关注公众号,发现CV技术之美
最近在学习open3d的相关应用,然后遇到了一个很有趣的问题。给定多个mesh,我们可能会需要把他们全部合并到一个文件并使用。但是这并不好实现,因为open3d自己不支持这样的操作。相比之下,其他一些集成度非常高的软件,是可以实现这样的操作的,例如meshlab通过交互栏中的“flatten visible layer”指令来实现。
唯一的缺点是,你每次都需要手动操作才行,这对于需要高度自动化的使用场景,就不是很合适了。因此,如何可以实现一个自动化的脚本,支持直接合并多个可染色的mesh,并输出带有纹理的最终结果,是一个非常重要的功能。遗憾的是度娘和谷歌目前没有相关的教程。因此本文带大家了解一下,如何重头写一个ply文件并且合并输出所有需要合并的m
esh。
▍如何存储一个带纹理的obj格式的mesh
这里我们首先介绍一下,怎么去存储一个mesh。为了方便,我们使用这篇文章中的代码 (https://zhuanlan.zhihu.com/p/569974846),先自己生成若干个mesh(有些带有纹理,有些没有),然后进行存储。单模型存储在open3d中是很简单的,open3d提供了一个接口来直接存储对应的mesh,接口是o3d.io.write_triangle_mesh。
但是要注意的是,如果要存纹理信息,这个命令需要使用obj格式,因为另外一种常见的ply格式,则无法存储纹理信息。因此,作为合并的第一步,我们手动输出全部mesh为obj格式以支持纹理信息,并且分开存储。
以下代码把场景内的全部mesh文件输出为obj格式。
if not os.path.exists("save_mesh"):
os.makedirs("save_mesh", exist_ok=False)
o3d.io.write_triangle_mesh("save_mesh/obj_back.obj", back_obj)
o3d.io.write_triangle_mesh("save_mesh/obj_left.obj", left_obj)
o3d.io.write_triangle_mesh("save_mesh/obj_front.obj", front_obj)
o3d.io.write_triangle_mesh("save_mesh/obj_right.obj", right_obj)
o3d.io.write_triangle_mesh("save_mesh/box_back.obj", back_box)
o3d.io.write_triangle_mesh("save_mesh/box_left.obj", left_box)
o3d.io.write_triangle_mesh("save_mesh/box_front.obj", front_box)
o3d.io.write_triangle_mesh("save_mesh/box_right.obj", right_box)▍如何存储一个带纹理的ply格式的mesh
存储为obj格式之后,我们通过meshlab自带的命令行格式,把所有带有纹理的mesh全部转化为ply文件。这里要注意的是,如果你的mesh模型本身是不带有色彩的,那么这一步可以直接加载mesh模型然后转为ply文件,上一步输出为obj格式则是可以跳过的。
下面我们依次加载obj文件并转存为ply文件。代码如下:
if not os.path.exists("save_mesh_ply"):
os.makedirs("save_mesh_ply", exist_ok=False)
for obj in ["save_mesh/obj_back.obj", "save_mesh/obj_left.obj", "save_mesh/obj_front.obj",
"save_mesh/obj_right.obj", "save_mesh/box_back.obj", "save_mesh/box_left.obj",
"save_mesh/box_front.obj", “save_mesh/box_right.obj"]: #简单粗暴的列出来所有mesh
ms = pymeshlab.MeshSet()
ms.load_new_mesh(obj)
ms.save_current_mesh(os.path.join(obj.split("/")[0]+"_ply", obj.split("/")[1].replace("obj", “ply")))最终存储的mesh,重新使用meshlab可视化结果如下:
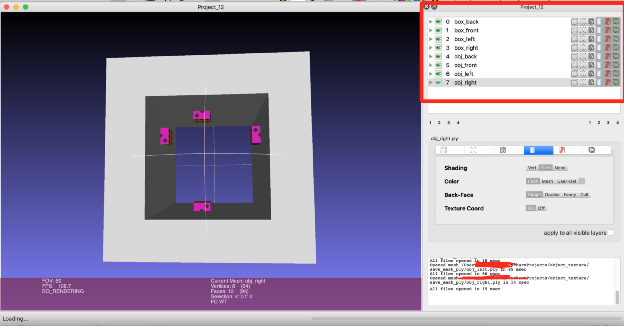
注意右侧红框,此时存在8个不同的层(layers)。我们的最终目的是把他们全部合并为一层并且统一存储。
▍ply文件格式介绍
下面我们来介绍一下ply文件格式的组成。ply文件有两个重要组成部分。第一组是头部(header),之后是对应于头部定义的数值组。
首先是头部(header)的定义,对于无纹理mesh文件来说,直接套用ply头部固定模板即可。
ply
format ascii 1.0
comment VCGLIB generated
element vertex vertex_count
property float x
property float y
property float z
property uchar red
property uchar green
property uchar blue
property uchar alpha
element face face_count
property list uchar int vertex_indices
end_header关于无纹理文件的头部的定义,大部分情况下可以直接照抄,无需修改,除了点、面对应的数量(红色变量对应位置替换即可)。这里进一步解释一下关键字:header中的comment是注释的意思,property详细定义了所需要的数据结构。最后使用end_header标注定义结束。另外ply文件格式的编码,我强烈推荐使用ascii格式,否则使用文本编辑工具打开是乱码,不利于分析问题。
头部的定义具体包含了顶点与面的定义。对于不带纹理的ply文件,其对应顶点的定义需要如下关键参数,分别为:当前mesh的三维坐标(X,Y,Z)以及对应面的顶点索引(vertex indices)
对于带纹理的ply文件,除了上述所需参数外,额外需要向header添加纹理定义。
纹理定义格式如下
comment TextureFile texture_name其中,前两个单词为关键字,最后一个为变量,指向纹理文件存储位置。需要注意的是,有多少纹理文件,就要对应性的添加多少行。否则对应的mesh无法染色。
对于面来说,需要额外定义五个变量,分别为 texcoord,red, green, blue, alpha,合并在一起记录面的颜色,分别对应于有纹理图片(texcoord)与自带纹理的情况(RGBA)。代码如下:
property list uchar float texcoord
property uchar red
property uchar green
property uchar blue
property uchar alpha全部合在一起,即为有纹理的mesh对应的完整定义。
介绍完header之后,我们就可以依次按照定义的顶点和面的顺序,往里面填数据了。对于带有、不带有纹理的mesh,其对应的ply文件的顶点信息和面对应信息稍有不同,具体的不同可以通过header的定义看出来,这里不再赘述。为了方便起见,我们统一填补所有不带纹理的mesh里缺失的列信息。具体如何填补我们稍后介绍。
▍如何读取并操作ply文件
ply文件本身是单纯的文本流,为了处理方便,这里我们使用python自带的plyfile进行处理,从而快捷的读取ply文件并转化为相应的numpy矩阵。
在读取相关文件前,我们先准备一下输入输出(IO)。代码如下:
need_texture = False
model_in_folder = "save_mesh_ply"
model_out_folder = "save_mesh_ply_out"
assert os.path.exists(model_in_folder), "input mesh models are not available! file path : {}".format(model_in_folder)
if not os.path.exists(model_out_folder):
os.makedirs(model_out_folder, exist_ok=True)
fuse_model_path = glob.glob(os.path.join(model_in_folder, "*.ply"))
fuse_model_path.sort()
fused_vertex, fused_faces = None, None
vertex_count = 0
coloring_list = []
merge_file_name = os.path.join(model_out_folder, "merged_mesh.ply")之后我们来讲解一下plyfile怎么处理ply文件。plyfile是python下处理ply一个经典的库,其自带plyData模块,可以读入输出ply文件。读取时,直接调用plyData即可。返回结果是一个字典,可以用来获得对应mesh的顶点和面的结果。
具体如何处理,可以看一下这里的代码。
plydata = PlyData.read(f_path)
vertexs = np.array(plydata['vertex'].data)
faces = plydata[‘face'].data然后我们来处理一下顶点和面,处理的原因上面已经提到过了,主要就是同步有纹理与无纹理mesh对应的顶点和面属性不匹配的问题。具体来说,无纹理的mesh对应的属性定义,要少于有纹理的mesh。如果不处理的话,是无法直接进行合并的,因此我们严格按照header中属性的定义,对于无纹理的mesh对应缺失的属性依次填充,即可得到最终的结果。关于如何填充缺失值,我们下一节会详细介绍。
继续讨论顶点和面的定义。首先我们介绍一下相关的数据结构。
对于顶点来说,我们需要读入三维坐标点信息与对应每个顶点的色彩纹理信息,而对于面来说,我们需要存入顶点顺序来构造每个面,以及对应的纹理坐标(Texcoord),和对应面的颜色值(RGBA)。这里要注意的是,如果提供了图像+纹理坐标,则对应面的RGBA值会被覆盖。详细数据结构的定义请看下表。
顶点对应的数据结构 | |
变量 | 数据结构 |
X | float32 |
Y | float32 |
Z | float32 |
Red | Uint8 |
Green | Uint8 |
Blue | Uint8 |
Alpha | Uint8 |
面对应的数据结构 | |
变量 | 数据结构 |
vertex_indices | Object |
Texcoord | Object |
Red | Uint8 |
Green | Uint8 |
Blue | Uint8 |
Alpha | Uint8 |
相关代码定义如下(这一节用不到,后面填充矩阵的时候会用到):
vertex_dtype = [('x', '<f8'), ('y',="" '
face_dtype = [('vertex_indices', 'O'), ('texcoord', 'O'), ('red', 'u1'), ('green', 'u1'), ('blue', 'u1'),
('alpha', ‘u1')]▍如何对顶点与面进行填充
我们再来看一下如何对顶点和面进行填充。填充的核心是针对无纹理的mesh操作的,主要是将其没有的属性,使用默认值直接进行填充,从而与有纹理的mesh相兼容。那么需要填充什么内容呢?
对于无纹理的mesh,具体来说:
其对应顶点的顶点颜色信息(red, green, blue, alpha)统一设定为(255,255,255,255),也就是设定为白色。不一定非要这个颜色,对应值可以根据你默认的需要颜色来改变。
其对应面的vertex_indices会按照实际遍历过的面对应顶点的编号重新排布,
其对应的texcoord一律设置为[0,0,0,0,0,0],也就是两个三角片面的染色坐标提取点为0。换句话说,不提取该位置的纹理信息。
该面的颜色一律设置为白色(对应RGBA值为255,255,255,255,如果你需要其他颜色可以直接改)
这部分直接看一下相关代码。
def process_vertex(vertexs, vertex_dtype):
if len(vertexs[0])<=3:
new_vertexs = []
for i in range(len(vertexs)):
new_vertexs.append(vertexs[i].tolist() + (255,)*4)
new_vertexs = np.array(new_vertexs, dtype=vertex_dtype)
return new_vertexs
else:
return vertexs
def process_face(faces, faces_dtype):
if len(faces[0]) == 1:
new_faces = []
texcoord = np.array([0]*6, dtype=np.float32)
rgba = (255, )*4
for i in range(len(faces)):
new_faces.append((faces[i][0], texcoord) + rgba)
new_faces = np.array(new_faces, dtype = faces_dtype)
return new_faces
else:
return faces
def update_vertex_idx(vertex_counts, faces, faces_dtype):
new_faces = []
for i in range(len(faces)):
vertex_idx, texcoord, r, g, b, a = faces[i].tolist()
vertex_idx = vertex_idx + vertex_counts
new_faces.append((vertex_idx, texcoord, r, g, b, a))
new_faces = np.array(new_faces, dtype=faces_dtype)
return new_faces上述代码中,process_vertex函数处理了问题1,process_face处理了问题3、4,而update_vertex_idx函数处理了问题2。通过使用这些函数,可以顺利的修正所有的顶点与相对应的面的匹配关系,并且合并所有的ply文件。
▍如何合并所有给定的ply文件
最后一步,我们尝试使用已有的代码来合并全部给定的ply文件。这里我们定义一个函数 write_merge_mesh来实现合并这一核心功能。
这个函数会执行如下操作:
自动生成header。同时检查是否有纹理mesh(通过传入参数need_texture判断)。如果有,则向header注入纹理文件信息。
从预处理好的顶点和面(也就是上面process_vertex和process_face的输出结果)上收集数据,然后统一写入新的ply文件。
相关代码如下:
def write_merge_mesh(merge_file_name, point_count, face_count, coloring_list, fused_vertex, fused_faces, need_texture=True):
texture_file = ""
if need_texture:
for file in coloring_list:
texture_file += "comment TextureFile {}\n".format(file)
head = """ply
format ascii 1.0
comment VCGLIB generated
"""
head += texture_file
head += """element vertex {}
property float x
property float y
property float z
property uchar red
property uchar green
property uchar blue
property uchar alpha
element face {}
property list uchar int vertex_indices
property list uchar float texcoord
property uchar red
property uchar green
property uchar blue
property uchar alpha
end_header""".format(point_count, face_count)
with open(merge_file_name, 'w') as f2:
f2.write(head)
for ve in fused_vertex:
f2.write(" ".join(map(str, ve.tolist()))+"\n")
for fe in fused_faces:
vertex_idx, texcoord, r, g, b, a = fe
out_str = str(len(vertex_idx.tolist())) + " " + " ".join(map(str, vertex_idx.tolist())) + " " + \
str(len(texcoord.tolist())) + " " + " ".join(map(str, texcoord.tolist())) + " " + str(r) + " "+str(g) + " "+ str(b) + " "+str(a)+"\n"
f2.write(out_str)
return head注意,最终合并的ply文件的输出位置,需要和存储纹理信息的位置一致,否则需要手动复制粘贴纹理信息到生成ply文件的位置。
最终由多个mesh合并为一个mesh并且输出的可视化结果如下:
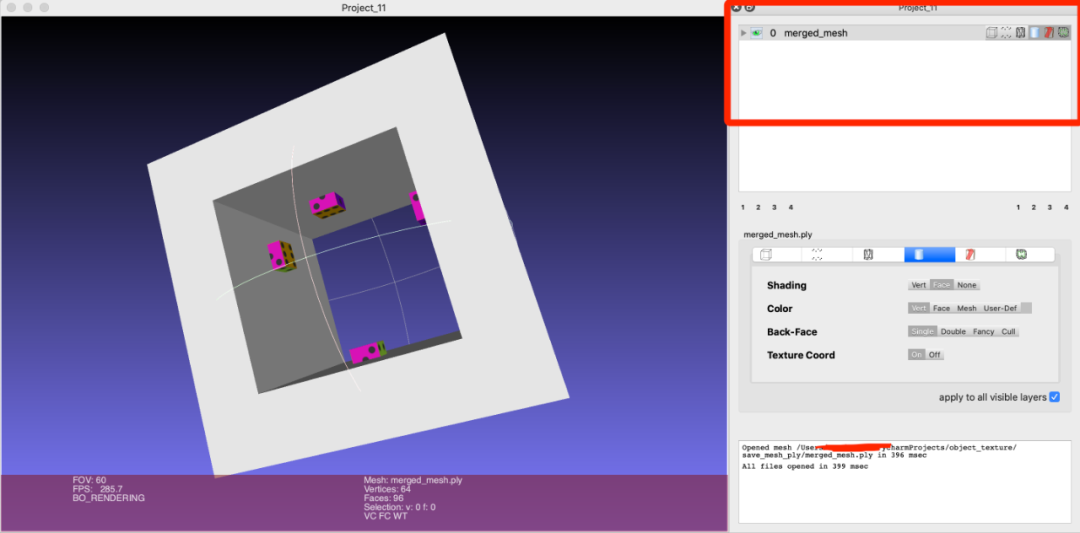
到底为止,我们顺利完成了多个组合面合并起来进行ply文件输出的python代码。
▍附录:本文涉及全部代码
# 设置need_texture = False 如果不存染色结果
import os
from plyfile import PlyData
import numpy as np
import glob
def process_vertex(vertexs, vertex_dtype):
if len(vertexs[0])<=3:
new_vertexs = []
for i in range(len(vertexs)):
new_vertexs.append(vertexs[i].tolist() + (255,)*4)
new_vertexs = np.array(new_vertexs, dtype=vertex_dtype)
return new_vertexs
else:
return vertexs
def process_face(faces, faces_dtype):
if len(faces[0]) == 1:
new_faces = []
texcoord = np.array([0]*6, dtype=np.float32)
rgba = (255, )*4
for i in range(len(faces)):
new_faces.append((faces[i][0], texcoord) + rgba)
new_faces = np.array(new_faces, dtype = faces_dtype)
return new_faces
else:
return faces
def update_vertex_idx(vertex_counts, faces, faces_dtype):
new_faces = []
for i in range(len(faces)):
vertex_idx, texcoord, r, g, b, a = faces[i].tolist()
vertex_idx = vertex_idx + vertex_counts
new_faces.append((vertex_idx, texcoord, r, g, b, a))
new_faces = np.array(new_faces, dtype=faces_dtype)
return new_faces
def write_merge_mesh(merge_file_name, point_count, face_count, coloring_list, fused_vertex, fused_faces, need_texture=True):
texture_file = ""
if need_texture:
for file in coloring_list:
texture_file += "comment TextureFile {}\n".format(file)
head = "ply\nformat ascii 1.0\ncomment VCGLIB generated\n"
head += texture_file
head += """element vertex %d
property float x
property float y
property float z
property uchar red
property uchar green
property uchar blue
property uchar alpha
element face %d
property list uchar int vertex_indices
property list uchar float texcoord
property uchar red
property uchar green
property uchar blue
property uchar alpha
end_header
""" % (point_count, face_count)
with open(merge_file_name, 'w') as f2:
f2.write(head)
for ve in fused_vertex:
f2.write(" ".join(map(str, ve.tolist()))+"\n")
for fe in fused_faces:
vertex_idx, texcoord, r, g, b, a = fe
out_str = str(len(vertex_idx.tolist())) + " " + " ".join(map(str, vertex_idx.tolist())) + " " + \
str(len(texcoord.tolist())) + " " + " ".join(map(str, texcoord.tolist())) + " " + str(r) + " "+\
str(g) + " "+ str(b) + " "+str(a)+"\n"
f2.write(out_str)
return head
if __name__ == "__main__":
need_texture = False
model_in_folder = "save_mesh_ply"
model_out_folder = "save_mesh_ply"
assert os.path.exists(model_in_folder), "input mesh models are not available! file path : {}".format(model_in_folder)
if not os.path.exists(model_out_folder):
os.makedirs(model_out_folder, exist_ok=True)
fuse_model_path = glob.glob(os.path.join(model_in_folder, "*.ply"))
fuse_model_path.sort()
fused_vertex, fused_faces = None, None
vertex_counts = 0
coloring_list = []
merge_file_name = os.path.join(model_out_folder, "merged_mesh.ply")
# definition
vertex_dtype = [('x', '<f8'), ('y',="" '
face_dtype = [('vertex_indices', 'O'), ('texcoord', 'O'), ('red', 'u1'), ('green', 'u1'), ('blue', 'u1'),
('alpha', 'u1')]
for f_path in fuse_model_path:
if need_texture:
# need_texture = True
coloring_list.append(f_path.split("/")[-1].split(".")[0]+"_0.png")
plydata = PlyData.read(f_path)
vertexs = np.array(plydata['vertex'].data)
faces = plydata['face'].data
vertexs = process_vertex(vertexs, vertex_dtype)
faces = process_face(faces, face_dtype)
if fused_vertex is None:
fused_vertex = vertexs
fused_faces = faces
else:
fused_vertex = np.concatenate((fused_vertex, vertexs))
faces = update_vertex_idx(vertex_counts, faces, face_dtype)
fused_faces = np.concatenate((fused_faces, faces))
vertex_counts += vertexs.shape[0]
write_merge_mesh(merge_file_name, vertex_counts, fused_faces.shape[0], coloring_list, fused_vertex, fused_faces)
END
欢迎加入「三维重建」交流群👇备注:3D

我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t