Redis集群
服务器的容量不足或者进行并发写操作的用户过多等情况下可以使用多台Redis集群的方式缓解压力。
注:(高并发的写操作,如果是一主多从模式主服务器承受的压力会很大,因此引入集群)
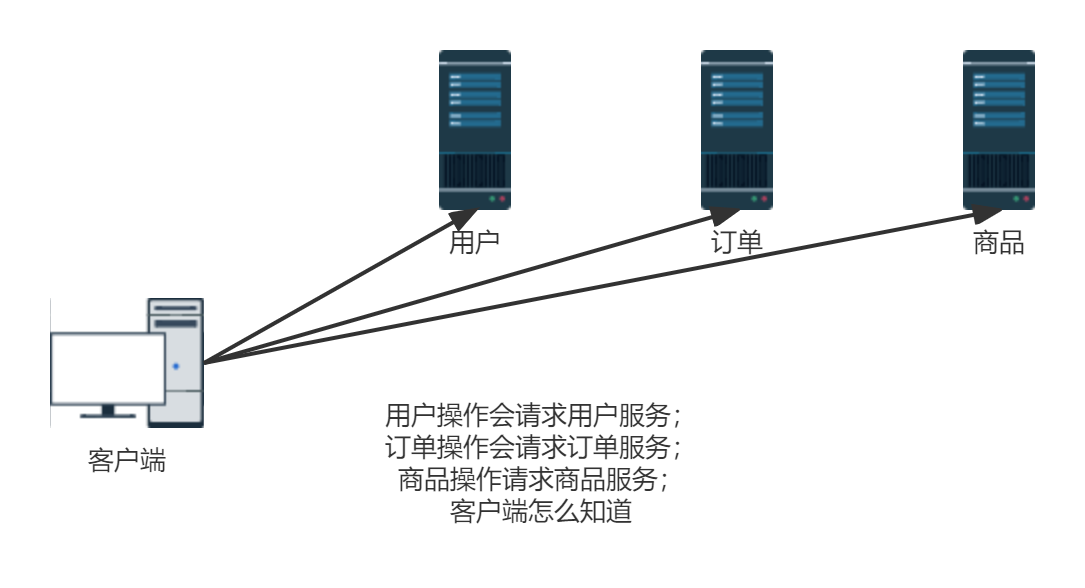
以电商项目的用户、订单、商品三个模块来演示代理主机和无中心化集群。如下图:
用户信息、订单信息、商品信息分别使用三台Redis服务器存储。 这样一来,相应的操作就会去请求相应的Redis服务器。
问题:客户端通过何种方式知道需要去请求哪个服务?
①代理主机方式通过加一层代理服务器解决此问题(不推荐使用)
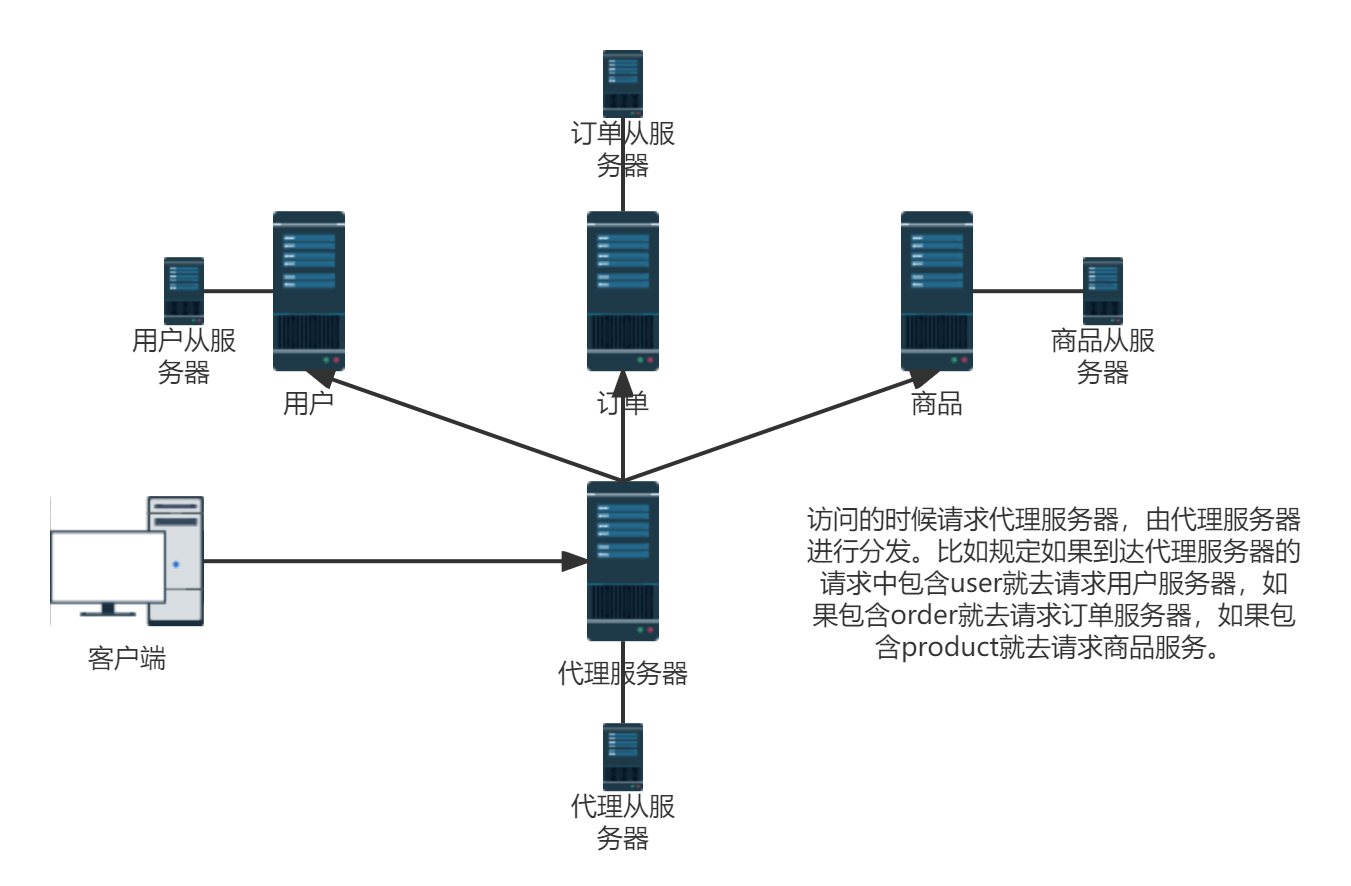
访问的时候请求代理服务器,由代理服务器进行分发。
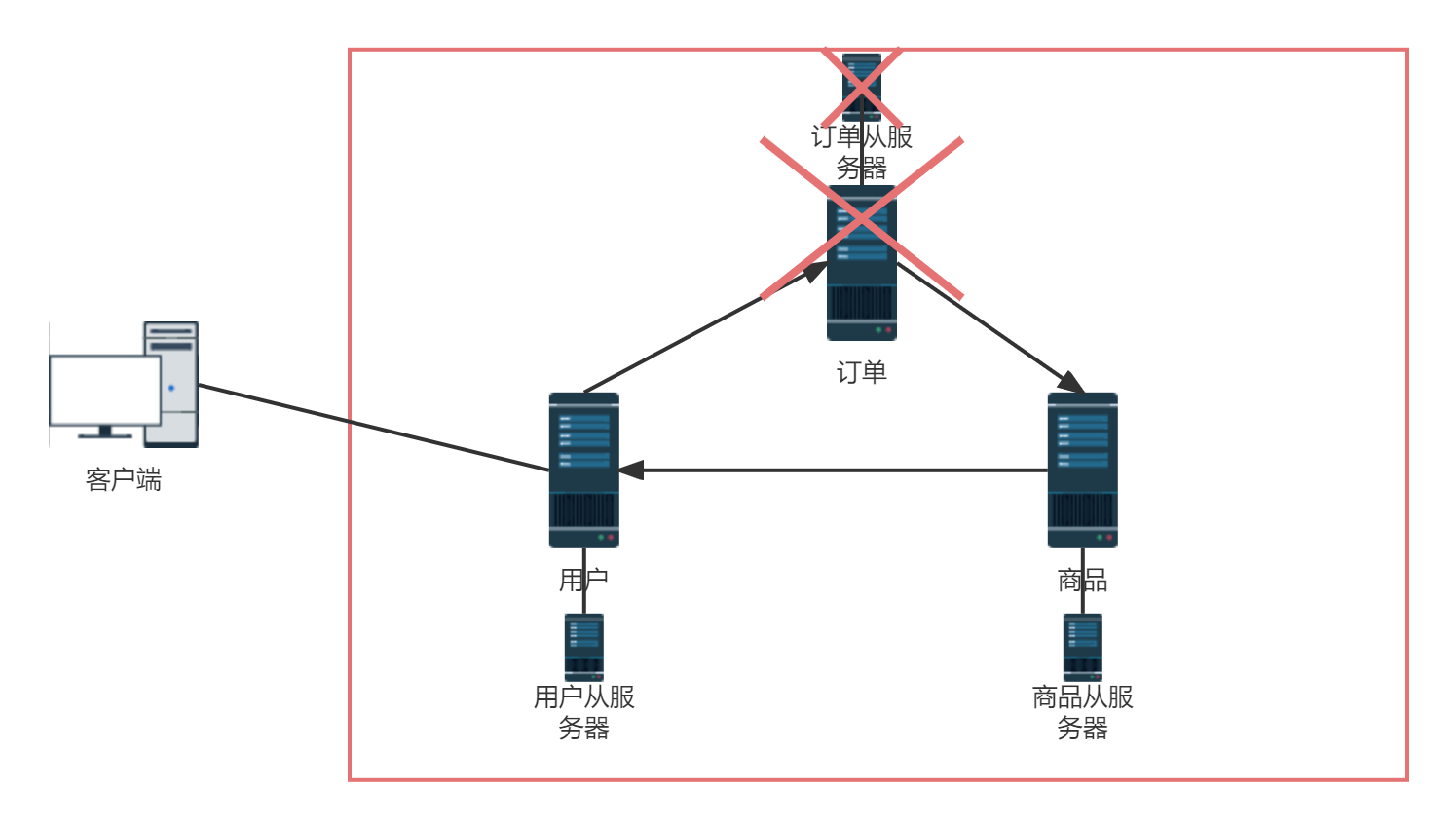
局部可以使用主从模式,如果其中某一台Redis服务器挂掉,从机上位变为主服务器继续提供服务。
可以看到,以代理主机方式按照目前的需求搭建集群,至少需要8台服务器。搭建和后期维护都很不方便,所以不推荐使用此方式创建集群,于是引入了无中心化方式的集群!!!
②无中心化搭建Redis集群方式解决此问题(推荐)
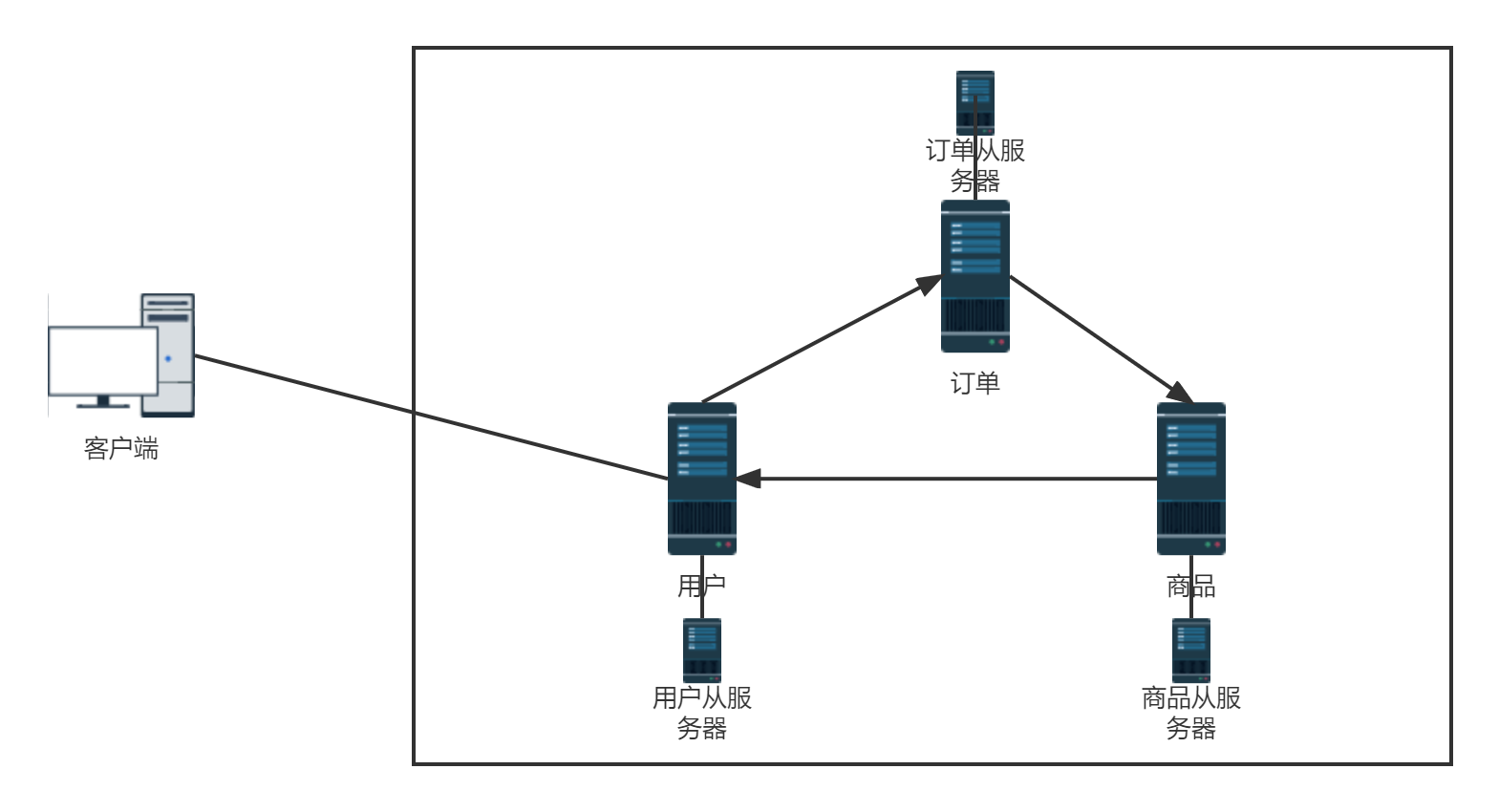
无中心化Redis集群搭建方式最少需要6台服务器即可。和代理主机方式相比优势明显。
Redis 集群实现了对Redis的水平扩容,即启动N个redis节点,将整个数据库分布存储在这N个节点中,每个节点存储总数据的1/N。
Redis 集群通过分区来提供一定程度的可用性: 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
根据上面介绍,我们了解到无中心化集群搭建方式至少需要6台Redis服务器。接下来演示无中心化Redis集群环境搭建:
接下来演示在一台linux主服务器上模拟六台Redis服务器,演示无中心化Redis集群环境的搭建:
①在Linux服务器中新建一个myredis文件夹。如下图:

②创建6个redis实例,端口号为:6379、6380、6381、6389、6390、6391
(如果使用云服务器记得设置这几个端口的安全组)
实现:
vim redis6379.conf 创建配置文件并写入如下内容:
复制出其余5个配置文件
依次通过字符串替换修改5个文件内容(下图是修改redis6381.conf的过程,修改其余配置文件操作类似)
③启动6个Redis服务
格式:redis-server redis6379.conf(启动redis6379服务)
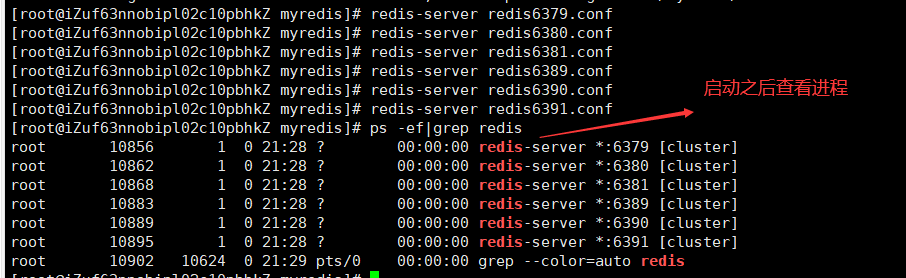
通过ll命令查看,确保如下的节点文件生成成功

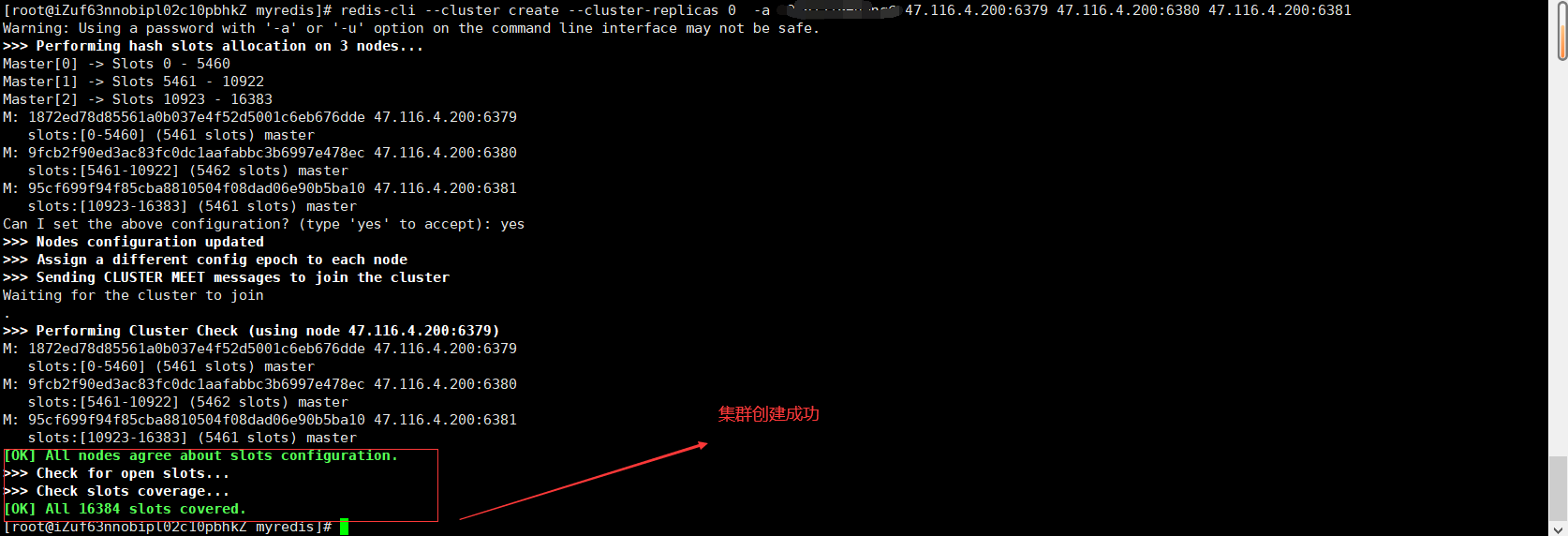
④一个集群至少要有三个主节点,先组合创建只有三个主节点的集群(6379、6380、6381)
组合之前,务必请确保所有redis实例启动后,nodes-xxxx.conf文件都生成正常。
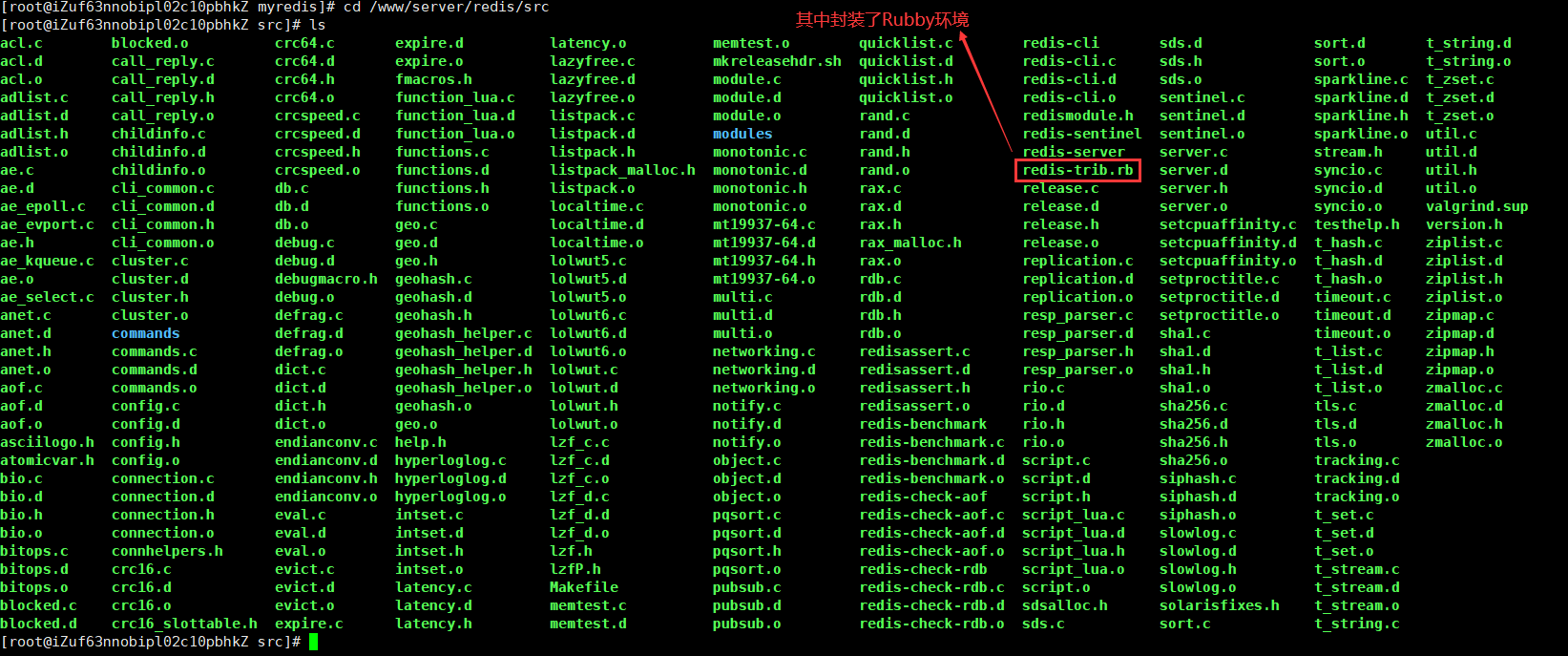
Redis版本低的话,需要额外装上rubby环境。新版的redis自带了rubby环境,。我使用的是新版本redis7
redis安装目录下的src目录中可以看到,,关于rubby的文件
使用命令进行合并创建集群
redis-cli --cluster create --cluster-replicas 0 -a 你的redis密码
47.116.4.200:6379 47.116.4.200:6380 47.116.4.200:6381
其中参数:
⑤启动redis服务后,需要连接Redis。

⑥通过 cluster nodes 命令查看集群信息

⑦增加三个从机到集群中去,并设置相应的主机
redis-cli --cluster add-node 47.116.4.200:6389 47.116.4.200:6379 --cluster-slave --cluster-master-id 主机的id (-a Redis密码):增加从节点6389到集群中去,并将其设置为6379主机的从机。
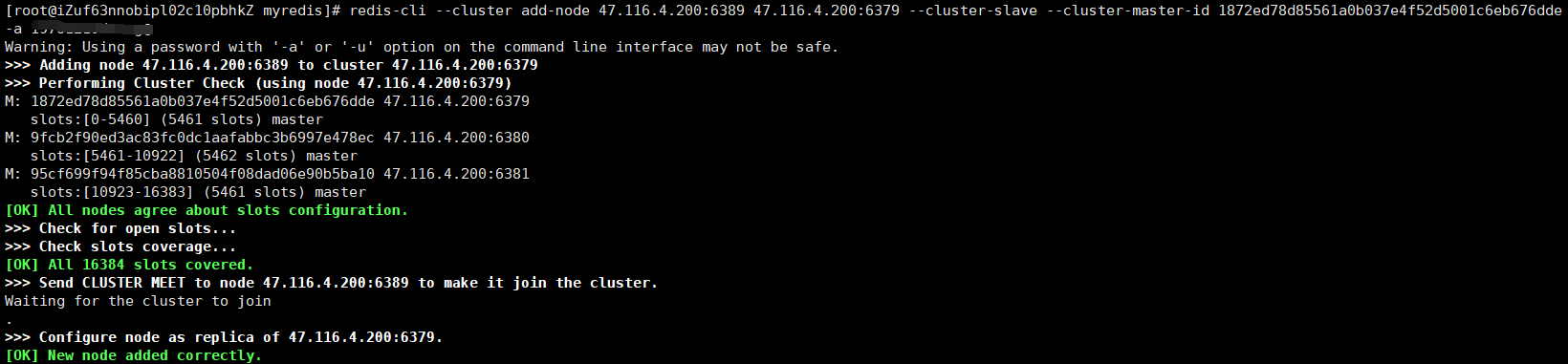
以同样的方式,把6390添加为6380的从机;把6391添加为6381的从机。
添加完毕之后通过redis-cli -c -p 6379连接一台集群中的redis服务器。并通过cluster nodes查看节点信息。如下图:

此时可以看到集群中节点已经分为三组:
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个。
插槽用来把值平均分配到不同主机中去,达到分担压力的效果。(比如set k1 v1操作的时候,会计算k1所在插槽值,根据各节点管辖的插槽范围,放入相应的节点中去)
集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。
集群中的每个节点负责处理一部分插槽。 如下图:

上图中的当前集群有三个主节点, 其中:
节点 6379 负责处理 0 号至 5460 号插槽。
节点 6380 负责处理 5461 号至 10922 号插槽。
节点 6381 负责处理 10923 号至 16383 号插槽。
①录入单个值

6381管理的插槽范围是10923 号至 16383 号,12706在其范围内。
一开始,请求进入6379,执行set k1 值操作时,计算k1的插槽值,发现k1插槽值不在6379服务器管理范围内,于是会转移请求找到6381服务器并执行set操作。
②尝试录入多个值

无法计算多个key的插槽值。集群中mset不能执行成功。
如果非要在集群中录入多个值,可以使用添加分组的方法
key值后面添加{ 组名 },就可以根据组名计算插槽,而不用再根据key值计算。此方法插入即可成功。如下图:

①cluster keyslot key:计算key值的插槽数

②cluster countkeysinslot 插槽值:计算插槽中有几个key(键)

注意: 虽然当前12706插槽中有一个k1,但12706在 6381节点的管辖的插槽值范围(10923~16383) 内。此命令只能计算当前6380节点管辖的插槽值范围(5461~10922) 内的数据。上图中的12706超出范围,因此返回0。
③cluster getkeysinslot 插槽数 个数:返回count个插槽中的key

上图表明,此时的4576插槽中只有一个k3。
此时我们搭建的集群中为三组“一主一从”,如果集群中某台主机挂掉,其从机立马上位接替主机工作,继续提供服务。此即为故障恢复。 如下图:

此时思考:如果此时再次重启6379服务器,6379的角色是什么?
答案是重启6379服务器,6379角色变为6389的从机,上位主机后的6389服务器依然是主机。如下图:

再次思考:如果集群中某台主机挂掉之后,此主机的所有从机也都挂掉了(如下图),整个集还能正常提供服务吗?
答案为不一定。主要要看配置文件。
某一段插槽的主从都挂掉时,集群能否提供服务主要看配置信息(cluster-require-full-coverage ):
优点:多台服务器集群可以分摊并发操作压力、实现扩容。
缺点:不支持多键操作(如mset命令会操作失败)、不支持多键的Redis事务、不支持lua脚本.
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
文章目录一.搭建集群时出现错误错误日志elasticsearch.logorg.elasticsearch.cluster.block.clusterblockexception:blockedby:[service_unavailable/1/statenotrecovered/initialized];原因:解决方案:一.搭建集群时出现错误错误日志elasticsearch.logorg.elasticsearch.cluster.block.clusterblockexception:blockedby:[service_unavailable/1/statenotrecovered/i
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
目录一、下载Elasticsearch1.选择你要下载的Elasticsearch版本二、采用通用搭建集群的方法三、配置三台es1.上传压缩包到任意一台虚拟机中2.解压并修改配置文件(配置单台es)3.配置三台es集群4.设置后台启动和开机自启(可选)一、下载Elasticsearch1.选择你要下载的Elasticsearch版本es下载地址这里我下载的是二、采用通用搭建集群的方法集群搭建方法三、配置三台es1.上传压缩包到任意一台虚拟机中上传方式有两种第一种:使用xftp上传直接拖动过去就可以了。第二种:使用lrzsz先安装yum-yinstalllrzsz切换到要上传的位置cd/opt/
文章目录一.k8s集群修改config1.1备份当前k8s集群配置文件1.2删除当前k8s集群的apiserver的cert和key1.3生成新的apiserver的cert和key1.4刷新admin.conf1.5重启apiserver1.6刷新.kube/config二.安装kubectl2.1下载kubectl2.2配置kubectl三.使用kubernetes-client操作k8s集群3.1依赖3.2注意(可忽略)3.3创建StatefulSet3.4运行shell命令3.5删除StatefulSet3.6线上运行注意一.k8s集群修改config因为默认的是内网IP,复制出来后,
十一、ES集群的相关概念上一篇文章《ElasticSearch-聚合查询》集群(cluster)一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜整合应用索功能。一个集群由一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群节点(node)一个节点是集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引节点和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点索引(Index)一组
一、安装ElasticSearch使用docker直接获取es镜像,执行命令dockerpullelasticsearch:7.7.0执行完成后,执行dockerimages即可看到上一步拉取的镜像。二、创建数据挂在目录,以及配置ElasticSearch集群配置文件,调高JVM线程数限制数量1.创建数据文件挂载目录,然后直接关闭防火墙mkdir-p/home/soft/ESmkdir-p/home/soft/ES/configcd/home/soft/ES创建挂载目录mkdirdata1data2data3进入config文件里面创建es配置文件cdES/config/查询防火墙状态syst
我想用自定义图像更改谷歌地图聚类。但是,它不会改变我提供的任何内容。这个initMap函数是https://developers.google.com/maps/documentation/javascript/marker-clustering然后我尝试用来自谷歌的一些随机图像来更改集群图像。但是,它不呈现任何内容。集群不支持自定义集群镜像??functioninitMap(){varmap=newgoogle.maps.Map(document.getElementById('map'),{zoom:3,center:{lat:-28.024,lng:140.887}});//Cr