举个宏观上的例子:
曾经有一个叫Google的公司觉得RDBMS这套东西太麻烦了,不适合大规模计算,所以在2005年发明了一个东西叫做Mapreduce,大概就是说用户需要提供mapper
和 reducer函数,这两个函数可以对数据干任何事情,框架会帮助用户做好并行。

但是15年后我们已经知道结果了,Mapreduce这种过度自由的框架其实并没有人玩的那么转,存活下来的都是sparkSQL,flinkSQL,Hive,Snowflake这些用SQL的产品。
从程序语言的角度上来说,API vs SQL 本质上是Imperative(命令式编程) vs Declarative(声明式编程)。
简单来讲 Imperative类似于你扮演一个程序员,对于一个功能,写出逻辑链上的每一行代码,然后程序运行得到结果。
而Declarative类似于你扮演一个产品经理,对于一个功能,你只需要描述你需要的结果,然后某程序会把中间的过程生成好。
不论从学术角度还是工程角度来讲Declarative是更加进步的。
再举个微观上的例子:
假设两张表,一张user(id, name)一张salary(id, user_id,salary)当你同时需要所有人的name和salary的时候,你会运行以下SQL
select * from user inner join salary on user.id = salary.user_id
但是如果你只有简单的CRUD API的话,你可能需要拿到所有user.id 然后走一个for loop 去salary里面找到对应的id,从正确性上来说也说得过去,但是性能会非常捉急,再后来你会发现所有的优化 = 你在用户侧重新实现了一个join算法。而如果用SQL的话会调用数据库内部的高效join算法。
所以,Declarative比Imperative更适合处理数据。很多时候你认为的约束和不便,其实是性能提升的来源。
而且,API是很难有一个语言的自由度的,很多SQL里面写起来很自然的东西要是用API实现的话都很丑陋。
2022 IEEE 编程语言榜单公布,最受欢迎以及发展趋势最好的是Python,但工作中最吃香的语言却是SQL。

作为一种广泛使用的数据专业语言,很多领先的科技公司都依赖于关系型数据库和SQL。像Mysql或者Oralce这类成熟的数据库,它已经和SQL深度绑定了。
SQL可以提供更高的性能和效率,以及更强的数据一致性和完整性,它能处理复杂的数据分析和查询。
综上所述,SQL想要轻易被取代是不可能的。
想要掌握SQL,你可能需要这款SQL工具 : SQL Studio
(1)免费。
(2)免费的基础上支持几乎所有主流数据库,不仅有MySQL、Oracel、PostgresSQL等国外数据库,还支持武汉达梦、人大金仓等国产数据库。
(3)突出亮点:Web版工具——一次部署,团队成员都能使用,占用的硬件资源都在服务器上;只要有可登录的软件链接和账号、密码,任意设备随时可用这款工具:省去了繁琐的工具安装配置、升级过程。(对于团队协作和教学场景简直不要太友好)
(4)亮点延伸:用户管理——SQL Studio只有管理员可以新建账号、也只有管理员可以增加和删除数据源,这样避免了许多安全问题。
(5)性能稳定且可圈可点:
a.可视化管理——支持图形化界面对数据库、表进行管理;支持直接修改表结构、表数据等,还能显示操作对应的SQL语句。

b.写sql支持智能提示:可以根据用户输入的字符及其语意提示表名等信息。
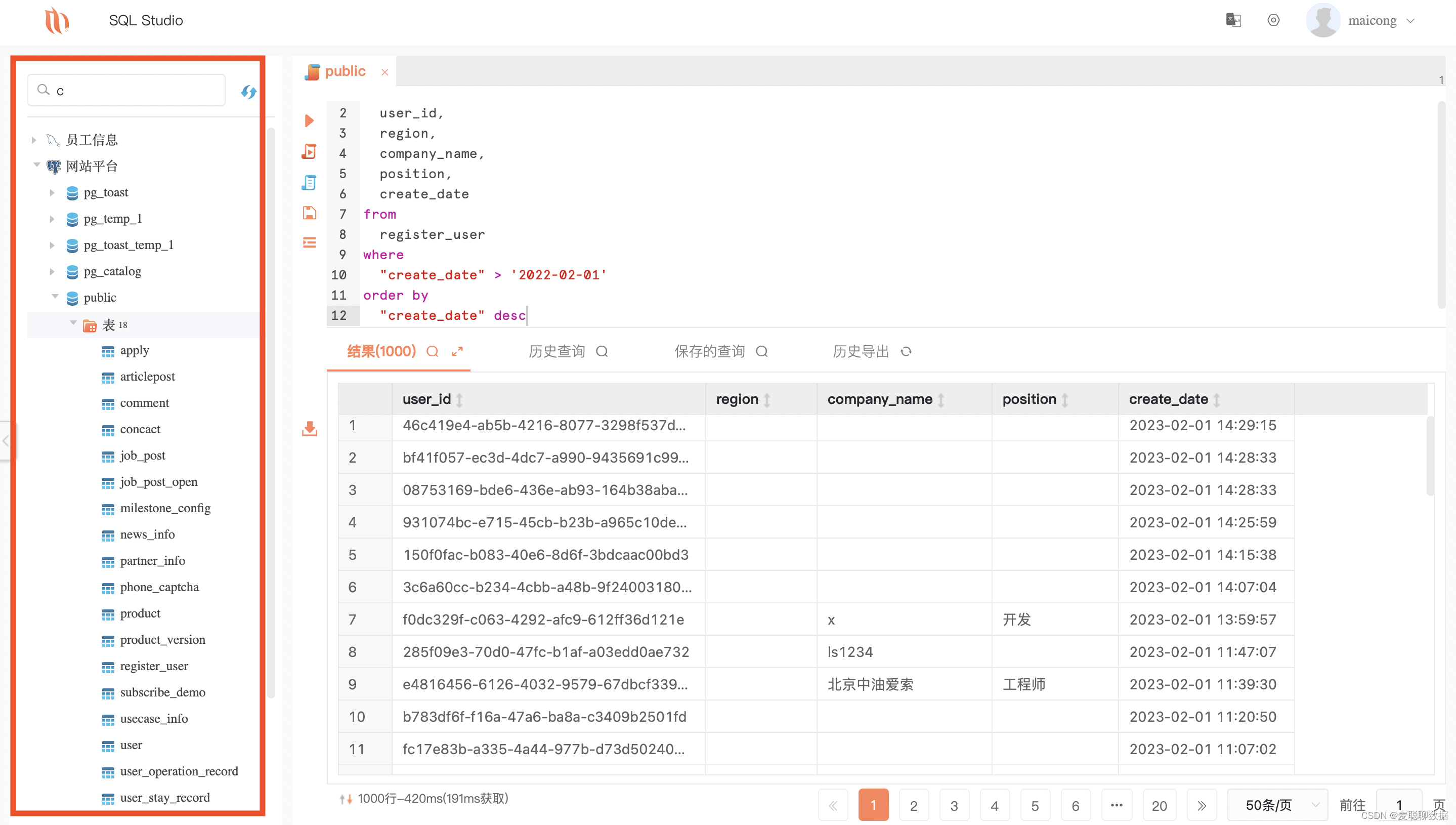
c.每次执行的SQL语句都会保存在主界面的“历史查询”中,而且找到对应语句可以直接复用。
d.经常需要用到的SQL语句也可以直接保存在主界面“保存的查询”中,不用再从电脑本地导入,而且能直接修改、复制、删除。
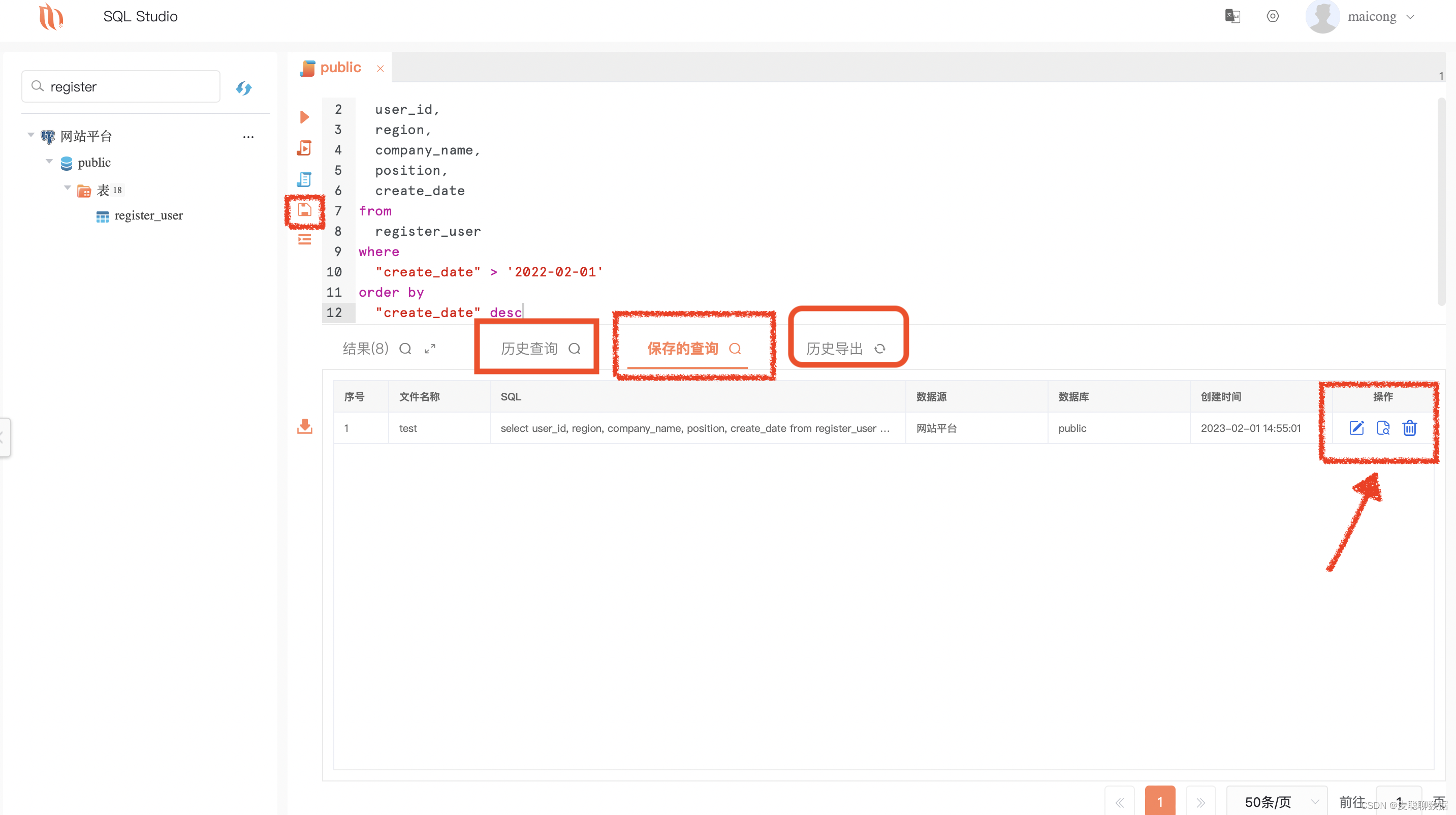
e.除了“历史查询”、“保存的查询”还有“历史导出”功能,每一次下载数据都会被记录,保证了工具完整的审计功能。
f.超强的数据导入、导出能力:近700万行数据导出只需20多秒,比Navicat还快两倍。
g.稳定性好:展开数据库中一万张表,丝毫不卡顿。SQL编辑框支持注释,有注释也能很好地执行语句,不出bug稳定性强。
h.一键批量执行:单击执行编辑框内所有SQL语句,方便大家进行刷库等操作。
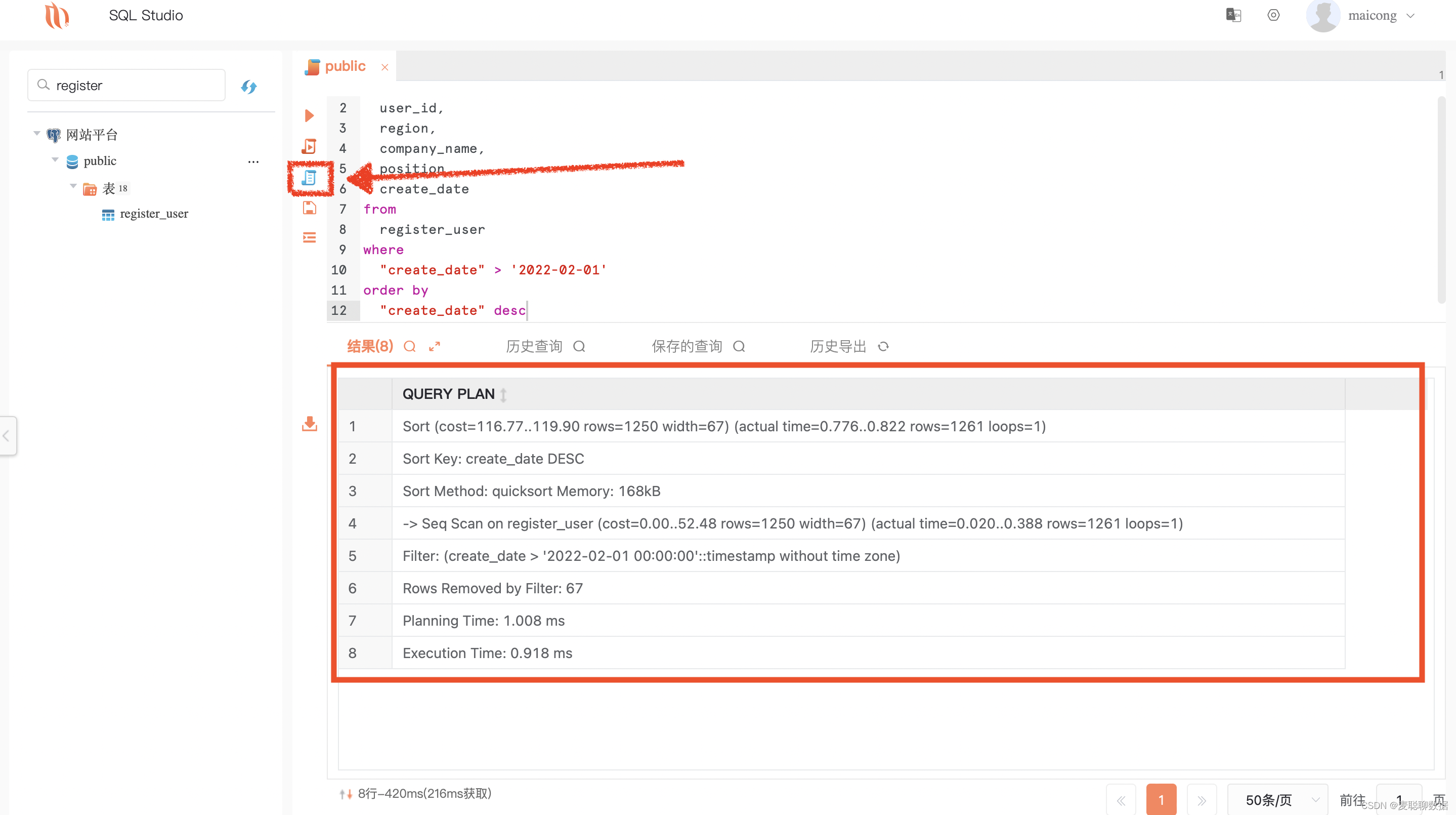
i.一键解释执行:单击即可帮助大家分析sql语句的性能,辅助优化。
j.结果栏支持调整每页展示多少条数据、且支持改变排序和全屏,看数据更方便。
k.数据库列表、结果栏、历史查询、保存查询都支持搜索定位。
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
查看Ruby的CSV库的文档,我非常确定这是可能且简单的。我只需要使用Ruby删除CSV文件的前三列,但我没有成功运行它。 最佳答案 csv_table=CSV.read(file_path_in,:headers=>true)csv_table.delete("header_name")csv_table.to_csv#=>ThenewCSVinstringformat检查CSV::Table文档:http://ruby-doc.org/stdlib-1.9.2/libdoc/csv/rdoc/CSV/Table.html
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我有用于控制用户任务的Rails5API项目,我有以下错误,但并非总是针对相同的Controller和路由。ActionController::RoutingError:uninitializedconstantApi::V1::ApiController我向您描述了一些我的项目,以更详细地解释错误。应用结构路线scopemodule:'api'donamespace:v1do#=>Loginroutesscopemodule:'login'domatch'login',to:'sessions#login',as:'login',via::postend#=>Teamroutessc
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
当谈到运行时自省(introspection)和动态代码生成时,我认为ruby没有任何竞争对手,可能除了一些lisp方言。前几天,我正在做一些代码练习来探索ruby的动态功能,我开始想知道如何向现有对象添加方法。以下是我能想到的3种方法:obj=Object.new#addamethoddirectlydefobj.new_method...end#addamethodindirectlywiththesingletonclassclass这只是冰山一角,因为我还没有探索instance_eval、module_eval和define_method的各种组合。是否有在线/离线资