文章目录
今天在测试环境新增数据时,报出如是错误:Data too long for column 'apply_service_type' at row 1 。
为了复现这个问题,我特地在本地数据库中增加如下test表:
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`apply_service_type` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 1 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
在test表中新增如下数据:
mysql> INSERT test(apply_service_type) VALUES('[{"code":"apply_service_type_encrypt","value":"加密服务类"},{"code":"apply_service_type_qrcode","value":"二维码支撑类"},{"code":"apply_service_type_decode","value":"解密服务类"}]');
报出上述错误:
ERROR 1406 (22001): Data too long for column 'apply_service_type' at row 1
为什么会报出这个错误呢?接下来便分析错误原因。
从test表中可以看到apply_service_type是字符串类型,长度为255。
但是,存储的数据是[{"code":"apply_service_type_encrypt","value":"加密服务类"},{"code":"apply_service_type_qrcode","value":"二维码支撑类"},{"code":"apply_service_type_decode","value":"解密服务类"}]。该数据长度为298,如下图所示:
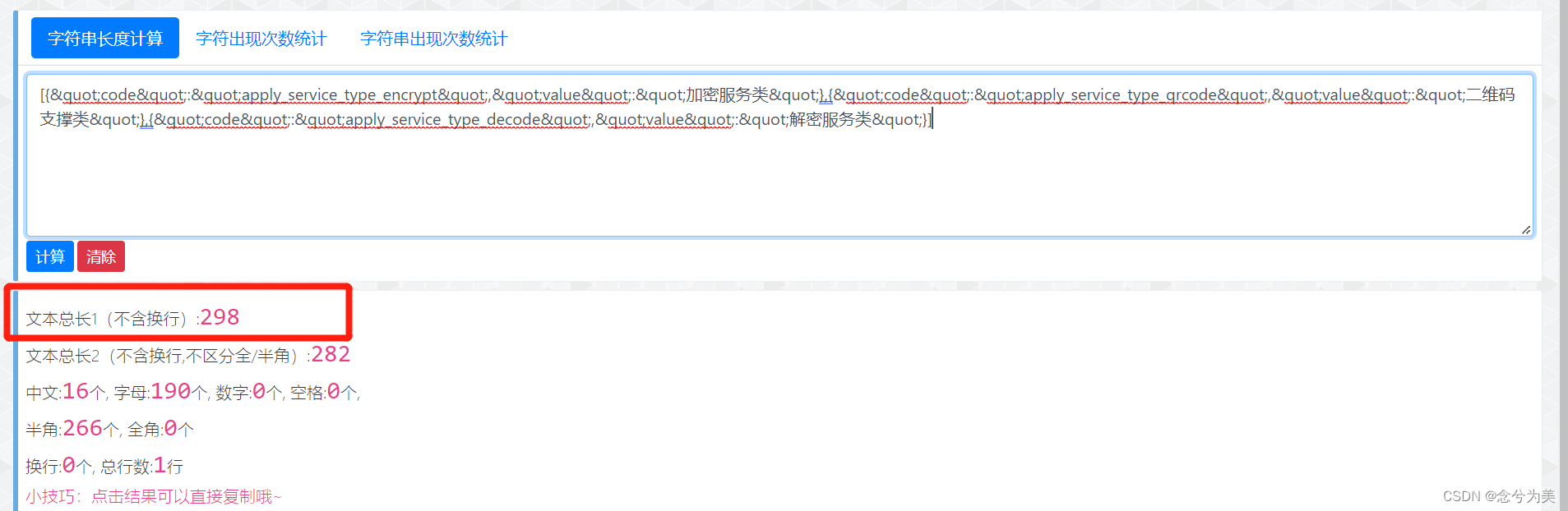
数据长度(298)大于varchar(255)的允许长度,自然会报出 Data too long for column 'apply_service_type' at row 1,即“apply_service_type”列太长。
为了更好的使用mysql数据库,在解决问题之前,我们需要了解mysql数据库字符串类型,以保证知其然知其所以然。
MySQL字符串类型其用来存储字符串数据,还可以存储图片和声音的二进制数据。
MySQL中的字符串类型有CHAR、VARCHAR、TINYTEXT、TEXT、MEDIUMTEXT、LONGTEXT、ENUM、SET 等。
下表中列出了MySQL中的字符串数据类型,括号中的M表示可以为其指定长度。
| 类型名称 | 说明 | 存储需求 |
|---|---|---|
| CHAR(M) | 固定长度非二进制字符串 | M 字节,1<=M<=255 |
| VARCHAR(M) | 变长非二进制字符串 | L+1字节,在此,L< = M和 1<=M<=255 |
| TINYTEXT | 非常小的非二进制字符串 | L+1字节,在此,L<2^8 |
| TEXT | 小的非二进制字符串 | L+2字节,在此,L<2^16 |
| MEDIUMTEXT | 中等大小的非二进制字符串 | L+3字节,在此,L<2^24 |
| LONGTEXT | 大的非二进制字符串 | L+4字节,在此,L<2^32 |
| ENUM | 枚举类型,只能有一个枚举字符串值 | 1或2个字节,取决于枚举值的数目 (最大值为65535) |
| SET | 一个设置,字符串对象可以有零个或 多个SET成员 | 1、2、3、4或8个字节,取决于集合 成员的数量(最多64个成员) |
VARCHAR和TEXT类型是变长类型,其存储需求取决于列值的实际长度(在前面的表格中用L表示),而不是取决于类型的最大可能尺寸。
假如一个VARCHAR(10)列能保存一个最大长度为10个字符的字符串,实际的存储需要字符串的长度L加上一个字节以记录字符串的长度。对于字符abcd,L是4,而存储要求5个字节。
CHAR(M)为固定长度字符串,在定义时指定字符串列长。当保存时,在右侧填充空格以达到指定的长度。M表示列的长度,范围是0~255个字符。
例如,CHAR(4)定义了一个固定长度的字符串列,包含的字符个数最大为4。当检索到CHAR值时,尾部的空格将被删除。
VARCHAR(M)是长度可变的字符串,M表示最大列的长度,M的范围是0~65535。VARCHAR的最大实际长度由最长的行的大小和使用的字符集确定,而实际占用的空间为字符串的实际长度加1。
例如,VARCHAR(50)定义了一个最大长度为50的字符串,如果插入的字符串只有10个字符,则实际存储的字符串为10个字符和一个字符串结束字符。VARCHAR在值保存和检索时尾部的空格仍保留。
**【实例】**下面将不同的字符串保存到CHAR(4)和VARCHAR(4)列,说明CHAR和VARCHAR之间的差别,如下表所示。
| 插入值 | CHAR(4) | 存储需求 | VARCHAR(4) | 存储需求 |
|---|---|---|---|---|
| ’ ’ | ’ ’ | 4字节 | ‘’ | 1字节 |
| ‘ab’ | 'ab ’ | 4字节 | ‘ab’ | 3字节 |
| ‘abc’ | 'abc ’ | 4字节 | ‘abc’ | 4字节 |
| ‘abcd’ | ‘abcd’ | 4字节 | ‘abcd’ | 5字节 |
| ‘abcdef’ | ‘abcd’ | 4字节 | ‘abcd’ | 5字节 |
对比结果可以看到,CHAR(4)定义了固定长度为4的列,无论存入的数据长度为多少,所占用的空间均为4个字节。VARCHAR(4)定义的列所占的字节数为实际长度加 1。
TEXT列保存非二进制字符串,如文章内容、评论等。当保存或查询TEXT列的值时,不删除尾部空格。
TEXT类型分为 4 种:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。不同的TEXT类型的存储空间和数据长度不同:
TINYTEXT表示长度为 255(28-1)字符的 TEXT 列。
TEXT表示长度为 65535(216-1)字符的 TEXT 列。
MEDIUMTEXT表示长度为 16777215(224-1)字符的 TEXT 列。
LONGTEXT表示长度为 4294967295 或 4GB(232-1)字符的 TEXT 列。
ENUM是一个字符串对象,值为表创建时列规定中枚举的一列值。其语法格式如下:
<字段名> ENUM( '值1', '值1', …, '值n' )
字段名指将要定义的字段,值n指枚举列表中第n个值。
ENUM类型的字段在取值时,能在指定的枚举列表中获取,而且一次只能取一个。如果创建的成员中有空格,尾部的空格将自动被删除。
ENUM值在内部用整数表示,每个枚举值均有一个索引值;列表值所允许的成员值从1开始编号,MySQL存储的就是这个索引编号,枚举最多可以有65535个元素。
例如,定义 ENUM 类型的列(first,second,third),该列可以取的值和每个值的索引如下表所示。
| 值 | 索引 |
|---|---|
| NULL | NULL |
| ‘’ | 0 |
| ’first | 1 |
| second | 2 |
| third | 3 |
ENUM值依照列索引顺序排列,并且空字符串排在非空字符串前,NULL值排在其他所有枚举值前。
提示:ENUM列总有一个默认值。如果将ENUM列声明为NULL,NULL值则为该列的一个有效值,并且默认值为NULL。如果ENUM列被声明为NOT NULL,其默认值为允许的值列表的第1个元素。
SET是一个字符串的对象,可以有零或多个值,SET列最多可以有64个成员,值为表创建时规定的一列值。指定包括多个SET成员的SET列值时,各成员之间用逗号,隔开,语法格式如下:
SET( '值1', '值2', …, '值n' )
与ENUM类型相同,SET值在内部用整数表示,列表中每个值都有一个索引编号。当创建表时,SET成员值的尾部空格将自动删除。
但与ENUM类型不同的是,ENUM类型的字段只能从定义的列值中选择一个值插入,而SET类型的列可从定义的列值中选择多个字符的联合。
提示:如果插入SET字段中的列值有重复,则MySQL自动删除重复的值;插入SET字段的值的顺序并不重要,MySQL会在存入数据库时,按照定义的顺序显示;如果插入了不正确的值,默认情况下,MySQL 将忽视这些值,给出警告。
通过以上的分析,我们需要把apply_service_type字段的数据类型修改为longtext或者text 都可以,本例将其修改为text的数类型类型,如下SQL所示:
mysql> alter table test modify column apply_service_type text;
Query OK, 0 rows affected (0.12 sec)
Records: 0 Duplicates: 0 Warnings: 0
重新执行如上插入语句:
mysql> INSERT test(apply_service_type) VALUES('[{"code":"apply_service_type_encrypt","value":"加密服务类"},{"code":"apply_service_type_qrcode","value":"二维码支撑类"},{"code":"apply_service_type_decode","value":"解密服务类"}]');
Query OK, 1 row affected (0.01 sec)
使用如下SQL查询可得:
mysql> select * from test;
+----+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | apply_service_type |
+----+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 1 | [{"code":"apply_service_type_encrypt","value":"加密服务类"},{"code":"apply_service_type_qrcode","value":"二维码支撑类"},{"code":"apply_service_type_decode","value":"解密服务类"}] |
+----+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
为什么将varchar类型修改为longtext或者text就行了呢,这里就涉及到mysql的数据类型。
了解mysql的字符串类型,对于熟练使用mysql存储数据,以及对字符串的性能优化,有着极大的好处。

总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i