ps: 网上看了一大堆文章, 介绍的东西真的是很够呛, 就没一个能真正用起来的, 各个都是自动补,然后很多都是不好用的。
我自己整理一篇,这是真能用。
本篇内容 :
① 按照 日 、周、月 、年 的维度 去对数据 做分组统计
② 不存在的数据自动补充 0 (实用)
不多说,开搞。
结合实例 :
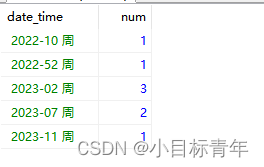
先看我们的表 student

建表sql:
CREATE TABLE `student` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT 'id',
`name` VARCHAR(50) NULL DEFAULT NULL COMMENT '名字' COLLATE 'utf8_general_ci',
`admission_time` DATETIME NULL DEFAULT NULL COMMENT '入学时间',
PRIMARY KEY (`id`) USING BTREE
)
现在我们就举个简单的业务场景:
根据admission_time 入学时间,按照年月日周这些维度 去统计 学生数量。
我们来做一些模拟数据,8条数据:

我们先简单看看 按照 日 、周 、月 、年 的统计 sql怎么写 :
sql:
SELECT date_format(admission_time, '%Y-%m-%d') date_time, COUNT(*) num
FROM student
GROUP BY date_time ;
看看效果:
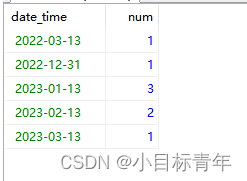
ps : 注意了 这些 ‘-’ 是我们定义的格式, 我们不要 ‘-’ 换成其他的也是可以的,但是 不能不要 ymd 这些关键字。
举个小栗子:
比如 ,date_format(admission_time, '收藏%Y点%m赞%d')
SELECT date_format(admission_time, '收藏%Y点%m赞%d') date_time, COUNT(*) num
FROM student
GROUP BY date_time ;
看看效果 :

sql:
SELECT DATE_FORMAT(admission_time,'%Y-%u 周') AS date_time, COUNT(*) num FROM student GROUP BY date_time;
ps : 为了让你们知道 这个周的概念, 我故意加了个中文。 而且特意把一条数据 时间改成 22年的最后一周的一天。
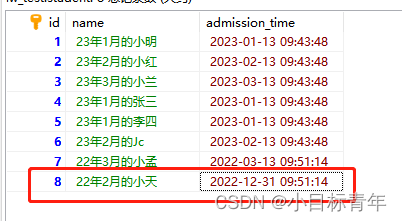
看看效果 :
sql:
SELECT DATE_FORMAT(admission_time, '%Y-%m') date_time, COUNT(*) num
FROM student
GROUP BY date_time ;
看看效果 :

sql:
SELECT DATE_FORMAT(admission_time, '%Y') date_time, COUNT(*) num
FROM student
GROUP BY date_time ;
看看效果: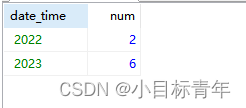
好了 知道这些基础的 时间分组sql 用法之后, 那么我们接下来就 来 玩下怎么 解决自动补 0 的这个问题。
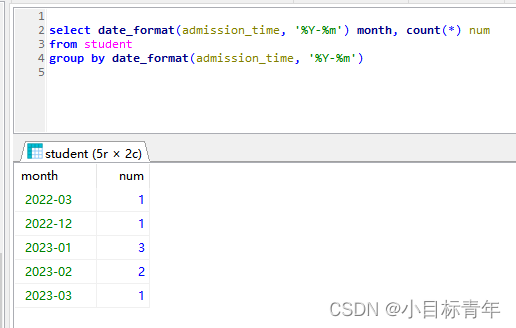
首先,如果说 sql查出来的数据没有, 我们拿月维度的来 做个示例 ,就像这样 :

这里突然想到个点,很多人说那这里面混了 2022年, 2023年的数据, 我想要指定查询某段时间的怎么搞?
其实一样的,就根据时间查询就行:
比如像这样传入我们的筛选时间范围,按照月就这样 :
sql:
SELECT * FROM (select date_format(admission_time, '%Y-%m') date_time, count(*) num
from student
group by date_format(admission_time, '%Y-%m'))t WHERE t.date_time BETWEEN '2023-01' AND '2023-03'
效果:

回到刚才,可以看到统计出来的数据, 比如说23年的,有1月的,2月的, 3月的, 那么 4,5,6,7后面这些月份,没数据,那怎么办?
写代码填充,后端拿到查数据库返回的数据,for循环遍历,检测时间段内的日期, 比如说 12个月,看看哪个月没有,就填充。
确实 这是可以的, 但是今天这一篇介绍的是通过sql返回 , 不考虑代码上面的填补。
接下来看看SQL怎么玩 。
思路&想法 :
我们能查出来 student 现有的日期数据, 那么缺少的数据 我也得给整出来 。
那我们肯定不能去改 student表的数据呀, 现在就是单纯少了一些 空白月份的数据 。
所以我们选择 临时数据表的思维。
ps : 网上一大堆文章,都让咱们去跑个存储过程 强行生成一个表..
你看看(一万个拒绝)
还有这种,按照目前时间拼接出来的:
(5000个拒绝,这种now 直接切割到现在,还得写一大堆这种01,02,03,04;
如果我是要填充 日维度的数据,那我这sql代码量不就爆炸了?
) 
这种也是:
OK, 我们来看看我们的SQL :
select DATE_FORMAT(date_add('2023-01-01', interval row MONTH),'%Y-%m') date_time from
(
SELECT @row := @row + 1 as row FROM
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t2,
(SELECT @row:=-1) r
) se
where DATE_FORMAT(date_add('2023-01-01', interval row MONTH),'%Y-%m') <= DATE_FORMAT('2023-12-01','%Y-%m')效果 :
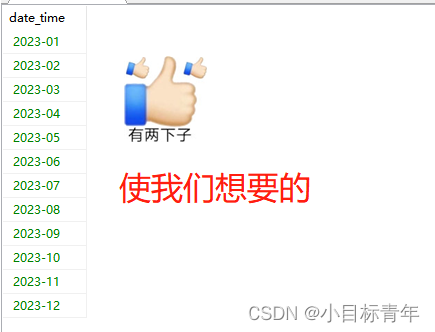
ps: 这里用了月举例, 要弄年或周或者日的 在文末有补充。
sql 作用简析 :
简析点一

简析点二

可以看到 ,这里面 我写了2行这个玩意 。
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t
简单说下:
写一行这个玩意, 代表能搞出 10 条 符合 范围时间内日期格式时间数据 ;
当写多一行呢(2行的时候),代表 10 * 10 =100 条
当再写多一行呢(3行的时候)? 10*10*10 =1000条
所以我们上面的sql,我写了2行,
代表 在我传入的时间范围 2023-01-01 到 2323-12-01 内
我写的时间格式是取月, 一共其实就12 个月数据,也就是12条, 但是只写一次10条不够用,我也就用了2次(100条)。言下之意, 其实你跟我这样写2次,100条, 什么概念, 1年12个月 相当于12条,这样 100条相当于可以查跨度 8年的时间了 (8*12-96)
如果你不是要查日, 业务需求一般不会让咱们写跨度这么大的。
当然了,如果就是有, 那么我们大不了直接写 4条, 相当于 10*10*10*10 =1 万 条。
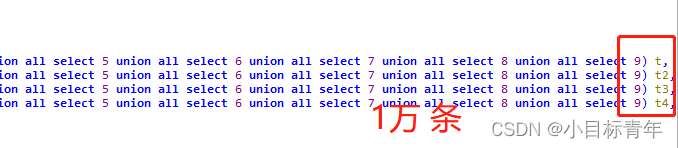
OK,不啰嗦,回到我们的示例 :
我们现在 如果说是查跨度 2年的数据, 比如现在按照我们part的sql 查出来是这样子的 。
可以看到结果集, 22年数据 缺了很多 需要补0的, 23年也缺了很多。
所以我们这时候需要做一个 left join 即可解决自动补 0 的事情。

sql操作图析:

sql:
SELECT A.date_time, COALESCE(B.num, 0) as num FROM
(
SELECT DATE_FORMAT(date_add('2023-01-01', interval row MONTH),'%Y-%m') date_time FROM
(
SELECT @row := @row + 1 as row FROM
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t2,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t3,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t4,
(SELECT @row:=-1) r
) se
WHERE DATE_FORMAT(date_add('2023-01-01', interval row MONTH),'%Y-%m') <= DATE_FORMAT('2023-12-01','%Y-%m')
) A
LEFT JOIN
(
SELECT DATE_FORMAT(admission_time, '%Y-%m') date_time, COUNT(*) num
FROM student
GROUP BY DATE_FORMAT(admission_time, '%Y-%m')
) B
ON A.date_time= B.date_time看看效果 :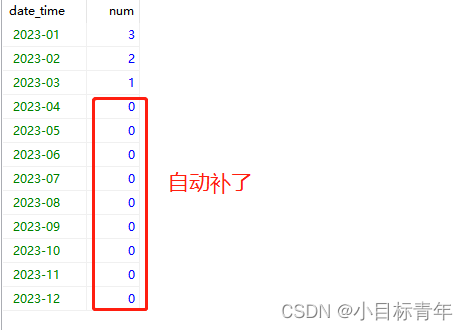

这盛世如我所愿, 好了, 该篇就到这。
文末补充 日、年、周 维度的 列出完整数据条sql :
按日 列出范围内日期的sql :
select date_add('2023-01-01', interval row DAY) date from
(
SELECT @row := @row + 1 as row FROM
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t2,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t3,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t4,
(SELECT @row:=-1) r
) se
where date_add('2023-01-01', interval row DAY) <= '2023-01-20'
效果:
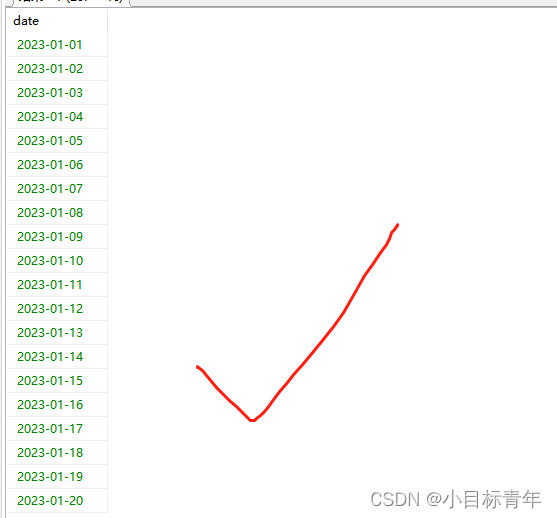
按周 列出范围内日期的sql :
按照周要注意一点,当传入每年的01-01这一天的时候 会出现0周 ,可以做一下处理。
select DATE_FORMAT(date_add('2023-01-01', interval row WEEK),'%Y-%u') date_time from
(
SELECT @row := @row + 1 as row FROM
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t2,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t3,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t4,
(SELECT @row:=-1) r
) se
where DATE_FORMAT(date_add('2023-01-01', interval row WEEK),'%Y-%u') <= DATE_FORMAT('2023-01-06','%Y-%u')按年 列出范围内日期的sql :
select DATE_FORMAT(date_add('2020-01-01', interval row YEAR),'%Y') date_time from
(
SELECT @row := @row + 1 as row FROM
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t2,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t3,
(select 0 union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9) t4,
(SELECT @row:=-1) r
) se
where DATE_FORMAT(date_add('2020-01-01', interval row YEAR),'%Y') <= DATE_FORMAT('2023-12-01','%Y')
效果: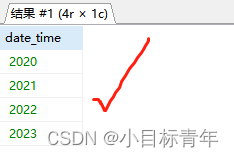
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我想用ruby编写一个小的命令行实用程序并将其作为gem分发。我知道安装后,Guard、Sass和Thor等某些gem可以从命令行自行运行。为了让gem像二进制文件一样可用,我需要在我的gemspec中指定什么。 最佳答案 Gem::Specification.newdo|s|...s.executable='name_of_executable'...endhttp://docs.rubygems.org/read/chapter/20 关于ruby-在Ruby中编写命令行实用程序
我需要检查DateTime是否采用有效的ISO8601格式。喜欢:#iso8601?我检查了ruby是否有特定方法,但没有找到。目前我正在使用date.iso8601==date来检查这个。有什么好的方法吗?编辑解释我的环境,并改变问题的范围。因此,我的项目将使用jsapiFullCalendar,这就是我需要iso8601字符串格式的原因。我想知道更好或正确的方法是什么,以正确的格式将日期保存在数据库中,或者让ActiveRecord完成它们的工作并在我需要时间信息时对其进行操作。 最佳答案 我不太明白你的问题。我假设您想检查
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s
我的模型有defself.empty_building//stuffend我怎样才能对这个现有的进行rspec?,已经尝试过:describe"empty_building"dosubject{Building.new}it{shouldrespond_to:empty_building}endbutgetting:Failure/Error:it{shouldrespond_to:empty_building}expected#torespondto:empty_building 最佳答案 你有一个类方法self.empty_bu
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit