默认情况下,在 spring boot 嵌入的 tomcat 限制了上传文件的大小,在 spring boot 的我官方文档中说明,每个文件的最大配置为1Mb,单次请求的总文件数不能大于10Mb。
这意味着如果你上传的图片大于1Mb,会被拦截下来,无法正常保存到后台,并抛出一个错误,返回状态码:500。
The field file exceeds its maximum permitted size of 1048576 bytes.
需要根据实际情况更改这两个数值。(application.yml 配置文件)
spring:
servlet:
multipart:
enabled: true
max-file-size: 10MB
max-request-size: 100MB
后端程序接收到图片资源后,会将图片保存到硬盘中的一个路径下,如果我们想通过URL直接访问到图片资源,就需要配置一个 Mapping 路径去映射这个真实存在的物理路径。
同样是在 application.yml 文件中,添加物理存储路径以及映射到项目中的 Mapping 路径。
image:
save-path: D:/image # 图片存储路径
mapping-path: /img # 图片的 RequestMapping 的路径
添加一个spring boot配置程序,这样就形成了一对映射关系。
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.ResourceHandlerRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class SpringbootConfigure implements WebMvcConfigurer {
//@Value可以将配置文件的内容自动注入到属性内
/***图标物理存储路径*/
@Value("${image.save-path}")
private String imageSavePath;
/***图标映射路径*/
@Value("${image.mapping-path}")
private String imageMappingPath;
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler(imageMappingPath + "**").addResourceLocations("file:" + imageSavePath);
}
}
用于接收图片的 Controller
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.FileSystemResource;
import org.springframework.core.io.Resource;
import org.springframework.http.MediaType;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.UUID;
@Controller
@RequestMapping("/img")
public class ImageController {
/*** 图片存储路径 */
@Value("${image.save-path}")
private String imageSavePath;
/*** 图片映射路径 */
@Value("${image.mapping-path}")
private String imageMappingPath;
/**
* 获取图片
*
* @param imagePath 图片在服务器中的路径
* @return 返回响应资源
*/
@GetMapping("/{path}")
public ResponseEntity<Resource> getImage(@PathVariable("path") String imagePath) throws IOException {
final Path path = new File(imagePath).toPath();
FileSystemResource resource = new FileSystemResource(path);
return ResponseEntity.ok()
.contentType(MediaType.parseMediaType(Files.probeContentType(path)))
.body(resource);
}
/**
* 上传
*
* @param fileUpload 图片资源
* @return 图映射的虚拟访问路径
*/
@PostMapping("/upload")
public String upload(@RequestParam("file") MultipartFile fileUpload) {
//获取文件名
String fileName = fileUpload.getOriginalFilename();
//获取文件后缀名。也可以在这里添加判断语句,规定特定格式的图片才能上传,否则拒绝保存。
String suffixName = fileName.substring(fileName.lastIndexOf("."));
//为了避免发生图片替换,这里使用了文件名重新生成
fileName = UUID.randomUUID() + suffixName;
try {
// 将图片保存到文件夹里
fileUpload.transferTo(new File(imageSavePath + fileName));
// 返回文件 Mapping 路径,使用 http://IP:端口/下面返回的路径 ,即可在网页中查看图片
return imageMappingPath + fileName;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}
要注意前端 post 提交 content-type 的格式以及后端 @RequestBody 注解的问题
@RequestBody 注解常用来处理 POST 请求,并且 content-type 不是默认的 application/x-www-form-urlcoded 编码的内容,比如说:application/json 或者是 application/xml 等。一般情况下来说常用其来处理 application/json 类型。
@RequestMapping注解的方法的参数中包含了@RequestBody注解,那么 Spring 会首先查看请求中的Content-Type头部,然后根据Content-Type头部去查找合适的HttpMessageConverter
@RequestBody用于需要触发HttpMessageConverter的场景:
Content-Type头部为application/json时,需要加上@RequestBody注解,并使用默认的HttpMessageConverter或者自定义的HttpMessageConverter对请求的body中的json字符串转换为java对象。Content-Type头部的值为application/x-www-form-urlencoded或者multipart/form-data时,表名此请求是一个常规的表单请求,不能使用@RequestBody注解。在《Spring 实战》中,表明了
@RequestBody注解的含义和使用方式:用来解析请求体(可能是POST,PUT,DELETE,GET请求)中Content-Type为application/json类型的请求,利用消息转换器将其转换为对应的java对象(必须使用 VO 对象(VO:存储表单数据的实体类对象,详见类命名:Java 中 PO、VO、POJO、DTO、DAO、Service 包等常见包名的理解)去接收)
那么什么类型的消息能够加上@RequestBody,什么类型的消息不能加呢?当请求中的ContentType分别为一下三种类型时的结果:
| 是否加上注解 | x-www-form-urlencoded | form-data | application/json |
|---|---|---|---|
不加@RequestBody注解 | 能接收 | 能接收 | 不能接收 |
加上@RequestBody注解 | 不能接收 | 不能接收 | 能接收 |
延伸学习:常见的表单数据格式
一般建议很小的图片保存为 Base64 格式,或者页面中图片特别少且大小不是很大的情况下使用,因为转为 Base64 编码格式后将会明显占用更多空间。因为 Base64 的使用缺点,所以一般图片小于10kb 的时候,我们才会选择使用 Base64 图片,比如一些表情图片,太大的图片转换成 Base64 得不偿失。当然,极端情况极端考虑。
Base64 编码的思想是是采用64个基本的 ASCII 码字符对数据进行重新编码。
Base64 编码要求把3个8位字节(3×8=24)转化为4个6位的字节(4×6=24),之后在6位的前面补两个0,形成8位一个字节的形式。
如果剩下的字符不足3个字节,则用0填充,输出字符使用’=‘,因此编码后输出的文本末尾可能会出现1或2个’='。
为了保证所输出的编码位可读字符,Base64 制定了一个编码表,以便进行统一转换。编码表的大小为2^6=64,这也是 Base64 名称的由来。
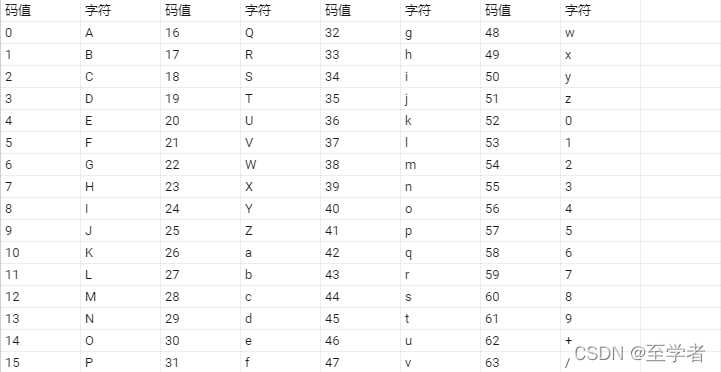
注BASE64字符表:
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/
从以上编码规则可以得知,通过 Base64 编码,原来的3个字节编码后将成为 4 个字节,即字节增加了 33.3%,数据量相应变大。所以 10M 的数据通过 Base64 编码后大小大概为10M*133.3%=13.33M。
(1)Base64 格式的图片是文本格式,占用内存小,转换后的大小比例大概为 1/3,降低了资源服务器的消耗;
(2)网页中使用 Base64 格式的图片时,不用再请求服务器调用图片资源,减少了服务器访问次数。
(1)base64格式的文本内容较多,存储在数据库中增大了数据库服务器的压力;(磁盘空间占用大)
(2)网页加载图片虽然不用访问服务器了,但因为base64格式的内容太多,所以加载网页的速度会降低,可能会影响用户的体验。
(3)Base64 无法缓存,要缓存只能缓存包含 Base64 的文件,比如 js 或者 css,这比直接缓存图片要差很多,而且一般 HTML 改动比较频繁,所以等同于得不到缓存效益。
其实也可以转换文件
import org.apache.tomcat.util.codec.binary.Base64;
import org.springframework.web.multipart.MultipartFile;
import java.io.*;
import java.util.Objects;
public class ImageToBase64Util {
/*** 本地文件(图片、excel等)转换成Base64字符串 */
public static String convertFileToBase64(String imgPath) {
//读取图片字节数组
byte[] data = null;
try {
InputStream in = new FileInputStream(imgPath);
System.out.println("文件大小(字节)=" + in.available());
data = new byte[in.available()];
in.read(data);
in.close();
} catch (IOException e) {
e.printStackTrace();
}
//对字节数组进行Base64编码,得到Base64编码的字符串
return new String(Objects.requireNonNull(Base64.encodeBase64(data)));
}
/*** 将base64字符串,生成文件 */
public static File convertBase64ToFile(String fileBase64String, String filePath, String fileName) {
BufferedOutputStream bos = null;
FileOutputStream fos = null;
File file = null;
try {
File dir = new File(filePath);
//判断文件目录是否存在
if (!dir.exists() && dir.isDirectory()) {
dir.mkdirs();
}
byte[] bfile = Base64.decodeBase64(fileBase64String);
file = new File(filePath + File.separator + fileName);
fos = new FileOutputStream(file);
bos = new BufferedOutputStream(fos);
bos.write(bfile);
return file;
} catch (Exception e) {
e.printStackTrace();
} finally {
if (bos != null) {
try {
bos.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
if (fos != null) {
try {
fos.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
}
return null;
}
/*** MultipartFile转成InputStream 将图片转换成Base64编码 */
public static String imgToBase64(MultipartFile uploadFiles) {
InputStream in;
byte[] data = null;
//读取图片字节数组
try {
byte[] byteArr = uploadFiles.getBytes();
in = new ByteArrayInputStream(byteArr);
data = new byte[in.available()];
in.read(data);
in.close();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e1) {
e1.getMessage();
e1.printStackTrace();
}
return new String(Objects.requireNonNull(Base64.encodeBase64(data)));
}
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
这道题是thisquestion的逆题.给定一个散列,每个键都有一个数组,例如{[:a,:b,:c]=>1,[:a,:b,:d]=>2,[:a,:e]=>3,[:f]=>4,}将其转换为嵌套哈希的最佳方法是什么{:a=>{:b=>{:c=>1,:d=>2},:e=>3,},:f=>4,} 最佳答案 这是一个迭代的解决方案,递归的解决方案留给读者作为练习:defconvert(h={})ret={}h.eachdo|k,v|node=retk[0..-2].each{|x|node[x]||={};node=node[x]}node[
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我有一个包含多个键的散列和一个字符串,该字符串不包含散列中的任何键或包含一个键。h={"k1"=>"v1","k2"=>"v2","k3"=>"v3"}s="thisisanexamplestringthatmightoccurwithakeysomewhereinthestringk1(withspecialcharacterslike(^&*$#@!^&&*))"检查s是否包含h中的任何键的最佳方法是什么,如果包含,则返回它包含的键的值?例如,对于上面的h和s的例子,输出应该是v1。编辑:只有字符串是用户定义的。哈希将始终相同。 最佳答案
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.