
单文件组件在实际开发中是经常使用的,那么如何创建一个单文件组件呢?那么本篇就来简单入一下单文件组件。
1.切换到你想要创建该文件的目录下,我这里切换的是desktop这个目录,当然,也可以根据自己需要来进行切换该命令为 cd 目录/文件名称

2.打开cmd,输入npm config set registry https://registry.npm.taobao.org 切换/设置到淘宝镜像
安装全局vue脚手架(简单方便在哪里都可以使用)npm install -g @vue/cli

看到如下内容表示安装成功
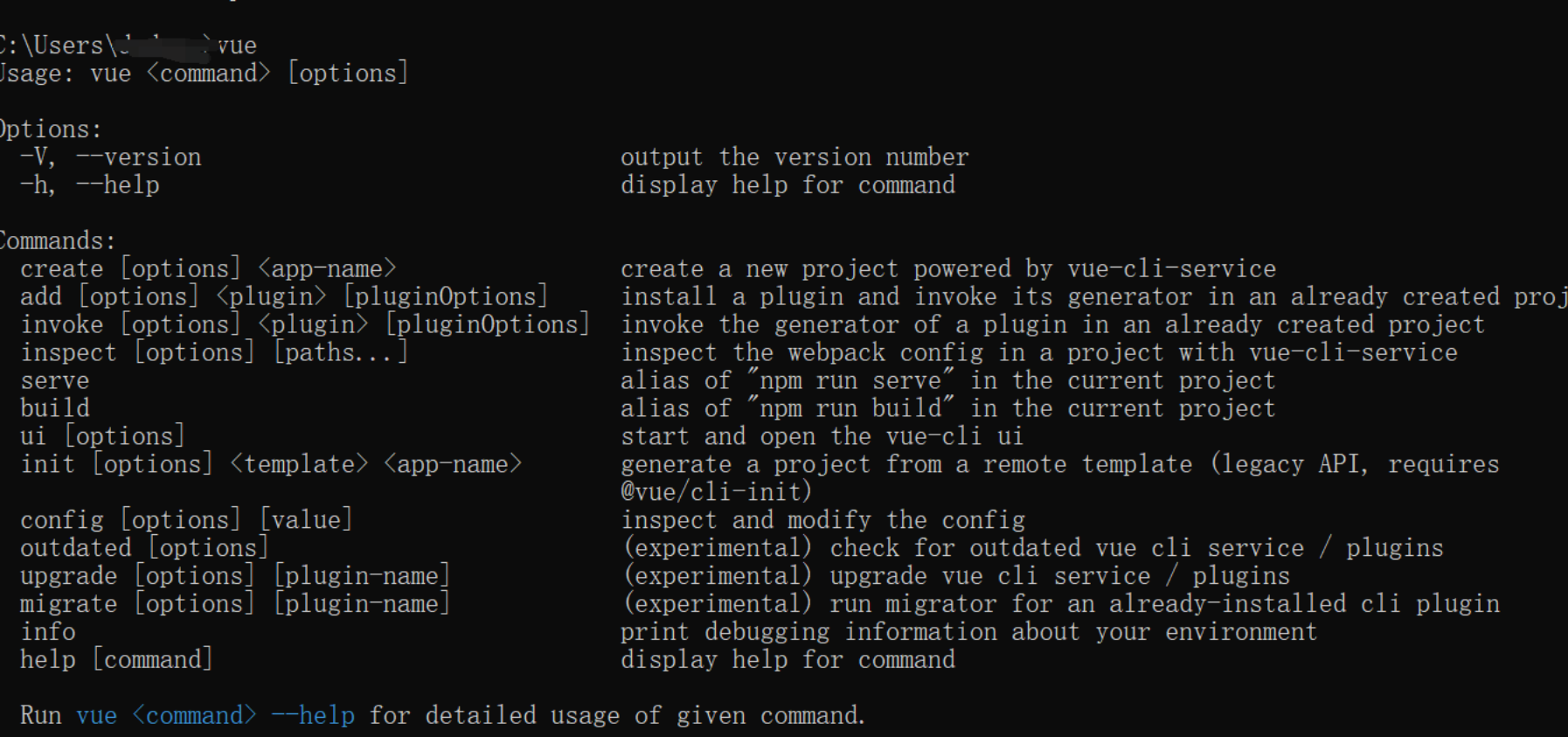
3.使用vue create 项目名称 创建项目,成功后会有一个vue版本的选择(按键盘的下箭头即可切换),这里我们选的是Vue2

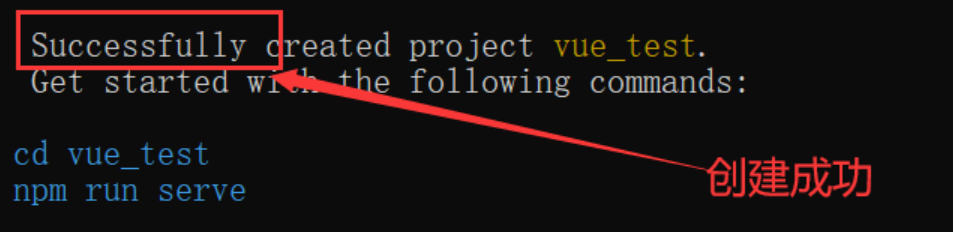
命令执行后,如果有下图所示,则表示创建成功(很贴心,下面第一行蓝色的代码就是切换到创建成功的目录上面,第二行则是运行该vue项目)
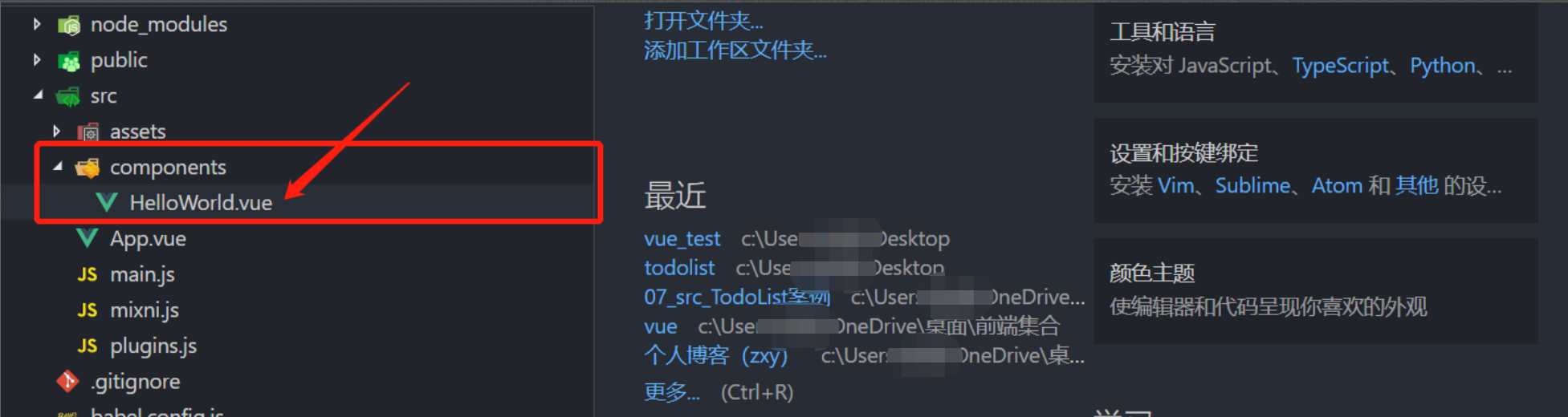
4.创建成功后该项目自带一个下图所示项目(到此为止一个基于脚手架的vue项目就完成了)

5.可以直接搜刚才所创建的文件,然后直接拖入vscode(有下面这些文件)我们可以找到src下面的components文件夹,在它里面有一个文件名叫HelloWorld.vue的文件,这里面就是写的上面图片的代码

下面简单的把该项目内的文件汇总了一下,文件创建完了,咱不能不知道这是干嘛的吧,

好奇的小伙伴会发现一个问题,就是在node_module下面有个vue文件,该文件内又包含着各种版本的vue,列如:vue.js ,vue.runtime.js等一大堆vue版本,下面来瞅瞅本本的区别
vue.js与vue.runtime.xxx.js的区别
(1) .vue.js是完整版的Vue,包含:核心功能+模板解析器。
(2) . vue.runtime. xxx. js是运行版的Vue,只包含核心功能,没有模板解析器。
因为vue.runtime.xxx. js没有模板解析器,所以不能使用template配置项,需要使用
render函数接收到的createElement函数去指定具体内容。
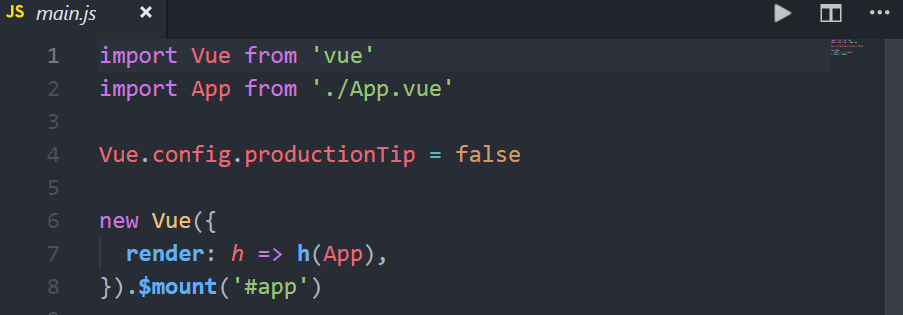
使用vue inspect > output. js可以查看到Vue脚手架的默认配置。
使用vue.config. js可以对脚手架进行个性化定制(下面是vue.config.js的配置,可供参考)

const { defineConfig } = require('@vue/cli-service')
module.exports = defineConfig({
transpileDependencies: true,
lintOnSave: false
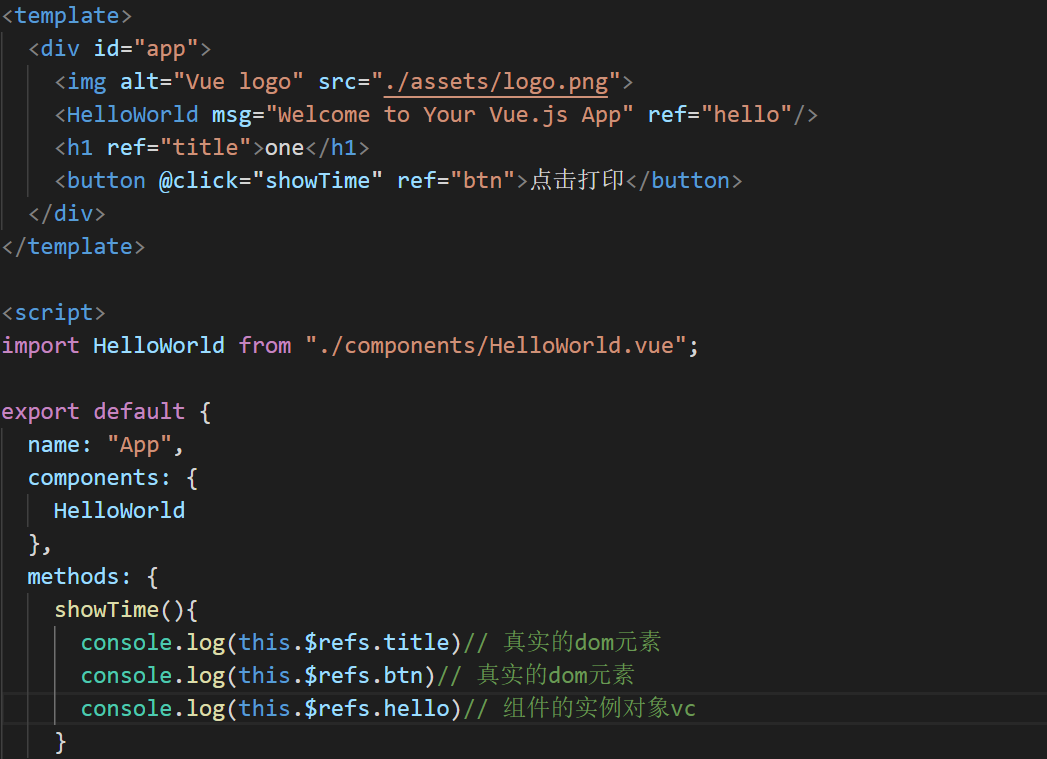
})1.被用来给元素或子组件注册引用信息,也可以说是用来代替id的
2.应用在htm1标签上获取的是真实DOM元素,应用在组件标签上是组件实例对象(VueComponent)
功能:让组件接收外部传过来的数据
(1)传递数据:<Demo name= " xxx" />
(2)接收数据:
第一种方式(只接收)
props: ["name"]第二种方式(限制类型)
props: {
name:string,
age:Number
}第三种方式(限制类型、限制必要性、指定默认值)
props :{
name : {
type:String, //类型
required:true, //必要性
default:'老王' //默认值
}
}注: props 是只读的,虽然是只读但是还可以被修改,Vue底层会监测到props的修改,如果进行了修改,就会发出警告,如果需求确实需要修改,那么就把props的内容复制到data里面,然后通过修改data里面的内容实现需求
功能:可以把多个组件共用的配置提取成一 个混入对象
使用方式:
第一步定义混合,例如:data(){....},methods:{....}},将该组件的methods或者data配置项拿出去,放到mixin.js里面,这里是将methods放到了mixin.js里面


第二步使用混入

功能:用于增强Vue
本质:包含insta1l方法的一个对 象,install的第一 个 参数是Vue, 第二个以后的参 数是插件使用者传递的据。
1.定义插件:install = function (Vue, options) {// 添加全局过滤器Vue.filter(....),这里也可以添加其他的,比如自定义指令等

2.使用插件: Vue.use()

scoped样式作用:让样式在局部生效,防止冲突。
写法: <style scoped> </style>
一般scoped只写在子组件内,app内不需要写,因为在app内大部分都是基础样式,每个组件都能用到的,如果加了scoped,那么只对本组件生效,其他的组件就无法使用

点赞:您的赞赏是我前进的动力! 👍
收藏:您的支持我是创作的源泉! ⭐
评论:您的建议是我改进的良药! ✍
山鱼的个人社区:欢迎大家加入我的个人社区—— 山鱼社区
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只