摘要:多模态认知智能是AI人工智能当前发展的主流趋势之一,其核心是以多模态知识的获取,表示与推理为主要内容的跨模态知识工程与认知智能,也是为了更好的处理多模态的数据,需要融合多种感知模态和智能处理技术。
本文分享自华为云社区《GPT-4发布,AIGC时代的多模态还能走多远?系列之三:多模态认知智能》,作者:码上开花_Lancer。
上两篇文章介绍了AIGC未来已来和AIGC的阿克琉斯之踵,了解到AIGC当前的发展趋势和当前的一些不足之处,接下来给大家介绍AIGC时代的多模态技术的发展。
多模态认知智能是AI人工智能当前发展的主流趋势之一,其核心是以多模态知识的获取,表示与推理为主要内容的跨模态知识工程与认知智能,也是为了更好的处理多模态的数据,需要融合多种感知模态和智能处理技术。
多模态认知智能是一种融合多种感知模态和智能处理技术的人工智能,旨在建立更加丰富、灵活和可信赖的人机交互平台。为此,需要研究一套完整的多模态认知智能研究框架,该框架应包含以下几个方面:
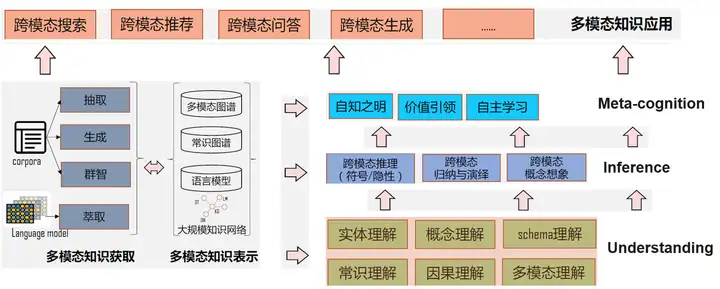
(多模态认知智能研究框架,图片来自网络)
我们明白多模态认知智能研究框架以后,对于多模态认知智能,它是怎么样实现的呢?
多模态大模型是一种连接主义和经验主义相结合的实现路径。它的核心思想是利用海量预训练数据来构建一个大规模的神经网络模型,能够自动学习和提取多模态数据中的特征和关系,并实现对多种语言、图像、音频等多种形式的信息进行联合理解。该方法具有概率关联、简单鲁棒等优点,但在学习逻辑关系等方面仍有局限性。 多模态知识工程则是一种符号主义的实现路径,主要依赖专家系统和知识图谱等手段,通过对精选数据和专家知识的整合和转化,将其转换成符号知识,实现对多模态数据的解析和分析。该方法具有易推理、可控、可干预、可解释等特点,但在信息损失方面存在一定的问题。 综合来看,多模态大模型和多模态知识工程各有优缺点,需要根据应用场景和需求进行选择和设计。在未来的研究中,我们需要进一步探索如何更好地结合两种实现路径,充分利用它们各自的优势,实现多模态认知智能的高效、准确和可解释性。 数据转换成符号知识的过程往往伴随着巨大的信息损失,隐性知识、难以表达的知识是损失信息中的主体, 在AIGC大模型时代,多模态知识工程依然不可或缺。

(以上图来自网络)
多模态知识工程中有一种常用的方法是利用知识图谱,这种方法被称为多模态知识图谱(MMKG)。与传统知识图谱不同,MMKG以多模态数据作为源头,从多方面描述实体和关系,构建出一个可以跨越多模态的知识体系。在MMKG中,多模态数据不仅仅作为文字符号实体的关联属性存在,还可以作为图谱中的实体存在,可与现有实体发生广泛关联。 MMKG的优势在于它能够消除多模态数据的异构性,将它们有机地结合在一起,使得系统能够实现对多模态数据的更加全面和深入的理解。同时,MMKG也能够提高数据的可发现性和可重用性,使得数据共享变得更加容易。
在实际应用中, 例如,假设你需要在家里搭建一套智能家居系统,这个系统需要支持语音控制、自动化定时等多种功能。那么,在建设过程中,MMKG就可以帮助系统对运作环境、设备状态、用户需求等方面的多模态数据进行综合分析和优化,从而提高系统的智能性、可靠性和适应性。 另一个具有代表性的例子是医疗领域的智能辅助诊断系统。这类系统会收集包括医学影像、实验室检查、文本记录等形式的多模态数据,利用MMKG进行知识关联、特征提取和预测策略优化等任务。通过这种方式,系统可以在医生与病人之间架起一座智能化的桥梁,让医疗决策变得更加全面、准确和科学。
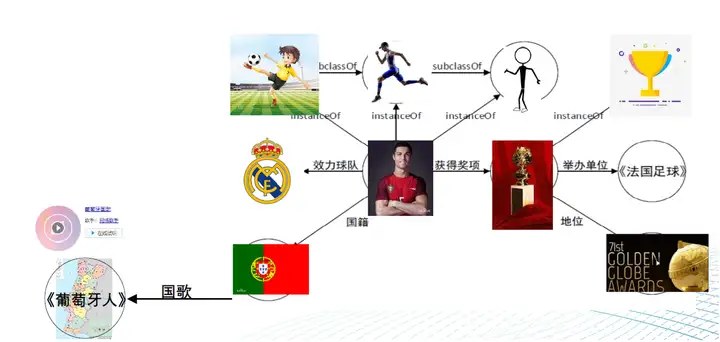
(以上图片来自文章X. Zhu, Z. Li et. al. Multi-Modal Knowledge Graph Construction and Application: A Survey, Accepted by TKDE in Dec. 2022)
MMKG已经被应用于多个领域,包括自然语言处理、计算机视觉、语音识别等。例如,在自然语言处理领域,MMKG可以将不同形式的语言信息连接起来,实现对文本、图片和音频内容的跨越式认知和分析;在计算机视觉领域,MMKG可以将图像和视频数据与其他领域的知识相结合,获得更具深度和复杂性的认知结果。 未来,随着各种智能设备的普及和多模态数据的日益增长,MMKG必将成为实现多模态认知智能的一个重要手段。我们需要进一步完善MMKG的理论框架和技术体系,在构建更加丰富和高效的多模态知识图谱的基础上,实现对多模态数据的更加准确和深刻的认知,推动人工智能技术的不断发展和应用。 总之,在多模态数据处理和应用方面,MMKG可以大大增强系统的认知和决策能力,实现人机交互的更加智能化和自然化,同时也可以促进各领域应用场景的创新和发展。
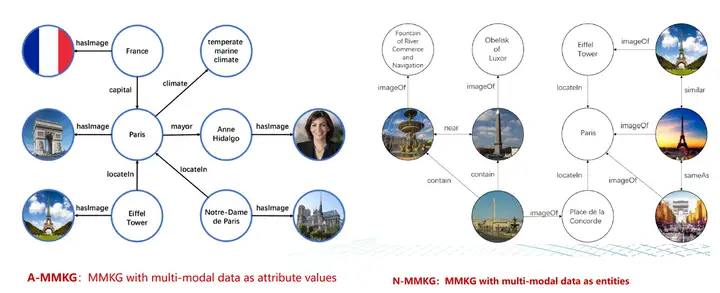
(以上图片来自文章《X. Zhu, Z. Li et. al. Multi-Modal Knowledge Graph Construction and Application: A Survey, Accepted by TKDE in Dec. 2022》)
在当前的自然语言处理领域中,多模态大模型和多模态知识图谱都有各自的优缺点。多模态大模型具有关联推理强、可适应多任务、人工成本低、适应能力强等优点,但其可靠程度低、知识推理能力弱、可解释性不足、训练成本高等不足之处也不容忽视。而多模态知识图谱则具有专业可信度高、可解释性强、可拓展性好等优点,但其推理能力弱、人工成本高、架构调整难等不足之处也同样存在。 针对这些不足之处,目前的研究方向主要包括以下几个方面:
当前阶段,大模型与知识图谱仍应继续保持竞合关系,互相帮助,互为补充,未来的研究方向将集中在如何充分利用多模态数据,提高模型的可靠性、推理能力和可解释性,降低训练成本和构建成本,实现更加精准和智能的自然语言处理。那AIGC多模态大模型在多模态知识图谱的实际场景是怎么的呢?请期待我的下一篇文章GPT-4发布,AIGC时代的多模态还能走多远?系列之四 AIGC for MMKG。
部分内容参考来自复旦大学教授李直旭《AIGC时代的多模态知识工程思考与展望》
论文:《Google’s PaLM-E is a generalist robot brain that takes commands》
《X. Zhu, Z. Li et. al. Multi-Modal Knowledge Graph Construction and Application: A Survey, Accepted by TKDE in Dec. 2022
http://arxiv.org/abs/2206.14268 和http://arxiv.org/abs/2212.05767
前面一篇关于智能合约翻译文讲到了,是一种计算机程序,既然是程序,那就可以使用程序语言去编写智能合约了。而若想玩区块链上的项目,大部分区块链项目都是开源的,能看得懂智能合约代码,或找出其中的漏洞,那么,学习Solidity这门高级的智能合约语言是有必要的,当然,这都得在公链``````以太坊上,毕竟国内的联盟链有些是不兼容Solidity。Solidity是一种面向对象的高级语言,用于实现智能合约。智能合约是管理以太坊状态下的账户行为的程序。Solidity是运行在以太坊(Ethereum)虚拟机(EVM)上,其语法受到了c++、python、javascript影响。Solidity是静态类型
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
我正在使用RABL输出Sunspot/SOLR结果集,搜索结果对象由多种模型类型组成。目前在rablView中我有:objectfalsechild@search.results=>:resultsdoattribute:id,:resource,:upccodeattribute:display_description=>:descriptioncode:start_datedo|r|r.utc_start_date.to_iendcode:end_datedo|r|r.utc_end_date.to_iendendchild@search=>:statsdoattribute:to
一文解决关于VLAN所有的疑惑VLAN基本概念为什么需要VLAN?怎么在交换机上划分VLAN,VLAN的工作原理有了子网,已经隔离了广播,还需要VLAN干啥?只进行子网划分,不进行VLAN划分VLAN划分与子网划分附加VLAN信息的方法VLAN划分交换机的端口类型(Access和Trunk)一、访问链接二、汇聚链接汇聚链接VLAN间通信为什么要进行VLAN间通信?路由器实现VLAN间通信路由器和交换机的连接方式通信细节三层交换机实现VLAN间通信加速VLAN间通信三层交换机与路由器三层交换机路由器路由器和交换机配合构建LAN的实例使用VLAN设计局域网的特点VLAN增加网络的灵活性不使用VLA
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
如何用IDEA2022创建并初始化一个SpringBoot项目?目录如何用IDEA2022创建并初始化一个SpringBoot项目?0. 环境说明1. 创建SpringBoot项目 2.编写初始化代码0. 环境说明IDEA2022.3.1JDK1.8SpringBoot1. 创建SpringBoot项目 打开IDEA,选择NewProject创建项目。 填写项目名称、项目构建方式、jdk版本,按需要修改项目文件路径等信息。 选择springboot版本以及需要的包,此处只选择了springweb。 此处需特别注意,若你使用的是jdk1