以下皆为部分代码,详见 https://github.com/liyuelian/furniture_mall.git
在生成订单的功能中,系统会去同时修改数据库中的order,order_item,furn三张表,如果有任意一个表修改失败,就会出现数据不一致问题。因此出现了事务控制问题。
之前,我们每次调用底层的dao操作,每次进行的都是独立事务,因此一但在一次业务中调用了多个dao操作,就不能保证多表的事务一致性。
因为JDBC局部事务是控制是由java.sql.Connection来完成的,要保证多个DAO的数据访问处于一个事务中,我们需要保证他们使用的是同一个java.sql.Connection.
要保证数据一致性,就要使用事务。使用事务的前提是保证同一个连接connection。我们的想法是,在进行dao操作的前面就开启事务,然后在进行各种dao操作后,如果没有出现异常,则手动进行事务提交,否则进行回滚。
现在的问题是:
q1. 我们之前使用数据库连接池,无法保证每次进行dao操作都是同一个connection连接对象
q2. 设置开启手动提交事务以及事务回滚的时机
解决方法:
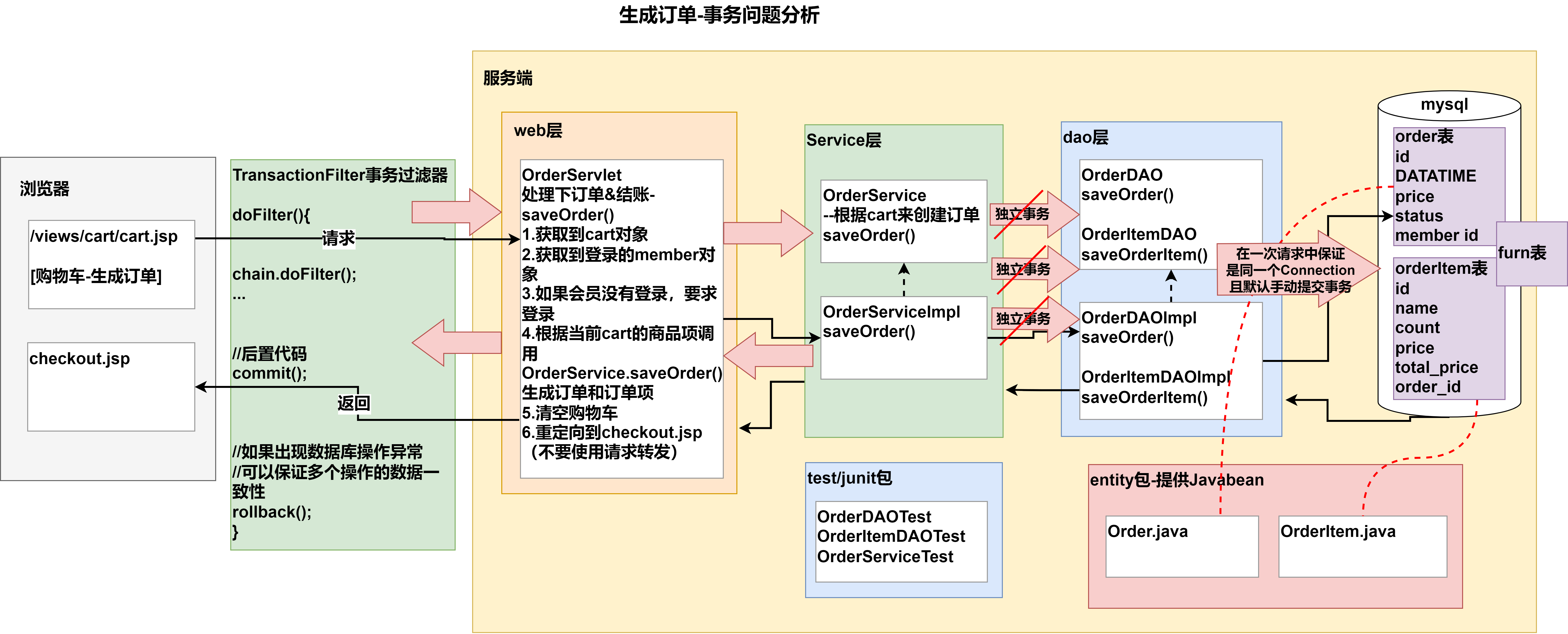
重写JDBCUtilsByDruid,修改getConnection方法,同时设置手动提交事务
package com.li.furns.utils;
import com.alibaba.druid.pool.DruidDataSourceFactory;
import javax.sql.DataSource;
import java.io.FileInputStream;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
import java.util.Properties;
/**
* 基于Druid数据库连接池的工具类
*/
public class JDBCUtilsByDruid {
private static DataSource ds;
//定义属性ThreadLocal,这里存放一个Connection
private static ThreadLocal<Connection> threadLocalConn = new ThreadLocal<>();
//在静态代码块完成ds的初始化
//静态代码块在加载类的时候只会执行一次,因此数据源也只会初始化一次
static {
Properties properties = new Properties();
try {
//因为我们是web项目,它的工作目录不在src下面,文件的加载需要使用类加载器
properties.load(JDBCUtilsByDruid.class.getClassLoader()
.getResourceAsStream("druid.properties"));
//properties.load(new FileInputStream("src\\druid.properties"));
ds = DruidDataSourceFactory.createDataSource(properties);
} catch (Exception e) {
e.printStackTrace();
}
}
// //编写getConnection方法
// public static Connection getConnection() throws SQLException {
// return ds.getConnection();
// }
/**
* 获取连接方法
* 从ThreadLocal中获取connection,
* 从而保证在同一个线程中获取的是同一个Connection
*
* @return
* @throws SQLException
*/
public static Connection getConnection() {
Connection connection = threadLocalConn.get();
if (connection == null) {//说明当前的threadLocalConn没有连接
//就从数据库连接池中获取一个连接,放到ThreadLocal中
try {
connection = ds.getConnection();
//设置为手动提交,即不要自动提交
connection.setAutoCommit(false);
} catch (SQLException e) {
e.printStackTrace();
}
threadLocalConn.set(connection);
}
return connection;
}
/**
* 提交事务
*/
public static void commit() {
Connection connection = threadLocalConn.get();
if (connection != null) {//确保该连接是有效的
try {
connection.commit();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
connection.close();//将连接释放回连接池
} catch (SQLException e) {
e.printStackTrace();
}
}
//1.当提交后,需要把connection从threadLocalConn中清除掉
//2.否则会造成ThreadLocalConn长时间持有该连接,会影响效率
//3.也因为我们Tomcat底层使用的是线程池技术
threadLocalConn.remove();
}
}
/**
* 回滚,回滚的是和connection相关的dml操作
*/
public static void rollback() {
Connection connection = threadLocalConn.get();
if (connection != null) {//保证当前的连接是有效的
try {
connection.rollback();
} catch (SQLException e) {
e.printStackTrace();
} finally {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
threadLocalConn.remove();
}
//关闭连接(注意:在数据库连接池技术中,close不是真的关闭连接,而是将Connection对象放回连接池中)
public static void close(ResultSet resultSet, Statement statemenat, Connection connection) {
try {
if (resultSet != null) {
resultSet.close();
}
if (statemenat != null) {
statemenat.close();
}
if (connection != null) {
connection.close();
}
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
因为现在连接的关闭是在commit或者rollback中发生的,因此BasicDAO中写的关闭连接已经没有意义了,将其删掉即可。
配置TransactionFilter
<filter>
<filter-name>TransactionFilter</filter-name>
<filter-class>com.li.furns.filter.TransactionFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>TransactionFilter</filter-name>
<!--这里我们对所有请求都进行事务管理-->
<url-pattern>/*</url-pattern>
</filter-mapping>
TransactionFilter:
package com.li.furns.filter;
import com.li.furns.utils.JDBCUtilsByDruid;
import javax.servlet.*;
import java.io.IOException;
/**
* 管理事务
*
* @author 李
* @version 1.0
*/
public class TransactionFilter implements Filter {
public void init(FilterConfig config) throws ServletException {
}
public void destroy() {
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws ServletException, IOException {
try {
//先放行
chain.doFilter(request, response);
//统一提交
JDBCUtilsByDruid.commit();
} catch (Exception e) {
//只有在try{}中出现了异常,才会进行catch{}
//这里想要捕获异常,前提是底层的代码没有将抛出的异常捕获
JDBCUtilsByDruid.rollback();//回滚
e.printStackTrace();
}
}
}
由于之前在BasicServlet中捕获了异常,因此需要修改BasicServlet,将捕获的异常抛出给Filter,否则无法在出现异常时进行回滚。
为了测试,在FurnDAOImpl操作中写入错误的sql语句,模拟表操作失败

现在来测试一下,当发生dao操作失败后会产生什么现象。
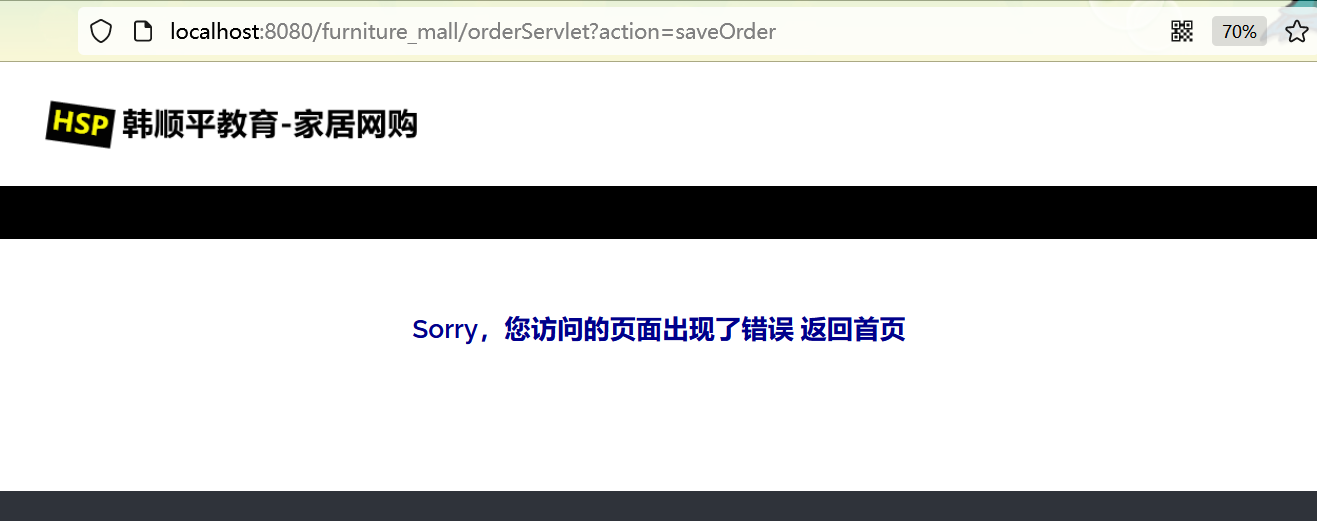
登录用户,点击添加某个家居,点击购物车生成订单,因为生成订单涉及到furn表的操作,因此可以看到点击后页面没有跳转到正常的显示订单页面
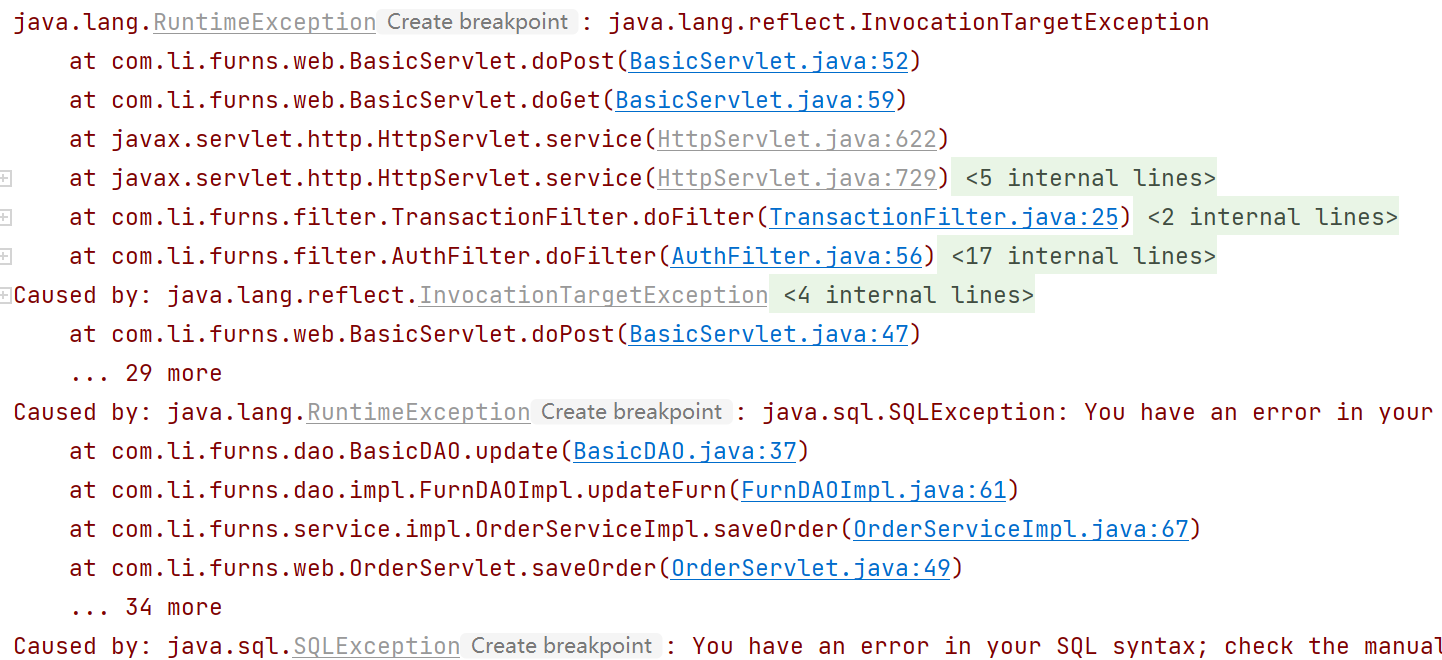
查看后台输出,发现抛出异常
查看数据库:
相关的表没有进行改动,说明事务管理起作用了。
order_item表:

order表:

furn表:(操作前后的sales和stock字段一致)

404.jsp用于显示404错误;500.jsp用于显示服务器内部错误。
页面代码:略。
在web.xml文件中配置错误提示页:
<!--404错误提示页面-->
<error-page>
<error-code>404</error-code>
<location>/views/error/404.jsp</location>
</error-page>
<!--500错误提示页面-->
<error-page>
<error-code>500</error-code>
<location>/views/error/500.jsp</location>
</error-page>
如果在代码中捕获了异常,那么将不会起到效果,应该要将异常抛出给tomcat,让tomcat可以根据不同的异常进行页面展示。
TransactionFilter:

在浏览器中输入一个项目不存在的资源http://localhost:8080/furniture_mall/abc.jsp,访问结果:
内部发生错误:
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建