 关于自动驾驶AI芯片选型目前市面上可供选择的AI芯片并不多,尤其是达到量产状态的,只有特斯拉、NVIDIA、Mobileye了。除了特斯拉自研自用不对外,其他品牌目前都可以通过合作开发方式拿到测试样件。
关于自动驾驶AI芯片选型目前市面上可供选择的AI芯片并不多,尤其是达到量产状态的,只有特斯拉、NVIDIA、Mobileye了。除了特斯拉自研自用不对外,其他品牌目前都可以通过合作开发方式拿到测试样件。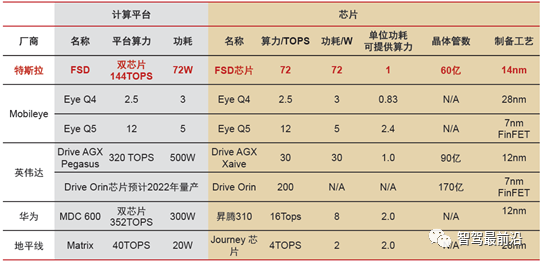 以NVIDIA Xavier为例,相对而言,由于NVIDIA Xavier推出较早,并且生态布局相对完善,对于开发者来说可以快速构建系统和开发AI应用,因此基于Xavier模组进行域控制器设计的企业不在少数。XavierSoC最高算力可达30TOPs,内有Valta TensorCore GPU,八核ARM64 CPU,双NVDLA 深度学习加速器,图像处理器,视觉处理器和视频处理器等六种不同的处理器,使其能够同时、且实时地处理数十种算法,用于传感器数据处理、环境感知、定位和绘图以及路径规划。芯片内部结构如下图所示:
以NVIDIA Xavier为例,相对而言,由于NVIDIA Xavier推出较早,并且生态布局相对完善,对于开发者来说可以快速构建系统和开发AI应用,因此基于Xavier模组进行域控制器设计的企业不在少数。XavierSoC最高算力可达30TOPs,内有Valta TensorCore GPU,八核ARM64 CPU,双NVDLA 深度学习加速器,图像处理器,视觉处理器和视频处理器等六种不同的处理器,使其能够同时、且实时地处理数十种算法,用于传感器数据处理、环境感知、定位和绘图以及路径规划。芯片内部结构如下图所示: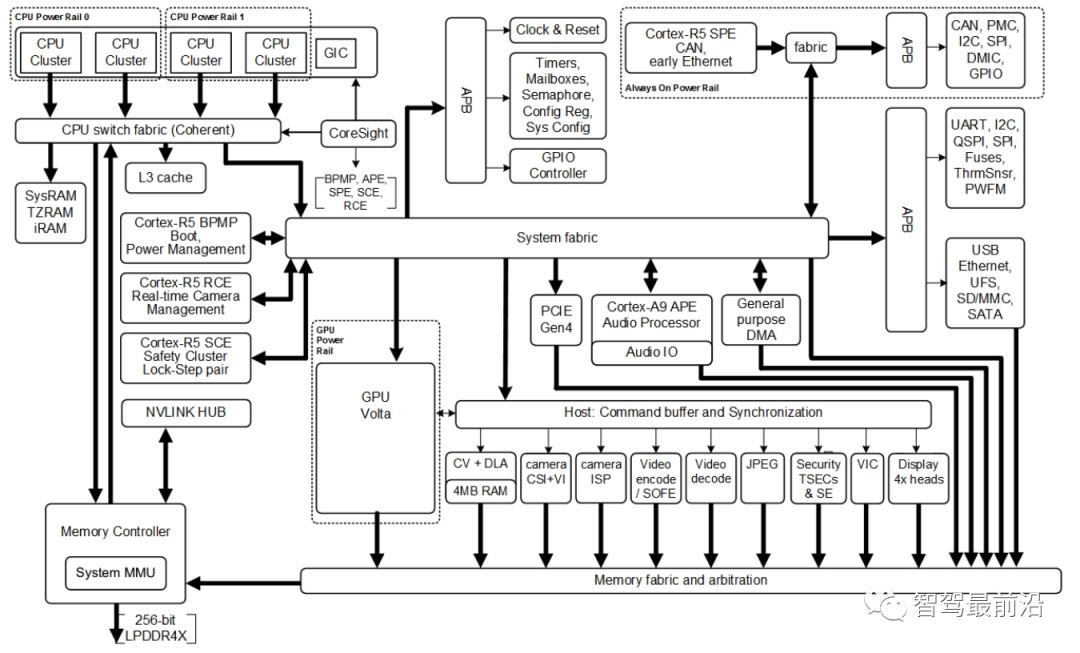 NVIDIA 提供的Xavier为核心模组,其接口如下图所示:
NVIDIA 提供的Xavier为核心模组,其接口如下图所示: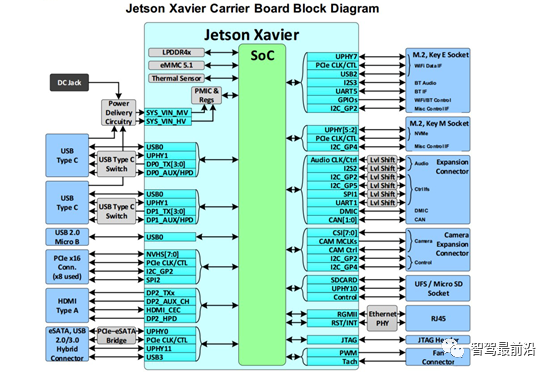
 芯片的关键指标1)Core:内核通常是空间中心。一方面便于自动驾驶控制器和外围传感器、执行器通讯,同时也用外围来保护它。core强调运行态,通常出现的core-down,是指cpu计算上出现问题了,core强调的是自动驾驶控制器整体对外功能中的核心功能。2)DMIPS:主要用于测整数计算能力。包含每秒钟能够执行的指令集数量,以及其这些指令集在实现我的测试程序的时候,每秒钟能够实现的工作数量,这个能力由cpu的架构,内存memory的访问速度等硬件特性来决定。它是一个测量CPU运行相应测试程序时表现出来的相对性能高低的一个单位(很多自动驾驶芯片评估场合,人们习惯用MIPS作为这个性能指标的单位)。3)Memory:存储器管理单元的主要功能包括:虚拟地址到物理地址映射、存储器访问权限控制、高速缓存支持等;4)DataFlash:DataFlash是美国ATMEL公司推出的大容量串行Flash存储器产品,采用Nor技术制造,可用于存储数据和程序代码。与并行Flash存储器相比,所需引脚少,体积小,易于扩展,与单片机或控制器连接简单,工作可靠,所以类似DataFlash的串行Flash控制器越来越多的用在自动驾驶控制器产品和测控系统评估中。5)ISP:ISP作为视觉处理芯片核心,其主要功能包括 AE(自动曝光)、AF(自动对焦)、AWB(自动白平衡)、去除图像噪声、LSC(Lens Shading Correction)、BPC(Bad PixelCorrection),最后把 Raw Data 保存起来,传给 videocodec 或 CV 等。通过 ISP 可以得到更好的图像效果,因此在自动驾驶汽车上对ISP的要求很高,比如开始集成双通道甚至三通道的 ISP。一般来说 ISP 是集成在 AP 里面(对很多 AP 芯片厂商来说,这是差异化竞争的关键部分),但是随着需求的变化也出现了独立的 ISP,主要原因是可以更灵活的配置,同时弥补及配合 AP 芯片内 ISP 功能的不足。6)算力:自动驾驶的实现,需要依赖环境感知传感器对道路环境的信息进行采集,将采集到的数据传送到汽车中央处理器进行处理,用来识别障碍物、可行道路等,依据识别结果,规划路径、制定车速,自动控制汽车行驶。整个过程需要在一瞬间完成,延时必须要控制在毫秒甚至微秒级别,才能保证自动驾驶的行驶安全。要完成瞬时处理、反馈、决策规划、执行的效果,对中央处理器的算力要求非常高。在自动驾驶中,最耗费算力的当属视觉处理,占到全部算力需求的一半以上,且自动驾驶级别每升高一级,对计算力的需求至少增加十倍。L2级别需要2个TOPS的算力,L3需要24个TOPS的算力,L4为320TOPS,L5为4000+TOPS。
芯片的关键指标1)Core:内核通常是空间中心。一方面便于自动驾驶控制器和外围传感器、执行器通讯,同时也用外围来保护它。core强调运行态,通常出现的core-down,是指cpu计算上出现问题了,core强调的是自动驾驶控制器整体对外功能中的核心功能。2)DMIPS:主要用于测整数计算能力。包含每秒钟能够执行的指令集数量,以及其这些指令集在实现我的测试程序的时候,每秒钟能够实现的工作数量,这个能力由cpu的架构,内存memory的访问速度等硬件特性来决定。它是一个测量CPU运行相应测试程序时表现出来的相对性能高低的一个单位(很多自动驾驶芯片评估场合,人们习惯用MIPS作为这个性能指标的单位)。3)Memory:存储器管理单元的主要功能包括:虚拟地址到物理地址映射、存储器访问权限控制、高速缓存支持等;4)DataFlash:DataFlash是美国ATMEL公司推出的大容量串行Flash存储器产品,采用Nor技术制造,可用于存储数据和程序代码。与并行Flash存储器相比,所需引脚少,体积小,易于扩展,与单片机或控制器连接简单,工作可靠,所以类似DataFlash的串行Flash控制器越来越多的用在自动驾驶控制器产品和测控系统评估中。5)ISP:ISP作为视觉处理芯片核心,其主要功能包括 AE(自动曝光)、AF(自动对焦)、AWB(自动白平衡)、去除图像噪声、LSC(Lens Shading Correction)、BPC(Bad PixelCorrection),最后把 Raw Data 保存起来,传给 videocodec 或 CV 等。通过 ISP 可以得到更好的图像效果,因此在自动驾驶汽车上对ISP的要求很高,比如开始集成双通道甚至三通道的 ISP。一般来说 ISP 是集成在 AP 里面(对很多 AP 芯片厂商来说,这是差异化竞争的关键部分),但是随着需求的变化也出现了独立的 ISP,主要原因是可以更灵活的配置,同时弥补及配合 AP 芯片内 ISP 功能的不足。6)算力:自动驾驶的实现,需要依赖环境感知传感器对道路环境的信息进行采集,将采集到的数据传送到汽车中央处理器进行处理,用来识别障碍物、可行道路等,依据识别结果,规划路径、制定车速,自动控制汽车行驶。整个过程需要在一瞬间完成,延时必须要控制在毫秒甚至微秒级别,才能保证自动驾驶的行驶安全。要完成瞬时处理、反馈、决策规划、执行的效果,对中央处理器的算力要求非常高。在自动驾驶中,最耗费算力的当属视觉处理,占到全部算力需求的一半以上,且自动驾驶级别每升高一级,对计算力的需求至少增加十倍。L2级别需要2个TOPS的算力,L3需要24个TOPS的算力,L4为320TOPS,L5为4000+TOPS。 光有算力还不够,考虑汽车应用的复杂性,汽车处理器还需要同时考虑算力利用率、是否通过车规和安全标准等。算力理论值取决于运算精度、MAC的数量和运行频率。理论算力是根据Net卷积层的乘法运算累加得出,卷积层中的每次乘加(MAC)算成两个OPS,卷积运算量占DL NET的90%以上,其它辅助运算或其它层的运算忽略不计,SSD所有卷积层乘法运算总数是40G MACs,所以理论算力是80GOPS。其中,
光有算力还不够,考虑汽车应用的复杂性,汽车处理器还需要同时考虑算力利用率、是否通过车规和安全标准等。算力理论值取决于运算精度、MAC的数量和运行频率。理论算力是根据Net卷积层的乘法运算累加得出,卷积层中的每次乘加(MAC)算成两个OPS,卷积运算量占DL NET的90%以上,其它辅助运算或其它层的运算忽略不计,SSD所有卷积层乘法运算总数是40G MACs,所以理论算力是80GOPS。其中, 真实值和理论值差异极大,考虑其它运算层,硬件实际利用率要高一些。决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,还有实际运行频率(即供电电压或温度),还有算法的batch尺寸。7)功耗:在最高性能模式下,如果自动驾驶控制器的芯片功耗级别较高,即便其自身性能强劲,但也会引发某些未可预知的隐患,如发热量成倍增加,耗电率成倍增加,这些结果尤其对于新能源车型来说也毫无疑问是颗“核弹”。因此,我们在前期自动驾驶芯片设计中需要充分考虑其功耗指标。8)3D GPU:GPU是基于大的吞吐量设计,用来处理大规模的并行计算。GPU的控制单元可以把多个的访问合并成少的访问。GPU将更多的晶体管用于执行单元,而非像CPU那样用作复杂的数据cache和指令控制。由于GPU具有超强的浮点计算能力,可用于在智能汽车前端的图像或视频处理领域的应用,也越来越多地应用在中央控制器高性能计算的主流设计中。9)丰富的IO接口资源自动驾驶的主控处理器需要丰富的接口来连接各种各样的传感器设备。目前业界常见的自动驾驶传感器主要有:摄像头、激光雷达、毫米波雷达、超声波雷达、组合导航、IMU以及V2X模块等。
真实值和理论值差异极大,考虑其它运算层,硬件实际利用率要高一些。决定算力真实值最主要因素是内存( SRAM和DRAM)带宽,还有实际运行频率(即供电电压或温度),还有算法的batch尺寸。7)功耗:在最高性能模式下,如果自动驾驶控制器的芯片功耗级别较高,即便其自身性能强劲,但也会引发某些未可预知的隐患,如发热量成倍增加,耗电率成倍增加,这些结果尤其对于新能源车型来说也毫无疑问是颗“核弹”。因此,我们在前期自动驾驶芯片设计中需要充分考虑其功耗指标。8)3D GPU:GPU是基于大的吞吐量设计,用来处理大规模的并行计算。GPU的控制单元可以把多个的访问合并成少的访问。GPU将更多的晶体管用于执行单元,而非像CPU那样用作复杂的数据cache和指令控制。由于GPU具有超强的浮点计算能力,可用于在智能汽车前端的图像或视频处理领域的应用,也越来越多地应用在中央控制器高性能计算的主流设计中。9)丰富的IO接口资源自动驾驶的主控处理器需要丰富的接口来连接各种各样的传感器设备。目前业界常见的自动驾驶传感器主要有:摄像头、激光雷达、毫米波雷达、超声波雷达、组合导航、IMU以及V2X模块等。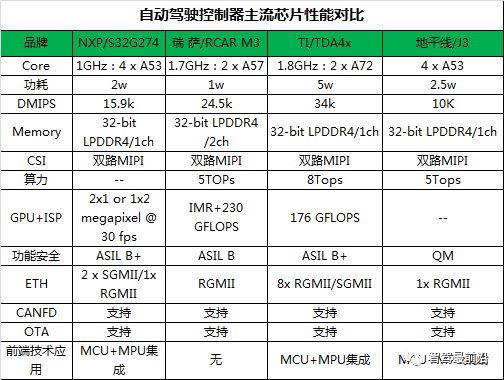
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我正在尝试学习Ruby词法分析器和解析器(whitequarkparser)以了解更多有关从Ruby脚本进一步生成机器代码的过程。在解析以下Ruby代码字符串时。defadd(a,b)returna+bendputsadd1,2它导致以下S表达式符号。s(:begin,s(:def,:add,s(:args,s(:arg,:a),s(:arg,:b)),s(:return,s(:send,s(:lvar,:a),:+,s(:lvar,:b)))),s(:send,nil,:puts,s(:send,nil,:add,s(:int,1),s(:int,3))))任何人都可以向我解释生成的
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我想知道是否可以通过自动创建数组来插入数组,如果数组不存在的话,就像在PHP中一样:$toto[]='titi';如果尚未定义$toto,它将创建数组并将“titi”压入。如果已经存在,它只会推送。在Ruby中我必须这样做:toto||=[]toto.push('titi')可以一行完成吗?因为如果我有一个循环,它会测试“||=”,除了第一次:Person.all.eachdo|person|toto||=[]#with1billionofperson,thislineisuseless999999999times...toto.push(person.name)你有更好的解决方案吗?
下面的代码工作正常:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson)do|key,oldv,newv|ifkey==:aoldvelsifkey==:bnewvelsekeyendendputskerson.inspect但是如果我在“ifblock”中添加return,我会得到一个错误:person={:a=>:A,:b=>:B,:c=>:C}berson={:a=>:A1,:b=>:B1,:c=>:C1}kerson=person.merge(berson
我定义了一个方法:defmethod(one:1,two:2)[one,two]end当我这样调用它时:methodone:'one',three:'three'我得到:ArgumentError:unknownkeyword:three我不想从散列中一个一个地提取所需的键或排除额外的键。除了像这样定义方法之外,有没有办法规避这种行为:defmethod(one:1,two:2,**other)[one,two,other]end 最佳答案 如果不想写**other中的other,可以省略。defmethod(one:1,two:2
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3