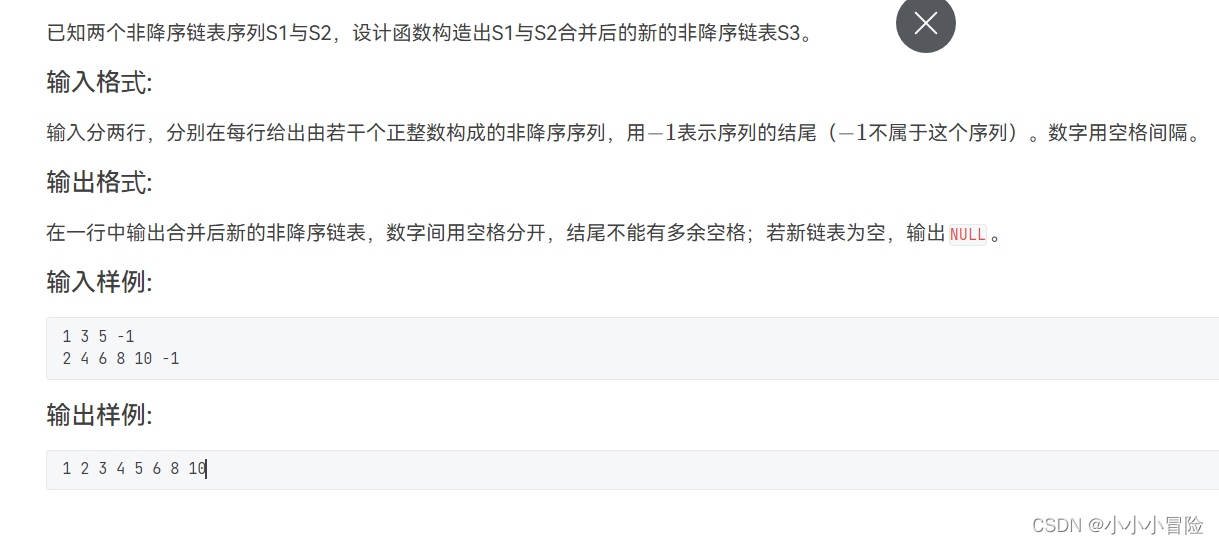
(最下边有完整代码及运行截图,中间部分仅提供思路,有残缺)
具体问题如下图所示
简单说一下思路
首先是常规定义一下单链表
#include <stdio.h>
#include <stdlib.h>
typedef struct Node
{
int data;
struct Node* next;
}Node;
然后是将输入的数列存入链表中
创建一个head节点,head的指针域设为NULL,并用L指针指向head。
建立一个循环:在循环内接收输入的序列值(假设为) [ 1 2 3 4 5 -1] (用空格隔开),第一次循环,新建一个节点Node,并让L->next(此时L代表head)指向该新建节点Node,形成链表,其中Node数据域data存入1。按此操作依次进行,直到序列值-1
序列值=-1时,L指向的节点的指针域指向NULL,完成单链表
Node* PutL()
{
Node head;
Node* L= &head;
head.next = NULL;
int n;
while (1)
{
scanf("%d", &n);
if (n != -1)
{
L->next = (Node*)malloc(sizeof(Node));
L->next->data = n;
L = L->next;
}
else
break;
}
L->next = NULL;
return head.next;
}然后就是最重要的合并功能
要合并单链表L1和单链表L2,我们首先定义一个空的链表L3
然后我们考虑如何将L1和L2的值如何放进L3
合并时要有这个思路
1.假设输入两个有序数列

2.再加上对应指针,首先指向对应序列的头一个节点

3.开始比较对应的值,输出较小的那一个(按题目要求

4.N1输出,将N1指向下一位,L3第一个节点data域等于1
接着比较N1,N2


5.N2输出后,将N2指向下一位,L3第二个节点data域等于2
接着比较N1,N2

如此循环下去
若L1与L2长度不等时

易知L2肯定先输出完,即N2最先指向链表尾部,此时N1指向7,则将N1指向的节点包括后面的全部连接到L3即可
完整代码如下:
#include <stdio.h>
#include <stdlib.h>
typedef struct Node
{
int data;
struct Node* next;
}Node;
Node* PutL()
{
Node head;
Node* L= &head;
head.next = NULL;
int n;
while (1)
{
scanf("%d", &n);
if (n != -1)
{
L->next = (Node*)malloc(sizeof(Node));
L->next->data = n;
L = L->next;
}
else
break;
}
L->next = NULL;
return head.next;
}
int main()
{
Node* L1 = PutL();
Node* L2 = PutL();
int f=0;//处理空格
while (L1&&L2)//两个链表都非空
{
if (L1->data > L2->data)//判断首源节点的data的大小
{
if (f)
printf(" ");//当f=0时,进入else;f=1时输出空格
else
f = 1;
printf( "%d",L2->data);
L2 = L2->next;
}
else
{
if (f)
printf(" ");
else
f = 1;
printf("%d",L1->data);
L1 = L1->next;
}
}
while (L1)//当L1有剩余时
{
if (f)
printf(" ");
else
f = 1;
printf("%d",L1->data);
L1 = L1->next;
}
while (L2)//当L2有剩余时
{
if (f)
printf(" ");
else
f = 1;
printf("%d",L2->data);
L2 = L2->next;
}
if (f == 0)
printf("NULL");//当f=0时,就证明没有进入任何一个循环,即新链表为空
return 0;
}
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我正在阅读一本关于Ruby的书,作者在编写类初始化定义时使用的形式与他在本书前几节中使用的形式略有不同。它看起来像这样:classTicketattr_accessor:venue,:datedefinitialize(venue,date)self.venue=venueself.date=dateendend在本书的前几节中,它的定义如下:classTicketattr_accessor:venue,:datedefinitialize(venue,date)@venue=venue@date=dateendend在第一个示例中使用setter方法与在第二个示例中使用实例变量之间是
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
我从用户Hirolau那里找到了这段代码:defsum_to_n?(a,n)a.combination(2).find{|x,y|x+y==n}enda=[1,2,3,4,5]sum_to_n?(a,9)#=>[4,5]sum_to_n?(a,11)#=>nil我如何知道何时可以将两个参数发送到预定义方法(如find)?我不清楚,因为有时它不起作用。这是重新定义的东西吗? 最佳答案 如果您查看Enumerable#find的文档,您会发现它只接受一个block参数。您可以将它发送两次的原因是因为Ruby可以方便地让您根据它的“并行赋
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
假设我必须(小型到中型)阵列:tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]如何确定tokens是否以相同的顺序包含template的所有条目?(请注意,在上面的示例中,应忽略第一个“ccc”,从而由于最后一个“ccc”而导致匹配。) 最佳答案 这适用于您的示例数据。tokens=["aaa","ccc","xxx","bbb","ccc","yyy","zzz"]template=["aaa","bbb","ccc"]po
首先,我使用的是rails3.1.3和来自master的carrierwavegithub仓库的分支。我使用after_init钩子(Hook)来确定基于属性的字段页面模型实例并为这些字段定义属性访问器将值存储在序列化哈希中(希望它清楚我是什么谈论)。这是我正在做的事情的精简版:classPage省略mount_uploader命令让我可以访问我想要的属性。但是当我安装uploader时出现错误消息说“nil类的未定义新方法”我在源代码中读到有方法read_uploader和扩展模块中的write_uploader。我如何必须覆盖这些来制作mount_uploader命令使用我的“虚拟
我已经有很多两个值数组,例如下面的例子ary=[[1,2],[2,3],[1,3],[4,5],[5,6],[4,7],[7,8],[4,8]]我想把它们分组到[1,2,3],[4,5],[5,6],[4,7,8]因为意思是1和2有关系,2和3有关系,1和3有关系,所以1,2,3都有关系我如何通过ruby库或任何算法来做到这一点? 最佳答案 这是基本Bron–Kerboschalgorithm的Ruby实现:classGraphdefinitialize(edges)@edges=edgesenddeffind_maximum_