(8) SELECT(9) DISTINCT column,…
选择字段 、去重
(6) AGG_FUNC(column or expression),…
聚合函数
(1) FROM [left_table]
选择表
(3) <join_type> JOIN <right_table>
链接
(2) ON <join_condition>
链接条件
(4) WHERE <where_condition>
条件过滤
(5) GROUP BY <group_by_list>
分组
(7) HAVING <having_condition>
分组过滤
(10) ORDER BY <order_by_list>
排序
(11) LIMIT count OFFSET count;
分页
反例:
SELECT * FROM student
正例:
SELECT id,NAME FROM student
理由:
查询id为1或者薪水为3000的用户:
反例:
SELECT * FROM student WHERE id=1 OR salary=30000
正例:
使用union all
SELECT * FROM student WHERE id=1
UNION ALL
SELECT * FROM student WHERE salary=30000
分开两条sql写
SELECT * FROM student WHERE id=1
SELECT * FROM student WHERE salary=30000
理由:
反例:
`deptname` char(100) DEFAULT NULL COMMENT '部门名称'
正例:
`deptname` varchar(100) DEFAULT NULL COMMENT '部门名称'
理由:
如果查询返回数据量很大,就会造成查询时间过长,网络传输时间过长。同时,大量数据返回也可能没有实际意义。如返回上千条甚至更多,用户也看不过来。
通常采用分页,一页习惯10/20/50/100条。
SQL很灵活,一个需求可以很多实现,那哪个最优呢?SQL提供了explain关键字,它可以分析你的SQL执行计划,看它是否最佳。Explain主要看SQL是否使用了索引。
EXPLAIN
SELECT * FROM student WHERE id=1
返回结果:

type:
性能排行:
System > const > eq_ref > ref > range > index > ALL
possible_keys:
key:
提高查询速度的最简单最佳的方式
ALTER TABLE student ADD INDEX index_name (NAME)
模糊查询,程序员最喜欢的就是使用like,但是like很可能让你的索引失效
反例:
EXPLAIN
SELECT id,NAME FROM student WHERE NAME LIKE '%1'
EXPLAIN
SELECT id,NAME FROM student WHERE NAME LIKE '%1%'
正例:
EXPLAIN
SELECT id,NAME FROM student WHERE NAME LIKE '1%'
理由:
未使用索引:故意使用sex非索引字段
EXPLAIN
SELECT id,NAME FROM student WHERE NAME=1 OR sex=1

主键索引生效
EXPLAIN
SELECT id,NAME FROM student WHERE id=1

索引失效,type=ALL,全表扫描
EXPLAIN
SELECT id,NAME FROM student WHERE id LIKE '%1'

反例:
#未使用索引
EXPLAIN
SELECT * FROM student WHERE NAME=123
正例:
#使用索引
EXPLAIN
SELECT * FROM student WHERE NAME='123'
理由:
如性别字段。因为SQL优化器是根据表中数据量来进行查询优化的,如果索引
列有大量重复数据,Mysql查询优化器推算发现不走索引的成本更低,很可能就放弃索引了。
数据中假定就一个男的记录
反例:
SELECT id,NAME FROM student WHERE sex='男'
正例:
SELECT id,NAME FROM student WHERE id=1 AND sex='男'
理由:
业务需求:查询最近七天内新生儿(用学生表替代下)
给birthday字段创建索引:
ALTER TABLE student ADD INDEX idx_birthday (birthday)
当前时间加7天:
SELECT NOW()
SELECT DATE_ADD(NOW(), INTERVAL 7 DAY)
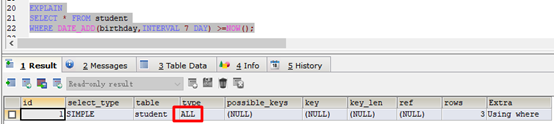
反例:
EXPLAIN
SELECT * FROM student
WHERE DATE_ADD(birthday,INTERVAL 7 DAY) >=NOW();
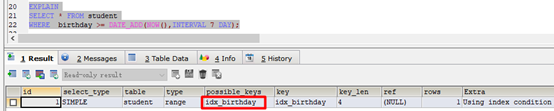
正例:
EXPLAIN
SELECT * FROM student
WHERE birthday >= DATE_ADD(NOW(),INTERVAL 7 DAY);
理由:
使用索引列上内置函数
索引失效:
索引有效:
反例:
EXPLAIN
SELECT * FROM student WHERE id+1-1=+1
正例:
EXPLAIN
SELECT * FROM student WHERE id=+1-1+1
EXPLAIN
SELECT * FROM student WHERE id=1
理由:
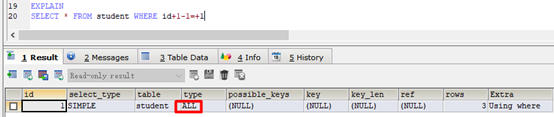

应尽量避免在where子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。记住实现业务优先,实在没办法,就只能使用,并不是不能使用。如果不能使用,SQL也就无需支持了。
反例:
EXPLAIN
SELECT * FROM student WHERE salary!=3000
EXPLAIN
SELECT * FROM student WHERE salary<>3000
理由:

#索引失效
EXPLAIN
SELECT DISTINCT * FROM student
#索引生效
EXPLAIN
SELECT DISTINCT id,NAME FROM student
EXPLAIN
SELECT DISTINCT NAME FROM student
理由:
环境准备:
#修改表,增加age字段,类型int,非空,默认值0
ALTER TABLE student ADD age INT NOT NULL DEFAULT 0;
#修改表,增加age字段的索引,名称为idx_age
ALTER TABLE student ADD INDEX idx_age (age);
反例:
EXPLAIN
SELECT * FROM student WHERE age IS NOT NULL
正例:
EXPLAIN
SELECT * FROM student WHERE age>0
理由:
大量数据提交,上千,上万,批量性能非常快,mysql独有
多条提交:
INSERT INTO student (id,NAME) VALUES(4,'name1');
INSERT INTO student (id,NAME) VALUES(5,'name2');
批量提交:
INSERT INTO student (id,NAME) VALUES(4,'name1'),(5,'name2');
理由:
避免同时修改或删除过多数据,因为会造成cpu利用率过高,会造成锁表操作,从而影响别人对数据库的访问。
反例:
#一次删除10万或者100万+?
delete from student where id <100000;
#采用单一循环操作,效率低,时间漫长
for(User user:list){
delete from student;
}
正例:
#分批进行删除,如每次500
for(){
delete student where id<500;
}
delete student where id>=500 and id<1000;
理由:
商品状态(state):1-上架、2-下架、3-删除
理由:
可以在执行到该语句前,把不需要的记录过滤掉
反例:先分组,再过滤
select job,avg(salary) from employee
group by job
having job ='president' or job = 'managent';
正例:先过滤,后分组
select job,avg(salary) from employee
where job ='president' or job = 'managent'
group by job;
创建复合索引,也就是多个字段
ALTER TABLE student ADD INDEX idx_name_salary (NAME,salary)
满足复合索引的左侧顺序,哪怕只是部分,复合索引生效
EXPLAIN
SELECT * FROM student WHERE NAME='name1'
没有出现左边的字段,则不满足最左特性,索引失效
EXPLAIN
SELECT * FROM student WHERE salary=3000
复合索引全使用,按左侧顺序出现 name,salary,索引生效
EXPLAIN
SELECT * FROM student WHERE NAME='陈子枢' AND salary=3000
虽然违背了最左特性,但MYSQL执行SQL时会进行优化,底层进行颠倒优化
EXPLAIN
SELECT * FROM student WHERE salary=3000 AND NAME='name1'
理由:
什么样的字段才需要创建索引呢?原则就是where和order by中常出现的字段就创建索引。
#使用*,包含了未索引的字段,导致索引失效
EXPLAIN
SELECT * FROM student ORDER BY NAME;
EXPLAIN
SELECT * FROM student ORDER BY NAME,salary
#name字段有索引
EXPLAIN
SELECT id,NAME FROM student ORDER BY NAME
#name和salary复合索引
EXPLAIN
SELECT id,NAME FROM student ORDER BY NAME,salary
EXPLAIN
SELECT id,NAME FROM student ORDER BY salary,NAME
#排序字段未创建索引,性能就慢
EXPLAIN
SELECT id,NAME FROM student ORDER BY sex
SHOW INDEX FROM student
#创建索引index_name
ALTER TABLE student ADD INDEX index_name (NAME)
#删除student表的index_name索引
DROP INDEX index_name ON student ;
#修改表结果,删除student表的index_name索引
ALTER TABLE student DROP INDEX index_name ;
#主键会自动创建索引,删除主键索引
ALTER TABLE student DROP PRIMARY KEY ;

三种连接如果结果相同,优先使用inner join,如果使用left join左边表尽量小
理由:
日常开发实现业务需求可以有两种方式实现:
#in子查询
SELECT * FROM tb_user WHERE dept_id IN (SELECT id FROM tb_dept);
#这样写等价于:
#先查询部门表
SELECT id FROM tb_dept
#再由部门dept_id,查询tb_user的员工
SELECT * FROM tb_user u,tb_dept d WHERE u.dept_id = d.id
假设表A表示某企业的员工表,表B表示部门表,查询所有部门的所有员工,很容易有以下程序实现,可以抽象成这样的一个嵌套循环:
List<> resultSet;
for(int i=0;i<B.length;i++) {
for(int j=0;j<A.length;j++) {
if(A[i].id==B[j].id) {
resultSet.add(A[i]);
break;
}
}
}
上面的需求使用SQL就远不如程序实现,特别当数据量巨大时。
理由:
反例:
SELECT * FROM student
UNION
SELECT * FROM student
正例:
SELECT * FROM student
UNION ALL
SELECT * FROM student
理由:
导读语言模型给我们的生产生活带来了极大便利,但同时不少人也利用他们从事作弊工作。如何规避这些难辨真伪的文字所产生的负面影响也成为一大难题。在3月9日智源Live第33期活动「DetectGPT:判断文本是否为机器生成的工具」中,主讲人Eric为我们讲解了DetectGPT工作背后的思路——一种基于概率曲率检测的用于检测模型生成文本的工具,它可以帮助我们更好地分辨文章的来源和可信度,对保护信息真实、防止欺诈等方面具有重要意义。本次报告主要围绕其功能,实现和效果等展开。(文末点击“阅读原文”,查看活动回放。)Ericmitchell斯坦福大学计算机系四年级博士生,由ChelseaFinn和Chri
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
SPI接收数据左移一位问题目录SPI接收数据左移一位问题一、问题描述二、问题分析三、探究原理四、经验总结最近在工作在学习调试SPI的过程中遇到一个问题——接收数据整体向左移了一位(1bit)。SPI数据收发是数据交换,因此接收数据时从第二个字节开始才是有效数据,也就是数据整体向右移一个字节(1byte)。请教前辈之后也没有得到解决,通过在网上查阅前人经验终于解决问题,所以写一个避坑经验总结。实际背景:MCU与一款芯片使用spi通信,MCU作为主机,芯片作为从机。这款芯片采用的是它规定的六线SPI,多了两根线:RDY和INT,这样从机就可以主动请求主机给主机发送数据了。一、问题描述根据从机芯片手
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我找到了这样的东西:Rails:Howtolistdatabasetables/objectsusingtheRailsconsole?这一行没问题:ActiveRecord::Base.connection.tables并返回所有表但是ActiveRecord::Base.connection.table_structure("users")产生错误:ActiveRecord::Base.connection.table_structure("projects")我认为table_structure不是Postgres方法。如何列出Postgres数据库的Rails控制台中表中的所有
Ruby中防止SQL注入(inject)的好方法是什么? 最佳答案 直接使用ruby?使用准备好的语句:require'mysql'db=Mysql.new('localhost','user','password','database')statement=db.prepare"SELECT*FROMtableWHEREfield=?"statement.execute'value'statement.fetchstatement.close 关于ruby-防止SQL注入(inject
我正在编写一个Rails应用程序,它将监视某些特定数据库的数据质量。为了做到这一点,我需要能够对这些数据库执行直接SQL查询——这当然与用于驱动Rails应用程序模型的数据库不同。简而言之,这意味着我无法使用通过ActiveRecord基础连接的技巧。我需要连接的数据库在设计时是未知的(即:我不能将它们的详细信息放在database.yaml中)。相反,我有一个模型“database_details”,用户将使用它来输入应用程序将在运行时执行查询的数据库的详细信息。因此与这些数据库的连接实际上是动态的,细节仅在运行时解析。 最佳答案
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva