自从yolov5-5.0加入se、cbam、eca、ca发布后,反响不错,也经常会有同学跑过来私信我能不能出一期6.0版本加入注意力的博客。个人认为是没有必要专门写一篇来讲,因为步骤几乎一样,但是问的人也慢慢多了,正好上一篇加入注意力的文章写的略有瑕疵,那就再重新写一篇。
1.common.py中加入注意力模块
2.yolo.py中增加判断条件
3.yaml文件中添加相应模块
所有版本都是一致的,加入注意力机制能否使模型有效的关键在于添加的位置,这一步需要视数据集中目标大小的数量决定。
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, h, w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.f1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu = nn.ReLU()
self.f2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.f2(self.relu(self.f1(self.avg_pool(x))))
max_out = self.f2(self.relu(self.f1(self.max_pool(x))))
out = self.sigmoid(avg_out + max_out)
return out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class CBAM(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, ratio=16, kernel_size=7): # ch_in, ch_out, number, shortcut, groups, expansion
super(CBAM, self).__init__()
self.channel_attention = ChannelAttention(c1, ratio)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
out = self.channel_attention(x) * x
out = self.spatial_attention(out) * out
return out
class SE(nn.Module):
def __init__(self, c1, c2, r=16):
super(SE, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.l1 = nn.Linear(c1, c1 // r, bias=False)
self.relu = nn.ReLU(inplace=True)
self.l2 = nn.Linear(c1 // r, c1, bias=False)
self.sig = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.size()
y = self.avgpool(x).view(b, c)
y = self.l1(y)
y = self.relu(y)
y = self.l2(y)
y = self.sig(y)
y = y.view(b, c, 1, 1)
return x * y.expand_as(x) if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost,CBAM,CoordAtt,SE]:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8) [[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, CoordAtt,[1024]],
[-1, 1, SPPF, [1024, 5]], # 9这是6.0版本的yolov5的骨干层,CoordAtt的位置可以换成以上任意一个注意力,其他参数不需要调整,傻瓜式复制粘贴,即可跑通。
以上就是具体将注意力添加至yolov5-6.0版本中的步骤。注意力模块并没有刻板规定一定要加在什么地方,使用者可随意调整。
接下来是理论部分。关于注意力的理论部分,各位博主大佬已经讲的非常细致了(这个地方想了半天成语想不出来),但是为了证明本人出色的复制粘贴能力,决定再写一下。
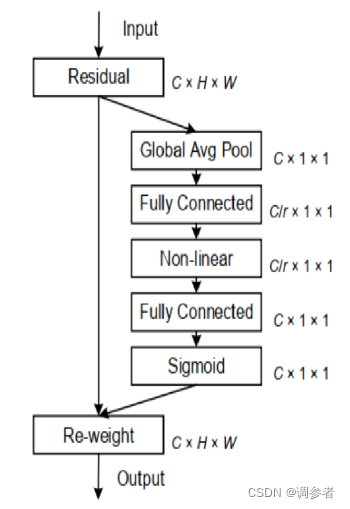
se注意力增强模型关注对象的方法分为两步:
对输入的特征图进行通道信息的全局平均池化,即挤压

将挤压之后的信息通过两个全连接层、激活函数再归一化后乘到输入特征图上

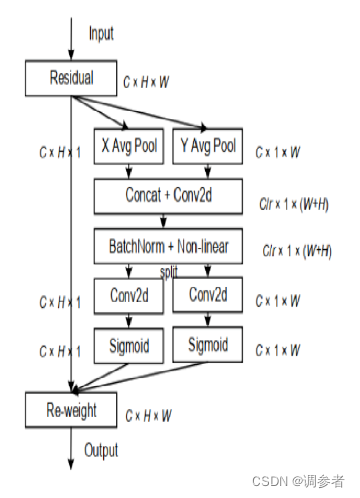
位置注意力将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。


(注:理论部分非本人原创,如有侵权,请联系我删除。)
各个注意力机制使用后的感受,yolov5中个人感觉CA效果最好。
我有一个.pfx格式的证书,我需要使用ruby提取公共(public)、私有(private)和CA证书。使用shell我可以这样做:#ExtractPublicKey(askforpassword)opensslpkcs12-infile.pfx-outfile_public.pem-clcerts-nokeys#ExtractCertificateAuthorityKey(askforpassword)opensslpkcs12-infile.pfx-outfile_ca.pem-cacerts-nokeys#ExtractPrivateKey(askforpassword)o
有道无术,术尚可求,有术无道,止于术。本系列SpringBoot版本3.0.4本系列SpringSecurity版本6.0.2本系列SpringAuthorizationServer版本1.0.2源码地址:https://gitee.com/pearl-organization/study-spring-security-demo文章目录前言1.OAuth2AuthorizationServerMetadataEndpointFilter2.OAuth2AuthorizationEndpointFilter3.OidcProviderConfigurationEndpointFilter4.N
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
大家好,感谢您花时间阅读本文。我需要验证由我自己的CA颁发的证书,我有一个证书。我怎样才能做相当于openssl的openssl验证-CAfile在Ruby代码中?OpenSSL的RDoc在这方面不是很有帮助。我试过:require'openssl'ca=OpenSSL::X509::Certificate.new(File.read('ca-cert.pem'))lic=OpenSSL::X509::Certificate.new(File.read('cert.pem'))putslic.verify(ca)但我得到:test.rb:7:in`verify':wrongargume
当引用此block时,此弃用消息对我来说意味着什么?defjson_response(object,status=:ok)renderjson:object,status:statusend编辑讯息:Rails6.1willreturnContent-Typeheaderwithoutmodification…use#media_typeinstead 最佳答案 当我将我的应用程序从Rails5.2.3升级到Rails6.0.0-rc1时,我收到了同样的错误消息config/application.rb#thiswastheline
我有一个测试环境,它使用Ruby通过https连接驱动服务器。由于最新版本的Ruby拒绝连接到具有无效证书的https服务器(请参阅thisearlierquestionofmine)并且我想开始使用更新版本的Ruby,因此我正在尝试设置有效证书。我已经创建了一个CA证书来使用(有多个服务器正在测试,所以这似乎是更简单的方法),并且已经成功地使用它来签署一个已安装在服务器上并正在使用的新证书。我已将CA证书添加到浏览器商店,它(浏览器)现在将毫无怨言地连接到服务器。因此,我确信我的证书有效且设置正确。我知道Ruby不使用与浏览器相同的商店。我使用了可用的CA文件here测试连接到其他(
我在ruby中遇到问题,OpenSSL无法验证SSL证书。我认为这是由于脚本不知道ca-bundle.pem造成的。是否可以手动配置ca-bundle.pem的路径? 最佳答案 OpenSSL使用SSL_CERT_FILE环境变量。您可以使用类似于第一个引入OpenSSL的require之前的东西在您的ruby脚本中设置它:ENV['SSL_CERT_FILE']='/path/to/ca-bundle.pem'或者,如果您愿意,可以根据您的情况在操作系统环境、网络服务器配置等中设置SSL_CERT_FILE环境变量。
本文档适用于SOPHGO(算能)BM1684-SE5及对应通用云开发空间,主要内容:注意:由于SOPHGOSE5微服务器的CPU是基于ARM架构,部分步骤将在基于x86架构CPU的开发环境中完成初始化开发环境(基于x86架构CPU的开发环境中完成)YOLO3D目标检测算法模型转换(基于x86架构CPU的开发环境中完成)YOLO3D模型推理测试(处理后的YOLO3D项目文件将被拷贝至SOPHGOSE5微服务器上推理测试)1.初始化开发环境(基于x86架构CPU的开发环境中完成)1.1初始化开发环境(若wget后的地址不可用,请前往算能官网下载Docker镜像及SDK)#切换成root权限sudo
趁着寒假期间稍微尝试跑了一下yolov5和yolov7的代码,由于自己用的笔记本没有独显,台式机虽有独显但用起来并不顺利,所以选择了租云服务器的方式,选择的平台是矩池云(价格合理,操作便捷)需要特别指出的是,如果需要用pycharm链接云服务器训练,必须要使用pycharm的专业版而不是社区版,专业版可以使用SSH服务连接云服务器。关于专业版的获取,据我所知一是可以买,二是如果你是在校大学生,可以用学生证向JetBrain申请专业版使用权,我就是通过这种方式激活专业版账户的,我记得当时两三天官方就发激活邮件了,还是很人性化的,使用期一年。下面开始正题本教程只涉及将yolov5及yolov7跑通
【摘 要】近年来,基于自注意力机制的神经网络在计算机视觉任务中得到广泛的应用。随着智能交通系统的广泛应用,面对复杂多变的交通场景,车牌识别任务的难度不断提高,准确识别的需求更加迫切。因此提出一个基于自注意力的免矫正的车牌识别方法T-LPR。首先对图像进行切片和序列化,并使用3D卷积对切片序列进行特征提取,从而得到图像的嵌入向量序列。然后将嵌入向量序列输入基于TransformerEncoder的编码器中,学习各个嵌入向量之间的关系并输出最终的编码结果。最后使用分类器进行分类。在多个公共数据集上的实验结果表明,所提方法对各类困难场景下的车牌识别都非常有效。【关键词】车牌识别 ; 图像嵌入向量 ;