为了防止不必要的报错,部署之前请务必从开头开始看,切勿跳过其中一个部署模式,因为每一个部署模式都是从上一个模式的配置上进行的
下载地址:https://archive.apache.org/dist/spark/
本文所下载版本为:spark-3.3.0-bin-hadoop2
环境:
hadoop-2.7.5jdk1.8.0Scala所谓的Local模式,就是不需要其他任何节点资源就可以在本地执行Spark代码的环境
将spark-3.3.0-bin-hadoop2.tgz包上传至Linux并解压指定目录
tar -zxvf spark-3.3.0-bin-hadoop2.tgz -C /export/servers
为了方便后续操作,建议修改文件名(可忽略)
cd /export/servers
mv spark-3.3.0-bin-hadoop2 spark-3.3.0
添加环境变量/etc/profile:
sudo vim /etc/profile
在文件内添加以下变量
export SPARK_HOME=/export/servers/spark-3.3.0
export PATH=$SPARK_HOME/bin:$HBASE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$PATH
使用环境变量生效:
source /etc/profile
进入spark-3.3.0执行命令 bin/spark-shel

看到这个界面表示本地启动成功
web端查看
启动成功后,可以输入网址进行Web UI监控页面访问
http://master:4040

local本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用Spark自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark的Standalone模式体现了经典的master-slave模式。
修改配置文件
进入spark的conf目录
cd /export/servers/spark-3.3.0/conf
修改以下配置
这三个文件在目录里都是模板,这里我们需要各复制一份出来并删除模板后缀名.template
cp workers.template workers
cp spark-defaults.conf.template spark-defaults.conf
cp spark-env.sh.template spark-env.sh
修改workers文件,删除localhost,添加以下内容
master
slave1
slave2
注意这里的节点,是你的分布式集群三台虚拟机的主机名
修改spark-env.sh,添加JAVA_HOME环境变量和对应的master节点
export JAVA_HOME=/export/servers/jdk1.8.0_181
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
注意:7077端口,相当于slave2内部通信的8020端口,此处的端口需要确认自己的Hadoop配置
默认就是7077,这里我们不做改动
分发spark文件给其他节点
scp -r /export/servers/spark-3.3.0 slave1:/export/servers
scp -r /export/servers/spark-3.3.0 slave2:/export/servers
将porfile环境配置文件发给其他节点并刷新配置
sudo scp -r /etc/profile slave1:/etc/profile
sudo scp -r /etc/profile slave2:/etc/profile
source /etc/profile
执行脚本 sbin/start-all.sh,注意是在spark目录下
sbin/start-all.sh

查看三台服务器的进程

查看master节点上的资源监控页面web端http://master:8080

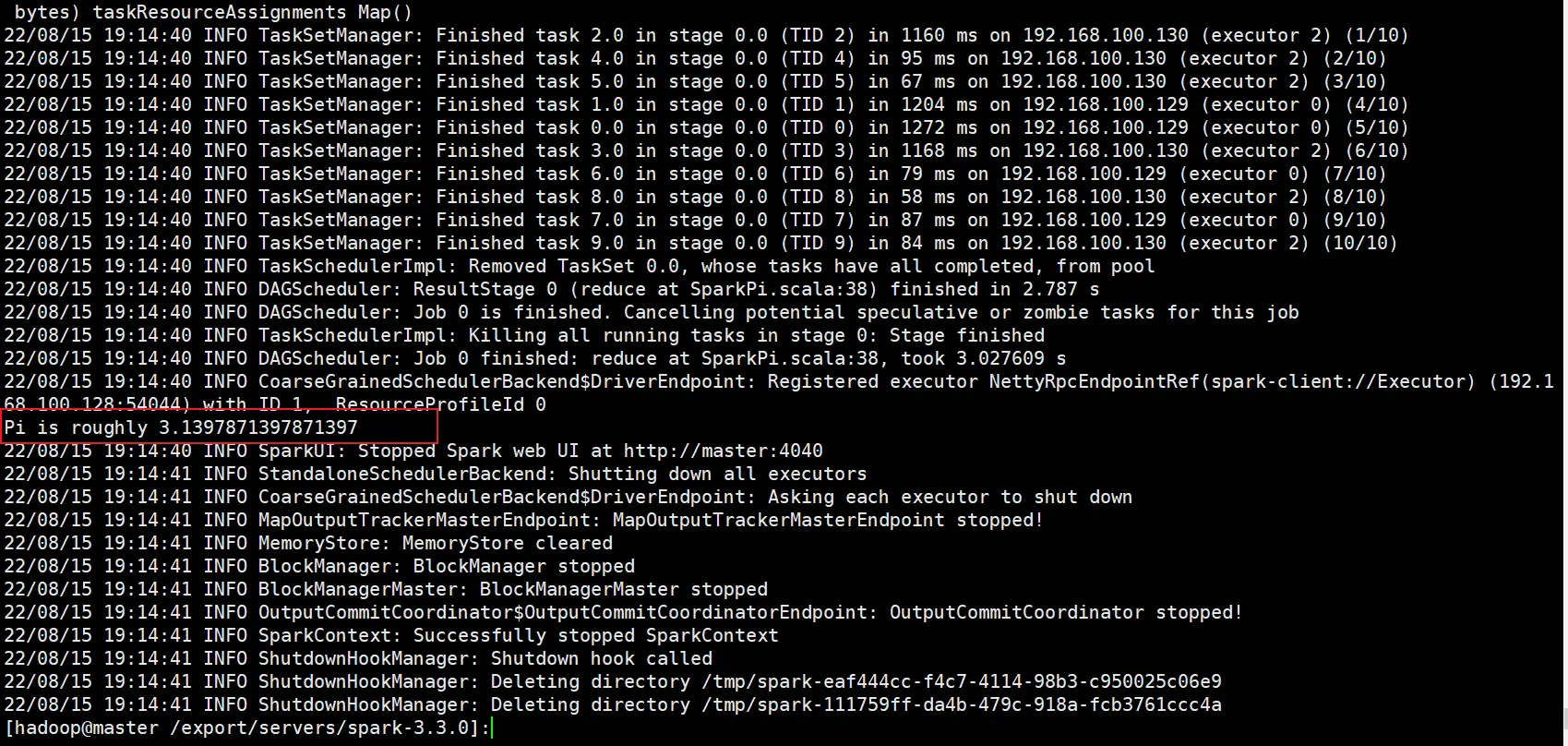
提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.3.0.jar \10
提交参数说明
在提交应用中,一般会同时一些提交参数
bin/spark-submit \
--class <main-class>
--master <master-url> \... # other options<application-jar> \[application-arguments]
| 参数 | 解释 | 可选值举例 |
|---|---|---|
| –class | Spark程序中包含主函数的类 | |
| –master | Spark程序运行的模式(环境) | 模式:local[*]、spark://hadoop02:7077、Yarn |
| –executor-memory 1G | 指定每个executor可用内存为1G | 符合集群内存配置即可,具体情况具体分析。 |
| –total-executor-cores 2 | 指定所有executor使用的cpu核数为2个 | |
| –executor-cores | 指定每个executor使用的cpu核数 | |
| application-jar | 打包好的应用jar,包含依赖。这个URL在集群中全局可见。 比如hdfs:// 共享存储系统,如果是file:// path,那么所有的节点的path都包含同样的jar | |
| application-arguments | 传给main()方法的参数 |
叨叨一句:以下端口号为9000的与hadoop的core-site.xml的配置文件中的一致的,有些人的可能是8020,也有些人的是9000
由于spark-shell停止掉后,集群监控master:4040页面就看不到历史任务的运行情况,所以开发时都配置历史服务器记录任务运行情况。
修改spar-defaults.conf文件添加日志存储路径配置
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:9000/directory

需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
start-all.sh
hadoop fs -mkdir /directory
修改spark-env.sh文件, 添加日志配置
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://master:9000/directory
-Dspark.history.retainedApplications=30"

分发配置文件
scp -r /export/servers/spark-3.3.0 slave1:/export/servers
scp -r /export/servers/spark-3.3.0 slave2:/export/servers
重新启动集群和历史服务
sbin/start-all.sh
sbin/start-history-server.sh
重新执行任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077 \
./examples/jars/spark-examples_2.12-3.3.0.jar \10
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r9J4qN8Z-1660795217488)(https://cdn.staticaly.com/gh/archenblog/imgs@master/imags/image-20220815202636140.webp)]
查看历史服务器http://master:18080

在集群中配置多个Master结点。这里的高可用采用Zookeeper设置。
集群规划:
| master | slave1 | salve2 |
|---|---|---|
| Master | Master | |
| Zookeeper | Zookeeper | Zookeeper |
| Worker | Worker | Worker |
停止集群
sbin/stop-all.sh
逐个节点启动 Zookeeper
zkServer.sh start
修改 spark-env.sh文件添加如下配置
#注释如下内容:
#SPARK_MASTER_HOST=master
#SPARK_MASTER_PORT=7077
#添加如下内容:
# Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,
# 所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=master,slave1,slave2
-Dspark.deploy.zookeeper.dir=/spark"

分发配置文件
scp -r /export/servers/spark-3.3.0 slave1:/export/servers
scp -r /export/servers/spark-3.3.0 slave2:/export/servers
启动集群
sbin/start-all.sh
查看当前结点状态:http://master:8989

启动 slave1 的单独 Master节点,此时 slave1 节点 Master 状态处于备用状态
sbin/start-master.sh


提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077,slave1:7077 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
如果报错,解决方法如下:
杀死master的master进程后再执行以上命令

查看 slave1 的 Master 资源监控 Web UI,稍等一段时间后,slave1 节点的 Master 状态提升为活动状态
217491)]
提交应用到高可用集群
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://master:7077,slave1:7077 \
./examples/jars/spark-examples_2.12-3.3.0.jar \
10
如果报错,解决方法如下:
杀死master的master进程后再执行以上命令
[外链图片转存中…(img-kfaEOiH0-1660795217492)]
查看 slave1 的 Master 资源监控 Web UI,稍等一段时间后,slave1 节点的 Master 状态提升为活动状态

我正在尝试测试是否存在表单。我是Rails新手。我的new.html.erb_spec.rb文件的内容是:require'spec_helper'describe"messages/new.html.erb"doit"shouldrendertheform"dorender'/messages/new.html.erb'reponse.shouldhave_form_putting_to(@message)with_submit_buttonendendView本身,new.html.erb,有代码:当我运行rspec时,它失败了:1)messages/new.html.erbshou
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
我打算为ruby脚本创建一个安装程序,但我希望能够确保机器安装了RVM。有没有一种方法可以完全离线安装RVM并且不引人注目(通过不引人注目,就像创建一个可以做所有事情的脚本而不是要求用户向他们的bash_profile或bashrc添加一些东西)我不是要脚本本身,只是一个关于如何走这条路的快速指针(如果可能的话)。我们还研究了这个很有帮助的问题:RVM-isthereawayforsimpleofflineinstall?但有点误导,因为答案只向我们展示了如何离线在RVM中安装ruby。我们需要能够离线安装RVM本身,并查看脚本https://raw.github.com/wayn
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
我有一个奇怪的问题:我在rvm上安装了rubyonrails。一切正常,我可以创建项目。但是在我输入“railsnew”时重新启动后,我有“程序'rails'当前未安装。”。SystemUbuntu12.04ruby-v"1.9.3p194"gemlistactionmailer(3.2.5)actionpack(3.2.5)activemodel(3.2.5)activerecord(3.2.5)activeresource(3.2.5)activesupport(3.2.5)arel(3.0.2)builder(3.0.0)bundler(1.1.4)coffee-rails(
我刚刚为fedora安装了emacs。我想用emacs编写ruby。为ruby提供代码提示、代码完成类型功能所需的工具、扩展是什么? 最佳答案 ruby-mode已经包含在Emacs23之后的版本中。不过,它也可以通过ELPA获得。您可能感兴趣的其他一些事情是集成RVM、feature-mode(Cucumber)、rspec-mode、ruby-electric、inf-ruby、rinari(用于Rails)等。这是我当前用于Ruby开发的Emacs配置:https://github.com/citizen428/emacs