Flink提交任务的方式有两种,第一种是自带的UI页面,但是这种提交方式很少有团队正式使用,因为这种方式的资源分配是按照task为单位,设置任务并行度的,而不是可以灵活的根据提交任务时的参数来改变所占资源大小的continer,一个task拥有多少计算资源已经在配置文件中写死了,且使用时一个并行度就代表占用一个task,它的好处就在于你能够明确的把控资源的使用频率,缺点就是不够灵活。
自己手搭过原生的或者其他发行版的yarn服务的朋友,就会明白yarn体系中资源的在使用频率是根据调度队列判断当前所有任务的Applicationmanage占总资源大小的一个百分比掌控的,默认是0.1也就是10%,另外90%用来运行具体任务,但是这90%的资源是否被充分利用或者是否被过度利用,这都说不准。而flink的task方式就用一种强硬的方式限制了被使用时的task,其他任务不能使用,反之只要存在空余task,就可以提交任务。
国内九成九的都是普通公司,不是大厂,根本原因是用不起Flink的第一种方式,做不到财大气粗的堆资源,只能那种最经济的用法,这也是flink很少在国内使用的原因之一。第二种提交方式就是命令行模式,这种方式下就和UI提交是同源的,也可以提交给yarn。说白了就算国内的公司跳不开必须使用flink时,也只是提交给了yarn,很少有公司有那个经济实力,直接把任务交给flink自身的jobmanager。一般测试环境为了方便才可能用ui页面提交。
UI页面你需要浏览器访问flink的jobmanager节点,默认端口号是8081
点击左侧导航栏最后一项
点击add new,会弹出文件框,你要选择你的jar包上传
上传后点击后边的Upload,在进度条完成后就会生成任务
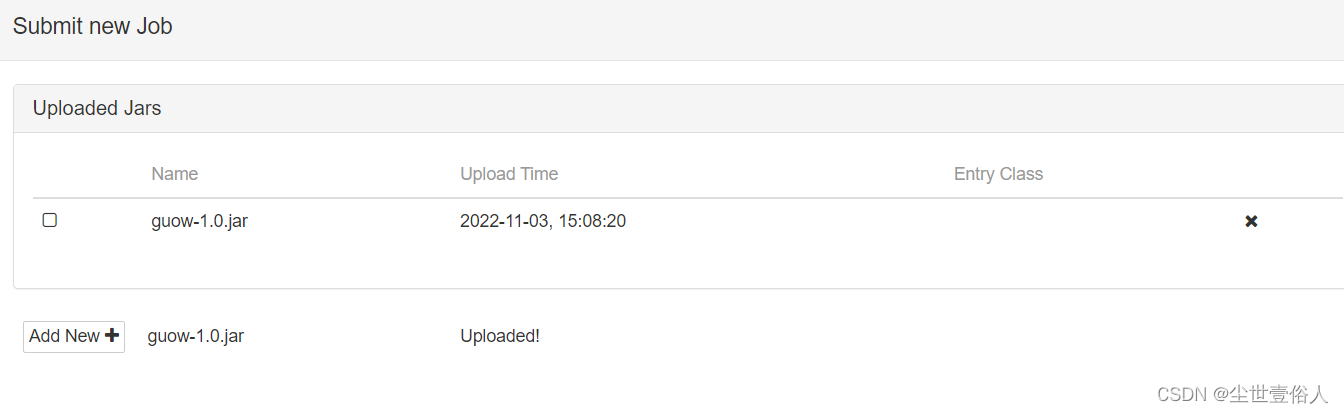
选择任务前面的复选框,点击后会弹出基本配置内容,分别是运行的类的包路径、并行度、参数,以及最后一个SavePath一般不用,它的作用和Spark的Checkpoint一样,都是设置一个检查点。
区别在于checkpoint是增量做的,每次的时间短,数据量小,只要在程序里面启用后会自动触发,用户无需感知;savepoint是全量做的,时间长,数据量大,需要用户主动触发。
checkpoint 是任务结束的时候自动使用,不需要用户指定,savepoint 一般用于程序版本更新、bug修复、A/B Test 等场景,需要用户指定。
需要特别注意的是并行度,最大不能超过Overview页面中显示的Available Task Slots可用数,而且并行度的生效权重遵循页面权重<代码中StreamExecutionEnvironment权重<算子权重
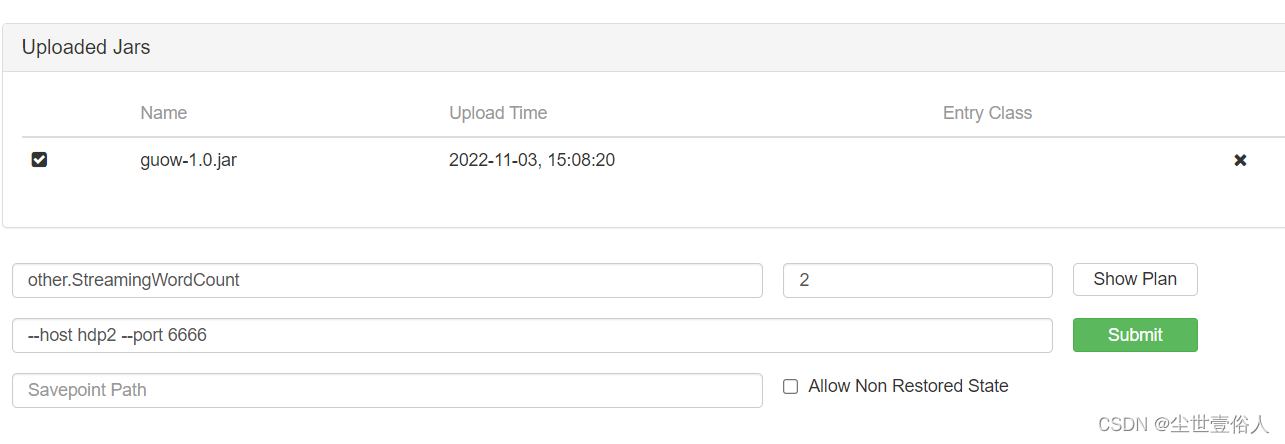
设置好这些就可以点击Submit提交了,然后就会跳转到任务的监控页面,你可以在这个页面中看到每一个详情算子的状态,以及整个任务的相关信息
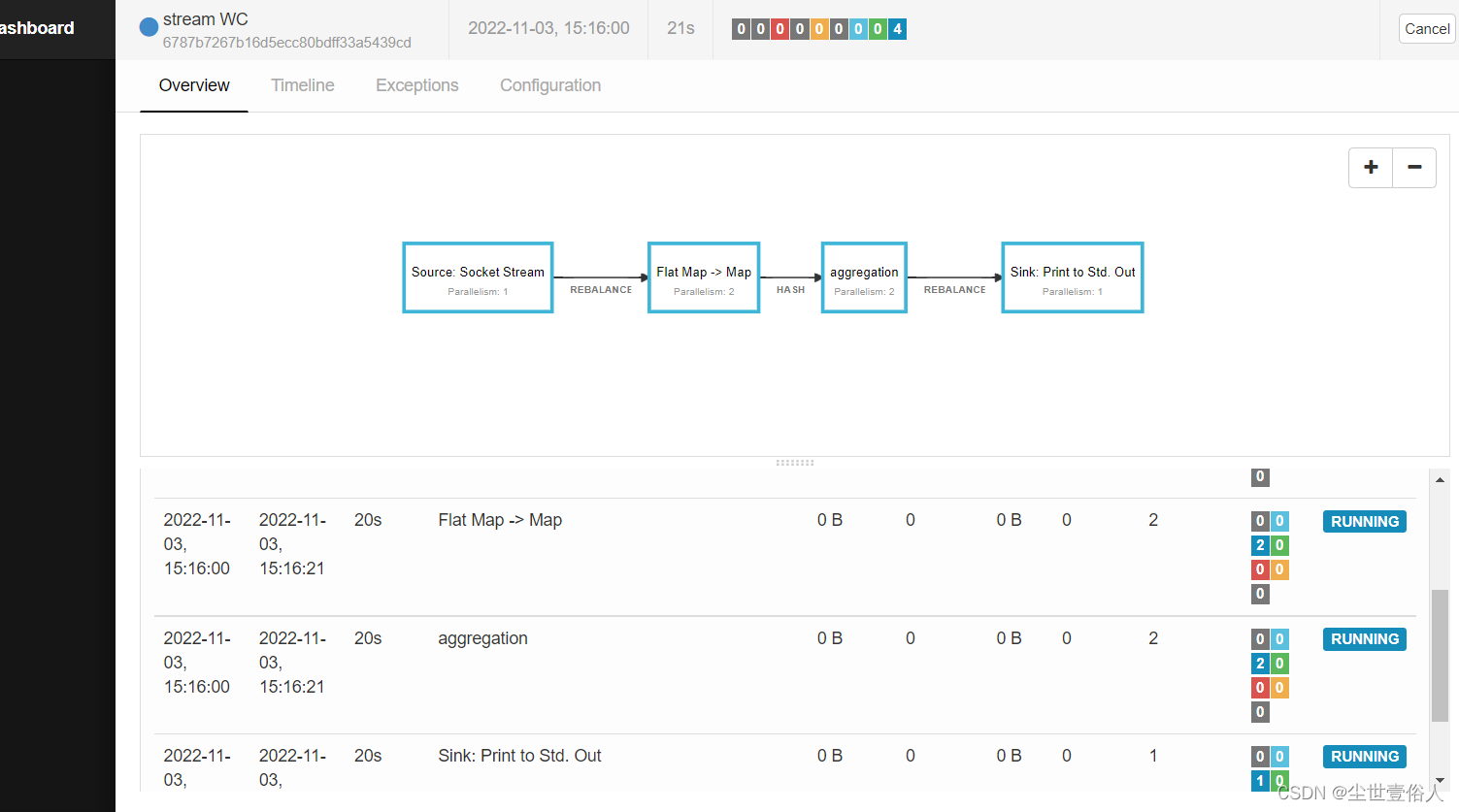
你要关注的重点是下面算子列表的状态,确保正常运行,此时你就可以不用管了,在,Running Jobs中可以看到这个任务,如果你想结束就进入任务详情,点击右上角的Cancel
命令行模式下就是使用${FLINK_HOME}/bin下的flink命令提交任务,和前面说的一样在使用flink的jobmanager下和页面操作没差别。命令使用方法如下
flink命令执行模板:flink run [option]
-c,--class : 执行的类路径
-C,--classpath : 向每个用户代码添加url,通过UrlClassLoader加载。url需要指定文件的schema如(file://)
-d,–-detached : 在后台运行
-p,–-parallelism : job需要的并行度,这个一般都需要设置。
-q,–-sysoutLogging : 禁止logging输出作为标准输出。
-s,--fromSavepoint : savepoint路径。
-sae,–-shutdownOnAttachedExit : 任务随着客户端终端而停止,这个参数和-d不是共存的
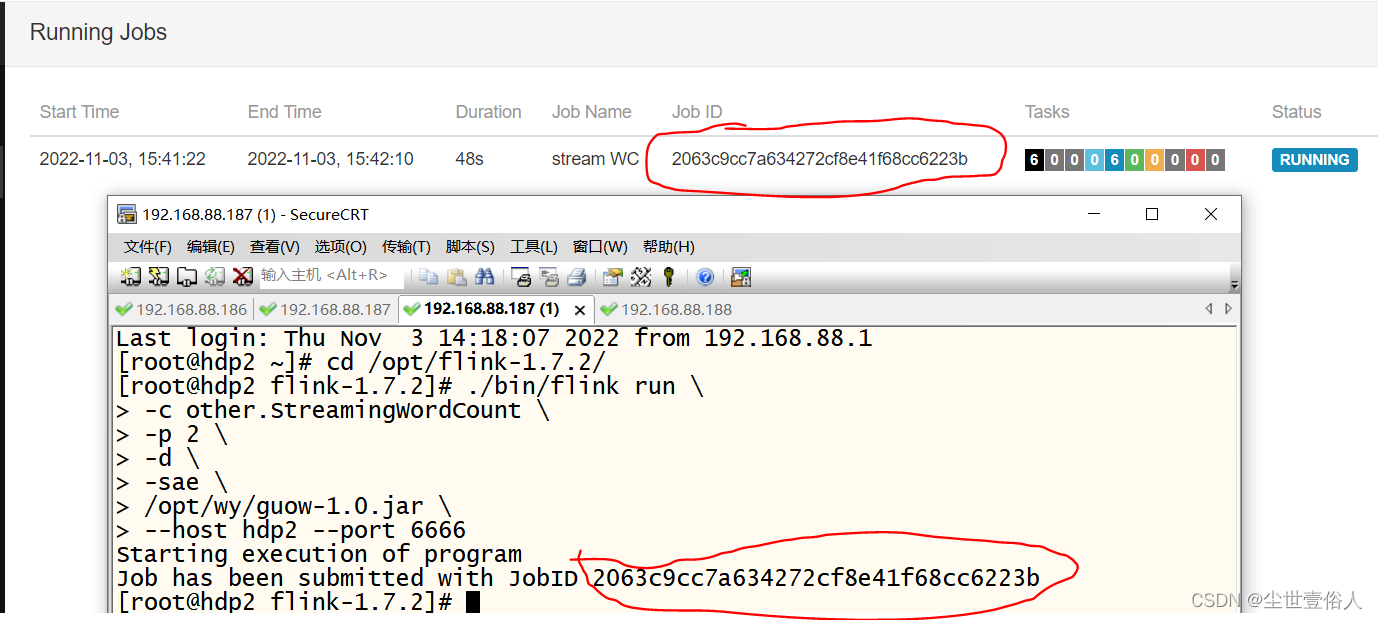
比如我上面例子,使用的命令,可以是下面这样
如果你要on yarn那在参数上就有些不同,你需要用如下参数
-m,–-jobmanager yarn模式
-yd,–-yarndetached 后台运行
-yjm,–-yarnjobManager jobmanager的内存
-ytm,–-yarntaskManager taskmanager的内存
-yn,–-yarncontainer TaskManager的个数
-yid,–-yarnapplicationId job依附的applicationId,一般不用,无实际使用意义
-ynm,–-yarnname application的名称
-ys,–-yarnslots 分配的slots个数
例:
./bin/flink run \
-m yarn-cluster \
-yjm 1024m \
-ytm 1024m \
-ys 2 \
-c other.StreamingWordCount \
/opt/wy/guow-1.0.jar \
192.168.88.187 6666
在服务器后台不报错,并提示任务starting execution of progarm就表示成功提交
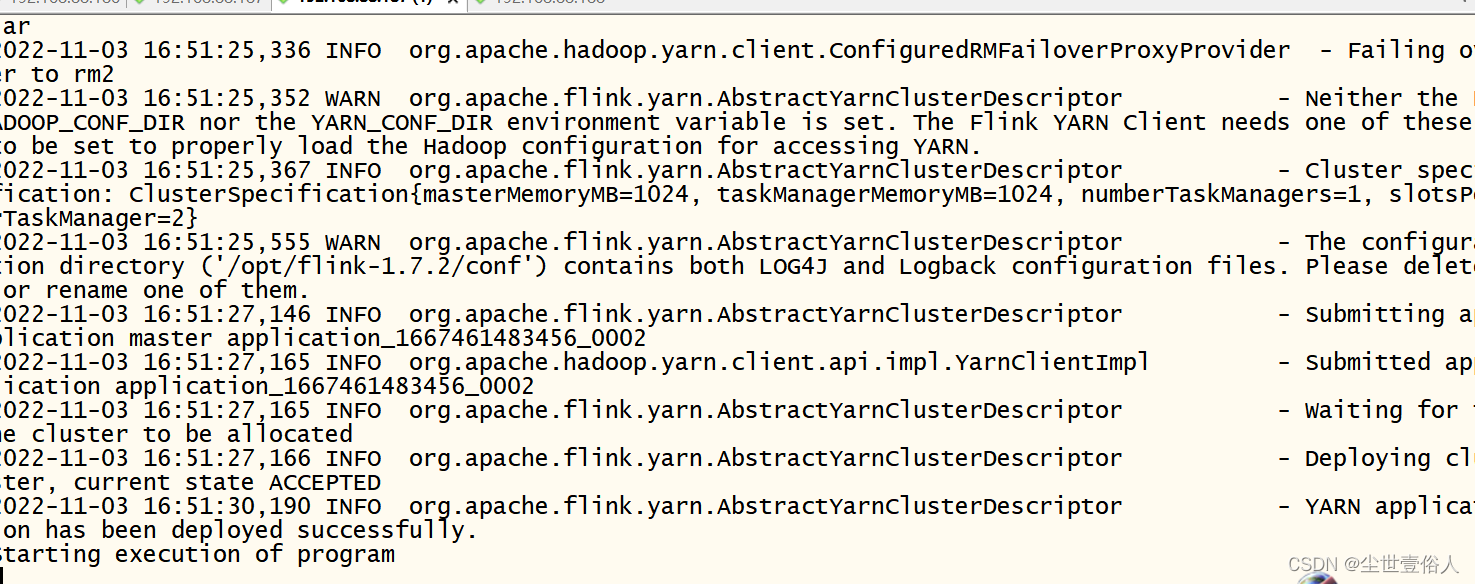
on yarn的时候flink自己的ui上是不显示任务的,你需要在yarn上看
on yarn有个尴尬的点,你想结束一个任务需要在yarn上kill掉
当然flink这个脚本不止能用来提交命令,也有其他作用。
可以展示任务列表
flink list:列出flink的job列表。
flink list -r/--runing :列出正在运行的job
flink list -s/--scheduled :列出已调度完成的job
可以取消某个任务
flink cancel [options] <job_id> : 取消正在运行的任务
flink cancel -s/--withSavepoint <job_id> : 取消正在运行的任务,并保存检查点
如果要取消的任务再其他的jobmanager上可以通过-m只能目标jobmanager
bin/flink cancel -m 127.0.0.1:8081 5e20cb6b0f357591171dfcca2eea09de
可以停止某个任务
#stop只能操作流任务,同上支持-m参数
flink stop [options] <job_id>
flink stop <job_id>:停止对应的流任务
取消和停止的差别在于,取消是立刻执行,停止是优雅的
还可以用来修改并行度
flink modify <job_id> [options]
flink modify <job_id> -p/--parallelism 数量
例: flink modify -p 并行数 <job_pid>
如果提交的任务设置了savepointpath,就可以触发保存
保存
flink savepoint [options] <job_id>
将flink的快照保存到hdfs目录
flink savepoint <job_id> hdfs://xxxx/xx/x
使用yarn触发保存点
flink savepoint <job_id> <target_directory> -yid <application_id>
使用savepoint取消作业
flink cancel -s <tar_directory> <job_id>
从保存点恢复
flink run -s <target_directoey> [runArgs]
如果复原的程序,对逻辑做了修改,比如删除了算子可以指定allowNonRestoredState参数复原。
flink run -s <target_directory> -n/--allowNonRestoredState [runArgs]
常用的就是如上这些命令参数,其他的你可以通过flink --help去了解,都是一些不常用的。
最后说一点flink on yarn需要服务器配置hadoop的home
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我以前没有使用过cron,所以我不能确定我这样做是对的。我想要自动化的任务似乎没有运行。我在终端中执行了这些步骤:sudogeminstall每当切换到应用程序目录无论何时。(这创建了文件schedule.rb)我将此代码添加到schedule.rb:every10.minutesdorunner"User.vote",environment=>"development"endevery:hourdorunner"Digest.rss",:environment=>"development"end我将此代码添加到deploy.rb:after"deploy:symlink","depl
如何在Rake任务中运行Capybara功能?例如:访问('http://google.com')谢谢! 最佳答案 在任务中尝试这样的事情:require'capybara'require'capybara/dsl'Capybara.current_driver=:seleniumBrowser=Class.new{includeCapybara::DSL}page=Browser.new.pagepage.visit("http://www.google.com")puts(page.html)
我在ruby表单中有一个提交按钮f.submitbtn_text,class:"btnbtn-onemgt12mgb12",id:"btn_id"我想在不使用任何javascript的情况下通过ruby禁用此按钮 最佳答案 添加disabled:true选项。f.submitbtn_text,class:"btnbtn-onemgt12mgb12",id:"btn_id",disabled:true 关于ruby-on-rails-如何在Rails中添加禁用的提交按钮,我们在St
保存成功后可以回滚吗?让我有一个带有属性名称、电子邮件等的用户模型。例如u=User.newu.name="test_name"u.email="test@email.com"u.save现在记录将成功保存在数据库中,之后我想回滚我的事务(不是销毁或删除)。有什么想法吗? 最佳答案 您可以通过交易来做到这一点,请参阅http://markdaggett.com/blog/2011/12/01/transactions-in-rails/例子:User.transactiondoUser.create(:username=>'Nemu
我正在根据Rakefile中的现有测试文件动态生成测试任务。假设您有各种以模式命名的单元测试文件test_.rb.所以我正在做的是创建一个以“测试”命名空间内的文件名命名的任务。使用下面的代码,我可以用raketest:调用所有测试require'rake/testtask'task:default=>'test:all'namespace:testdodesc"Runalltests"Rake::TestTask.new(:all)do|t|t.test_files=FileList['test_*.rb']endFileList['test_*.rb'].eachdo|task|n
根据thispostbyStephenHagemann,我正在尝试为我的一个rake任务编写Rspec测试.lib/tasks/retry.rake:namespace:retrydotask:message,[:message_id]=>[:environment]do|t,args|TextMessage.new.resend!(args[:message_id])endendspec/tasks/retry_spec.rb:require'rails_helper'require'rake'describe'retrynamespaceraketask'dodescribe're