借着ACL2022一篇知识增强Tutorial的东风,我们来聊聊如何在预训练模型中融入知识。Tutorial分别针对NLU和NLG方向对一些经典方案进行了分类汇总,感兴趣的可以去细看下。这一章我们只针对NLU领域3个基于实体链接的知识增强方案Baidu-ERNIE,THU-ERNIE和K-Bert来聊下具体实现~
Knowledge is any external information absent from the input but helpful for generating the output
Tutorial里一句话点题,知识就是不直接包含在当前文本表达中的,但是对文本理解起到帮助作用的补充信息,大体可以分成
常规预训练预语料也是包含部分知识的,不过受限于知识出现的频率,以及非结构化的知识表征,预训练任务的设计等等因素,知识信息往往等不到充分的训练,因此BERT不可避免会给出一些不符合知识但是符合语言表达的预测结果,于是有了尝试在预训练阶段融入结构化知识信息的各种尝试
LM中融入知识的一般分成3个步骤:定位知识(knowledge grounding),知识表征(knowledge representation),融入知识(knowledge fusion),这么说就像把大象放进冰箱一样easy,不过实现起来细节问题颇多,例如定位知识时的消歧问题,知识表征和文本表征的不一致问题,知识融入时如何不干扰原始的上下文语义等等,下面我们来看下3种不同的增强方案
- paper: ERNIE: Enhanced Representation through Knowledge Integratiion
- Github: https://github.com/PaddlePaddle/ERNIE
- Take Away: 通过knowledge masking学到隐含的实体以及短语内部一致信息

ERNIE的主要创新是在预训练阶段引入了knowledge masking,这里的knowledge包括短语和实体两种。所以ERINE定位知识的方式是通过分词定位短语,以及通过实体匹配定位到实体。对比BERT对独立token进行掩码,ERNIE分阶段采用token,phrase和entity这三种不同粒度的span进行掩码。实体和短语内部的字符,因为被同时掩码,所以会被相同的上下文信息进行梯度更新,使得token之间学到内部关联信息,以及更清晰的实体边界信息,在NER等局部信息抽取任务上更有优势。不过模型本身并没有引入更丰富的实体关联等知识信息~
- paper:ERNIE: Enhanced Language Representation with Informative Entities
- github: https://github.com/thunlp/ERNIE
- Take Away: 引入KG预训练Embedding,通过FusionLayer进行知识融入
论起名的重要性,这两篇ERNIE其实是完全不同的方向。THU-ERNIE更完整的给出了在预训练中融入知识的方案。THU-ERNIE由T-Encoder和K-Encoder构成,其中T-Encoder就是常规的Transformer Block用来学习基于上下文的文本表征,而K-Encoder负责知识表征和融入,同时ERNIE设计了新的预训练目标dAE来辅助知识信息融入。以’Bob Dylan wrote Blowin in the Wind in 1962‘为例,分别看下THU-ERNIE如何定位,表征和融入知识
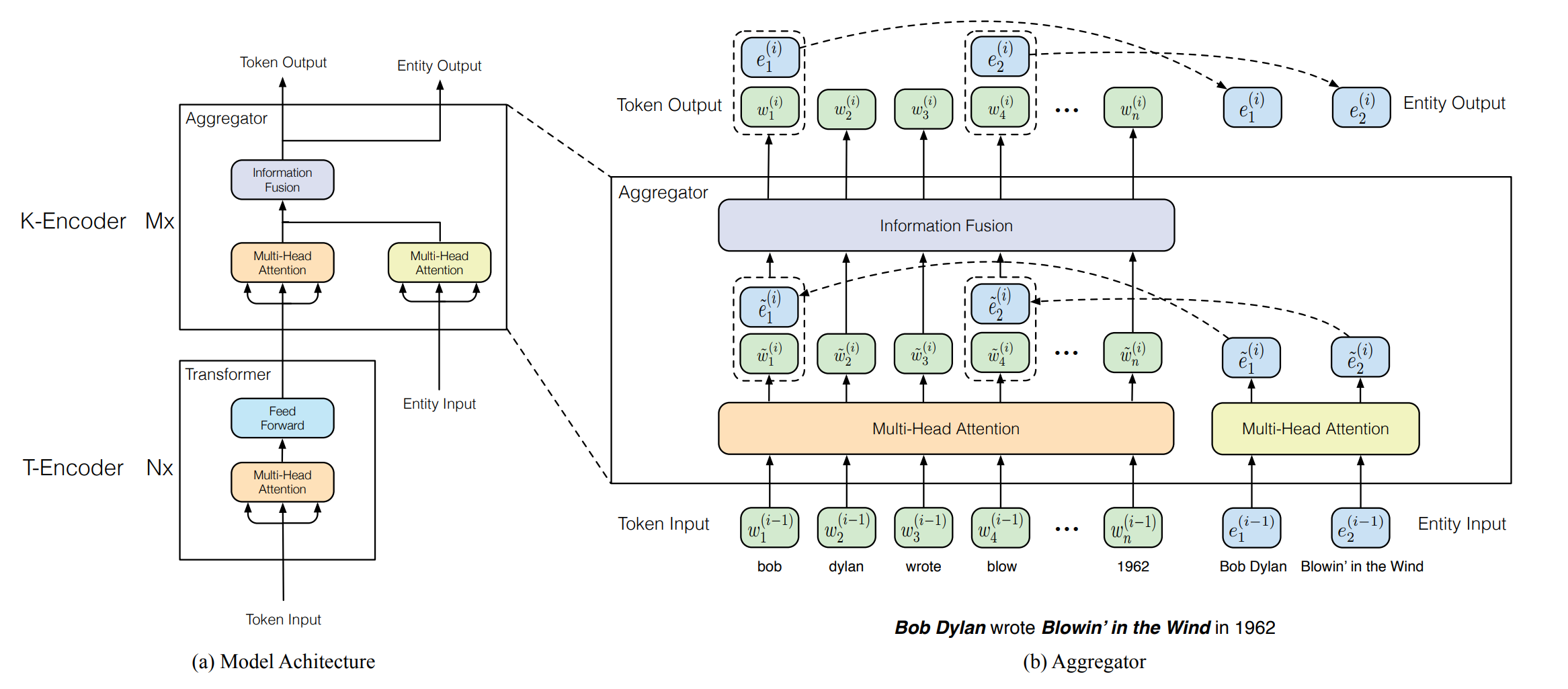
ERNIE通过TAGME从句子中定位到实体知{e1, ...en},并使用TransE预训练的实体embedding作为知识表征。在知识融入上,首先原始文本输入会过T-Encoder得到考虑上下文的文本表征,然后会通过K-Encoder中的多个Aggregator层进行知识融合,这里的知识融合包括知识表征和文本表征的对齐以及双方的信息交互。每个Aggregator层由两部分构成
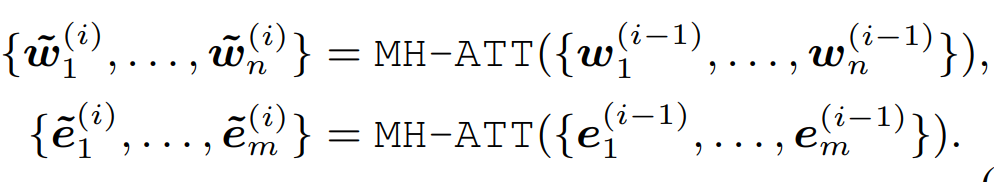
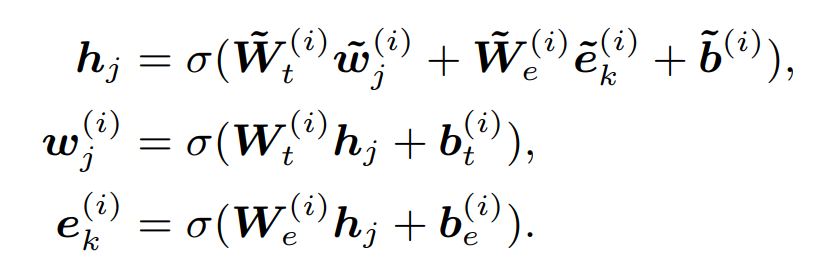

作者在MLM和NSP的预训练任务的基础上,加入了实体还原dAE任务,来帮助模型融合知识相关信息。同样是AutoEncoder任务,实体还原和MLM任务主要有两个差异
整体上dAE的任务设计偏简单,首先是掩码部分和BERT只保留10%的原始token相比,dAE85%的概率都保留原始token;同时还原任务只使用当前句子的实体作为候选,候选集较小。至于为什么把任务调整的更加简单,作者只简单说是因为token-entity对齐会存在一定error,不过我对这部分的任务设计还是有些疑惑~有了解的同学求解答
ERNIE的预训练过程使用了google BERT的参数来初始化T-Encoder,TransE的实体Embedding在训练过程中是Freeze的,K-Encoder的参数会随机初始化。效果上在Entity Typing和Relation Classification上都有较明显的效果提升
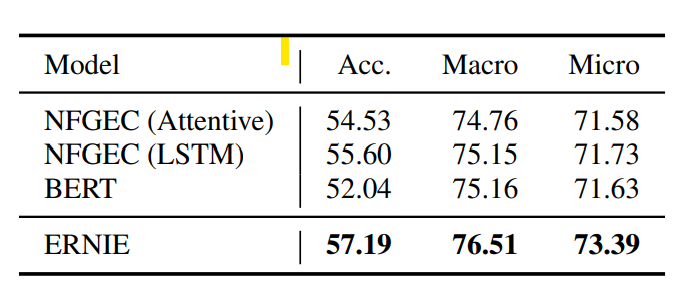
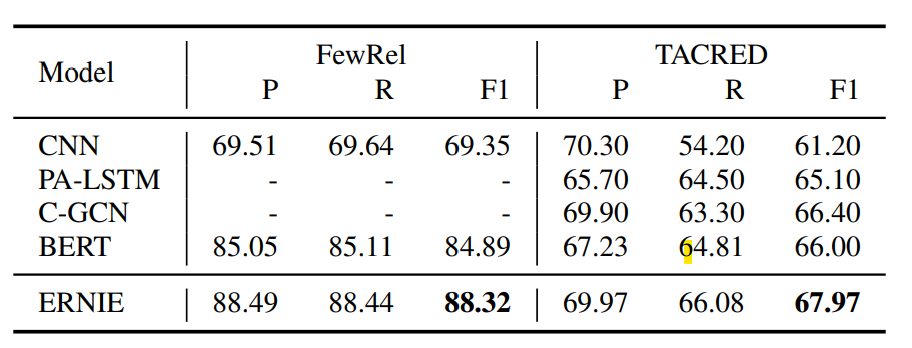
在常规的GLUE Benchmark上,针对样本量较大的任务ERNIE和BERT持平,但是对样本较小的任务上存在波动有好有坏,不过波动本身并不小。。。所以感觉不太能说明实体信息引入完全没有影响到原始上下文信息
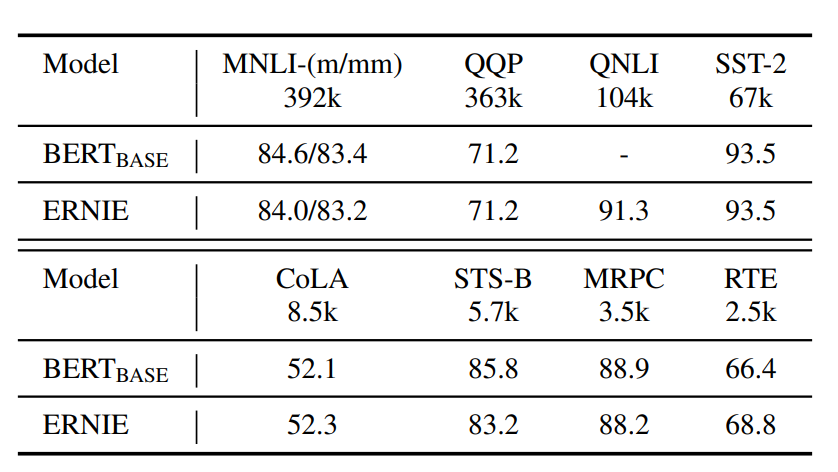
整体上ERNIE的效果提升还是显著的,几个能想到的讨论方向有
- paper: ERNIE: Enhanced Language Representation with Informative Entities
- gitub: https://github.com/autoliuweijie/K-BERT
- Take Away: 通过soft MASK和soft PE在引入知识表征的同时不影响原有文本语义
K_BERT通过soft-Mask和soft-position,在不影响原始语义的情况下,把知识图谱的3元组信息直接融入文本表征。以’CLS Tim Cook is visiting Beijing Now‘ 为例,分别看下K-bert如何定位,表征和融入知识
K-bert在输入层之前加入知识层,负责知识的定位和表征。K-Bert通过字符匹配的方式先定位到句子中的实体,然后去图谱中请求实体相关的全部3元组。句子中的Tim Cook和Beijing实体,分别能请求到如下三元组:[Tim Cook, CEO, Apple], [Beijing, capital, China],[Beijing, is_a , City]。这里请求深度为1,也就是Beijing请求得到的China后,不会用China去进一步检索。所有请求到的三元组会构建如下的句子树
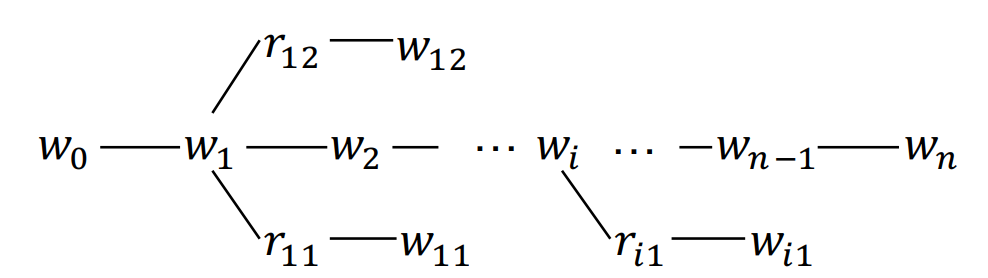
定位到知识后,在知识表征上K-Bert没有引入图谱相关的预训练知识表征,而是选择把三元组信息和原始token一同输入模型,使用相同的token embedding来进行语义表征。所以需要对以上的句子树进行展开,展开的顺序是按照原始句子遍历,如果碰到分支就把分支的token加入,然后继续遍历原始句子,展开后的句子如下。输入和BERT相同是token+position+segment embedding

不过以上的知识表征方式存在一个问题,就是对句子树进行展开时,人为引入了噪音,主要包括3个方面
针对这些问题,作者提出了Soft—PE和Soft-MASK的实现。核心就是让原始token的PE保持不变,原始token之间的交互不变,每个token只和自己的知识进行交互。
Soft-PE就是保持原始句子的位置编码不变,对于插入的知识会从实体的位置开始向后顺延,于是会存在重复的PE,例如is在原始句子中的位置id是3,CEO对应的实体是TimCook位置是2,顺延后位置id也是3,他们的位置编码就是相同的,这样就解决了以上的问题1
Soft-Mask就是通过掩码对知识部分进行隔离,CEO Apple只和Tim Cook进行交互,不和其他token进行交互,保证知识的引入只是为当前实体提供补充信息,不会干扰整体上下文语义,也不会和其他token交互引入噪音,这样就解决了以上的问题2和3
作者也通过消融实验证明了,如果不使用Soft-MASK和Soft-PE, k-bert的效果会显著低于原始BERT。

K-Bert只在下游任务微调中使用了KG,核心问题在于如果在预训练中加入KG,因为知识表征中使用了和原始文本相同的词向量,所以会导致实体三元组中两个实体的文本表征变得变得高度相似,导致语义信息损失。所以K-Bert只在微调中引入了实体三元组信息。
效果上,医疗领域KG对医疗NER的效果提升最明显,通用知识KG对与金融和法律的NER有部分提升,对推理类任务有微小提升,情感分类任务因为和知识关系不大所以效果有限~
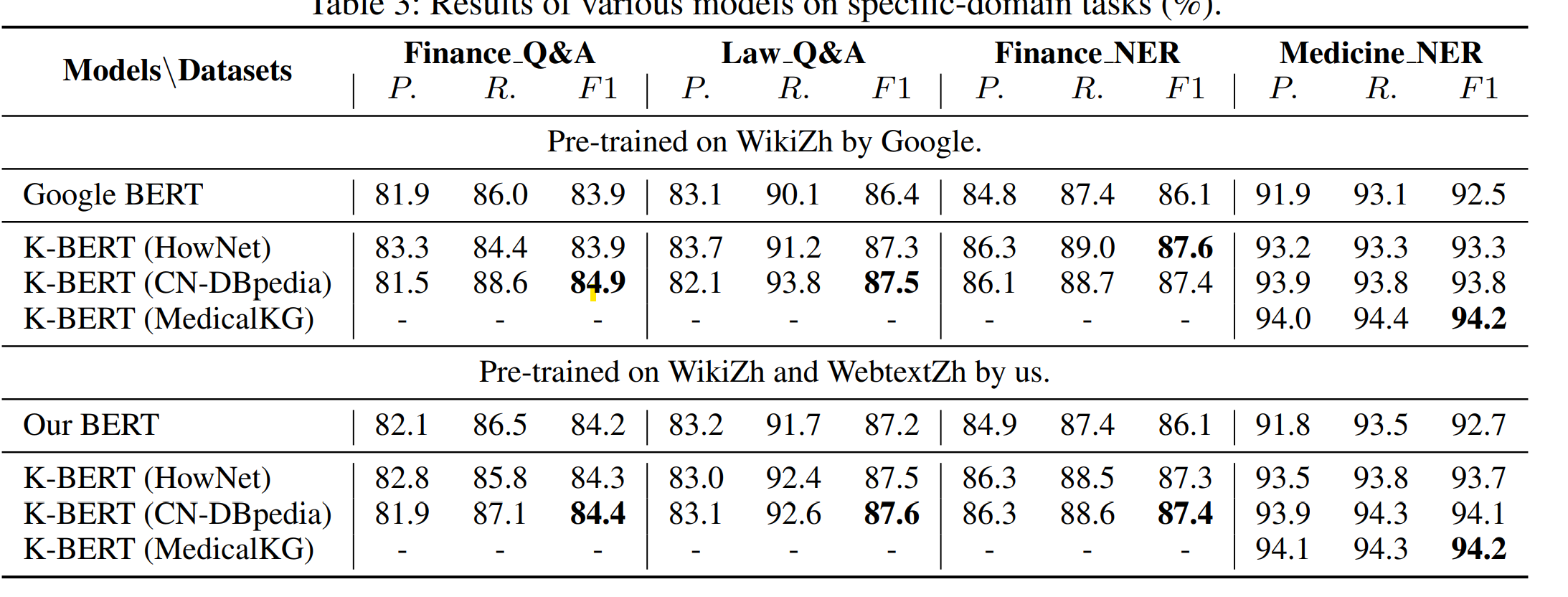
K-BERT只在微调中引入KG的好处是迁移到不同领域的成本较低,几个能想到的讨论点有
BERT手册相关论文和博客详见BertManual
Reference
我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我的瘦服务器配置了nginx,我的ROR应用程序正在它们上运行。在我发布代码更新时运行thinrestart会给我的应用程序带来一些停机时间。我试图弄清楚如何优雅地重启正在运行的Thin实例,但找不到好的解决方案。有没有人能做到这一点? 最佳答案 #Restartjustthethinserverdescribedbythatconfigsudothin-C/etc/thin/mysite.ymlrestartNginx将继续运行并代理请求。如果您将Nginx设置为使用多个上游服务器,例如server{listen80;server
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳