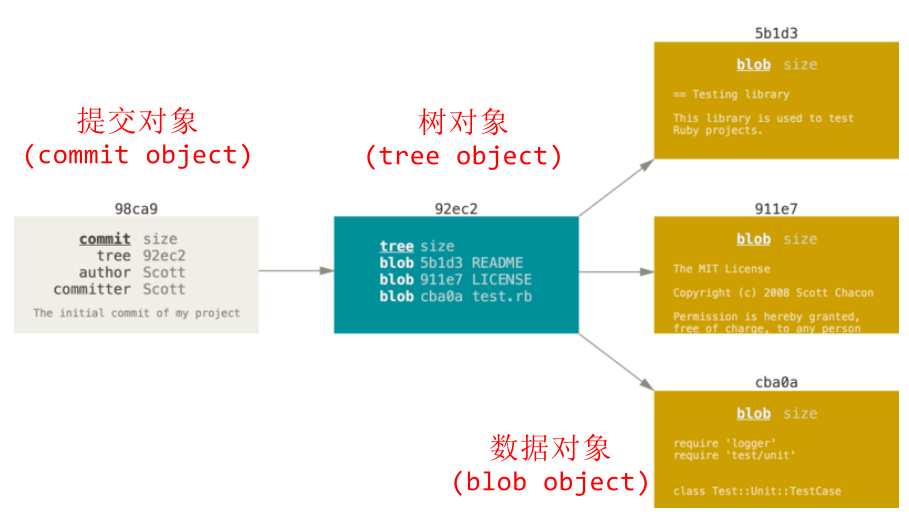
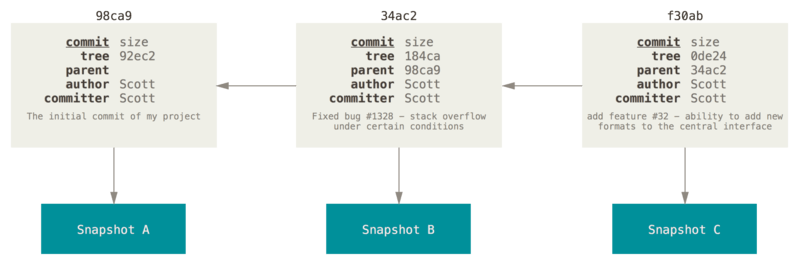
每次产生的提交对象会包含一个指向上次提交对象(父对象)的指针,首次提交产生的提交对象没有父对象,普通提交操作产生的提交对象有一个父对象, 而由多个分支合并产生的提交对象有多个父对象。
2. git branch
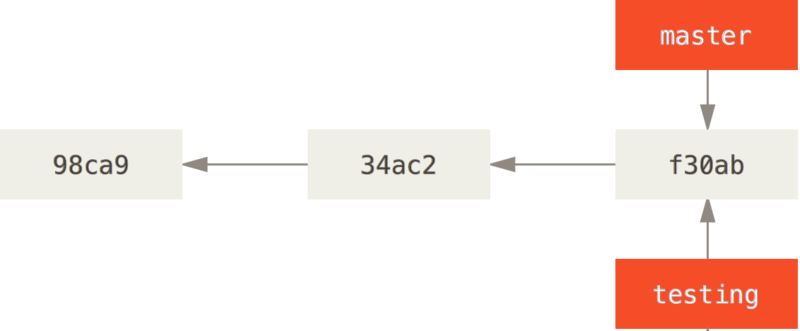
Git 的分支,其实本质上仅仅是指向提交对象的可变指针。 Git 的默认分支名字是 master。 在多次提交操作之后,你其实已经有一个指向最后那个提交对象的 master 分支。master 分支会在每次提交时自动向前移动。
注意:Git 的 master 分支并不是一个特殊分支。 它就跟其它分支完全没有区别。 之所以几乎每一个仓库都有 master 分支,是因为 git init 命令默认创建它,并且大多数人都懒得去改动它。
git branch 命令可以列出你所有的分支、创建新分支、删除分支及重命名分支。比如,创建一个 testing 分支:
git branch testing这会在当前所在的提交对象上创建一个指针。
在 Git 中,HEAD 是一个特殊指针,指向当前所在的本地分支(PS:将 HEAD 想象为当前分支的别名)
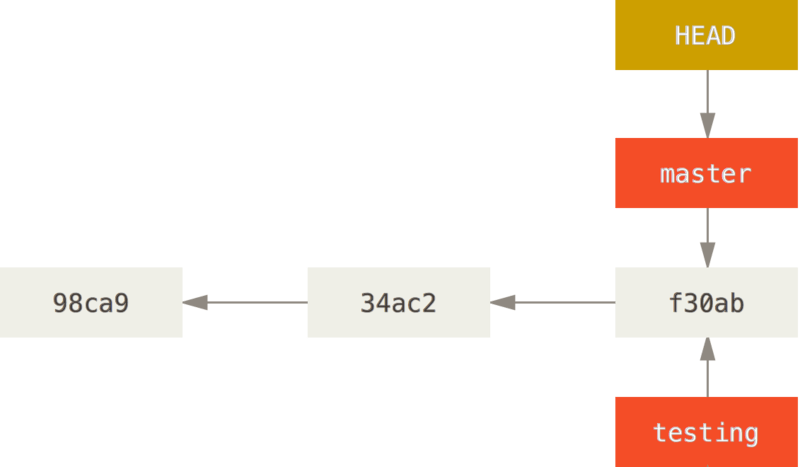
由于 Git 的分支实质上仅是包含所指对象校验和(长度为 40 的 SHA-1 值字符串)的文件,所以它的创建和销毁都异常高效。
3. git checkout
git checkout 命令用来切换分支,或者检出内容到工作目录。
git checkout testing这样 HEAD 就指向 testing 分支了。
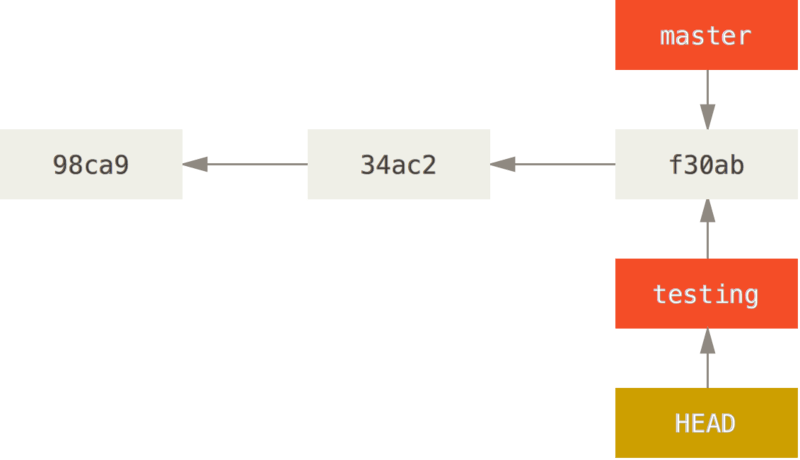
注意:分支切换会改变你工作目录中的文件。如果是切换到一个较旧的分支,你的工作目录会恢复到该分支最后一次提交时的样子。 如果 Git 不能干净利落地完成这个任务,它将禁止切换分支。
使用 git checkout -- <file> 可以撤消对文件的修改
使用 git reset HEAD <file>... 可以取消文件的暂存
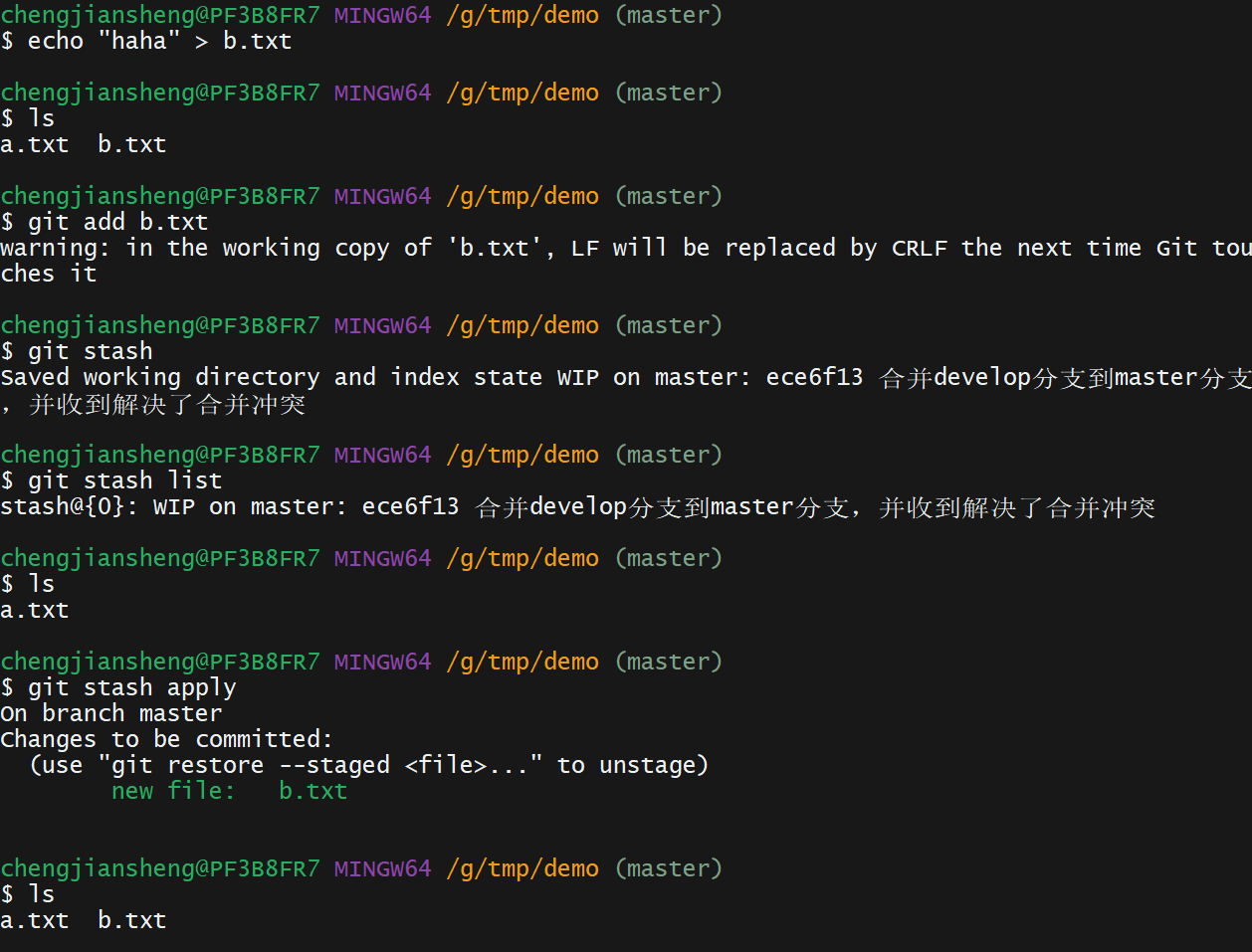
4. git stash
git stash 命令用来临时地保存一些还没有提交的工作,以便在分支上不需要提交未完成工作就可以清理工作目录。
当你在项目的一部分上已经工作一段时间后,所有东西都进入了混乱的状态, 而这时你想要切换到另一个分支做一点别的事情。 问题是,你不想仅仅因为过会儿回到这一点而为做了一半的工作创建一次提交。 针对这个问题的答案是 git stash 命令。
贮藏(stash)会处理工作目录的脏的状态——即跟踪文件的修改与暂存的改动——然后将未完成的修改保存到一个栈上, 而你可以在任何时候重新应用这些改动(甚至在不同的分支上)。
# 新的贮藏推送到栈上
git stash
# 查看贮藏的东西
git stash list
# 将你刚刚贮藏的工作重新应用
git stash apply从贮藏创建一个分支
如果贮藏了一些工作,将它留在那儿了一会儿,然后继续在贮藏的分支上工作,在重新应用工作时可能会有问题。 如果应用尝试修改刚刚修改的文件,你会得到一个合并冲突并不得不解决它。这种情况下,可以运行 git stash branch <new branchname> 以你指定的分支名创建一个新分支,检出贮藏工作时所在的提交,重新在那应用工作,然后在应用成功后丢弃贮藏。
5. git clean
git clean 这个命令被设计为从工作目录中移除未被追踪的文件
默认情况下,git clean 命令只会移除没有忽略的未跟踪文件
使用 git clean -f -d 命令来移除工作目录中所有未追踪的文件以及空的子目录
如果只是想要看看它会做什么,可以使用 git clean -d -n
6. git reset
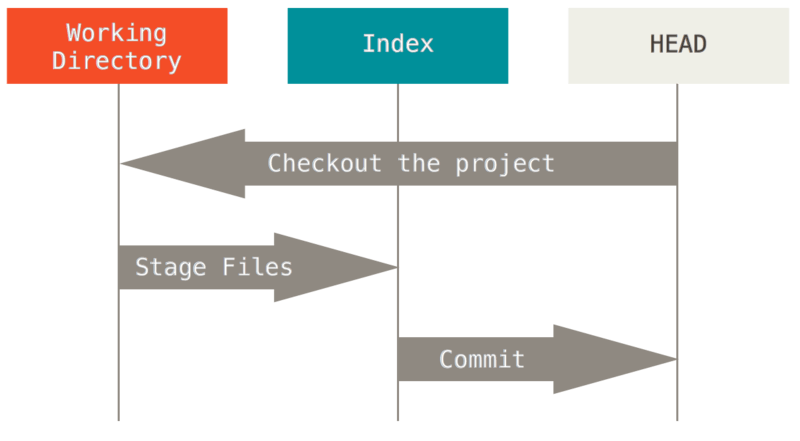
6.1. 三棵树
“树” 在这里的实际意思是 “文件的集合”,而不是指特定的数据结构。
Git 作为一个系统,是以它的一般操作来管理并操纵这三棵树的:
HEAD 是当前分支引用的指针,它总是指向该分支上的最后一次提交。 这表示 HEAD 将是下一次提交的父结点。 通常,理解 HEAD 的最简方式,就是将它看做 该分支上的最后一次提交 的快照。
索引是你的 预期的下一次提交。 我们也会将这个概念引用为 Git 的“暂存区”,这就是当你运行 git commit 时 Git 看起来的样子。
Git 将上一次检出到工作目录中的所有文件填充到索引区,它们看起来就像最初被检出时的样子。 之后你会将其中一些文件替换为新版本,接着通过 git commit 将它们转换为树来用作新的提交。
工作目录(通常也叫 工作区)。 另外两棵树以一种高效但并不直观的方式,将它们的内容存储在 .git 文件夹中。 工作目录会将它们解包为实际的文件以便编辑。 你可以把工作目录当做 沙盒。在你将修改提交到暂存区并记录到历史之前,可以随意更改。
6.2. 工作流程
经典的 Git 工作流程是通过操纵这三个区域来以更加连续的状态记录项目快照的。
6.3. 重置的效果
假设现在是这样的
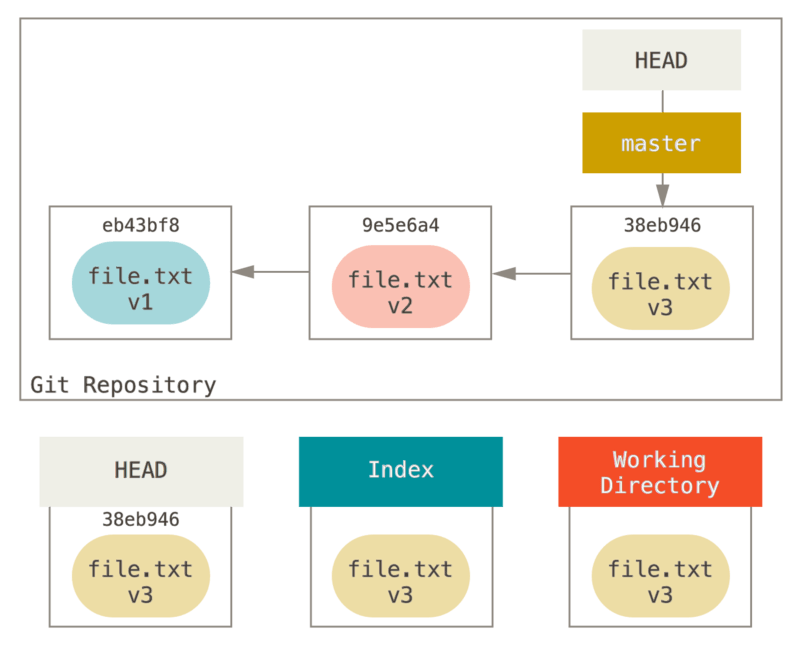
reset 做的第一件事是移动 HEAD 的指向。 这与改变 HEAD 自身不同(checkout 所做的);reset 移动 HEAD 指向的分支。 这意味着如果 HEAD 设置为 master 分支(例如,你正在 master 分支上), 运行 git reset 9e5e6a4 将会使 master 指向 9e5e6a4。
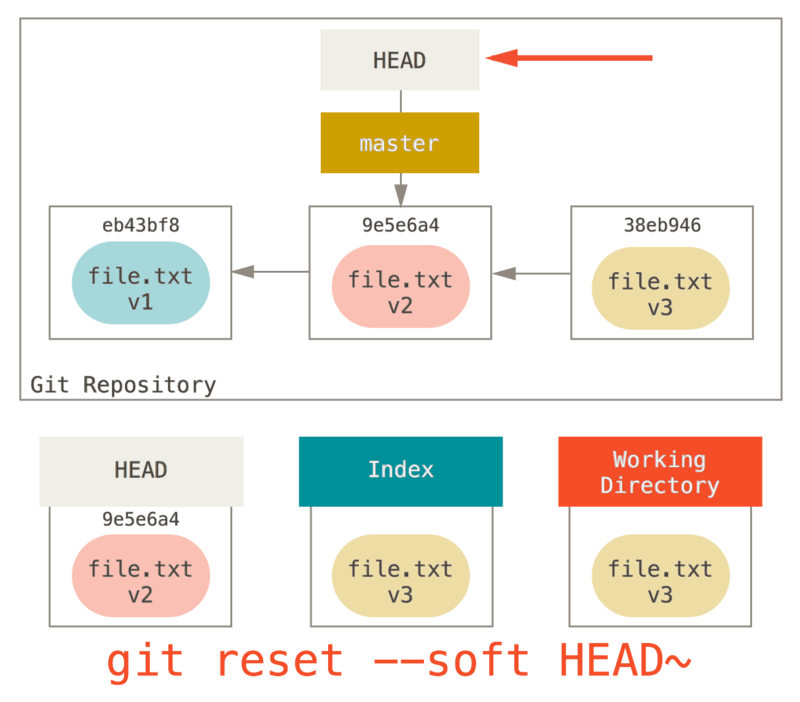
无论你调用了何种形式的带有一个提交的 reset,它首先都会尝试这样做。 使用 reset --soft,它将仅仅停在那儿。
现在看一眼上图,理解一下发生的事情:它本质上是撤销了上一次 git commit 命令。 当你在运行 git commit 时,Git 会创建一个新的提交,并移动 HEAD 所指向的分支来使其指向该提交。 当你将它 reset 回 HEAD~(HEAD 的父结点)时,其实就是把该分支移动回原来的位置,而不会改变索引和工作目录。
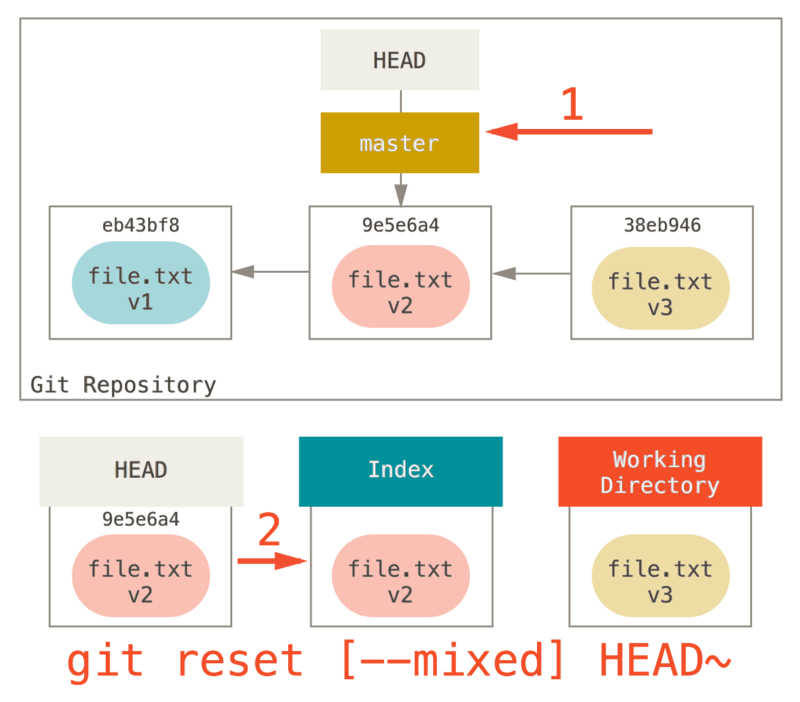
如果指定 --mixed 选项,reset 将会在这时停止。 这也是默认行为,所以如果没有指定任何选项(在本例中只是 git reset HEAD~),这就是命令将会停止的地方。
现在再看一眼上图,理解一下发生的事情:它依然会撤销一上次 提交,但还会 取消暂存 所有的东西。 于是,我们回滚到了所有 git add 和 git commit 的命令执行之前。
reset 要做的的第三件事情就是让工作目录看起来像索引。 如果使用 --hard 选项,它将会继续这一步。

注意:其他任何形式的 reset 调用都可以轻松撤消,但是 --hard 选项不能,因为它强制覆盖了工作目录中的文件。
回顾一下:
reset 命令会以特定的顺序重写这三棵树,在你指定以下选项时停止:
6.4. 通过路径来重置
前面讲述了 reset 基本形式的行为,不过你还可以给它提供一个作用路径。 若指定了一个路径,reset 将会跳过第 1 步,并且将它的作用范围限定为指定的文件或文件集合。 这样做自然有它的道理,因为 HEAD 只是一个指针,你无法让它同时指向两个提交中各自的一部分。 不过索引和工作目录 可以部分更新,所以重置会继续进行第 2、3 步。
现在,假如我们运行 git reset file.txt (这其实是 git reset --mixed HEAD file.txt 的简写形式,因为你既没有指定一个提交的 SHA-1 或分支,也没有指定 --soft 或 --hard),它会:
所以它本质上只是将 file.txt 从 HEAD 复制到索引中。

它还有 取消暂存文件 的实际效果。 如果我们查看该命令的示意图,然后再想想 git add 所做的事,就会发现它们正好相反。
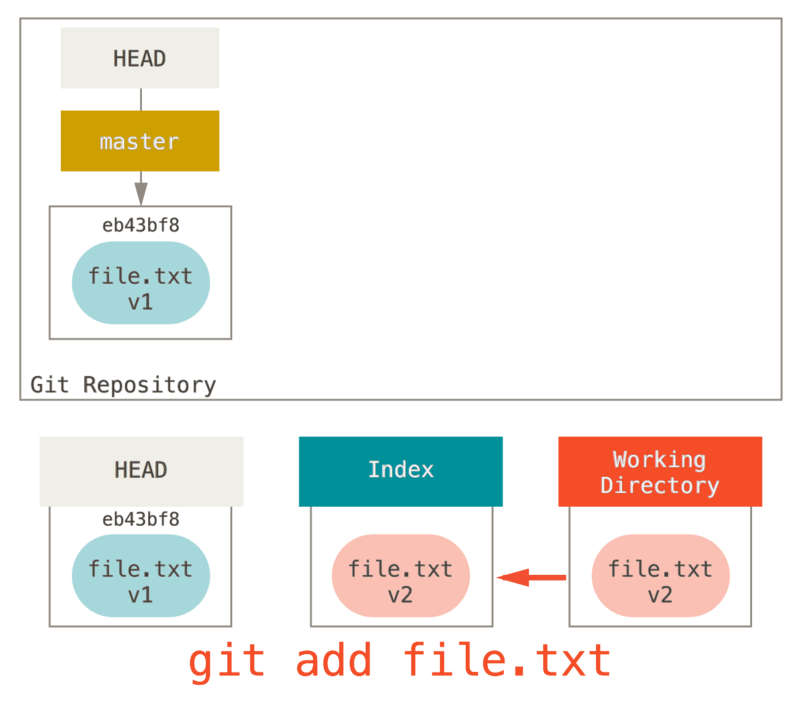
可以不让 Git 从 HEAD 拉取数据,而是通过具体指定一个提交来拉取该文件的对应版本。 我们只需运行类似于 git reset eb43bf file.txt 的命令即可。

它其实做了同样的事情,也就是把工作目录中的文件恢复到 v1 版本
6.5. reset与checkout之间的区别
和 reset 一样,checkout 也操纵三棵树,不过它有一点不同,这取决于你是否传给该命令一个文件路径。
运行 git checkout [branch] 与运行 git reset --hard [branch] 非常相似,它会更新所有三棵树使其看起来像 [branch],不过有两点重要的区别。
首先不同于 reset --hard,checkout 对工作目录是安全的,它会通过检查来确保不会将已更改的文件弄丢。 其实它还更聪明一些。它会在工作目录中先试着简单合并一下,这样所有 还未修改过的 文件都会被更新。 而 reset --hard 则会不做检查就全面地替换所有东西。
第二个重要的区别是 checkout 如何更新 HEAD。 reset 会移动 HEAD 分支的指向,而 checkout 只会移动 HEAD 自身来指向另一个分支。

运行 checkout 的另一种方式就是指定一个文件路径,这会像 reset 一样不会移动 HEAD。 它就像 git reset [branch] file 那样用该次提交中的那个文件来更新索引,但是它也会覆盖工作目录中对应的文件。 它就像是 git reset --hard [branch] file(如果 reset 允许你这样运行的话), 这样对工作目录并不安全,它也不会移动 HEAD。
git checkout [branch] file 用指定的某次提交中的那个文件来更新索引中的这个文件,因为分支是一个指针,指向的是某一次提交,因此当我们说检出分支的时候其实说的是将那个分支所指向的提交更新到暂存区和工作区中,所以说从某次提交中更新某个文件到当前工作目录没毛病。
https://git-scm.com/docs/git-reset
https://git-scm.com/docs/git-checkout
7. git merge
git merge 工具用来合并一个或者多个分支到你已经检出的分支中。 然后它将当前分支指针移动到合并结果上。
一般用法是 git merge <branch> 带上一个你想合并进来的一个分支名称。
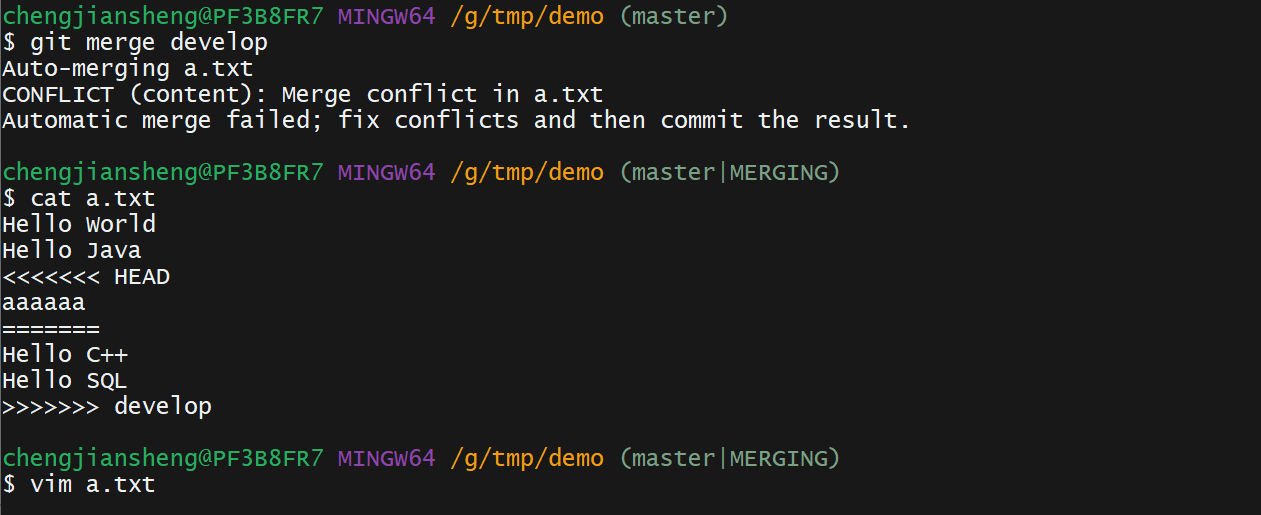
7.1. 合并冲突
首先,在做一次可能有冲突的合并前尽可能保证工作目录是干净的。 如果你有正在做的工作,要么提交到一个临时分支要么储藏它。
可以使用 git merge --abort 来中断次合并
--abort 选项会尝试恢复到你运行合并前的状态。但当运行命令前,在工作目录中有未暂存、未提交的修改时它不能完美处理,除此之外它都工作地很好。
使用 -Xignore-all-space 或 -Xignore-space-change 选项可以忽略空白。第一个选项在比较行时 完全忽略 空白修改,第二个选项将一个空白符与多个连续的空白字符视作等价的。
7.2. 撤销合并
假设现在在一个主题分支上工作,不小心将其合并到 master 中,现在提交历史看起来是这样:
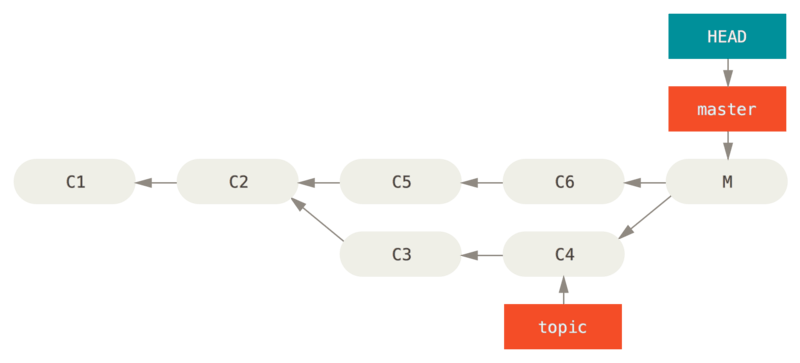
对于这种意外的合并提交,有两种方法来解决这个问题,这取决于你想要的结果是什么。
如果这个不想要的合并提交只存在于你的本地仓库中,最简单且最好的解决方案是移动分支到你想要它指向的地方。 大多数情况下,如果你在错误的 git merge 后运行 git reset --hard HEAD~,这会重置分支指向所以它们看起来像这样:
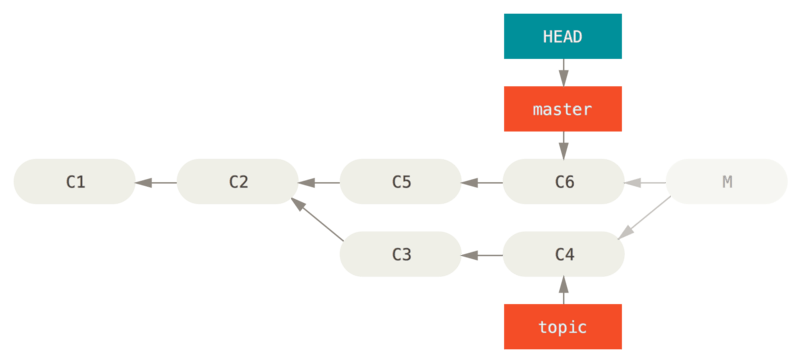
回顾一下 git reset --hard
- 移动 HEAD 指向的分支
- 使索引看起来像 HEAD
- 使工作目录看起来像索引
这个方法的缺点是它会重写历史,在一个共享的仓库中可能会造成一些问题。比如,假设有人在在合并之后又创建了新的提交,那么移动指针实际上会丢失那些改动。
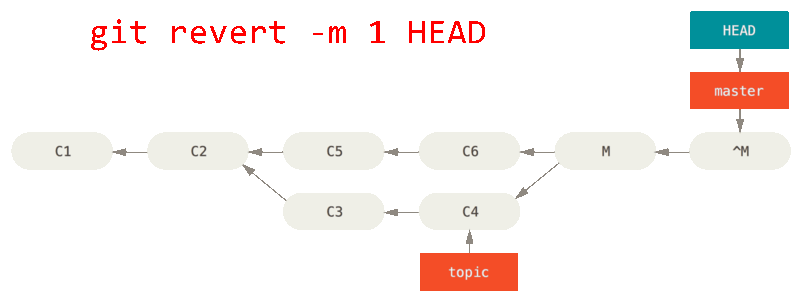
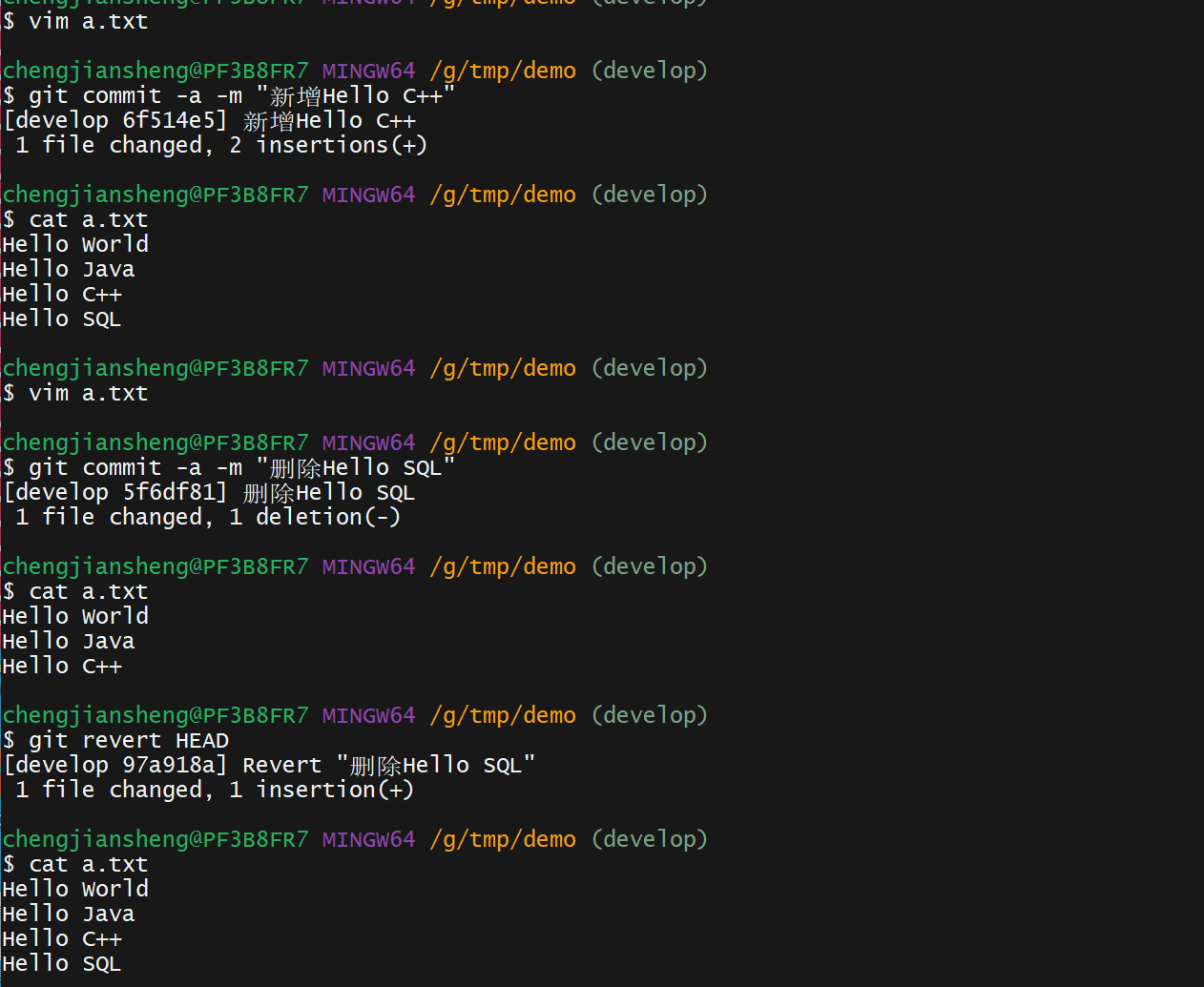
如果移动分支指针并不适合你,Git 给你一个生成一个新提交的选项,提交将会撤消一个已存在提交的所有修改。 Git 称这个操作为“还原”,在这个特定的场景下,你可以像这样调用它:
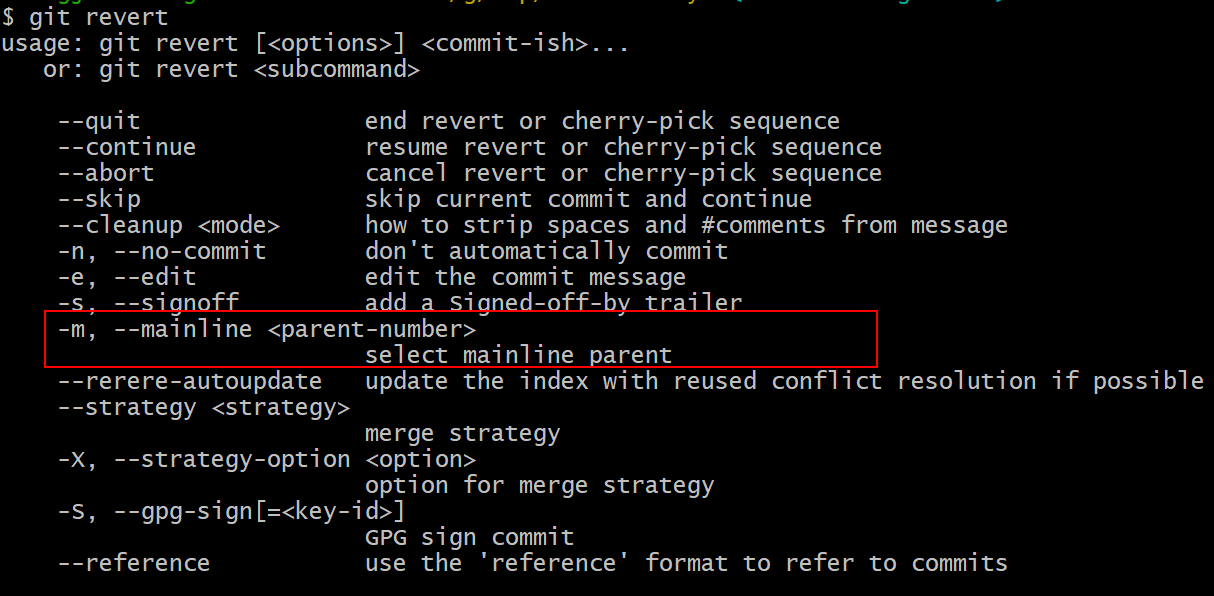
git revert -m 1 HEAD-m 1 标记指出 “mainline” 需要被保留下来的父结点。 当你引入一个合并到 HEAD(git merge topic),新提交有两个父结点:第一个是 HEAD(C6),第二个是将要合并入分支的最新提交(C4)。 在本例中,我们想要撤消所有由父结点 #2(C4)合并引入的修改,同时保留从父结点 #1(C6)开始的所有内容。
有还原提交的历史看起来像这样:
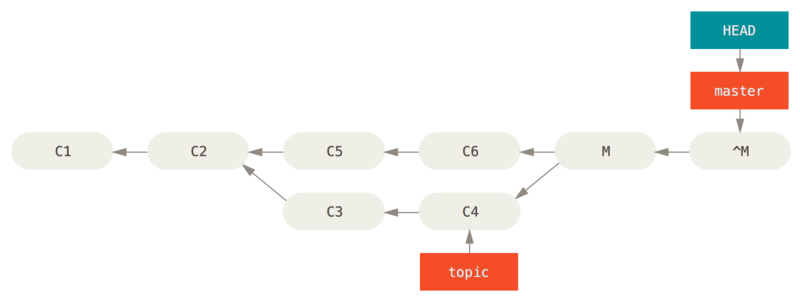
在 git revert -m 1 后,新的提交 ^M 与 C6 有完全一样的内容,所以从这儿开始就像合并从未发生过。
如果你在 topic 中增加工作然后再次合并,Git 只会引入被还原的合并 之后 的修改。
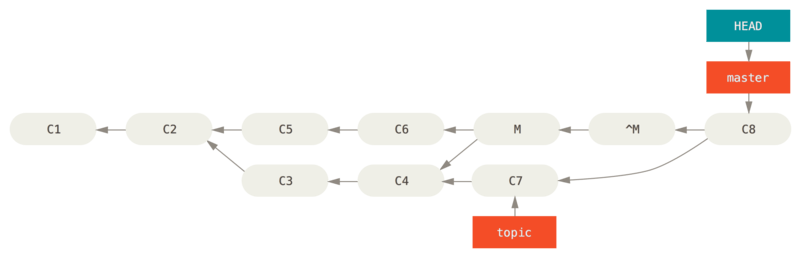
解决这个最好的方式是撤消还原原始的合并,因为现在你想要引入被还原出去的修改,然后 创建一个新的合并提交:
git revert ^M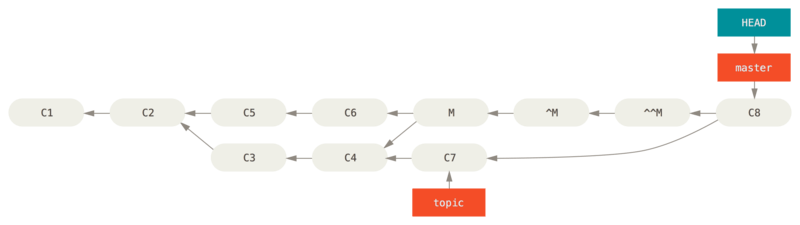
在本例中,M 与 ^M 抵消了。 ^^M 事实上合并入了 C3 与 C4 的修改,C8 合并了 C7 的修改,所以现在 topic 已经完全被合并了。
8. 远程仓库
# 查看你已经配置的远程仓库服务器
git remote
# 显示需要读写远程仓库使用的 Git 保存的简写与其对应的 URL
git remote -v
# 查看某一个远程仓库的更多信息
git remote show <remote>
# 添加一个新的远程 Git 仓库,同时指定一个方便使用的简写
git remote add <shortname> <url>
# 修改一个远程仓库的简写名
git remote rename
# 从远程仓库中获得数据
git fetch <remote>
# 推送到远程仓库
git push <remote> <branch>如果使用 clone 命令克隆了一个仓库,命令会自动将其添加为远程仓库并默认以 “origin” 为简写。所以,git fetch origin 会抓取克隆(或上一次抓取)后新推送的所有工作。
必须注意 git fetch 命令只会将数据下载到你的本地仓库——它并不会自动合并或修改你当前的工作。可以用 git pull 命令来自动抓取后合并该远程分支到当前分支。
git pull 命令基本上就是 git fetch 和 git merge 命令的组合体,Git 从你指定的远程仓库中抓取内容,然后马上尝试将其合并进你所在的分支中。
git push 命令用来与另一个仓库通信,计算你本地数据库与远程仓库的差异,然后将差异推送到另一个仓库中。它需要有另一个仓库的写权限,因此这通常是需要验证的。
9. 补丁
每一次提交都是一个补丁
9.1. git cherry-pick
git cherry-pick 命令用来获得在单个提交中引入的变更,然后尝试将作为一个新的提交引入到你当前分支上。从一个分支单独一个或者两个提交而不是合并整个分支的所有变更是非常有用的。
Git 中的拣选类似于对特定的某次提交的变基。 它会提取该提交的补丁,之后尝试将其重新应用到当前分支上。这种方式在你只想引入主题分支中的某个提交时很有用。
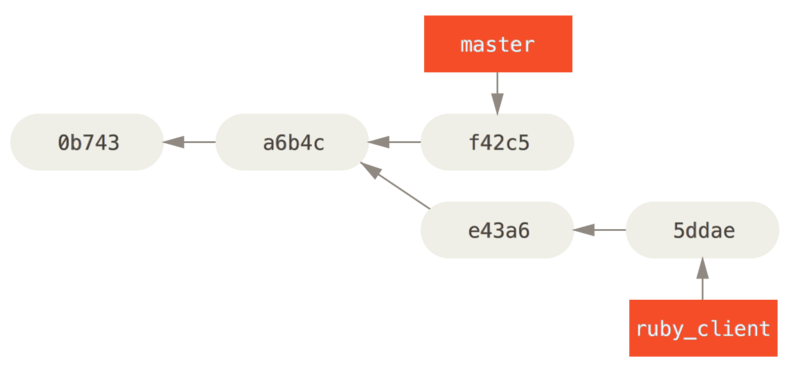
如上图所示,假设现在的提交时这样(拣选之前)
如果你希望将提交 e43a6 拉取到 master 分支,你可以运行:
git cherry-pick e43a6这样会拉取和 e43a6 相同的更改,但是因为应用的日期不同,你会得到一个新的提交 SHA-1 值。 现在你的历史会变成这样:

9.2. git rebase
git rebase 命令基本是一个自动化的 cherry-pick 命令。它计算出一系列的提交,然后再以同样的顺序一个一个的 cherry-picks 出它们。
在 Git 中整合来自不同分支的修改主要有两种方法:merge 以及 rebase
假设现在的提交历史是这样的:
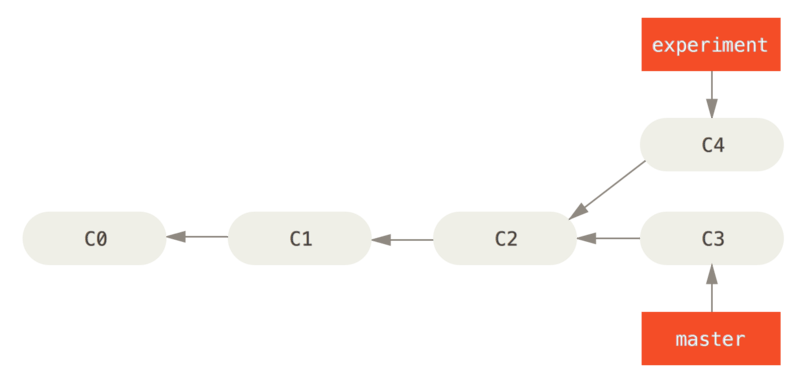
之前介绍过,整合分支最容易的方法是 merge 命令。 它会把两个分支的最新快照(C3 和 C4)以及二者最近的共同祖先(C2)进行三方合并,合并的结果是生成一个新的快照(并提交)。
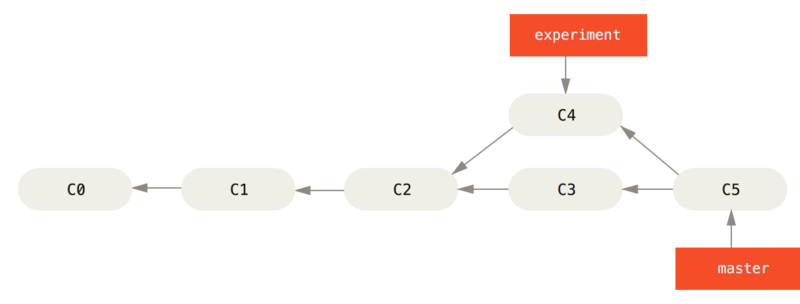
其实,还有一种方法:可以提取在 C4 中引入的补丁和修改,然后在 C3 的基础上应用一次。 在 Git 中,这种操作就叫做 变基(rebase)。可以使用 rebase 命令将提交到某一分支上的所有修改都移至另一分支上,就好像“重新播放”一样。
在这个例子中,你可以检出 experiment 分支,然后将它变基到 master 分支上:
git checkout experiment
git rebase master这样就将 C4 中的修改变基到 C3 上了
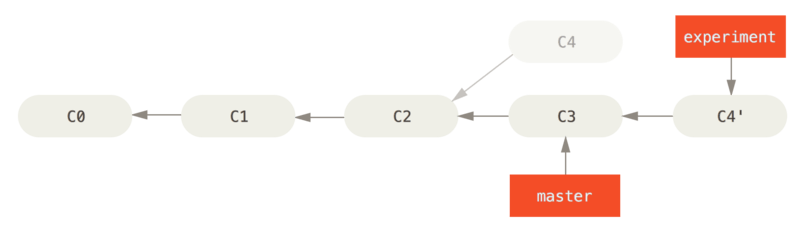
现在回到 master 分支,进行一次快进合并。
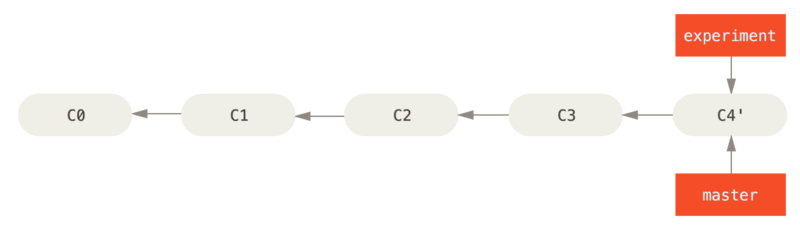
此时,C4' 指向的快照就和前面使用merge合并后的那个 C5 指向的快照一模一样了。
这两种整合方法的最终结果没有任何区别,但是变基使得提交历史更加整洁。 你在查看一个经过变基的分支的历史记录时会发现,尽管实际的开发工作是并行的, 但它们看上去就像是串行的一样,提交历史是一条直线没有分叉。
金科玉律:“如果提交存在于你的仓库之外,而别人可能基于这些提交进行开发,那么不要执行变基。”
9.3. git revert
git revert 命令本质上就是一个逆向的 git cherry-pick 操作。它将你提交中的变更的以完全相反的方式应用到一个新创建的提交中,本质上就是撤销或者还原。
git revert 相当于撤销/还原了上一次提交,就好像从当前这个提交中摘除上一次提交的内容,然后生成了一个新的提交
再举个例子
假设现在的提交历史是 C1 <--- C2 <--- C3,HEAD指向C3,此时执行 git revert -m 1 的话就生成一个新的提交 C4,C4的内容和C2是一样的
reset是通过移动分支的指向来达到撤销的目的,revert是通过挑出提交的内容重新生成一次新的提交来达到撤销的目的
10. 选择修订版本
可以通过任意一个提交的 40 个字符的完整 SHA-1 散列值来指定它,不过还有很多更人性化的方式来做同样的事情。
Git 十分智能,你只需要提供 SHA-1 的前几个字符就可以获得对应的那次提交, 当然你提供的 SHA-1 字符数量不得少于 4 个,并且没有歧义——也就是说, 当前对象数据库中没有其它对象以这段 SHA-1 开头。
Git 可以为 SHA-1 值生成出简短且唯一的缩写。如果在 git log 后加上 --abbrev-commit 参数,输出结果里就会显示简短且唯一的值。
git log --abbrev-commit --pretty=oneline当你在工作时, Git 会在后台保存一个引用日志(reflog),引用日志记录了最近几个月你的 HEAD 和分支引用所指向的历史。
可以使用 git reflog 来查看引用日志
每当你的 HEAD 所指向的位置发生了变化,Git 就会将这个信息存储到引用日志这个历史记录里。 你也可以通过 reflog 数据来获取之前的提交历史。 如果你想查看仓库中 HEAD 在五次前的所指向的提交,你可以使用 @{n} 来引用 reflog 中输出的提交记录。
git show HEAD@{5}注意:引用日志只存在于本地仓库,它只是一个记录你在 自己 的仓库里做过什么的日志。
祖先引用是另一种指明一个提交的方式。 如果你在引用的尾部加上一个 ^ , Git 会将其解析为该引用的上一个提交。
可以使用 HEAD^ 来查看上一个提交,也就是 “HEAD 的父提交”
可以在 ^ 后面添加一个数字来指明想要 哪一个 父提交。例如 d921970^2 代表 “d921970 的第二父提交” 这个语法只适用于合并的提交,因为合并提交会有多个父提交。 合并提交的第一父提交是你合并时所在分支(通常为 master),而第二父提交是你所合并的分支(例如 topic)
git show d921970^
git show d921970^2另一种指明祖先提交的方法是 ~(波浪号)。同样是指向第一父提交,因此 HEAD~ 和 HEAD^ 是等价的。而区别在于后面加数字的时候,HEAD~2 代表“第一父提交的第一父提交”,也就是“祖父提交”,HEAD^2 代表“HEAD的第二父提交”。
HEAD~3 也可以写成 HEAD~~~,表示“第一父提交的第一父提交的第一父提交”
可以组合使用这两个语法,例如,可以通过 HEAD~3^2 来取得之前引用的第二父提交(假设它是一个合并提交)
补充:
1、在 HEAD 后面加 ^ 或者 ~ 其实就是以 HEAD 为基准,来表示之前的版本,因为 HEAD 代表当前分支的最新版本,那么 HEAD~ 和 HEAD^ 都是指次新版本,也就是倒数第二个版本,HEAD~~ 和 HEAD^^ 都是指次次新版本,也就是倒数第三个版本,以此类推。
2、HEAD~ 和 HEAD^ 的作用是相同的,它们本来的面貌是 HEAD~1 和 HEAD^1
3、如果后面跟的数字大于1的话就有区别了,比如:HEAD~2 代表后退两步,每一步都后退到第一个父提交上,而 HEAD^2 代表后退一步,这一步退到第二个父提交上,如果没有第二个父提交就会报错.
最常用的指明提交区间语法是双点。 这种语法可以让 Git 选出在一个分支中而不在另一个分支中的提交。
例如,现在的提交历史是这样的:

如果想要查看 experiment 分支中还有哪些提交尚未被合并入 master 分支。我们可以使用 master..experiment 来让 Git 显示这些提交。也就是“在 experiment 分支中而不在 master 分支中的提交”。
git log master..experiment反过来,如果想查看在 master 分支中而不在 experiment 分支中的提交,你只要交换分支名即可。experiment..master 会显示在 master 分支中而不在 experiment 分支中的提交。
双点语法很好用,但有时候你可能需要两个以上的分支才能确定你所需要的修订, 比如查看哪些提交是被包含在某些分支中的一个,但是不在你当前的分支上。 Git 允许你在任意引用前加上 ^ 字符或者 --not 来指明你不希望提交被包含其中的分支。 因此下列三个命令是等价的:
git log refA..refB
git log ^refA refB
git log refB --not refA比如,你想查看所有被 refA 或 refB 包含的但是不被 refC 包含的提交,你可以使用以下任意一个命令:
git log refA refB ^refC
git log refA refB --not refC11. 查看提交历史
不传入任何参数的默认情况下,git log 会按时间先后顺序列出所有的提交,最近的更新排在最上面。
# 显示最近的两次提交所引入的差异
git log -p -2
# 显示简短且唯一的值
git log --abbrev-commit
git log --pretty=oneline
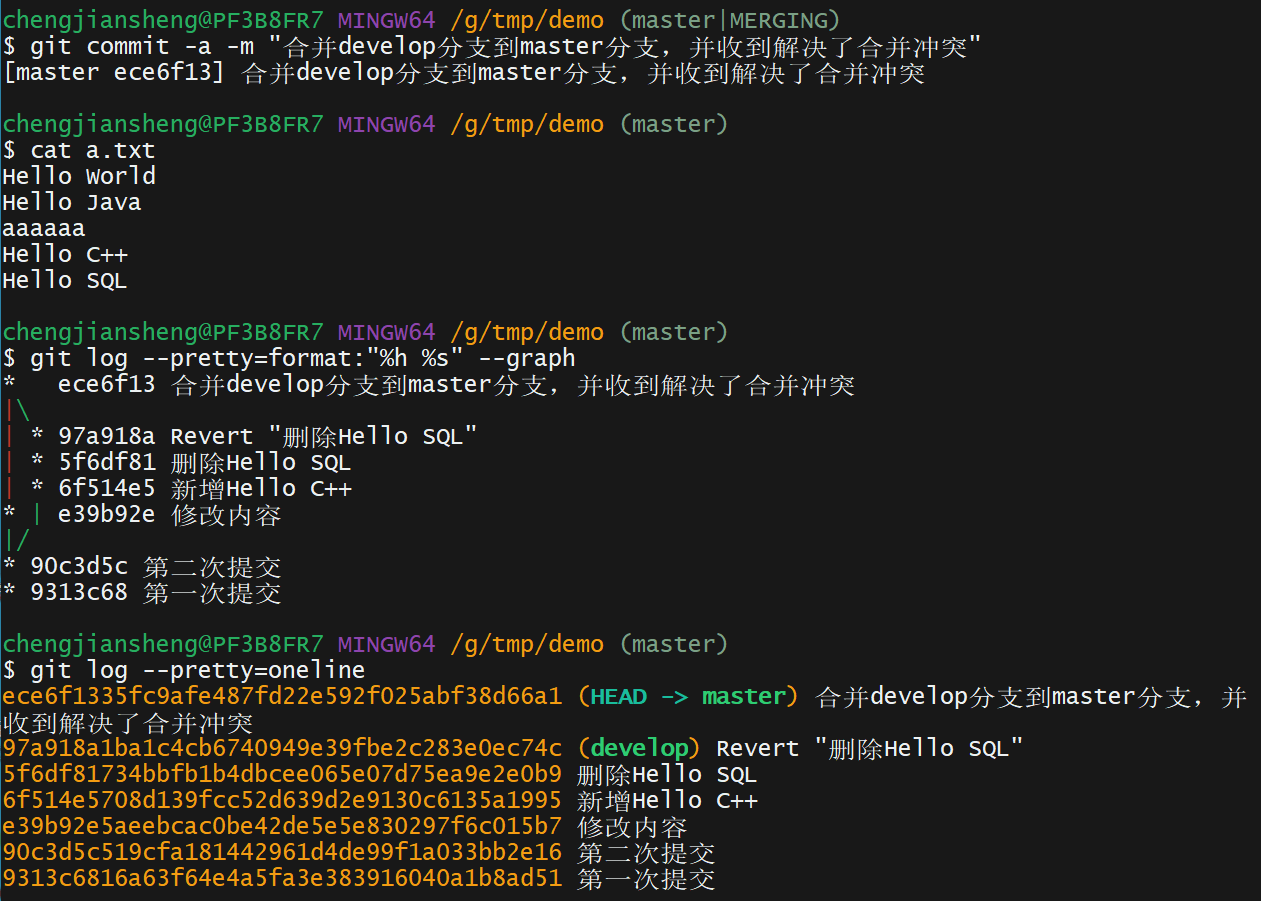
git log --pretty=format:"%h %s" --graph12. 演示
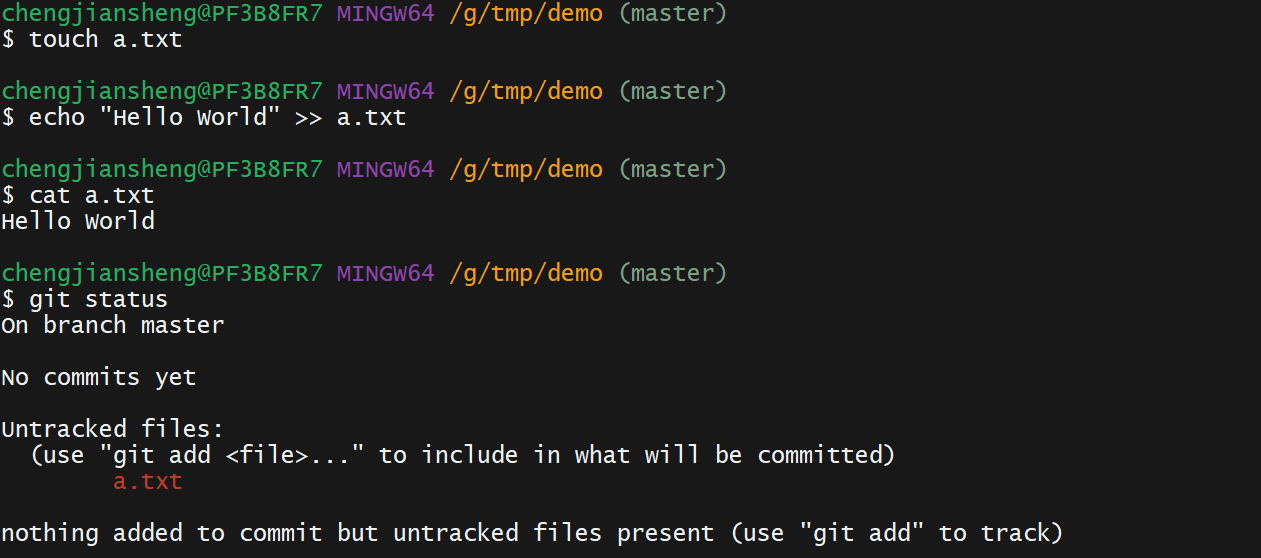
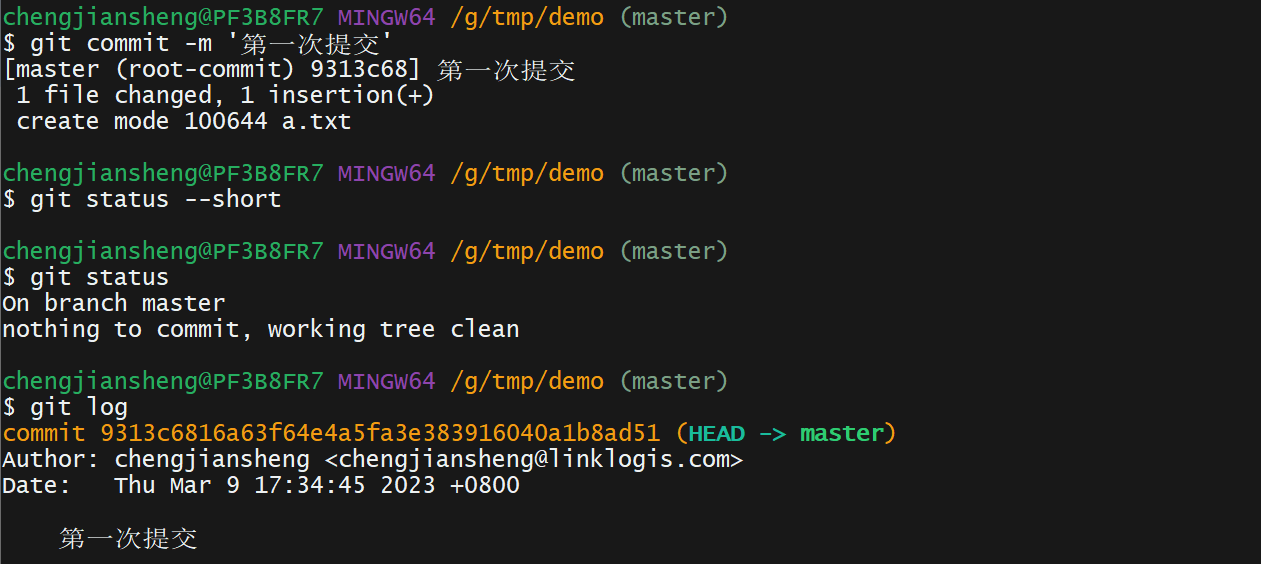
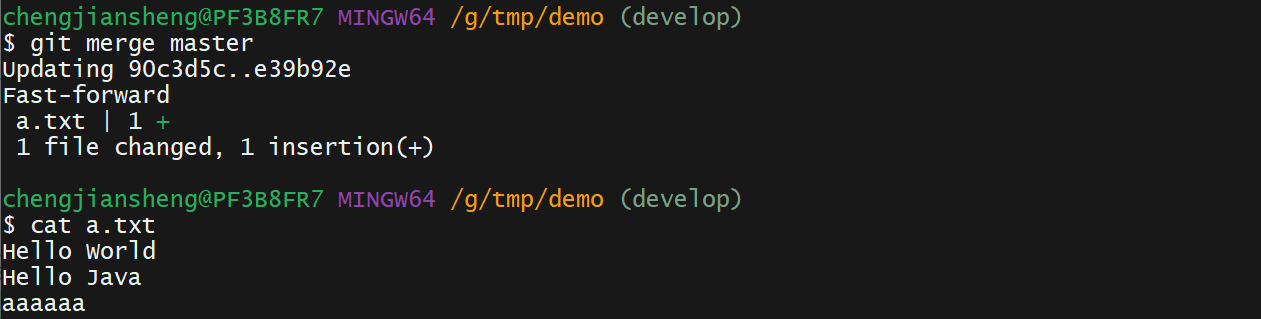

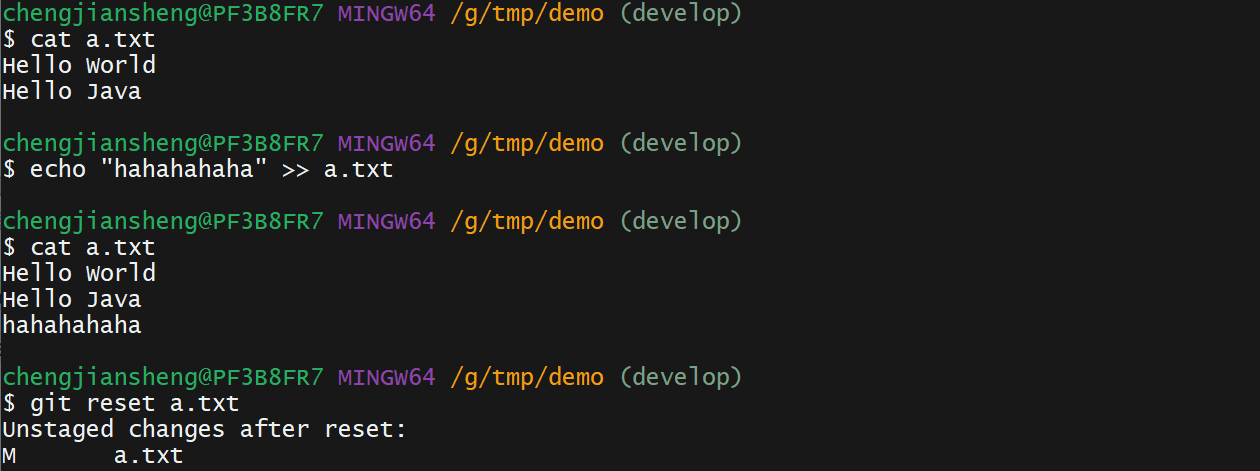
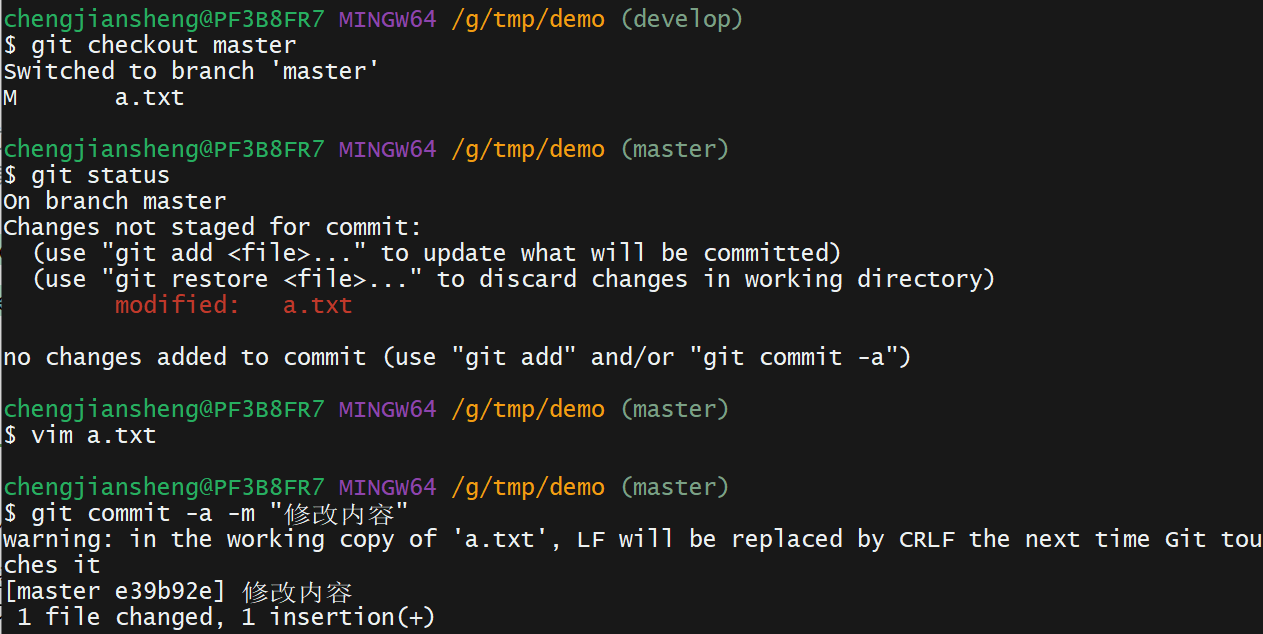
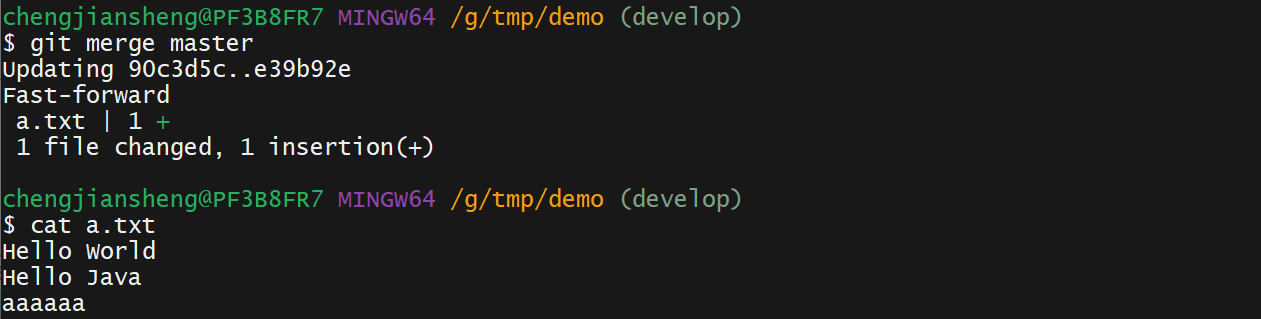



我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
关于如何使用git设置类似Dropbox的服务,您有什么建议吗?您认为git是解决此问题的合适工具吗?我在考虑使用git+rush解决方案,你觉得怎么样? 最佳答案 检查这个开源项目:https://github.com/hbons/SparkleShare来自项目的自述文件:Howdoesitwork?SparkleSharecreatesaspecialfolderonyourcomputer.Youcanaddremotelyhostedfolders(or"projects")tothisfolder.Theseprojec
我编写了一个非常简单的“部署”脚本,作为我的裸git存储库中的post-updateHook运行。变量如下livedomain=~/mydomain.comstagingdomain=~/stage.mydomain.comgitrepolocation=~/git.mydomain.com/thisrepo.git(bare)core=~/git.mydomain.com/thisrepo.gitcore==addedremoteintoeachlive&stagegitslive和stage都初始化了gitrepos(非裸),我已经将我的裸仓库作为远程添加到它们中的每一个(名为co
我正在安装gitlabhq,并且在Gemfile中有对某些资源的“git://...”的引用。但是,我在公司防火墙后面,所以我必须使用http://。我可以手动编辑Gemfile,但我想知道是否有另一种方法告诉bundler使用http://作为git存储库? 最佳答案 您可以通过运行gitconfig--globalurl."https://".insteadOfgit://或通过将以下内容添加到~/.gitconfig:[url"https://"]insteadOf=git://
之前有人问过这个问题,我发现了以下clip关于如何一次设置一个类对象的所有属性,但由于批量分配保护,这在Rails中是不可能的。(例如,您不能Object.attributes={})有没有一种很好的方法可以将一个类的属性合并到另一个类中?object1.attributes=object2.attributes.inject({}){|h,(k,v)|h[k]=vifObjectModel.column_names.include?(k);h}谢谢。 最佳答案 利用assign_attributes使用:without_prote
Activeadmingem已添加到我的rails项目中,但每次我尝试安装railsgactive_admin:install时,我都会收到类似的错误git://github.com/activeadmin/activeadmin.git(atmaster)isnotyetcheckedout.Runbundleinstallfirst.我肯定在运行“railsgactive_admin:install”之前运行了bundle。运行“bundleshow”后,我看到我已将“*activeadmin(1.0.0.pre3f916d6)”添加到我的项目中,但不断收到此错误消息。我的gem文
我一直在尝试使用nanoc用于生成静态网站。我需要组织一个复杂的排列页面,我想让我的内容保持干燥。包含或合并的概念在nanoc系统中如何运作?我已阅读文档,但似乎找不到我想要的内容。例如:我如何获取两个部分内容项并将它们合并到一个新的内容项中。在staticmatic您可以在您的页面中执行以下操作。=partial('partials/shared/navigation')类似的约定在nanoc中如何运作? 最佳答案 这里是nanoc的作者。在nanoc中,部分是布局。因此,您可以拥有layouts/partials/shared/
我有一个使用Jekyll托管在GitHub上的静态网站。问题是,我真的不需要master分支,因为存储库唯一包含的是网站。这样我就必须gitcheckoutgh-pages,然后gitmergemaster,然后gitpushorigingh-pages。有什么简单的方法可以摆脱gh-pages分支并直接从master推送? 最佳答案 Theproblemis,Idon'treallyneedthemasterbranch,astheonlythingtherepositorycontainsisthewebsite.Isthere