
🧑💼 个人简介:一个不甘平庸的平凡人🍬
🖥️ 本系列专栏:Node.js从入门到精通
👉 你的一键三连是我更新的最大动力❤️!
📢 欢迎私信博主加入前端交流群🌹
📑目录
目前绝大多数的系统都少不了登录验证的功能,这主要是为了保存用户的状态,以此来限制用户的各种行为,从而方便有效的控制用户的权限。比如一个用户登陆微博,发布、关注、评论的操作都应是在登录后的用户状态下进行的。
实现登录验证的功能主要有Cookie&Session、JWT两种方式,这一节我们将先对 Cookie&Session的工作原理 做详细的介绍,在之后的文章中会陆续对JWT,以及如何使用Cookie&Session和JWT来完善前几节我们搭建的简易用户管理系统进行讲解。
关注博主,订阅专栏,学习Node不迷路!
我们知道,HTTP 是无状态的。也就是说,HTTP 请求方和响应方间无法维护状态,都是一次性的,它不知道前后的请求都发生了什么。但有的场景下,我们需要维护状态。最典型的,一个用户登陆微博,发布、关注、评论,都应是在登录后的用户状态下的。
这个时候就可以引入Cookie与Session来保存用户的登录状态。
本篇文章主要介绍使用
Cookie-Session来做登录验证的工作原理,关于Cookie与Session的详细介绍可查阅这位大佬的文章:Cookie和Session详解
Cookie是存放在浏览器中的,可以在浏览器中打开控制台,选择应用,找到存储中的Cookie进行查看:
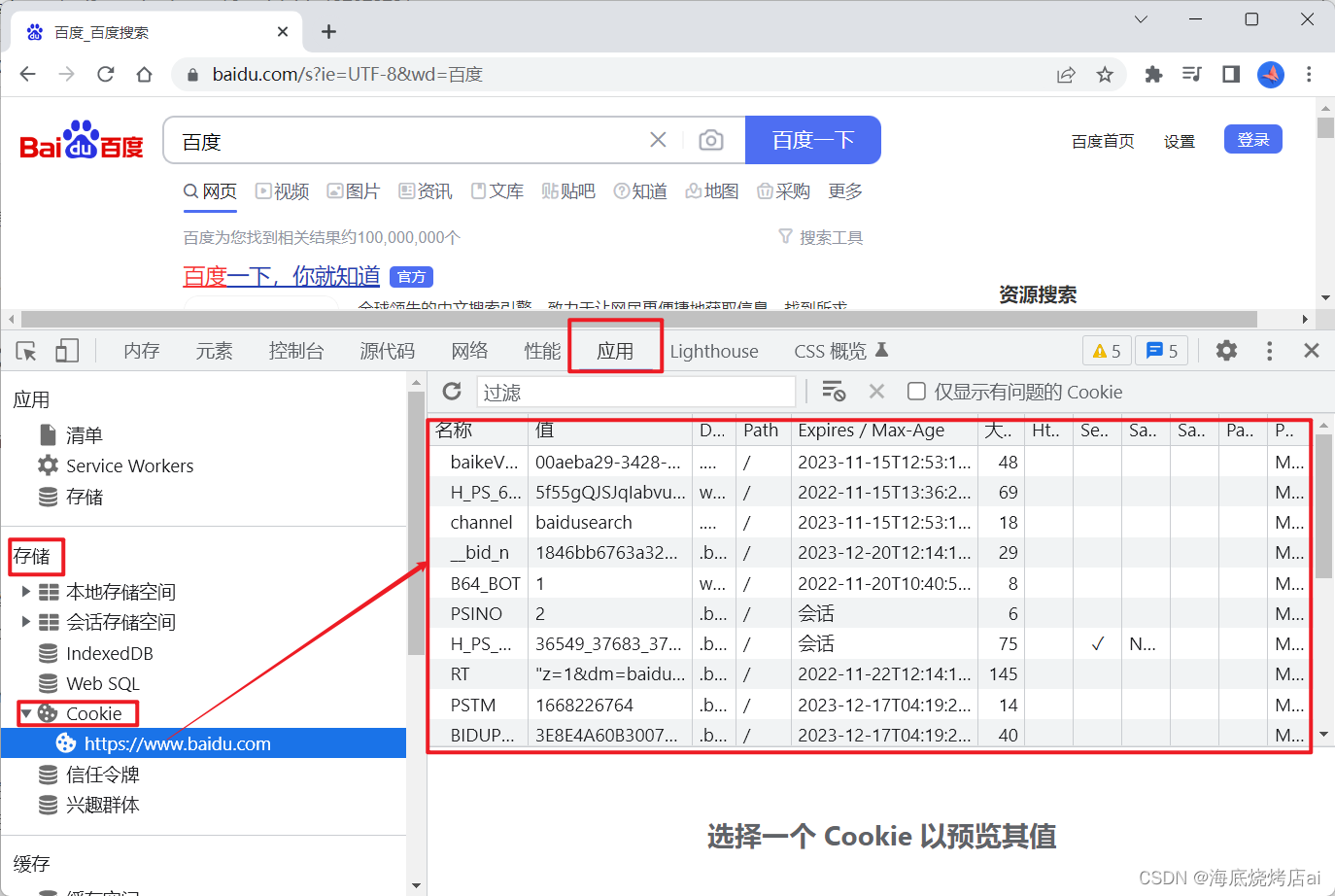
当客户端向服务端发送网络请求时浏览器会自动将Cookie添加到请求头中,这样服务端就能获取这个Cookie,如下:
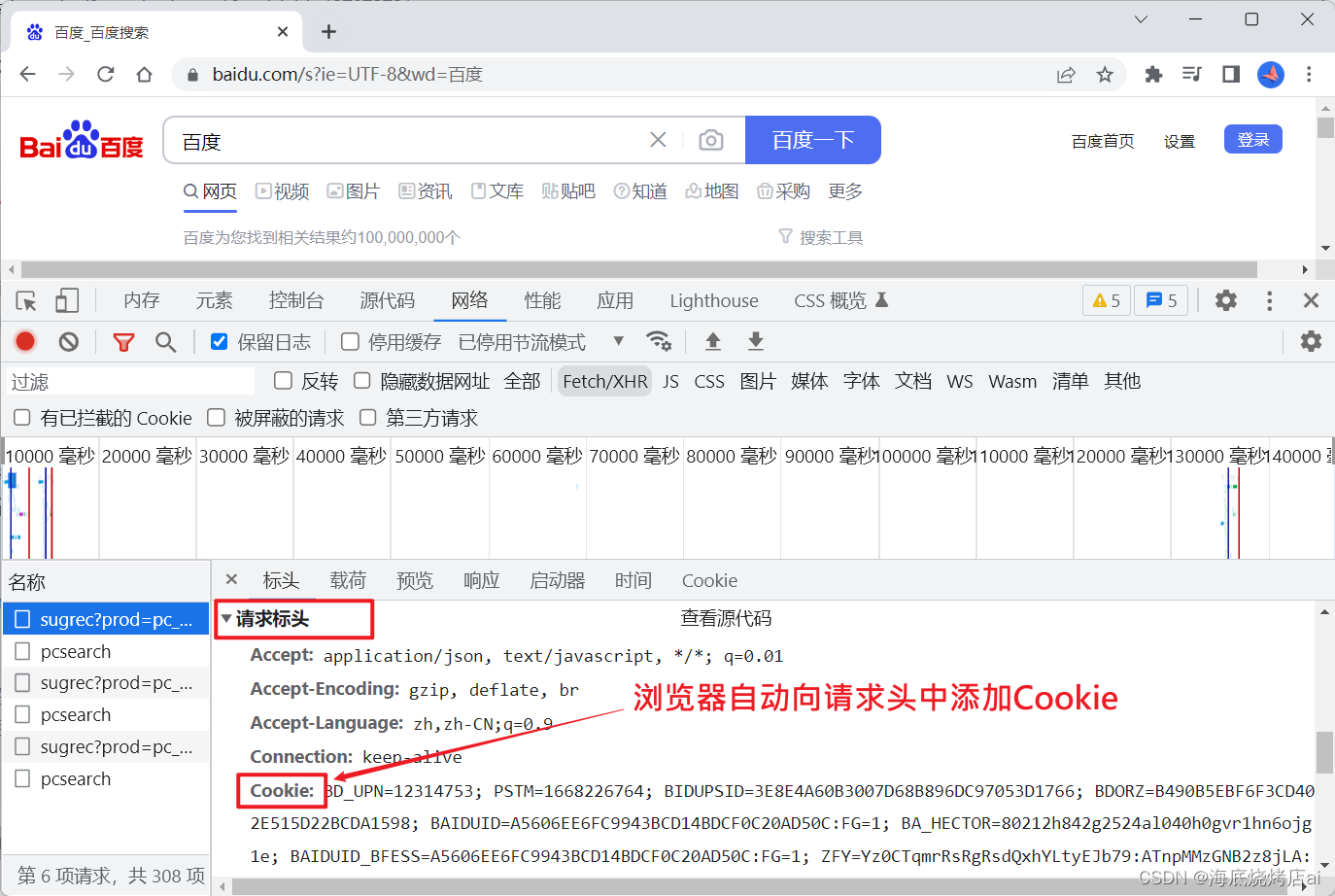
知道了这个原理后,我们就可以想到,如果在用户登录系统时:客户端由用户的部分登录信息(比如username、id等)生成一个Cookie存放到浏览器中,那么在这之后的每一次网络请求都会自动携带上该Cookie。
之后让服务端根据请求中是否携带Cookie并且携带的Cookie中是否存在有效的username、id来判断用户是否已经登录过了,这样一来用户的登录状态不就被保存下来了吗。
回到上面我们提到的微博的例子,按照这种过程来说,当用户登录过后Cookie已经被保存,这时当用户进行发布、关注、评论等需要登录才能使用的操作时我们就能提前判断是否存在Cookie,如果存在并且Cookie中含有该用户的id,那么我们就可以允许该用户的这些操作(这些操作一般都是需要用户的id的,这时就可以从Cookie中进行获取)。相反的,如果Cookie不存在或者Cookie无效,那么就禁止该用户的这些操作。
说到这,你可能会问:既然一个Cookie就能实现我们想要的效果,那为何还要使用Session呢?
这是因为 Cookie很容易被伪造! ,如果我们知道了Cookie中存放的信息是username和id(就算不知道,也可以在登录后的网络请求的请求体中找到Cookie),那么我们完全可以在不登录的情况下手动向浏览器存储一个伪造的Cookie:
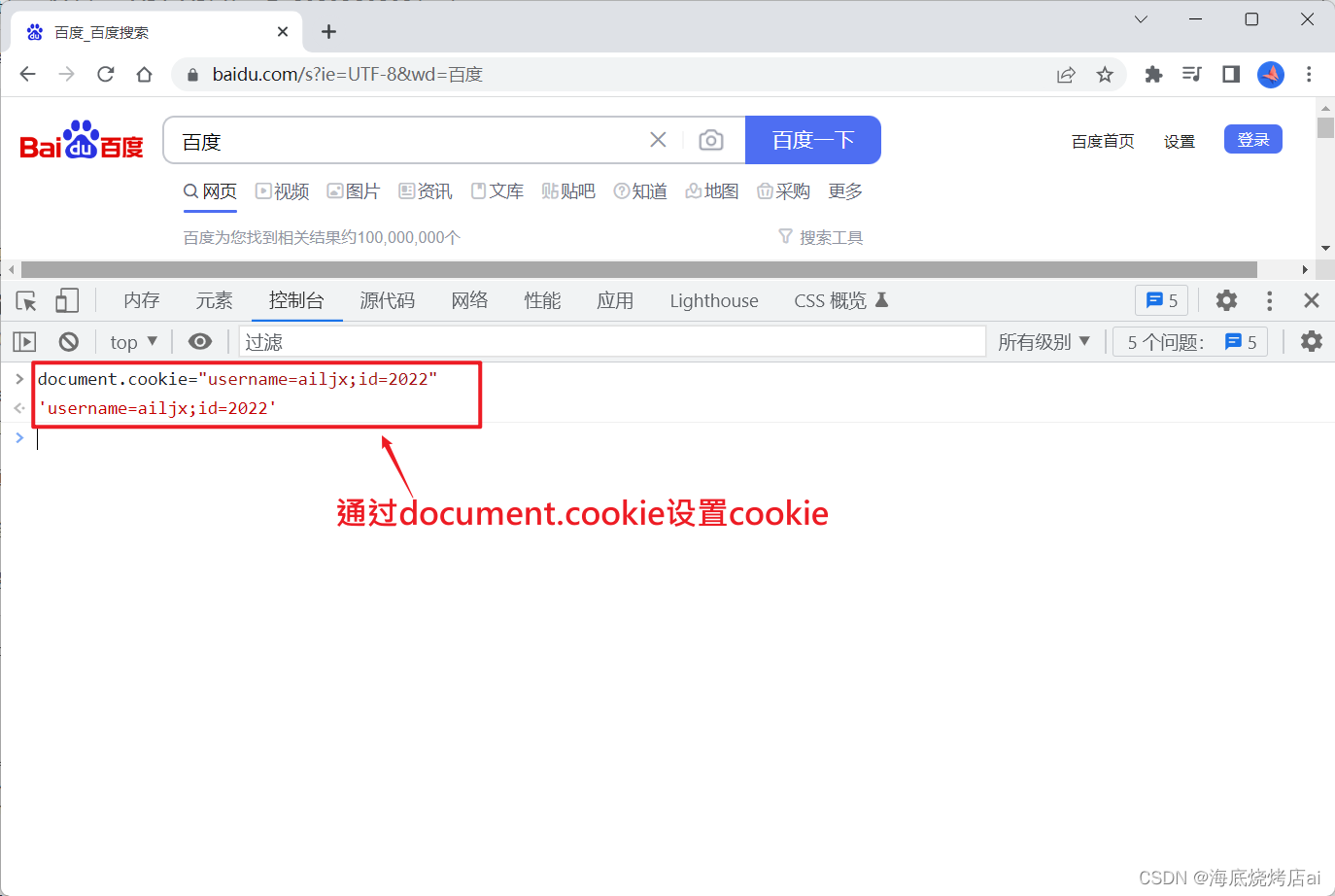
说到这,你应该就能明白为什么不能单独使用Cookie了吧。
Session其实是基于Cookie实现的,并且Session存储在服务端的内存或者数据库中。
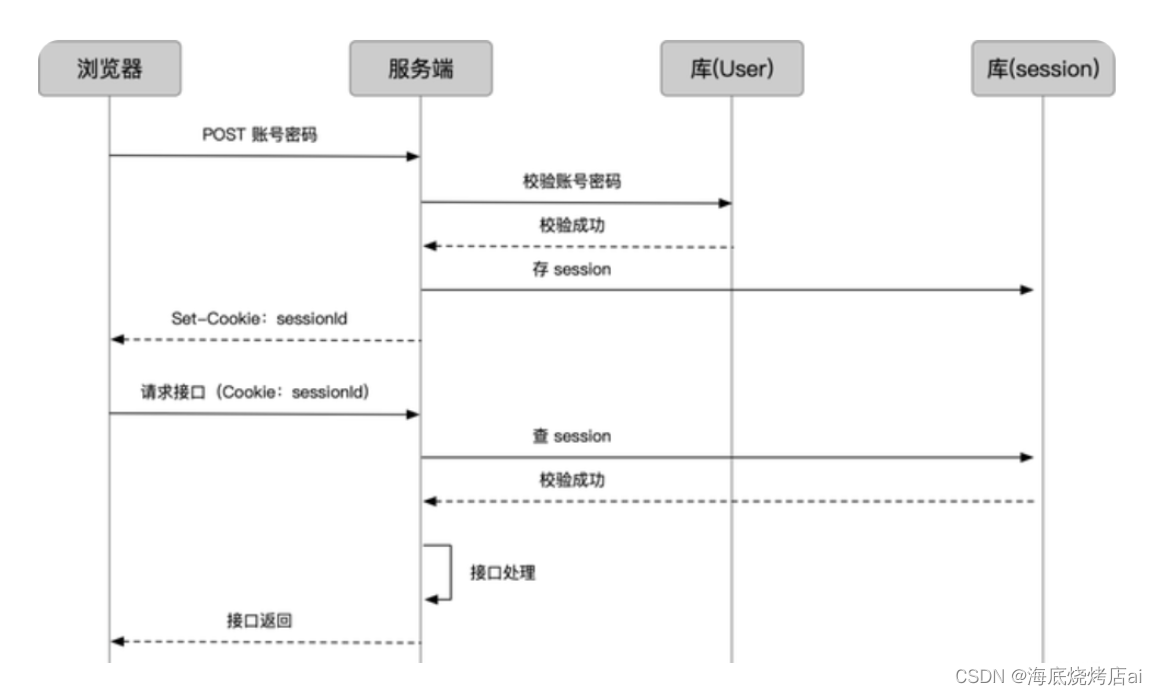
当用户登录成功时,使用Cookie&Session的登录验证会进行以下操作:
由服务端生成Session与SessionId;
Session一般是根据用户登录的信息,如用户名、id等进行生成。
如果把Session比作是一把锁,那么SessionId就相当于是这把锁的钥匙。
服务端将Session存储到内存或者数据库中;
服务端将SessionId存放到请求的响应头(response对象)中的Set-Cookie字段中发送给客户端;
客户端收到Set-Cookie后会自动将Set-Cookie的值(也就是SessionId)存放到Cookie中;
之后的每次网络请求都会自动带上Cookie,也就是带上这个SessionId;
服务端收到后续请求时获取请求上的Cookie,也就是获取到了SessionId,然后通过SessionId查询并校验服务端存储的Session,若校验成功说明这个SessionId有效则通过此次请求,反之则阻止此次请求。
图示:
为了保存用户的登录状态,我们需要为每一位登录的用户生成并存储Session,这势必就会造成以下问题:
Session存放到内存中,那么当服务端重启时,这些内存中的Session都将被清除,那么所有用户的登录状态都将会过期,并且当用户量较大时,过多的内存占用也势必会影响服务端的性能。Session存放到数据库中,虽然能够解决因服务端重启造成用户登录状态过期的问题,但当用户量较大时,对于这个数据库的维护也会变得相对困难。Session在两个服务器间共享通常会将Session存放到一个单独的数据库中,这样就使得整个项目变得更为复杂也更加难以维护。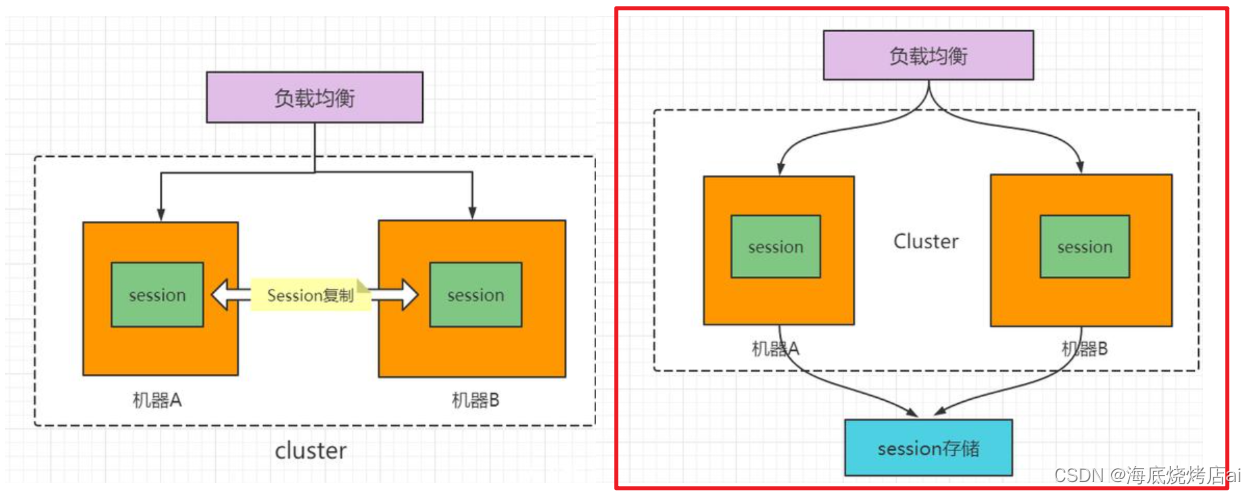
CSRF全称为 Cross-site request forgery 即 跨站请求伪造,使用Cookie进行验证的网站都会面临或大或小的CSRF威胁,我们以一个银行网站的例子来介绍CSRF的攻击原理:
假如一家银行网站A的登录验证采用的是Cookie&Session,并且该网站上用以运行转账操作的Api地址为:http://www.grillbankapi.com/?account=AccoutName&amount=1000
api参数:account代表账户名,amount代表转账金额。
那么,一个恶意攻击者可以在另一个网站B上放置如下代码:
<img src="http://www.grillbankapi.com/?account=Ailjx&amount=1000">
注意:
img标签的src是网站A转账操作的api地址,并且参数account为Ailjx,amount为1000,也就是说这个api地址相当于是账户名为 Ailjx 转账1000 时调用的api。
如果有账户名为 Ailjx 的用户刚访问过网站A不久,登录信息尚未过期(网站A的Cookie存在且有效)。
那么当 Ailjx 访问了这个恶意网站B时,上面的img标签将被加载,浏览器就会自动请求img标签的src路由,也就是请求http://www.grillbankapi.com/?account=Ailjx&amount=1000 (我们将这个请求记为请求Q),并且因为Cookie存放在浏览器中且浏览器发送请求时会自动带上Cookie,所以请求Q上就会自动携带 Ailjx 在网站A上的Cookie凭证,结果就是这个 请求Q将会被通过,那么 Ailjx 就会损失1000资金。
这种恶意的网址可以有很多种形式,藏身于网页中的许多地方。 此外,攻击者也不需要控制放置恶意网址的网站。例如他可以将这种地址藏在论坛,博客等任何用户生成内容的网站中。这意味着如果服务端没有合适的防御措施的话,用户即使访问熟悉的可信网站也有受攻击的危险。
透过例子能够看出,攻击者并不能通过CSRF攻击来直接获取用户的账户控制权,也不能直接窃取用户的任何信息。他们能做到的,是欺骗用户浏览器,让其以用户的名义运行操作。
这些就是使用Cookie&Session来做登录验证的问题所在,那么我们如何解决这些问题呢?这就需要引入JWT的概念,使用token来做登录验证,这些我们将在之后的文章中进行讲解。
博主的Node.js从入门到精通专栏正在持续更新中,关注博主订阅专栏学习Node不迷路!
如果你有一些问题与疑惑,欢迎评论区留言,也欢迎私信博主加入我们的前端技术交流群。
如果本篇文章对你有所帮助,还请客官一件四连!❤️

我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我希望我的UserPrice模型的属性在它们为空或不验证数值时默认为0。这些属性是tax_rate、shipping_cost和price。classCreateUserPrices8,:scale=>2t.decimal:tax_rate,:precision=>8,:scale=>2t.decimal:shipping_cost,:precision=>8,:scale=>2endendend起初,我将所有3列的:default=>0放在表格中,但我不想要这样,因为它已经填充了字段,我想使用占位符。这是我的UserPrice模型:classUserPrice回答before_val
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport: