spark on yarn 的常用提交命令如下:
${SPARK_HOME}/bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 1g \
--executor-cores 4 \
--num-executors 3 \
--queue default \
${SPARK_HOME}/examples/jars/spark-examples*.jar \
10
提交的应用程序在 AM 中运行起来就是一个 driver,它构建 sparkContext 对象、DAGScheduler 对象、TaskScheduler 对象、将 RDD 操作解析成有向无环图、依据宽窄依赖划分 stage、构建 task、封装 taskSet 等等,这些操作都需要占用内存空间,driver-memory 就是为其分配内存。
rdd 最终被解析成一个个 task 在 executor 中执行,每一个 cpu core 执行一个 task。集群上有 num-executors 个 executor,每个 executor 中有 executor-cores 个 cpu core,则同一时刻最大能并行处理 num-executors * executor-cores 个 task,也就是说这两个参数调整 task 的最大并行处理能力,实际的并行度还跟数据分区数量有关。
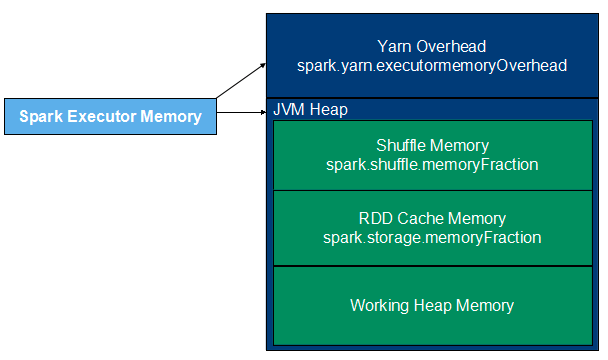
executor 的内存结构如下图所示,由 yarn overhead memory 和 JVM Heap memory 两部分构成,其中 JVM Heap memory 又可分为 RDD cache memory、shuffle memory、work heap 三部分,executor-memory 表示 JVM Heap 的大小。spark 比 mapreduce 速度快的原因之一是它将计算的中间结果保存在内存中,而不是写回磁盘。所以当内存越大时,RDD 就可以缓存更很多的数据、shuffle 操作可以更多地使用内存,将尽量少的数据写入磁盘,从而减少磁盘IO;在task执行时,更大的内存空间意味着更少频率地垃圾回收,从这个点上又能提升性能。当然内存空间也不是越大越好,要大了集群分配不出来,yarn 直接将任务 kill 了,不过一定程度上提高资源的申请的确可以提高任务执行的效率。
充分地利用资源,才能让任务的执行效率更。这个其实也简单,一句话:task 任务的数量和 executor cores 的数量相匹配。假设 executor-cores=4、num-executors=3 则能实现 12 task 并行执行。但如果执行某个 stage 时 task 少于 12 个,这就导致了申请到的资源浪费了,而且执行效率相对低。
# 总数据量 12G 时:
分区 每个分区数据量 使用的 cores 效率
10 1.2G 10 低
12 10G 12 高
Clusters will not be fully utilized unless you set the level of parallelism for each operation high enough.
Spark automatically sets the number of “map” tasks to run on each file according to its size (though you can
control it through optional parameters to SparkContext.textFile, etc), and for distributed “reduce” operations,
such as groupByKey and reduceByKey, it uses the largest parent RDD’s number of partitions. You can pass the
level of parallelism as a second argument (see the spark.PairRDDFunctions documentation), or set the config
property spark.default.parallelism to change the default. In general, we recommend 2-3 tasks per CPU core in
your cluster.
细节自己看了,在 reduce 操作时,例如 reduceByKey 和 groupByKey,可以通过参数修改分区数,也可以在配置文件中使用 spark.default.parallelism 修改分区数。通常,建议每个 CPU core 分配 2-3 个 task,即 task 数量是全部 cores 的 2-3 倍。
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我在rspec中收到来自webkit驱动程序的以下消息:Capybara::Driver::Webkit::WebkitInvalidResponseError:UnabletoloadURL:http://127.0.0.1:44923/posts几天前它成功了。问题出在save_page方法上。有什么问题吗? 最佳答案 当我的页面出现错误时,我收到过类似的错误消息。您应该通过在测试模式下启动服务器(railss-etest)并自行访问页面来手动检查情况是否如此。 关于ruby-on-
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我是ruby的新手,正在配置IRB。我喜欢pretty-print(需要'pp'),但总是输入pp来漂亮地打印它似乎很麻烦。我想做的是默认情况下让它漂亮地打印出来,所以如果我有一个var,比如说,'myvar',然后键入myvar,它会自动调用pretty_inspect而不是常规检查。我从哪里开始?理想情况下,我将能够向我的.irbrc文件添加一个自动调用的方法。有什么想法吗?谢谢! 最佳答案 irb中默认pretty-print对象正是hirb被迫去做。Theseposts解释hirb如何将几乎所有内容转换为ascii表。虽
我想在IRB中浏览文件系统并让提示更改以反射(reflect)当前工作目录,但我不知道如何在每个命令后进行提示更新。最终,我想在日常工作中更多地使用IRB,让bash溜走。我在我的.irbrc中试过这个:require'fileutils'includeFileUtilsIRB.conf[:PROMPT][:CUSTOM]={:PROMPT_N=>"\e[1m:\e[m",:PROMPT_I=>"\e[1m#{pwd}>\e[m",:PROMPT_S=>"FOO",:PROMPT_C=>"\e[1m#{pwd}>\e[m",:RETURN=>""}IRB.conf[:PROMPT_MO