字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 Hudi Payload 的合并机制提出的全新解决方案。
字节跳动数据湖团队在实时数仓构建宽表的业务场景中,探索实践出的一种基于 Hudi Payload 的合并机制提出的全新解决方案。
该方案在存储层提供对多流数据的关联能力,旨在解决实时场景下多流 JOIN 遇到的一系列问题。接下来,本文会详细介绍多流拼接方案的背景以及实践经验。
字节跳动存在较多业务场景需要基于具有相同主键的多个数据源实时构建一个大宽表,数据源一般包括 Kafka 中的指标数据,以及 KV 数据库中的维度数据。
业务侧通常会基于实时计算引擎在流上做多个数据源的 JOIN 产出这个宽表,但这种解决方案在实践中面临较多挑战,主要可分为以下两种情况:
场景挑战:指标数据与维度数据进行关联,其中维度数据量比较大,指标数据 QPS 比较高,导致数据可能会产出延迟。
当前方案:将部分维度数据缓存起起来,缓解高 QPS 下访问维度数据存储引擎产生的任务背压问题。
存在问题:由于业务方的维度数据和指标数据时间差比较大,所以指标数据流无法设置合理的 TTL;而且存在 Cache 中维度数据没有及时更新,导致下游数据不准确的问题。
总结上述场景遇到的挑战,主要可归结为以下两点:
针对这些问题,并结合业务场景对数据延迟有一定容忍,但对数据准确性要求比较高的背景,我们在不断的实践中探索出了基于 Hudi Payload 机制的多流拼接方案:
此外,多流拼接方案还支持:
首先简单介绍下本方案依赖 Hudi 的一些核心概念:
这是一个中心化的数据湖元数据管理系统。它基于 Timeline 乐观锁实现并发写控制,可以支持列级别的冲突检查。这在 Hudi 多流拼接方案中能够实现并发写入至关重要,更多细节可参考字节跳动数据湖团队向社区贡献的 RFC-36。
MergeOnRead 表里面的文件包含两种, LogFile (行存) 和 BaseFile (列存),适用于实时高频更新场景,更新数据会直接写入 LogFile 中,读时再进行合并。为了减少读放大的问题,会定期合并 LogFile 到 BaseFile 中,此过程叫 Compact。
针对上述业务场景,我们设计了一种完全基于存储层的多流拼接方案,支持多个数据流并发写入,读时按照主键合并多流数据,此外还支持异步 Compact 来加速下游读取数据。
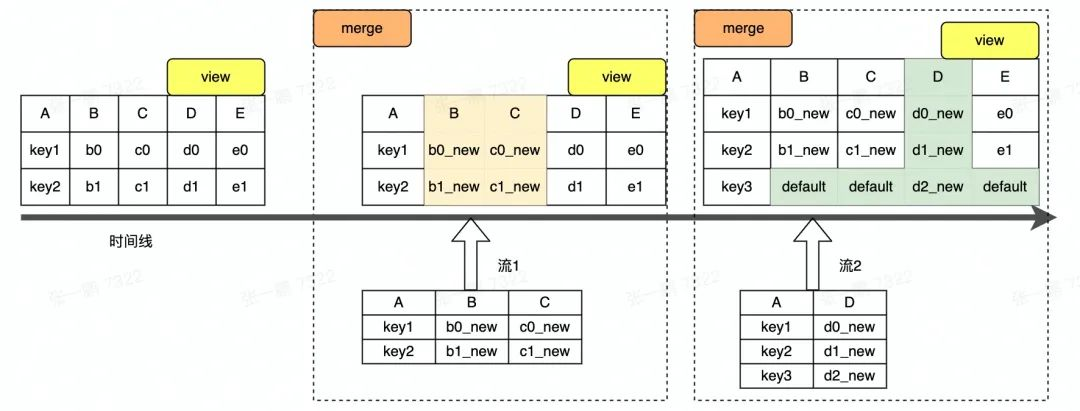
图 1 Hudi 多流拼接概念图(本文所有图中示例数据均与图 1 一致)
现以一个简单的示例流程对方案原理进行阐述,图 1 为多流拼接示意图。图中的宽表包含 BCDE 五列,是由两个实时流和一个离线流拼接而成,其中 A 是主键列,实时流 1 负责写入 ABC 三列,实时 流 2 负责写入 AD 两列,离线流负责写入 AE 两列,此处仅对两个实时流的拼接过程进行介绍。
图 1 中显示两个流写入数据以 LogFile 形式存储,Merge 过程是合并 LogFile 和 BaseFile 中的数据。合并过程中,LogFile 中每一列的值被更新到 BaseFile 中对应的列上,BaseFile 中未被更新的列保持原来的值不变,如图 1 中 BCD 三列被更新成新值,E 列保持旧值不变。
多流数据拼接方案支持多流并发写入,相互独立。对于单个流的写入,逻辑与 Hudi 原有写入流程一致,即数据以 Upsert 的方式写入 Hudi 表,以 LogFile 的形式存储,并在数据写入的过程中对数据去重。在多流写入的场景,核心点在于如何处理并发问题。
图 2 显示了数据并发写入的流程。流 1 和 流 2 是两个并发的任务,检查这两个任务写入的列除了主键以外是不是存在其它交集。例如:
流 1 的 Schema 包含三列 (A,B,C),流 2 的 Schema 包含两列 (A,D)。
在并发写入的时候,先在 Hudi MetaStore 对两个任务发起的 DeltaCommit 做列冲突检查,即除了主键列外的其它列是否存在交集,如图中的 (B,C) 和 (D):
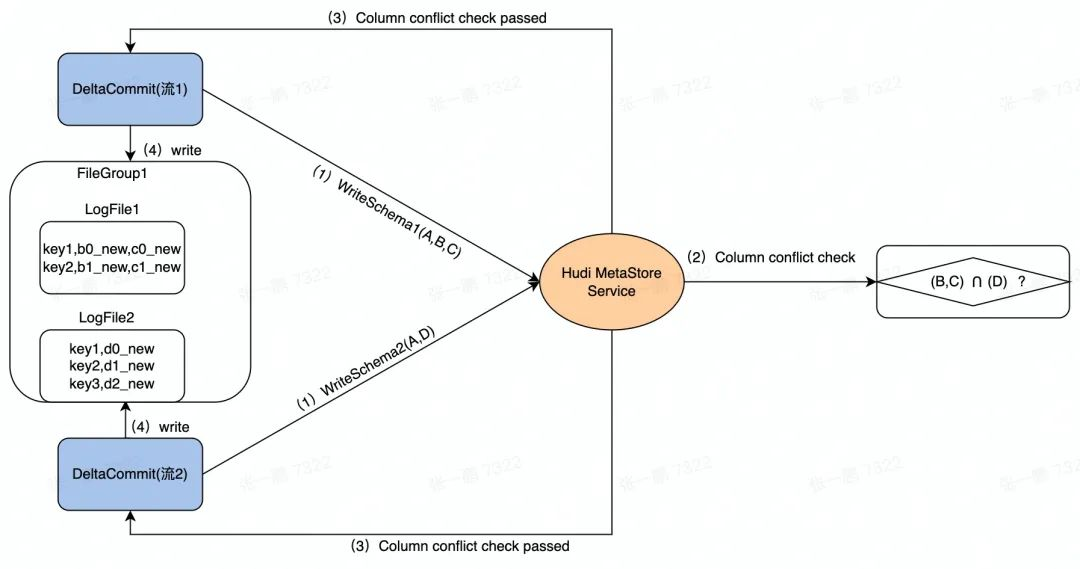
图 2 数据写入过程示意图
接下来,介绍多流拼接场景下 Snapshot Query 的核心过程,即先对 LogFile 进行去重合并,然后再合并 BaseFile 和 去重后的 LogFile 中的数据。图 3 显示了整个数据合并的过程,具体可以拆分成以下 两个过程:
在多流拼接中,因为 LogFile 中存在不同数据流写入的数据,即每条数据的列可能不相同,所以在更新的时候需要判断相同 Key 的两个 Record 是否来自同一个流,是则做更新,不是则做拼接。
如图 3 所示,读到 LogFile2 中的主键是 key1 的 Record 时,key1 对应的 Record 在 Map 中已经存在,但这两个 Record 来自不同流,则需要拼接形成一条新的 Record (key1,b0_new,c0_new,d0_new) 放入 Map 中。
Hudi 现有默认逻辑是对于每一条存在于 BaseFile 中的 Record,查看 Map 中是否存在 key 相同的 Record,如果存在,则用 Map 中的 Record 覆盖 BaseFile 中的 Record。在多流拼接中,Map 中的 Record 不会完整覆盖 BaseFile 中对应的 Record,可能只会更新部分列的值,即 Map 中的 Record 对应的列。
如图 3 所示,以最简单的覆盖逻辑为例,当读到 BaseFile 中的主键是 key1 的 Record 时,发现 key1 在 Map 中已经存在并且对应的 Record 有 BCD 三列的值,则更新 BaseFile 中的 BCD 列,得到新的 Record(key1,b0_new,c0_new,d0_new,e0),注意 E 列没有被更新,所以保持原来的值 e0。
对于新增的 Key 如 Key3 对应的 Record,则需要将 BCE 三列补上默认值形成一条完整的 Record。
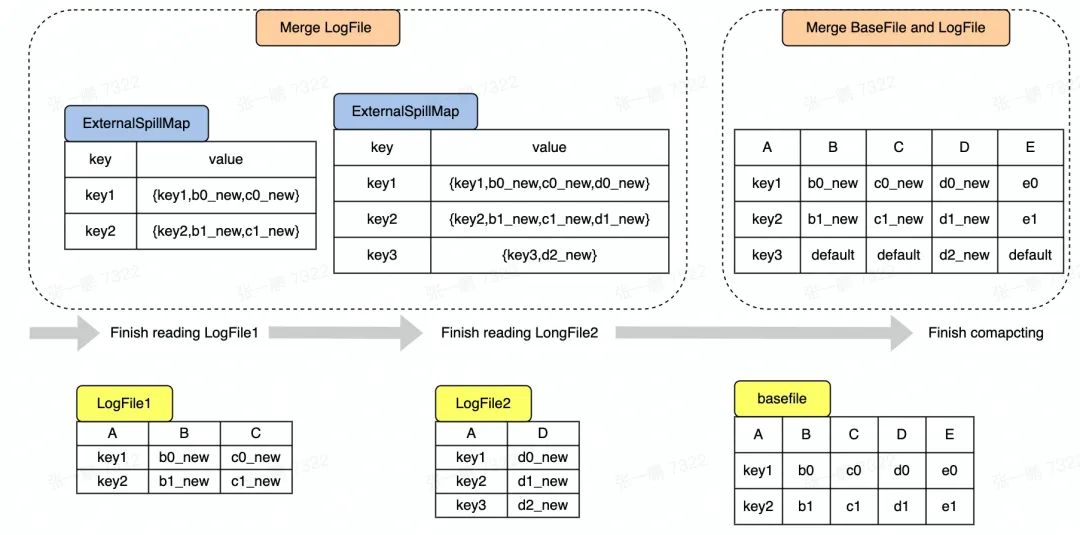
图3 SnapShot Query 中数据合并过程
为了提升读取性能,某些数据源的写入任务会同步执行 Compaction,但实践过程中发现同步执行 Compaction 会阻塞写入任务,而且 Compaction 任务需要资源比较多,可能会抢占流式导入任务的资源。
针对这类场景,通过独立的 Compaction Service 来隔离 Compaction 任务和流式数据导入任务。与 Hudi 本身自带的异步 Compaction 不同的是,用户无需指定要执行的 Compaction Instant,且有一个独立的 Compaction Service 负责所有的表的 Compaction 操作。关于 Compaction Service 的细节就不在本文展开,详情可参考 RFC-43。
具体过程是流式导入任务同步生成 Schedule Compaction Plan,并将 Plan 存入 Hudi MetaStore。有一个独立于流式导入任务的 Async Compactor,它从 Hudi MetaStore 循环拉取 Compaction Plan 并执行。
最终,基于 Hudi 多流拼接的方案,在实时数仓的 DWS 层落地,单表支持了 3+ 数据流的并发导入,覆盖了数百 TB 的数据。
此外,在使用 Spark 对宽表数据进行查询时,在单次扫描量几十 TB 的查询中,性能相比于直接使用多表关联性能提升在 200% 以上,在一些更加复杂的查询下,也有 40-140% 的性能提升。
目前,基于 Hudi 多流拼接方案易用性不足,单个任务至少需要配置超过 10 个参数,为了进一步降低用户使用成本,后续会做部分列插入和更新的 SQL 的语法支持以及参数的收敛。
除此之外,为了进一步提升宽表数据查询性能,还计划在多流拼接场景下支持基于列存格式的 LogFile,提供列裁剪和过滤条件下推等功能。
数据湖团队正在招人,
欢迎关注字节跳动数据平台同名公众号
面向湖仓一体架构的Serverless数据处理分析服务,提供一站式的海量数据存储计算和交互分析能力,完全兼容 Spark、Presto、Flink 生态,帮助企业轻松完成数据价值洞察。点击了解
支持构建开源 Hadoop 生态的企业级大数据分析系统,完全兼容开源,提供 Hadoop、Spark、Hive、Flink 集成和管理,帮助用户轻松完成企业大数据平台的构建,降低运维门槛,快速形成大数据分析能力。点击了解
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
我正在使用Ruby,我正在与一个网络端点通信,该端点在发送消息本身之前需要格式化“header”。header中的第一个字段必须是消息长度,它被定义为网络字节顺序中的2二进制字节消息长度。比如我的消息长度是1024。如何将1024表示为二进制双字节? 最佳答案 Ruby(以及Perl和Python等)中字节整理的标准工具是pack和unpack。ruby的packisinArray.您的长度应该是两个字节长,并且按网络字节顺序排列,这听起来像是n格式说明符的工作:n|Integer|16-bitunsigned,network(bi
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源