
介绍一个关于CSS :nth-child 选择器的新特性。
不知道大家有没有碰到过这样的问题或者需求,从一个特殊的、不可更改的HTML结构中选择出你想要的元素,比如
<h1 class="h1">标题1</h1>
<h1 class="h2">标题2</h1>
<p class="p1">段落1</p>
<p class="p1">段落1</p>
<p class="p2">段落2</p>
<p class="p2">段落2</p><!--想选中这个-->
<p class="p2">段落2</p>
<p class="p3">段落3</p>请问,如何选择第2个.p2标签,如下:

如果不借助 JS,好像并不是很容易?今天一起来探讨这样一个问题
选择第几个元素可以想到nth-child和nth-of-type。
这两个的区别是,nth-child代表的是第几个子元素,而nth-of-type代表的是该标签类型的第几个元素。
直接看例子吧。
:nth-child(2){
color: red
}选中第2个元素。

然后是nth-of-type。
:nth-of-type(2){
color: red
}选择每种元素(h1元素和p元素)的第2个。

如果限制一下类名,是不是好像可以实现我们想要的效果?
.p2:nth-of-type(2){
color: red
}结果...什么都没选中。

为什么会这样呢?其实.p2:nth-of-type(2)可以拆分为:nth-of-type(2)和.p2。
:nth-of-type(2)可以选中每种元素的第2个,也就是.h2和.p1,再结合.p2选择器,注意,这里是“且”的关系,由于两者没有同时满足的,所以什么都没选中,示意如下:

好像并不是我们想象的那样?那有没有办法在所有的.p中再选择第2个呢?
没错,of 关键词就是为了实现这样的功能而产生的,或者说是弥补了nth-child和nth-of-type的不足。
:nth-child() takes a single argument that describes a pattern for matching element indices in a list of siblings. Element indices are 1-based.
通俗意思就是先通过 of 后面的选择器筛选元素,然后再匹配第几个。
:nth-child(<nth> [of <complex-selector-list>]?) {
/* ... */
}比如要实现选择第2个.p2,可以直接这样实现。
:nth-child(2 of .p2){
color: red
}效果如下,刚好是第2个.p2。

原理是这样的。

是不是非常容易?
现在在原先的 dom 中插入其他干扰元素,比如这样的。
<h1 class="h1">标题1</h1>
<p class="p1">段落1</p>
<p class="p1">段落1</p>
<p class="p2">段落2</p>
<p class="p3">段落3</p>
<h2 class="p2">标题段落2</h2>
<p class="p2">段落2</p><!--想选中这个-->
<p class="p3">段落3</p>那么,现在如何选择第2个.p2并且标签为p的元素呢?

如果用of关键词,可以很轻松的实现,只不过需要注意筛选条件p.p2。
:nth-child(2 of p.p2){
color: red
}这样就会跳过h2.p2元素,如下:

其实这个关键词早在 2015 年就已经在Safari上支持了(Safari终于雄起了一回),但直到最近才在Chrome 111上正式支持,足足落后了 8 年啊,如下:
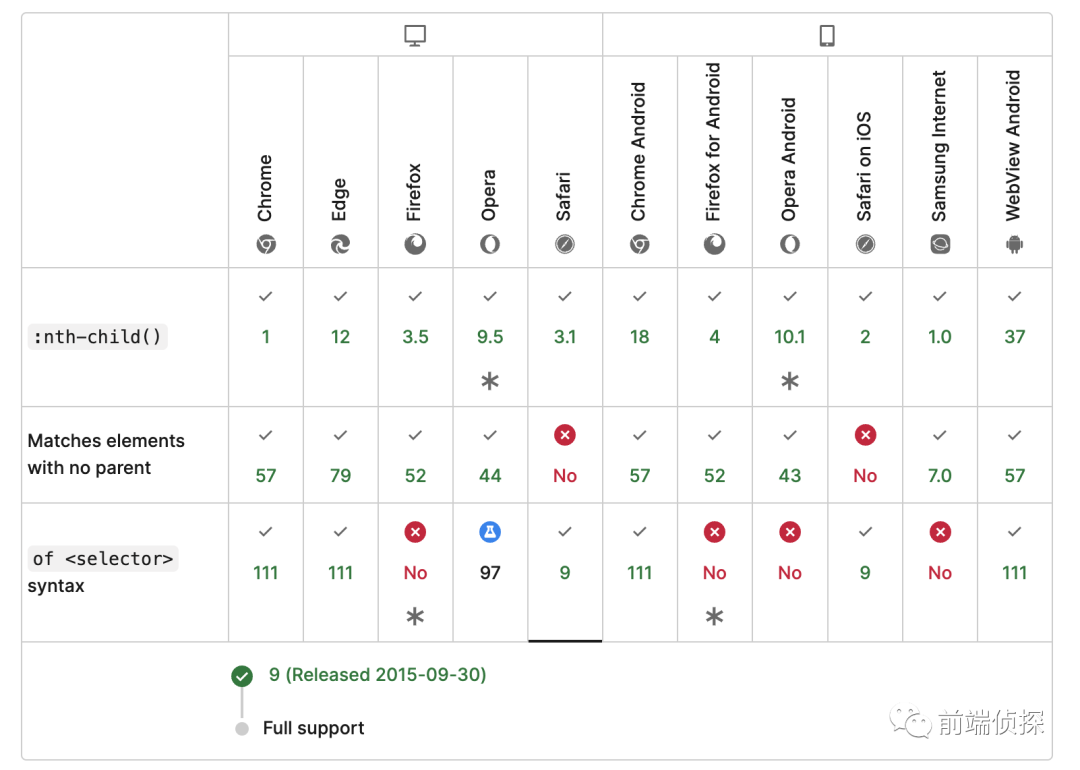
其实没什么好总结的,只需要记住一点,通过of可以提前筛选元素,然后在匹配第 N 个元素,弥补了nth-child和nth-of-type的不足。虽然目前还不能大规模使用,但是一些实验项目或者Electron项目还是可以尝试一下的。
当我使用has_one时,它工作得很好,但在has_many上却不行。在这里您可以看到object_id不同,因为它运行了另一个SQL来再次获取它。ruby-1.9.2-p290:001>e=Employee.create(name:'rafael',active:false)ruby-1.9.2-p290:002>b=Badge.create(number:1,employee:e)ruby-1.9.2-p290:003>a=Address.create(street:"123MarketSt",city:"SanDiego",employee:e)ruby-1.9.2-p290
我正在尝试将以下SQL查询转换为ActiveRecord,它正在融化我的大脑。deletefromtablewhereid有什么想法吗?我想做的是限制表中的行数。所以,我想删除少于最近10个条目的所有内容。编辑:通过结合以下几个答案找到了解决方案。Temperature.where('id这给我留下了最新的10个条目。 最佳答案 从您的SQL来看,您似乎想要从表中删除前10条记录。我相信到目前为止的大多数答案都会如此。这里有两个额外的选择:基于MurifoX的版本:Table.where(:id=>Table.order(:id).
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
我遇到了一些Ruby代码,我试图理解为什么变量在initialize方法声明中的名称末尾有冒号。冒号有什么原因吗?attr_reader:var1,:var2definitialize(var1:,var2:)@var1=var1@var2=var2end 最佳答案 那些是关键字参数。您可以按名称而非位置使用它们。例如ThatClass.new(var1:42,var2:"foo")或ThatClass.new(var2:"foo",var1:42)Anarticleaboutkeywordargumentsbythoughtbot
我正在安装gitlabhq,并且在Gemfile中有对某些资源的“git://...”的引用。但是,我在公司防火墙后面,所以我必须使用http://。我可以手动编辑Gemfile,但我想知道是否有另一种方法告诉bundler使用http://作为git存储库? 最佳答案 您可以通过运行gitconfig--globalurl."https://".insteadOfgit://或通过将以下内容添加到~/.gitconfig:[url"https://"]insteadOf=git://
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
我创建了一个文件,这样我就可以在lib/foo/bar_woo.rb中的许多模型之间共享一个方法。在bar_woo.rb中,我定义了以下内容:moduleBarWoodefhelloputs"hello"endend然后在我的模型中我正在做类似的事情:defMyModel解释器提示它期望bar_woo.rb定义Foo::BarWoo。《使用Rails进行敏捷Web开发》一书指出,如果文件包含类或模块,并且文件使用类或模块名称的小写形式命名,那么Rails将自动加载文件。因此我不需要它。定义代码的正确方法是什么,在我的模型中调用代码的正确方法是什么? 最佳答案
我已经按照https://github.com/wayneeseguin/rvm#installation上的说明通过RVM安装了Ruby.有关信息,我有所有文件(readline-5.2.tar.gz、readline-6.2.tar.gz、ruby-1.9.3-p327.tar.bz2、rubygems-1.8.24.tgz、wayneeseguin-rvm-stable.tgz和yaml-0.1.4.tar.gz)在~/.rvm/archives目录中,我不想在任何目录中重新下载它们方式。当我这样做时:sudo/usr/bin/apt-getinstallbuild-essent
我的Ruby-on-Rails项目中有以下文件结构,用于规范:/spec/msd/serviceservice_spec.rb/support/my_modulerequests_stubs.rb我的request_stubs.rb有:moduleMyModule::RequestsStubsmodule_functiondeflist_clientsurl="dummysite.com/clients"stub_request(:get,url).to_return(status:200,body:"clientsbody")endend在我的service_spec.rb我有:re
Ruby是否支持(找不到更好的词)非转义(逐字)字符串?就像在C#中一样:@"c:\ProgramFiles\"...或者在Tcl中:{c:\ProgramFiles\} 最佳答案 是的,您需要在字符串前加上%前缀,然后是描述其类型的单个字符。你想要的是%q{c:\programfiles\}。镐书很好地涵盖了这一点here,部分是通用分隔输入。 关于ruby-Ruby是否支持逐字字符串?,我们在StackOverflow上找到一个类似的问题: https:/