大数据行业工作好找还是难找不是光靠嘴说出来的结合实际,看看市场上的招聘需求和岗位要求就大致知道了
要想符合企业用人规范,学历,工作经验,掌握技能都是非常重要的~
先来看几个招聘网站的报告数据:
Boss直聘发布的,今年春季的招聘数据大数据需求增长排名第二
猎聘发布的2019年来新发职位同比增长最快的5大领域,前五名就是:人工智能,生产制造,大数据,医疗健康,能源环保。
《2020中国大数据产业发展白皮书》显示,2019年中国大数据产业规模达5397亿元,同比增长23.1%,随后稳定增长,预计到2022年将突破万亿元。
根据LinkedIn、赛迪智库、拉勾网等机构的统计结果,大数据时代下的数据人才总体缺口呈现加剧增长状态。近3年,数据人才缺口在以每年50万人增加,预计在2022年,相关大数据专业高校毕业生大规模进入就业市场后,整体缺口增速才会有所放缓,但这一缺口仍会长期存在。
招聘有了,但是应聘者往往因为学历,工作经历找工作会遇到各种各样的问题,那么现在已经从事大数据的开发人员具体情况是怎样的呢?我们来看下面这几个方面:
1、学历层次
从学历层次来看,我国大数据人才的学历层次分为4个大类,分别是硕士及以上、本科、专科、专科以下,其中本科学历的大数据人才最多,占到高达65.45%的比例,其次是硕士及以上,而专科及以下学历的大数据人才仅占一小部分。可以看出,大数据行业作为一个新兴行业,对人才的学历要求普遍较高。
2、专业来源
在专业来源方面,我国大数据人才的专业来源主要由数理类、经济管理类、计算机类及其他专业四大类构成,其中计算机类占比最高,其次是数理类。
3、渠道来源
大数据人才的渠道来源分为4个大类,分别是校招、社招、内部培养和推荐、培训机构招聘。企业大数据人才各渠道来源的人数和占比见下图。
其中社招占比最大,比校招、内培和内推以及培训机构招聘的总和还要高。目前主要依靠社招,说明学校教育与社会需求脱节,内培和培训也不能满足岗位要求。
4、薪资水平分布
当前,大数据人才的薪资处于相对较高水平。薪资在1万元以下,占总人数的34.6%;1万元-2万元占比为35.64%;2万以上占比为29.77%。
5、岗位类型及数量
目前企业提供的大数据岗位按照工作内容要求,可以分为以下几类:
① 初级分析类,包括业务数据分析师、商务数据分析师等。
② 挖掘算法类,包括数据挖掘工程师、机器学习工程师、深度学习工程师、算法工程师、AI工程师、数据科学家等。
③ 开发运维类,包括大数据开发工程师、大数据架构工程师、大数据运维工程师、数据可视化工程师、数据采集工程师、数据库管理员等。
④ 产品运营类,包括数据运营经理、数据产品经理、数据项目经理、大数据销售等。四类岗位的数量和占比见下图。
大数据需求越来越多,国家也在开设相关岗位,从2018年开始就逐年较大的增长。
此时报考大学的学生和家长也对大数据,人工智能非常感兴趣,大数据连续3年进了前5,而且学历主要是本科就可以。
可以预见的将来这几年,这真的是一个朝阳行业,而且现在缺口很大。
那么想知道以后能找什么工作以及工作薪水,那不妨让我们以数据的方式来展示一下~
那么打开Boss直聘,搜大数据工程师:
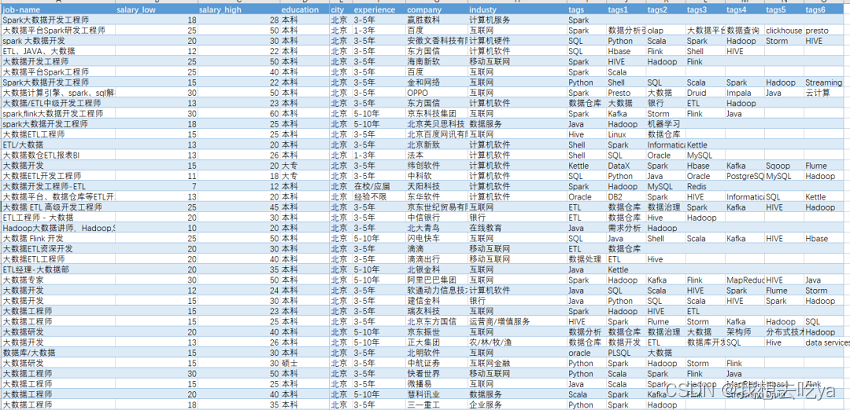
我们来做下数据分析:
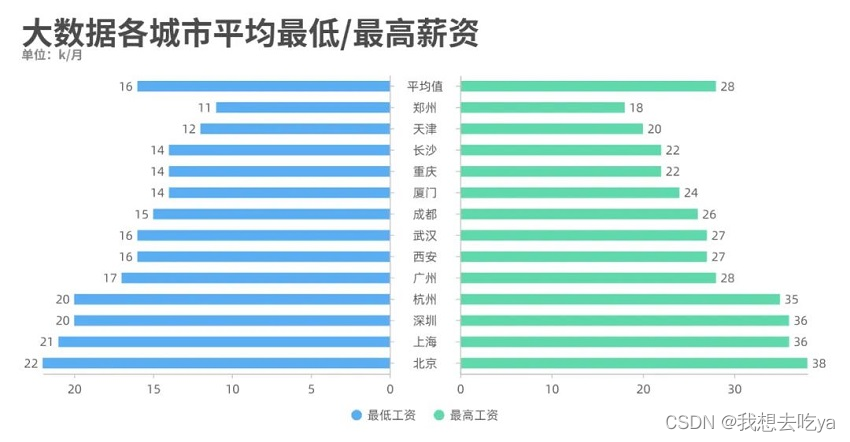
薪资那一列都有一个最低薪资和最高薪资,我们通过不同城市来对比分析一下,发现北京的工资水平最高,最低为22k,最高为38k。
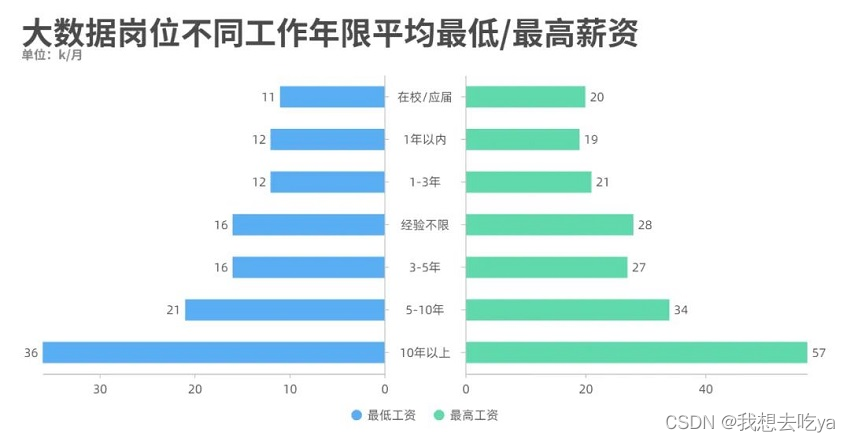
工作年限也是一个制约工资水平的很大因素,从图中可以看出,即使是刚毕业,也能达到一个11-20k的薪资范围。
而学历要求来说,大部分为本科,其次为大专和硕士,其他比较少,以至于在图中并没有显示出来。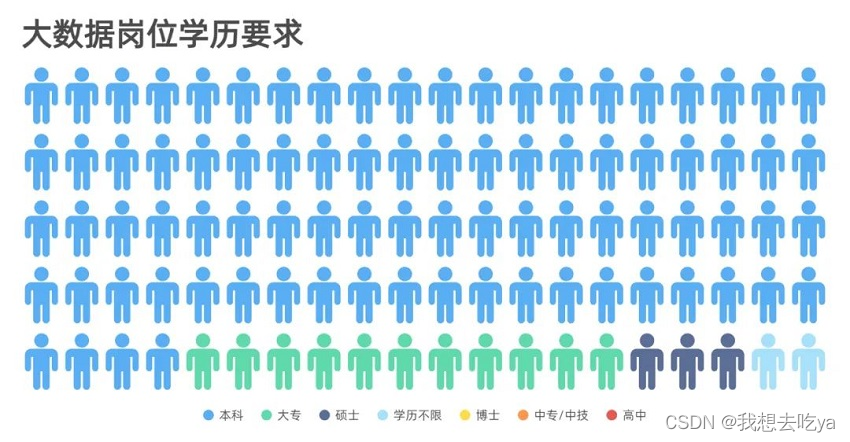
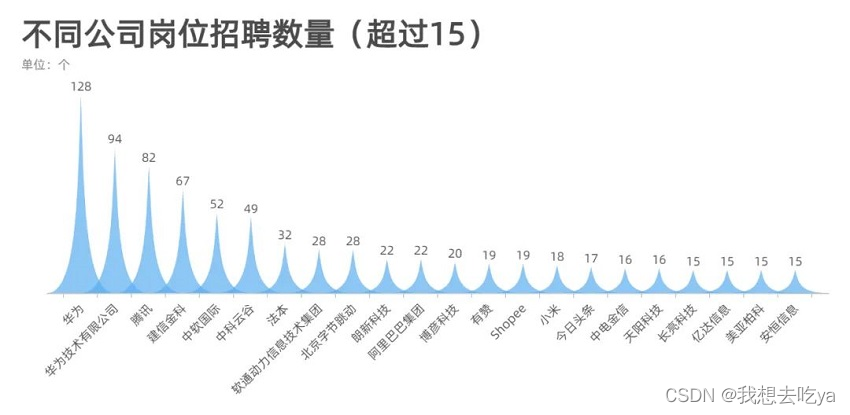
企业对不同岗位的要求以3-5年的居多,企业当然是需要有一定工作经验的员工,但是在实际招聘中,如果你有项目经验,且理论知识没问题,企业也会放宽条件。
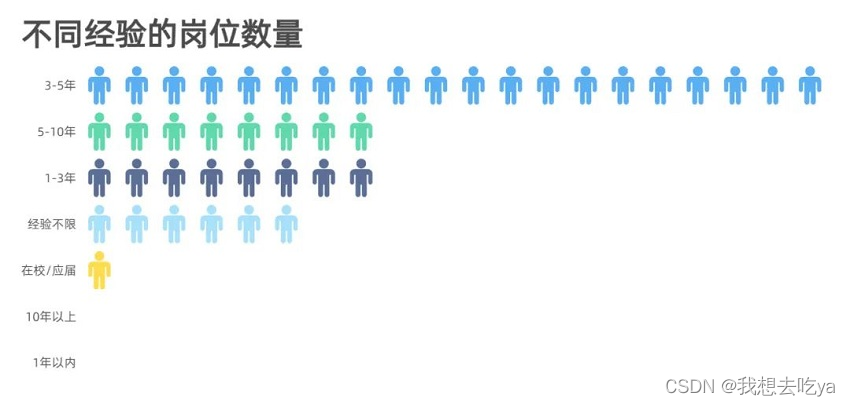
分析不同行业, 我们发现,大数据岗位需求分布在各行各业,主要还是在计算机软件和互联网最多,也有可能是这个招聘软件决定的,毕竟Boss直聘还是以互联网行业为主。
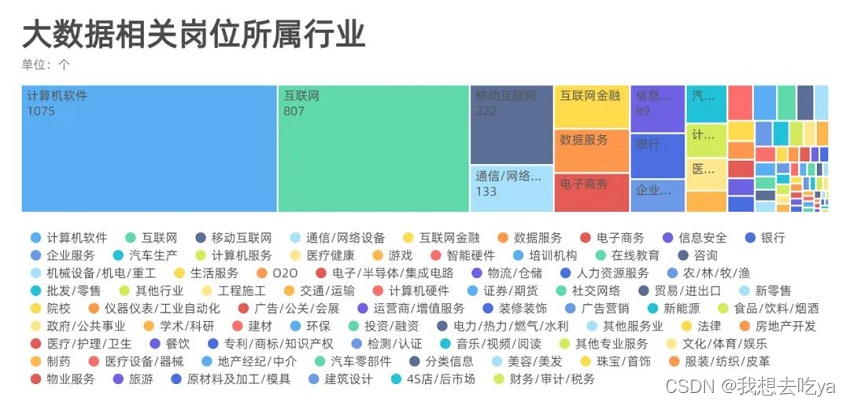
来看看哪些公司在招聘大数据相关岗位,从这个超过15的数量来看,华为,腾讯,阿里,字节,这些大厂对这个岗位的需求量还是很大的。
那么这些岗位都需要什么技能呢?Spark,Hadoop,数据仓库,Python,SQL,Mapreduce,Hbase等等

根据国内的发展形势,大数据未来的发展前景会非常好。自 2018 年企业纷纷开始数字化转型,一二线城市对大数据领域的人才需求非常强烈,未来几年,三四线城市的人才需求也会大增。
在大数据领域,国内发展的比较晚,从 2016 年开始,仅有 200 多所大学开设了大数据相关的专业,也就是说 2020 年第一批毕业生才刚刚步入社会,我国市场环境处于急需大数据人才但人才不足的阶段,所以未来大数据领域会有很多的就业机遇。
薪资高、缺口大,自然成为职场人的“薪”选择!
任何学习过程都需要一个科学合理的学习路线,才能够有条不紊的完成我们的学习目标。Python+大数据所需学习的内容纷繁复杂,难度较大,为大家整理了一个全面的Python+大数据学习路线图,帮大家理清思路,攻破难关!
Python+大数据学习路线图详细介绍
学前导读:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。
1.大数据数据开发基础MySQL8.0从入门到精通
MySQL是整个IT基础课程,SQL贯穿整个IT人生,俗话说,SQL写的好,工作随便找。本课程从零到高阶全面讲解MySQL8.0,学习本课程之后可以具备基本开发所需的SQL水平。
2022最新MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程
学前导读:学习Linux、Hadoop、Hive,掌握大数据基础技术。
2022版大数据Hadoop入门教程
Hadoop离线是大数据生态圈的核心与基石,是整个大数据开发的入门,是为后期的Spark、Flink打下坚实基础的课程。掌握课程三部分内容:Linux、Hadoop、Hive,就可以独立的基于数据仓库实现离线数据分析的可视化报表开发。
2022最新大数据Hadoop入门视频教程,最适合零基础自学的大数据Hadoop教程
学前导读:本阶段课程以真实项目为驱动,学习离线数仓技术。
数据离线数据仓库,企业级在线教育项目实战(Hive数仓项目完整流程)
本课程会、建立集团数据仓库,统一集团数据中心,把分散的业务数据集中存储和处理 ;目从需求调研、设计、版本控制、研发、测试到落地上线,涵盖了项目的完整工序 ;掘分析海量用户行为数据,定制多维数据集合,形成数据集市,供各个场景主题使用。
大数据项目实战教程_大数据企业级离线数据仓库,在线教育项目实战(Hive数仓项目完整流程)
学前导读:Spark官方已经在自己首页中将Python作为第一语言,在3.2版本的更新中,高亮提示内置捆绑Pandas;课程完全顺应技术社区和招聘岗位需求的趋势,全网首家加入Python on Spark的内容。
1.python入门到精通(19天全)
python基础学习课程,从搭建环境。判断语句,再到基础的数据类型,之后对函数进行学习掌握,熟悉文件操作,初步构建面向对象的编程思想,最后以一个案例带领同学进入python的编程殿堂。
全套Python教程_Python基础入门视频教程,零基础小白自学Python必备教程
2.python编程进阶从零到搭建网站
学完本课程会掌握Python高级语法、多任务编程以及网络编程。
Python高级语法进阶教程_python多任务及网络编程,从零搭建网站全套教程
3.spark3.2从基础到精通
Spark是大数据体系的明星产品,是一款高性能的分布式内存迭代计算框架,可以处理海量规模的数据。本课程基于Python语言学习Spark3.2开发,课程的讲解注重理论联系实际,高效快捷,深入浅出,让初学者也能快速掌握。让有经验的工程师也能有所收获。
Spark全套视频教程,大数据spark3.2从基础到精通,全网首套基于Python语言的spark教程
4.大数据Hive+Spark离线数仓工业项目实战
通过大数据技术架构,解决工业物联网制造行业的数据存储和分析、可视化、个性化推荐问题。一站制造项目主要基于Hive数仓分层来存储各个业务指标数据,基于sparkSQL做数据分析。核心业务涉及运营商、呼叫中心、工单、油站、仓储物料。
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
使用Ruby1.9.2运行IDE提示说需要gemruby-debug-base19x并提供安装它。但是,在尝试安装它时会显示消息Failedtoinstallgems.Followinggemswerenotinstalled:C:/ProgramFiles(x86)/JetBrains/RubyMine3.2.4/rb/gems/ruby-debug-base19x-0.11.30.pre2.gem:Errorinstallingruby-debug-base19x-0.11.30.pre2.gem:The'linecache19'nativegemrequiresinstall
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_