95 个正样本,但是负样本只有 5 个。这种类别数据不均衡的情况下,如果不做不平衡样本的处理,会导致模型在数目较少的类别上出现“欠学习”现象,即可能在测试集上完全丧失对负样本的预测能力。
除了常见的分类、回归任务,类似图像语义分割、深度估计等像素级别任务中也是存在不平衡样本问题的。
解决不平衡样本问题的处理方法一般有两种:
ACNet)参考文章 如何针对数据不平衡做处理。虽然目前深度学习框架中都自带了一些数据增强函数,但更多更强的数据增强手段可以使用一些图像增强库,比如
imgaug 这个 python 库。
模型训练过程中,pytorch 框架如何在数据构建 pipeline 阶段使用 imgaug 库可以参考文章 数据增强-imgaug。
over-sampling、up-sampling,也叫数据过采样) 或 也叫数据欠采样数据下采样(under-sampling 、down-sampling )。
1,对于样本数目较少的类别,可用数据过采样方法(over-sampling),即通过复制方法使得该类图像数目增至与样本最多类的样本数一致。
2,而对于样本数较多的类别,可使用数据欠采样(Under-sampling,也叫数据欠采样)方法。对于深度学习和计算机视觉领域的任务来说,下采样并不是直接随机丢弃一部分图像,正确的下采样策略是: 在批处理训练时(数据加载阶段 dataloader),对于样本较多的类别,严格控制每批(batch)随机抽取的图像数目,使得每批读取的数据中正负样本是均衡的(类别均衡)。以二分类任务为例,假设原始数据分布情况下每批处理训练正负样本平均数量比例为 9:1,如仅使用下采样策略,则可在每批随机挑选训练样本时每 9 个正样本只取 1 个作为该批训练集的正样本,负样本选择策略不变,这样可使得每批读取的训练数据中正负样本时平衡的。
数据过采样和欠采样示意图如下所示。

这里的较小类别的意思是样本数目较少的类别,较大类别即样本数目较多的类别。以上内容都是对解决类别不平衡问题中数据采样方法的策略描述,但想要在实际任务中解决问题,还要求我们加深对任务(
task)的分析、对数据的理解分析,以及要求我们有更多的数据处理、数据采样的代码经验,即良好的策略 + 熟练的工具。
需要注意的是,因为仅仅使用数据上采样策略有可能会引起模型过拟合问题,所以在实际任务中,更为保险的数据采样策略哇往往是将上采样和下采样结合起来使用。
ImageNet 数据集)。由此,在类别平衡采样的基础上,国内海康威视研究院提出了一种“类别重组采样”的平衡方法。
类别重组法是在《解析卷积神经网络》这本书中看到的,可惜没在网上找到原论文和代码,但这个方法感觉还是很有用的,且也比较好复现。如下图所示,类别重组方法步骤如下:
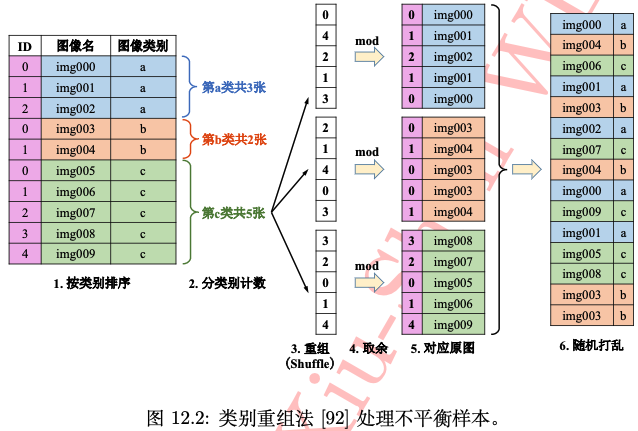
max_num。max_num 产生一个随机数列表,然后用此列表中的随机数对各自类别的样本数求余,得到对应索引值列表 index_list。random.shuffle(list(range(max_num)))index_list,从该类的图像数据中提取图像,生成该类的图像随机列表。epoch)都对此列表进行遍历数据用于模型训练,如此重复。 类别重组法对有点很明显,在设计好重组代码函数后,只需要原始图像列表即可,所有操作都在内存中在线完成,易于实现且更通用。其实仔细深究可以发现,海康提出的这个类别重组法和前面的数据采样方法是很类似的,其本质都是通过采样(sampler)策略让类别不均衡的各类数据在每轮训练中出现的次数是一致的。
类别重组法对有点很明显,在设计好重组代码函数后,只需要原始图像列表即可,所有操作都在内存中在线完成,易于实现且更通用。其实仔细深究可以发现,海康提出的这个类别重组法和前面的数据采样方法是很类似的,其本质都是通过采样(sampler)策略让类别不均衡的各类数据在每轮训练中出现的次数是一致的。
one-stage 目标检测中正负样本比例严重失衡的问题,该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘,经实践证明 Focal Loss 在 one-stage 目标检测中还是很有效的,但是在多分类中不一定有效。
Focal Loss 作者通过在交叉熵损失函数上加上一个调整因子(modulating factor)$(1-p_t)^\gamma$,把高置信度 $p$(易分样本)样本的损失降低一些。Focal Loss 定义如下:
$$FL(p_t) = -(1-p_t)^\gamma log(p_t) = \left{\begin{matrix}
-(1-p)^\gamma log(p), & if \quad y=1 \
-p^\gamma log(1-p), & if\quad y=0
\end{matrix}\right.$$
Focal Loss 有两个性质:
1,loss 几乎不受影响;当 $p_t$ 接近于 1,调质因子(factor)也接近于 0,容易分类样本的损失被减少了权重,整体而言,相当于增加了分类不准确样本在损失函数中的权重。Focal Loss 等同于 CE Loss。 $\gamma$ 在增加,调制因子的作用也就增加,实验证明 $\gamma = 2$ 时,模型效果最好。100 倍,而当 $p_t = 0.968$ 时,其损耗将降低 1000 倍。这反过来又增加了错误分类样本的重要性(对于 $pt≤0.5$ 和 $\gamma = 2$,其损失最多减少 4 倍)。在训练过程关注对象的排序为正难 > 负难 > 正易 > 负易。
| 难 | 易 | |
|---|---|---|
| 正 | 1. 正难 | 3. 正易,$\gamma$ 衰减 |
| 负 | 2. 负难,$\alpha$ 衰减 | 4. 负易,$\alpha、\gamma$衰减 |
Focal Loss:
$$FL(p_t) = -\alpha (1-p_t)^\gamma log(p_t)$$
作者在实验中采用这种形式,发现它比非 $\alpha$ 平衡形式(non-$\alpha$-balanced)的精确度稍有提高。实验表明 $\gamma$ 取 2,$\alpha$ 取 0.25 的时候效果最佳。
更多理解参考 focal loss 论文。
Focal Loss 这种高明的损失函数策略外,针对图像分类问题,还有一种简单直接的损失函数加权方法,即在计算损失函数过程中,对每个类别的损失做加权处理,具体的 PyTorch 实现方式如下:
weights = torch.FloatTensor([1, 1, 8, 8, 4]) # 类别权重分别是 1:1:8:8:4
# pos_weight_weight(tensor): 1-D tensor,n 个元素,分别代表 n 类的权重,
# 为每个批次元素的损失指定的手动重新缩放权重,
# 如果你的训练样本很不均衡的话,是非常有用的。默认值为 None。
criterion = nn.BCEWithLogitsLoss(pos_weight=weights).cuda()
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
如何匹配未被反斜杠转义的平衡定界符对(其本身未被反斜杠转义)(无需考虑嵌套)?例如对于反引号,我试过了,但是转义的反引号没有像转义那样工作。regex=/(?!$1:"how\\"#expected"how\\`are"上面的正则表达式不考虑由反斜杠转义并位于反引号前面的反斜杠,但我愿意考虑。StackOverflow如何做到这一点?这样做的目的并不复杂。我有文档文本,其中包括内联代码的反引号,就像StackOverflow一样,我想在HTML文件中显示它,内联代码用一些spanMaterial装饰。不会有嵌套,但转义反引号或转义反斜杠可能出现在任何地方。
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我对图像处理完全陌生。我对JPEG内部是什么以及它是如何工作一无所知。我想知道,是否可以在某处找到执行以下简单操作的ruby代码:打开jpeg文件。遍历每个像素并将其颜色设置为fx绿色。将结果写入另一个文件。我对如何使用ruby-vips库实现这一点特别感兴趣https://github.com/ender672/ruby-vips我的目标-学习如何使用ruby-vips执行基本的图像处理操作(Gamma校正、亮度、色调……)任何指向比“helloworld”更复杂的工作示例的链接——比如ruby-vips的github页面上的链接,我们将不胜感激!如果有ruby-
我有一个super简单的脚本,它几乎包含了FayeWebSocketGitHub页面上用于处理关闭连接的内容:ws=Faye::WebSocket::Client.new(url,nil,:headers=>headers)ws.on:opendo|event|p[:open]#sendpingcommand#sendtestcommand#ws.send({command:'test'}.to_json)endws.on:messagedo|event|#hereistheentrypointfordatacomingfromtheserver.pJSON.parse(event.d
我正在尝试解析网页,但有时会收到404错误。这是我用来获取网页的代码:result=Net::HTTP::getURI.parse(URI.escape(url))如何测试result是否为404错误代码? 最佳答案 像这样重写你的代码:uri=URI.parse(url)result=Net::HTTP.start(uri.host,uri.port){|http|http.get(uri.path)}putsresult.codeputsresult.body这将打印状态码和正文。
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/