二分搜索代码模板:

例题:

#include<bits/stdc++.h>
using namespace std;
double n;
const double eps = 1e-12;
//二分搜索
int main() {
int t;
cin>>t;
while(t--) {
cin>>n;
double l = 0,r = 100000,res = -1;
while(l<=r) {
double mid = (l+r)/2;
if(abs(mid*mid*mid - n) <= eps) {
res = mid;
break;
}
if(mid*mid*mid>n) r = mid - 0.0001;
else if(mid*mid*mid<n) l = mid+0.0001,res = mid;
}
printf("%.3lf\n",res);
}
return 0;
}二分搜索是只能对有序的数据处理的方式。并且每次操作可以将未搜索的区间减少一半,因此速度十分的快。
前面说了每次搜索将搜索的区间减少一半,因此二分搜索的关键主要是将数据区间的更新,在每次操作过程中需要跟(L+R)/ 2 得到的mid 中间值去比较,如果小于mid,则R = mid-1;大于mid,则L = mid + 1;当L不小于R时,循环结束,此时mid就是想要的值。
三分搜索和二分搜索类似,模板可以参考下面的例题。
例题:

#include<bits/stdc++.h>
using namespace std;
//三分法
#define double long double
int a,b,c,Q;
const double esp = 1e-9;
double check(double x){
return a * x * x + b * x + c;
}
int main(){
cin>>a>>b>>c>>Q;
while(Q--){
double l,r;
cin>>l>>r;
while(r - l > esp){
double lmid = l + (r - l) / 3;
double rmid = r - (r - l) / 3;
if(check(lmid)>check(rmid)) r = rmid;
else if(check(lmid)<check(rmid)) l = lmid;
else l = lmid,r = rmid;
}
cout << setprecision(2) << fixed << a * l * l + b * l + c << '\n' ;
}
return 0;
}二分搜索也是有局限,它只能对有序的数据进行搜索,也就是数据必须单调。本题给出的二元一次函数,明显非单调。这就要用到三分搜索了,就是将原来的搜索区间分成三份,如下图。分别计算LMID和RMID,然后对其进行比较,若LMID大于RMID,那最大值一定在L到RMID这区间内。小于类似。
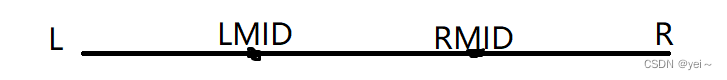
BFS的代码模板:

例题:

#include<bits/stdc++.h>
using namespace std;
int x,y,x2,y2;
int mp[105][105];
int n,m;
bool vis[105][105]; //标记地图上的点是否访问过
int dir[4][2] = {{1,0},{-1,0},{0,1},{0,-1}}; //搜索方向
struct node{
int a,b,c;
}; //方便计算和存入队列中
bool check(int x,int y){ //排除边界点、地图不能访问的点、以及已经访问过了的点
if(x<1 || x> n || y<1 || y>m || !mp[x][y] || vis[x][y]) return false;
return true;
}
int bfs(int x,int y){
queue<node> q;
q.push(node{x,y,0});
vis[x][y] = 1;
while(!q.empty()){
node u = q.front();
q.pop();
if(u.a == x2 && u.b == y2) return u.c;
for(int i = 0;i<4;i++){
int xx = dir[i][0]+u.a;
int yy = dir[i][1]+u.b;
if(!check(xx,yy)) continue;
vis[xx][yy] = 1;
q.push(node{xx,yy,u.c+1});
}
}
return -1;
}
int main()
{
cin>>n>>m;
for(int i = 1;i<=n;i++){
for(int j = 1;j<=m;j++){
cin>>mp[i][j];
}
}
cin>>x>>y>>x2>>y2;
cout<<bfs(x,y)<<endl;
return 0;
}BFS适用于求最短路径,该算法的搜索过程:
- 将起始位置加入队列
- 从队列开头取出一个元素,将这个元素四周可到达并且未被访问的点加入队列
因为队列先进先出的特性,只有当所有距离为 111的点被取出队列后,才会遍历距离为 222 的点,而距离为 111的点能到达的只有距离为 222的点,这也就保证这搜索答案的正确性。
DFS的代码模板:

例题:

#include <bits/stdc++.h>
using namespace std;
int vis[17];
int m[5][5];
int cnt = 0;
bool judge() {
for (int i = 0; i < 4; i ++ ) { //四行四列的和
if (m[i][0] + m[i][1] + m[i][2] + m[i][3] != 34) return 0;
if (m[0][i] + m[1][i] + m[2][i] + m[3][i] != 34) return 0;
}
if (m[0][0] + m[1][1] + m[2][2] + m[3][3] != 34) return 0;//对角线
if (m[0][3] + m[1][2] + m[2][1] + m[3][0] != 34) return 0;
return 1;
}
void dfs(int n) {
if (n == 16) {
if (judge()) cnt ++;
return;
}
if (n%4 == 0) //简单剪枝:检查第一行的和是不是34
if (m[n/4 - 1][0] + m[n/4 - 1][1] + m[n/4 - 1][2] + m[n/4 - 1][3] != 34)
return;
for (int i = 2; i <= 16; i ++ ) {
if (vis[i] == 0) {
m[n/4][n%4] = i;
vis[i] = 1;
dfs(n + 1);
vis[i] = 0;
}
}
}
int main() {
m[0][0] = 1;
dfs(1);
cout << cnt << endl; //416
return 0;
}本质上是暴力把所有的路径都搜索出来,它运用了回溯,保存这次的位置并深入搜索,都搜索完便回溯回来,搜下一个位置,直到把所有最深位置都搜一遍(找到目的解返回或者全部遍历完返回一个事先定好的值)。要注意的一点是,搜索的时候有记录走过的位置,标记完后要改回来。
这题的递归出口是所有数都填完,然判断该解是不是题目要求的解,是的话cnt++。有一个剪枝,可以降低时间复杂度,即当一行的和加起来不是34时,就一定不是我们要的解,往后就没必要再搜索下去了。
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
我正在使用Mandrill的RubyAPIGem并使用以下简单的测试模板:testastic按照Heroku指南中的示例,我有以下Ruby代码:require'mandrill'm=Mandrill::API.newrendered=m.templates.render'test-template',[{:header=>'someheadertext',:main_section=>'Themaincontentblock',:footer=>'asdf'}]mail(:to=>"JaysonLane",:subject=>"TestEmail")do|format|format.h
文章目录git常用命令(简介,详细参数往下看)Git提交代码步骤gitpullgitstatusgitaddgitcommitgitpushgit代码冲突合并问题方法一:放弃本地代码方法二:合并代码常用命令以及详细参数gitadd将文件添加到仓库:gitdiff比较文件异同gitlog查看历史记录gitreset代码回滚版本库相关操作远程仓库相关操作分支相关操作创建分支查看分支:gitbranch合并分支:gitmerge删除分支:gitbranch-ddev查看分支合并图:gitlog–graph–pretty=oneline–abbrev-commit撤消某次提交git用户名密码相关配置g
所以这可能有点令人困惑,但请耐心等待。简而言之,我想遍历具有特定键值的所有属性,然后如果值不为空,则将它们插入到模板中。这是我的代码:属性:#===DefaultfileConfigurations#default['elasticsearch']['default']['ES_USER']=''default['elasticsearch']['default']['ES_GROUP']=''default['elasticsearch']['default']['ES_HEAP_SIZE']=''default['elasticsearch']['default']['MAX_OP
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
我正在构建一个应用程序,想知道是否将未使用的对象设置为nil是生产级编码中的常见做法。我知道这只是垃圾收集器的提示,并不总是处理对象。 最佳答案 根据这个thread如果您使用完一个成员对象,将其设置为nil将引发被引用对象被垃圾回收。如果它是局部变量,方法exit将做同样的事情。也就是说,如果您要求将成员显式设置为nil,我会质疑您的设计。 关于ruby-将对象设置为nil是否很常见?,我们在StackOverflow上找到一个类似的问题: https://