参考文章如下:https://blog.csdn.net/lqzdreamer/article/details/79676305
https://blog.csdn.net/lqzdreamer/article/details/79676305
一般常用范数来衡量向量,向量的Lp范数定义为:
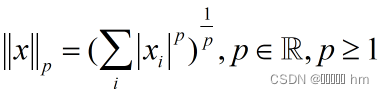
Lp范数示意图:
从图中可以看出,p的取值在 [0,1) 之间,范数不具有凸性,实际优化过程中,无法进行,一般会把L0范数转化为L1范数。
L0范数是指向量x中的非0个数,是一种度量向量的稀疏性的表示方法。例如:x=[1,1,0,1],
L1范数是向量中元素的绝对值之和,也是一种度量向量的稀疏性的表示方法。
矩阵的L1范数定义为:所有矩阵列向量绝对值之和的最大值
矩阵的L2范数定义为:矩阵的最大特征值的开方
其中λi为的特征值。
矩阵的F范数定义为:矩阵元素绝对值的平方和再开方
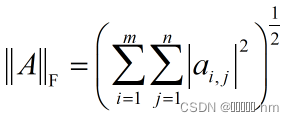
矩阵的L2,1范数定义为:矩阵A的每一行的L2范数之和
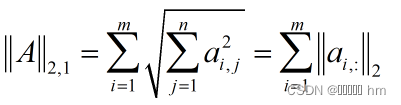
在最小化问题中,只有每一行的L2范数都最小总问题才最小,而每一个函数取得最小的含义是,当行内尽可能多的元素为0的时候,约束才可以取到最小。
为了避免过拟合,我们常会给简单的函数加一个偏移,假如有两个函数都可以很好的拟合数据,我们会倾向于使用简单的那个,可以通过添加一个正则项来实现,也就是范数,常用形式:

其中λ是正则系数,表示想要正则化的程度。
根据范数的定义,我们可以知道权重越大,范数越大,也就是说最小化范数可以得到一个相对简单的函数。总结来说,最小化权重的范数可以让过拟合函数变简单。
通过给我们最小化目标函数添加范数,可以促使拟合出权重较小的函数,带来了正则效应,提升了数据的泛化性。
在特征选择中,通过稀疏化的特征选择矩阵来选取特征,相当于是一种线性变换。
一行代表一个数据点,每一列代表一个特征分量。
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
点向量坐标矩阵的几何意义介绍旋转矩阵的几何含义之前,先介绍一下点向量坐标矩阵的几何含义点:在一维空间下就是一个标量,如同一条直线上,以任意某一个位置为0点,以一定的尺度间隔为1,2,3...,相反方向为-1,-2,-3...;如此就形成了一维坐标系,这时候任何一个点都可以用一个数值表示,如点p1=5,即即从原点出发沿着x轴正方向移动5个尺度;点p2=-3,负方向移动3个尺度; 在一维坐标系上过原点做垂直于一维坐标系的直线,则形成了二维坐标系,此时描述一个点需要两个数值来表示点p3=(3,2),即从原点出发沿着x轴正方向移动3个尺度,在此基础上沿着y轴正方向移动两个尺度的位置就是点p3。
@raw_array[i]=~/[\W]/非常简单的正则表达式。当我用一些非拉丁字母(具体来说是俄语)尝试时,条件是错误的。我能用它做什么? 最佳答案 @raw_array[i]=~/[\p{L}]/使用西里尔字符进行测试。引用:http://www.regular-expressions.info/unicode.html#prop 关于ruby-正则表达式将非英文字母匹配为非单词字符,我们在StackOverflow上找到一个类似的问题: https://
我需要一个非常简单的字符串验证器来显示第一个符号与所需格式不对应的位置。我想使用正则表达式,但在这种情况下,我必须找到与表达式相对应的字符串停止的位置,但我找不到可以做到这一点的方法。(这一定是一种相当简单的方法……也许没有?)例如,如果我有正则表达式:/^Q+E+R+$/带字符串:"QQQQEEE2ER"期望的结果应该是7 最佳答案 一个想法:你可以做的是标记你的模式并用可选的嵌套捕获组编写它:^(Q+(E+(R+($)?)?)?)?然后你只需要计算你获得的捕获组的数量就可以知道正则表达式引擎在模式中停止的位置,你可以确定匹配结束
这是一个例子:s="abcd+subtext@example.com"s.match(/+[^@]*/)Result=>"+subtext"问题是,我不想在其中包含“+”。我希望结果是“潜台词”,没有+ 最佳答案 您可以在正则表达式中使用括号来创建匹配组:s="abcd+subtext@example.com"s=~/\+([^@]*)/&&$1=>"subtext" 关于ruby-正则表达式-排除一个字符,我们在StackOverflow上找到一个类似的问题:
我们有一个字符串:“”这个正则表达式://i如何从当前字符串中获取所有匹配项? 最佳答案 "".scan(//)参见scan在ruby-docs上 关于ruby-如何遍历Ruby中所有正则表达式匹配的字符串?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6857852/
我正在尝试通过正则表达式拆分参数列表。这是一个带有我的参数列表的字符串:"a=b,c=3,d=[1,3,5,7],e,f=g"我想要的是:["a=b","c=3","d=[1,3,5,7]","e","f=g"]我试过先行,但Ruby不允许使用动态范围后行,所以这行不通:/(?如何让正则表达式忽略方括号中的所有内容? 最佳答案 也许这样的东西对你有用:str.scan(/(?:\[.*?\]|[^,])+/)编辑再三考虑。简单的非贪婪匹配器在某些嵌套括号的情况下会失败。 关于Ruby正则
我想找到给定字符串中的所有匹配项,包括重叠匹配项。我怎样才能实现它?#Example"a-b-c-d".???(/\w-\w/)#=>["a-b","b-c","c-d"]expected#Solutionwithoutoverlappedresults"a-b-c-d".scan(/\w-\w/)#=>["a-b","c-d"],but"b-c"ismissing 最佳答案 在积极的前瞻中使用捕获:"a-b-c-d".scan(/(?=(\w-\w))/).flatten#=>["a-b","b-c","c-d"]参见Rubyde
我想为名字验证编写一个正则表达式。正则表达式应包括所有字母(拉丁/法语/德语字符等)。但是我想从中排除数字并允许-。所以基本上它是\w(减)数(加)-。请帮忙。 最佳答案 ^[\p{L}-]+$\p{L}匹配anykindofletterfromanylanguage. 关于ruby-on-rails-rails中的正则表达式匹配[\w]和"-"但不匹配数字,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
这就是我做的a="%span.rockets#diamonds.ribbons.forever"a=a.match(/(^\%\w+)([\.|\#]\w+)+/)putsa.inspect这是我得到的#这就是我想要的#帮助?我尝试过但失败了:( 最佳答案 通常,您不能获得任意数量的捕获组,但如果您使用扫描,您可以为您想要捕获的每个标记获得一个匹配:a="%span.rockets#diamonds.ribbons.forever"a=a.scan(/^%\w+|\G[.|#]\w+/)putsa.inspect["%span","