
完成以下迷宫
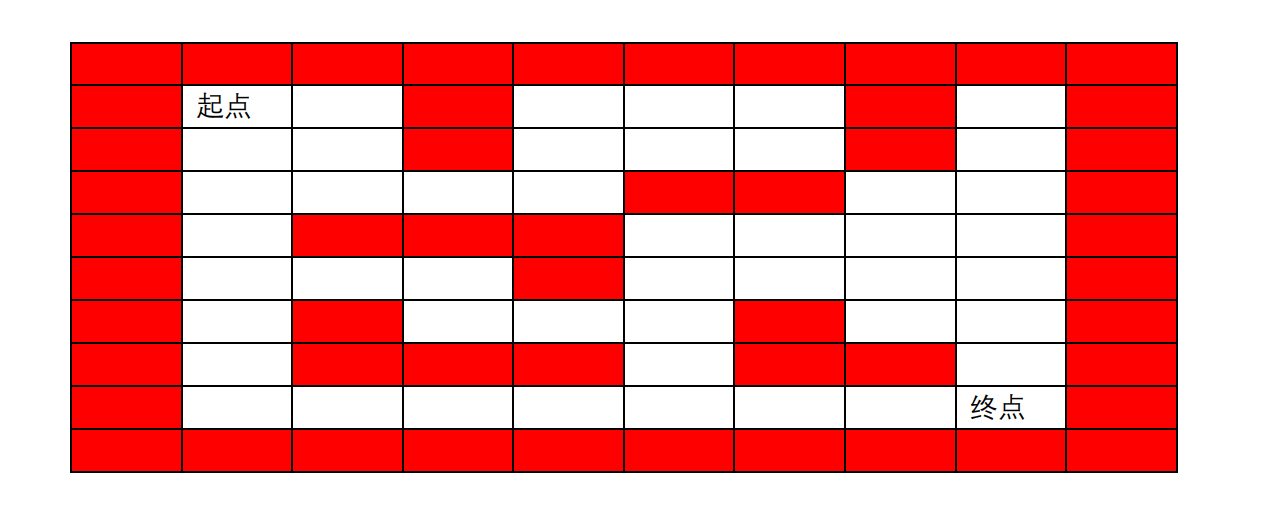
利用二维数组储存每一个数组里的值,若是不能走则为1,若是可行就是0,走过了就设为2。
一般是再复制一个数组,用来记录。
堆栈的思想就是将一个点的上下左右都遍历一遍,若可行进栈,跳出遍历,再寻找下一个可走的。若遇到无路可走的就退回上一步,就是出栈。所以就是说堆栈里记录的是可以走到终点的路。
队列的思想就是一直找,把所有可以走的路都走一遍,直到遇到终点。
这里的每一个可以走的点都为链表中的一个节点,在队列中要记录这个点的上一点是什么,就是哪一个点衍生出的这个点。
若是堆栈,最后在出栈便是所走的路径,但是堆栈是后进先出的原理,可能为了好看最后要做些处理。
若是队列,最后是利用找到的终点的那个节点,一直找这个节点的上一个节点,上个节点的上个节点,一直找到起点,可能为了好看最后还是要做些处理。
这里就是按照上述方法做的,但是太懒了,做出来就没有处理了。
堆栈是比较简单的,主要是队列中的头部和尾部的节点设置,和进队列的时候是怎么循环,这个循环是怎么在遍历之前的节点的也同时在加入新的节点进队。后来我是没有用出队这个原理去做。
以下是用堆栈实现的
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<time.h>
typedef struct stack{
int x;//记录下标
int y;
int direction;//记录方向
struct stack *next;
}stack;
int main(){
int maze[10][10];
int i,j;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
if(i==0 || j==0 || i==9|| j==9){
maze[i][j]=1;
} else{
maze[i][j]=0;
}
}
}
maze[1][3]=1;
maze[1][7]=1;
maze[2][3]=1;
maze[2][7]=1;
maze[3][5]=1;
maze[3][6]=1;
maze[4][2]=1;
maze[4][3]=1;
maze[4][4]=1;
maze[5][4]=1;
maze[6][2]=1;
maze[6][6]=1;
maze[7][2]=1;
maze[7][3]=1;
maze[7][4]=1;
maze[7][6]=1;
maze[7][7]=1;
maze[8][1]=1;
//这里是输进去的迷宫,也可以随机实现,但是这里偷下懒
int cmaze[10][10];
for(i=0;i<10;i++){
for(j=0;j<10;j++){
cmaze[i][j]=maze[i][j];
}
}
//用一个新的二维数组记录走过的点
printf("\n\n");
stack *top,*p,*q,*t,*s;
top=(stack *)malloc(sizeof(stack));
top->next=NULL;
//人为设置的,(1,1)是起点,(8,8)是终点
int flag=0,x=0,y=0;
if(flag==0){
p=(stack *)malloc(sizeof(stack));
p->x=1;
p->y=1;
p->direction=-1;
q=top->next;
top->next=p;
p->next=q;
flag=1;
}
q=top->next;
x=q->x;
y=q->y;
while(q->x!=8 || q->y!=8){
//0:向左 y+1 1:向下 x+1 2:向右 y-1 3:向上 x+1
if(cmaze[x][y+1]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y+1;
p->direction=0;
q=top->next;
top->next=p;
p->next=q;
cmaze[x][y+1]=2;
}else if(cmaze[x+1][y]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x+1;
p->y=y;
p->direction=1;
q=top->next;
top->next=p;
p->next=q;
cmaze[x+1][y]=2;
}else if(cmaze[x][y-1]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y-1;
p->direction=2;
q=top->next;
top->next=p;
p->next=q;
cmaze[x][y-1]=2;
}else if(cmaze[x+1][y]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y-1;
p->direction=3;
q=top->next;
top->next=p;
p->next=q;
cmaze[x+1][y]=2;
}else{
t=top->next;
s=t->next;
top->next=s;
free(t);
}
q=top->next;
x=q->x;
y=q->y;
//每次都是栈顶的元素找方向,找不到就是free掉,出栈,就是后退一步
}
for(i=0;i<10;i++){
for(j=0;j<10;j++){
printf(" %d",cmaze[i][j]);
}
printf("\n");
}
printf("溯源:\n");
while(top->next!=NULL){
p=top->next;
x=p->x;
y=p->y;
printf("x=%d,y=%d\n",x,y);
top=top->next;
}
return 0;
}

//队列
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define maxsize 10
#define null 0
typedef struct node{
int x;
int y;
struct node*last;
struct node*next;
} lqnode;
typedef struct{
node *front,*rear;
}Queue;
//定义一个队列的结构体,记录头和尾
int main(){
int maze[10][10];
int i,j;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
if(i==0 || j==0 || i==9|| j==9){
maze[i][j]=1;
} else{
maze[i][j]=0;
}
}
}
maze[1][3]=1;
maze[1][7]=1;
maze[2][3]=1;
maze[2][7]=1;
maze[3][5]=1;
maze[3][6]=1;
maze[4][2]=1;
maze[4][3]=1;
maze[4][4]=1;
maze[5][4]=1;
maze[6][2]=1;
maze[6][6]=1;
maze[7][2]=1;
maze[7][3]=1;
maze[7][4]=1;
maze[7][6]=1;
maze[7][7]=1;
maze[8][1]=1;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
printf(" %d",maze[i][j]);
}
printf("\n");
}
Queue *q;
lqnode *p;
q=(Queue *)malloc(sizeof(Queue));
p=(lqnode *)malloc(sizeof(lqnode));
p->next=null;
q->rear=p;
q->front=p;
int x,y;
lqnode *r,*t;
r=(lqnode *)malloc(sizeof(lqnode));
r->x=1;
r->y=1;
r->last=null;
q->rear->next=r;
r->next=null;
q->rear=r;
t=q->front->next;
x=t->x;
y=t->y;
printf("可以走的点\n");
while(x!=8 || y!=8){
if(maze[x][y+1]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x;
r->y=y+1;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x][y+1]=2;
}
if(maze[x+1][y]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x+1;
r->y=y;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x+1][y]=2;
}
if(maze[x][y-1]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x;
r->y=y-1;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x][y-1]=2;
}
if(maze[x+1][y]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x+1;
r->y=y;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x+1][y]=2;
}
//可以走的就加入队列,然后队列是从头开始循环的,一边循环一边加入了新元素
t=t->next;
x=t->x;
y=t->y;
printf("%d,%d\n",x,y);
}
printf("溯源:\n");
while(t->last!=NULL){
printf("x=%d,y=%d\n",t->x,t->y);
t=t->last;
}
//用last记录每一个节点是由哪个节点走过来的
return 0;
}
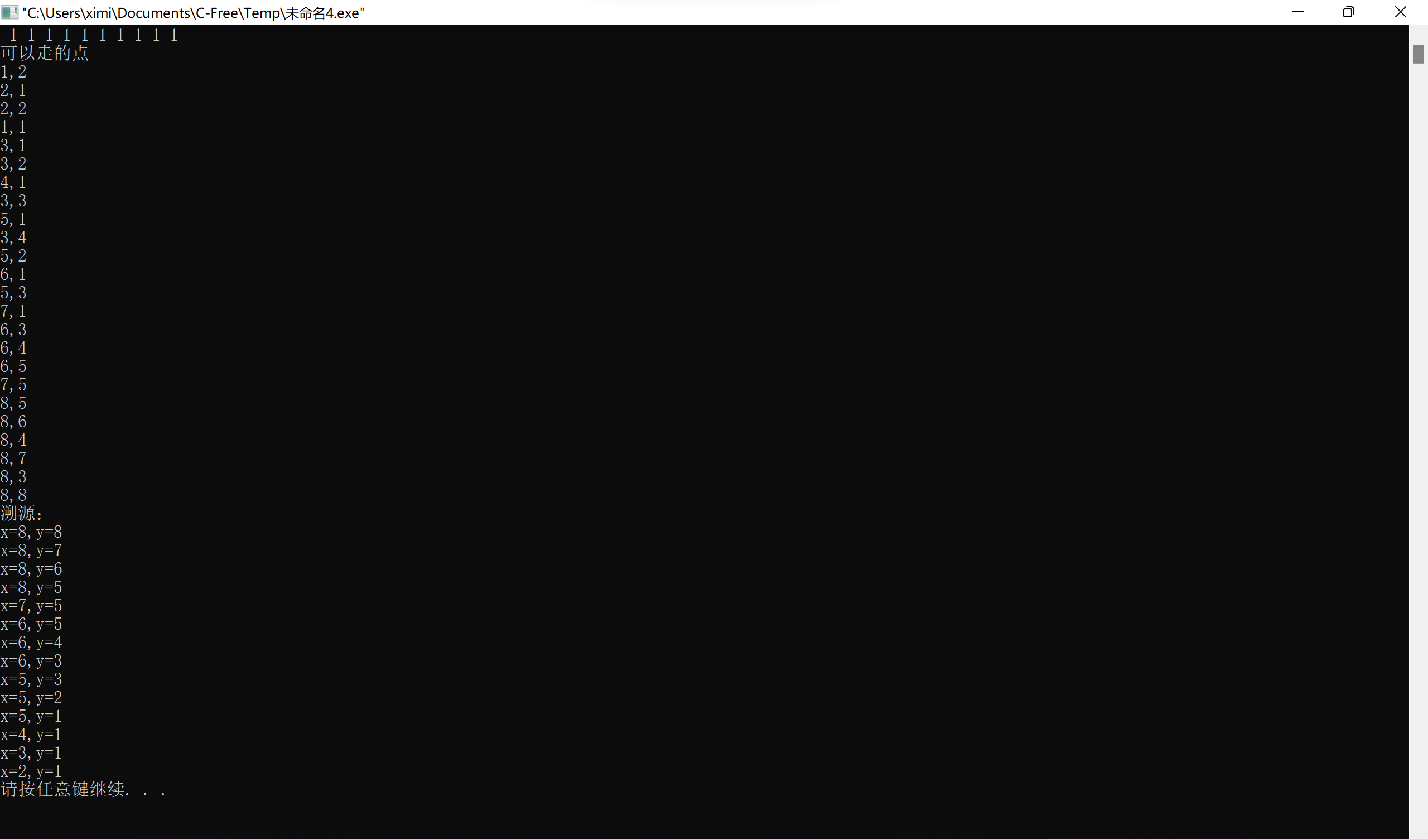
1 1 1 1 是上面的迷宫,截图没有截好
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
嗨~大家好,这里是可莉!今天给大家带来的是7个C语言的经典基础代码~那一起往下看下去把【程序一】打印100到200之间的素数#includeintmain(){ inti; for(i=100;i 【程序二】输出乘法口诀表#includeintmain(){inti;for(i=1;i 【程序三】判断1000年---2000年之间的闰年#includeintmain(){intyear;for(year=1000;year 【程序四】给定两个整形变量的值,将两个值的内容进行交换。这里提供两种方法来进行交换,第一种为创建临时变量来进行交换,第二种是不创建临时变量而直接进行交换。1.创建临时变量来
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我有一个将某些事件写入队列的Rails3应用。现在我想在服务器上创建一个服务,每x秒轮询一次队列,并按计划执行其他任务。除了创建ruby脚本并通过cron作业运行它之外,还有其他稳定的替代方案吗? 最佳答案 尽管启动基于Rails的持久任务是一种选择,但您可能希望查看更有序的系统,例如delayed_job或Starling管理您的工作量。我建议不要在cron中运行某些东西,因为启动整个Rails堆栈的开销可能很大。每隔几秒运行一次它是不切实际的,因为Rails上的启动时间通常为5-15秒,具体取决于您的硬件。不过,每天这样做几
关闭。这个问题是off-topic.它目前不接受答案。想改进这个问题吗?Updatethequestion所以它是on-topic用于堆栈溢出。关闭11年前。Improvethisquestion我不经常使用ruby-通常它加起来相当于每两个月或更长时间编写一次脚本。我的大部分编程都是使用C++进行的,这与ruby有很大不同。由于我与ruby之间的差距如此之大,我总是忘记语言的基本方面(比如解析文本文件和其他简单的东西)。我想每天练习一些基本的东西,我想知道是否有一些我可以订阅的网站,并且会向我发送当天的Ruby问题或类似的东西。有人知道这样的站点/Internet服务吗?
如果特定语言环境中缺少翻译,如何配置i18n以使用en语言环境翻译?当前已插入翻译缺失消息。我正在使用RoR3.1。 最佳答案 找到相似的question这里是答案:#application.rb#railswillfallbacktoconfig.i18n.default_localetranslationconfig.i18n.fallbacks=true#railswillfallbacktoen,nomatterwhatissetasconfig.i18n.default_localeconfig.i18n.fallback
在我的双语Rails4应用程序中,我有一个像这样的LocalesController:classLocalesController用户可以通过此表单更改其语言环境:deflocale_switcherform_tagurl_for(:controller=>'locales',:action=>'change_locale'),:method=>'get',:id=>'locale_switcher'doselect_tag'set_locale',options_for_select(LANGUAGES,I18n.locale.to_s)end这有效。但是,目前用户无法通过URL更改