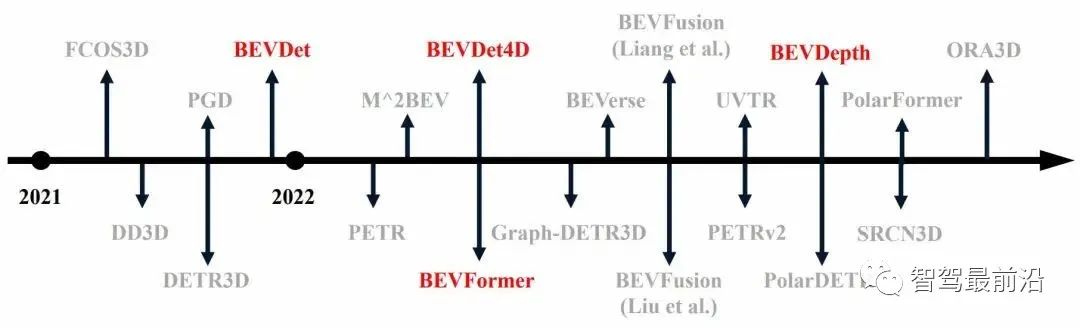
 图1 三维目标检测近一年发展
图1 三维目标检测近一年发展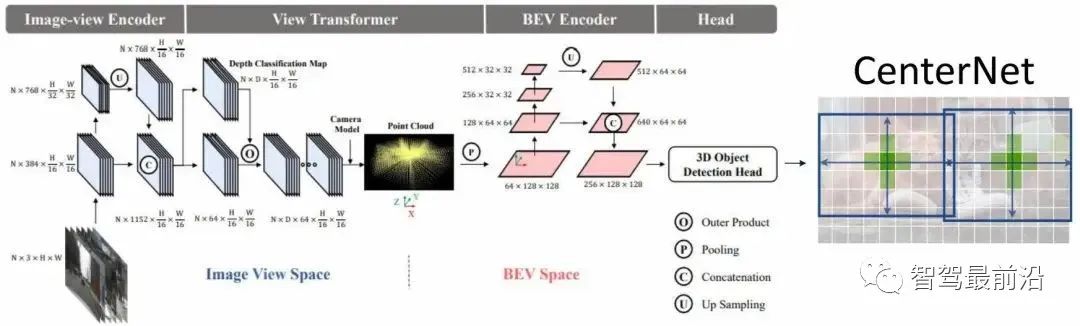 图2 BEVDet网络结构视角变化模块过程分两步走,首先假设要变换的特征的大小是VxCxHxW,然后在图像空间以分类的方式去预测一个深度,对于每一个像素得到一个D维的深度分布,那么就可以利用这两个将不同深度的特征进行渲染,得到一个视觉特征,然后利用相机模型将它投影到3维空间中,对3维空间进行体素化,其次进行splat过程得到BEV特征。视角变化模块的一个非常重要特点是在数据增缓中起到了一个相互隔离的作用。具体而言就是经过相机的内参,可以投影到3维空间中得到相机坐标系上的一个点,当数据增广的作用在图像空间上点的时候,为了维持在这个相机坐标系上点的坐标不变,则需要做一个逆变换,即在相机坐标系上面的一个坐标在增广前和增广后是不变的,这就起到了一个相互隔离的效果。相互隔离的缺点是图像空间的增广并不会对BEV空间的学习起到正则化的作用,优点可以提高BEV空间学习的鲁棒性我们从实验上可以得到几个比较重要的结论。首先,在使用了BEV空间的编码器之后,算法更容易陷入过拟合的情况。另外一个结论是BEV空间的增广会比图像空间的增广对性能的影响更大。还有就是BEV空间的目标尺寸和类别高度的相关,同时目标之间的重合长度很小会导致一些问题,观察到在图像空间里面设计的非极大值抑制方法并非是最优的。同时加速的策略的核心是利用并行的计算方式去给不同小的计算任务去分配独立的线程去达到并行计算加速的目的,优点在于没有额外的显存开销。
图2 BEVDet网络结构视角变化模块过程分两步走,首先假设要变换的特征的大小是VxCxHxW,然后在图像空间以分类的方式去预测一个深度,对于每一个像素得到一个D维的深度分布,那么就可以利用这两个将不同深度的特征进行渲染,得到一个视觉特征,然后利用相机模型将它投影到3维空间中,对3维空间进行体素化,其次进行splat过程得到BEV特征。视角变化模块的一个非常重要特点是在数据增缓中起到了一个相互隔离的作用。具体而言就是经过相机的内参,可以投影到3维空间中得到相机坐标系上的一个点,当数据增广的作用在图像空间上点的时候,为了维持在这个相机坐标系上点的坐标不变,则需要做一个逆变换,即在相机坐标系上面的一个坐标在增广前和增广后是不变的,这就起到了一个相互隔离的效果。相互隔离的缺点是图像空间的增广并不会对BEV空间的学习起到正则化的作用,优点可以提高BEV空间学习的鲁棒性我们从实验上可以得到几个比较重要的结论。首先,在使用了BEV空间的编码器之后,算法更容易陷入过拟合的情况。另外一个结论是BEV空间的增广会比图像空间的增广对性能的影响更大。还有就是BEV空间的目标尺寸和类别高度的相关,同时目标之间的重合长度很小会导致一些问题,观察到在图像空间里面设计的非极大值抑制方法并非是最优的。同时加速的策略的核心是利用并行的计算方式去给不同小的计算任务去分配独立的线程去达到并行计算加速的目的,优点在于没有额外的显存开销。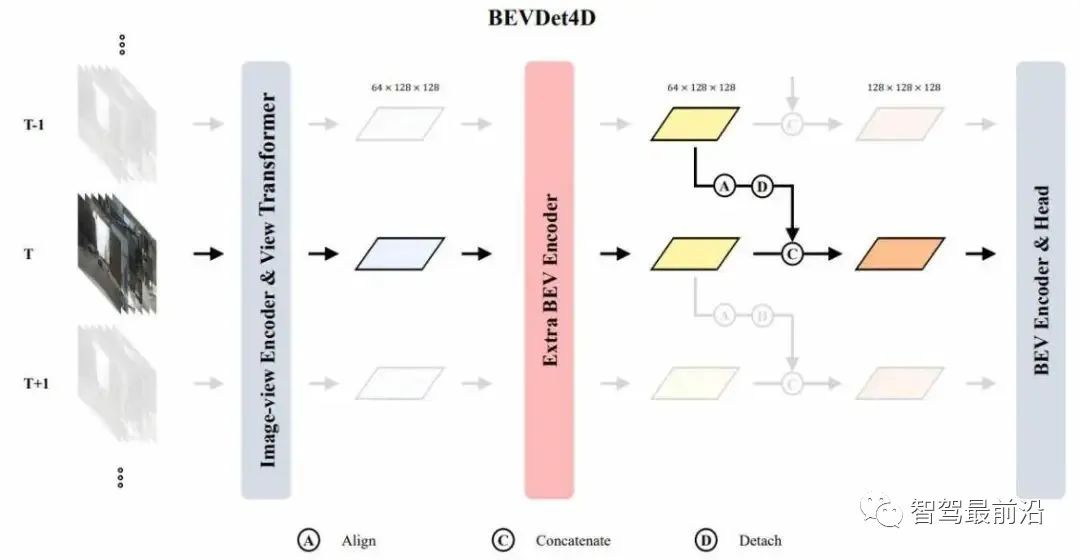 图3 BEVDet4D网络结构怎么去设计与网络结构相匹配的目标变量?在这之前,我们首先要了解一下网络的一些关键的特性,首先是特征的感受野,因为网络是通过BP学习,特征的感受野是由输出空间所决定的。自动驾驶的感知算法的输出空间一般会定义在自车周围的一定范围内的空间,特征图就可以视为该连续空间上一个均匀分布,角点对齐的一个离散采样。由于在特征图的感受野是定义在自车周围的一定范围内就会随着自车的运动而发生了变化,因此在两个不同时间节点,特征图的感受野在世界坐标系上面是有一定的偏移的。若直接把两个特征进行一个拼接,静态目标在两个特征图中的位置是不同的,动态目标在这两个特征途图中的偏移量等于自测的偏移量加上动态目标在世界坐标系中的偏移量。根据模式一致的一个原则,既然拼接的特征里面目标的偏移量是跟自车相关的,因此在设定网络的学习目标的时候,应该是目标在这两张特征图中的位置的变化量。根据下面的公式去进行推导,可以得到一个学习的目标是跟自测的运动是不相关的,只跟目标在世界坐标系下面的一个运动相关。
图3 BEVDet4D网络结构怎么去设计与网络结构相匹配的目标变量?在这之前,我们首先要了解一下网络的一些关键的特性,首先是特征的感受野,因为网络是通过BP学习,特征的感受野是由输出空间所决定的。自动驾驶的感知算法的输出空间一般会定义在自车周围的一定范围内的空间,特征图就可以视为该连续空间上一个均匀分布,角点对齐的一个离散采样。由于在特征图的感受野是定义在自车周围的一定范围内就会随着自车的运动而发生了变化,因此在两个不同时间节点,特征图的感受野在世界坐标系上面是有一定的偏移的。若直接把两个特征进行一个拼接,静态目标在两个特征图中的位置是不同的,动态目标在这两个特征途图中的偏移量等于自测的偏移量加上动态目标在世界坐标系中的偏移量。根据模式一致的一个原则,既然拼接的特征里面目标的偏移量是跟自车相关的,因此在设定网络的学习目标的时候,应该是目标在这两张特征图中的位置的变化量。根据下面的公式去进行推导,可以得到一个学习的目标是跟自测的运动是不相关的,只跟目标在世界坐标系下面的一个运动相关。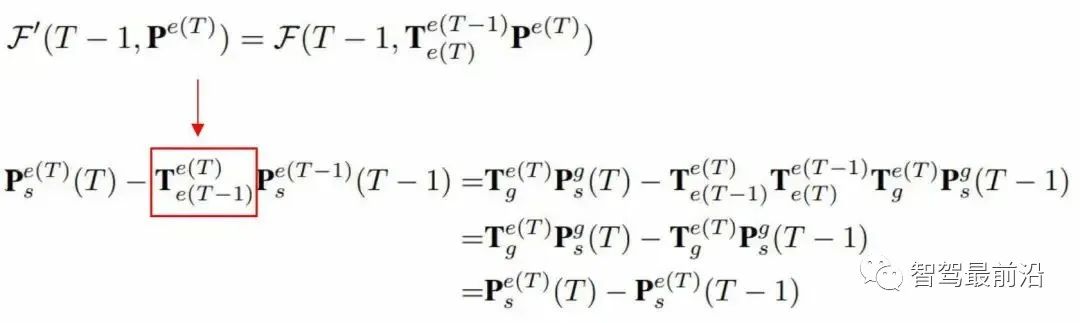 我们从上述推导得到的学习目标和当前主流方法的学习目标区别就在于去掉了时间成分,而速度等于位移/时间,但这两个特征中并没有提供时间相关的线索,所以如果学习这个速度的目标,需要网络去准确的估计出这个时间的成分,这就增加了一个学习的难度。在实际中,我们可以把训练过程中两帧的时间设定为恒定值,一个恒定的时间间隔网络是可以通过学 BP学习到的。在时域的增广当中,我们在训练过程中随机的采用不同的时间间隔,在不同的时间间隔下,目标在两张这张图中的偏移量不同,学习的目标偏移量也不同,以此达到模型对不同偏移量的鲁邦效果。同时,模型对于目标的偏移量是有一定的灵敏度的,即如果间隔太小,两帧之间变化太小就很难被感知到。因此在测试的时候选择一个合适的时间间隔,可以有效提高模型的一个泛化的性能。
我们从上述推导得到的学习目标和当前主流方法的学习目标区别就在于去掉了时间成分,而速度等于位移/时间,但这两个特征中并没有提供时间相关的线索,所以如果学习这个速度的目标,需要网络去准确的估计出这个时间的成分,这就增加了一个学习的难度。在实际中,我们可以把训练过程中两帧的时间设定为恒定值,一个恒定的时间间隔网络是可以通过学 BP学习到的。在时域的增广当中,我们在训练过程中随机的采用不同的时间间隔,在不同的时间间隔下,目标在两张这张图中的偏移量不同,学习的目标偏移量也不同,以此达到模型对不同偏移量的鲁邦效果。同时,模型对于目标的偏移量是有一定的灵敏度的,即如果间隔太小,两帧之间变化太小就很难被感知到。因此在测试的时候选择一个合适的时间间隔,可以有效提高模型的一个泛化的性能。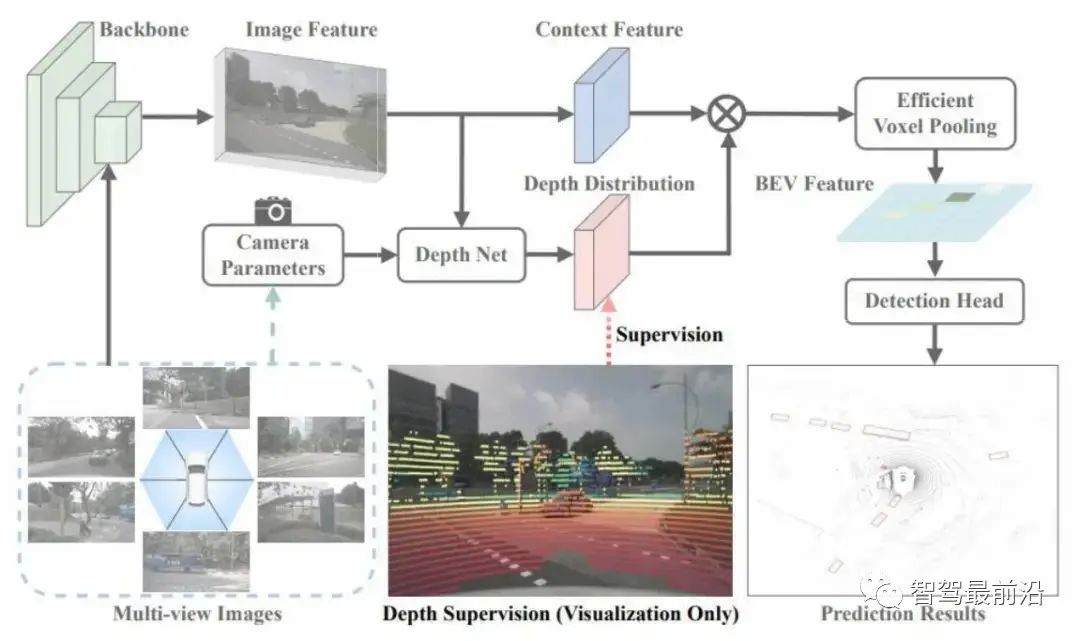 图4 BEVDepth网络结构这篇工作另外一个方面是把特征和深度分了两个分支进行估计,并且在深度估计的分支里面增加额外的残差网络以提高深度估计分支的感受野。研究人员认为这个相机内外参的精度问题会导致context和深度是不对齐的,当这个深度估计的网络的感受不够大的时候,会有一定的精度损失。最后就是将这个相机的内参作为一个深度估计的分支输入,使用了一个类似于NSE的方式,对输入特征的通道进行一个通道层面的调整,这可以有效提高网络对于不同的相机内参的鲁棒性。
图4 BEVDepth网络结构这篇工作另外一个方面是把特征和深度分了两个分支进行估计,并且在深度估计的分支里面增加额外的残差网络以提高深度估计分支的感受野。研究人员认为这个相机内外参的精度问题会导致context和深度是不对齐的,当这个深度估计的网络的感受不够大的时候,会有一定的精度损失。最后就是将这个相机的内参作为一个深度估计的分支输入,使用了一个类似于NSE的方式,对输入特征的通道进行一个通道层面的调整,这可以有效提高网络对于不同的相机内参的鲁棒性。很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我想知道是否可以通过自动创建数组来插入数组,如果数组不存在的话,就像在PHP中一样:$toto[]='titi';如果尚未定义$toto,它将创建数组并将“titi”压入。如果已经存在,它只会推送。在Ruby中我必须这样做:toto||=[]toto.push('titi')可以一行完成吗?因为如果我有一个循环,它会测试“||=”,除了第一次:Person.all.eachdo|person|toto||=[]#with1billionofperson,thislineisuseless999999999times...toto.push(person.name)你有更好的解决方案吗?
我刚刚看到whitehouse.gov正在使用drupal作为CMS和门户技术。drupal的优点之一似乎是很容易添加插件,而且编程最少,即重新发明轮子最少。这实际上正是Ruby-on-Rails的DRY理念。所以:drupal的缺点是什么?Rails或其他基于Ruby的技术有哪些不符合whitehouse.org(或其他CMS门户)门户技术的资格? 最佳答案 Whatarethedrawbacksofdrupal?对于Ruby和Rails,这确实是一个相当主观的问题。Drupal是一个可靠的内容管理选项,非常适合面向社区的站点。它
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3