文章目录
数据类型转换在实际应用中非常常见。GaussDB作为一款企业级分布式关系型数据库,在实际业务场景使用中,也会避免不了数据类型的转换。以下是一些数据类型转换的应用场景:
数据清洗与转换:在数据分析和处理中,经常需要对数据进行清洗和转换,例如将文本数据转换为数字格式,将日期格式转换为文本格式等。
数据格式化:在输出数据时,需要将数据格式化为合适的格式,例如将数字格式化为货币格式、百分比格式等。
数据计算:在进行数据计算时,需要对数据类型进行转换,例如将整数类型的数据转换为浮点数类型的数据,以便进行精确的计算或处理。
数据存储:在将数据存储到数据库中时,需要将不同类型的数据转换为数据库支持的数据类型,以便正确地存储和查询数据。
数据传输:在数据传输过程中,需要将不同类型的数据转换为相同的数据类型,以便正确地传输数据。
总之,数据类型转换在数据处理、数据分析、数据存储和数据传输等领域都有广泛的应用。
在SQL语言中,每个数据都与一个决定其行为和用法的数据类型相关。GaussDB提供一个可扩展的数据类型系统,该系统比其它SQL实现更具通用性和灵活性。因而,GaussDB中大多数类型转换是由通用规则来管理的。
数据库中允许有些数据类型进行隐式类型转换(赋值、函数调用的参数等),有些数据类型间不允许进行隐式数据类型转换,可尝试使用GaussDB提供的类型转换函数。
描述:CAST进行数据类型强转。如果有必要,可以将值显式转换为指定类型。
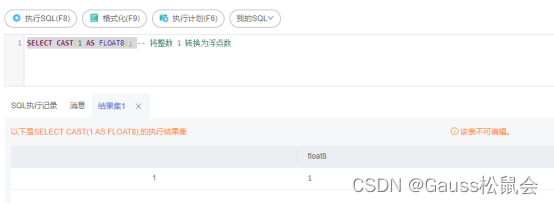
1)整型转浮点型
SELECT CAST(1 AS FLOAT8); – 将整数 1 转换为浮点数
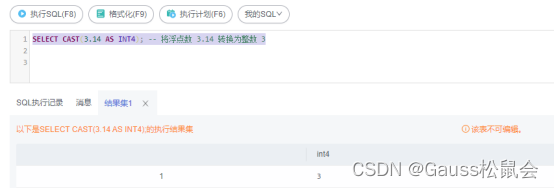
2)浮点型转整型
SELECT CAST(3.14 AS INT4); – 将浮点数 3.14 转换为整数 3
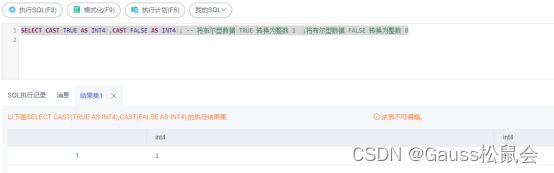
3)布尔型转整型
使用 CAST 函数将布尔型数据转换为整型数据,其中 TRUE 转换为 1,FALSE 转换为 0,例如:
SELECT CAST(TRUE AS INT4),CAST(FALSE AS INT4); – 将布尔型数据 TRUE 转换为整数 1;将布尔型数据 FALSE 转换为整数 0
描述:将文本类型的值转换为指定格式的时间戳。
格式一:无分隔符日期,如20230314,需要包括完整的年月日。
格式二:带分隔符日期,如2023-03-14,分隔符可以是单个任意非数字字符。
SELECT TO_DATE(‘20230314’),TO_DATE(‘2023-03-14’);
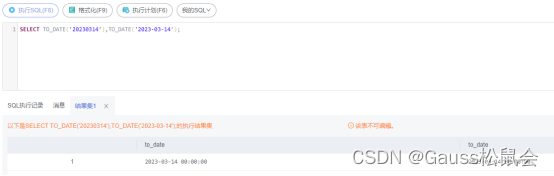
描述:将字符串类型的值转换为指定格式的日期。
SELECT TO_DATE(‘14 MAR 2023’, ‘DD MON YYYY’),TO_DATE(‘20230314’,‘YYYYMMDD’);
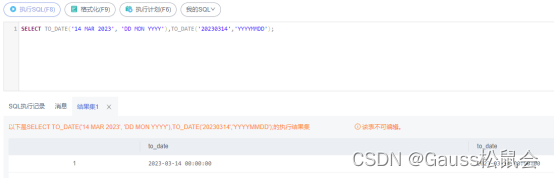
描述:日期时间型转字符型。
SELECT TO_CHAR(NOW(), ‘YYYY-MM-DD HH24:MI:SS’); – 将当前日期时间型数据转换为字符型数据,格式为 ‘YYYY-MM-DD HH24:MI:SS’
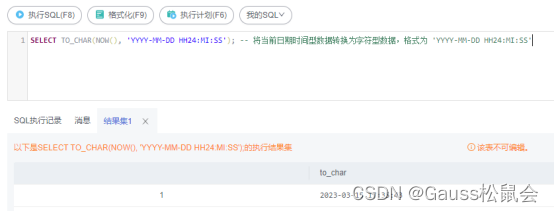
描述:将CHAR、VARCHAR、VARCHAR2、CLOB类型转换为VARCHAR类型。
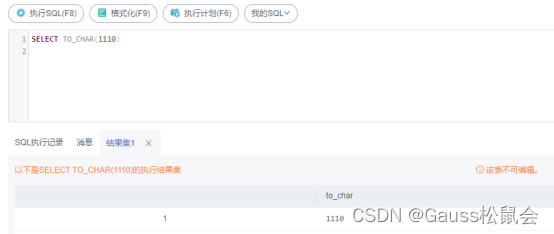
SELECT TO_CHAR(1110)
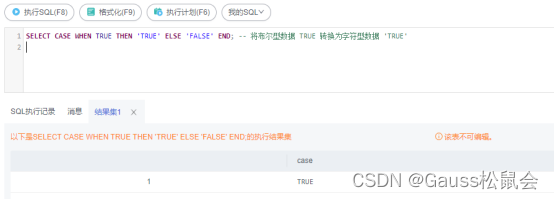
布尔型转字符型,使用 CASE 表达式将布尔型数据转换为字符型数据,例如:
1)SELECT CASE WHEN TRUE THEN ‘TRUE’ ELSE ‘FALSE’ END; – 将布尔型数据 TRUE 转换为字符型数据 ‘TRUE’
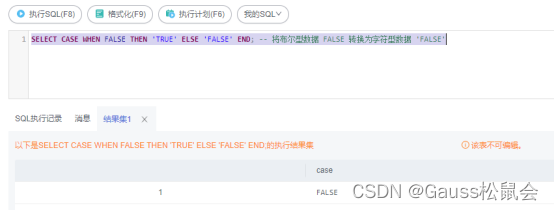
2)SELECT CASE WHEN FALSE THEN ‘TRUE’ ELSE ‘FALSE’ END; – 将布尔型数据 FALSE 转换为字符型数据 ‘FALSE’
数据类型转换是将一种数据类型转换为另一种数据类型的过程。在中,我们经常需要对数据类型进行转换以满足代码的需求。 在很多编程语言中,数据类型转换可以分为隐式转换和显式转换两种类型。 隐式转换是指在代码中进行赋值、运算或比较等操作时,编程语言会自动对数据类型进行转换,以保证操作的正确性和合法性。
GaussDB支持多种数据类型转换,以下是GaussDB中常用的数据类型转换方式:
隐式转换:GaussDB支持隐式转换,即在表达式中,如果不同数据类型的操作数参与运算,GaussDB会自动将其中一个数据类型转换为另一个数据类型,以满足运算要求。例如,如果一个整型数值与一个浮点型数值进行运算,GaussDB会将整数转换为浮点数再进行运算。
显式转换:GaussDB中支持使用CAST函数进行显式转换。CAST函数可将一个数据类型的值转换为另一个数据类型的值。例如,使用CAST函数将一个字符串类型转换为整型类型。
-数字转换:GaussDB支持将数字类型转换为其他数字类型,例如将整型转换为小数型、将小数型转换为整型等。
需要注意的是,在进行数据类型转换时,应该考虑出现的数据精度、数据溢出、数据失真等问题,同时也要避免数据类型不兼容造成的错误。当然了,数据类型转换也会影响查询效率和性能,需要根据实际业务需求和数据量大小进行优化和调整。
以上示例到此结束,更多类型转换可参考官网文档,欢迎大家测试、交流。
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
这道题是thisquestion的逆题.给定一个散列,每个键都有一个数组,例如{[:a,:b,:c]=>1,[:a,:b,:d]=>2,[:a,:e]=>3,[:f]=>4,}将其转换为嵌套哈希的最佳方法是什么{:a=>{:b=>{:c=>1,:d=>2},:e=>3,},:f=>4,} 最佳答案 这是一个迭代的解决方案,递归的解决方案留给读者作为练习:defconvert(h={})ret={}h.eachdo|k,v|node=retk[0..-2].each{|x|node[x]||={};node=node[x]}node[
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s