本篇文章讲述 Flink Application On Yarn 提交模式下,从命令提交到 AM 容器创建
1、脚本入口
flink run-application -t yarn-application hdfs:///TopSpeedWindowing.jar以上是flink application 模式的 任务提交命令,可以发现,任务提交入口在 FLINK_HOME/bin 目录中的flink 脚本中
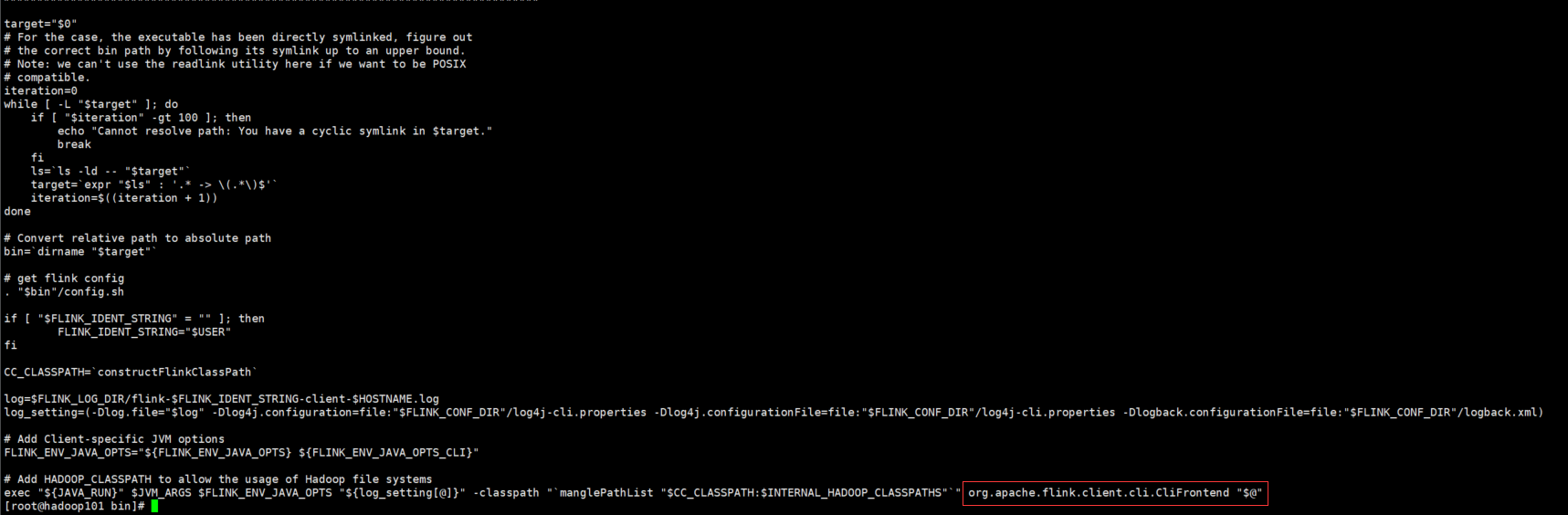
根据flink 脚本中的执行操作,可发现flink 脚本最终指向了 org.apache.flink.client.cli.CliFrontend 这个入口类
2、flink 程序入口类org.apache.flink.client.cli.CliFrontend
main 作为程序的入口方法,从main 方法开始进行代码跟踪
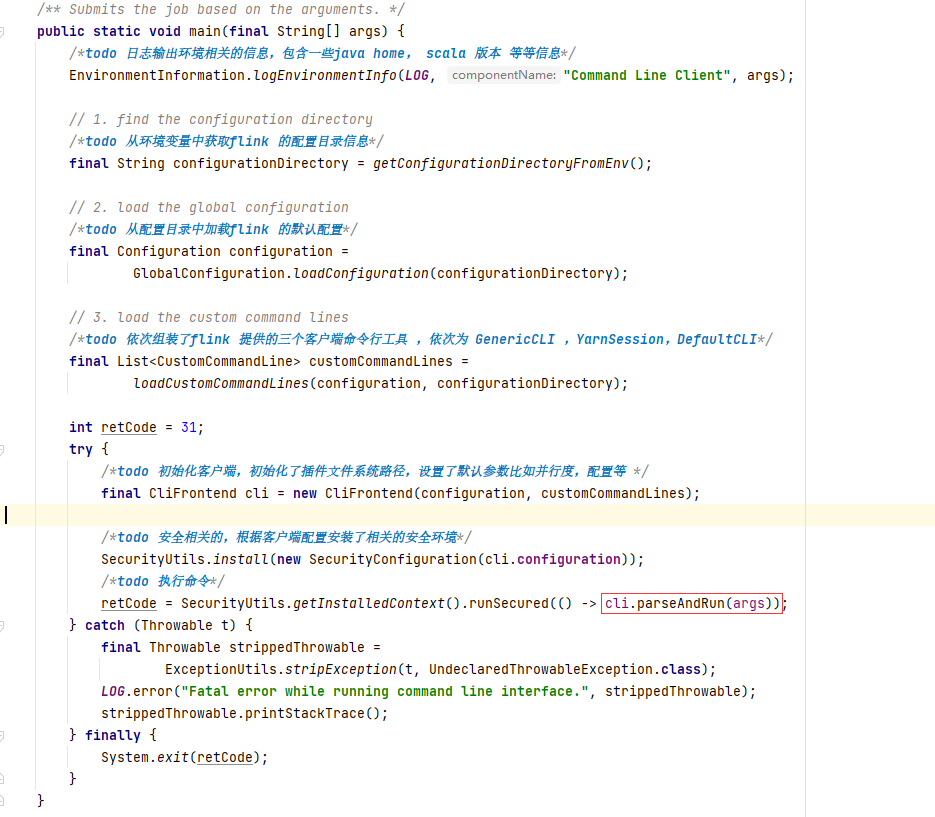
根据 CliFrontend 中的main 方法,可以发现,在执行命令前,进行了一些环境的信息输出,flink 配置加载,运行环境准备等工作,最后 执行了 parseAndRun 方法,开始执行。
进入parseAndRun 方法,发现,系统根据提交命令参数进行解析,提取执行命令的类型,根据命令类型不同,执行对应的操作。
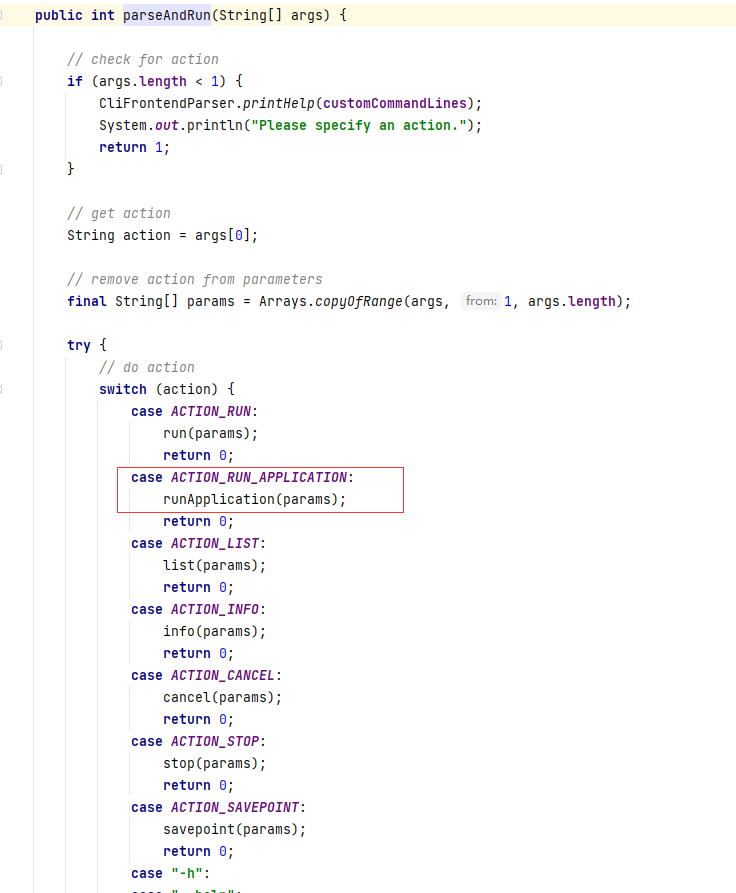
进入 runApplication 方法 ,继续跟踪 application 模式下的任务提交逻辑
protected void runApplication(String[] args) throws Exception {
LOG.info("Running 'run-application' command.");
final Options commandOptions = CliFrontendParser.getRunCommandOptions();
//todo 组装提交命令行对象
final CommandLine commandLine = getCommandLine(commandOptions, args, true);
// todo 如果包含help 命令 比如 flink flink run-application --help 这种命令,那么就进行命令帮助输出
if (commandLine.hasOption(HELP_OPTION.getOpt())) {
CliFrontendParser.printHelpForRunApplication(customCommandLines);
return;
}
// todo 获取激活的命令行对象
final CustomCommandLine activeCommandLine =
validateAndGetActiveCommandLine(checkNotNull(commandLine));
final ApplicationDeployer deployer =
new ApplicationClusterDeployer(clusterClientServiceLoader);
final ProgramOptions programOptions;
final Configuration effectiveConfiguration;
// No need to set a jarFile path for Pyflink job.
// todo 如果是 pyflink 的命令入口
if (ProgramOptionsUtils.isPythonEntryPoint(commandLine)) {
// todo 组装 pyflink 所需要的依赖配置
programOptions = ProgramOptionsUtils.createPythonProgramOptions(commandLine);
effectiveConfiguration =
getEffectiveConfiguration(
activeCommandLine,
commandLine,
programOptions,
Collections.emptyList());
} else {
// todo 组装非pyflink 程序的配置
programOptions = new ProgramOptions(commandLine);
programOptions.validate();
final URI uri = PackagedProgramUtils.resolveURI(programOptions.getJarFilePath());
effectiveConfiguration =
//todo 主要是做了将命令行中的配置覆盖 从 confDir 中读取的默认配置
getEffectiveConfiguration(
activeCommandLine,
commandLine,
programOptions,
Collections.singletonList(uri.toString()));
}
final ApplicationConfiguration applicationConfiguration =
new ApplicationConfiguration(
programOptions.getProgramArgs(), programOptions.getEntryPointClassName());
// todo 部署应用
deployer.run(effectiveConfiguration, applicationConfiguration);
}在 runApplication 方法中,程序进行了命令行对象的组装,程序运行配置的组装,然后进行任务提交,继续跟踪 deployer.run(effectiveConfiguration, applicationConfiguration);
发现在run 方法中,获取了一个集群描述器,然后进行了应用部署
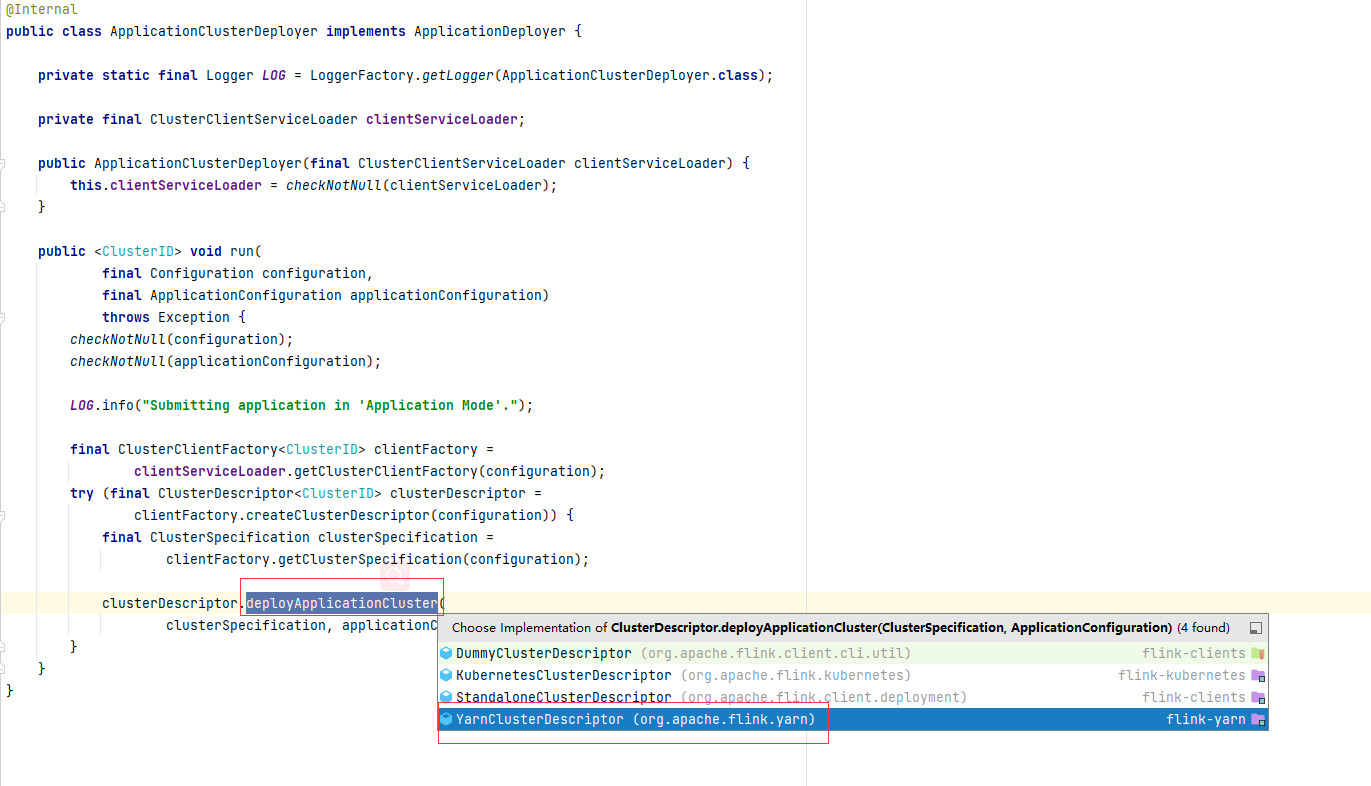
由于是采用的yarn application 模式,因此使用 YarnClisterDescriptor,进入到 deployApplicationCluster 方法中,可发现 其继续进行了 部署模式校验,任务jar 的校验 、配置应用等操作,最后向集群执行 部署

在部署 flink 任务到 yarn 上时,入口程序指定的是 YarnApplicationClusterEntryPoint.class.getName()
根据 deployInternal 方法的调用,可以发现,在 yarn application 模式下,部署并未传入 jobGraph ,此处也能说明,yarn application 的 流图生成是在 AM 容器中完成的
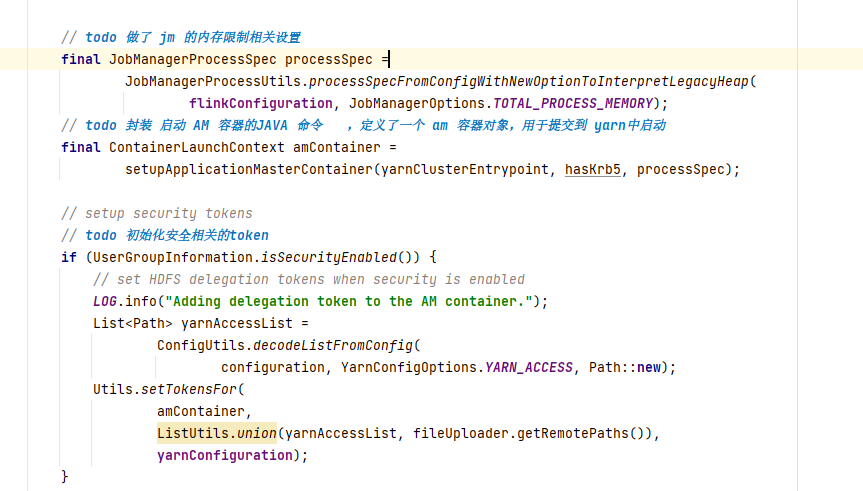
在 deployInternal 方法中,执行了大量的校验工作,比如进行了 Kerberos 认证校验,yarn 的资源校验, yarn 的队列校验等等,一切校验通过后,就开始创建AM 容器

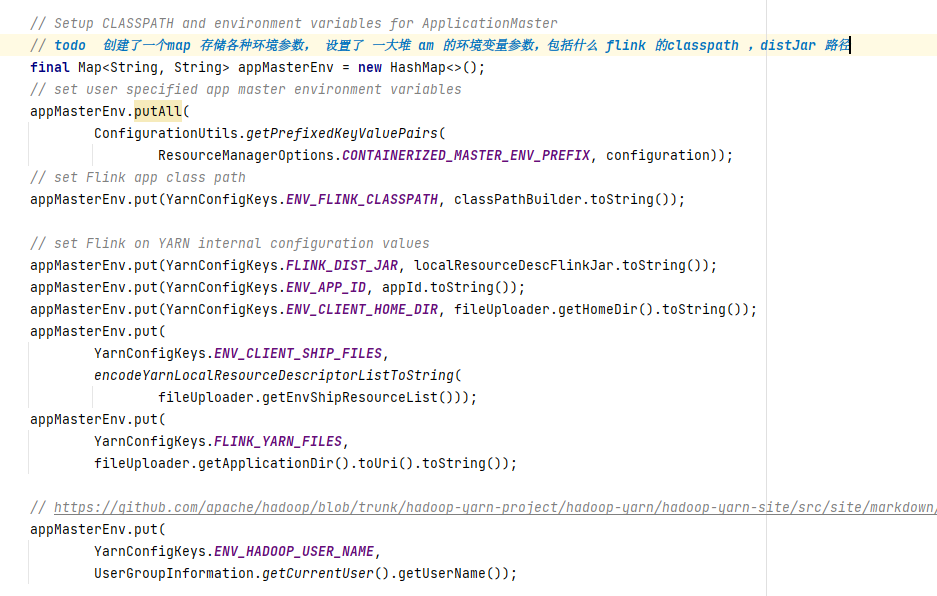
在创建AM 容器时,flink 进行了文件系统初始化 ,构造了 一个资源上传器,用于进行依赖的lib 包,配置文件的上传,上传能完成以后,设置了这些资源的classpath 信息,然后构造了AM 启动命令,由于yarn application 模式的启动入口传入的是YarnApplicationClusterEntryPoint,因此在构造 AM 中启动时运行的是 YarnApplicationClusterEntryPoint 的main 方法, 最后进行了 AM 容器提交

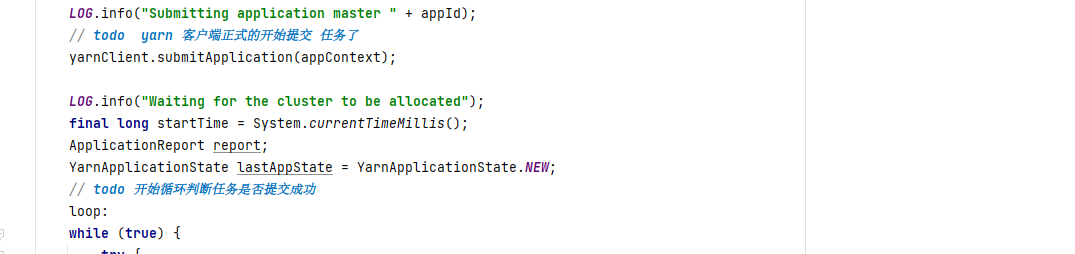
至此,flink 的任务终于提交到yarn 上,并开始创建AM 容器了
具体AM 容器中都干了些啥,咱们下回再说
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我已经通过提供MagickWand.h的路径尝试了一切,我安装了命令工具。谁能帮帮我?$geminstallrmagick-v2.13.1Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingrmagick:ERROR:Failedtobuildgemnativeextension./Users/ghazanfarali/.rvm/rubies/ruby-1.8.7-p357/bin/rubyextconf.rbcheckingforRubyversion>=1.8.5...yescheckingfor/