原文首发于微信公众号:实用自然语言处理
作者:风兮
建议查看原文: https://mp.weixin.qq.com/s/nURcYKN6vRBKjbMXAUbEng
关键词: 爬虫、文本数据预处理、数据分析、可视化、自然语言处理
摘要: 本文主要内容,获取解析豆瓣《狂飙》的短评相关数据和演职员信息,在数据预处理后,进行简单的数据分析和可视化展示。
本文全部代码路径: https://github.com/fengxi177/pnlp2023/tree/main/chapter_1
前文 文本数据预处理:可能需要关注这些点 分享了关于文本预处理的理论知识,本文将分享一份示例demo。正好,碰到了热议的电视剧《狂飙》。因此,本文打算从自然语言处理、数据分析和可视化的角度来凑个热闹(原本计划在大结局当天发出来文章,可惜,大结局有一段时间了。拖延了,哈哈哈)。
既然要做电视剧《狂飙》相关的nlp数据分析,那么就先选定数据目标站。经过一圈搜寻对比,发现还是豆瓣中的评论更为客观,参与群体数量多,见解更丰富专业,哈哈哈。因此,本文将获取 https://movie.douban.com/subject/35465232/ 页面中的相关数据。
截止2023年2月28日,豆瓣中电视剧《狂飙》的短评已经22w+(2023年2月6日13w+,评论热度依然很高)。通过翻看短评数据,可以发现不登录状态最多可以获取220条数据,登录后最多可以获取600条数据。一般,可以通过cookie和selenium的方式实现登录,网上有参考教程,自行搜集。
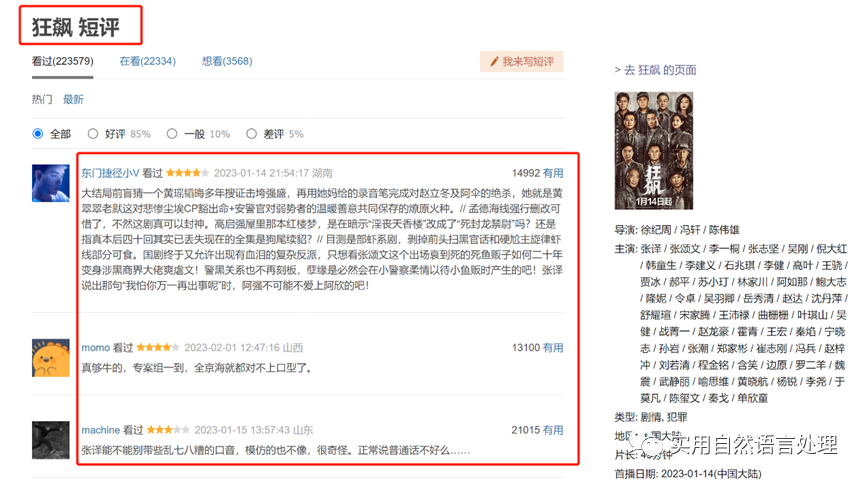
不过,在不登录状态下,通过URL参数设置分析,发现各参数下都可以获得220条数据。因此,本文只获取不登录状态下的数据。具体的,通过好评、中评和差评参数percent_type设置分别获取220条短评及其相关数据。(特别的,仔细观察URL的参数设置还可以获得更多的数据哦。)
def parse_comments(url):
"""
解析HTML页面,获得评论及相关数据
:param url:
:return:
"""
html = get_html(url)
soup_comment = BeautifulSoup(html, 'html.parser')
# 所有获取的一页数据
data_page = []
# 提取评论
comments_all = soup_comment.findAll("div", "comment-item")
for comments in comments_all:
try:
# 解析评论及相关数据
comment_info = comments.find("span", "comment-info") # 评论id相关信息
comment_vote = comments.find("span", "comment-vote") # 评论点赞信息
comment_content = comments.find("span", "short").text.replace("\n", "") # 评论内容
# 提取需要的各字段信息
info_list = comment_info.findAll("span")
star_rating = info_list[1]
user_name = comment_info.find("a").text
video_status = info_list[0].text # 电视剧观看状态
comment_score = int(star_rating["class"][0][-2:]) # 评论分值
comment_level = star_rating["title"] # 评论等级
comment_time = info_list[2].text.replace("\n", "").replace(" ", "") # 评论时间
# print(info_list)
comment_location = info_list[3].text # 评论位置
comment_vote_count = int(comment_vote.find("span", "votes vote-count").text) # 评论被点赞数
# 获取的一条数据
# ["用户名", "电视剧观看状态", "评论分数", "评论等级", "评论时间", "评论位置", "评论点赞数", "评论"]
data_row = [user_name, video_status, comment_score, comment_level,
comment_time, comment_location,
comment_vote_count, comment_content]
data_page.append(data_row)
except:
# 跳过解析异常的数据
continue
return data_page
完整代码:请查看get_comments_data.py文件
此外,本文还获取了《狂飙》的演职员信息数据,页面解析的代码片段如下。
html = get_html(url)
soup_info = BeautifulSoup(html, 'html.parser')
# 获得的结果信息
result_info_dict = {}
# 提取评论
info_all = soup_info.findAll("div", "info")
for info in info_all:
info_name = info.find("span", "name").text
info_role = info.find("span", "role").text
info_works_list = info.find("span", "works").findAll("a")
完整代码:请查看get_celebrity_info.py文件。
文本数据预处理的详细介绍,可以参考文章文本数据预处理:可能需要关注这些点。在实际的应用分析中,数据预处理并不是等数据完全收集完毕后一蹴而就的。通常,在合适的时候进行必要的处理是十分必要的,比如本文在解析爬取数据的时候会进行一些替换和数据转换操作。
词云图作为一种直观、简洁、易于理解的数据可视化方法,通过词云图文字大小、颜色、字体等方式的展示,人们可以迅速了解文本数据中的关键词和主题等有用信息。
本文利用pyecharts生成短评的词云图,其他也可以通过wordcloud包绘制词云图。特别的,可以通过背景图设置生成各种形状的词云图。

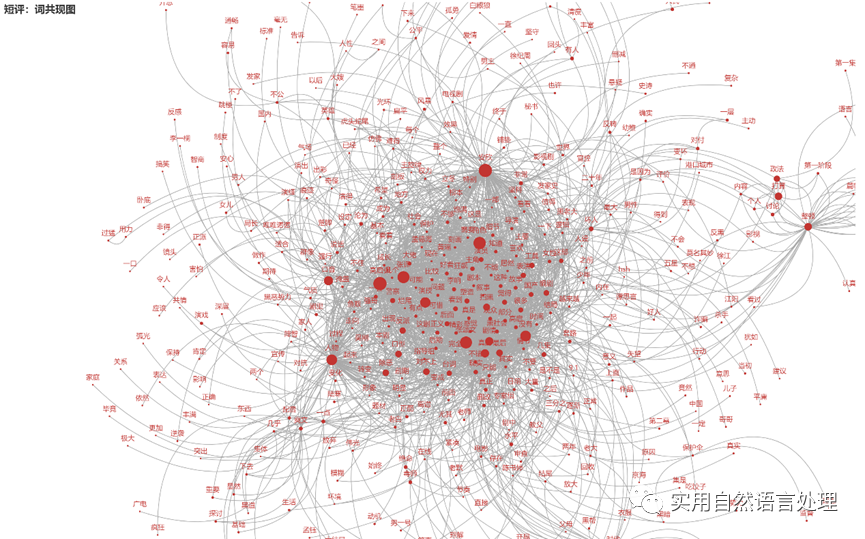
文本中关键词是很重要的特征,关键词共现矩阵网络是一组文本中词或短语之间的共现关系网。该网络可以帮助我们发现文本中的潜在主题、领域和关联性,也可以用于文本数据可视化和分析。共现网络中,每个关键词被表示为一个节点,词之间的共现关系被表示为边,关键词之间的共现频率表示权重。我们可以使用网络分析算法挖掘文本中的相关主题和模式。
利用pyecharts可视化短评top 2000关键词的词共现结果如图所示。
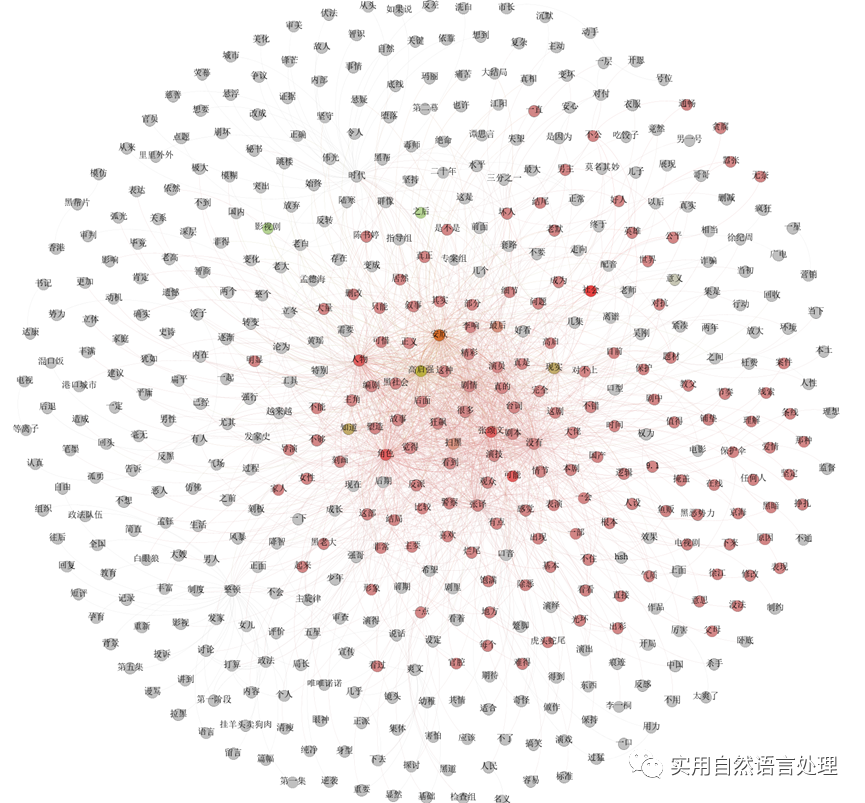
Gephi是一个常用的网络分析和可视化软件,本文同时用gephi可视化了一组top 2000关键词的词共现关系图如下。

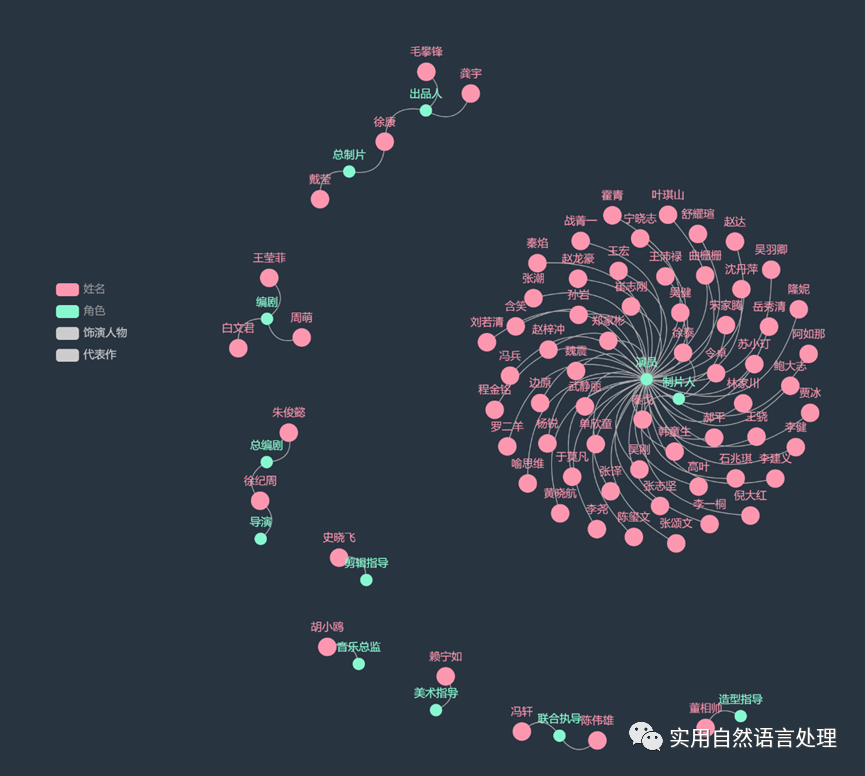
知识图谱是一种将实体、属性、关系等知识以图谱的形式进行表示和存储的技术,可以帮助人们更加直观地了解知识的关联和组织方式。在影视、音乐、文学等领域,知识图谱也被广泛应用于作品分析、人物关系探究方面。
知识图谱的构建需要经过多个阶段,包括实体识别、关系抽取、实体链接等步骤。本文通过爬取《狂飙》的演职员信息,进行数据清洗和处理后,使用pyecharts构建了一个包含演员、导演、编剧、代表作、《狂飙》中的饰演人物等实体,以及他们之间关系的《狂飙》演职员知识图谱,用于展示演职员、作品及饰演人物之间的关系。通过图谱关系展示,可以直观的了解到演员、导演、编剧等之间的合作关系。这些关系的分析可以帮助我们更好地了解影视行业的人际关系网络,感兴趣的朋友可以继续扩展该图谱,探索更多的应用场景。


图谱构建的代码如下:
def generate_celebrity_graph():
"""
构建演职员关系图谱
:return:
"""
df = pd.read_csv("./data/狂飙演职员信息表.csv")
data = df.values.tolist()
# 转换格式
nodes = []
links = []
nodes_name = []
symbolSize_dict = {"姓名": 30, "角色": 20, "饰演人物": 20, "代表作": 20}
categories = [{"name": x} for x in symbolSize_dict.keys()]
for row in data:
# 姓名、角色(";"分割多个)、饰演人物(可能为空)、代表作(";"分割多个)
name, role, role_to_play, works = row
role_list = role.split(";")
works_list = works.split(";")
if name not in nodes_name:
nodes_name.append(name)
# 一个节点
node = {
"name": name,
"symbolSize": symbolSize_dict["姓名"],
"category": "姓名",
}
nodes.append(node)
for role_temp in role_list:
if role_temp not in nodes_name:
nodes_name.append(role_temp)
node = {
"name": role_temp,
"symbolSize": symbolSize_dict["角色"],
"category": "角色",
}
nodes.append(node)
link = {
"source": name,
"target": role_temp
}
links.append(link)
if role_temp == "演员":
if role_to_play not in nodes_name:
nodes_name.append(role_to_play)
node = {
"name": role_to_play,
"symbolSize": symbolSize_dict["饰演人物"],
"category": "饰演人物",
}
nodes.append(node)
link = {
"source": name,
"target": role_to_play
}
links.append(link)
for works_temp in works_list:
if works_temp not in nodes_name:
nodes_name.append(works_temp)
if works_temp == "狂飙":
node = {
"name": works_temp,
"symbolSize": 50, # 特别设置
"category": "代表作",
}
else:
node = {
"name": works_temp,
"symbolSize": symbolSize_dict["代表作"],
"category": "代表作",
}
nodes.append(node)
link = {
"source": name,
"target": works_temp
}
links.append(link)
c = (
Graph(init_opts=opts.InitOpts(theme=ThemeType.CHALK, width="1500px", height="1000px"))
.add(
"",
nodes,
links,
categories,
repulsion=1000,
linestyle_opts=opts.LineStyleOpts(curve=0.6),
)
.set_global_opts(
legend_opts=opts.LegendOpts(pos_left=100, pos_top=350, orient="vertical"),
title_opts=opts.TitleOpts(title="人物关系图谱"),
)
.render("./result/演职员图谱.html")
)
print("演职员关系图谱,保存路径为:./result/演职员图谱.html")
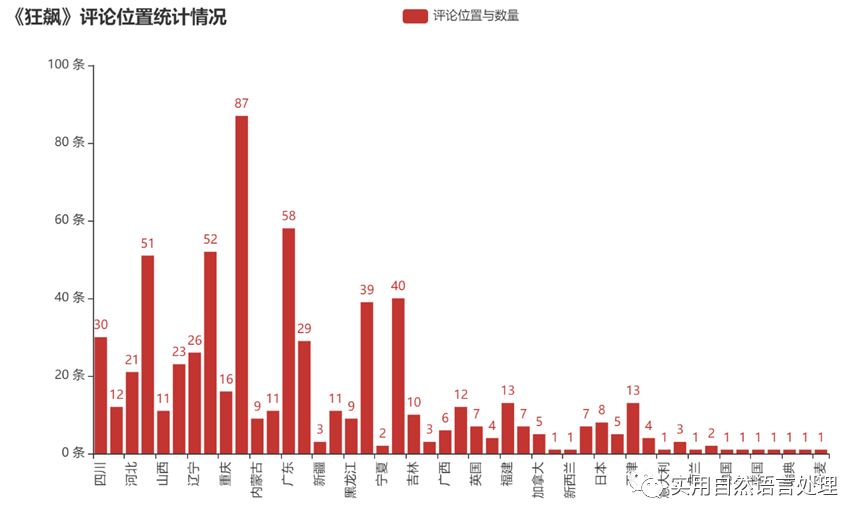
在获取评论的时候,顺便获取了关于评分、评论时间、评论位置和评论点赞数等相关数据。本文对评论位置与评论数量进行了统计分析,并将结果利用pyecharts进行了可视化展示。由柱状图可以直观看到获取评论数据量与地域之间的分布。此外,如感兴趣,还可以对“评分与时间”、“评分与位置”、“评分与点赞数”等关系进行分析,绘制折线图、饼图、地图等可视化效果。
本文通过获取和解析豆瓣电视剧《狂飙》的短评和演职员信息,对这部电影进行了简单的数据分析和可视化展示。感兴趣的朋友,可以继续发散思维、扩展数据,探索发现更多的数据分析和可视化结果。

原文链接:https://mp.weixin.qq.com/s/nURcYKN6vRBKjbMXAUbEng
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
为什么4.1%2返回0.0999999999999996?但是4.2%2==0.2。 最佳答案 参见此处:WhatEveryProgrammerShouldKnowAboutFloating-PointArithmetic实数是无限的。计算机使用的位数有限(今天是32位、64位)。因此计算机进行的浮点运算不能代表所有的实数。0.1是这些数字之一。请注意,这不是与Ruby相关的问题,而是与所有编程语言相关的问题,因为它来自计算机表示实数的方式。 关于ruby-为什么4.1%2使用Ruby返
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我可以得到Infinity和NaNn=9.0/0#=>Infinityn.class#=>Floatm=0/0.0#=>NaNm.class#=>Float但是当我想直接访问Infinity或NaN时:Infinity#=>uninitializedconstantInfinity(NameError)NaN#=>uninitializedconstantNaN(NameError)什么是Infinity和NaN?它们是对象、关键字还是其他东西? 最佳答案 您看到打印为Infinity和NaN的只是Float类的两个特殊实例的字符串
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我刚刚被困在这个问题上一段时间了。以这个基地为例:moduleTopclassTestendmoduleFooendend稍后,我可以通过这样做在Foo中定义扩展Test的类:moduleTopmoduleFooclassSomeTest但是,如果我尝试通过使用::指定模块来最小化缩进:moduleTop::FooclassFailure这失败了:NameError:uninitializedconstantTop::Foo::Test这是一个错误,还是仅仅是Ruby解析变量名的方式的逻辑结果? 最佳答案 Isthisabug,or