 观点一出,直接炸了一波。就连马库斯坐不住了,向其泼了一盆冷水,直言道,是AI的炒作量每18个月翻一番。
观点一出,直接炸了一波。就连马库斯坐不住了,向其泼了一盆冷水,直言道,是AI的炒作量每18个月翻一番。 那么,对于Altman提到的宇宙中智能数量,我们该用什么指标来衡量这种增长?根据现有的研究可以推测,一种拟合的评估方式如下:- 运算能力- 学术刊物- 专利数量- 数据存储
那么,对于Altman提到的宇宙中智能数量,我们该用什么指标来衡量这种增长?根据现有的研究可以推测,一种拟合的评估方式如下:- 运算能力- 学术刊物- 专利数量- 数据存储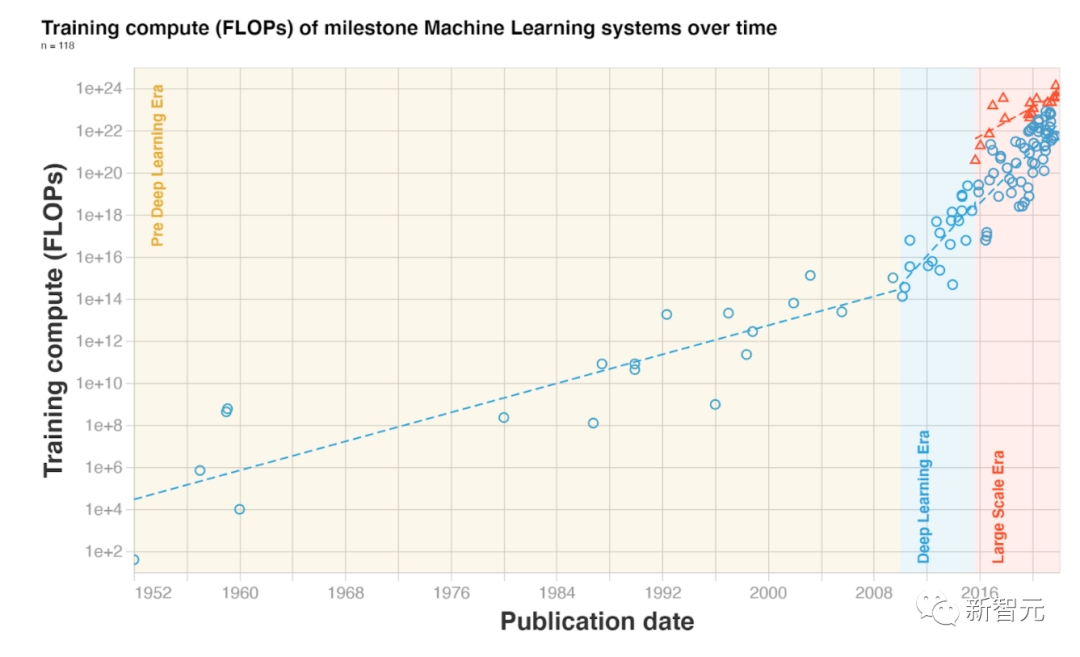 要知道,ChatGPT的诞生,以及人人能够访问ChatGPT背后离不开的是算力。在最新的财报会议上,英伟达CEO黄仁勋称,英伟达的GPU在过去的十年里将AI的处理性能提高了100万倍。摩尔定律在其最好的日子里,可以在十年内实现 100 倍的增长。通过提出新处理器、新系统、新互连、新框架和算法,并与数据科学家、AI研究人员合作开发新模型,在整个跨度中,我们已经使大型语言模型的处理速度提高了一百万倍。换句话说,没有英伟达,就没有ChatGPT。据称,这一模型运行在10,000个英伟达GPU上。像GPT-3这样的大型语言模型需要大量计算能力来进行初始训练。即使是用于训练模型的最大GPU的内存容量也有限,而需要多个处理器并行运行。那么,使用ChatGPT进行实时查询,也是需要多个处理器。英伟达和微软研究论文称,有1750亿参数的GPT-3模型在单个V100上估计训练需要288年。即使我们能够在单个GPU中拟合模型,所需的大量计算也会带来不切实际的漫长训练时间。使用并行运行的处理器是加快速度的最常见解决方案,但也有局限性,因为超过一定数量的GPU,每个GPU的批处理量变得太小,进一步增加数量变得不可行,反而增加了成本。
要知道,ChatGPT的诞生,以及人人能够访问ChatGPT背后离不开的是算力。在最新的财报会议上,英伟达CEO黄仁勋称,英伟达的GPU在过去的十年里将AI的处理性能提高了100万倍。摩尔定律在其最好的日子里,可以在十年内实现 100 倍的增长。通过提出新处理器、新系统、新互连、新框架和算法,并与数据科学家、AI研究人员合作开发新模型,在整个跨度中,我们已经使大型语言模型的处理速度提高了一百万倍。换句话说,没有英伟达,就没有ChatGPT。据称,这一模型运行在10,000个英伟达GPU上。像GPT-3这样的大型语言模型需要大量计算能力来进行初始训练。即使是用于训练模型的最大GPU的内存容量也有限,而需要多个处理器并行运行。那么,使用ChatGPT进行实时查询,也是需要多个处理器。英伟达和微软研究论文称,有1750亿参数的GPT-3模型在单个V100上估计训练需要288年。即使我们能够在单个GPU中拟合模型,所需的大量计算也会带来不切实际的漫长训练时间。使用并行运行的处理器是加快速度的最常见解决方案,但也有局限性,因为超过一定数量的GPU,每个GPU的批处理量变得太小,进一步增加数量变得不可行,反而增加了成本。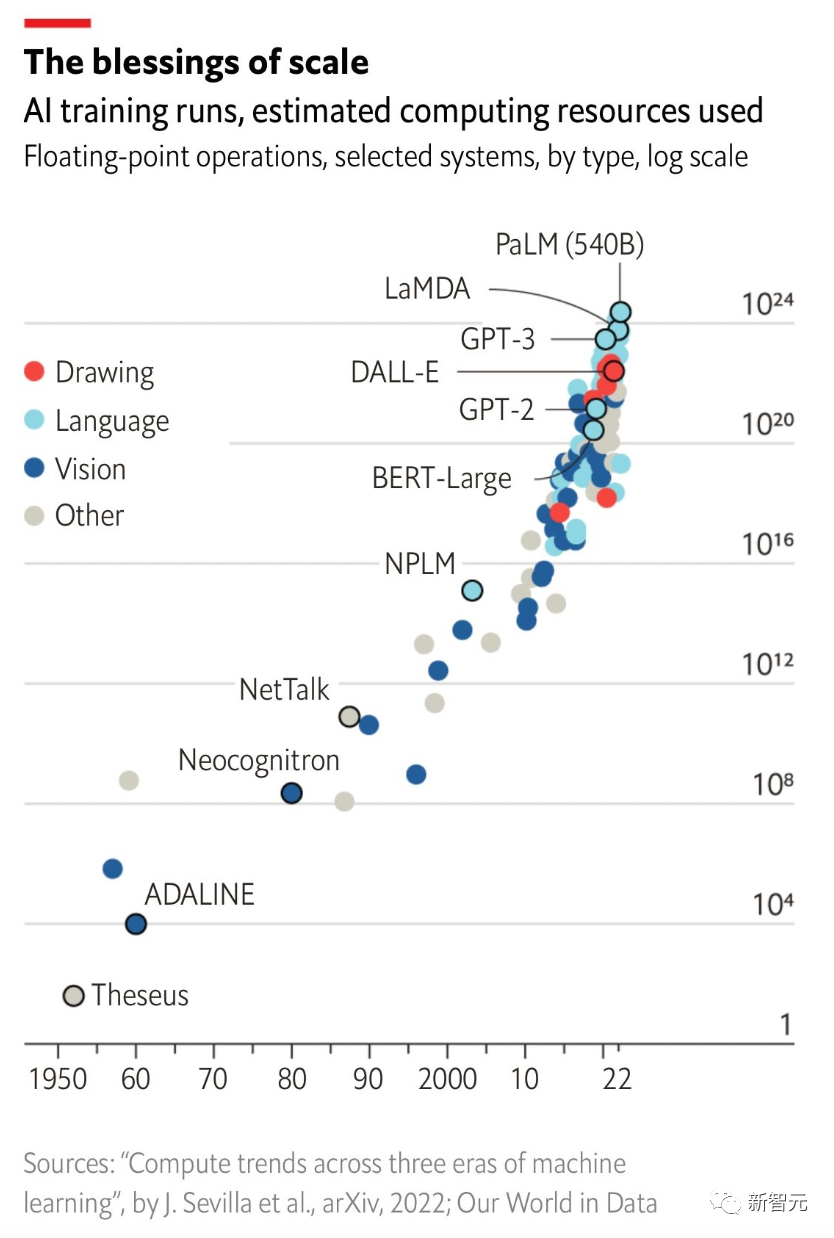 这样一来,GPU的处理能力成为先进人工智能模型的前提。位于爱丁堡大学的超级计算中心,英国电子政务委员会(ePCC)主任Mark Parsons教授称,最大极限是使用大约1000个GPU,而解决这一问题最可行的方法是一台专用的人工智能超级计算机。即使GPU可以变得更快,但瓶颈仍然存在,因为GPU和系统之间的互连不够快。随着GPT和其他大模型不断发展,并行训练的一些难点正在得到解决。
这样一来,GPU的处理能力成为先进人工智能模型的前提。位于爱丁堡大学的超级计算中心,英国电子政务委员会(ePCC)主任Mark Parsons教授称,最大极限是使用大约1000个GPU,而解决这一问题最可行的方法是一台专用的人工智能超级计算机。即使GPU可以变得更快,但瓶颈仍然存在,因为GPU和系统之间的互连不够快。随着GPT和其他大模型不断发展,并行训练的一些难点正在得到解决。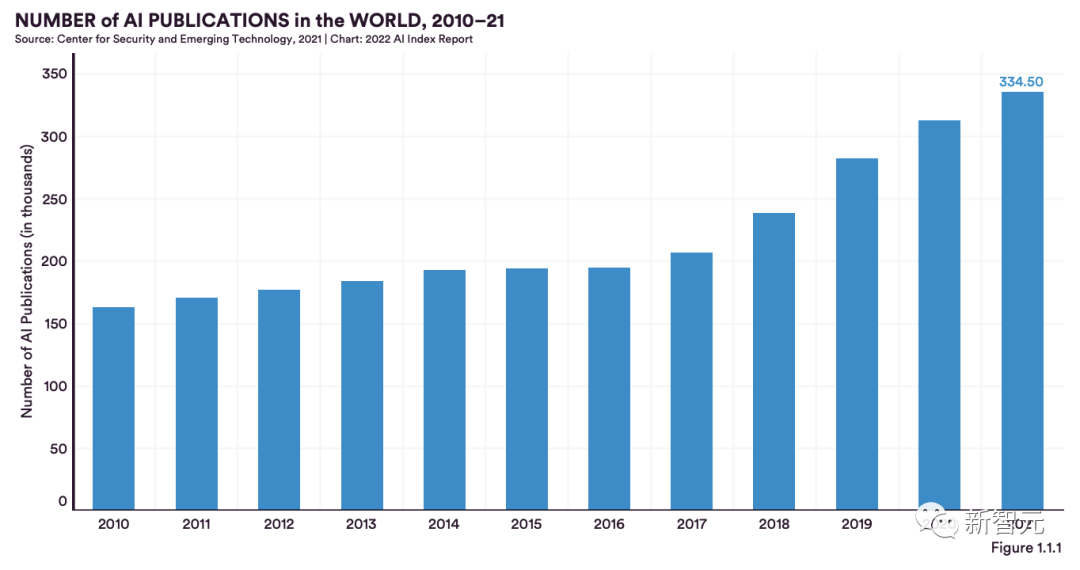 具体而言,模式识别和机器学习领域的论文,仅2015年至2021年的6年间,就实现了倍增。其它诸如计算机视觉、数据挖掘和自然语言处理等领域,保持了比较平稳的发展。在专利方面,根据世界知识产权 (WIPO) 报告,2021年共提交了340万件专利申请,是有史以来最高的年度总数。在全球范围内,专利申请从1995年的100万件增加到2010年的200万件,然后是2016年的300万件。2021年,亚太国家占全球专利申请的三分之二以上,其中中国以近160万件专利申请领先。日本的专利申请总量位居第三,超过28.9万件。在亚太地区之外,美国以略高于590,000的记录位居第二。
具体而言,模式识别和机器学习领域的论文,仅2015年至2021年的6年间,就实现了倍增。其它诸如计算机视觉、数据挖掘和自然语言处理等领域,保持了比较平稳的发展。在专利方面,根据世界知识产权 (WIPO) 报告,2021年共提交了340万件专利申请,是有史以来最高的年度总数。在全球范围内,专利申请从1995年的100万件增加到2010年的200万件,然后是2016年的300万件。2021年,亚太国家占全球专利申请的三分之二以上,其中中国以近160万件专利申请领先。日本的专利申请总量位居第三,超过28.9万件。在亚太地区之外,美国以略高于590,000的记录位居第二。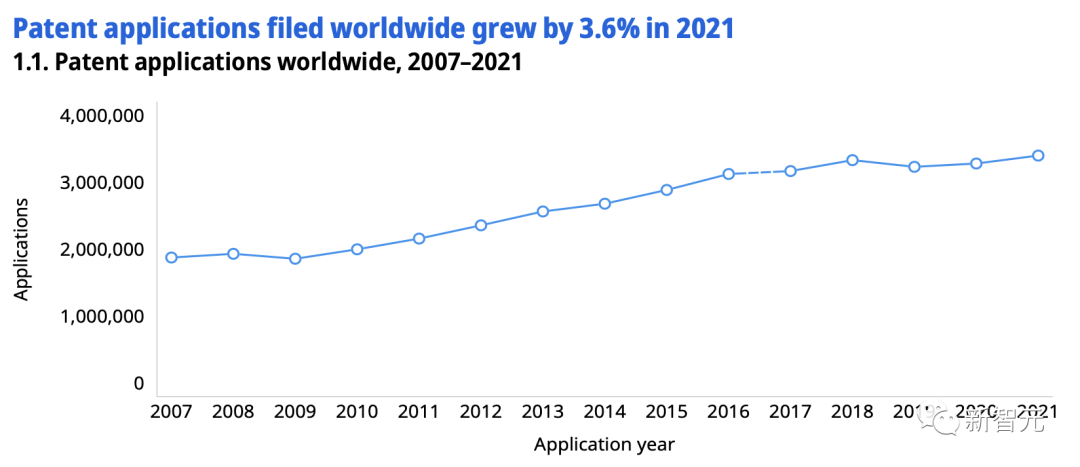
 对于Altman这一句话给大家整的也挺懵圈,智能,到底是什么智能?
对于Altman这一句话给大家整的也挺懵圈,智能,到底是什么智能? 他说的是 「智能」,并没有把增长限制在人工智能甚至软件上。
他说的是 「智能」,并没有把增长限制在人工智能甚至软件上。 有网友端上了Intelligence的定义。
有网友端上了Intelligence的定义。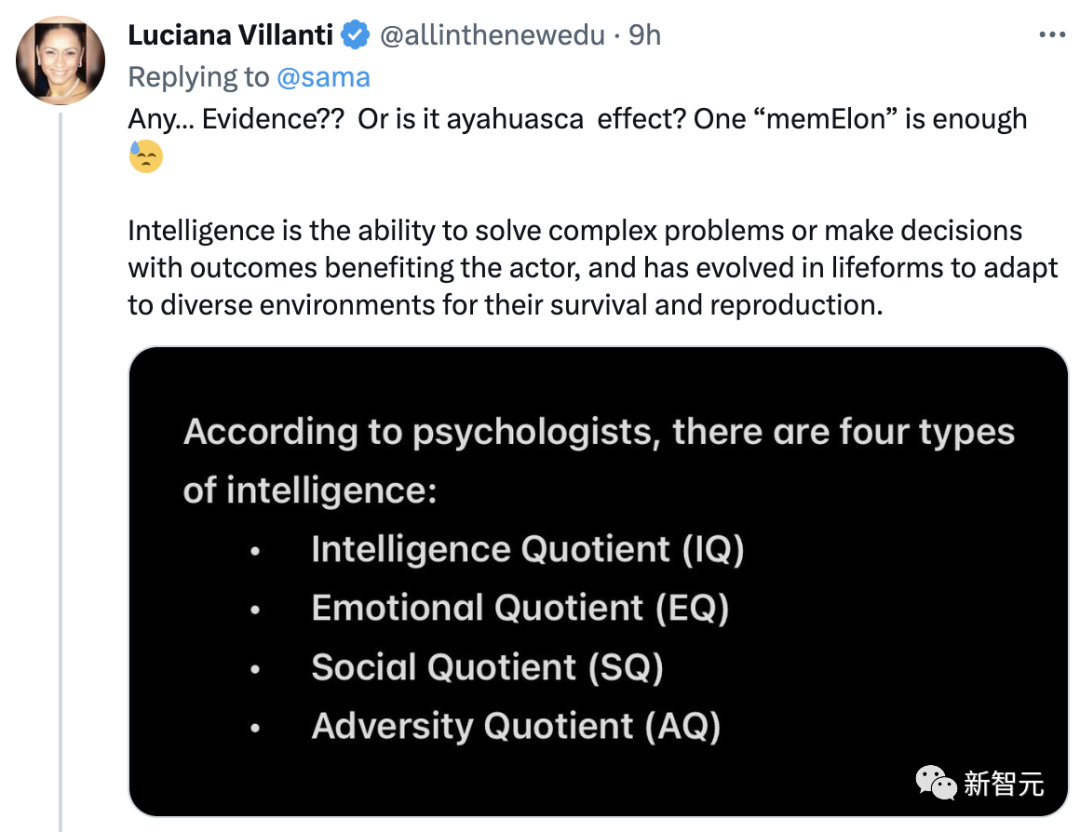 有网友直接将其称为,Altman's Law。
有网友直接将其称为,Altman's Law。
我正在使用i18n从头开始构建一个多语言网络应用程序,虽然我自己可以处理一大堆yml文件,但我说的语言(非常)有限,最终我想寻求外部帮助帮助。我想知道这里是否有人在使用UI插件/gem(与django上的django-rosetta不同)来处理多个翻译器,其中一些翻译器不愿意或无法处理存储库中的100多个文件,处理语言数据。谢谢&问候,安德拉斯(如果您已经在rubyonrails-talk上遇到了这个问题,我们深表歉意) 最佳答案 有一个rails3branchofthetolkgem在github上。您可以通过在Gemfi
我看到这个错误:translationmissing:da.datetime.distance_in_words.about_x_hours我的语言环境文件:http://pastie.org/2944890我的看法:我已将其添加到我的application.rb中:config.i18n.load_path+=Dir[Rails.root.join('my','locales','*.{rb,yml}').to_s]config.i18n.default_locale=:da如果我删除I18配置,帮助程序会处理英语。更新:我在config/enviorments/devolpment
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
大家好!我对我的:username字段进行了一个小的验证,它应该是4到30个字符。我写了一个验证::length=>{:within=>4..30,:message=>I18n.t('activerecord.errors.range')-我想显示一个错误各种错误的消息(不像,太长或太短),但这里有一个问题-我可以将最小值和最大值都传递给翻译,以便有类似的东西:用户名应该在4到30个字符之间。目前我有:range:"shouldbebetween%{count}and%{count}characters",这显然不起作用(只是为了检查)。是否可以从范围中获取这些值?谢谢大家的指教!
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
我正在尝试提取所有包含与当前月份/年份或下一个月年份匹配的字段的账单信息。例如,假设当前月份是2014年12月,我想要这样的内容:Billing.where(exp_month:12,exp_year:2014ORexp_month:1,exp_year:2015)该语法显然不正确,但它让您了解我所追求的。所以,这里的问题是...如何正确设置该查询的格式?如何获取该查询格式的当前/下个月/年份?我正在运行Ruby2.1.2。 最佳答案 Ruby的Date类提供了很多方法:first_of_month=Date.current.beg
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
我正在使用Enumerizegemhttps://github.com/brainspec/enumerize/它允许我以简单的形式使用漂亮的选择。并且此选择中的所有选项均已翻译。en:enumerize:user:sex:male:'Man'female:'Woman'所以,在我的表单中,我选择了变体“男人”和“女人”。当我用“男人”值保存记录时,我得到了“男性”值的性别属性。现在我想在显示页面上将该值显示为“Man”,但是=@user.sex输出为'male'而不是'Man' 最佳答案 我可能会使用.text方法(您可以通过使用
3月26日,映宇宙(HK:03700,即“映客”)发布截至2022年12月31日的2022年度业绩财务报告。财报显示,映宇宙2022年的总营收为63.19亿元,较2021年同期的91.76亿元下降31.1%。2022年,映宇宙的经营亏损为4698.7万元,2021年同期则为净利润4.57亿元;期内亏损(净亏损)为1.68亿元,2021年同期的净利润为4.33亿元;非国际财务报告准则经调整净利润为3.88亿元,2021年同期为4.82亿元,同比下降19.6%。 映宇宙在财报中表示,收入减少主要是由于行业竞争加剧,该集团对旗下产品采取更为谨慎的运营策略以应对市场变化。不过,映宇宙的毛利率则有所提升
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在