ChatGPT具有多种先进性特征,一经发布备受瞩目,作为一个由OpenAI训练的大型自然语言处理模型,可实现自然语言生成、语言翻译、自然语言理解、语言摘要等一系列功能。发布两个月后月活用户突破1亿,成为史上用户增长速度最快的消费级应用程序。
事实上,ChatGPT的推出正式标志着生成式AI商用元年的到来。生成式AI是通过机器学习方法从数据中学习内容或对象,然后根据学习得到的模型生成全新、完全原创的新内容,目前已被广泛应用于各种领域,如自然语言处理、图像生成、音频生成等。
Gartner预计到2025年,生成式AI将占所有生成数据的10%,目前这一比例还不到1%,生成式AI商用前景广阔,其商业化应用方向主要有:
面向更智能的信息检索和处理。近日,微软宣布将推出整合了ChatGPT的新版Bing搜索引擎,ChatGPT可部分替代搜素引擎功能,根据用户的提问检索已有知识库,提供更直观的回答。未来ChatGPT有望接入Office全套工具,辅助用户对信息进行总结、提取、翻译等。
面向专业领域的垂直服务。生成式AI可广泛应用于电子商务、广告营销、编写代码等专业服务领域,替代部分初级的专业工作,成为人类的助手,帮助企业节约大量的人力成本,提高生产效率。
但是ChatGPT是如何与现有技术融合呢?我们先从ChatGPT+知识图谱、ChatGPT+办公自动化为例入手来看看:
1、ChatGPT+知识图谱
事实性错误是ChatGPT当前存在的一个比较大的问题,其在回答一些问题时候,不可避免的会给人一种"一本正经的胡说八道"的感觉,其解决方式就是如何干预它的方式,引入外部知识进行处理,
一种引入外部知识的方式是在回答过程中并给出链接,虽然回答中事实性存在错误,但通过链接可以进行人工核查,以解决事实性错误问题。
而另一种引入外部知识的方式,就是知识图谱了。知识图谱,是一种基于二元关系的知识库,用以描述现实世界中的实体或概念及其相互关系,基本组成单位是【实体-关系-实体】三元组(triplet),实体之间通过关系相互联结,构成网状结构。
从根本上讲,知识图谱本质上是一种知识表示方式,其通过定义领域本体,对某一业务领域的知识结构(概念、实体属性、实体关系、事件属性、事件之间的关系)进行了精确表示,使之成为某个特定领域的知识规范表示。随后,通过实体识别、关系抽取、事件抽取等方法从各类数据源中抽取结构化数据,进行知识填充,最终以属性图或RDF格式进行存储。
实际上,早年在针对PTM(还不算LLM)的时候,就说PTM(pretrained language model)就是Knowledge base,包含了大量如Knowledge probing等任务来分析和理解,LLM(chatgpt)是参数化的知识。KG优势还是在于方便debugging,人可理解,图结构表达能力强。
但这两点是可以进行结合的,尤其是在推理(常识和领域推理)、业务系统交互、超自动化、时效性内容的接入和更新等方面,有许多结合的实例。
例如,各种图谱任务的text generation映射,KG本身往更多适合符号来做的,包括数值计算,包括规则推理等方向去做深,因为这块对于LLM来说,其实是相对薄弱,或者说学习效率太低。将知识图谱融合到ChatGPT中可以通过多种方式实现。给它足够正确的知识,再引入知识图谱这类知识管理和信息注入技术,还要限定它的数据范围和应用场景,使得它生成的内容更为可靠。
例如,我们可以将知识图谱中的实体和关系表示为嵌入向量,将其作为额外的特征融入到模型中,以提高模型的性能。这种方法可以将知识图谱的结构信息和语义信息都融合到模型中,使得模型能够更好地理解和生成自然语言文本。
在对话中,知识图谱可以帮助模型理解对话的上下文,为回答问题提供更准确的信息。在LaMDA论文中,就使用了知识图谱来提供对话的上下文信息。通过结合知识图谱的信息,可以自动生成问题,从而帮助用户更好地理解实体和关系之间的语义和上下文。
百度在日前正式发布了生成式大语言模型“文心一言”,以及其底层的“文心大模型”(Ernie 3.0)就结合了知识图谱。在文心之前,大部分LLM大模型使用纯文本数据。例如1750亿个参数的GPT-3的语料库中有570GB来自普通爬网的过滤文本。这些原始文本缺乏语言知识和世界知识等知识的明确表达。此外,大多数大型模型都是以自回归的方式进行训练的,在适应下游语言理解任务时,此类模型在传统微调的情况下表现出较差的性能。
从理论上讲,引入知识图谱,将极大增强文心在下游应用上理解问题、解决实际问题的表现。因此文心3.0使用了纯文本加上大规模知识图谱组成的4TB语料库作为训练数据,同时采用各种类型的预训练任务,使模型能够更有效地学习由有价值的词汇、句法和语义信息组成的不同层次的知识。其中预训练任务传播了三种任务范式,即自然语言理解、自然语言生成和知识提取。文心3.0在few-shot和zero-shot任务中表现出相较之前大模型的优势,使其各项指标超过了当时的SOTA模型,在Super GLUE基准测试中获得第一名。
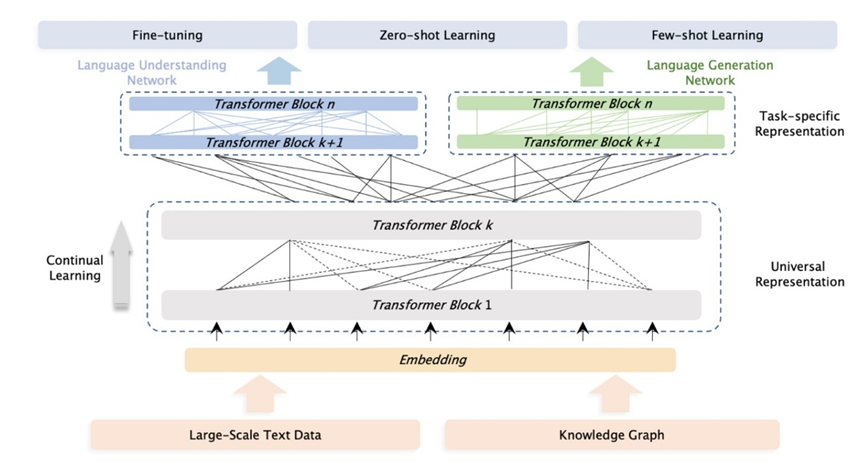
另一方面,ChatGPT在zero-shot/few-shot上面的优秀表现,实际上也可以反馈到知识图谱构建的整个流程当中,例如利用ChatGPT进行实体识别、关系抽取以及事件抽取,这可以在一定程度上缓解知识图谱在落地过程中的高成本难题。
不过,ChatGPT遇到的事实性错误和时效性问题,知识图谱同样存在。知识图谱也需要解决知识更新的问题。而且知识图谱如果不能保证非结构化数据源的正确性,到后面也注定会发生事实性错误,这无疑需要引起重视。
2、ChatGPT+办公自动化
在办公自动化场景,目前已经有多种ChatGPT结合的现象级的应用出现,例如:
ChatPDF,可以先对上传的PDF进行分析,为文件中每个段落创建语义索引。当用户提出一个问题后,工具就会把关联语段发送给ChatGPT,然后让它结合问题进行解读;
ResearchGPT,可以直接上传要看的论文PDF或者链接之后,就可以显示论文原文,右侧可以直接问它问题。
DocsGPT,这一工具简化了在项目文档中查找信息的过程。通过集成强大的GPT模型,开发人员可以轻松地提出关于项目的问题并得到准确的答案。
ChatExcel,这一新应用可以直接使用自然语言对表格中的数据信息进行查询、修改等操作,就像是一个精通Excel的助手。
不过,我们可以清晰的看到,在这些“ChatGPT+办公自动化“工具的背后,实际上有一个文档标准化和规范化处理的模块在进行支撑,有效的处理当前复杂格式的文档,如word/pdf/doc/excel等进行规范化处理,扫描版pdf等的处理,并以此作为输入。与ChatGPT进行结合,可以极大的提升其产品性能和用户体验。
好啦,今天就说到这。我们预计,业界将会紧跟ChatGPT这个技术点,结合各类相关技术和最终应用场景,探索出更多可能。
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
我遇到了ruby正则表达式的问题。我需要找到所有(可能重叠的)匹配项。这是问题的简化:#Simpleexample"Hey".scan(/../)=>["He"]#Actualresults#Withoverlappingmatchestheresultshouldbe=>["He"],["ey"]我尝试执行并获得所有结果的正则表达式如下所示:"aaaaaa".scan(/^(..+)\1+$/)#Thislooksformultiplesof(here)"a"biggerthanonethat"fills"theentirestring."aa"*3=>true,"aaa"*2=
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。我最近开始学习Ruby,这是我的第一门编程语言。我对语法感到满意,并且我已经完成了许多只教授相同基础知识的教程。我已经写了一些小程序(包括我自己的数组排序方法,在有人告诉我谷歌“冒泡排序”之前我认为它非常聪明),但我觉得我需要尝试更大更难的东西来理解更多关于Ruby.关于如何执行此操作的任何想法?
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
在部署在heroku上的Rails应用程序(v:3.1)中,我在内存中获得了更多具有相同ID的对象。我的heroku控制台日志:>>Project.find_all_by_id(92).size=>2>>ActiveRecord::Base.connection.execute('select*fromprojectswhereid=92').to_a.size=>1这怎么可能?可能是什么问题? 最佳答案 解决方案根据您的SQL查询,您的数据库中显然没有重复条目。也许您的类项目中的size或length方法已被覆盖。我试过find_
在我们的项目中,我们有一些“被遗忘的”类存在了很长一段时间。那些类已被其他类替代,但我们忘记删除它们。是否有一些自动化的方法/工具可以发现Ruby{onRails}应用程序中没有使用哪些类?谢谢! 最佳答案 这个问题已经被提出了很多次,但是最好的答案都在这里:FindunusedcodeinaRailsapp我个人喜欢日志解析:https://stackoverflow.com/a/14161807但在任何情况下,您都可以创建自己的记录器,扩展ActiveRecord::Base以创建一个观察器,该观察器将最常用的模块存储在数据库中
我正在研究Ruby解释器是如何实现的,并且出现了一个问题,但我还没有得到答案。这就是标题中的那个:因为Class(r_cClass)将super设置为自身(忽略元类,因为实际上super是r_cClass的元类),如果我向Class对象发送一个方法,这将在Class的方法表中查找'类(class)。但是Class的类是Class,所以我不应该最终寻找Class的实例方法吗?但事实并非如此,因为在文档中Class类方法和Class实例方法是分开的。在Ruby的eval.c中的search_method中,我没有发现对Class类有什么特别的检查。任何人都可以阐明这一点吗?
我知道我能做到:classParentdefinitialize(args)args.eachdo|k,v|instance_variable_set("@#{k}",v)endendendclassA但我想使用关键字参数来更清楚地说明可以接受哪个散列键方法(并进行验证表明不支持此键)。所以我可以写:classAdefinitialize(param1:3,param2:4)@param1=param1@param2=param2endend但是有没有可能写一些更短的东西而不是@x=x;@y=y;...从传递的关键字参数初始化实例变量?是否可以访问作为哈希传递的关键字参数?