🎇C++学习历程:入门
- 博客主页:一起去看日落吗
- 持续分享博主的C++学习历程
博主的能力有限,出现错误希望大家不吝赐教- 分享给大家一句我很喜欢的话: 也许你现在做的事情,暂时看不到成果,但不要忘记,树🌿成长之前也要扎根,也要在漫长的时光🌞中沉淀养分。静下来想一想,哪有这么多的天赋异禀,那些让你羡慕的优秀的人也都曾默默地翻山越岭🐾。
🍁 🍃 🍂 🌿
目录
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到
l
o
g
2
N
log_2 N
log2N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同,本文中只对unordered_map和unordered_set进行介绍,
unordered_multimap和unordered_multiset学生可查看文档介绍。
map和set底层是红黑树实现的,map是KV模型,set是K模型,而unordered_map和unordered_set底层是哈希表实现的,unordered_set是K模型,unordered_map是KV模型

unordered_map和unordered_set的命名体现特点,在功能和map/set是一样的,区别在于,它遍历出来是无序的,另外,它们的迭代器是单向迭代器
| 函数声明 | 功能介绍 |
|---|---|
| unordered_map | 构造不同格式的unordered_map对象 |
| 函数声明 | 功能介绍 |
|---|---|
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
| 函数声明 | 功能介绍 |
|---|---|
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
| 函数声明 | 功能介绍 |
|---|---|
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说明key已经在哈希桶中,将key对应的value返回。
| 函数声明 | 功能介绍 |
|---|---|
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K& key) | 返回哈希桶中关键码为key的键值对的个数 |
注意:unordered_map中key是不能重复的,因此count函数的返回值最大为1
| 函数声明 | 功能介绍 |
|---|---|
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器中的元素 |
| 函数声明 | 功能介绍 |
|---|---|
| size_t bucket_count()const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n)const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
#include<iostream>
#include<unordered_set>
#include<unordered_map>
using namespace std;
void test_unordered_set()
{
unordered_set<int> s;
s.insert(3);
s.insert(4);
s.insert(5);
s.insert(3);
s.insert(1);
s.insert(2);
s.insert(6);
unordered_set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
}
int main()
{
test_unordered_set();
return 0;
}
可以看到它遍历出来是无序的,并且相同的数只会插入一次
#include<iostream>
#include<unordered_map>
using namespace std;
void test_unordered_map()
{
unordered_map<string, string> dict;
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("sort", "排序"));
dict.insert(make_pair("string", "字符串"));
dict.insert(make_pair("string", "字符串"));
auto it = dict.begin();
while (it != dict.end())
{
cout << it->first << ":" << it->second << endl;
it++;
}
}
int main()
{
test_unordered_map();
return 0;
}
它遍历出来也是无序的,并且相同的数只会插入一次

class Solution {
public:
int repeatedNTimes(vector<int>& nums) {
size_t N = nums.size() / 2;
unordered_map<int,int> m;
for(auto e : nums)
m[e]++;
for(auto &e : m)
{
if(e.second == N)
return e.first;
}
return 0;
}
};

class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
// 用unordered_set对nums1中的元素去重
unordered_set<int> s1;
for (auto e : nums1)
s1.insert(e);
// 用unordered_set对nums2中的元素去重
unordered_set<int> s2;
for (auto e : nums2)
s2.insert(e);
// 遍历s1,如果s1中某个元素在s2中出现过,即为交集
vector<int> vRet;
for (auto e : s1)
{
if (s2.find(e) != s2.end())
vRet.push_back(e);
}
return vRet;
}
};

class Solution {
public:
vector<int> intersect(vector<int>& nums1, vector<int>& nums2) {
if (nums1.size() > nums2.size()) {
return intersect(nums2, nums1);
}
unordered_map <int, int> m;
for (int num : nums1) {
++m[num];
}
vector<int> intersection;
for (int num : nums2) {
if (m.count(num)) {
intersection.push_back(num);
--m[num];
if (m[num] == 0) {
m.erase(num);
}
}
}
return intersection;
}
};

class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_set<int> s;
for (int x: nums) {
if (s.find(x) != s.end()) {
return true;
}
s.insert(x);
}
return false;
}
};

class Solution {
public:
vector<string> uncommonFromSentences(string s1, string s2) {
unordered_map<string, int> freq;
auto insert = [&](const string& s) {
stringstream ss(s);
string word;
while (ss >> word) {
++freq[move(word)];
}
};
insert(s1);
insert(s2);
vector<string> ans;
for (const auto& [word, occ]: freq) {
if (occ == 1) {
ans.push_back(word);
}
}
return ans;
}
};
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( l o g 2 N log_2 N log2N),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素。
当向该结构中:
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者称散列表)
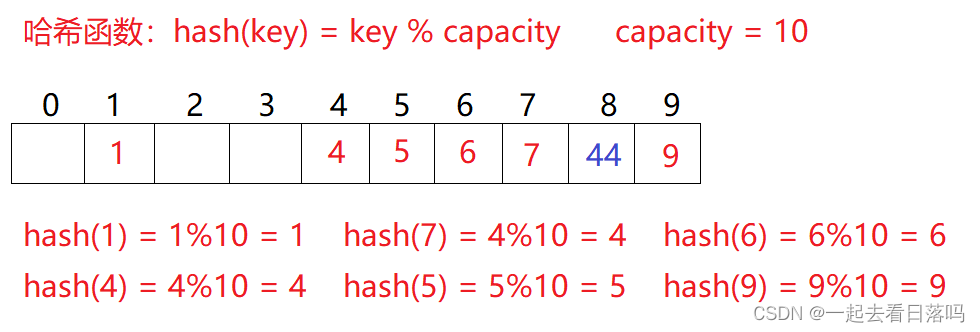
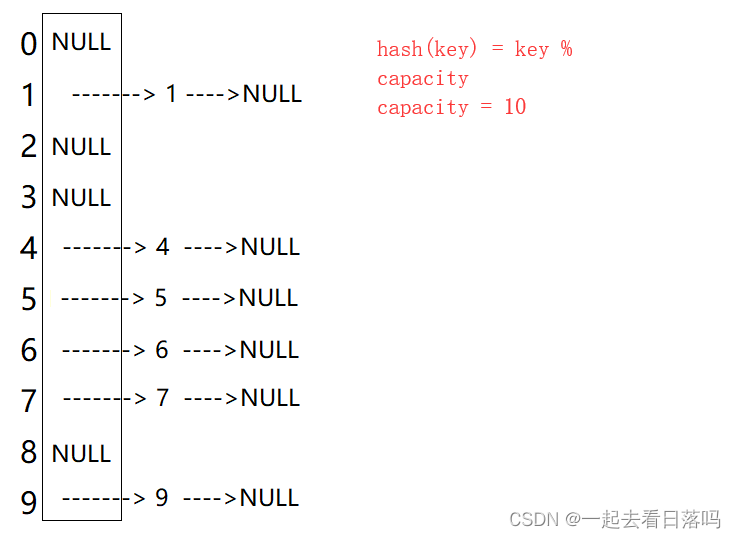
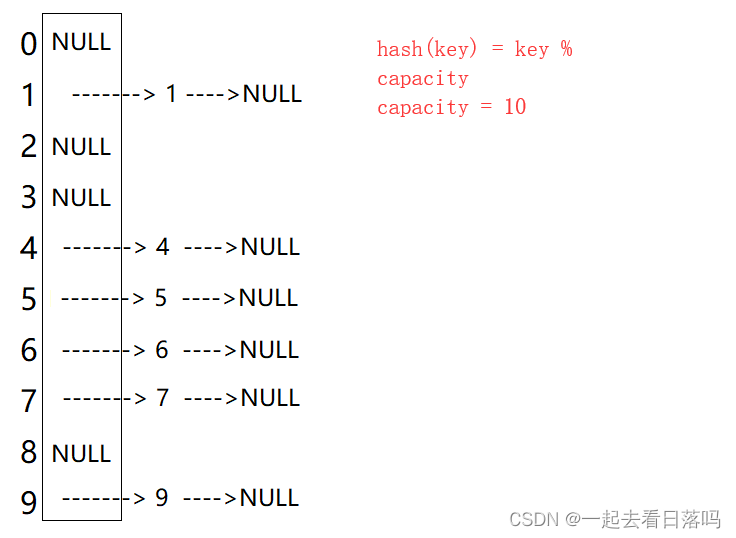
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小。
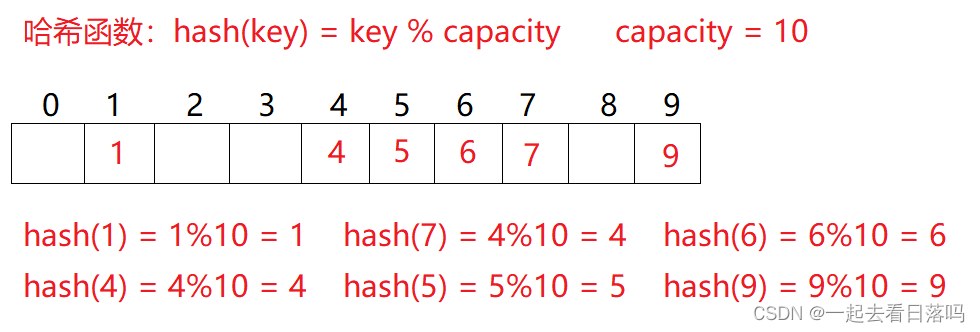
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
问题:按照上述哈希方式,向集合中插入元素44,会出现什么问题?
发现4这个位置已经被占用了
对于两个数据元素的关键字 k i k_i ki和 k j k_j kj(i != j),有 k i k_i ki != k j k_j kj,但有:Hash( k i k_i ki) == Hash( k j k_j kj),
即:不同关键字通过相同哈希哈数计算出相同的哈希地址,该种现象称为哈希冲突
或哈希碰撞。
把具有不同关键码而具有相同哈希地址的数据元素称为“同义词”。
发生哈希冲突该如何处理呢?
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。
哈希函数设计原则:
常见哈希函数:
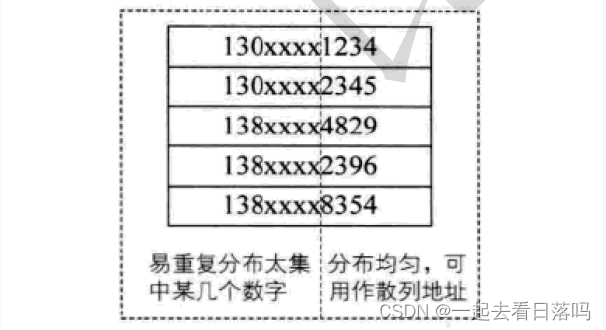 假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现 冲突,还可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移位、前两数与后两数叠加(如1234改成12+34=46)等方法。
假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现 冲突,还可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移位、前两数与后两数叠加(如1234改成12+34=46)等方法。注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
解决哈希冲突两种常见的方法是:闭散列和开散列
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?
因此:比散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
#pargma once
namespace close_hash
{
enum Status
{
EMPTY,//空
EXIST,//存在
DELETE//删除
};
template<class K,class V>
struct HashData
{
pair<K,V> _kv;
Status _status = EMPTY; //状态
};
template<class K>
struct HashFunc
{
size_t operator()(const K&key)
{
return key;
}
};
//特化
template<>
struct HashFunc<string>
{
size_t operator()(const string& key)
{
//BKDR Hash思想
size_t hash = 0;
for(size_t i = 0;i<key.size();++i)
{
hash*=131;
hash += key[i];//转成整形
}
return hash;
}
};
template<class K,class V,class Hash = HashFunc<K>>
class HashTable
{
public:
bool Erase(const K& key)
{
HashData<K,V>* ret = Find(key);
if(ret == nullptr)
{
//没有这个值
return false;
}
else
{
//伪删除
ret->_status = DELETE;
_n--;
return true;
}
}
HashData<K,V>* Find(const K& key)
{
if(_table.size() == 0)
{
//防止除0错误
return nullptr;
}
Hash hf;
size_t index = hf(key) % _table.size();
size_t i = 0;
size_t index = start + i;
while(_tables[index]._status != EMPTY)
{
if(_tabled[index]._kv.first == key && _table[index]._status == EXIST)
{
return &_tabled[index];
}
else
{
++i;
//index = start+i;//线性探测
index = start+i*i;//二次探测
index %= _tables.size();
}
}
return nullptr;
}
//插入
bool Insert(const pair<K,V>& kv)
{
if(Find(kv.first))
{
return false;
}
if(_table.size() == 0 || (double)(_n / _table.size()) > 0.7)
{
//扩容
//方法二:
size_t newSize = _table.size()==0? 10 : _table.size()*2;
HashTable<K,V> newHT;//建立一个临时新表
newHT._tables.resize(newSize);//给新表开扩容后的空间
for(auto& e:_tables)
{
if(e._status == EXIST)
{
newHT.Insert(e._kv);//将旧表的数据插入新表
}
}
_table.swap(newHT._tables);//将新表和旧表交换
}
Hash hf;
size_t start = hf(kv.first) % _tables.size();
//线性探测
size_t i = 0;
size_t index = start + i;
while(_table[index]._status == EXIST)
{
++index;
if(index == _tables.size())
{
//当index到达最后的时候,让它回到起始
index = 0;
}
//插满的时候会死循环
}
//走到这里要么是空要么是删除
_tables[index]._kv = kv;
_tables[index]._status = EXIST;
++_n;
return true;
}
private:
vector<HashData<K,V>> _tables;//vector来存储HashData
size_t _n = 0;//存储有效数据的个数
}
}
namespace bucket_hash
{
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K, V>& kv)
:_kv(kv)
, _next(nullptr)
{}
};
size_t GetNextPrime(size_t prime)
{
const int PRIMECOUNT = 28;
static const size_t primeList[PRIMECOUNT] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
size_t i = 0;
for (; i < PRIMECOUNT; ++i)
{
if (primeList[i] > prime)
return primeList[i];
}
return primeList[i];
}
template<class K, class V, class Hash = HashFunc<K>>
class HashTable
{
typedef HashNode<K, V> Node;
public:
// 拷贝 和 赋值 需要自己实现桶的拷贝
~HashTable()
{
for (size_t i = 0; i < _tables.size(); i++)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_tables[i] = nullptr;
}
_n = 0;
}
bool Erase(const K& key)
{
if (_tables.size() == 0)
{
return false;
}
Hash hf;
// 素数
size_t index = hf(key) % _tables.size();
Node* prev = nullptr;
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == key)
{
// 1、cur是头结点
// 2、非头节点
if (prev == nullptr)
{
_tables[index] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
--_n;
return true;
}
else
{
prev = cur;
cur = cur->_next;
}
}
return false;
}
Node* Find(const K& key)
{
if (_tables.size() == 0)
{
return nullptr;
}
Hash hf;
size_t index = hf(key) % _tables.size();
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == key)
{
return cur;
}
else
{
cur = cur->_next;
}
}
return nullptr;
}
bool Insert(const pair<K, V>& kv)
{
Hash hf;
//当负载因子到1时,进行扩容
if (_n == _tables.size())
{
//size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;
size_t newSize = GetNextPrime(_tables.size());
//HashTable<K, V> newHT;
vector<Node*> newtables;
newtables.resize(newSize, nullptr);
for (size_t i = 0; i < _tables.size(); ++i)
{
Node* cur = _tables[i];
while (cur)
{
Node* next = cur->_next;
size_t index = hf(cur->_kv.first) % newSize;
cur->_next = newtables[index];
newtables[index] = cur;
cur = next;
}
_tables[i] = nullptr;
}
newtables.swap(_tables);
}
size_t index = hf(kv.first) % _tables.size();
Node* cur = _tables[index];
while (cur)
{
if (cur->_kv.first == kv.first)
{
return false;
}
else
{
cur = cur->_next;
}
}
Node* newnode = new Node(kv);
newnode->_next = _tables[index];
_tables[index] = newnode;
++_n;
return true;
}
private:
vector<Node*> _tables;
size_t _n = 0; // 存储多少有效数据
};
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
