前言:如题。直接上手撸,附带各种截图,就不做介绍了。
1、influxDB的官网下载地址 https://portal.influxdata.com/downloads/
打开以后,如下图所示,可以选择版本号,以及平台。此处咱们选择windows平台。不过此处没有实际的可以下载的地方,着实比较过分,不过咱们可以另辟蹊径。
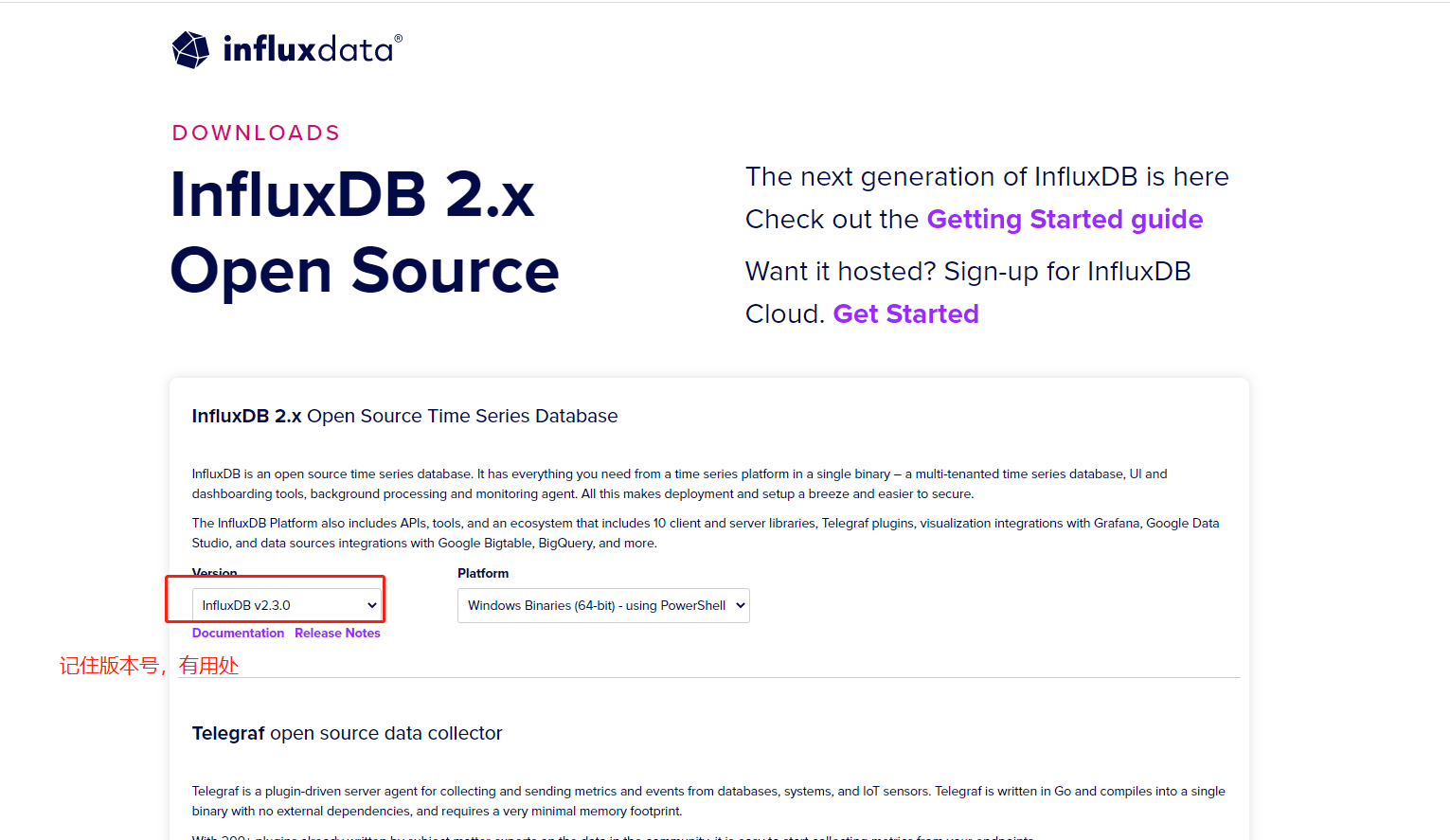
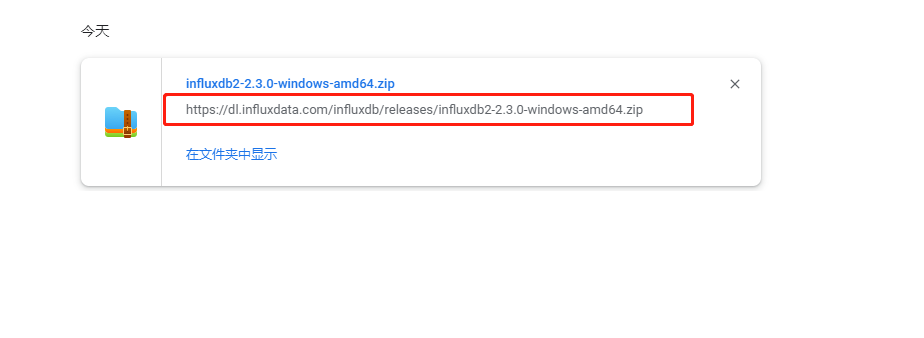
2、直接下载。具体地址如下,2.3.0是版本号:
https://dl.influxdata.com/influxdb/releases/influxdb2-2.3.0-windows-amd64.zip
链接说明:该链接是下载windows版本的influxDB的链接,其中 influxdb2-2.3.0-windows-amd64.zip 里面,2.3.0是版本号,可以通过修改这个版本号来下载你所需要的具体版本文件。
3、或者通过这个地址进行下载:
https://docs.influxdata.com/influxdb/v2.1/install/?t=Windows
其中,/v2.1是版本号,把2.1改成2.3就可以下载2.3的版本了。此处仅做个实验,例如下载2.1版本。

4、可以对比下真实的下载链接地址,与上面的2.3.0版本地址只差了一个版本号信息,其他都一样。
5、此处使用2.3.0版本,解压以后进行使用。
6、CMD到解压的根目录下,直接执行influxdb.exe文件(cmd命令执行,不会闪退,直接点有可能会一闪而过)
备注:也可以通过nssm工具进行部署成Windows服务,部署方法可以参考我的其他博客内容,有相关信息,此处不再重复写。
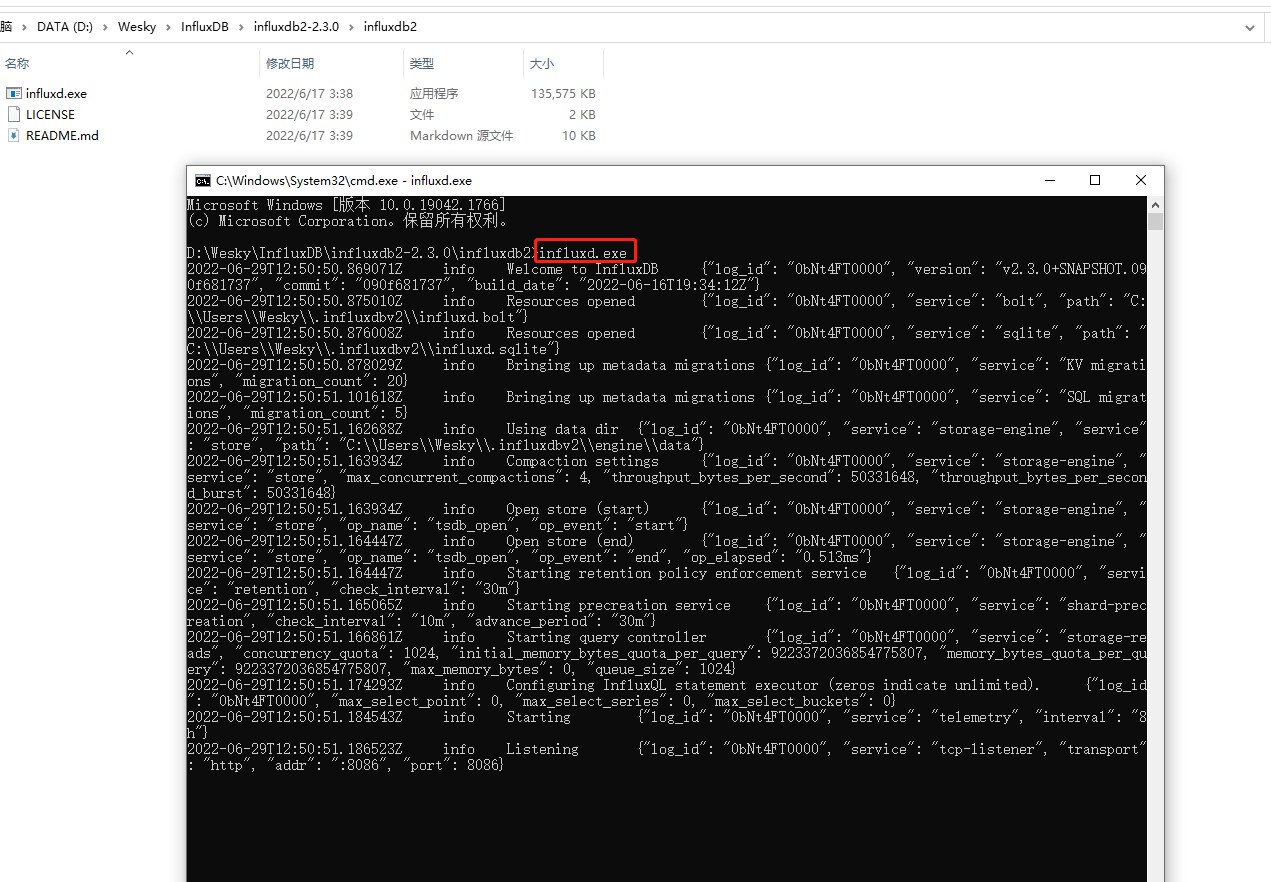
7、启动以后,在cmd窗口也可以看到默认端口号8086,所以在地址栏输入 htp://127.0.0.1:8086/onboarding/ 就可以打开起始监控面板,然后进行一些初始化操作了。
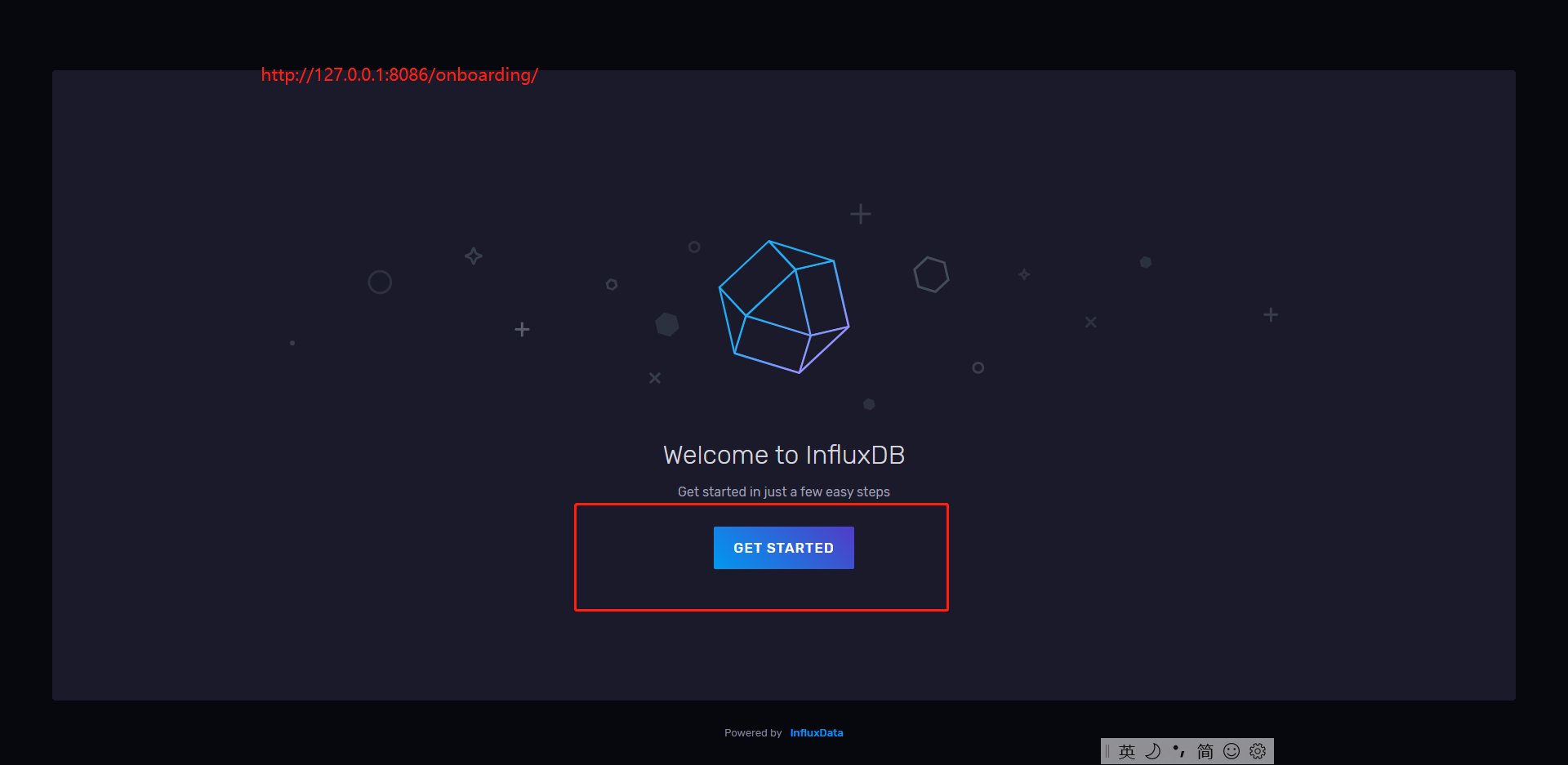
8、打开初始页面,可以用来创建初始用户信息
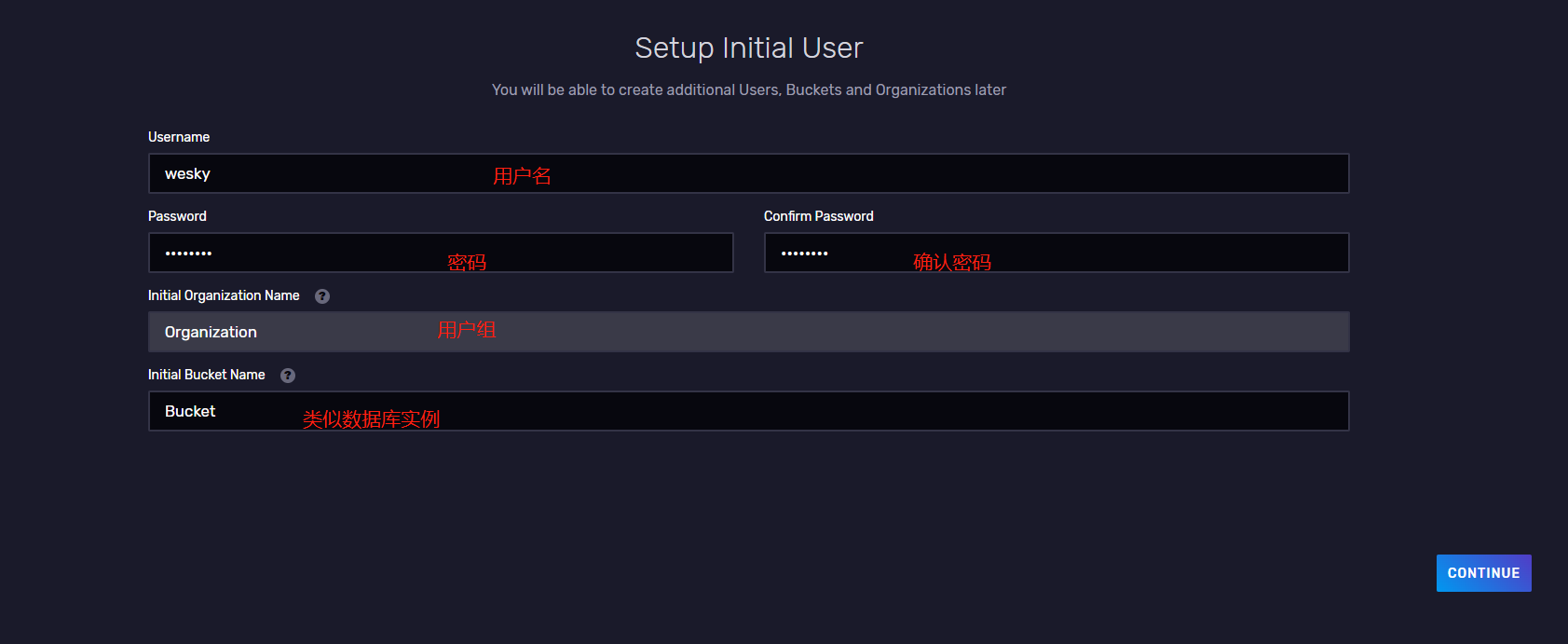
9、例如,我此处创建一个用户 wesky,以及有关的组和实例,如图备注的信息。然后执行下一步(CONTINUE)
10、选择快速开始
11、创建完成以后,进入到主页。
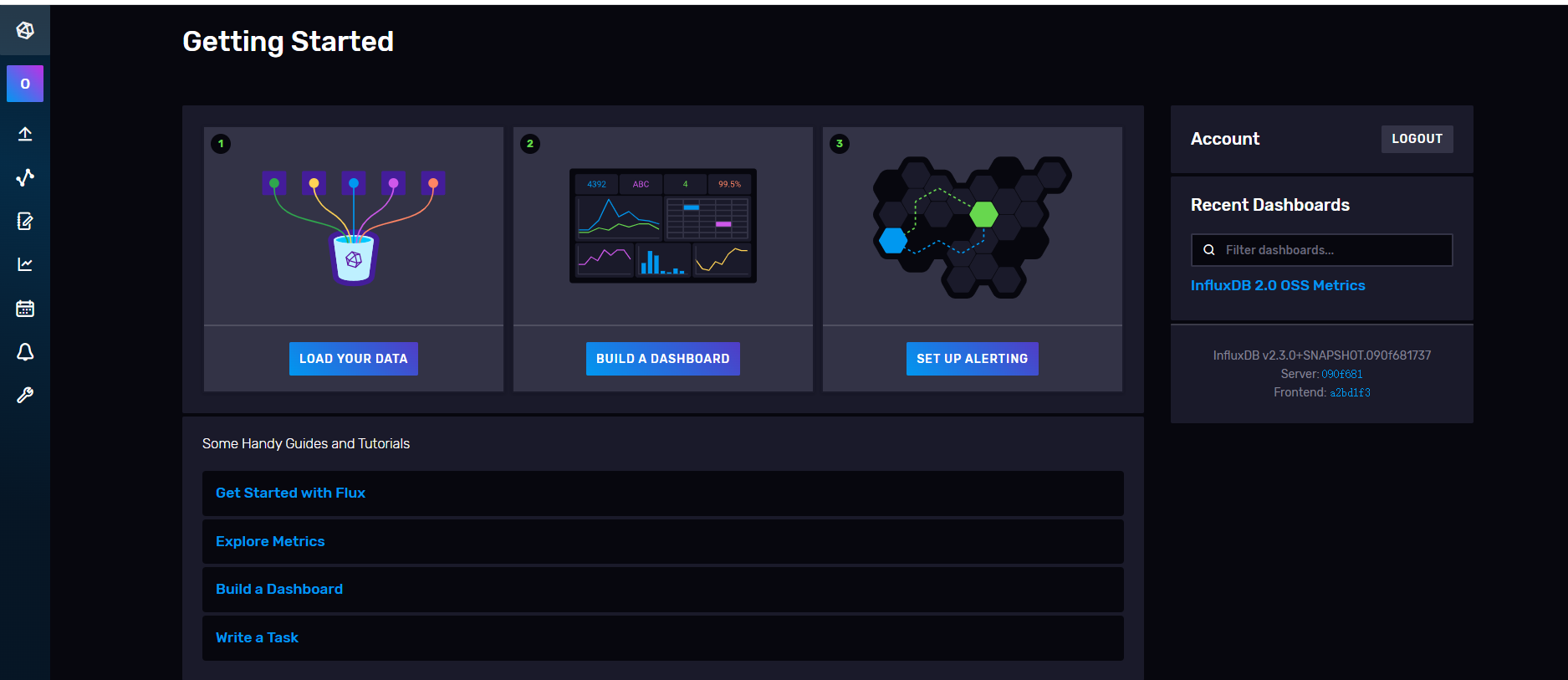
12、可以看到它支持的客户端,包括C#,以及其他很多别的支持。说明还是比较强大了,支持的方案有很多,以及也可以支持从消息队列、系统日志、其他数据库等地方进行导入或写入数据,有待大佬们自己摸索了。

13、找到API TOKENS选项,这里会生成用户的一个唯一token信息,用来写代码时候会用到。

14、点击用户's Token,可以打开具体的token信息
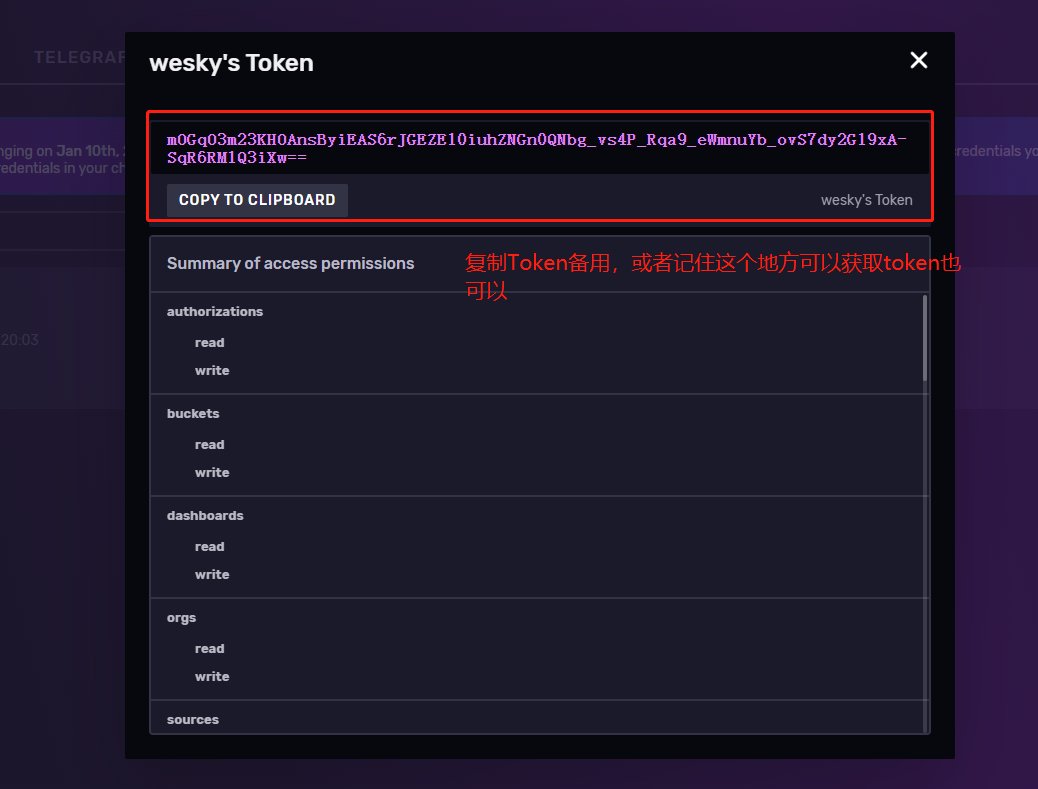
15、找到token信息,可以先拷贝下来备用。或者等下需要的时候,知道在这里寻找也可以。
16、接下来开始写个代码进行演示一下基础操作,当作入个门。创建一个控制台项目,叫InfluxDbTest
17、此处选择.net 6版本环境,当然,大佬们也可以选择其他环境,问题不大的。
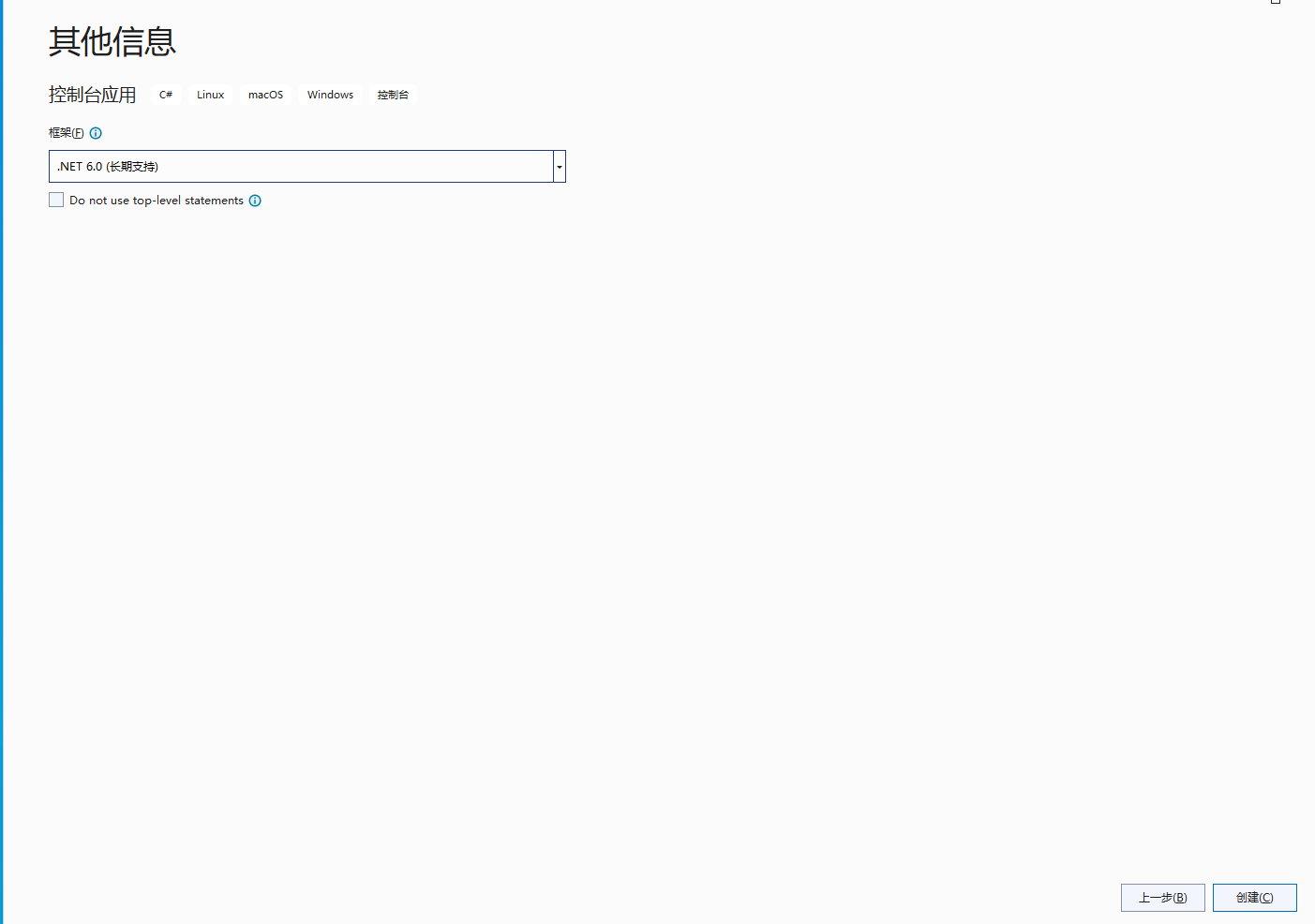
18、创建完成以后,引入nuget包 InfluxDB.Client
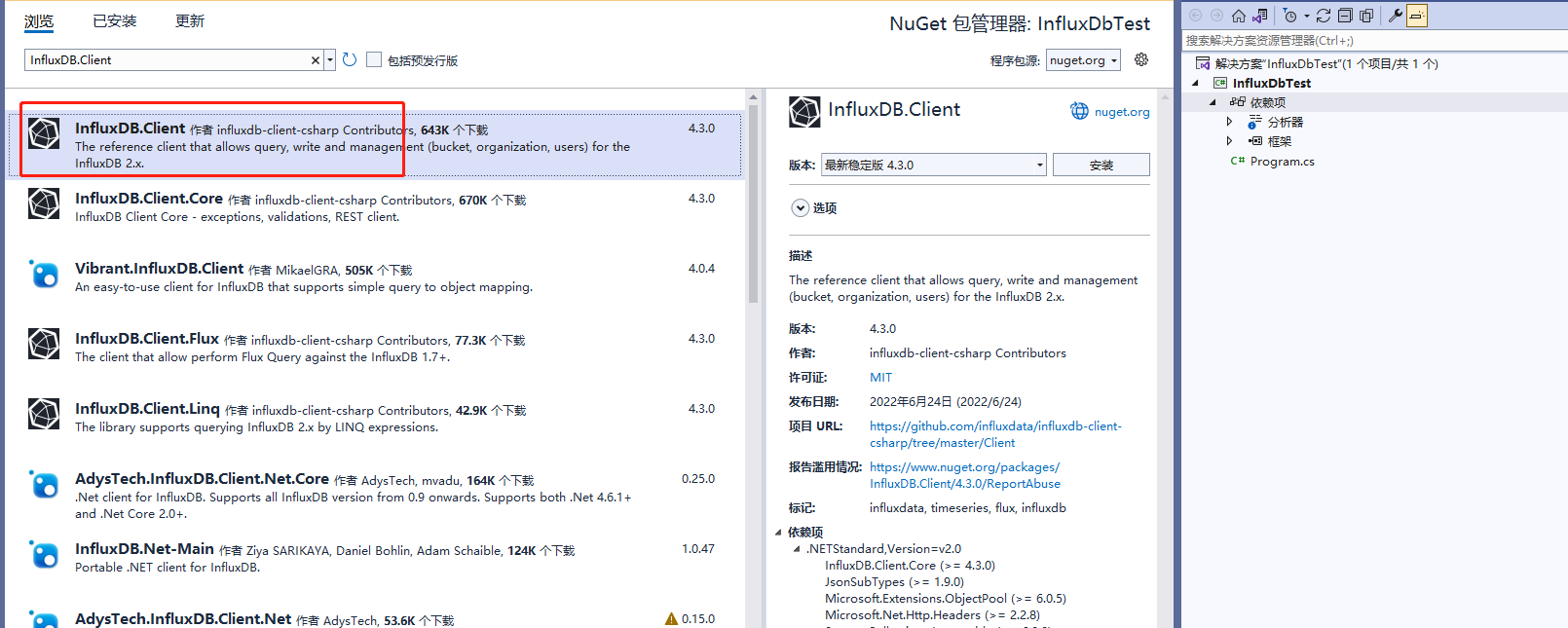
19、写点代码测试一下(源码会附录在文末),此处先创建客户端,然后定义组织、以及实例(Bucket),然后通过写入一个数据进行进行测试(此处手抖了一下,我运行了两次,所以实际写入了两个数据)
备注:写入数据或者读写或者其他操作,也可以参考上面influxdb面板里面提供C#功能的案例里面,点击进去可以看到一些例子。
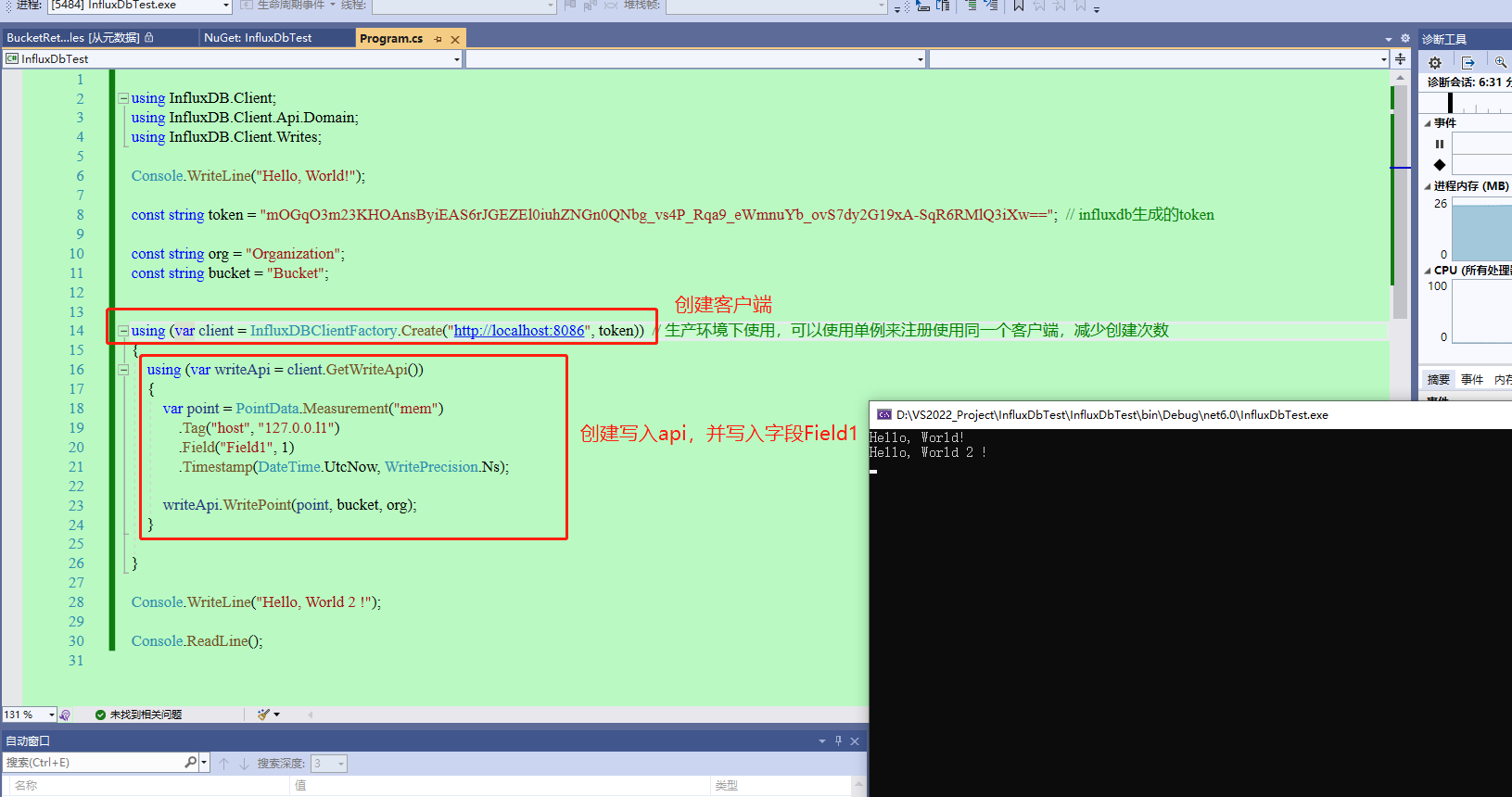
20、如图,可视化面板里面,可以进行数据查询,以及数据可视化。Bucket就是咱们创建的数据库实例,mem就是对应上面的代码里面写的mem,可以当作是一个表,然后是一些标签、字段等。Field是字段,可以自己拓展其他字段等等。
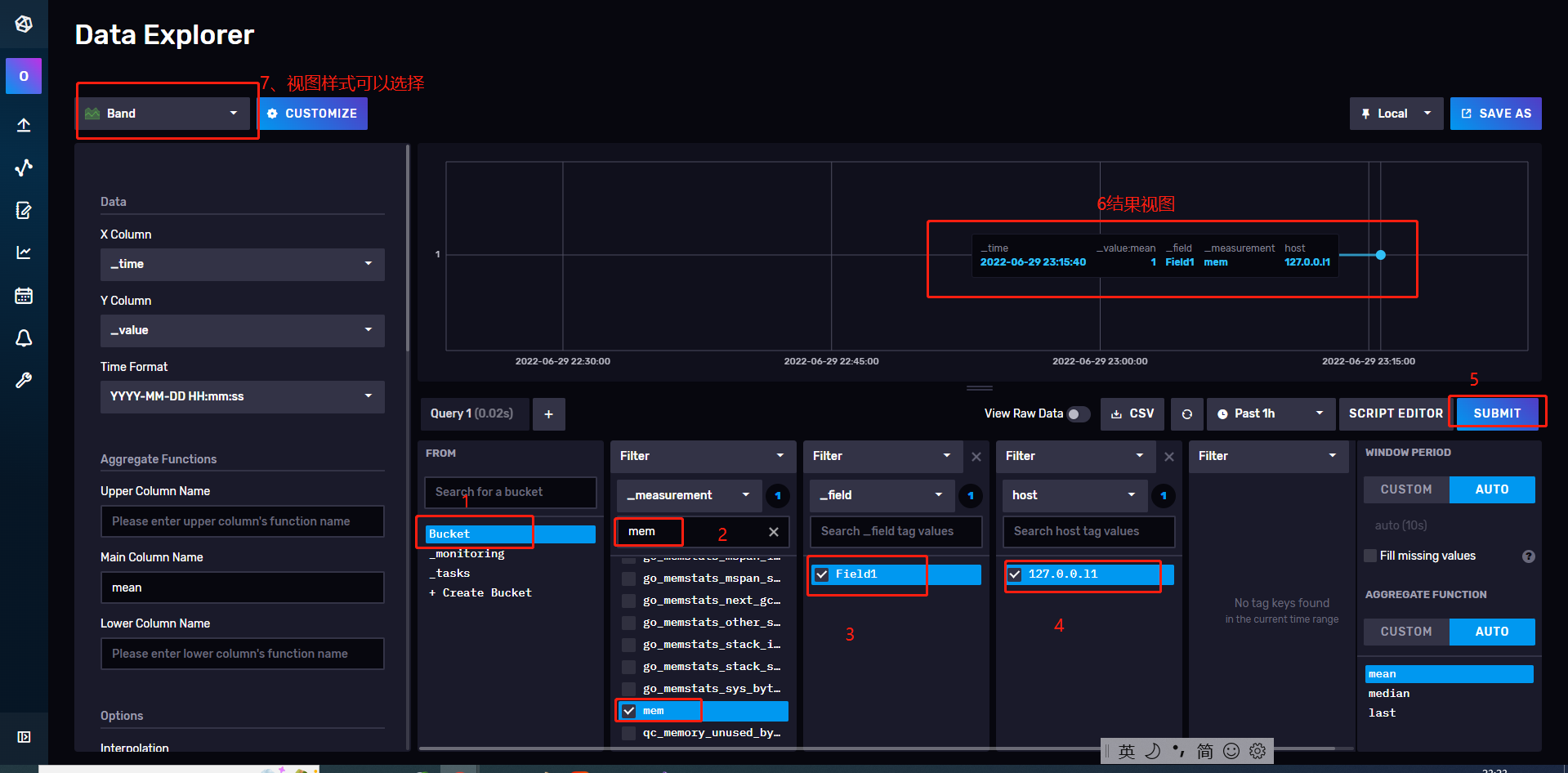
21、写个循环,累加测试一下,改造一下代码,然后继续运行。
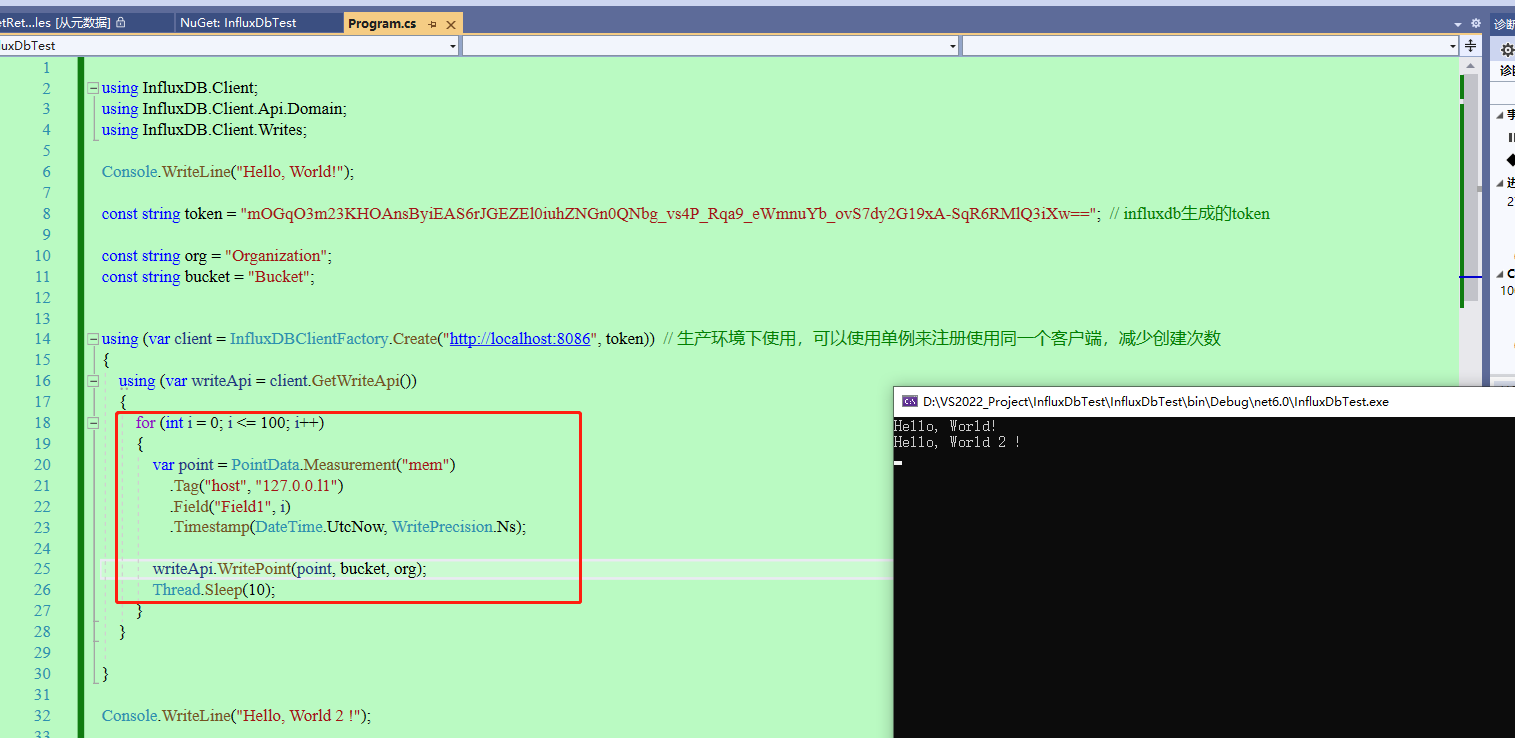
22、可以看到数据一直往上飘,因为值是累加的,所以效果和预期一致。
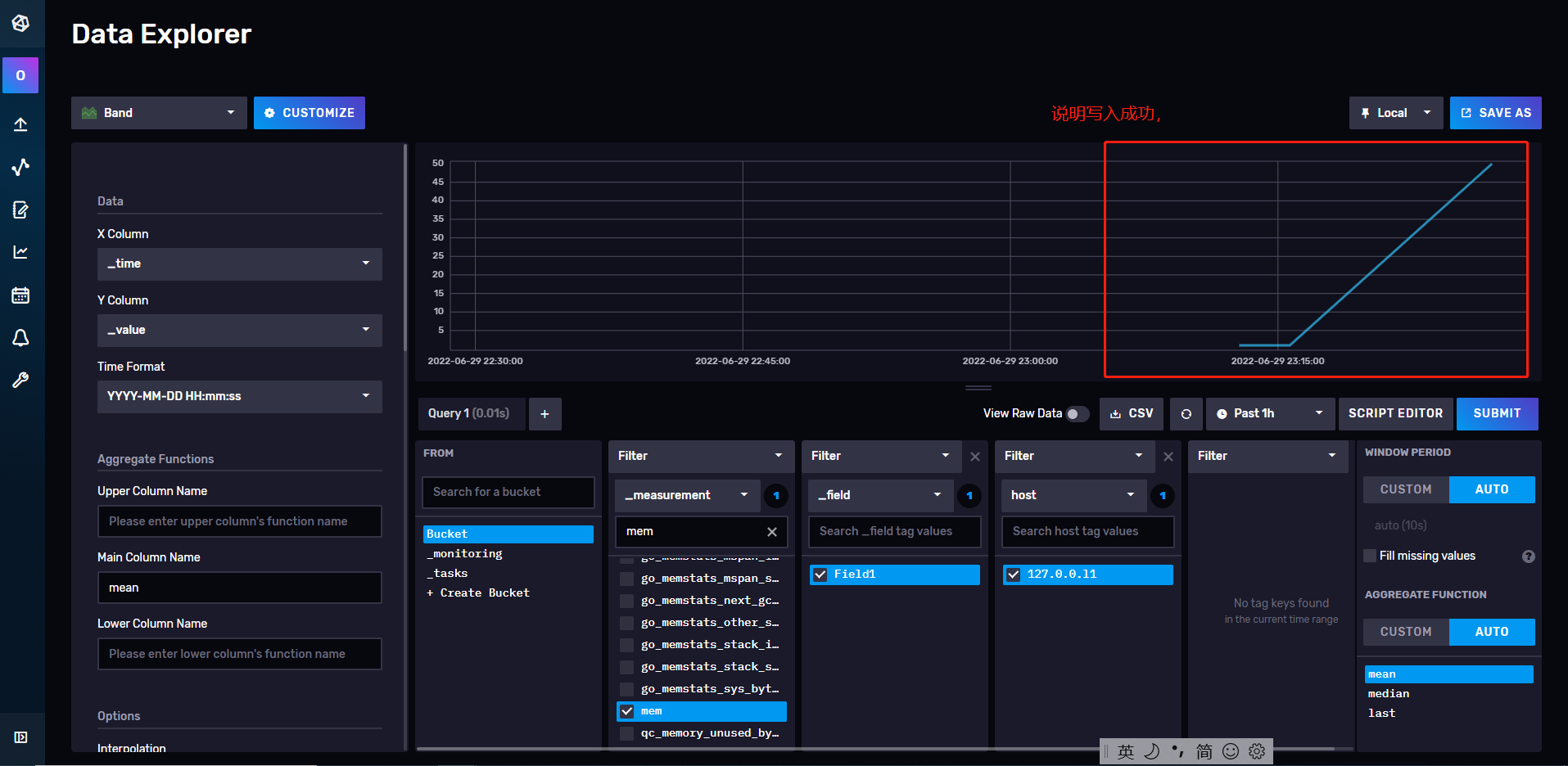
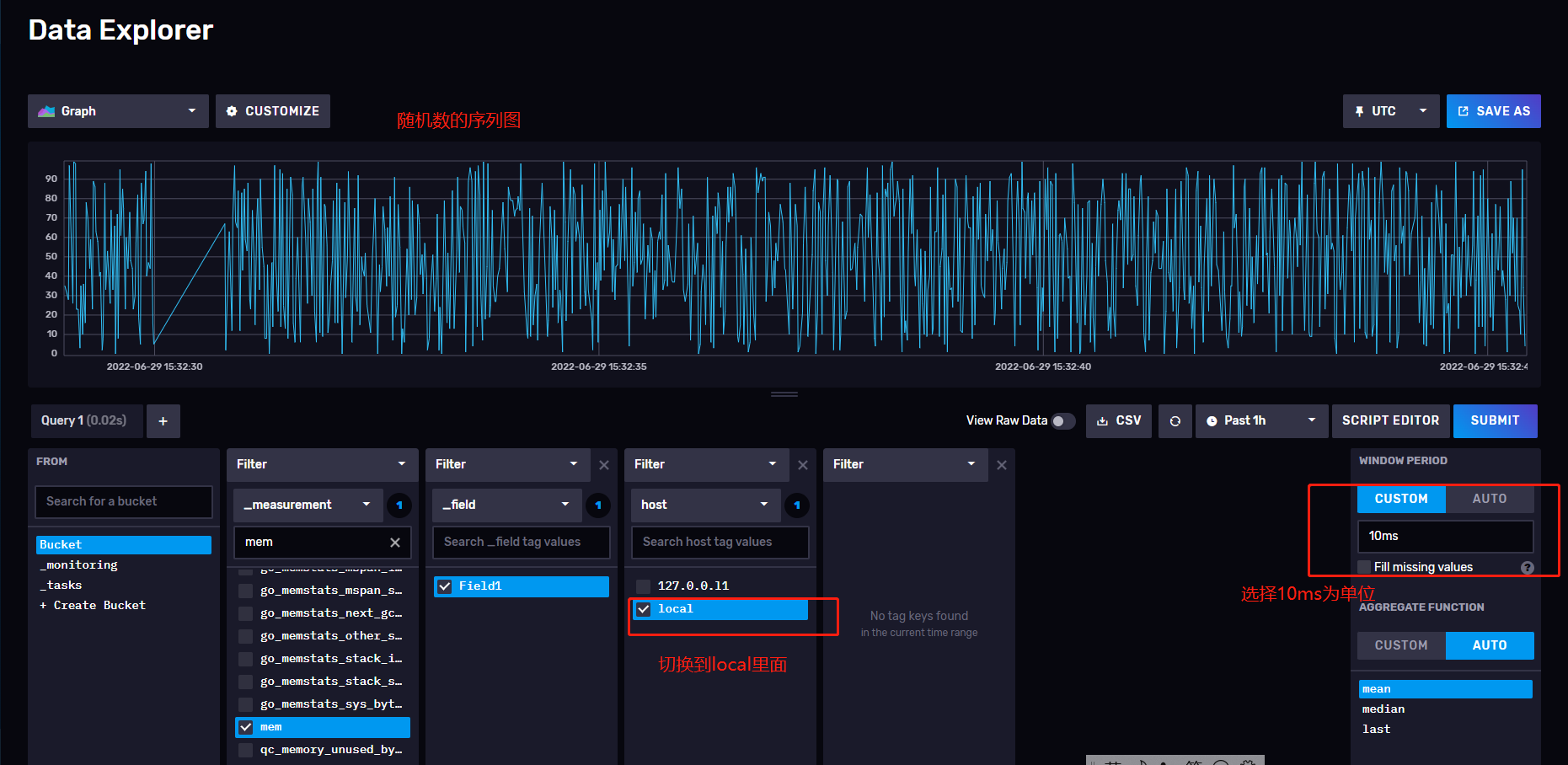
23、来点刺激一点的测试,搞个随机数,可能效果会好玩一点。此处弄个写入0-100的随机数,然后间隔10msx写入一次。
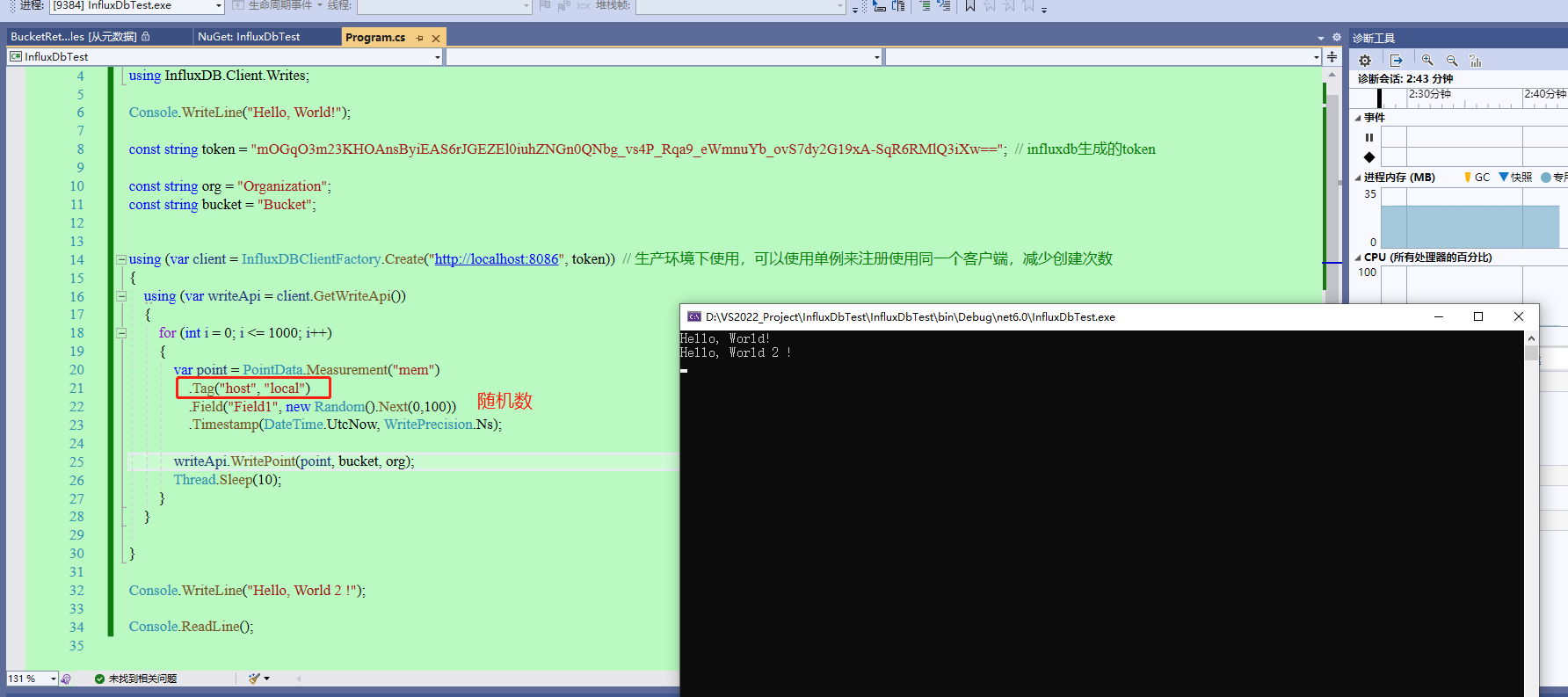
24、让显示的按照10ms为单位进行显示,效果如图,数值都是随机的,所以走势就很花里胡哨了。
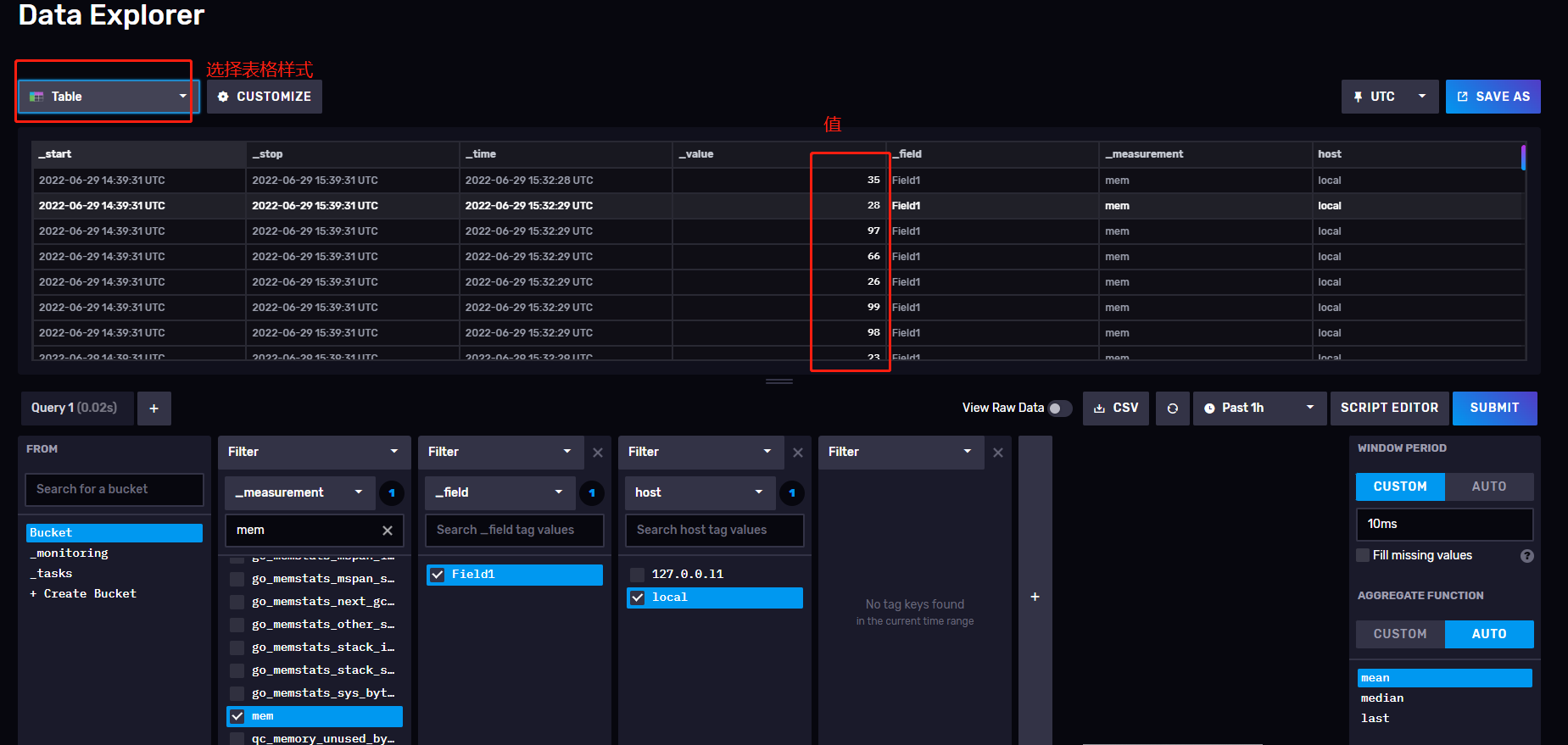
25、展示效果选择表格样式,如图,也是可以的。
有关最终的代码:
using InfluxDB.Client;
using InfluxDB.Client.Api.Domain;
using InfluxDB.Client.Writes;
Console.WriteLine("Hello, World!");
const string token = "mOGqO3m23KHOAnsByiEAS6rJGEZEl0iuhZNGn0QNbg_vs4P_Rqa9_eWmnuYb_ovS7dy2G19xA-SqR6RMlQ3iXw=="; // influxdb生成的token
const string org = "Organization";
const string bucket = "Bucket";
using (var client = InfluxDBClientFactory.Create("http://localhost:8086", token)) // 生产环境下使用,可以使用单例来注册使用同一个客户端,减少创建次数
{
using (var writeApi = client.GetWriteApi())
{
for (int i = 0; i <= 1000; i++)
{
var point = PointData.Measurement("mem")
.Tag("host", "local")
.Field("Field1", new Random().Next(0,100))
.Timestamp(DateTime.UtcNow, WritePrecision.Ns);
writeApi.WritePoint(point, bucket, org);
Thread.Sleep(10);
}
}
}
Console.WriteLine("Hello, World 2 !");
Console.ReadLine();
以上就是该文章的全部内容,时序数据库可以用于工业物联网环境下,特别是对设备数值进行监控,可以很直观看出每个时间区间的状态图、或者步行图等等。欢迎大佬们自行去拓展更加风骚的玩法,此处仅用于入门教程。
如果对你有帮助,欢迎点赞、推荐、或留言。如果对.net 技术感兴趣或比较有想法,也欢迎点击下发QQ群链接加入群组,一起吹牛一起嗨。当然也可以扫下方二维码加我私人微信,我还可以拉你到微信群一起吹牛一起聊技术,也是可以的。如图没找到Q群和微信二维码,说明URL不是最原始的,可以点击原文链接【https://www.cnblogs.com/weskynet/p/16426297.html】进行获取

很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
在控制台中反复尝试之后,我想到了这种方法,可以按发生日期对类似activerecord的(Mongoid)对象进行分组。我不确定这是完成此任务的最佳方法,但它确实有效。有没有人有更好的建议,或者这是一个很好的方法?#eventsisanarrayofactiverecord-likeobjectsthatincludeatimeattributeevents.map{|event|#converteventsarrayintoanarrayofhasheswiththedayofthemonthandtheevent{:number=>event.time.day,:event=>ev
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
这是一道面试题,我没有答对,但还是很好奇怎么解。你有N个人的大家庭,分别是1,2,3,...,N岁。你想给你的大家庭拍张照片。所有的家庭成员都排成一排。“我是家里的friend,建议家庭成员安排如下:”1岁的家庭成员坐在这一排的最左边。每两个坐在一起的家庭成员的年龄相差不得超过2岁。输入:整数N,1≤N≤55。输出:摄影师可以拍摄的照片数量。示例->输入:4,输出:4符合条件的数组:[1,2,3,4][1,2,4,3][1,3,2,4][1,3,4,2]另一个例子:输入:5输出:6符合条件的数组:[1,2,3,4,5][1,2,3,5,4][1,2,4,3,5][1,2,4,5,3][
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我已经构建了一些serverspec代码来在多个主机上运行一组测试。问题是当任何测试失败时,测试会在当前主机停止。即使测试失败,我也希望它继续在所有主机上运行。Rakefile:namespace:specdotask:all=>hosts.map{|h|'spec:'+h.split('.')[0]}hosts.eachdo|host|begindesc"Runserverspecto#{host}"RSpec::Core::RakeTask.new(host)do|t|ENV['TARGET_HOST']=hostt.pattern="spec/cfengine3/*_spec.r
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url