文章目录
核心内容
(1)功能结构
网络层用于提供主机与主机之间的逻辑通信,源主机网络层接收来自运输层的报文段,将其封装为一个数据报并向相邻的路由器发送数据报。接收方的网络层接收来自相邻路由器的数据报,提取出报文段交付给运输层。为此需要提供转发和路由选择两个功能。网络层能够被划分为两个相互作用的部分,数据部分和路由部分:
每台网络路由器中都有一个转发表。路由器通过使用分组的首部目的地址在转发表中索引,来转发分组。那转发表是如何进行初始配置的呢?
传统方法:由路由选择算法决定插入转发表的内容。
①路由选择算法运行在每台路由器上。
②每台路由器都包括转发和路由选择两种功能。
③每台路由器都有与其他路由器进行通信的路由选择组件。

SDN方法:由远程控制器计算和分发转发表以供每台路由器使用。
①控制平面路由选择功能与路由器分离。
②路由器仅执行转发,由远程控制器计算和分发转发表。
③远程控制器实现在具有高可靠性和冗余的远程数据中心中。

在传统方法中,路由器兼具转发和路由选择两种功能,由路由选择算法更新路由表。在SDN方法中,路由器仅执行转发功能,路由选择在远程控制器执行,远程控制器计算和分发路由表。
(2)网络服务模型
网络服务模型定义了分组在发送与接收端系统之间的端到端运输特性。
因特网的网络层提供了单一的服务,称为尽力而为服务。(也就是不提供任何服务)
网络层具有转发和路由选择功能。在传统方法中,路由器能实现转发和路由选择两个功能。在SDN方法中,路由器仅实现转发功能。所以我们接下来就去了解路由器的组成结构,以及功能实现的细节。
一台路由器由四个部分组成:
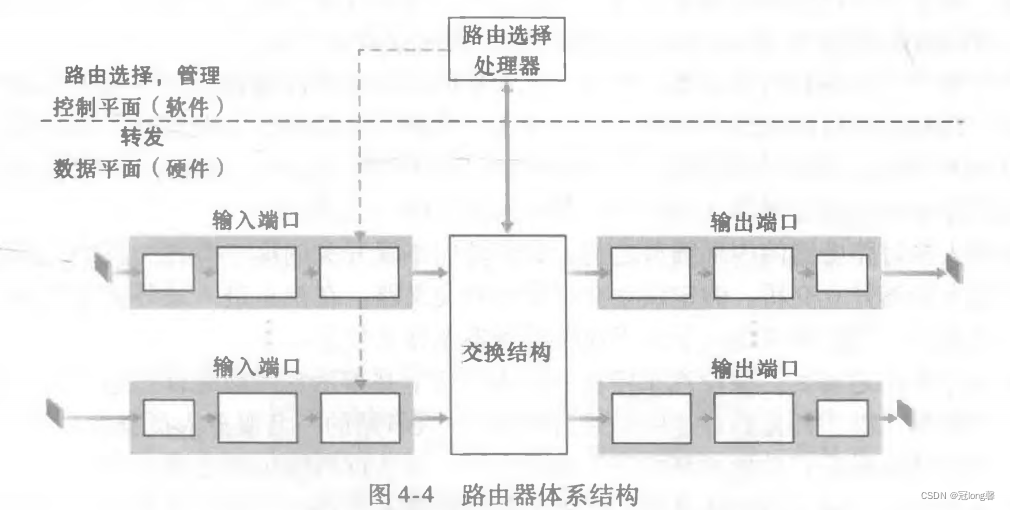
其中,路由器的输入端口、交换结构、输出端口总是用硬件实现。因为如果有多个端口结合在一个线路卡上,数据报处理流水线必须以N倍速率运行,这远快于软件实现的速率。而控制平面的功能通常在软件实现并由路由选择处理器执行。
分组转发的决定由有两种方式:
路由器具有转发功能,即将分组从输入端口转发到合适的输出端口。路由器使用转发表来查找输出端口。那么路由器是如何依赖转发表来来实现这样的功能的呢?
路由器的四个结构在实现转发功能中都起到了关键的作用。输入端口保存着转发表的影子副本,实现了在输入端口就能查找到合适的分组输出接口。交换结构将分组从输入端口传输到了输出端口。
路由器的转发功能是将分组从输入端口传输到合适的输出端口。首先路由器使用转发表来查找合适的输出端口。
(1)转发表
因此分组的转发决策是在输入端口做出的。这样分组在输入端口就能找到合适的输出端口,避免了每个分组都调用集中式路由选择处理器而导致的集中式处理瓶颈。
(2)基于目的地的转发
一个入分组到达路由器后,是基于其首部的目的地址找到输出端口的。路由器通过查找转发表中匹配的表项,向与该表象相关联的输出链路接口发送分组。一般有三种表项匹配方式:

通常我们使用最长前缀匹配机制。这样路由器就可以使用转发表找到最长匹配项对应的输出链路接口,并将分组发送到对应的输出端口。
(3)输入端口处理
输入端口除了查找功能,还具备的功能有:
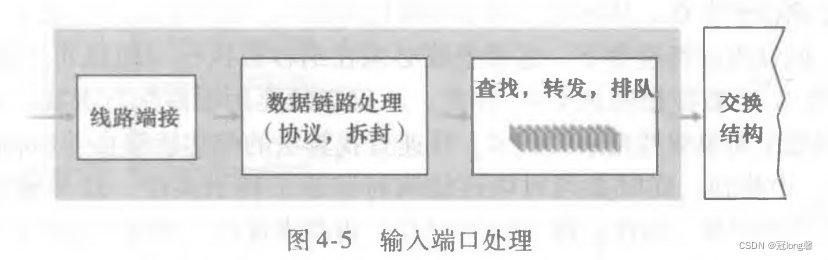
路由器通过使用转发表和输入队列实现了为分组查找合适的输出端口号,并将分组发往交换结构。
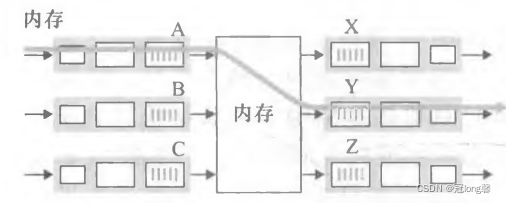
交换结构将从输入端口收到的分组传输到输出端口。常见的三种交换技术:
经内存交换(memory):分组从输入端口经总线复制到内存,再从内存复制到输出端口。
①因总线一次仅能执行一次内存读写,所以一次只能传输一个分组。
②路由器的交换受总线速率限制。
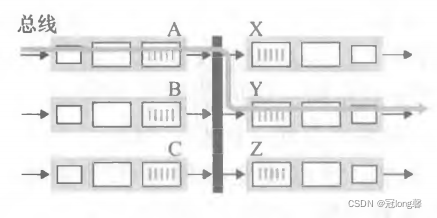
经总线交换(Bus):输入端口经共享总线将分组直接传送到输出端口,而不需要路由选择处理器干预。
①一次只能传输一个分组。
②路由器的交换受总线速率限制。
③不需要路由转发处理器干预。
经互联网络交换(CrossBar):使用复杂的互联网络,能够一次发送多个分组。
①克服了单一、共享总线对交换带宽的限制。
②一次可以传送多个分组。
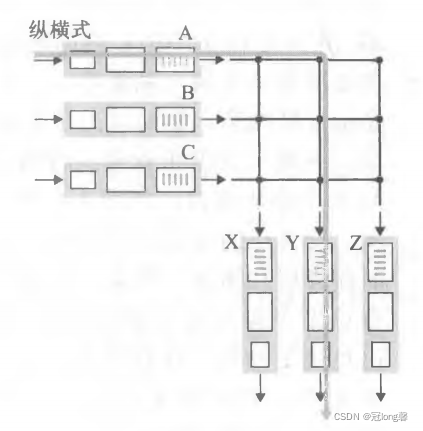
这样分组就通过交换结构到达了输出端口。
输出端口取出已存储在输出端口内存中的分组并将其发送到输出链路。所以输出端口主要提供两个功能:
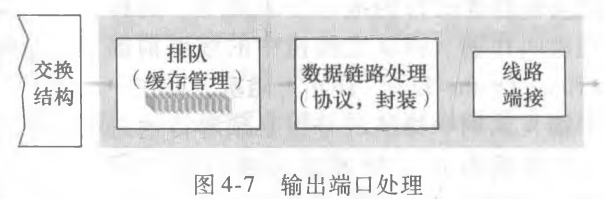
当分组通过输入端口到达交换结构时,发现交换结构正在传输另一个端口到达的分组。当前分组会被暂时阻塞。同理,当分组通过交换结构到达输出链路时,发现链路正在忙于传输另一个分组,当前分组也会被暂时阻塞。所以输入端口和输出端口都可能形成等待队列。
(1)排队
排队的位置和程度由流量负载、交换结构的相对速率与线路速率决定。
输入队列:用于匹配输入线路速率与交换结构传输速率。
①当输入速率大于交换结构传输速率时,会形成排队。
②假设有N个输入端口,当交换传输速率比输入线路速率快N倍时,才会出现微不足道的排队。
输出队列:用于匹配交换结构传输速率与输出线路速率。
因为交换结构一次只能传送一个分组到达指定端口,所以可能会出现阻塞问题。如线路前部空闲(HOL),当来自不同输入端口,但具有相同输出端口的分组同时到达时,交换结构回传输其中一个分组,其他分组则需要等待,即使其他输出端口空闲。在输出队列中等待的分组,也需要通过分组调度选择一个分组传输。当队列满了的时候,需要选择丢弃分组或者删除已有的分组。为了避免缓存溢出,缓存量通常设置为 B = R T T ∗ C B=RTT * C B=RTT∗C,即平均往返时延乘上链路容量。
(2)分组调度
常见的有四种分组调度方式:
先进先出:分组按照到达的次序离开。
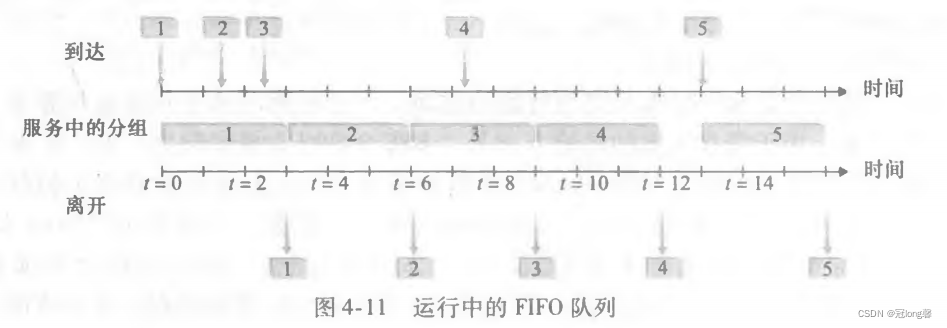
优先权排队:到达输出链路的分组先被分类放入优先级类。当选择一个分组输出时,从一个非空的最高优先级队列中传输一个分组。

循环排队:没有严格的服务优先权,循环调度器在不同类之间轮流提供服务。
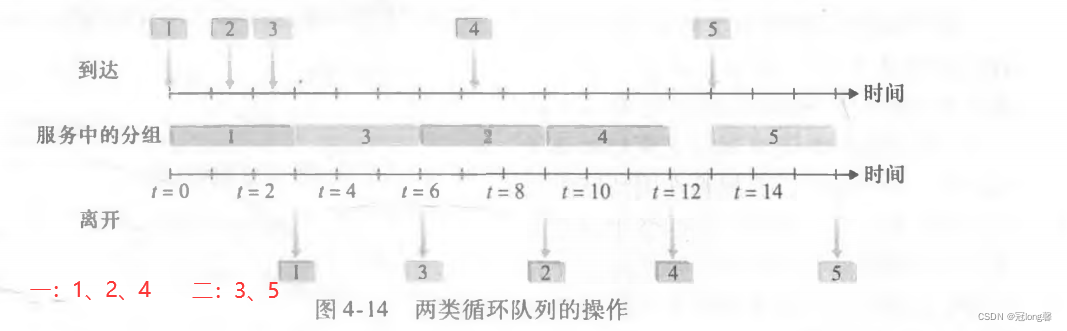
加权公平排队:循环调度器轮流在不同类提供服务。
①每个类都分配一个权,第i类确保接收到的服务部分等于
w
i
/
∑
w
j
w_i / \sum w_j
wi/∑wj。
综上所述,我们对路由器的结构和功能进行了介绍。路由器分为输入端口、交换结构、路由选择处理器、输出端口四个部分。实现了数据平台和控制平台两个部分的功能“转发”和“路由选择”。分组在输入端口通过查找路由表中的匹配表项,找到对应的输出链路接口。然后分组通过交换结构到达输出端口。其中路由表有两种方式计算和分配方式,传统路由器通过路由选择处理器计算和分配路由表。SDN路由器接收来自远程控制器计算的路由表,经由总线到达线路卡上。路由表在每个输入端口都保存了影子副本。为了匹配输入速率、交换结构传输速率、输出线路速率,在输入端和输出端口都有等待队列。输出端口也需要通过分组调度选择一个分组输出链路。
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
我知道全局变量$!包含最新的异常对象,但我对下面的语法感到困惑。谁能帮助我理解以下语法?rescue$! 最佳答案 此构造可防止异常停止您的程序并使堆栈跟踪冒泡。它还会将该异常作为值返回,这很有用。a=get_me_datarescue$!在此行之后,a将保存请求的数据或异常。然后您可以分析该异常并采取相应措施。defget_me_dataraise'Nodataforyou'enda=get_me_datarescue$!puts"Executioncarrieson"pa#>>Executioncarrieson#>>#更现实的