C语言网:2022年第十三届蓝桥杯大赛软件类省赛Python大学B组真题![]() https://www.dotcpp.com/oj/train/1034/
https://www.dotcpp.com/oj/train/1034/
只能说这波有点混,我估计 48.5 分左右 (满分 150)。广东总共 78 个省一,我只排到了第 33 (42.3%)
考前主要在力扣上面练,考试时发现并无卵用,打蓝桥杯还是要以真题为主
 考完没有第一时间写题解也是因为考试时有很多不懂的,现在已经是个要打国赛的人了,重新做一下
考完没有第一时间写题解也是因为考试时有很多不懂的,现在已经是个要打国赛的人了,重新做一下
| 填空题 | 编程题 | |||
| 5 分 | 10 分 | 15 分 | 20 分 | 25 分 |
| A、B | C、D | E、F | G、H | I、J |
【问题描述】
小蓝要把一个字符串中的字母按其在字母表中的顺序排列。
例如,LANQIAO 排列后为 AAILNOQ。
又如,GOODGOODSTUDYDAYDAYUP 排列后为 AADDDDDGGOOOOPSTUUYYY
请问对于以下字符串,排列之后字符串是什么?
WHERETHEREISAWILLTHEREISAWAY
【解析及代码】
string = 'WHERETHEREISAWILLTHEREISAWAY'
print(''.join(sorted(string)))You can do it if you have hands.
【问题描述】
有一个不超过 的正整数 n,知道这个数除以2至49后的余数如下表所示,求这个正整数最小是多少。
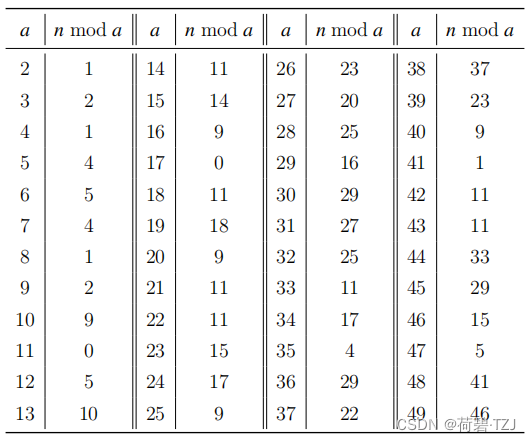
【解析及代码】
首先按照余数进行分类,求出余数相同的除数的最小公倍数
例如,余数为 1 的除数有 2, 4, 8, 41,这四个数的最小公倍数为 328,则当除数为 328 时余数也为 1
data = [0, 0, 1, 2, 1, 4, 5, 4, 1, 2, 9, 0, 5, 10,
11, 14, 9, 0, 11, 18, 9, 11, 11, 15, 17, 9,
23, 20, 25, 16, 29, 27, 25, 11, 17, 4, 29, 22,
37, 23, 9, 1, 11, 11, 33, 29, 15, 5, 41, 46]
# Python 3.9.0 版本特有
from math import lcm
mod_list = list(enumerate(data))[2:]
# 关于余数的字典
res_dict = {res: [] for res in data}
for mod, res in mod_list:
res_dict[res].append(mod)
# 按余数查询的最小公倍数字典
for res in res_dict:
res_dict[res] = lcm(*res_dict[res])
print(res_dict)得到关于余数的字典如下
{0: 187, 1: 328, 2: 9, 4: 35, 5: 564, 9: 400, 10: 13, 11: 59598, 14: 15, 18: 19, 15: 46, 17: 408, 23: 78, 20: 27, 25: 224, 16: 29, 29: 180, 27: 31, 22: 37, 37: 38, 33: 44, 41: 48, 46: 49}
因为最大的除数是 59598,所以作为搜索步长,其对应的余数 11 作为初始值
# 当前的结果
result = 11
# 当前的最小公倍数
pace = res_dict.pop(11)如果用 for 循环进行搜索的话,那么
假如对某一 a 存在:,此时又满足
为了保持在更新的过程中仍然保持这两个条件,搜索步长应该更新为 (lcm 为求最小公倍数的函数):
即此时的 p 既可被原本的 59598 整除,也可以被 328 整除,不影响原来的余数
for res in res_dict:
mod = res_dict[res]
while result % mod != res:
# 当前结果求余结果不满足条件时
result += pace
else:
# 更新搜索步长
pace = lcm(pace, mod)
print(result)答案:2022040920220409
【问题描述】
在 ISO 国际标准中定义了 A0 纸张的大小为 1189mm × 841mm,将 A0 纸沿长边对折后为 A1 纸,大小为 841mm × 594mm,在对折的过程中长度直接取下整(实际裁剪时可能有损耗)。将 A1 纸沿长边对折后为 A2 纸,依此类推。
输入纸张的名称,请输出纸张的大小。
【输入格式】
输入一行包含一个字符串表示纸张的名称,该名称一定是 A0、A1、A2、A3、A4、A5、A6、A7、A8、A9 之一。
【输出格式】
输出两行,每行包含一个整数,依次表示长边和短边的长度。
【样例】
| 输入 | 输出 |
| A0 |
|
| A1 |
|
【解析及代码】
require = int(input()[1])
size = [(1189, 841)]
# 当不是 A0
if require:
for time in range(require):
# 原长边、原短边
last_a, last_b = size[time]
# 原短边 -> 现长边
now_a = last_b
# 长边对折
now_b = last_a // 2
# 记录当前尺寸
size.append((now_a, now_b))
print(*size[require], sep='\n')
【问题描述】
小蓝对一个数的数位之和很感兴趣,今天他要按照数位之和给数排序。当两个数各个数位之和不同时,将数位和较小的排在前面,当数位之和相等时,将数值小的排在前面。
例如,2022 排在 409 前面,因为 2022 的数位之和是 6,小于 409 的数位之和 13。
又如,6 排在 2022 前面,因为它们的数位之和相同,而 6 小于 2022。
给定正整数 n,m,请问对 1 到 n 采用这种方法排序时,排在第 m 个的元素是多少?
【输入格式】
输入第一行包含一个正整数 n。
第二行包含一个正整数 m。
【输出格式】
输出一行包含一个整数,表示答案。
【样例】
| 输入 | 输出 | 说明 |
|
| 3 | 1 到 13 的排序为: 1, 10, 2, 11, 3, 12, 4, 13, 5, 6, 7, 8, 9。 第 5 个数为 3。 |
【评测用例规模与约定】
| 30% | 1 ≤ m ≤ n ≤ 300 |
| 50% | 1 ≤ m ≤ n ≤ 1000 |
| 100% | 1 ≤ m ≤ n ≤ |
【解析及代码】
from heapq import nsmallest
n, index = map(int, [input() for _ in range(2)])
# 求值函数: 所有数位之和
key_fun = lambda num: sum(map(int, str(num)))
# 使用堆排, 取前 n 小
print(nsmallest(index, range(1, n + 1), key=key_fun)[-1])
【问题描述】
蜂巢由大量的六边形拼接而成,定义蜂巢中的方向为:0 表示正西方向,1 表示西偏北 60◦,2 表示东偏北 60◦,3 表示正东,4 表示东偏南 60◦,5 表示西偏南 60◦。
对于给定的一点 O,我们以 O 为原点定义坐标系,如果一个点 A 由 O 点先向 d 方向走 p 步再向 (d + 2) mod 6 方向(d 的顺时针 120◦ 方向)走 q 步到达,则这个点的坐标定义为 (d, p, q)。在蜂窝中,一个点的坐标可能有多种。
下图给出了点 B(0, 5, 3) 和点 C(2, 3, 2) 的示意。

给定点 (d1, p1, q1) 和点 (d2, p2, q2),请问他们之间最少走多少步可以到达?
【输入格式】
输入一行包含 6 个整数 d1, p1, q1, d2, p2, q2 表示两个点的坐标,相邻两个整数之间使用一个空格分隔。
【输出格式】
输出一行包含一个整数表示两点之间最少走多少步可以到达。
【样例】
| 输入 | 输出 |
| 0 5 3 2 3 2 | 7 |
【评测用例规模与约定】
| 25% | p1, p2 ≤ |
| 50% | p1, p2 ≤ |
| 75% | p1, p2 ≤ |
| 100% | 0 ≤ d1, d2 ≤ 5,0 ≤ q1 < p1 ≤ |
【解析及代码】
基本的思路是,把 (d, p, q) 坐标转换成 xy 坐标,因为 xy 坐标可叠加
SQRT_3 = 3 ** 0.5
def dir_tran(direct):
''' direct: 方向
return: 单位步长的分量'''
if direct == 0:
x, y = -1, 0
elif direct == 1:
x, y = -1 / 2, SQRT_3 / 2
elif direct == 2:
x, y = 1 / 2, SQRT_3 / 2
else:
x, y = dir_tran(direct % 3)
x, y = -x, -y
return x, y
def loc_tran(d, p, q):
''' 将 (d, p, q) 坐标转换为 (x, y) 坐标'''
# 沿 d 方向走 p 步
x1, y1 = dir_tran(d)
x1, y1 = x1 * p, y1 * p
# 沿 (d+2)%6 方向走 q 步
x2, y2 = dir_tran((d + 2) % 6)
x2, y2 = x2 * q, y2 * q
return x1 + x2, y1 + y2
d1, p1, q1, d2, p2, q2 = map(int, input().split())
x1, y1 = loc_tran(d1, p1, q1)
x2, y2 = loc_tran(d2, p2, q2)
# 求出等价的距离向量
x, y = abs(x1 - x2), abs(y1 - y2)转换成 xy 坐标后,可求出距离向量 (就是坐标差值),记为 (x, y)。因为研究多少步可以走完 (3, -4) 这段距离和研究多少步可以走完 (3, 4) 这段距离是等价的,故对该距离向量取绝对值
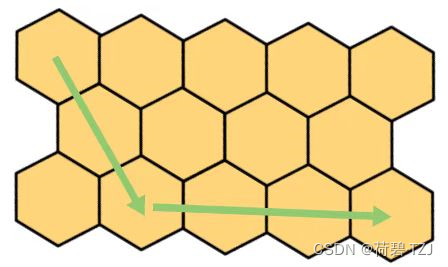
如果 ,则从某一点回到 x 轴需要走 n 步,同时会在 x 方向上产生最多
步的移动。当然,因为在回到 x 轴的过程中,可以向左下、右下移动,所以这个
是最多,而不是一定
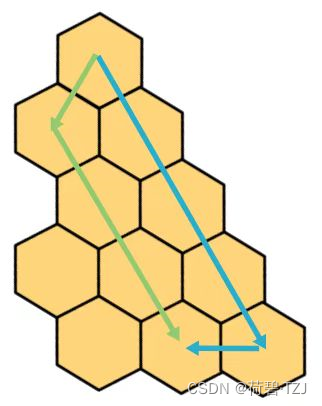
蓝色的线走了 6 步,绿色的线走了 5 步,差别就是绿色的线在回到 x 轴的过程中调整过方向
总步数 = 回到 x 轴的步数 + 在 x 轴上移动的步数
# 回到 x 轴所需的步数
total_pace = y / SQRT_3 * 2
# 回到 x 轴时, 在 x 方向上产生的最大偏移量
x_move = y / SQRT_3
# 在 x 方向上还需移动的步数
total_pace += max([0, x - x_move])
print(int(round(total_pace)))
【问题描述】
在一个字符串 S 中,如果 且
,则称
和
为边缘字符。如果
且
,则
和
也称为边缘字符。其它的字符都不是边缘字符。
对于一个给定的串 S,一次操作可以一次性删除该串中的所有边缘字符(操作后可能产生新的边缘字符)。
请问经过 次操作后,字符串 S 变成了怎样的字符串,如果结果为空则输出 EMPTY。
【输入格式】
输入一行包含一个字符串 S
【输出格式】
输出一行包含一个字符串表示答案,如果结果为空则输出 EMPTY
【样例】
| 输入 | 输出 |
| edda | EMPTY |
| sdfhhhhcvhhxcxnnnnshh | s |
【评测用例规模与约定】
| 25% | |S | ≤ |
| 50% | |S | ≤ |
| 75% | |S | ≤ |
| 100% | |S | ≤ |
【解析及代码】
import itertools as it
string = input()
for _ in range(pow(2, 63)):
# 保存相邻字符的比较结果
eq_flag = [string[i] == string[i + 1] for i in range(len(string) - 1)]
# 是否保留该位置的字符
keep_flag = [True] * len(string)
# 是否不再出现边缘字符?
all_done_flag = True
# 标记边缘字符
for i in range(len(string) - 2):
# S[i] == S[i+1], S[i+1] != S[i+2], 除去 S[i+1] S[i+2]
if eq_flag[i]:
if not eq_flag[i + 1]:
keep_flag[i + 1] = keep_flag[i + 2] = False
all_done_flag = False
# S[i] != S[i+1], S[i+1] == S[i+2], 除去 S[i] S[i+1]
else:
if eq_flag[i + 1]:
keep_flag[i] = keep_flag[i + 1] = False
all_done_flag = False
# 根据 keep_flag 进行保留
string = ''.join(it.compress(string, keep_flag))
# 退出: keep_flag 全部为 True / 字符串长度 < 3
if all_done_flag or len(string) < 3: break
print(string if string else 'EMPTY')
时间超限,刷不上去了
【问题描述】
对于一个排列 ,定义价值
为
至
中小于
的数的个数,即
。定义 A 的价值为
给定 n,求 1 至 n 的全排列中所有排列的价值之和。
【输入格式】
输入一行包含一个整数 n
【输出格式】
输出一行包含一个整数表示答案,由于所有排列的价值之和可能很大,请输出这个数除以 998244353 的余数
【样例】
| 输入 | 输出 | 说明 |
| 3 | 9 |
|
| 2022 | 593300958 |
【评测用例规模与约定】
| 40% | n ≤ 20 |
| 70% | n ≤ 5000 |
| 100% | 2 ≤ n ≤ |
【解析及代码】
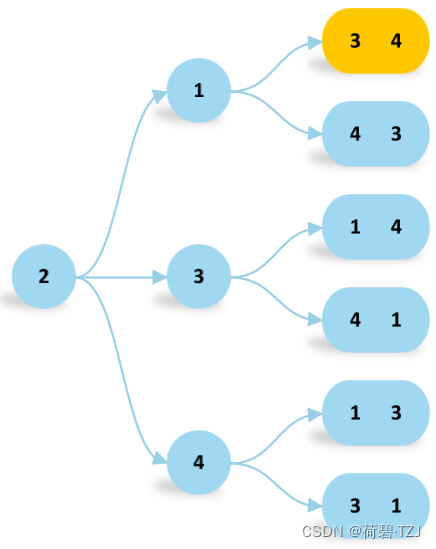
以 4 的全排列为例,当第一位是 2 时,总共有 种排列方式。而且每一种排列方式下必有“3 4”大于 2,贡献了 2 × 6 = 12 的价值,同理可得:
总共是
计算完第一位产生的贡献后,剔除第一位,剩下“1 3 4”全排列产生的贡献,等价为“1 2 3”全排列产生的贡献
当现在的第一位为 1 时,总共有 种排列方式:
总共是
剔除第二位,剩下 3 4,正反两种排列总共贡献 1。全排列所有末两位的总贡献即为
答案为 36 + 24 + 12 = 72
对于 4,全排列的价值为:
对于 n,全排列的价值为:
n = int(input())
mod = 998244353
value = n * (n - 1) / 4 % mod
for i in range(1, n + 1):
value = value * i % mod
print(round(value))
在阶乘的时候一定要用 for 循环边乘边求余数,不要用 math 库的 factorial
【问题描述】
小蓝最近正在玩一款 RPG 游戏。他的角色一共有 N 个可以加攻击力的技能。其中第 i 个技能首次升级可以提升 点攻击力,以后每次升级增加的点数都会减少
。
(上取整) 次之后,再升级该技能将不会改变攻击力。
现在小蓝可以总计升级 M 次技能,他可以任意选择升级的技能和次数。请你计算小蓝最多可以提高多少点攻击力?
【输入格式】
输入第一行包含两个整数 N 和 M
以下 N 行每行包含两个整数 和
【输出格式】
输出一行包含一个整数表示答案
【样例】
| 输入 | 输出 |
|
|
|
【评测用例规模与约定】
| 40% | 1 ≤ N, M ≤ 1000 |
| 60% | 1 ≤ N ≤ |
| 100% | 1 ≤ N ≤ |
【解析及代码】
这份代码的瓶颈主要在于 M 太大了,下面是比较简单的思路
读取输入之后,对 进行排序,然后每次都取出列表末端的技能 (即最大值)
将技能取出并使用后,修改技能点数,利用 bisect 库的二分法放回技能列表
import bisect
n, m = map(int, input().split())
skill = [list(map(int, input().split())) for _ in range(n)]
skill.sort()
answer = 0
for i in range(m):
if skill[-1][0] <= 0: break
answer += skill[-1][0]
# 修改技能点数, 并用二分法插入
skill[-1][0] -= skill[-1][1]
bisect.insort(skill, skill.pop(-1))
print(answer)
【问题描述】
给定一个长度为 N 的整数序列:。现在你有一次机会,将其中连续的 K 个数修改成任意一个相同值。请你计算如何修改可以使修改后的数列的最长不下降子序列最长,请输出这个最长的长度。
最长不下降子序列是指序列中的一个子序列,子序列中的每个数不小于在它之前的数。
【输入格式】
输入第一行包含两个整数 N 和 K
第二行包含 N 个整数
【输出格式】
输出一行包含一个整数表示答案
【样例】
| 输入 | 输出 |
|
| 4 |
【评测用例规模与约定】
| 20% | 1 ≤ K ≤ N ≤ 100 |
| 30% | 1 ≤ K ≤ N ≤ 1000 |
| 50% | 1 ≤ K ≤ N ≤ 10000 |
| 100% | 1 ≤ K ≤ N ≤ |
【解析及代码】
我有个可以找到最优解的思路,不过要写的话代码太多,懒得做。从左到右做个递增序列的搜索,从右到左做个递增序列的搜索,变换成两个递增序列的拼接问题
挂个 C++ 大佬的满分做法:Link ~
【问题描述】
给定一个长度为 N 的数列 。现在小蓝想通过若干次操作将这个数列中每个数字清零。
每次操作小蓝可以选择以下两种之一:
1. 选择一个大于 0 的整数,将它减去 1;
2. 选择连续 K 个大于 0 的整数,将它们各减去 1。
小蓝最少经过几次操作可以将整个数列清零?
【输入格式】
输入第一行包含两个整数 N 和 K
第二行包含 N 个整数
【输出格式】
输出一个整数表示答案
【样例】
| 输入 | 输出 |
|
| 6 |
【评测用例规模与约定】
| 20% | 1 ≤ K ≤ N ≤ 10 |
| 40% | 1 ≤ K ≤ N ≤ 100 |
| 50% | 1 ≤ K ≤ N ≤ 1000 |
| 60% | 1 ≤ K ≤ N ≤ 10000 |
| 70% | 1 ≤ K ≤ N ≤ 100000 |
| 100% | 1 ≤ K ≤ N ≤ 1000000, 0 ≤ Ai ≤ 1000000 |
【解析及代码】
从测试结果来看,只对了一部分样例,这个并不是最优的做法,接下来讲讲怎么一本正经的骗分
对于 3 1 2 4 5,操作长度为 3 时,最优的操作应当是:
如果将两种操作合并成“链式减 1”,则上述操作等价于:
在某一轮链式减 1 中,该区间首元素的数值即为操作数 (直接将首元素置 0),其它元素的减少量不高于上一位的减少量、不高于本身数值
n, k = map(int, input().split())
seq = list(map(int, input().split()))
# 记录操作次数
time, pin = 0, 0
while pin < n:
if seq[pin]:
# 操作次数 = 当前 pin 指向的值
time += seq[pin]
# 链式操作量: 必是降序
sub_list = [seq[pin]]
seq[pin] = 0
# 操作不超过限制个数的数
for next_ in range(pin + 1, min([pin + k, n])):
# 计算可减少的量
sub = min([sub_list[-1], seq[next_]])
if sub == 0: break
# 存储减少量, 并减少
sub_list.append(sub)
seq[next_] -= sub
pin += 1
print(time)
运行bundleinstall后出现此错误:Gem::Package::FormatError:nometadatafoundin/Users/jeanosorio/.rvm/gems/ruby-1.9.3-p286/cache/libv8-3.11.8.13-x86_64-darwin-12.gemAnerroroccurredwhileinstallinglibv8(3.11.8.13),andBundlercannotcontinue.Makesurethat`geminstalllibv8-v'3.11.8.13'`succeedsbeforebundling.我试试gemin
我已经通过提供MagickWand.h的路径尝试了一切,我安装了命令工具。谁能帮帮我?$geminstallrmagick-v2.13.1Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingrmagick:ERROR:Failedtobuildgemnativeextension./Users/ghazanfarali/.rvm/rubies/ruby-1.8.7-p357/bin/rubyextconf.rbcheckingforRubyversion>=1.8.5...yescheckingfor/
目录前言: 一、ASC分析代码实现二、 卡片分析代码实现三、 直线分析代码实现四、货物摆放分析代码实现小结:前言: 在刷题的过程中,发现蓝桥杯的题目和力扣的差别很大。让人有一种不一样的感觉,蓝桥杯题目偏向对于实际问题用编程去的解决,而力扣给人感觉很锻炼自己的编程思维,逻辑能力。两者结合去刷,相信会有不一样的收获。 一、ASC 已知大写字母A的ASCII码为65,请问大写字母L的ASCII码是多少?分析 这道题目看上去很简单,我们需确定自己计算的准确,所以我建议用编程去解决。代码实现publicclassTest8{publicstaticvoidmain(String[]args){Sy
自从我将我的应用程序部署到heroku以来,在过去的几天里,我一直在断断续续地收到这个错误。它发生在我开始使用unicorn作为服务器之前和之后。有时我可以通过使用herokurunrakedb:migrate然后herokurestart让它恢复运行,但这只修复了几个小时,它又坏了。至于网页,它说“应用程序错误”。日志不是很有用,但每次发生此错误时都会显示以下内容:[2014-10-27T21:13:31.675956#2]ERROR--:worker=1PID:8timeout(16s>15s),killing[2014-10-27T21:13:31.731646#14]INFO-
?作者主页:静Yu?简介:CSDN全栈优质创作者、华为云享专家、阿里云社区博客专家,前端知识交流社区创建者?社区地址:前端知识交流社区?博主的个人博客:静Yu的个人博客?博主的个人笔记本:前端面试题个人笔记本只记录前端领域的面试题目,项目总结,面试技巧等等。接下来会更新蓝桥杯官方系统基础练习的VIP试题,依然包括解题思路,源代码等等。问题描述:给定当前的时间,请用英文的读法将它读出来。时间用时h和分m表示,在英文的读法中,读一个时间的方法是: 如果m为0,则将时读出来,然后加上“o’clock”,如3:00读作“threeo’clock”。 如果m不为0,则将时读出来,然后将分读出来,如5
考拉版本:2.2.0Errormessage:/scss/styles.scss/System/Library/Frameworks/Ruby.framework/Versions/2.3/usr/lib/ruby/2.3.0/rubygems/dependency.rb:319:into_specs':Couldnotfind'sass'(>=0)among15totalgem(s)(Gem::LoadError)Checkedin'GEM_PATH=/Users/monstercritic/.gem/ruby/2.3.0:/Library/Ruby/Gems/2.3.0:/Syst
当我尝试安装rmagic时:geminstallrmagic它给出了错误:Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingrmagick:ERROR:Failedtobuildgemnativeextension./home/biske/.rbenv/versions/2.0.0-p247/bin/rubyextconf.rbcheckingforRubyversion>=1.8.5...yescheckingforgcc...yescheckingforMagick-config...yesche
我最近注意到ActiveRecord对象上的方法changed?在Rails3.2.13和Rails4.0.1之间发生了变化。问题在于连接到数据库中整数字段的字段。假设我的模型Model带有number整数字段:#Rails3.2.13m=Model.lastm.number#=>5m.number='5hello'm.number#=>5m.number_changed?#=>truem.changed?#=>truem.changes#=>{:number=>[5,5]}#Rails4.0.1m=Model.lastm.number#=>5m.number='5hello'm.nu
我们有一个Rubyv.2.0.0-p247在Railsv4.0.1应用程序使用pggemv0.17.0.应用在MacOSXMavericksv10.9下顺利运行与PostgreSQLServerv9.2.4使用HomeBrew安装但它在Ubuntuv13.04下抛出以下异常使用PostgreSQLServer9.1:PG::UnableToSend:serverclosedtheconnectionunexpectedlyThisprobablymeanstheserverterminatedabnormallybeforeorwhileprocessingtherequest.异常发
十四届蓝桥青少组模拟赛Python-20221108T1.二进制位数十进制整数2在十进制中是1位数,在二进制中对应10,是2位数。十进制整数22在十进制中是2位数,在二进制中对应10110,是5位数。请问十进制整数2022在二进制中是几位数?print(len(bin(2022))-2)#运行结果:11T2.晨跑小蓝每周六、周日都晨跑,每月的1、11、21、31日也晨跑。其它时间不晨跑。已知2022年1月1日是周六,请问小蓝整个2022年晨跑多少天?#样例代码1ls=[0,31,28,31,30,31,30,31,31,30,31,30,31]ans=0k=6foriinrange(1,13)