
1.Hadoop分布式文件系统(Hadoop Distributed File System,HDFS)是Hadoop核心组件之一,我们已经安装好了Hadoop 2.7.1,其中已经包含了HDFS组件,不需要另外安装
最基本的shell命令: HDFS既然是Hadoop的组件,那么首先需要启动Hadoop:启动虚拟机,打开终端,输入以下命令:
cd /usr/local/hadoop #进入 hadoop安装目录
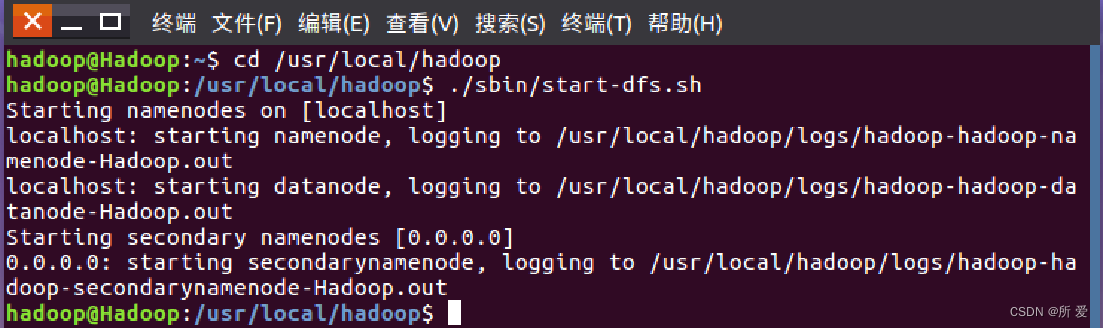
./sbin/start-dfs.sh #启动 hadoop可以看到,输入启动Hadoop的命令之后,在本地主机 localhost上面开始启动名称节点,然后启动数据节点,第二名称节点
2.Hadoop启动成功之后,可以开始在终端使用常用的shell命令与HDFS进行交互了: Hadoop支持很多Shell命令,其中 fs 是HDFS最常用的命令,利用 fs 可以查看HDFS文件系统的目录结构、上传和下载数据、创建文件等。
在终端输入如下命令,查看fs总共支持了哪些命令:
./bin/hadoop fs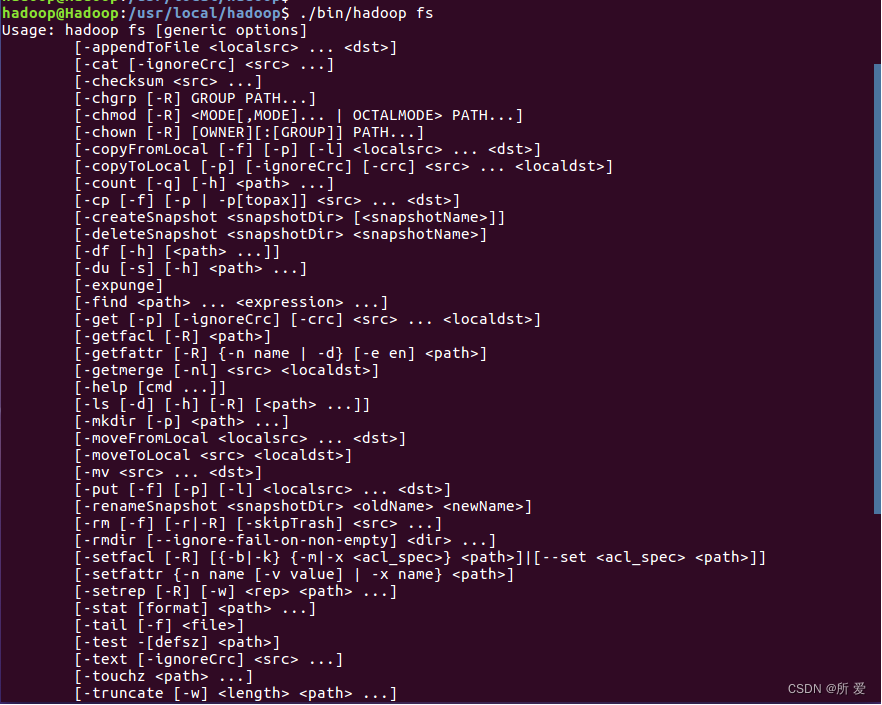
在终端输入如下命令,可以查看具体某个命令的作用:
./bin/hadoop fs -help 某个命令的名称
比如大家喜欢的 cp:
./bin/hadoop fs -help cp
而实际上,HDFS有三种shell命令方式:
hadoop fs:适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs:只能适用于HDFS文件系统
hdfs dfs:跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
尝试以”./bin/hadoop dfs”开头的Shell命令方式
输入了”./bin/hadoop dfs”命令之后,同样,给出了fs 总共支持了哪些命令,但是这里红框里多出了一行提示:

根据提示,尝试以”./bin/hdfs dfs”开头的Shell命令方式:
没有再出现提示:

在HDFS中,shell命令的统一格式是类似“hdfs dfs -ls”这种形式,即在“-”后面跟上具体的操作
下面开始常用的Shell操作:
1.目录操作
Hadoop系统安装好以后,第一次使用HDFS时,需要首先在HDFS中创建用户目录,由于我是采用hadoop用户登录Linux系统,因此,需要在HDFS中为hadoop用户创建一个用户目录,即 user/hadoop,命令如下:
./bin/hdfs dfs –mkdir –p /user/hadoop 
此命令表示在HDFS中创建一个“/user/hadoop”目录,“–mkdir”是创建目录的操作,“-p”表示如果是多级目录,则父目录和子目录一起创建,这里“/user/hadoop”就是一个多级目录,因此必须使用参数“-p”,否则会出错。 此时,“/user/hadoop”目录就成为hadoop用户对应的用户目录,可以使用如下命令显示HDFS中与当前用户hadoop对应的用户目录下的内容:
./bin/hdfs dfs –ls .

该命令中,“-ls”表示列出HDFS某个目录下的所有内容,“.”表示HDFS中的当前用户目录,也就是“/user/hadoop”目录,因此,上面的命令和下面的命令是等价的:
./bin/hdfs dfs –ls /user/hadoop
这个带“.”的命令 “./bin/hdfs dfs –ls . ”与下面这个命令等价:
./bin/hdfs dfs –ls
这里我们发现,这几个命令得到的结果都一样,是因为我们的HDFS使用(且只使用)过一次,时间在上面有标注,里面已经有了input和output两个文件夹,这是我们上次装hadoop伪分布式模式的时候,第五步,运行伪分布式实例的操作,我们一起来回顾一下:
运行Hadoop伪分布式实例: 单机模式下,grep 例子读取的是本地数据,伪分布式读取的则是 HDFS 上的数据。要使用 HDFS,首先需要在 HDFS 中创建用户目录
./bin/hdfs dfs -mkdir -p /user/hadoop
然后,在当前目录,即/user/hadoop/下面创建一个文件夹input,用如下命令:
./bin/hdfs dfs -mkdir input 接着用如下命令将 ./etc/hadoop 中的 xml 文件作为输入文件复制到分布式文件系统中: 即将 /usr/local/hadoop/etc/hadoop 复制到分布式文件系统中的 /user/hadoop/input 中:
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
复制完成后,可以通过如下命令查看文件列表:
./bin/hdfs dfs -ls input
可以看到其中有8个xml文件。
刚才是在/user/hadoop/下面创建了一个文件夹input,使用的命令是:
./bin/hdfs dfs –mkdir input如果要在HDFS的根目录下创建一个名称为input的目录,则需要使用如下命令:
./bin/hdfs dfs –mkdir /input此时,我们再来对当前HDFS的各级目录里面的内容进行查看,使用如下三个命令:
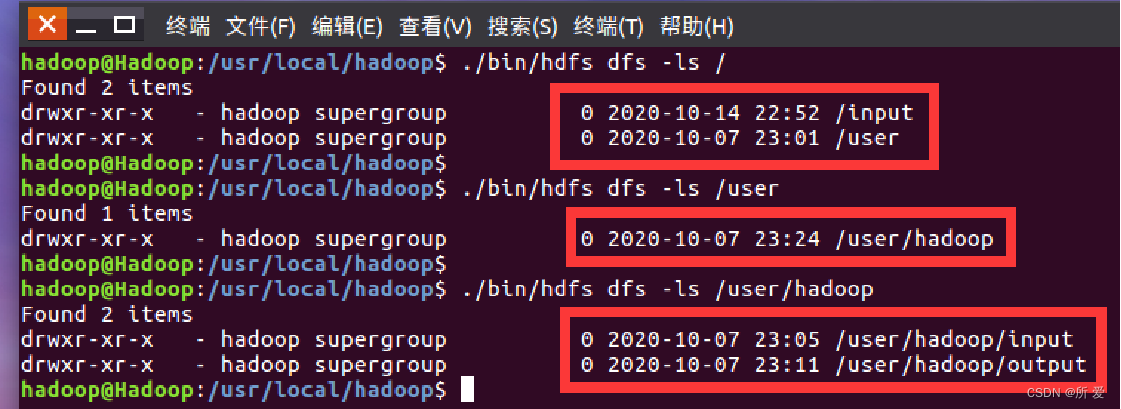
./bin/hdfs dfs -ls / #查看HDFS的根目录
./bin/hdfs dfs -ls /user
./bin/hdfs dfs -ls /user/hadoop查看的结果如下:请注意各级目录里面的内容
可以使用 rm 命令删除一个目录,比如,可以使用如下命令删除刚才在HDFS中创建的“/input”目录(在根目录中创建的,不是“/user/hadoop/input”目录)
./bin/hdfs dfs –rm –r /input
2. 文件操作
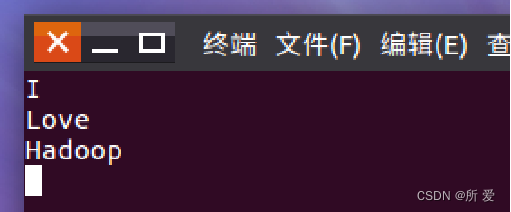
在实际应用中,经常需要从本地文件系统,即Linux的本地文件系统,向HDFS中上传文件,或者把HDFS中的文件下载到本地文件系统中。 首先,使用vim编辑器,在本地Linux文件系统的“/home/hadoop/”目录下创建一个文件myLocalFile.txt,里面可以随意输入一些单词,比如,输入如下三行:
这个 myLocalFile.txt 文件创建完成之后,我们使用 ls 命令可以查看到它,注意,/home/hadoop这个目录就是我们当前登录Linux的账户hadoop的主文件夹:

然后,可以使用如下命令把本地文件系统的“/home/hadoop/myLocalFile.txt”上传到HDFS中的当前用户目录的input目录下,也就是上传到HDFS的“/user/hadoop/input/”目录下:
./bin/hdfs dfs -put /home/hadoop/myLocalFile.txt input
然后,使用 ls 命令查看一下文件是否成功上传到HDFS中,具体如下:
./bin/hdfs dfs –ls input
如上图红框,文件 myLocalFile.txt 已成功上传到HDFS中
下面使用如下命令查看HDFS中的myLocalFile.txt这个文件的内容:
./bin/hdfs dfs –cat input/myLocalFile.txt
下面把HDFS中的 myLocalFile.txt 文件下载到本地文件系统中的“/home/hadoop/下载/”这个目录下,命令如下:
./bin/hdfs dfs -get input/myLocalFile.txt /home/hadoop/下载
这里虽然报了一个警告信息,但是我们去查看一下下载这个目录,发现本次操作是成功完成了的: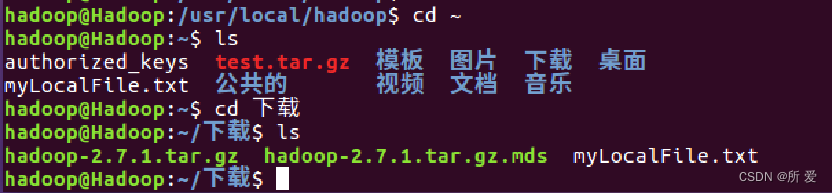
以上为本文全部内容。
由于我是新手小白,如有错误请斧正。

大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
我有一个问题。我想从另一个ruby脚本运行一个ruby脚本并捕获它的输出信息,同时让它也输出到屏幕。亚军#!/usr/bin/envrubyprint"Enteryourpassword:"password=gets.chompputs"Hereisyourpassword:#{password}"我运行的脚本文件:开始.rboutput=`runner`putsoutput.match(/Hereisyour(password:.*)/).captures[0].to_s正如您在此处看到的那样,存在问题。在start.rb的第一行,屏幕是空的。我在运行程序中看不到“输入您的密
有这样的事吗?我想在Ruby程序中使用它。 最佳答案 试试这个http://csl.sublevel3.org/jp2a/此外,Imagemagick可能还有一些东西 关于ruby-是否有将图像文件转换为ASCII艺术的命令行程序或库?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/6510445/